基于BMA多模型组合的疏勒河径流预测研究
2022-11-16温小虎尹振良杨林山
周 婷,温小虎,冯 起,尹振良,杨林山
(1.中国科学院西北生态环境资源研究院,甘肃 兰州 730000;2.中国科学院大学,北京 100049)
0 引言
准确可靠的日径流预测是水文研究的重要内容,也是水资源管理的重要环节[1],可为流域内水资源的科学管理、合理利用以及水资源评估提供重要的科学依据[2]。其中,3日以上的中长期日径流预测对于流域内的防洪、水资源调控、生态环境保护等具有十分重要的意义[3]。特别对于我国西北干旱半干旱地区,水资源已成为限制区域社会经济发展、影响生态安全的主要因素[4]。因此,准确的径流预测对于区域内的水资源管理与可持续利用都具有非常重要的现实意义[5-6]。
分布式水文模型与机器学习方法是径流模拟预测的常用工具[7-8]。分布式水文模型可以准确地描述流域内的水文物理过程,但通常需要大量的水文、气象等数据作为输入,而西北地区由于观测站点稀疏,水文、气象资料不足,使用分布式模型会使建模过程既耗时又昂贵[3,9]。机器学习方法仅从数学上考虑输入与输出之间的非线性关系,不需要描述水文过程的物理参数,通过挖掘数据本身的潜在规律对径流进行预测。近年来,机器学习由于算法简单、易于实现等优点,在资料有限的条件下,展现出更优的预测能力,已经广泛应用于各种条件下的径流模拟预测研究中[10]。其中,极限学习机(Extreme Learning Machine,ELM)模型、支持向量机(Support Vector Machine,SVM)模型、多元自适应回归样条(Multivariate Adaptive Regression Spline,MARS)模型等在西北地区径流预测研究中均取得了较好的预测结果[9-11]。虽然单一模型在特定的时空条件下都表现了较好的模拟预测性能。但是,由于径流过程的高度非线性、形成机制的复杂性以及模型结构自身的不确定性,单一模型的模拟预测结果存在较大不确定性[12]。
针对径流预测研究通常采用单一方法进行建模与预测,难以有效利用各预测模型优势的问题,有学者提出多模型融合的方法,即将多个单一模型进行组合,通过降低单一模型的偏差,发挥各模型的优势,使预测值更加接近于实测值,进而提高径流预测结果的精确度与可靠性[13]。Zhang等[14]运用奇异谱分析(SSA)与自回归综合移动平均模型(ARIMA)结合对年径流量进行预测。结果表明组合模型具有更佳的预测能力。Wang等[15]将人工神经网络模型(ANN)与集成经验模式分解(EEMD)结合用于中长期径流时间序列预测,其结果较单一ANN模型有了明显的改进。Shamseldin等[16]运用简单平均法(SAM)、加权平均法(WAM)、神经网络方法(NNM)对5个水文模型进行组合用于日径流量预测,结果表明三组组合模型的预测精度均高于单一模型。以上方法均基于确定性的理论,集成不同模型的预测结果,能够提供更精确的综合预测结果,但无法定量评价模型结构的不确定性[12]。基于贝叶斯理论发展起来的贝叶斯模型平均方法(Bayesian Model Averaging,BMA)通过计算单一模型的后验概率,并基于后验概率对组合模型成员进行加权平均,判断成员模型优劣。因此,BMA可以有效处理组合模型成员的不确定性,在提供精度更高的预测结果的同时,还能提供可靠的预测概率,定量评价模型结构不确定性对预测结果的影响[17]。近年来,BMA方法也被应用于水文学领域,董磊华等[18]运 用BMA方 法 综 合SIMHYD、SMAR(Soil Moisture Accounting and Routing),以及新安江模型的预报结果,推求出可靠的预报值的概率分布;Jiang等[19]利用BMA方法集成多卫星降水产品,对湘江日径流进行模拟;Xu等[20]以中国为研究区,研究了BMA在多模态水文预报后处理中的应用。以上研究均表明BMA能够提高水文预测的准确性与可靠性,还能得到更为优良的预测区间。然而,目前运用BMA方法进行中长期日径流预测的相关研究尚不多见。
疏勒河是河西走廊三大内陆河之一,其上游出山径流量制约着下游玉门、瓜州以及敦煌等地区的经济发展和生态环境变化[21]。因此,对疏勒河上游径流进行准确地模拟预测对于加强区域内水资源管理、实现水资源高效利用以及促进人与生态可持续发展都具有重要的现实意义[22]。因此,本文将以疏勒河上游作为研究区,利用疏勒河上游出山口昌马堡水文站2010—2017年实测日径流数据,基于SVM、ELM、MARS模型对疏勒河上游流域未来1~7日径流量进行预测,运用贝叶斯模型平均(BMA)方法对ELM、SVM、MARS模型的预测结果进行组合,构建径流组合预测模型,并提供确定性预测与概率预测结果。
1 研究方法
1.1 极限学习机(Extreme Learning Machine,ELM)
ELM通过对输入权值和偏置随机赋值,并根据“最小二乘法”的原理,运用Moor-Penrose伪逆矩阵计算输出权值,在保证学习和训练精度的前提下,克服了传统神经网络训练速度慢、容易陷入局部最优等缺点。假设n、l、m分别是网络输入层、隐含层以 及 输 出 层 的 节 点 数,对 于N个 样 本(xi,ti),i=1,2,…,N,其 中xi=[xi1,xi2,…,xin]T∈Rn,ti=[ti1,ti2,…,tim]T∈Rm,ELM模型可表示为:

