基于深度学习的手势识别人机交互应用研究
2022-11-16杨海红
杨海红
(山西旅游职业学院 计算机科学系,山西 太原 030031)
随着计算机视觉技术的迅速发展,如何从包含视觉混乱和多人的复杂场景中提取有用的信息显得尤为重要。然而,遮挡和形变的物体以及分散注意力的运动线索使语义信息提取变得十分困难。对于大多数应用来说,低层级信号的大多数细节都是不相关的,重要的信息通常出现在图像或视频的显著部分。这就需要能够从复杂和有噪声的视觉数据中可靠地提取出有用的信息。常用的特征提取网络之一是卷积神经网络[1]。它们能够从复杂的视觉数据中进行归纳,适合于现实场景中的视觉应用。本文率先分析了使用神经网络定位多人场景中显著人体运动的潜力,因为这种场景对于真实环境中的视觉应用是比较典型的。本文通过对某个场景进行深入对比研究,从一个典型的单人实验扩展到包含多人的情况。其中一个人做了一个动态的人体手势,而其他人则是被动的旁观者,只执行一些细微且与任务无关的动作。卷积神经网络的目的是从图像序列中检测和定位出手势的执行人,并忽略其他的非手势运动。为实现这一目的,本文提出一种三维卷机神经网络结构,该结构将来自Kinetic设备采集的包含RGB-D信息的帧序列作为其输入。它经过端到端的训练以产生具有明亮像素的二维输出,亮的像素代表手势执行者的空间位置。我们使用3D的卷积核,它允许网络输入固定大小的图片序列。
1 研究现状
1.1 行人检测和定位
在视觉数据中的检测和定位任务上,传统方法是通过使用Haar小波模板[2],方向梯度直方图(HoG)[3],或者光流直方图(HoF)与方向梯度直方图(HoG)相结合[4]来实现的。输入来自微软Kinect等设备的RGB-D数据,这些特征也被扩展到深度通道,例如定向深度直方图(HoD)[5]。为在图像中定位一个人,许多研究使用了滑动窗口的方法[6]。随着卷积神经网络[7]取得了极大的进展,它们也开始被广泛应用于行人检测任务,并展示出与早期基于特征工程的方法相比更先进的性能[8]。常见的数据集[9]由包含了机动车和行人的交通场景图像组成。然而,行人检测任务只是简单地检测和定位人,它没有考虑一个人是否正在执行特定的动作。
1.2 多人场景人机交互
在动作识别和手势识别的领域中通常更加关注执行人的实际运动。传统的特征工程方法通常使用手工提取的特征,包括肤色建模[10]或运动分析[11]。最近,各种深度学习特征提取方法也被广泛应用于手势识别[12]和动作识别[13-14]的任务。虽然这些研究旨在区分不同类型的运动并进行分类,但它们只针对单人的场景。一些广泛使用的数据集[15]大都包含单人的场景,研究结果也隐式地假设系统的输入只包含一个人。然而在实际机器人应用中,例如在办公室[16]或博物馆[17],选择一个人作为机器人的交互伙伴是很重要的。在这些研究中,计算了场景中关于人的高层级知识,例如,脸的位置和大小,到机器人的距离,以及人最后一次说话后经过的时间。基于这一知识,使用一些启发式方法来对活跃的人进行决策,例如社会距离分数来执行[18]。本文方法侧重于定位出主动处理传感器的人。此外,我们的评估直接基于低层级信号,并使用定量指标来评估系统性能。
1.3 显著性机制
在关于显著性的研究中,我们调研一些相关工作,它们直接在低层级信号上来确定视觉数据中的相关部分。显著性描述某些数据中与其他数据显著不同的独特元素。许多显著性研究着眼于人眼跟踪数据,以比较计算系统的结果[5]。传统的显著性和视觉注意力模型通常直接使用从实际人类视觉系统的神经学研究中已知的特征。根据Bylinskii等人[5]的说法,目前最准确的显著性计算模型是基于深度学习的网络结构,例如Kruthiventi等人[19]所使用的方法。然而,我们所经历的世界并不是静止的,事实上运动已经显示出显著的影响来吸引我们的注意力。然而,Gullberg和Holmqvist等人[20]对这一事实提出异议,并将Nobe等人[21]的观察结果归因于特定的实验装置。他们认为人类处理手势的方式受到他们所处的社会环境的严重影响。Riche等人[22]根据RGB-D数据计算了光流特征,并识别了与场景中其他运动不同的图像区域。这些现象即被解释为突出的运动。相比之下,本文的方法直接使用低层级的深度数据作为信号,并且直接针对多人场景进行设计。
2 方法介绍
为评估一个包含显著运动的多人场景,本文设计一个实验,在一个有人的场景,其中一个人做一个动态的人体姿势。这个活跃的人被随机安排在房间的任意位置。对于有监督学习的神经网络,我们需要一个具有足够样本的大数据集来让网络进行任务的学习。每个样本是代表这种多人场景的帧序列。此外,每个序列还需要一个标注来编码执行人的位置。在本节中,我们将描述如何制作这样的数据集。然后,本文针对该数据集提出一个三维卷积神经网络结构,以在该数据集上执行检测和定位任务的训练及测试。
2.1 数据集制作
由于卷积神经系统通常需要大量准备充分的数据集来获得良好的结果[17],本文通过将一个人的标注片段系统地组合成多人序列。利用微软Kinect设备来采集RGB-D数据,并人工地使用其深度通道创建多人场景。
使用RGB-D传感器的优点是可以获得深度信号。信号中的值越大意味着与传感器的距离更大。这使我们能够方便地组合多个标注记录,使结果看起来像真实的标注序列。
在数据收集过程中,本文记录手势执行者和被动人的身体姿势。在这些记录中,一个人被放在一个大房间中央的Kinect传感器前面,使得这个人可以很容易地被裁剪,而不会有任何家具遮挡等问题,便于数据采集。此外,本文记录大量的空房间场景,用作生成序列的背景帧。
执行者主要执行八个类似命令的身体手势。这些手势分别代表不同的手臂运动(见图1)。执行者也进行一些随机的身体姿势,比如以不同的视角面对传感器,同时垂下手臂,交叉手臂或稍微移动腿部,但不要明显地移动手臂。

