基于目标检测和模板匹配的交警手势识别研究
2022-11-17马天祥
马天祥
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
0 引 言
计算机软硬件的更新迭代,推动了无人驾驶技术的蓬勃发展。但随着无人驾驶车辆的不断增加以及现实道路复杂化的加深,仅仅依靠红绿灯来指挥川流不息的车辆,在一些特殊时刻可能会导致交通事故的发生,因此交警的现场指挥不可或缺。若无人驾驶车辆在路口处仅遵循交通信号灯的指导,而不能对交警的手势进行捕获和解析,那么可能会带来不必要的损失。在驾驶辅助领域,驾驶人员也可能会因一些突发事件而无法及时观察到交警的指挥手势,或者无法有效判断出交警手势的含义,同样会导致交通事故的发生。
现行的交警指挥手势包括:直行、左转弯、变道、减速慢行、右转弯、左转弯等待、停止、示意靠边停车等八种手势[1]。在交警手势识别方面国内外已有相关研究,如Yuan等[2]通过让交警使用可穿戴设备,便于驾驶员捕获并分析交警手势,该方法虽然准确率很高,但无法将识别到的数据分享到车辆上用以辅助驾驶。张备伟[3]等使用Kinect 捕获人体关键点,经处理后将其交给DTW 算法进行手势识别,该方法虽然有着不错的效果,但Kinect 设备成本较高且设备体积较大,不便于部署。常津津等[4]提出的将c3d 和convLSTM集合的交警手势识别方法,同样具有可观的识别效果,但由于c3d 的参数量巨大,难以保证识别的实时性。
鉴于上述所提方法的不足之处,本人提出一种基于YOLOv5s 和FastDTW 的交警手势识别方法。通过该方法,可实现在众多人物中定位到交警,并可实时地对其动作进行分析,避免了目标人物识别错误,而导致手势识别不准确情况的发生。
1 技术简介
1.1 YOLOv5 模型
目标检测算法大致可分为两个类别:一种是两阶段目标检测,代表算法有R-CNN、Faster R-CNN 等;另一种是单阶段目标检测,代表算法有SSD 和YOLO 系列等[5]。相较于前者,后者的检测精度略有下降,但它的速度更快、实时性更好。因此本文为保障检测的实时性,选择YOLOv5 系列作为目标提取网络。
YOLOv5 是一种单阶段目标检测算法。通过该算法可以从输入的图片或视频中框选出感兴趣的目标并推理出其分类的准确度,同时该算法有着较高的检测速率,是实现交警和行人目标分离任务的首选。
YOLOv5 结构如图1所示,主要由四部分构成:输入端、Backbone、Neck、和Prediction。
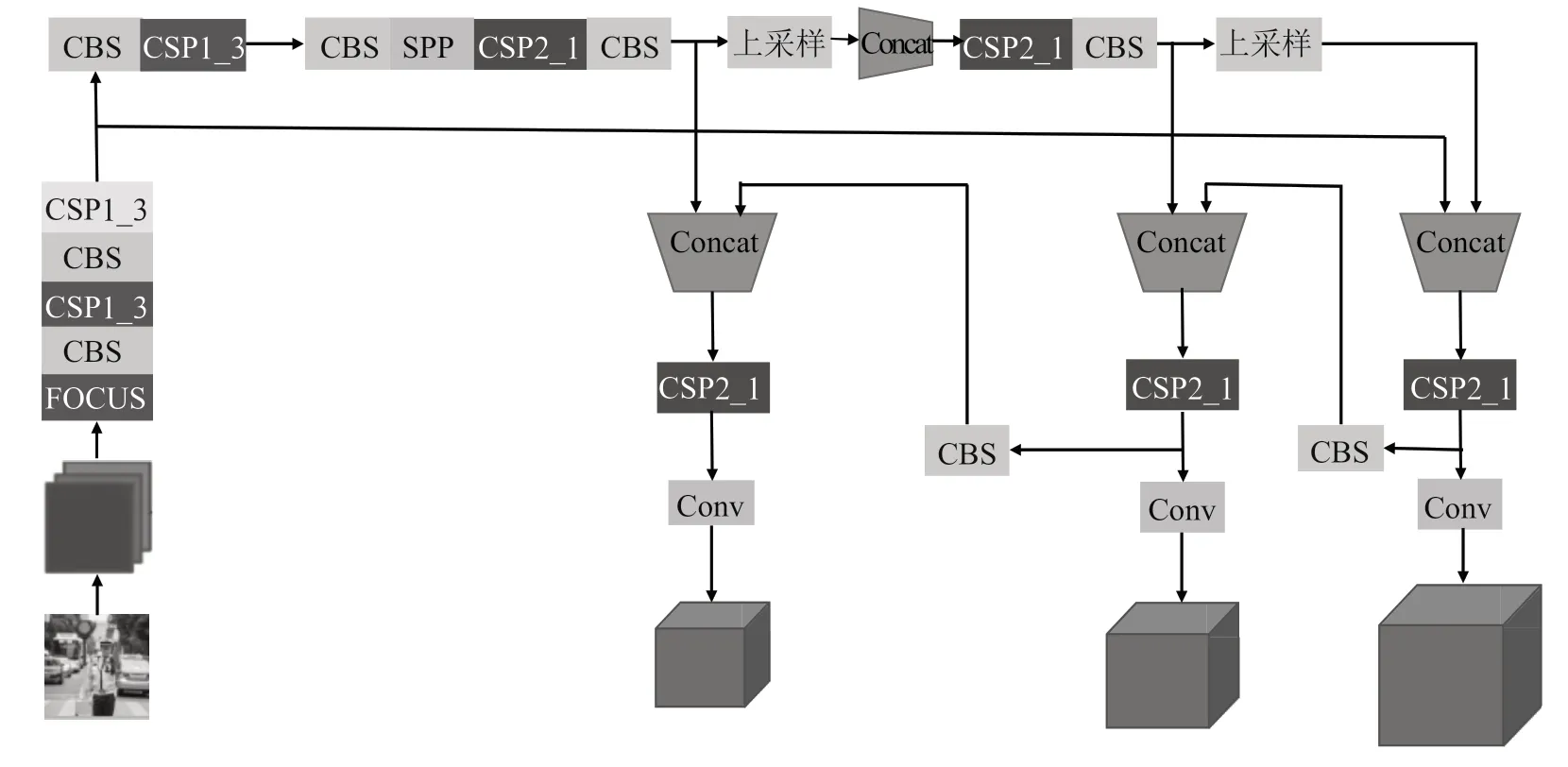
图1 YOLOv5 系列结构图
在输入端,该算法使用Mosaic 进行数据增强,对输入的四张图片进行裁剪、拼接、填充等操作,加强输入图片的多样性。