其中:g(x)是第l个隐节点的阈值和非线性映射函数;βi是隐含层和输出层的连接权值向量;ωi是输入层和隐含层的连接权值向量;bi是隐含层神经元阈值;oj是网络输出。此时,上式可以改写为:

其中:H是隐含层的输出矩阵;β是输出权值矩阵;T是样本集目标矩阵。
实现基于ELM预测径流量的过程如下。第一步:确定隐含神经元个数,本研究根据均方误差(Mean Squared Error,MSE)最小原则,设定隐藏神经元个数。随机设定输入层与隐含层的连接权值ωi和隐含神经元的阈值bi。第二步:选择一个无限可微的函数作为隐含层神经元的激活函数,进而计算隐含层输出矩阵H。通过交叉验证方法,选取误差最小的sigmoid函数为激活函数。第三步:计算输出层的连接权值矩阵β∶β=T+H。
1.2 支持向量机(Support Vector Machine,SVM)
支持向量机是根据统计学理论提出的一种通用学习方法,通过核函数把低维空间中的非线性回归问题映射到高维特征空间中,在高维特征空间中求解凸优化的问题,能很好地解决非线性、高维数、小样本以及局部极小点等问题。主要转换过程如下:

最终回归函数为:

式中:∅(x)为非线性映射函数;ω为超平面法向量;C为惩罚参数;b为超平面偏移量;ε为线性不灵敏损失函数;K(xi,yi)=∅(xi)∅(yi)是满足Mercer条件的核函数;ai和a*
i为二次规划中Lagrange乘子。SVM核函数的选择直接影响模型径流量预测结果好坏,高斯核函数是一种局部性极强的核函数,面对小样本数据可以使用较少的参数取得较好的分类性能,因此本研究选取高斯径向基核函数(radial)作为核函数。在此基础上,通过交叉验证网格搜索算法确定最优惩罚系数C与核函数参数γ。
1.3 多元自适应回归样条(Multivariate Adaptive Regression Spline,MARS)
多元自适应回归样条模型是一种非参数和非线性回归方法,其原理是进行局部回归建模,通过样条函数估算非线性模型的变化趋势,将数据整体划分为几个子区域,在每个特定的子区域,响应变量用线性回归进行拟合。MARS的优点是能够估算基函数的贡献,并通过模拟变量之间的交互影响和加性来确定对应变量。MARS把基函数作为基本单元,可表示为:

其中:hi(x)为第i个基函数,x为输入变量;c为输入参数的阈值向量。MARS的结构为:

其中:f(x)为输出结果;β0为初始常数;βi为第i个基函数的系数;m为基函数的个数;hi(x)为第i个基函数。
在建模过程中,模型使用常数值对目标变量进行估计,得到目标变量的平均值,根据最大基函数的个数m,所有可能的基函数都会加入到模型中,从而导致结果出现过拟合现象。为避免这一局限,通过遵循广义交互验证(Generalized Cross Validation,GCV)原则,识别重要性较低的基函数,并去除这些基函数,获得最佳MARS模型。

式中:N为数据总数;H为基函数的个数;d为惩罚因子。
实现基于MARS预测径流量的过程关键主要为惩罚因子d个数的选择,惩罚因子数量决定了基函数的个数,d越小,生成的MARS模型中基函数越多。d越大,被放置的节点数越少,函数就会更加平滑,但同时被排除在外的基函数也就越多。本研究通过反复训练模型,根据MSE最小原则确定惩罚因子个数。
1.4 贝叶斯模型平均(Bayesian Model Averaging,BMA)
BMA方法对单个模型进行加权平均,生成一个整体的概率分布函数(PDF),通过PDF集成不同模型的预测结果得到的更可靠的综合预测值[23]。该方法的基本原理为:
设y为径流模拟值,D=[d1,d2,…,dr]为径流实测值,f=[f1,f2,…,fk]为所取K个水文模型组成的模型空间。根据总概率法则,BMA模拟变量y的概率密度函数可以表示为:

