基于ResNet-BiLSTM 模型的电力客服工单分类研究
2022-11-18黄秀彬许世辉何学东
黄秀彬,许世辉,赵 阳,居 强,何学东
(1.国家电网有限公司客户服务中心,天津 300306;2.北京中电普华信息技术有限公司,北京 100031)
电力系统客服是供电企业和电力客户间的沟通桥梁,可为电力客户提供高效便利的服务。电力客服工单数据能够记录电力客户在用电过程中的需求、建议和意见,分析工单数据能够有效地定位用户类别,并且有利于提升用户体验。目前的工单数据分类方法,主要由专业的调查人员对工单数据进行数据分析,从而判别工单数据对应的服务类别。但是这种方法在分析大量的工单数据时存在效率偏低的问题,这会影响到电力系统的高效运转和快速发展。因此,找到一种智能,高效和准确的工单分析方法对于电力客服系统十分关键。
近年来,电力客服工单分析任务得到了许多研究人员的关注,并取得了一些成果。汤宁[1]通过提取词频特征并建立了基于K 最近邻(K-Nearest Neighbor,KNN)及支持向量机(Support Vector Machine,SVM)的工单分类模型。林溪桥及其团队[2]提出一种基于主成分分析的工单分类方法。杨柳林及其团队[3]使用TF-IDF(Term Frequency-Inverse Document Frequency)算法得到词频特征,再通过K-means 聚类算法得到工单分类的结果。武光华等[4]提出一种改进 的TF-IDF 算 法SI-TFIDF(Semantic Influence-Term Frequency Inverse Document Frequency),通过构建LDA(Latent Dirichlet Allocation)模型获得词向量的权重。以上基于浅层机器学习的工单分类方法虽然具有易于实现和训练快速的优点,但这些模型的特征学习能力和泛化能力往往欠缺。
为解决浅层机器学习模型存在的问题,研究者采用了基于深度学习的神经网络模型对分类任务进行研究。目前卷积神经网络(Convolutional Neural Networks,CNN)[5]和双向长短时记忆网络(Bilateral Long-Short-Term Memory network,BiLSTM)[6]被广泛应用于文本识别[7]、语音识别[8]和情感识别[9]。CNN 的优势在于强大的局部信息提取与学习能力,但其在全局信息学习上存在缺陷[10]。深层的CNN 能够更好地挖掘样本包含的信息,但深层卷积网络较难获得有效的训练[11]。残差网络(Residual Convolutional Network,ResNet)可以在提升网络模型深度的同时保证训练效率。BiLSTM 的优势在于能够对特征间的上下文关联信息进行学习,能够挖掘文本信息中的深层语义信息,提升识别性能[12]。因此,该文提出了一种基于ResNet-BiLSTM 的电力客服工单分类模型,该模型利用残差网络学习句内的细节特征,再通过BiLSTM 学习句间的上下文关联信息,最终得到工单的类别预测结果。
1 算法概述
1.1 Word2Vec词嵌入算法