Backbone 层包含以下结构:Focus、CSP 和SPP。Focus结构是YOLOv5 新增的,该结构会对输入的图片进行切片操作,将所输入原始图片的分辨率降至原来的四分之一,将通道数增加到原来的四倍,如原始图片的输入参数是640×640×3,经过Focus 结构处理后会变成320×320×12的特征图。CSP 结构是一系列残差块的堆叠,同时存在一个大的残差边,经些许处理后直接连在网络末端。SPP 全称为空间金字塔池化,该模块对网络最后输出的特征层进行最大池化处理(池化核的大小分别为5×5、9×9 和13×13),然后再对池化后的特征图进行融合以增大感受野。
Neck 结构由FPN 和PAN 两部分组成,该结构会对特征层进行上采样,并结合上一级输出到Neck 结构的特征图进行特征融合,使得最后生成的特征图能够保存更多的细节。
在输出端即Prediction 层,使用CIoU_Loss 作为损失函数帮助回归BoundingBox,使用NMS 非极大值抑制,使得每种物体最后只由一个检测框框定。
YOLOv5 所包含的四种模型分别是YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x。这四种模型在网络的配置文件上几乎完全相同,最大的区别就是depth_multiple和width_multiple 两个参数。改变这两个值的大小会影响到主干网络的复杂程度,进而影响最终训练模型的准确度和识别速率。由于本文的分类数目较少,对于网络的复杂程度要求较低,故使用YOLOv5s 对交警和行人进行分类和定位[6]。
1.2 人体关键点提取
Mediapipe 是由谷歌提出的集姿态估计、目标检测等为一体的多媒体框架,该框架底层由c++编写,最突出的优势是在CPU 上运行时依然有着不错的检测速度,同时其检测的精确度也十分可观[7]。该框架可生成身体33 个关键点、手部21 个关键点以及面部的468 个关键点组成的面网。由于对交警手势动作的评估更加看重人体的姿态,因此本文选取该框架产生的躯干和四肢部分33 个关键点供后期处理时使用。该框架检测出的人体关键点效果如图2所示。
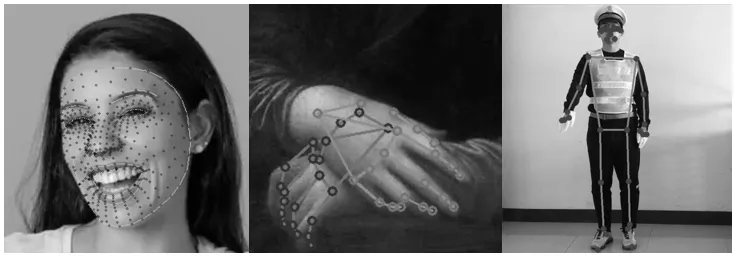
图2 Mediapipe 的检测效果
1.3 DTW 及其改进算法
DTW 算法又称动态时间规整算法,是一种弹性度量方法,相较于锁步度量方法如常见的欧氏距离(Euclidean Distance,ED),其只能对等长的序列进行距离的计算,而DTW 算法打破了这一限制,可对不等长的序列进行距离的计算,且不需要进行训练,序列匹配的精度也十分可观,该算法通常应用于金融预测、语音识别、动态手势识别等领域[8]。