其中:p(fk|D)为模型所模拟序列fk的后验概率,即在给定的数据条件下模型为最优模型的概率,反映了fk与实际径流量的吻合程度。实际上,p(fk|D)是BMA的权重ωk,预测精度越高的模型分配到的权重越大,并且本质上,BMA均值预测序列是对权重为ωi的不同模型的最优预测序列进行加权平均。pk(y|fk,D)是给定模型预测fk与数据D条件下的预测值Q的后验分布。BMA平均预测值与方差公式如下:
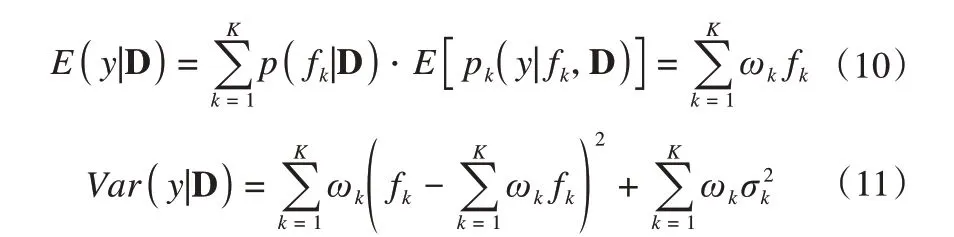
其中:σ2k为给定观测数据D和模型fk的条件下模拟变量的方差。BMA预测变量方差包括模型间误差和模型自身误差,式(11)中
本研究运用蒙特卡洛组合抽样的方法生成BMA在任意时刻t的预测值的不确定性区间[24]。步骤如下:
(1)通 过 单 一 模 型 权 重[ω1,ω2,…,ωk],在[1,2,…,K]中随机生成整数k以抽选模型。具体步骤为:①设累计概率=0,计算;②在0~1之间随机生成小数u;③若满足,则选择第k个模型。
(2)通过第k个模型在t时刻的概率分布随机生成流量值是均值为f t k,方差为的正态分布。(3)对步骤(1)(2)重复M次,M是任意t时刻的样本容量,本文M=10 000。
BMA在任意t时刻得到M个样本后,将样本从小到大排序,BMA的95%预测区间即为2.5%与97.5%分位数之间的部分。
BMA均值预测过程主要依赖于Zellner的g先验下的线性模型,为减少先验信息的主观性,本文将参数先验概率分布设定为单位信息先验分布(UIP)。参数先验概率分布设定完成,还需要设置模型先验概率分布,本文选取随机分布(Random Distribution)为先验概率分布。为减少对所有模型平均计算的繁杂过程,本文选取蒙特卡洛抽样方法抽取后验概率较高的模型。
2 研究区概况与模型构建
2.1 研究区概况
