基于加速结构和CUDA的光线追踪算法和技术研究
2022-11-16李益文姚立民陈立海
王 平,李益文,乔 磊,姚立民,陈立海
(1.河北石油职业技术大学 1a.仪器仪表中心;1b.热能工程系,河北 承德 067000;2.空军工程大学 等离子体动力学重点实验室,陕西 西安 710038;3.承德摩隐信息科技有限公司 应用开发部,河北 承德 067000)
自然界万事万物都是并发的,按照其内在时间序列运行着。真实世界是高度并行的,和串行计算相比,并行计算更适用于对现实世界中的复杂现象进行建模、模拟和理解。
目前,并行计算特别是基于GPU的并行计算在很多效率问题的解决上起到了重要的作用,特别是涉及浮点运算的算法上[1-2]。另一方面,加速结构对减少射线追踪过程中相交判断有着非常好的效果[3-5]。在进行射线追踪相关仿真计算时,由于所产生的射线数量巨大,导致计算量非常庞大。开展基于GPU的射线追踪并行算法的研究,并对多种加速结构在GPU下数据传递方法和应用场景进行研究具有重要价值!
1 并行计算及CUDA技术
并行计算是相对串行计算的,简单来说就是同时使用多个计算资源来解决一个计算问题。并行计算的问题或算法具有离散化、可并行执行、需进行集中调度等特点。
并行计算模型是作为硬件和内存架构之上的一种抽象存在,这些模型并不和特定的机器和内存架构有关。常见的并行编程模型[6]包括:共享内存模型、线程模型、分布式内存/消息传递模型、数据并行模型、混合模型、单程序多数据模型、多程序多数据模型。
常见编程模型[7-12]包括OpenMP、MPI、CUDA、OpenCL、C++ AMP等。这些编程模型在程序逻辑方面相似,也有一定区别。因为CUDA与OpenCL更接近硬件底层,所以前两者的性能更好,然而C++ AMP的易编程性却要优于CUDA和OpenCL。