DTW 算法的原理为:以两个不等长的一维序列a{1,2,6,4,8}和b{1,3,4,7,8,9}为例,其长度分别为M和N。首先构造一个累加距离矩阵,其维度为M×N,之后按照如下算法对其进行填充。矩阵填充的详细步骤为:对于自左向右的第一列,首先使用某一种两点间距离计算公式得到两点之间的距离,以欧氏距离为例,计算公式为d=ED(I,j)+ED(I,j-1)。同理对于从下到上的第一行,可用公式d=ED(I,j)+ED(i-1,j)求得各点的累加距离。对于其余点的距离,可用公式d=ED(I,j)+min(ED(i-1,j-1),ED(I,j-1),ED(i-1,j))求得,至此累加距离矩阵构造完成。
为保障点的对应关系按照序列顺序进行推进,DTW 算法有如下几个约束条件:
(1)两条序列的首尾必须匹配。
(2)在累加矩阵的其余点中找寻最优路径时,不得进行跨越连接,即只能在相邻的上下左右或者对角线上相邻的点上找寻下一个连接点。若从左下到右上进行匹配时,下一个点在((i+1,j),(I,j+1),(i+1,j+1))中寻找;若从右上到左下进行匹配时,下一个点在((i-1,j),(I,j-1),(i-1,j-1))中寻找。完成搜寻后即可得到一条最优路径,计算这条路径上的值即可得到两条序列间的距离。累加距离矩阵以及在该矩阵中寻找到的最优路径如图3所示。

图3 DTW 算法生成的累加矩阵和最优路径
FastDTW 算法是DTW 的改进版,其在原始DTW 算法的基础上进行了改进,使用粗粒度化、投影和细粒度化的方式实现序列匹配的加速[9]。该算法相较原算法的改进之处是将搜索区域限制和数据抽象相结合,具体步骤如下:
(1)粗粒度化。该过程会从原始序列中抽象出新的序列,经过数次的迭代后,每个粗粒度的数据对应着原始序列中多个数据的均值。
(2)投影。使用原始的DTW 求解策略,在粗粒度化后的序列中找寻到最优路径。
(3)细粒度化。对粗粒度化的序列进行更加细粒度化的操作,再将得到的最优路径映射到新的更加细粒度化的序列上,之后对最优路径周围的搜索区域进行扩充,扩充范围为纵横斜向扩充1~2 个单位。然后使用DTW 的求解策略更新最优路径,如此迭代往复,直至得到原始序列下的最优路径。FastDTW 算法的迭代效果如图4所示。
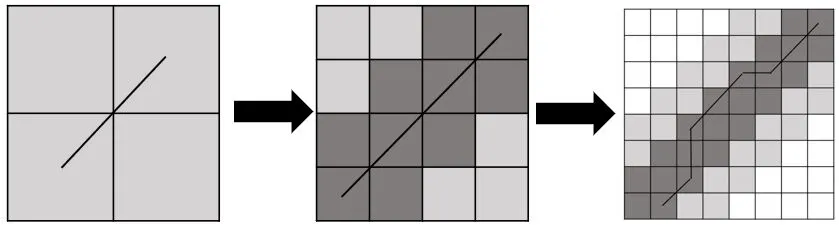
图4 FastDTW 算法的迭代流程
2 数据集和模板库构建
2.1 数据集的构建及YOLOv5s 预定义锚框调整
2.1.1 图片爬取
由于网络上不存在公开的交警和行人数据集,故本人编写爬虫分别从百度图片、搜狗图片、360 图片等三大主流图片搜索网站爬取所需的图片[10],从每个网站爬取800 张图片。由于所爬取的图片中包含不符合要求的图片,经过筛选后得到2 200 张合格图片,将其中的2 000 张图片用于训练,200张图片用于测试。数据集爬取和制作流程如图5所示,首先在浏览器端打开图片搜索引擎进行搜索操作,之后检测ajax请求,通过requests 库解析后端返回的json 格式数据即可得到要爬取的图片地址,将其下载到本地。

图5 网络爬虫爬取交警和行人图片数据