图1 手势数据集
虽然同一个人的每个手势执行都不同(受试者内部的可变性),但多人之间动作执行的差异要更大(受试者之间的多样性)。为了保证在记录的手势执行样本中有足够的多样性,让6个受试者分别执行图1中列出的手势。其中女性1人,男性5人,年龄在25~34岁之间。每一个手势都被重复执行多次。所有受试者总共执行了568个手势实例,得到共计42 000帧图像可用于数据集生成。使用Vatic视频标注工具,对这些帧标记了行人包围框以及人头部的边界框(见图2)。

图2 帧标注示意图
获得帧数据和标记之后,就可以根据任何期望的场景描述来生成序列。除这些序列之外,本文还额外生成一个教师帧(用作数据标签)。这个二维的帧代表了场景中人的位置,并以白色显示动作执行人。生成序列的基本策略是将人的轮廓从记录的深度通道中分离出来,并将其放置在背景记录中顶部的随机位置,如图3所示。

图3 多人序列生成过程示意图
本文根据多个场景设置将多个人进行了随机放置,从而生成包含多人场景的数据集。主要包括以下五种场景:
(1)没有人的空房间:占比为所有序列的10%;
(2)一个人做一个手势:占比为所有序列的20%;
(3)一个人不做手势:占比为所有序列的20%;
(4)两个人,其中一个人执行手势:占比为所有序列的30%;
(5)三个人,其中一个人执行手势:占比为所有序列的20%。
2.1.1 序列长度
本文将数据集的每个样本分别生成为15个连续帧的序列。帧率为30帧/秒,即这个长度相当于记录的手势表演的半秒钟。手势序列长度分布见表1。