在 CUDA 的架构下,一个程序分为两个部份:Host端和 Device 端。Host 端是指在 CPU 上执行的部份,而 Device端则是在显示芯片上执行的部份。Device 端的程序又称为 “Kernel”核函数。通常Host端程序会将数据准备好后,复制到显卡的内存中,再由显示芯片执行 Device端程序,完成后再由 Host端程序将结果由显存中取回。为了让GPU有可用的编程环境,从而能通过程序控制底层的硬件进行计算,CUDA提供Host-Device的编程模式以及非常多的接口函数和科学计算库,通过同时执行大量的线程而达到并行的目的。
2 常用加速结构
光线追踪涉及到大量计算,通过空间划分数据结构来实现加速是一种比较常用的手段。
1)四叉树索引的基本思想是将地理空间递归划分为不同层次的树结构。它将已知范围的空间等分成四个相等的子空间,如此递归下去,直至树的层次达到一定深度或者满足某种要求后停止分割。四叉树的结构在空间数据对象分布比较均匀时,具有比较高的空间数据插入和查询效率(复杂度O(logN))。八叉树的结构和四叉树基本类似,其拥有8个节点。
2)KD-Tree是一棵二叉树,其每个节点都代表一个k维坐标点;树的每层都是对应一个划分维度;树的每个节点代表一个超平面,该超平面垂直于当前划分维度的坐标轴,并在该维度上将空间划分为两部分,一部分在其左子树,另一部分在其右子树;即若当前节点的划分维度为i,其左子树上所有点在i维的值均小于当前值,右子树上所有点在i维的值均大于等于当前值,本定义对其任意子节点均成立。
3)层次包围盒(BVH)与前几种方法最显著的区别就是,不再以空间作为划分依据,而是从对象的角度考虑,过程如下:第一步同样找出场景的整体包围盒作为根节点;第二步找到合适的划分点,将最大包围盒内的三角形面分为两部分,再分别重新计算新的包围盒;包围盒会重叠,但一个三角形面只会被存储在唯一的包围盒内,而这也就解决了KD-Tree的缺点。接下来与KD-Tree的建立类似,递归对所有子空间重复该步骤。
4)基于表面积的启发式评估划分方法:在KD树、BVH的构建过程中采用了中点划分和等量划分两种方式对图元进行划分。当图元分布不均匀的时候,划分结果会变得很差。基于表面积的启发式评估划分方法(Surface Area Heuristic,SAH)[13]通过对求交代价和遍历代价进行评估,给出了每一种划分的代价,而KD树等构建过程便是寻找代价最小的划分。