在目标框的标注上,本文使用的是一款在线数据集标注工具Makesense,该工具可生成多种格式的数据集标签,本文使用txt 格式的YOLOv5s 支持的标签文件格式。
2.1.2 自定义锚框的生成
由于本文使用自定义数据集对YOLOv5s 进行训练,因此在预定义锚框的选择上,本文使用K-means 算法重新对自定义数据集边界框进行聚类,得到新的不同下采样倍数特征层上的预定义锚框。新旧预定义锚框数据如表1所示。

表1 新旧预定义锚框数值对比
2.2 人体关键点的提取及交警区域裁切比例的设定
本文自行构建交警手势数据集,首先编写脚本调用笔记本电脑摄像头,同时使用Mediapipe 进行人体关键点检测。录制时本人在现有的八种交警手势中添加一个“无手势”类别,用来匹配交警没有做出指挥手势时的姿态。为便于在目标检测算法中对交警区域进行裁切,录制时约定好做手势人员在视频画面中的位置。具体流程为:首先规定做手势的人员双手向上举起时保证竖直方向上的人体区域边界接近视频画面的边缘;其次令做手势的人员双手平举得到臂展范围(效果如图6中的第二幅图片所示);最后将Mediapipe 生成的相对原视频画面的坐标值,转化为新生成边界框中的相对坐标值。

图6 关键点相对坐标区域的变换
为防止采集到的关键点出现波动,降低因关键点匹配不准确而出现的偏差。本文对九种手势中的每一种动作均采集十次,每个动作的片段由30 帧的关键点坐标构成。
2.3 手势模板的制作和优化
针对包含“无手势”在内的九种交警动作类别,本节使用五种策略制作手势特征模板。首先将经过噪声处理的关键点数据,按照每种手势包含10 个动作片段的方式进行组合,其中每个片段包含30 帧的关键点信息;其次将每种手势中的10 个片段关键点坐标平均值作为该手势的最终关键点数据;最后按照以下5 种策略对每种手势对应的关键点数据进行组织得到手势模板。
5 种策略为:
(1)将手臂12 个关键点的坐标作为特征组织为模板。
(2)将全身33个关键点的坐标作为特征组织为手势模板。
(3)将手臂处的4 个关节角度变化数据组织为手势模板。
(4)将手臂12 个关键点和4 个关节角度变化数据组织为手势模板。
(5)将全身33 个关键点坐标和4 个关节角度变化数据组织为模板。
图7为策略五生成的手势模板。由于策略一到策略四生成的手势模板均可看作是从策略五所得序列中截取部分坐标点绘制而成的,故不作展示。
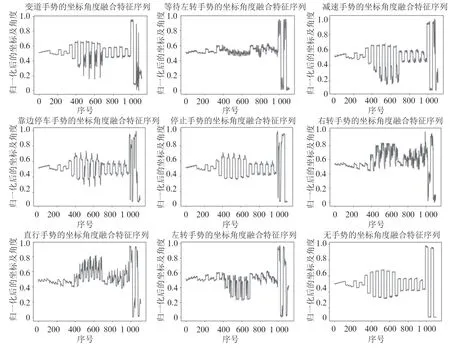
图7 由33 个关键点坐标及4 个关节角度变化数据构成的序列模板
本文所提方法的整体流程如图8所示。
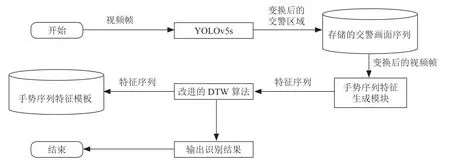
图8 整体流程框架
3 实验结果