疏勒河发源于托勒南山与疏勒南山之间的沙果林那木吉木岭。疏勒河上游(图1)主要包含了出山口昌马堡以上的山区(96.6°~99.0° E,38.3°~39.9°N),流域面积1.14×104km2,涵盖了甘肃省酒泉市肃北蒙古族自治州县、青海省西蒙古族自治州天骏县等地区。地形上由托勒南山、疏勒南山以及疏勒河谷组成。河谷地区相对平坦,山区地势高大险峻、地形陡峭,海拔约在2 100~5 750 m,4 500 m以上广泛分布着现代冰川,冰川资源丰富[25]。
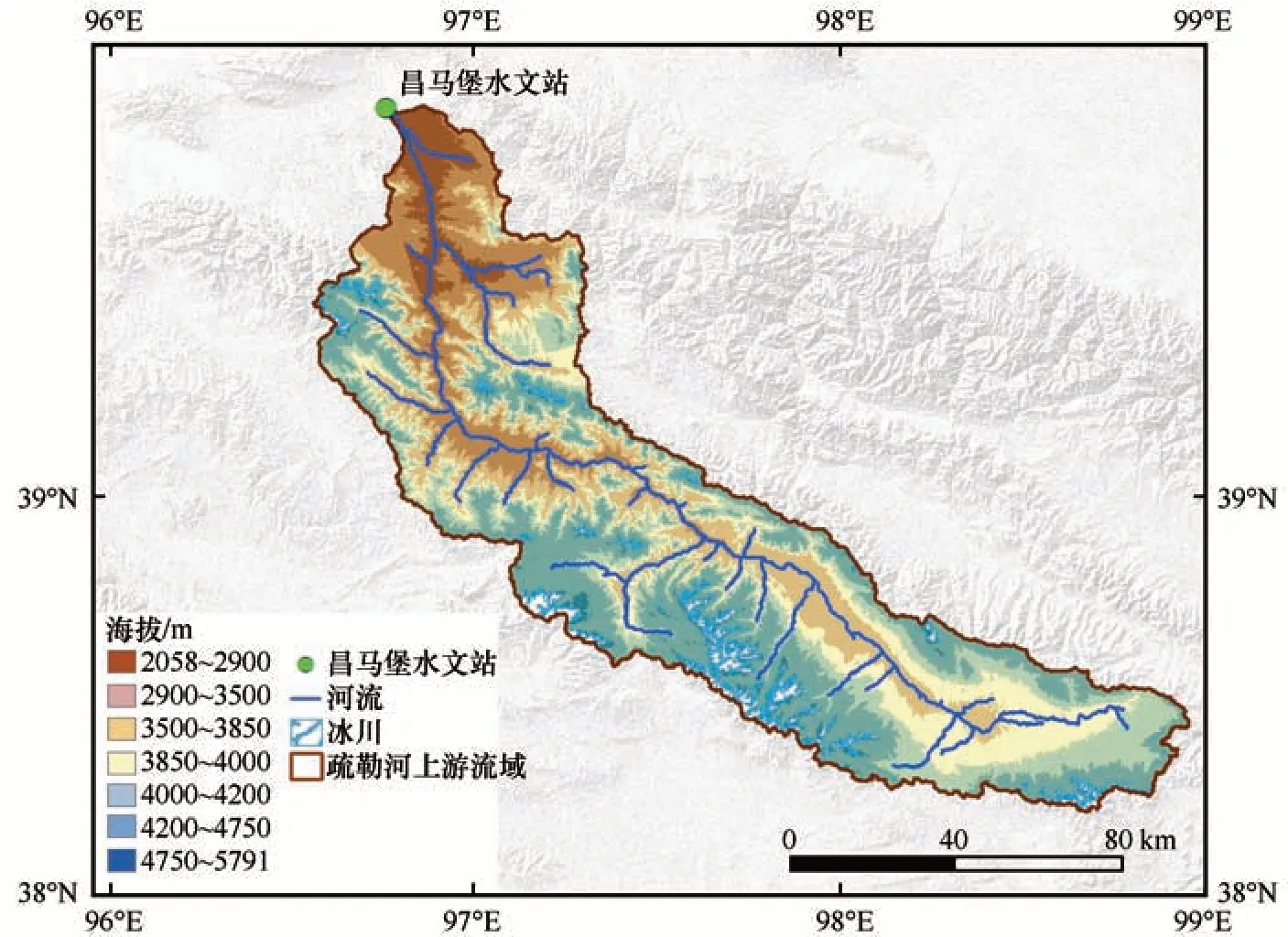
图1 研究区位置Fig.1 Location of the study area
疏勒河出山径流的年内分配差异较大,受气候影响,径流多集中在5月至9月,占全年径流量的80%左右,最大日径流可达415 m3·s-1,10月到次年4月径流量则明显偏少。其中,冬季降水常以固态形式存在,每年12月到次年3月日径流量较少,甚至无径流。4、5月气温逐渐回升,积雪和冰川融化使径流量增加,随之进入一年中降水最为集中的季节,加上高山冰雪融水的增加,7、8月份出山径流量达到最大值,10月之后随着气温的降低和暖湿气流影响的削弱,径流量逐渐减少[26]。
2.2 数据获取与处理
本文选用昌马堡水文站2010—2017年日径流量作为疏勒河出山径流分析数据。其中,2010—2014年数据用于模型训练,2015—2017年数据用于模型测试。疏勒河上游出山口径流量数据基本统计资料见表1。由表1可知,径流量数据呈现明显的高偏态分布(训练数据集为2.39,测试数据集为2.81),并且不同数据集日径流数据的变异系数均大于1,这可能会对预测精度产生一定的影响。为了保证对模型的有效训练以及有效特征的提取,通常对输入数据进行归一化处理。本文采用最小-最大归一化方法对径流数据时间序列进行归一化处理。公式为:

表1 昌马堡日径流量基本统计值Table 1 Basic daily runoff statistics of Changmapu

式中:Q*为经标准化处理后的径流序列;Q为原始径流序列;Qmin为原始最小径流量;Qmax为原始最大径流量。
2.3 模型构建
径流时间序列能够揭示其随时间变化的规律,并将这种规律延伸到未来。因此,径流时间序列可以作为径流预测的基本输入因素。本文通过计算2010—2017年实测日径流的自相关函数(ACF)和偏自相关函数(PACF)来确定模型的输入。如图2所示,径流时间序列的ACF与PACF均表现出拖尾特征,ACF逐渐衰减并在95%的置信区间内表现出明显的自相关性,特别是在时滞数小于5时,ACF大于0.8,表现出显著的自相关性。同时,PACF显著不为0的时滞数为1,2,3。因此,综合ACF与PACF分析结果,确定Qt-3、Qt-2、Qt-1为模型输入量。

图2 实测径流时间序列的ACF和PACFFig.2 ACF and PACF of measured runoff time series
构建一个包含7列数据的表格,表格形式为(Qt-3,Qt-2,Qt-1,Qt+1,Qt+3,Qt+5,Qt+7),其中,Qt-3、Qt-2、Qt-1为输入变量,分别表示t-3、t-2、t-1日的径流量组合;Qt+1、Qt+3、Qt+5、Qt+7表示模型在t+1、t+3、t+5、t+7日的预测径流量,即模型的输出。
对于单一模型的构建主要分为两部分:第一部分为确定模型的输入向量;第二部分为利用确定的输入向量设置模型运行的最优基本参数,建立中长期日径流预测模型。对于BMA组合模型的构建,主要是利用各模型后验概率将单一模型的预测结果组合起来得到集合预测结果,建立中长期日径流组合预测模型。此外,本文采用马尔科夫蒙特卡洛抽样对集合预测结果进行10 000次抽样,获取集合预测结果的95%置信区间,对预测结果进行不确定性分析。为验证BMA集合预测的有效性,在相同预见时间的条件下,与单一ELM、SVM、MARS模型进行对比研究。本文主要研究技术路线如图3所示。

图3 研究技术路线Fig.3 Research technical route
2.4 模型评价指标
模拟效率可体现模型在研究区的适用情况,本文选取相关系数R、纳什效率系数NSE(Nash-Sutcliffe efficient)以及均方根误差RMSE(Root-Mean-Square Error)对预测结果进行评价,表达式如下:
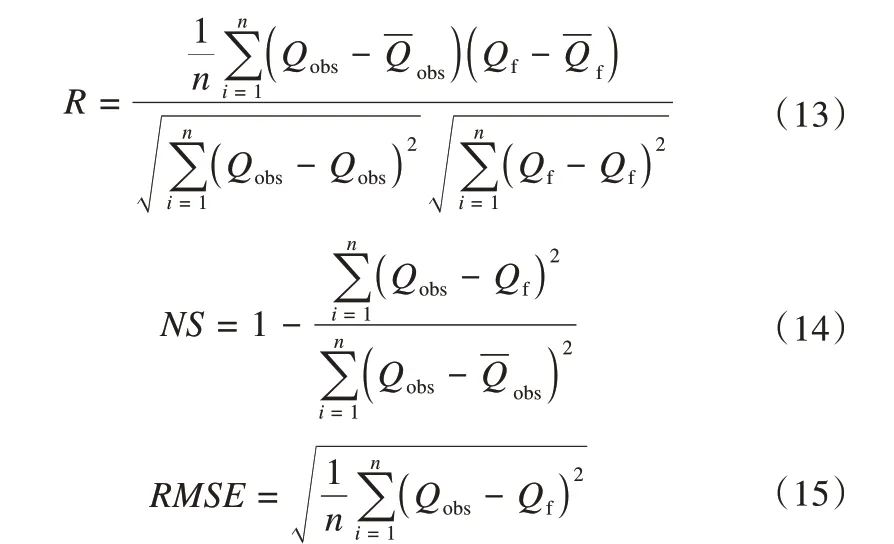
式中:Qobs为实测值(m3·s-1);Qf为预测值(m3·s-1);为实测均值(m3·s-1);为预测值均值(m3·s-1);n为实测数据数量。
R是判断实测值与预测值的线性相关程度。R取值范围是-1至1,R的绝对值越接近于1,线性相关程度越高;NSE代表预测值与实测值在1∶1水平上的相似度,NSE在-∞至1.0之间取值,NSE≥0.5时预测结果可接受,NSE越接近1,拟合效果越好;RMSE反映预测值与实测值之间的偏差,该值越接近于0,模型的拟合度越高。当R=1、NSE=1、RMSE=0时,认为该模型为最佳模型[27]。
评价预测结果的不确定性区间的优良性可以体现模型的可靠性。本文采用覆盖率(CR)、平均带宽(B)以及平均偏移幅度(D)三个主要指标来分析比较BMA的不确定性区间[28]。

覆盖率是评价模拟区间最常用的指标,指预测区间所覆盖的实测流量数据的比率。CR值越大,表明模拟区间的覆盖率越高,预测结果包含的真实信息越多;平均带宽B是在指定的置信水平,以及较高的覆盖率保证的前提下,预测区间的平均带宽越窄预测区间的不确定程度越小,反之,预测的不确定性程度越大;平均偏移幅度D是评价预测区间的中心线相较实际径流过程线偏离程度的指标,理论上,平均偏移幅度越小,表明预测区间的对称性越好。
3 结果分析
3.1 单一模型预测精度分析
为了验证单一模型预测的有效性,表2~4给出了最优参数下三个单一模型在不同时间的预测结果评价。由表2~4可知,随着时间的增加,三个单一模型的预测精度逐渐降低。但总体上三个单一模型的预测值与实测值的R值均在0.75以上,表明预测值与实测值之间存在着很高的线性相关关系。NSE值均在0.55以上,说明预测值与实测值之间的拟合程度是可以接受的。因此,说明所构建的单一模型的预测结果合理、有效,可以作为BMA集合预测的有效成员。