文本的稀疏编码可将众多的单词映射到一个共享空间,但是当词库中的单词类别很多时,会导致“维数灾难”。为此,Mikolov 及其团队[13]提出了Word2Vec 框架来对单词进行编码,如图1 所示。假设当前单词的上下文表示为V=[v1,v2,…,vc]∈R^(c×D),其中D表示词向量的稀疏表示的维度,c表示上下文单词的数量。Word2Vec 利用共享的线性映射得到低维的隐含表示Vh∈R^(c×V),其中V表示降维后的词向量维度。最终在Vh的数量维度上进行平均得到Vo∈R^V,即降维后的当前单词的词向量表示。Word2Vec 不仅是一种有效的降维方法,而且考虑了单词间的上下文关联,因此Word2Vec 不仅能够避免“维数灾难”问题而且还可以减轻语义鸿沟带来的问题。
1.2 残差卷积网络(ResNet)
何凯明及其团队在2016 年机器视觉顶会CVPR上提出ResNet[14],用以解决网络层数增加带来的梯度爆炸、梯度消失以及随网络层数增加正确率退化的问题[15]。ResNet 的残差连接形式如图2 所示,输出的期望映射H(x)被表示为残差F(x)与恒等映射x的和。模型学习残差的收敛速率要比传统网络结构更快且训练误差更小。因此,选择ResNet结构能够使模型更高效地学习到鲁棒性强的深层语义特征。ResNet-18 是ResNet 的经典架构之一,其网络结构如图3 所示。ResNet-18 网络中的第一个卷积层采用了64 个7×7 卷积核的结构,阶段1 至阶段4 采用了3×3 卷积核的结构,并且阶段1 至阶段4 的卷积核数量分别为64、128、256 和512,每经历一个阶段后会经过一个2×2 的池化层来缩小特征图的大小。ResNet-18 网络中的激活函数全部采用Relu 函数,并且Batch Normalization 应用于每个卷积层之后。
1.3 双向长短时记忆网络(BiLSTM)
长短时记忆网络(Long-Short-Term Memory network,LSTM)的门控制和记忆细胞有效改善了循环神经网络(Recurrent Neural Network,RNN)的梯度消失和梯度爆炸问题[16]。但是LSTM 只能利用过去和当前的信息来对此时间进行预测,无法利用后续的信息进行预测。对于文本分类任务,文本的上下文关联对于分类结果至关重要。因而,可以学习双向语义相关信息的BiLSTM 被广泛应用于文本语义识别[13]。BiLSTM 的输入门、遗忘门、输出门和记忆细胞的更新公式可表示为:
其中,式(1)、(2)和(3)对应于输入门、遗忘门和输出门的公式,σ(·)表示sigmoid 激活函数,tanh(·)表示tanh激活函数,Wi、Wf、Wo对应于每个门的权重,bi、bf、bo为每个门的偏置项,Yt-1表示(t-1)时间步的输出,Xt表示t时间步的输入,C'表示状态变量,Ct-1表示(t-1)时间步的记忆细胞,Ct表示t时间步的记忆细胞。
其中,Yt表示t时间步的输出。BiLSTM 将双向的最后一个时间步的输出Yleft和Yright进行拼接,并进行最后的输出预测。
其中,Y为对Yleft和Yright拼接后的输出,表示经过激活层后BiLSTM 的最终输出结果。
2 模型框架与算法设计
该文针对电力客服工单分类设计的ResNet-BiLST 模型主要包括三个部分:Word2Vec 词嵌入、ResNet 语义学习网络和BiLSTM 上下文关联学习网络,如图4 所示。每个工单中的N个语句,分别经过Word2Vec 对句内的每个单词进行词嵌入处理,并将句中每个单词的词向量拼接成语义矩阵X=[X1,X2,…,XN]。每个句子对应的语义矩阵分别输入至ResNet来学习深层次的语义特征。然后将每句提取的深层语义特征输入至BiLSTM 的不同时间步,通过BiLSTM 学习句间的上下文关联信息。最后,将BiLSTM 的两个方向特征[Xleft,Xright]进行拼接,得到最终预测结果。
