面向基本路径学习的代码自动命名
2022-11-18王一凡赵逢禹
王一凡,赵逢禹,艾 均
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
方法名是一种用于标识程序方法的特殊标识符,标识符的质量被证明对源代码的可读性和维护性有显著影响[1].一个恰当的方法名不仅要描述方法是什么,还要描述它的功能,因此方法的抽象命名通常具有挑战性.
方法代码抽象命名的相关研究已经有许多成果,如基于启发式规则的方法[2]和应用文本分析技术的方法[3].文献[2]提取方法代码的数据流和控制流相关的特征,作为方法名模板对应的规则,根据启发式规则去检测具有与规则类似特征的方法代码名称是否准确.应用文本分析技术的方法的基本思想是将方法代码当作自然语言文本进行处理.文献[3]将源代码中关键字标识符剔除,使用文本主题提取算法得到文本主题特征,将提取的文本摘要作为方法名.
最近,研究者将机器学习的技术引入到方法代码的抽象命名中[4,7],这种方法的关键技术是将方法代码抽象成新的代码表示作为代码特征,应用机器学习技术自动学习代码特征,根据相似的代码具有相似的特征的原则,从给定的方法名语料库中匹配出已有类似的方法名或者组合出高质量新的方法名,因此抽象出的代码表示要包含程序丰富的语义信息.文献[4]引入log-bilinear神经语言模型,捕获源代码中能够表示长距离上下文特征的token序列,将方法名以及方法名的子标记嵌入到高维空间,推荐在空间中与新方法具有相似嵌入的方法名.文献[5]引入卷积注意力神经网络,对方法的token序列进行卷积操作,将方法片段总结为具有描述性的方法名的过程看作一个翻译任务.然而token序列缺失了方法代码的结构信息,提取到的方法特征不能表示方法代码的强结构性,为了提取代码语义信息,文献[6]提出一种通用的基于路径的方法,使用AST中叶子节点之间的路径和叶子节点相关联的标识符作为一条路径来表示方法,这使得深度学习模型能够利用源代码的结构特性,而不是将其视为一个扁平的token序列.在此结构基础上,文献[7]又提出code2vec,进一步引入注意力神经网络将AST路径集聚合成分布式向量,具有相似AST路径的方法的分布式向量在高维连续空间彼此接近,从而捕获方法之间以及方法名称之间的语义相似性.
文献[6]和文献[7]的研究,考虑到了程序的强结构特性[8],然而对程序的控制流信息以及程序动态可执行性等特征的关注度不够.
本文针对提取出的方法特征缺失控制流信息以及不能反映程序动态可执行的问题,提出基于基本路径学习的方法来对方法代码抽象命名.首先研究了方法代码控制流图的构建,接着从本文构建的控制流图中抽取基本路径作为方法代码的中间表示.然后将基本路径集转换成向量形式输入到引入注意力机制[9]的LSTM神经网络[10],以方法标签为输出目标设计损失函数.最后为了验证学习基本路径训练出的模型能更好理解方法代码的语义信息,构建了基于文献[6]的数据集的训练样本,训练得到代码自动命名模型,并对实验结果进行了分析.
2 基于基本路径学习的方法代码自动命名
神经网络是以向量作为输入,所以需要将程序表示为向量,并且转换出的向量能够表示程序的语义信息.因此可以使用中间表示作为程序和转换成的向量之间的桥梁.为了使神经网络学习到程序的控制流以及动态可执行的语义信息,本文以方法作为程序大小的粒度,使用基本路径作为方法代码的中间表示,并将基本路径转换成向量形式输入神经网络,训练出基于基本路径学习的程序方法名代码自动命名模型.
基于基本路径学习的方法代码自动命名分为两个阶段:训练阶段和自动命名阶段.如图1所示给出了训练阶段的流程,该流程包括构建控制流图,提取基本路径集,将提取的基本路径转换成向量表示以及训练神经网络模型4步.自动命名阶段将待命名的方法代码按照训练阶段前3步进行处理,第4步直接将向量输入到训练好的神经网络中,解析出与方法名标签库中语义最接近的方法名.下面详细介绍训练阶段的具体过程.
第1步.构建方法代码控制流图
从源代码中提取以方法为粒度的代码段,通过编译器将方法代码分析优化得到三地址码中间表示[11],然后通过本文给出的控制流图构建算法,将三地址码代码段进行代码段分块,并在基本块之间添加控制流边得到控制流图.
第2步.提取基本路径集
将控制流图中的每个基本块作为基本路径中的路径节点,并且将路径节点中变量的具体值抽象为具体的token以达到降低token数量级的目的,降低词嵌入学习过程的复杂度[12].接着借鉴深度优先搜索的思想,构建算法提取出方法代码的所有执行路径作为方法的基本路径集合.
