自适应顺序采样Kriging方法及其在增量动力分析中的应用
2022-11-17焦圣虎侯和涛冉德胜曾晓真高梦起熊方明
焦圣虎,侯和涛,冉德胜,陈 城,曾晓真,高梦起,熊方明
(1.山东大学土建与水利学院,山东济南 250000;2.旧金山州立大学工程学院,美国旧金山94132;3.临沂市建设工程施工图审查有限公司,山东临沂 276000;4.郑州城建集团投资有限公司,河南郑州 450001;5.青岛鑫光正钢结构股份有限公司,山东青岛 266700)
引言
概率地震需求分析对于基于性能地震工程中有着重要的作用。对于一个选定的强度指标(Intensity Measure,IM),通过增量动力分析(Incremental Dynamic Analysis,IDA)对一组具有递增强度的地震动记录进行大量非线性动力时程分析[1],从而对结构在各种极限状态下的抗震性能,包括弹性、动力失稳和最终倒塌进行详细评估[2-3],继而获得结构的工程需求参数(Engineering Demand Parameter,EDP)。近年来,随着计算机性能的提高,即使对于复杂的多自由度结构,包含大量参数的IDA分析也变得可行[4-5]。结构的最大层间位移角与结构损伤密切相关,通常作为研究建筑物地震易损性的较为普遍的EDP[6],而以5%阻尼的一阶振型谱加速度Sa(T1,5%)作为地震动强度指标在IDA中被广泛接受。但是IDA通常需要进行大量的非线性动力时程分析,因此具有计算量大的缺点。VAMVATSIKOS等[7]发展了一种基于静力推覆分析与统计分析的简化近似方法,但这种简化方法只适用于基本振型起主导作用的结构。在此基础上,VAMVATSIKOS等提出了hunt&fill方法[8],汪梦甫等[9]提出了快速增量动力弹塑性分析方法(FIDA方法),为进一步提高IDA的计算效率开展了开拓性的研究。
代理模型主要应用于结构的可靠性分析以代替那些耗时的结构计算模型[10]。通过结构计算模型对少量样本的数值模拟,对代理模型进行训练从而较为准确地模拟结构可靠性分析中的极限状态函数。常用的代理模型包括Kriging模型、径向基函数模型和神经网络模型[11-14]。代理模型近年来逐渐应用于抗震分析,GIOVANIS等[15]将基于蒙特卡洛(Monte Carlo,MC)的神经网络模型运用于IDA,从而计算出有效的响应统计数据和易损性曲线。因为同时提供了预测值和预测方差,Kriging代理模型是近年来得到较为广泛的关注[16]。顺序采样(Sequential Sampling,SS)方法被广泛应用于基于Kriging的可靠性分析中。通过有限初始点及其响应评估构建一个初始Kriging模型,根据选定的采样准则确定新的样本点并进行相关的响应评估,通过对元模型进行不断的更新以期增加其准确性。研究表明:基于顺序采样的方法比通过一次性采样建立Kriging模型的静态方法更为有效[17]。本文根据选用IM和EDP,将基于主动顺序采样的Kriging代理模型运用于IDA分析,在保证计算准确性的基础上,提高IDA的计算效率,并进一步考虑结构的不确定性。
1 Kriging代理法
Kriging模型是一种基于由回归模型和随机过程假设的插值方法,根据所研究问题定义的随机场及其参数,通过最佳线性无偏估计预测在样本点上的响应。Kriging模型将确定性输出y(x)视为随机过程的实现Y(x):式中:x为待预测的样本点;µ是响应均值;Z(x)表示空间内x和w的两点之间具有零均值和协方差的平稳高斯过程,w是用于建立Kriging模型的初始点,其公式为:


式中:σ2是过程方差;Rθ是由一组参数θ定义的相关函数;θ的维度与x相同。本文中相关模型采用简化的Matern-5/2函数,可由式(3)表示:

式中:θi(i=1,2,…,k)可以看作是变量在i方向的重要性:θi越大,x在i方向对w的影响越大。给定一组包含n个观测点xD1,xD2,...,xDn的样本XD及其所对应的响应yD=[yD1,yD2,...,yDn]T,其最佳线性无偏估计定义为:

式中:Jn是n维单位向量;RD为一个n×n矩阵,其元素表示两个样本点之间的相关性:RDij=Rθ(xDi,xDj),1≤i,j≤n;n维 向 量rD(x)表示一个候选点与初始样本点的相关性:rDi(x)=Rθ(x,xDi),1≤i≤n;是µ的广义最小二乘估计。
2 顺序采样Kriging模型
2.1 基于熵(Entropy)的顺序采样
SHANNON[18]和CURRIN等[19-20]提出了贝叶斯框架下计算机实验设计的熵准则用于量化信息量。给定一组样本XD(包含所有l个初始样本点xD1,xD2,...,xDl)以及初始Kriging模型(基于初始样本XD建立),熵采样方法就是从一组新的样本XC(包含m个样本点xC1,xC2,...,xCm)中选择一个使信息量最大化的样本点。这个标准等价于:

式中:RA是样本集XA=XD∪XC内l+m个点的相关矩阵,其计算方式与Kriging模型中相关矩阵RD相同;Jl+m是l+m维单位向量;相关矩阵RA内的相关性参数θi与初始Kriging模型中的相同,这使得新采样点适用于现有的Kriging模型。
2.2 顺序采样Kriging模型的流程图
图1给出了顺序采样Kriging方法进行IDA的的流程图。其由6个步骤组成:

图1 顺序采样Kriging模型方法的流程图Fig.1 Flow chart for sequential Kriging surrogate approach
(1)首先在取值范围内选择初始样本点并计算其真实响应,同时采用蒙特卡洛(Monte Carlo,MC)方法获得候选样本集S;
(2)利用初始样本点及其真实响应建立Kriging模型;
(3)依据Kriging模型,用熵采样方法确定最优的候选点,计算其真实响应并对Kriging模型进行更新;
(4)判断是否满足样本点的数量要求;
(5)如果没有满足,确定新的最优候选点及结构的真实响应,并对Kriging模型进行更新;
(6)如果满足样本点的数量要求,则输出最优代理模型并计算均方根误差(Root Mean Squared Error,RMSE)。RMSE用来评估元模型的准确性,其定义为:
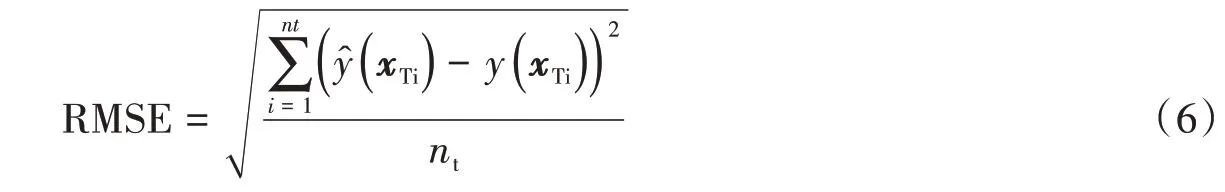
式中:xTi(i=1,2,…nt)是用于评估元模型精度的一组随机样本点分别是xTi处基于最优Kriging模型的预测响应和真实响应;nt是验证点的数量,即真实IDA分析所用的Sa(T1,5%)数量。
3 算例分析
本文通过计算分析某二层单开间和某九层多跨的钢框架(Steel Moment Resisting Frame,SMRF)来评估顺序采样Kriging模型方法的有效性。当最大层间位移角达到10%时,结构被视为倒塌[21],从而停止分析。本文用以往记录的两组地震动作为地震激励。表1给出了这些地震动记录的详细信息。

表1 选作计算研究的地震动记录信息Table 1 Selected ground motions
3.1 二层钢框架结构
本文用OpenSees软件平台对二层单开间钢框架结构模型[22-23],以下简称“结构A”,进行建模,第一周期为0.84 s,示意图和梁柱截面尺寸如图2(a)所示。通过采用非线性IMK滞回模型建立框架结构有限元模型来模拟因强度和刚度退化而导致的框架侧移[24],如图2(b)所示,其中:My为屈服弯矩值,对应梁和柱的值分别为1 235.83 kN·m和2 299.24 kN·m;Mc/My为屈服后硬化刚度,对应梁和柱的值均为1.05;θcap,pl为塑性转角,对应梁和柱的值分别为0.014和0.275;θpc为峰值后转角,对应梁和柱的值分别为0.24和0.1。通过受重力荷载的P-Δ柱考虑地震中的P-Delta效应。