3 模型框架与算法设计
3.1 实验环境
网络的实现是通过pytorch 深度学习框架实现,运行环境为CPU Intel Core i7-9700F、GPU NIVIDA GTX1060 以及Windows10 64 位操作系统。
3.2 数据预处理
实验数据全部来源于电网客服中心记录的数据,该数据记录了客户对电网的需求、建议和意见。并且每条工单以文本的形式记录,共分为咨询(C1)、故障报修(C2)、服务申请(C3)、举报(C4)、表扬(C5)和意见与建议(C6)六类。所有的数据进行了句停顿划分和数据清洗等预处理操作。最终将全部数据按比例9∶1 划分为训练集和测试集,并进行十折交叉验证。
3.3 网络的超参数设置
Word2Vec 词嵌入算法的隐含层神经元个数设置为100,词向量的维度设置为200。ResNet 网络的架构选取为ResNet-18,BiLSTM 隐含层为2,每层的神经元个数分别为64 和32。另外训练参数设置如表1 所示,正确率和宏-F1 分数将用来评价客服工单多分类任务的性能。
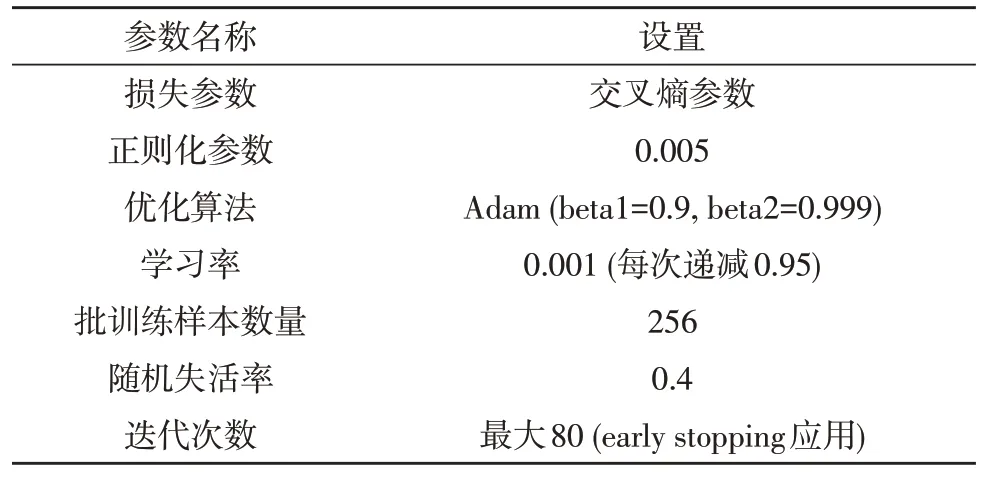
表1 训练超参数设置
3.4 实验结果与分析
所提出的ResNet-BiLSTM 在测试集上六类工单分类的正确率和宏-F1 分数如表2 所示。根据表2的实验结果ResNet-BiLSTM 取得了90.8%的平均正确率和0.889 的宏-F1 分数,证明了所提出的模型能够准确地对工单数据进行分类,并且对于表扬(C5)类别的识别正确率最高,达到96.5%,但是对于举报(C4)识别正确率最低,只有84.0%。这可能是由于举报(C4)容易被误分类至咨询(C1)或故障报修(C2)等反馈中。

表2 ResNet-BiLSTM的工单分类结果
在对比实验中,将所提出的模型与TextCNN,BiLSTM 和ResNet 模型在分类性能上进行对比,其结果如表3 所示。通过表3 的结果可知,所提出的ResNet-BiLSTM 取得最高的分类性能,相较于其他三种模型分别提升了1.6%,6.2%和10.6%。这是由于所提出的模型,不仅使用ResNet 学习句内的语义信息,还使用了BiLSTM 对句间的上下文关联信息进行了有效地学习,进而提升了模型对工单分类性能。
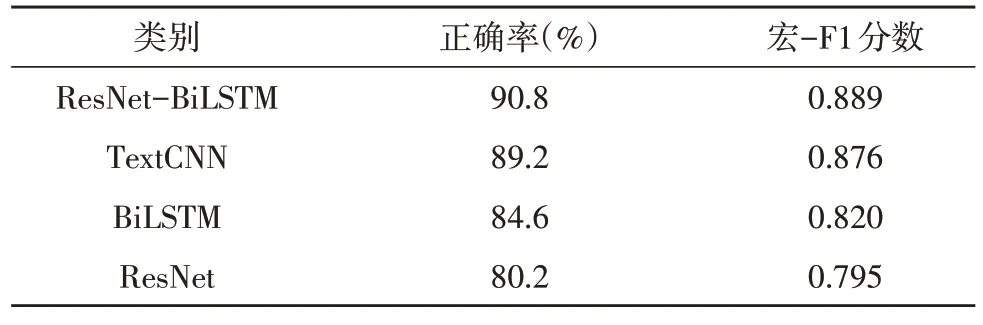
表3 不同网络模型的性能比较
最终,对上述四种模型的训练及测试的时间复杂度进行对比,结果如表4 所示。所提出的模型虽然在训练时间上速度慢,但是其在测试阶段仍要优于主流的文本分类模型TextCNN,说明所提出的模型在实时性能方面存在一定的优势。

表4 所有网络模型的时间复杂度对比
4 结束语
该文对电力客服工单数据的分类进行了研究,所提出的ResNet-BiLSTM 对工单数据的句内语义和句间上下文关联信息进行了有效地建模。通过Word2Vec 得到词向量并将每一句中的词向量拼接成语义矩阵,再通过ResNet 对句内的语义特征进行学习,并将得到的深层次语义特征输入至BiLSTM 来进行句间上下文关联的表征。所提出的模型在真实电力客服工单数据上的分类准确度达到90.8%,高于对比模型。且ResNet-BiLSTM 相较于对比模型在分类性能和时间复杂度方面都具有一定的优势,能够保证其在线性能的稳定。在下一阶段的研究中,将重点关注模型的轻量化,提升工单分类模型的在线性能。