第3步.将基本路径集转进行词嵌入
首先将基本路径集中的字符建立token词表,此时基本路径中的对应的token使用词表中的token编号进行映射表示.然后将token通过word2vec技术[13]训练得到每个token的词向量.最后通过字典表映射关系将基本路径转换成向量形式.
第4步.训练神经网络模型
方法代码的语义信息上下文依赖较长,本文选择拥有记忆单元的LSTM神经网络进行建模.首先将上一步得到的路径向量输入到LSTM神经网络中,得到每条路径的上下文基本路径向量.然后将每条路径向量聚合为代码向量,在聚合过程中使用注意力机制对每条路径向量计算权重,其中的权重是训练过程中根据每条路径的影响程度不断更新.最后通过softmax层计算出代码向量和方法名标签的分布概率,损失函数计算出正确分布与预测分布的差值,使用梯度优化算法完成整个模型的闭环训练.最终得到LSTM神经网络以及注意力向量的参数.
3 模型算法
3.1 控制流图构建
3.1.1 三地址码与Soot
本文使用更加抽象和简洁的三地址码作为方法代码的中间表示.三地址码由一组类似于汇编语言的指令组成,每条指令最多由3个运算分量组成,且最多只执行一次运算,这里的运算通常是计算、比较或者分支跳转.表1给出了源代码对应的“三地址”指令序列的示例.

表1 三地址码指令序列
考虑到模型的复用性,模型可以选择特定于语言的编译器来优化处理源代码,以得到方法代码的三地址码序列.本文选择Java语言编写的源代码作为研究对象,因此选择分析Java程序的Soot静态编译器,生成Soot特有的三地址码:Jimple[14].Soot能够将Java代码中的循环结构转换成goto指令的形式,使代码中只有分支和顺序两种控制流向,达到简化方法代码控制逻辑的目的.
3.1.2 控制流图构建算法
传统方法构建的控制流图分支结构复杂,在此基础上提取的基本路径包含的路径较长[15],使用LSTM神经网络训练时会出现梯度消失与梯度爆炸的问题.本文在三地址代码序列基础上构建程序控制流图,优化程序控制结构,达到缩短基本路径长度的目的.控制流图中的每一个节点表示一个基本块(基本块表示控制流只能从基本块第一条指令进入,除了基本块的最后一条指令控制流在离开基本块前不发生跳转),每一条边表示两个基本块之间的控制流转移.
构建程序控制流图的步骤如下:
1)通过静态编译器分析得到三地址代码序列;
2)在三地址代码序列的基础上进行基本块划分;
3)基本块之间添加边信息,构建程序控制流程图.
算法1.方法代码控制流图构建算法
输入:方法代码序列,Method={token1,…,tokenn},其中Method为方法代码,tokenn为方法中的词法单元.
输出:方法代码对应的控制流图CFG={V,E},其中V={BasicBlock1,…,BasicBlockn},E={〈BasicBlocki,BasicBlockj〉,…}.
处理:
//Soot静态分析器得到三地址码序列
1.Jimple3AC←SootCompilerProcess(Method);
//每条三地址码指令记录在数组Stmts[]里
2.Stmts[]←Abstract3ACProcess(Jimple3AC);
3.V=φ;//控制流图节点序列,每个节点代表一个基本块BasicBlock
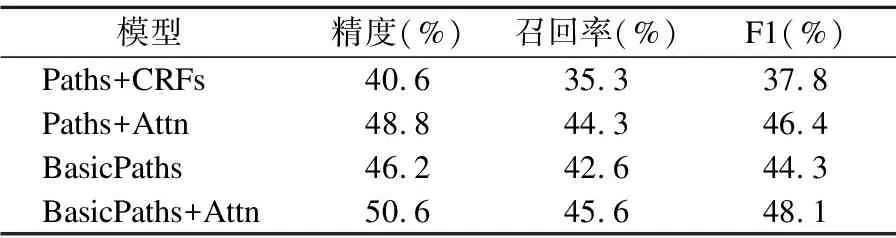
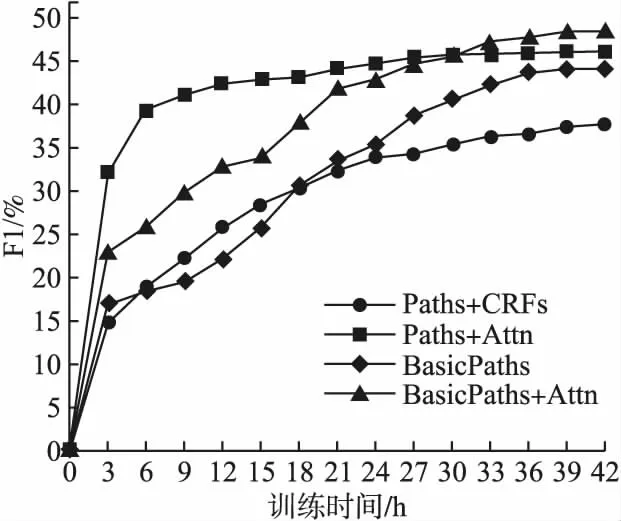
4.while(i new BasicBlock;//创建一个新的基本块 BasicBlock.add(Stmts[i]); while(Stmts[i]与Stmts[i+1]能够组成基本块){ BasicBlock.add(Stmts[i+1]); i++; } V=V∪{BasicBlock}; i++; } 5.E=Ø//控制流图边序列 //添加基本块之间的控制流边 6.for each(BasicBlockiin V){ if(BasicBlocki有后继基本块) E=E∪{〈BasicBlocki,BasicBlocki+1〉}; if(BasicBlocki中存在跳转指令){ for each(BasicBlockjin V){ if(BasicBlockj中存在BasicBlocki的跳转目标指令) E=E∪{〈BasicBlocki,BasicBlockj〉}; } } } 7.return new CFG = {V,E};//返回控制流图 算法1首先将方法代码通过Soot静态分析器得到三地址码指令序列,然后将指令信息封装记录在数组里.