随机森林在农业方面的应用*
2022-11-17李衍瑞
李衍瑞
(塔里木大学信息工程学院,新疆 阿拉尔 843300)
我国是农业大国,农业经济在国民经济中占据着非常重要的地位,2020年全国农业及相关产业增加值为166 900亿元,占国内生产总值(GDP)的比重为16.47%[1]。随着经济的飞速发展,人们的生活质量大幅度提升,人们对于食品方面的要求越来越高,这就要求农业生产质量也要不断提高。机器学习成为农业信息化中的重要一环,为农业提质增效作出了巨大贡献,随机森林算法作为机器学习的一种,在农业中有着广泛的应用[2-4]。
1 随机森林算法
1.1 决策树
决策树是有监督的机器学习算法,是一种树状结构的流程图,主要解决分类问题。这种方法根据数据及参数的属性特征对其进行分类,对每一次分类过程进行记录并汇总。决策树本身由根节点、非叶子节点(决策点)、叶子节点和分支组成。在决策树中,每个决策点实现一个具有离散输出的测试函数记为分支[5]。根节点是决策树中最上面一层的节点,该节点往往具有信息增益大的特点,在根节点处,信息熵值下降最快,可以有效地对数据进行第一次分类。非叶子节点代表问题的决策,通常对应决策所依据的属性。叶子节点代表分类的标签值,决策树是一个由上到下的遍历过程,每一次分类会有不同的判断结果,将不同的判断结果引入不同的分支,从而赋予不同的标签值[6]。
1.2 决策树的剪枝
如果决策树在构建中考虑了所有的训练数据集,得到的决策树就会很庞大[7]。虽然这样可以保证训练数据集的决策正确率达到100%,但是由于需要考虑所有数据,将数据分割得过于零散,致使决策树学习到一些噪声点和错误点,出现过拟合现象[8]。对于上述问题可以通过决策树的剪枝有效解决。决策树常用的剪枝方法有两种。
1)预剪枝:在构建决策树时提前停止。如果该节点的信息增益过低,则说明该节点的分类效果不好,并将该节点设为叶子节点。
2)后剪枝:在决策树构造完成后,进行剪枝。自下而上地对每个非叶子节点进行考察,选择该节点中个数最多的类别作为标签,试将节点的子树替换为叶子节点;若能够使得决策树在验证集上的准确率升高,则将该子树替换成叶子节点。
1.3 随机森林算法
随机森林由Leo Breiman提出,它通过自助法(Bootstrap)重采样技术,从原始训练样本集N中有放回地重复随机抽取m个样本生成新的训练样本集合,然后根据自助样本集生成m个分类树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。通俗来讲,随机森林就是将若干个弱分类器组成一个强分类器。其本质是将决策树算法进行了集合,将若干个决策树组起来,每一个独立抽取样本建立一棵相关的决策树,森林中的每棵树具有相同的分布,每棵树的误差取决于每棵树的相关性。参数特征采用随机方式对每一个节点进行分类,然后比较不同情况下产生的误差,能够检测到内在估计误差、分类能力和相关性决定选择特征的数目[9]。每一棵树的分类能力较小,随着大量的树的建立,其分类能力逐步提高,一个测试样品可以通过每一棵树的分类结果统计后选择最可能的分类。随机森林的基本原理和技术路线如图1、图2所示。