3 算法程序设计与验证
3.1 程序总体设计
程序设计分为两个大的部分,其中第一部分是通过WinForm框架,结合C#语言开发的带界面的前端程序;第二部分是使用C++语言结合CUDA开发的射线生成程序,以及光线与三角面片进行相交判断的内核程序(见图1)。两者之间通过约定格式的文件来实现数据传递。

3.2 无加速结构CUDA设计关键点
CUDA程序设计有两个核心点,一个是如何有效的将数据从CPU向GPU传递,并且能够正常高效的供CPU的内核使用;另外就是如何将程序并行化分配到每一个内核上。
1)CPU数据向GPU数据的传递:由于GPU中无法使用map之类的泛型结构,因此需要以数组等方式来组织好数据,并通过cudaMemcpy将内存中的信息拷贝到CPU的内存中。
2)将相关算法修改为可在Device上调用的函数。
3)对算法程序进行并行改造:每一个GPU线程处理一个指定索引号对应的计算需求。
4)调用方法的适应性修改:设置相应的Block块和每个Block中的Threads,然后通过指定的语法调用相应的函数和相应的参数。
5)GPU数据向CPU数据的传递:将GPU算法中计算完成的数据拷贝到主机内存中再进行下一步的处理和展示等操作。
3.3 加速结构的CUDA数据传递方式
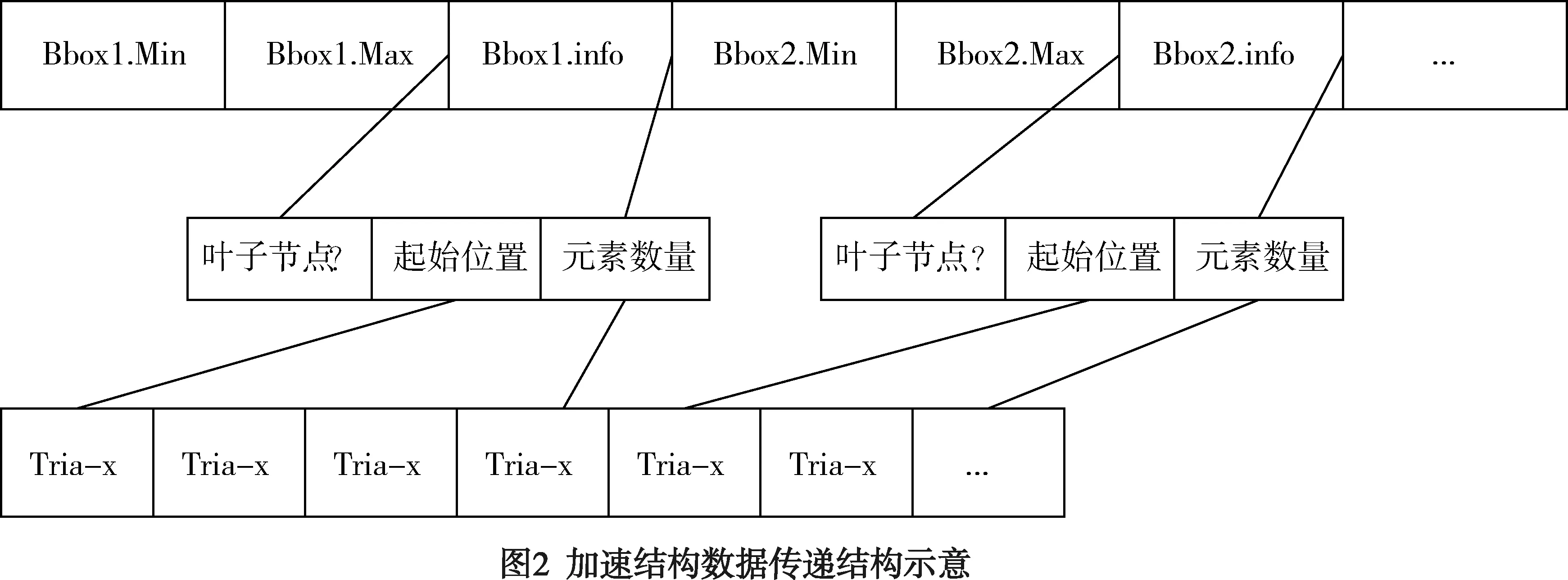
采用加速结构的CUDA程序从总体上与无加速结构程序类似,区别之处在于在于进行射线相交时需要考虑先使用加速结构来缩小三角面片判断的范围,这样带来的问题就是如何将加速结构有效的进行组织,传递到GPU中并进行相应的计算判断(见图2)。
3.4 SAH算法带来的调整
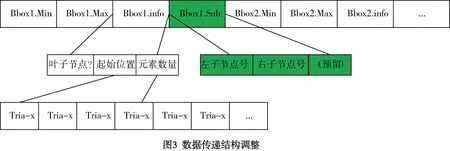