接着划分本块集合作为控制流图的节点集,在划分过程中,步骤4两条指令是否能够划分到同一基本块的依据是判断Stmts[i+1]是否为跳转指令的目标指令或者是跳转指令的下一条指令,如果是则不能划分到同一基本块.最后在基本块与其后继基本块之间以及与其跳转到的目标基本块之间添加控制流边.基本块之间的控制流信息包含顺序流向和跳转流向,分别反映出方法代码中的顺序和分支循环逻辑. 基本路径的提取是在控制流图的基础上,通过深度优先搜索算法提取所有的基本路径,构成基本路径集[16].基本路径集中的元素是基本路径,基本路径是指控制流图中从起始结点到终止结点所经过的一系列基本块序列,且该路径上至少有一条边在其它路径中没有出现过,即包含其它路径未曾引入的基本块.基本路径满足覆盖方法代码中的所有分支单元和循环单元,能够覆盖控制流图的各个执行路径以及覆盖所有逻辑控制条件,所以从侧面反映出方法代码的上下文语句执行的因果关系,因此将基本路径作为方法代码的中间表示能够表示程序的动态可执行的特征. 基本路径集定义: 1)基本路径集是由多条基本路径组成,且每条基本路径是集合中的独立路径; 2)集合中的路径包含控制流图的所有节点和边; 3)每条独立路径至少包含一条在其它路径中未出现过的边. 算法2.基本路径提取算法 输入:方法代码对应的控制流图CG={V,E},其中V={v0,…,vn},E={〈vi,vj〉,…〈vm,vn〉}. 输出:基本路径集BPS={path1,…,pathn},其中pathi= 〈vi,…,vm〉. 处理: 1.初始化: BasicPathSet=Ø;//基本路径集 Stack.push(v0);//控制流图开始节点入栈 VisitedV[]=Ø;//记录已被访问节点 VisitedEdge[]=Ø;//记录已被访问边 2.while(Stack is not null){ curV = Stack.peek();//读取当前栈顶节点 Visited[curV];//记录访问过得节点 if(curV是终结节点){ //返回一条基本路径,该路径序列为栈顶到栈底的逆序序列 path←TraversalStack(); BasicPathSet=BasicPathSet∪{path}; while(Stack.peek()不存在未访问过的边){ Stack.pop();//弹出栈中不存在未访问过边的节点 } }else if(curV不存在未访问过的边){ Stack.pop();//回退状态 }else{ e=〈curV,nextV〉∈E且未访问过; if(nextV未被访问过){ VisitedEdge[e]=true;//记录访问过该条边 Stack.push(nextV);//压入堆栈 }else if(nextV不存在未访问过的边){ VisitedEdge[e]= true; path1←TraversalStack(); path2←SearchExistedSubseq(nextV); //返回BasicPathSet中任意一条基本路径中存在nextV节点的后继序列 BasicPathSet=BasicPathSet∪{〈path1,path2〉}; } } } 算法从控制流图入口节点开始深度优先遍历,首先判断栈顶节点curV是否为终结节点,如果是则输出栈的逆序序列作为一条基本路径.不是则判断curV是否存在未访问过的边,如果不存在则弹出curV开始下一次循环.如果存在则取以curV为开始节点的边e且后继节点为nextV,此时判断nextV是否访问过,如果未被访问过则记录边e被访问且将nextV压入堆栈;否则如果nextV被访问过且不存在未访问过的边,则此时基本路径集中的某条基本路径pathi必定存在nextV节点,输出栈的逆序序列并拼接pathi中从nextV开始的序列作为一条基本路径. 