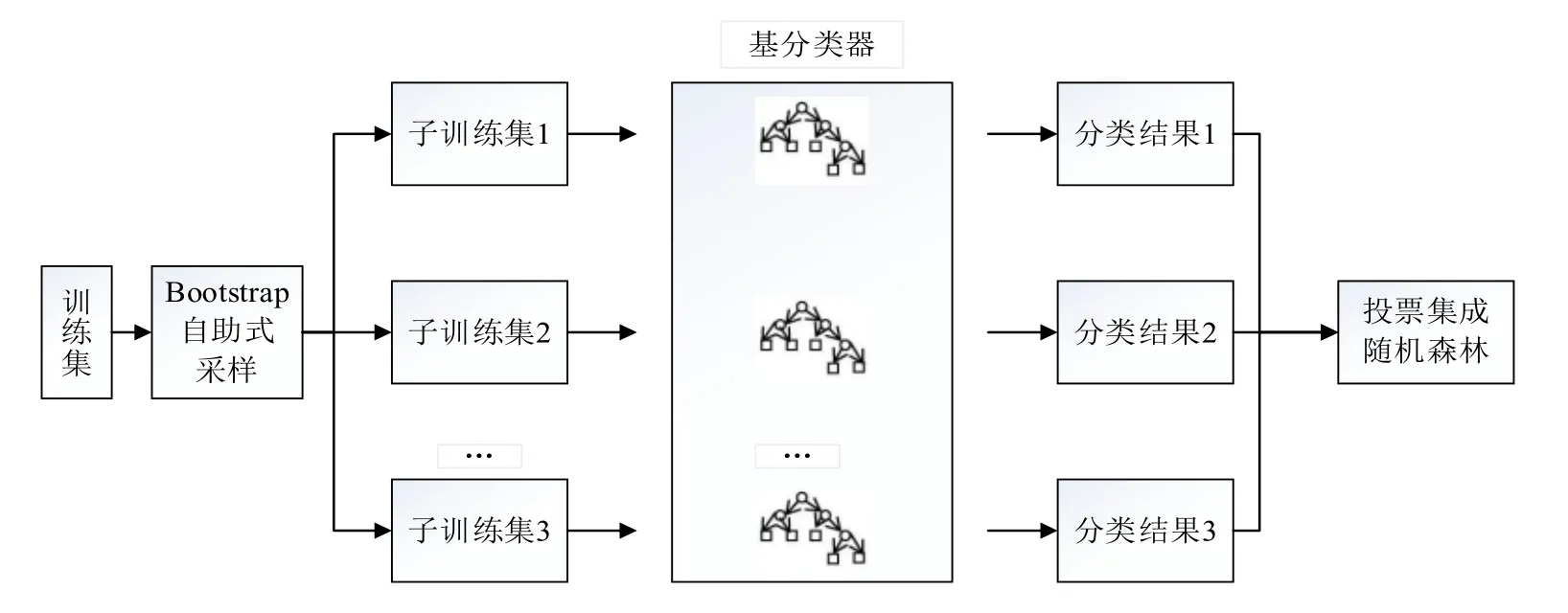
图1 随机森林基本原理

图2 随机森林技术路线
2 现代农业存在的问题
2.1 农业干旱监测误差较大
农业干旱监测一直是农业方面的一项重大工作,干旱意味着农作物从种植、生长到收获都会受到巨大影响,而农业干旱监测如果出现误差过大的情况,会导致灌溉量不符合要求,作物生长得不到有效保障,使得农民种植成本大大提高,甚至出现经济损失等问题。对于大部分农民来说,对土壤干旱检测的方法还停留在经验层面,通过种植经验对土壤干旱程度进行估算,从而确定灌溉量等信息。这样以经验来判断土壤干旱程度的方法,对农民种植经验有着较高要求。另外,不同作物的需水量不同,对土壤的含水量需求也不相同,一定程度上加大了土壤干旱检测的误差,使得农民资金受损的风险大大提高。少部分人使用手持土壤检测设备,对农田进行随机采样,通过随机采样点的数据对整体农田的土壤干旱度进行估算。这种方法不仅对人力有着巨大要求,而且只对农田的个别区域有着较高的精度,农田整体的土壤干旱数据可能存在较大误差。上述两种常用的方法都有着高误差风险,一旦出现估算错误,对整体的种植进程有着巨大影响。
2.2 农作物产量预测不准确
农作物与人们生活息息相关,农作物产量对人们的生活有着巨大的影响,随着我国人口的增长,农业系统的压力逐步增大,另外,农作物产量对国家农业系统的政策制定等也有着重要的影响,因此农作物产量预测非常重要。传统的农作物产量预测通常以近几年的农作物产量数据为基础,应用统计类模型进行相关预测,常用的分析方法有灰色关联度分析、逐步回归模型等。其中,灰色关联度分析需要对各项指标的最优值进行现行确定,相当一部分的指标无法现行确定,这就导致该方法主观性过强,容易产生误差,另外灰色关联度分析的一系列模型已不能满足当前对于模型的需求,导致结果具有偏差。在逐步回归模型中,采用哪一种因子和该因子采用哪一种具体的表达式并不能完全确定,这就影响了因子的多样性和不确定性,使得回归分析的精度受到影响,导致作物产量预测有较大误差。
2.3 农作物品质检测烦琐
随着经济社会发展,人们对生活质量的要求越发提高,并且随着食品安全意识的普及,老百姓对食品品质也越来越重视,农产品在日常饮食中占据极大的比例,所以如今对农作物品质的检测要求也越来越高。现如今对农作物的品质检测分为有损检测和无损检测,有损检测虽然更为精确,但是成本过高,而且农作物的有损检测步骤烦琐,需要消耗大量的人力、物力。对于无损检测来说,传统的检测方法有近红外光谱检测和高光谱检测,通过高光谱成像对作物进行检测。近红外光谱检测和高光谱成像技术虽然极具优势,但是有一定的局限性。近红外光谱设备造价高,且接收光谱时容易受到外界因素的干扰,高光谱成像技术数据采集时间长,获取的数据复杂、冗余高。
3 随机森林在农业中的应用
3.1 随机森林应用于农业干旱监测