图2 结构A示意图Fig.2 Schematic of structure A
首先对结构A进行传统的直接IDA分析,以0.005 g为间隔取Sa(T1,5%)值,并计算对应的最大层间位移角,从而绘制IDA曲线并以此为真实解。同时采用VAMVATSIKOS等出的hunt&fill方法对结构A进行分析并绘制相应IDA曲线。本文提出的熵顺序采样Kriging模型方法分别以GM1-0.5 g、GM3-0.5 g和GM4-0.5 g,GM2-0.3 g的Sa(T1,5%)增量,从0.1 g开始取4个点作为初始实验设计,在此基础上补充5个候选点以完善Kriging模型。图3显示了将所选地震动作用于结构时,传统方法、hunt&fill方法与使用熵顺序采样Kriging模型方法的IDA曲线比较。
从图3(a)中可以发现:使用hunt&fill方法和熵顺序采样Kriging模型方法的曲线与传统计算分析得到的真实IDA曲线十分接近;图3(b)-图3(d)表明:本文提出的方法所得到的IDA曲线比hunt&fill方法更贴近于真实的IDA曲线。从图3(b)和图3(d)中可知:θmax对应的Sa值不唯一,即同一EDP值可能有多个IM值与其相对应,这属于结构“硬化”现象[1,25]。这些拐点的出现使IDA曲线变得曲折,增加分析难度。而通过熵顺序采样方法选出的点更集中在这些重要的拐点处,从而使预测结果更贴近于真实的IDA曲线。可见:文中提出的方法与传统的IDA方法具有很好的一致性。此外,图3中的补充点存在分布位于初始点的范围外的情况,这表明:即使在初始点具有局限性的情况下,熵采样仍然能够选取适当的样本点从而使Kriging模型模拟出真实的IDA曲线。在使用相同配置电脑(CPU:Intel(R)Xeon(R)E5-2620 v4,内存:16G)的情况下,一次地震波非线性时程分析需要70 s,传统IDA方法获得一条IDA曲线,需要至少200个Sa(T1,5%)点,即需要进行200次非线性时程分析。在相同精度下,本文提出的熵顺序采样Kriging模型方法仅需要9次。相比之下,熵顺序采样Kriging模型方法可以有效地提高IDA计算效率。

图3 结构A三种方法的IDA曲线比较Fig.3 Comparison of IDA curves of three methods for structure A
图4显示了熵值的最大值和RMSE值随样本点变化的过程,图4(b)中虚线为hunt&fill方法使用9个点得到的RMSE值。从图4(a)可以看出:熵最大值总体处于下降趋势,这说明利用熵顺序采样得到的点所建立的Kriging模型精度随着样本点的增加得到提高。其中:对应GM1和GM4的熵值下降趋势比GM2更为明显,表明增加相同数量的样本点更能有效提高GM1的IDA曲线的精度,这主要是由于GM2作用下的结构IDA曲线有显著的突变或弯折,相对难以预测。在补充4个点之后,熵值的最大值逐渐趋于稳定,甚至出现过拟合,这表明继续增加样本点无法有效提高模拟结果的准确性。类似的结果也表现在图4(b)中:随着点数的增加,Kriging模型的RMSE值不断降低,这意味Kriging模型精确度在不断提高。值得一提的是:GM1作用下使用hunt&fill方法得到的RMSE值始终大于Kriging模型;GM2、GM3和GM4作用下,在补充4个点之后,Kriging模型的RMSE值小于hunt&fill方法,这表明在总样本点相同的情况下,文中提出的熵顺序采样Kriging方法比hunt&fill方法的精度更高。