表1 手势数据集统计分布
2.1.2 训练、验证和测试集
我们以一种易于分离的方式将记录的手势划分成训练、验证和测试的三个子集,为实现这种分离方式,数据集在生成的过程中会产生5个不同的小子集。每个子集使用完全不同的记录帧集合,因此这5个子集之间没有重叠。网络然后可以使用三个子集作为训练集来训练,剩下的两个子集分别用于验证和测试。每个子集至少包含512个序列。
2.1.3 移除地平面
当在Kinect数据的深度通道中分离一个人的轮廓时,我们发现在将人从其周围切开之前移除地平面是有必要的,如图4所示。这有利于产生了更干净的轮廓。我们可以假设一个地面的直线方位和相机的直线方位,使得地面在深度信号中表现为线性梯度。为去除地平面,我们假设在这个梯度附近的所有像素都属于地板,并屏蔽掉匹配的值。这个简单的步骤极大地改善我们的方法对于轮廓的提取,无论是在拼接多个记录帧或者是生成教师帧时。

图4 帧中提取人物轮廓示意图
2.1.4 数据扩充
为进一步丰富数据的多样性。将每个人放入场景之前,改变了其亮度值。亮度的变化模拟离传感器更近或更远的不同位置,并且是从高斯分布中采样的。
2.1.5 教师帧生成
它显示场景中所有人的位置,并对执行者进行了编码。每个人都用他们的轮廓进行标记。每个轮廓都被涂上白色(执行者)或更深的灰色(旁观者)。由于生成该帧的目的是用于网络的训练,所以它被称为教师帧,如图5和图6所示。每个轮廓内部的细节都被忽略。帧的每个像素都应该编码像素的内容(即执行者、旁观者、背景)。轮廓的亮度可以有两个不同的值,这取决于在场景中人的扮演角色。执行者被分配全亮度(灰度值255),被动的人被分配全亮度的30%(0.3×255≈76)。背景像素则被生成为黑色。

图5 单人手势序列

图6 多人手势序列
2.2 网络结构
本节将描述两种不同的网络体系结构。一种使用3D卷积,另一种使用标准的2D卷积,用于在评估阶段的性能比较。
2.2.1 网络输入
我们的3D卷积网络接收15帧固定长度的序列作为其输入。每帧宽160像素,高120像素,可以清楚地看到单个身体部分和演员的运动。我们用作对比的2D卷积网络结构也使用相同的帧格式,但只接收单帧作为其输入。在将帧传递给网络之前,我们将所有深度值标准化到-1到1的范围,以统一激活,使得他们集中在零附近。
2.2.2 网络输出
两种结构最终都产生了一个二维帧作为它们的输出,低值代表背景,高值代表场景中的人。输出层的单元产生该输出帧的单个像素。选择输出层的大小意味着在输出的视觉描述能力和训练网络的计算成本之间进行权衡。我们决定输出尺寸为,宽32像素,高24像素,结果输出层为768个单位。
2.2.3 回归任务
为从提取的特征中产生2D的空间定位结果,我们采用包含一个隐藏层的多层感知器。它的输出层中每个像素都需要一个神经元,即768个单元。
2.2.4 训练
通过最小化均方误差损失函数来训练网络的回归任务。并使用Adam优化算法的梯度下降策略进行权重更新[15]。为防止过拟合,我们在多层感知器的隐藏层之后使用Dropout正则化策略。
2.2.5 3 D网络结构
我们的主网络有三个带有3D卷积的卷积层。每个卷积之后是ReLU激活层和最大池化层。特征提取块后接着多层感知器执行回归任务。
2.2.6 2D网络结构
作为性能比较,我们同样选取神经网络结构,该结构没有考虑时序信息,只处理单帧输入。从总体结构来看,它与前面描述的3D网络相同,主要区别在于它使用2D卷积而不是3D卷积。因此,第一层的输入不是序列帧。相反,只有每个序列的最后一帧被认为是网络的输入。
网络实现和依赖库。我们使用OpenNI 1.5.x来收集Kinect记录。使用开源工具oni2avi将这些视频转换为常规视频,并使用Vatic提供的浏览器界面对这些视频进行标注。帧序列和教师帧是通过自定义Python脚本使用多个开源库生成的,例如:OpenCV、Numpy和SciPy。我们使用TensorFlow实现不同的网络结构,并在英伟达GTX 1080Ti上进行训练。
3 实验
为评估所提出的网络结构是否能够很好地学习到期望的显著性机制,我们进行一系列实验。我们用生成的多人数据集训练这两种网络结构,并对来自该数据集的测试样本进行评估。
3.1 网络配置
无论是2D网络还是3D网络,在结构上都十分相似,主要区别是使用2D或者3D卷积,网络结构的对比如表2所示。