SAH算法可以有效的解决图元分布不均匀的情况,但SAH算法会导致加速结构树不是完全树,因此在进行GPU编程开发时需要调整数据结构(见图3)。完全二叉树的父节点与子节点存在着明确的关系(j=(i-1)*K+1+1),而非完全树的父节点与子节点的关系是不确定的,因此对于加速结构包围盒树结构进行子节点相交测试时需要明确节点下的子节点编号关系。在使用SAH时需要调整数据传递及调用关系,由于要多传递一组数据,数据结构有所调整。
3.5 效率测试与评估
最后,在实现上述算法并进行相应细节上的优化操作之后,通过实验对算法的整体性能进行了测试。实验时所采用的PC平台为64位Win10操作系统,处理器和内存为:Intel Core(TM)i7-7700HQ CPU @2.8 GHz,RAM 8.0 GB,所使用的显卡GPU支持为GTX 1050。
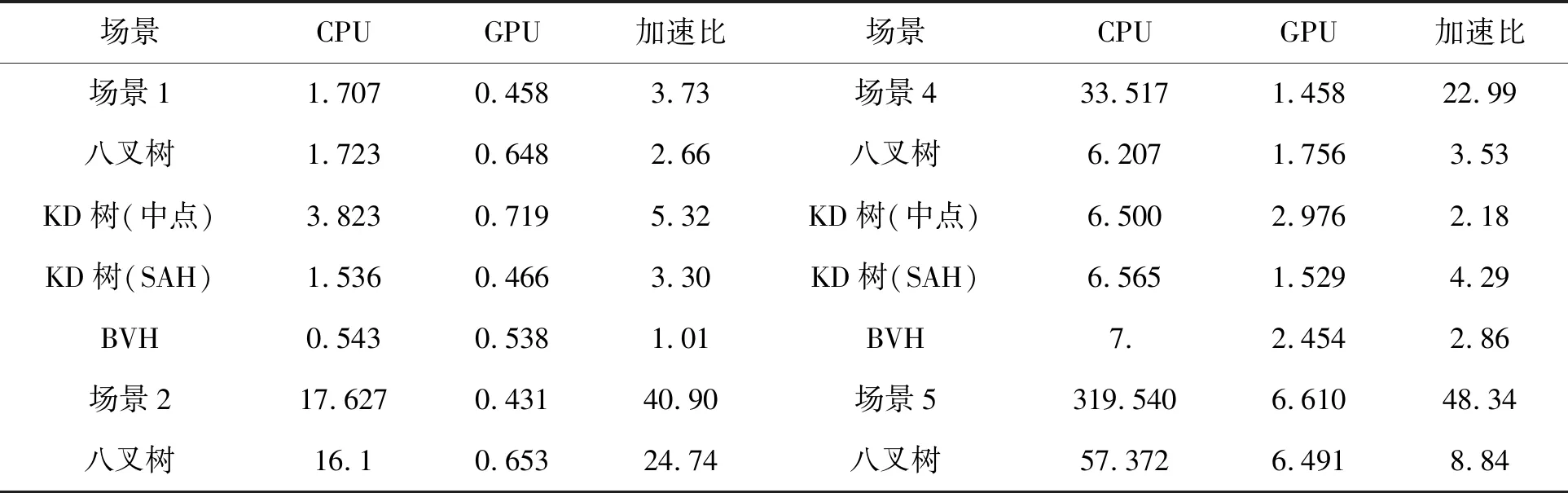
表1 实验测试数据及加速比
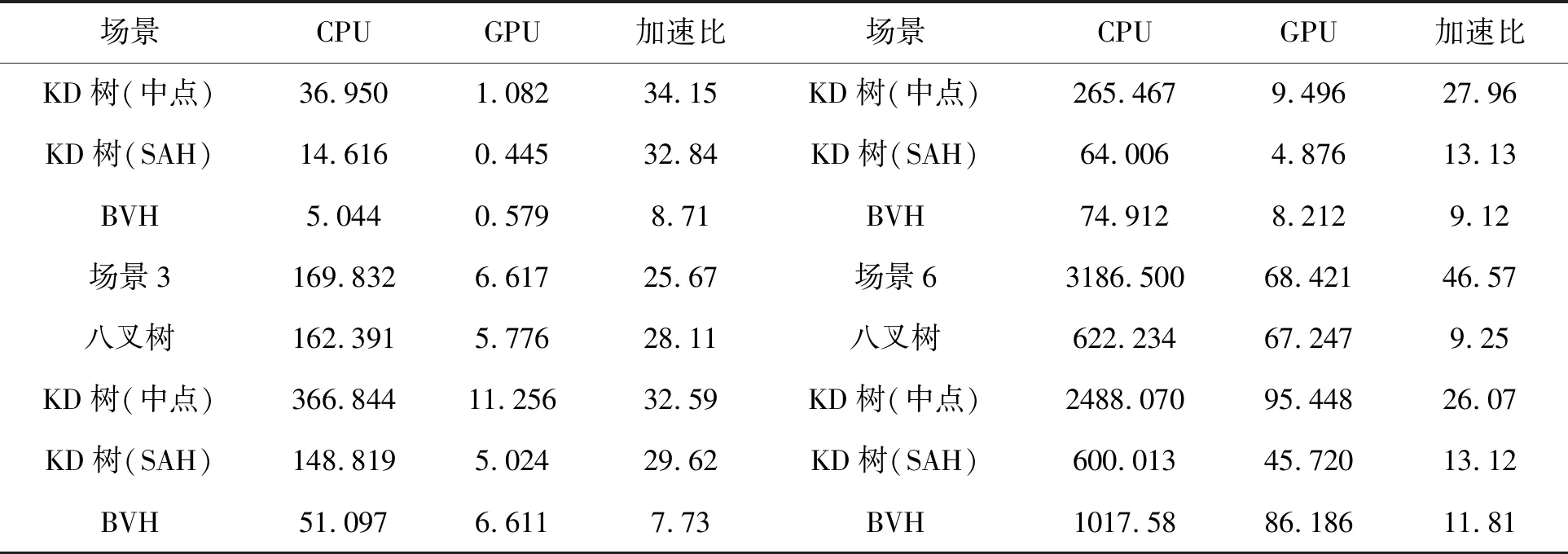
续表
从表1中可以看出将算法合理并行化后移植于GPU平台得到了很大的速度提升。通过实验可以看出:
1)加速结构的构建相对射线相交判断来说耗时少很多,研究重点可以集中在对加速结构的合理构建上,图元分布均匀性对加速结构的加速效果有着比较大的影响。总体来看,BVH和KD树(SAH)加速效果普遍好一些,其次是八叉树,最后是KD树(中点分隔)。
2)在网格数量较少时,加速结构效果并不明显,甚至耗时有所增加(增加了加速结构包围盒层次结构与射线的判断);而随着网格数量增加后,加速结构可以有效的减少射线与面片的相关判断次数,从而减少时间。
4 结论
本文首先较为详细阐述了并行计算在光线追踪计算中的作用、常用加速结构;然后通过加速结构和基于CUDA的射线追踪算法的并行化实现及效率测试。经测试可知:随着网格数量增加后,加速结构可以有效的减少射线与面片的相关判断次数,从而减少时间;BVH和KD树(SAH)在加速效果比较明显;GPU加速的效果整体上也比较明显,但不同GPU的性能和参数都有不同,如何最大限度的利用好GPU性能需要进一步的细化分析和研究。