本实验所用设备为笔记本电脑,其为Windows 10 操作系统,所搭载的CPU 为英特尔酷睿I5-9300H,显卡为移动端GTX1660TI,使用的集成开发环境是Pycharm,开发语言为Python 3.6.3。在测试阶段,使用公开的中国交警手势数据集[11]并搭配自行录制的交警手势动作,对本文所提方法的有效性进行验证。
3.1 YOLOv5s 的训练和测试情况
在训练YOLOv5s 网络方面,本文使用2 000 张包含行人和交警的图片作为训练集,将200 张图片作为测试集,在YOLOv5s 的预训练权重基础上接着训练300 个轮次,最终得到的训练结果如图9所示,其中包含训练精度、边界框损失、分类损失及置信度损失。
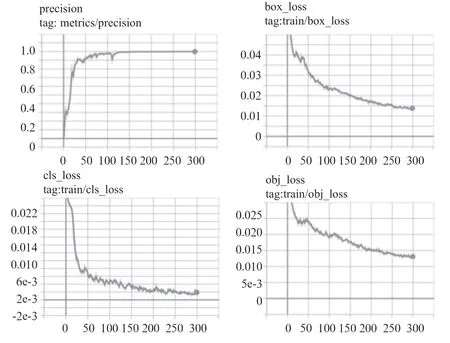
图9 YOLOv5s 训练过程曲线
YOLOv5s 模型经过边界框变换得到的输出结果如图10所示,从左到右分别为原视频帧、原输出区域、经过变换的输出区域。输出的交警区域画面会暂存在图片队列中,供手势识别模块的调用。

图10 经坐标变换得到的目标区域
3.2 对FastDTW 算法的测试
对图片队列中的交警区域画面进行关键点的检测和手势序列的匹配。本节使用制定手势模板时规定的五种策略对交警手势匹配效果进行测试。每种策略中各手势均进行100 次的匹配测试,对一种策略进行测试共需要900 次的对比,最终得到的测试结果如表2所示。

表2 五种手势模板策略的测试结果
策略一到策略五对每种手势的平均检测时间分别为0.005 024 秒、0.042 922 秒、0.000 997 秒、0.008 972 秒和0.043 883 秒。通过观察测试结果可以发现,在识别直行和右转手势的时候,五种策略均存在较为明显的误差。经分析,该结果是在关键点提取阶段直行手势和右转手势的关键点变化在运动过程中存在一定的相似性以及关键点发生轻微偏移所致。经过对比使用策略四(手臂关键点坐标及四个关节处角度变化的序列)可兼获手势识别的准确性和实时性,但在关键点捕捉和相似手势判断上仍需加强。在整体测试中因受限于YOLOv5s 和Mediapipe 的检测速度和磁盘IO 的速度,实际运行时的帧率维持在15~20 帧。
4 结 论
针对当前交警手势识别过程中交警所处画面区域以及距离较为固定,且在现实道路中无法精确定位交警位置的问题,本文提出一种基于YOLOv5s和FastDTW算法相结合的方法,使得在交警手势识别过程中能够在人群中定位到交警,对其指挥手势进行分析,避免了画面中包含多个人物时出现的手势误识别问题。在手势特征提取上本文使用谷歌的Mediapipe 作为人体关键点生成框架,其可以在CPU 上实现实时的效果。同时搭配运行在GPU 端的目标检测算法实现对交警区域的截取,两者相互协调充分利用计算机资源,使得本文方法在实际运行过程中可以达到接近20 帧的识别效果。虽然本文方法在画面中有多个人物时可实现对某一交警的定位与识别,但当画面中存在多个交警时,精确捕捉并识别某一交警的手势则有待进一步的优化,这也是我们今后的研究重心。