图4 熵值和RMSE值的变化Fig.4 Variation of entropy and RMSE values
3.2 九层钢框架结构
九层钢框架结构[26],下述简称“结构B”,用于进一步评估IDA的拟定方法。结构B梁柱的示意图和型号如图5所示。结构B的场地类别为D,第一周期为1.45 s。其楼层和屋顶的永久荷载分别为5.08 kN/m2和3.97 kN/m2。构建OpenSees模型的策略与结构A的相同。
图5 结构B示意图Fig.5 Schematic of structure B
与结构A相同,以0.005 g为间隔取Sa(T1,5%)值,并计算对应的最大层间位移角,从而绘制IDA曲线并以此为真实解。同时采用hunt&fill方法对结构B进行分析并绘制相应IDA曲线。熵顺序采样Kriging模型方法分别以GM1-1 g、GM2-1 g和GM4-1 g,GM3-0.5 g的Sa(T1,5%)增量,从0.1 g开始取4个点作为初始实验设计,在此基础上补充5个候选点以完善Kriging模型。将所选地震动作用于结构时,传统方法、hunt&fill方法与本文方法的IDA曲线比较如图6所示。
图6中再次表明:使用本方法计算分析得到的IDA曲线非常接近真实IDA曲线,而且比hunt&fill方法吻合程度更高,特别是在曲线重要的拐点处。可见:文中提出的方法与传统的IDA方法对于复杂结构仍具有很好的一致性。此外,图6(a)-图6(c)中的补充点超过初始点的范围,这证明即使复杂结构在初始点范围有限的情况下,熵采样仍然能够选取合适的补充点从而使Kriging模型更准确。从图6(a)-图6(c)中可以看出:Entropy采样更聚焦于IDA曲线存在巨大突变的位置,这表明本文提出的方法对复杂IDA曲线具有更好的预测分析能力。计算耗时的结果与结构A相同,由于结构B为高层结构,需要69 s进行一次非线性分析。传统的IDA方法比提出的方法花费更多的时间来获得IDA曲线。相比之下,建立Kriging模型的时间可以忽略不计。

图6 结构B三种方法的IDA曲线比较Fig.6 Comparison of IDA curves of three methods for structure B
熵值的最大值和RMSE值随样本点变化的过程如图7所示,图7(b)中虚线为hunt&fill方法使用9个点所得到的RMSE值。图7(a)表明:总体上熵的最大值具有下降趋势,这证明Kriging模型的精度不断提高。同样在图7(b)中,Kriging模型的RMSE值随着样本点数的增加而降低,这说明Kriging模型精度在不断提升。GM1、GM2、GM3和GM4作用下,在补充4个点之后,Kriging模型的RMSE值小于hunt&fill方法,这与图4结果相同,证明在总样本点相同的情况下,本文提出的方法比hunt&fill方法的精度更高。

图7 熵值和RMSE值的变化Fig.7 Variation of entropy and RMSE values
3.3 考虑结构不确定性的IDA曲线模拟
本文提出的熵顺序采样Kriging方法可以应用于考虑结构不确定性的IDA分析。以GM1为例,选取结构A和结构B中用于模拟构件滞回特征的IMK模型为研究对象[23],选用2个参数I和My分别代表转动惯量和塑性铰的屈服力矩的不确定性参数,其均服从均值为1,方差为0.01,上下边界分别为0.70和1.30的正态分布,如表2所示。与前文相同,选取结构的最大层间位移角作为输出的EDP。

表2 随机变量及其概率描述Table 2 Random variables andtheir probabilistic description
考虑此时不确定性参数数量为I、My和Sa,将初始点的数量设置为12,通过拉丁超立方采样(Latin Hypercube Sampling,LHS)产生,考虑到所选用模型的非线性和不确定性较强,因此将补充样本点的数量分别设置为100、200和300。运用本文提出的熵顺序采样Kriging模型方法,使用最终的Kriging模型得到考虑结构不确定性的IDA曲线。在最终的Kriging模型中代入转动惯量I和塑性铰的屈服力矩My的均值,即可得到只考虑地震动强度的IDA曲线,如图8所示。由图可知:样本点的数量越多,熵顺序采样Kriging模型方法得到的IDA曲线越准确,其中:300个点的预测结果在曲线重要的拐点处非常接近真实的IDA曲线。这表明补充点的数量对预测结果的准确性影响较大。

图8 考虑结构不确定性的Kriging模型方法的IDA曲线比较Fig.8 Comparison of IDA curves of Kriging surrogate model method considering structural uncertainty
为进一步校验熵顺序采样Kriging模型方法的有效性,选取预测曲线变化率较大处对应的Sa(1.4 g)作为结构A的特征点,Sa(2.5 g)作为结构B的特征点。通过对结构不确定性参数进行10 000次蒙特卡洛模拟,对结构非线性时程分析得到的EDP和Kriging模型预测值进行比较,并用拟合优度R2来描述预测结果的拟合程度。对比结果如图9-10所示,不同样本点数量的熵顺序采样Kriging模型均能较为准确地预测出结构的EDP,且随着样本点数量的增加,预测结果更精确。结构A中:200个样本点的Kriging模型预测R2超过90%。当样本点增加到300时,Kriging模型预测R2为91.972 6%,增长幅度较小。相同的现象也出现在结构B中。总体而言,本文中提出的熵顺序采样Kriging模型方法对考虑结构不确定下的IDA分析具有较高的计算效率。