表2 ELM模型参数及预测结果评价Table 2 Parameter and evaluation of prediction results of ELM model
3.2 BMA均值预测与单个模型的预测值对比
本研究得到的BMA方法在测试期的(t+1)d、(t+3)d、(t+5)d与(t+7)d的预测结果如图4与表5所示。通过水文过程曲线可以看出(图4),BMA的整体预测效果比较好,预测值与实测值变化趋势一致,洪峰出现时间同实际观测情况一致。BMA对径流低值的预测结果较好,但对径流高值的预测有一定的误差,并且随着预测时间的增加,峰值预测误差逐渐增大。这被认为是目前径流研究工作中的一个重要局限性,在其他径流模拟预测研究中也出现了同样的局限性[9-10]。尽管如此,从散点图可以看出,BMA在(t+1)~(t+7)d上的中长期日径流的R均大于0.8,表明预测精度是可以接受的[29]。另外,由表5可知,BMA的预测精度随着预测时间的增加而逐渐减小,但BMA在(t+1)~(t+7)d的R值均大于0.78,表明BMA的预测值与实测值之间存在较高的线性相关关系;NSE值均大于0.6,表明预测值与实测值之间的拟合效果较好。综上,说明BMA可以用于(t+1)~(t+7)d的中长期日径流预测,并具有较高的预测精度。然而,BMA在(t+1)d后训练期的R值不如测试期的R值,而训练期的RMSE值却优于训练期。由表1可知,训练期的变差系数高于测试期,训练期数据离散程度大,导致训练期R值低于测试期;而测试期数据的偏度大于训练期,分布不均匀,产生的较大误差。

表3 SVM模型参数及预测结果评价Table 3 Parameter and evaluation of prediction results of SVM model

表4 MARS模型参数及预测结果评价Table 4 Parameter and evaluation of prediction results of MARS model