作为机器学习的一种,随机森林算法有着分类回归的作用。2022年,王晓燕等[10]通过随机森林、BP神经网络、支持向量机等对农业干旱监测建立了模型。通过确定不同的参数因子,提取2002—2019年甘肃4—10月所有气象站点的VCI、TCI、PCI和VSWI指数,按月依次对4种遥感指数和1个月、3个月、6个月时间尺度的SPEI进行Pearson相关性分析,分析单个遥感干旱指数监测农业干旱的能力以及融合多源数据的必要性。结果表示,各项因子都高于0.01,表示其对于干旱指数显著相关,选取站点数据构建随机模型,对于随机森林、BP神经网络、支持向量机的结果进行R2、RMSE、MAE的测算,结果如下:R2=0.86、0.81、0.82,RMSE=0.53、0.59、0.53,MAE=0.41、0.45、0.42。随机森林算法在对数据进行拟合后,其精度高于BP神经网络和支持向量机。从而得出结论:随机森林可以更全面、可靠地进行农业干旱监测。
3.2 随机森林应用于农作物产量预测
2019年,王鹏新等[11]基于随机森林回归的算法,对玉米进行了单产估测。该文的研究区域为河北省的中原区域,特征变量选取了上包络线S-G滤波的叶面积指数和条件植被温度指数。该文首先确定了玉米对于水分的胁迫程度,进行了VTCI的计算,VTCI的计算公式如下:

通过上包络线S-G滤波对选取的叶面积指数进行平滑处理,使得该叶面指数更加符合该地区玉米生长的实际情况,之后建立回归决策树,通过建立随机子空间法确立决策树的相关节点及其分裂特征。通过有放回地随机参数抽样,从最初的原始样本抽取训练样本,通过该方法确立m个训练样本,在决策树建立过程中,利用CART方法随机选取树的数量,且不对决策树进行剪枝,将所有决策树构建成随机森林后,对所有回归后得到的玉米单产值进行平均计算,所得到的最终值即为该地区玉米单产的估算值。结果表明,通过随机森林回归模型构建变量估产模型时,其精度较高,具有实际意义,可以对该地区的相关作物产量进行相对精确的预测。
3.3 随机森林应用于农作物品质检测
2019年,刘倩[12]以哈密瓜为试验材料,通过随机森林算法对其进行了模型构建,对哈密瓜的无损检测进行研究。该文首先通过哈密瓜对不同基质的含水量进行统计和处理,包括糖分、可溶性固体物、维生素C等不同品质指标。并且提取了哈密瓜相关的外部表型特征,例如纹理特征、颜色特征等。之后对哈密瓜进行了外部因子的相关性分析,综合多个环境因子,使用随机森林的回归算法,对哈 密瓜的纹理特征和颜色特征进行模型建立,结合哈密瓜对外部环境因子的敏感程度,对不同的环境因子进行了R2的测算。最后通过试验证明哈密瓜内部品质与外部特征有着显著的相关性,通过随机森林进行预测模型的建立,结合外部表型特征,建立果实预测模型。通过对比哈密瓜含水量与内部品质,确定其规律,并将特征分析的结果与外部表型对比。试验结果表明,哈密瓜对不同的内外部因素测算得到相应的R2,其R2均高于0.75。该试验表明随机森林算法在农作物的品质检测方面,构建的品质预测模型有着较高的精度及实用性。
4 结论
综上所述,随机森林作为机器学习的一类算法,可以应用到很多方面,在农业上的应用也很广泛,无论是在农业环境中的应用还是在农产品中的应用,都有着较高的应用价值。随机森林算法具有高精度以及对数据的强大处理能力,并且可以有效地避免数据过多时出现数据冗余的情况。