图9 结构A的蒙特卡罗方法与所提出方法的比较:Fig.9 Comparison of Monte Carlo and proposed method of structure A

图10 结构B的蒙特卡罗方法与所提出方法的比较:Fig.10 Comparison of Monte Carlo and proposed method of structure B
3.4 关于Kriging代理模型的讨论
为进一步评估熵顺序采样Kriging模型方法的准确性和高效性,本文从样本点和终止条件两个方面进行讨论分析。
3.4.1 样本点的影响
样本点包括初始样本点和候选样本点。初始样本点主要从两个方面影响模拟的结果:
(1)初始点的数量,初始点数量越多,建立的初始Kriging模型越精确,同时需要补充的候选点的也会相应的减少;但是因为文中方法的效率体现在用对非线性时程分析的调用次数上,所以初始点数量越多会导致计算效率降低。
(2)初始点的选取方法,在不清楚结构倒塌所对应的Sa(T1,5%)值的情况下,初始点的范围应该尽可能地大,但由于某些Sa(T1,5%)值会导致大于10%的层间位移角,从而无法用于建立模型。因此,按照一定的增量确定初始点是一种比较合理的方法。
与初始样本点相同是:需要补充的候选样本点应该在数量和计算效率之间保持平衡。与初始样本点不同的是:候选样本点的个数可以尽可能的多,这样可以有充足的选择空间,同时模拟的结果包含更多的信息,可以提高准确性。
3.4.2 自适应顺序采样Kriging方法的改进
本文提出的方法在达到预定样本点数量之后终止,可能会造成样本点的浪费。考虑将广泛应用于自适应Kriging分析的min(U()
xC)≥2作为终止条件[27],U的定义为:

图11表明:GM1作用下,Kriging模型初始便满足终止条件;GM2作用下,在加入第2个补充点之后满足终止条件,精度达到要求。考虑GM2的IDA曲线非线性较强,因此将终止条件U与RMSE值结合,进行讨论。在Kriging模拟中:不同结构的输出结果的单位影响RMSE值。但是,IDA一般选择最大层间位移角为作为输出,这意味着任意结构的IDA中输出结果的单位和限值均是一致的。min(U()xC)≥2对应的误差为2.3%,而本文中最大层间位移角的限值为0.1,因此,本文中误差限值即RMSE的限值为0.1×2.3%=0.002 3。图4(b)表明:在加入第4个补充点之后,GM2作用下Kriging模型的RMSE值已小于0.002 3,说明已满足终止条件,精度达到要求,这个结果与图4(a)中按照Entropy的最大值趋于稳定作为终止条件的结论一致。因此,综合考虑终止条件U和RMSE的影响,对本文中的二层钢框架在GM1和GM2作用下,本文方法只需4个初始点和4个补充点即可满足IDA精度要求。

图11 U最小值的变化Fig.11 Variation of min(U)values
4 结论
增量动力分析法在研究确定结构处于不同强度地震动作用下的反应具有重要意义。本文将增量动力分析法结合自适应顺序采样和Kriging代理模型,构造了一种基于自适应顺序采样Kriging的IDA方法,即顺序采样Kriging模型方法。通过结构模型分析,证明所提出的方法在耗时久的非线性时程分析中是高效的,并且其结果对于IDA曲线模拟是非常准确的。
(1)该方法综合了Kriging模型和顺序采样两种方法的优点。将Kriging模型的预测误差用于实现顺序采样的自适应学习,与一次性采样生成Kriging模型相比,准确性更高且更稳定。同时充分利用候选点,使模型更合理。
(2)算例分析表明:本文提出的方法不仅计算精度满足设计要求,计算过程所需要的时间与传统IDA方法相比有显著降低,计算效率得到较大提升。与hunt&fill方法相比,在运算次数相同的情况下,本文方法得到的结果精度更高。
(3)在考虑结构不确定性的IDA分析中,本文方法得到的IDA曲线与蒙特卡洛模拟的结果非常接近,但计算成本远低于后者,验证了本文方法的高效性和准确性。
(4)算例表明本方法对低层和中高层钢框架结构的IDA适用性较好,但适用范围有限,对于高层和其他结构形式需要进一步分析研究。