表5 BMA在(t+1)~(t+7)d日径流量预测结果评价Table 5 Evaluation of daily runoff predicted results of BMA in(t+1)~(t+7)days
由表2~5可知,BMA与组成BMA的3个单一模型均可适用于(t+1)~(t+7)d的中长期日径流预测,但进一步对比分析可知,BMA的预测结果较单一模型具有更高的预测精度。以训练期和测试期的(t+1)d与(t+7)d预测结果为例,训练期(t+1)d时BMA的R值均为0.979,高于SVM(0.971)ELM(0.959)和MARS(0.972)的R值。BMA的NSE值为0.982,高于单一ELM(0.919)、SVM(0.919)、MARS(0.944)的NSE值。BMA的RMSE值较单一ELM、SVM、MARS的RMSE值 分 别 提 高 了28.35%、26.08%、13.77%。在训练期(t+7)d时,BMA与MARS的R值(0.786)相同,高于单一ELM(0.781)和SVM模型(0.778)。BMA的NSE值为0.618,分别高于三个单一模型的NSE值(ELM为0.610、SVM为0.595、MARS为0.612)BMA的RMSE值较单一ELM、SVM、MARS模型分别提高了4.79%、7.17%、4.58%。
在测试期(t+1)d时,BMA与SVM的R值相同(0.967),较ELM、MARS的R值 分 别 提 高 了1.83%、0.6%;NSE值较单一ELM、SVM、MARS模型分别提高了3.7%、3.1%、0.3%;RMSE值较单一ELM、SVM、MARS模 型 分 别 降 低 了33.7%、25.8%、3.8%。在测试期(t+7)d时,ELM、SVM、MARS的R值分别为0.781、0.783、0.781,BMA的R值 为0.800,高 于 单一模 型。BMA的NSE值为0.64,较单一模型ELM、SVM、MARS的NSE值分别提高了5.8%、9.1%、5.6%。另外,ELM、SVM、MARS的RMSE值分别为35.548、36.494、35.503,均大 于BMA的RMSE值33.878。因此,综合R、NSE、RMSE的评价结果可以看出,BMA较单一模型无论是在(t+1)~(t+3)d的短期日径流,还是在(t+5)~(t+7)d的中长期日径流预测均具有较高的预测精度,能够提供更准确的预测结果。
对不同等级的径流量进行预测对及时发布极端水文事件预警信息以及制定防治预案具有重要意义。本文参考董磊华等[18]研究成果,根据疏勒河的径流量特征,将径流量分为3个等级:流量从大到小排序,将前10%的大流量定为高水,中间50%的流量定为中水,后40%的小流量定为低水。对比分析BMA与单一模型ELM、SVM、MARS在不同等级径流量的预测结果(表6)。从表6可以看出,BMA与单一模型对中水预测效果最好,BMA与单一模型均可预测出未来5~7 d中水径流量;低水次之,除单一SVM模型可以预测未来3日的中水径流量,其余模型均只能预测未来1日低水径流量;高水最差,仅BMA与SVM模型能预测未来1日的高水径流量。但相比之下,BMA较单一模型的预测效果更好,这是因为BMA方法综合发挥了单一模型各自的优势,在一定程度上克服了单一模型无法避免的局部极值问题[28]。
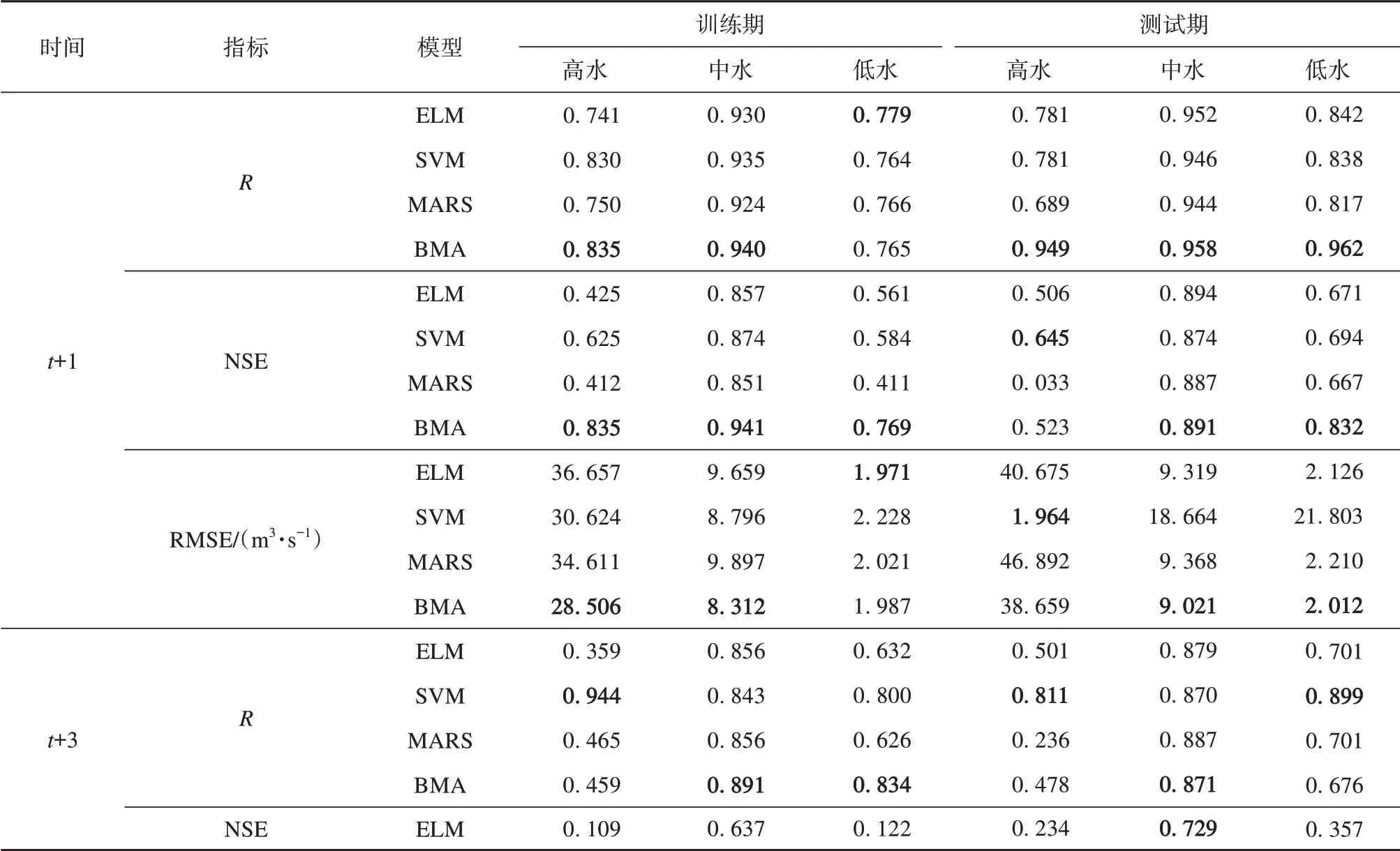
表6 BMA和组成它的3个模型的预测值在3个不同流量等级的统计结果Table 6 Statistical results of BMA and the forecast values of the three models that comprised it at three different flow levels