表2 网络结构对比
3.1.1 3D网络
如图7所示,3D网络包含三个卷积层,分别包含8、16和32个3×3×3的滤波核,带有ReLU激活层,多层感知器中的隐藏层中包含了384个隐藏单元,在训练阶段以2×2×2的步长使用3×3×3最大池化和Dropout正则化。Dropout层放置于隐藏层之后。

图7 三维网络结构示意图
3.1.2 2D网络
如图8所示,2D网络包含三个卷积层,分别包含4、16和16个维度为3×3、5×5和3×3的卷积核,带有ReLU激活,以及一个具有384个单元隐藏层的多层感知器。在训练期间采用步长为2×2的3×3最大池化层和Dropout的正则化。Dropout层同样位于隐藏层之后。

图8 二维网络结构示意图
3.2 训练
使用Xavier初始化方法分别初始化两个网络的权重。然后通过最小化均方误差损失函数进行训练。权重更新是使用Adam优化器[22]进行的,学习率为0.001,学习率以0.9倍率衰减,以小批量进行训练且批量大小为4。
我们对每个网络进行5次重复训练,并计算测试集的平均分数。2D网络训练40个迭代周期,3D网络则训练50个迭代周期。在训练期间,Dropout概率被设置为50%。
3.3 评价指标
为评估网络是否正确地检测到活动的手势执行者,我们定义一个评价指标来评估预测结果的准确性,如图9所示。

图9 预测结果和标注结果对比图
数据集中的教师帧将活跃的表演者编码为白色的轮廓。正确的网络预测也应该在轮廓内具有其最亮的值。该度量的基本思想是查看网络输出中最亮像素的位置,并比较该位置是否是教师帧中的白色像素。然而,由于原始教师帧的重新采样,它不仅仅由黑色(背景)、白色(前景)和0.3的亮度值(旁观者)组成。因此,我们没有显式地检查白色,而是将该值与阈值0.3进行比较。高于该阈值的值被认为足够亮。选择0.3的阈值是因为它是旁观者的最低亮度。
由于有些序列不包含活动的手势执行者,因此教师帧为全黑色像素。在这种情况下,我们检查网络预测是否包括任何高于0.3阈值的像素。如果所有像素的值都低于该阈值,则返回真。否则,返回假。
对于两个帧的比较,度量返回真或假,作为输出是否正确的决定。然后在整个测试集中使用这个正确性度量来计算网络的运动检测分数:

为了量化网络对运动检测任务的学习程度,我们确定了一个基线分数,即当执行随机预测时的分数,为5%。
3.4 实验结果与分析
如表3所示,两个网络结构在测试集上展示出了非常相似的整体性能,可见两个网络都成功地从数据集学习到了期望的显著性检测任务。他们能够在场景中检测和定位出主动手势,准确率明显高于随机预测的基线分数。为以更精细的方式比较两个网络的性能,我们将测试集分成多个子集,每个子集只包含相同活动手势的序列。这为每个手势产生了8个子集,加上两个序列子集,其中有空场景和只有旁观者而没有执行者的场景。然后,我们在这些子集上评估运动性能度量,并比较两个网络的性能得分,如表4所示。
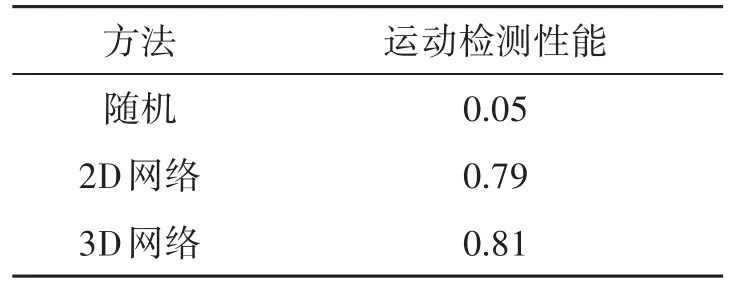
表3 网络总体性能对比

表4 不同网络在不同子集上的手势预测结果对比
当比较不同子集的结果时,有两个得分明显较低的类别:“Stop”手势和旁观者。我们发现教师帧中“Stop”手势有时生成得不正确,因此有一些帧不包含人的轮廓,只包含手的微小轮廓,如图10所示。这是因为在其他手势中,手臂离传感器更近。当生成教师帧时,轮廓随后被错误地生成,并存在训练和测试数据中。该度量将这些错误生成的帧与网络预测进行比较,因此为这些序列产生了低的分数。对于这两个手势类别,3D网络显示出比2D网络更高的性能。在只有旁观者的场景下,它也显示出低得多的标准差。这个现象揭示3D网络如何系统地和更好地区分实际的执行者和在同一帧中相对于其他人显得更活跃的人。

图10 正确/不正确的教师帧及其预测结果示意图
3D网络结构对于手臂位置更加多样化的手势,显示出更高的性能。“X”和“Check”手势就是这种情况,它们都包含在空中画一个符号。这些运动的手臂位置都较低,如图11所示。从单帧的角度看,手臂的摆放位置看起来更像是旁观者的手臂位置。3D网络接收完整的图像帧序列作为输入,其覆盖范围不止单帧图像。这也是为什么3D网络在检测这种姿势的主动运动方面表现得更好。同样地,我们观察到3D网络在检测“Circle”手势时的分数也更高,其包含帧中的手臂位置也非常低。

图11 低位置的手势示意图
实验结果表明,神经网络的能力非常适合在多人场景中检测和定位显著的运动,而且像2D或3D卷积核这样的设计决策应该根据所选手势集的特征来做出。这两种结构的总体性能非常相似。同时,我们还可以发现,手势集的选择对网络特征学习的影响也不容忽视。2D网络的总体良好表现可能是基于我们实验中使用的是类似命令的手势。由于2D网络的优势对于清晰的手臂姿势来说是显而易见的,因此它在这种姿势设置下表现良好是有意义的。对于不同手势,网络结构表现出不同的结果也指出了这样的事实,即某些手势特征影响了网络结构能够学习到该手势的程度。
我们的方法不需要预处理步骤,如Riche等人[21]中在显著图融合过程中的透视校正,这些步骤确保他们的系统在人到传感器的不同距离上进行工作。这在本文中是不需要的,因为由于我们的数据增强技术,我们的数据集中已经包含不同距离的人。神经网络能够从这些数据中具有泛化能力,并在没有人工预处理的情况下学习这些不变性。因此,我们的工作重心转移到如何创建合适的数据集。
4 结束语
本文引入卷积神经网络结构来检测和定位多人场景中的显著身体运动。所采用的3D神经网络不需要任何手动预处理步骤,即可定位出一个人所执行的身体姿势。本文提出的系统实现了一种显著性机制,该机制能够针对特定身体运动线索做出反应。实验结果表明,本文的网络结构可以可靠地检测和定位到场景中执行显著运动的人。