模型输入:方法代码对应的基本路径集BPS={path1,…,pathn}的向量表示,其中pathi=〈bi1,…,biε〉;因为每条基本路径有不同数量的token,为了让神经网络拥有相同长度的向量输入,引入超参数ε作为基本路径向量的固定长度.方法名标签序列嵌入向量y. 训练结果:得到LSTM神经层和注意力层的权重参数,以及方法代码的向量. softmax层:调用TensorFlow框架的softmax层计算代码向量v在方法名标签嵌入空间的预测概率分布,以cross-entropy损失函数[17]计算正确分布p和预测分布q之间的误差,使用Adam梯度优化算法更新模型参数训练网络[18].其中正确分布是方法代码的标签在标签库的真实分布(是正确标注值为1,否则为0),模型预测得到的概率分布q是由方法代码向量v和标签库中对应标签嵌入向量的点积得到. 为了验证将基本路径作为方法代码的中间表示能够包含更丰富的语义信息,训练得到的模型能够更准确的命名方法名,本文与先前工作进行实验对比,并从学习开销的角度分析方法优劣.为了统计分析模型在对不同复杂度的方法代码命名的表现,以圈复杂度作为衡量代码复杂度的依据进行实验. 本文采用文献[6]中的Java-med数据集,该数据集包含了1000个高质量Java项目,约400万个方法,其中900个项目作为训练集,100个作为测试集,并将该数据集经过如下处理构建实验训练样本. 首先将项目中的类依据方法签名(即返回值类型、方法名、参数类型)拆分出各个方法,并抽取方法名作为该方法的标注,在拆分过程中过滤掉类中的set、get类型方法,这些方法对于模型训练没有多少价值[19].然后,将拆分出的方法代码按照3.1.2节的方法构建出控制流图.最后,将控制流图按照3.2节中论述的方法提取出基本路径集,以方法代码的基本路径集作为模型的输入,方法名标签作为标注,构成如表2所示的训练数据格式. 表2 训练数据格式 本文在操作系统为Ubuntu 16.04.7 LTS的服务器上进行相关实验.设备硬件环境为:处理器是Intel®CoreTMi7-7700 CPU@4.20 GHz*8,内存为64GB,显卡为NVIDIA GeForce GTX 1080Ti.设备软件环境为:深度学习框架是TensorFlow_gpu-1.4.0,Python使用Python3.7版本. 步骤1.构建控制流图 将数据集中预处理好的方法代码依次保存在单独文件中,通过处理程序调用soot工具包中的Main处理类将方法源代码文件转换成Jimple三地址码文件.编写BasicBlock类作为抽象基本块的数据结构,编写Edge类记录基本块之间边信息,编写CFG类聚合基本块以及边信息作为控制流图保存的数据结构. 步骤2.提取基本路径集 编写处理程序读入控制流图数据,调用3.2节设计的算法得到基本路径集合,将每个方法代码以{方法名标注,基本路径集}的数据组合形式输出到具体的训练集和测试集的文件中. 步骤3.将基本路径和方法名标签量化表示 将基本路径集中的每条基本路径的三地址码序列使用moses切词工具得到token,并对token建立字典库.使用word2vec词向量嵌入工具对token嵌入学习,得到每个token对应的词向量.根据字典映射关系将基本路径中的每个token使用词向量表示.方法名标注组成的标签库中的方法名token随机生成一个唯一数字对标注进行量化表示,以便softmax计算方法代码向量在标签库中的概率分布. 步骤4.训练LSTM神经网络 将训练集采用十折交叉验证的方法用于训练LSTM神经网络,网络初始化参数设置为深度学习广泛使用的值,并且设置不同LSTM神经网络的隐藏层数,观察其对结果的影响,最终选择256个隐藏层数效果最好.基本路径转换成的向量固定长度设置为200,能够覆盖大多数基本路径序列长度,因此LSTM网络的时间步长也设置为ε.dropout设置为0.25,更新模型参数的minibatch设置为64,迭代训练epoch设置为4,使用Adam梯度优化算法进行训练,学习速率初始设置为0.01,然后当交叉验证时准确率停止改善时,让学习速率减半继续迭代,最终得到代码自动命名模型. 步骤5.