续表6
3.3 BMA径流预测不确定性分析
对预测结果的不确定性分析可以判断模型结构的可靠性,对提高水资源管理的科学性、极端水文事件风险防范能力具有重要意义[29]。本文基于覆盖度(CR)、平均区间宽度(B)以及平均偏移幅度(D)3个指标对BMA的95%置信区间的径流预测结果的不确定性进行分析。从图4可看出,大多数实测值都在不确定性区间之内,测试期内BMA在(t+1)~(t+7)d的95%置信区间的覆盖度分别为达到了94.7%、94.1%、93.8%、92.9%,几乎覆盖了整个实测径流序列,表明95%置信区间预测效果好,不确定性较小。
由于BMA对高水和低水的预测出现了较大偏差,存在较大的不确定性。因此,为进一步研究模型结构的不确定性,对每个等级径流预测结果进行评价。表7综合了BMA在3个不同流量等级的预测区间优良性,可以看出BMA预测区间覆盖了整个低水部分,中水部分除在(t+7)d时刻上覆盖率较低,其余时间均在95%以上。但是测试期与训练期在高水部分的覆盖率均不足65%,其中测试期(t+7)d的高水部分最低覆盖率仅43.52%,拉低了整体覆盖率。同时,BMA 95%置信区间的平均带宽在低水部分最小,在高水部分最大,表明BMA在高水部分的预测不确定性更大。就平均偏移幅度来说,BMA在高水部分的平均偏移幅度最大,中水部分最小,说明BMA在高水部分的预测值偏离实测值的程度最大,中水部分的预测值偏离实测值的程度最小。综上,BMA的预测不确定性主要来源于高水部分,主要原因在于高水一般出现在汛期,径流量受降水、融水影响较大,预测难度较大,因此高水预测的不确定性较大。另外,各流量等级的区间不确定性均随着时间增加而增大。但总体而言,BMA的95%置信区间效果良好,对实测径流量覆盖率高。

表7 BMA 95%在3个不同流量等级的统计结果Table 7 Statistical results of BMA 95%confidence interval at three different traffic levels
4 讨论
李洪源等[30]在运用分布式水文模型SPHY对疏勒河上游径流进行了逐日与逐月径流预测,并取得了较好的预测精度。但SPHY在率定期的日径流NSE值为0.62,低于本文BMA在训练期(t+1)d的NSE值0.943。SPHY在测试期中的日径流的NSE值为0.79,低于本文BMA在测试期(t+1)d的NSE值(0.935),表明BMA方法具有较高的精度,这可能是因为BMA方法通过对各单一模型的后验概率进行加权平均,有效解决了单一模型的不确定性,把多个单一模型的优点组合起来,从而获得了更准确的预测值。
本文通过计算径流的ACF与PACF确定模型的输入,但如何利用径流本身的自相关关系确定模型输入暂无统一标准。对于自相关关系差的小流域来说,可以针对流域自身特点来确定模型的输入。如于海姣等[31]在对小流域排露沟日降水-径流模拟研究中,针对降水-径流的非线性关系,选择相对百分比误差方法来确定模型的输入。Gavin等[32]根据输入与输出之间的显著线性关系,运用互相关法确定模型输入,对澳大利亚Murray河流的含盐量进行模拟。
BMA方法通过集成各个模型的自身优势,弥补单个模型的不足获得较单一模型更高的预测精度。在疏勒河上游流域(t+1)~(t+7)d的中长期日径流预测中,BMA方法较单一模型的预测效果更好,精度更高,为缺乏资料的干旱半干旱地区的径流预测提供了有效的预测工具。但是,BMA在中长期日径流预测中仍然存在着一定的不足。BMA在高径流量和低径流量预测上表现出较单一模型更高的精度,但是预测值仍然小于实测值,存在着较大的误差。误差原因可能是:疏勒河上游流域冰川积雪、冻土分布广,由此形成了独特的寒区水文过程,流域内的温度、蒸发、冻融作用都是影响高径流量时期径流变化的重要因素,所以,只将径流数据作为模型输入过于单一,导致预测序列出现偏差[31,33]。低径流时期的径流量数值较小且存在0值,经归一化处理后的径流数据产生较多的0值,导致模型在运行过程中出现一定的误差[31]。因此,在日后的工作中可以尝试从增加模型输入、优化模型参数计算等方面提高模型预测精度,更真实地反映径流变化规律。
5 结论
本文利用BMA方法对疏勒河上游2010—2017年的(t+1)~(t+7)d中长期日径流进行了预测,对BMA与组成BMA的ELM、SVM、MARS模型的预测结果进行分析对比,并对BMA预测结果的不确定性进行定量分析。得到以下结论:
(1)BMA在(t+1)~(t+7)d的径流预测结果比单一ELM、SVM、MARS结果准确度更高,不同时期径流量的预测值与实测值的相关系数均在0.7以上,纳什系数均在0.55以上,能够再现径流量的变化趋势,说明BMA方法具有较好的实用性,在中长期日径流预测中可以提供更准确的径流量预测值。BMA对高水、低水的预测值与实测值的相关系数、纳什系数在(t+1)d后均低于0.5,但仍较单一模型保持较高精度。
(2)贝叶斯模型加权平均(BMA)方法是一种通过综合多个模型预测结果的后验分布来推断预测结果的可靠概率分布分析的工具。BMA对(t+1)~(t+7)d的95%置信区间实现了对低水径流量的100%全覆盖,对中水径流量的覆盖率在70%以上,对高水径流量的覆盖率较低,但整体覆盖率均在90%以上。表明BMA不仅可以提供更准确的综合预测结果,还能提供一个综合预测区间来进行模型结果不确定性分析,可成为资料有限条件下的径流模拟预测的有效工具。