模型评估对比 将本文构建的训练集按照文献[6,7]的方法训练得到对比模型.将测试集分别输入到对比模型和本文得到的模型,采用文献[7]中的评价指标对模型结果统计分析. 实验1.模型对比结果分析 如表3所示本文提出基于基本路径学习的代码自动命名模型与其它基线模型:Paths+CRFs[6]、Paths+Attn[7]的对比情况.本文提出的模型记为BasicPaths+Attn,其中BasicPaths表示不使用注意力机制进行的对比实验,具体做法是在聚合上下文基本路径向量时直接使用求和取平均的方法得到方法代码向量. 表3 模型得分评估 观察实验结果得出本文提出的模型得分优于其它模型.文献[7]提出的AST路径更多的表示上下文token的依赖关联,而本文提取的基本路径不局限于单个上下文token,而是上下文关联的基本块之间的依赖关系,并且LSTM网络能够捕获到长距离的上下文依赖,因此本文模型能够更好理解方法代码的语义.并且本文使用注意力机制作用于方法代码的关键基本路径,使聚合得到的方法代码向量更能够表示代码的特征信息,从而训练得到的模型效果更好. 实验2.模型训练开销分析 将基线模型与本文模型在处理好的数据集上进行训练,并且基线模型使用他们默认的超参数.对于本文模型,调整LSTM神经网络隐藏层以及基本路径序列长度等参数,观察对于F1值的影响,确定最佳的超参数.在调整过程中神经网络超参数根据硬件性能从大往小进行调整,基本路径序列的长度从短到长进行设置,最终确定LSTM隐藏层数为256,基本路径序列长度固定为200.本文也基于该超参数讨论与基线模型的训练时间开销对比,统计结果如图2所示. 图2 模型训练时间开销对比 观察训练时间开销可知,Paths+Attn模型在较短时间内达到最佳效果,本文模型在27小时之后分数超过基线模型并在42个小时达到最佳效果.Paths+Attn模型的输入吞吐量达到每分钟1000个方法,所以能够在较短时间内学习大量的方法代码,因此能够在短时间内达到较好的效果.而本文模型采用的LSTM神经网络计算开销高于基线模型,模型输入吞吐量较小,然而随着学习大量数据网络记忆单元的参数进行调整,网络输出的上下文基本路径向量包含更多的上下文信息,因此随着训练时间的推移本文模型的效果优于基线模型. 实验3.方法代码复杂度影响分析 本文在构建控制流图过程中根据点边计算法得到方法代码的圈复杂度,以统计分析复杂度对模型的性能影响.针对本模型,方法代码圈复杂度数量增大,其控制流图包含的边和节点线性增加,为了满足逻辑覆盖以及分支覆盖,提取出的基本路基长度也随着线性增加,在训练过程中受LSTM的时间步的限制,基本路径向量上下文关联性会逐渐丢失,进而影响模型效果.为了评估方法代码逻辑复杂度对本模型的影响,本文选择圈复杂度数在1-12之间的方法代码检验模型的F1得分情况,并且与基线模型进行对比. 如图3所示本文提出的模型与基线模型在方法代码圈复杂度数相同时的对比情况.从图中可以看出,随着代码复杂度的增加,模型性能均逐渐下降.在复杂度较低情况下,Paths+Attn模型由于模型设计简单且此时AST路径较短,模型能更好的学习到代码特征.然而随着复杂度的提升,AST路径增多且变长,基线模型效果降低,但是基本路径的数量与控制结构的数量相关,因此本文模型所需要学习的路径数量较少,并且本文模型中采用LSTM神经网络能够捕获更长的上下文依赖性,因此在复杂度提升的情况下,本文模型表现的更好. 图3 方法代码复杂度影响对比 本研究提出基于基本路径学习的代码自动命名模型.首先使用编译器对源代码优化分析,得到方法代码的三地址码序列并构建基于三地址码的控制流图.然后构建算法提取基本路径集合.最后构建神经网络模型学习基本路径集的特征,迭代训练得到自动命名模型. 实验结果表明,本文提取能够反映控制流信息以及方法代码可执行特征的基本路径作为代码中间表示,训练出的模型能够更好的捕获代码语义信息,并且对复杂度更高的代码,模型能更好学习到代码特征.在未来的工作中,将继续研究将得到的代码向量应用于代码缺陷检测的任务中.3.2 基本路径提取算法
3.3 神经网络模型


4 实验与结果
4.1 数据集

4.2 实验环境
4.3 实验过程
4.4 实验结果与分析

5 结 论
