万维网环境下涉灾信息数据采集方法研究
2022-11-15邓雨婷胡卓玮胡一奇
邓雨婷,胡卓玮,胡一奇
(1.首都师范大学资源环境与旅游学院,北京 100048;2.首都师范大学资源环境与地理信息系统北京市重点实验室,北京 100048;3.首都师范大学城市环境过程与数字模拟国家重点实验室培育基地,北京 100048)
引言
中国是灾害频发的国家,如何对突发灾害进行预防、处置是一个重要的研究领域[1]。涉灾数据在灾害发生的各个阶段都起着至关重要的作用[2],专家学者在进行分析研究和制作相关产品时需要用到大量的涉灾信息数据,因此涉灾数据的获取与集成逐渐成为该领域的研究热点问题。
传统的涉灾信息数据获取方式单一,一般由国家部门统一发布。随着步入互联网时代,万维网逐渐成为大量信息的载体。多方以万维网为载体发布涉灾信息数据,使得数据获取呈现多源化的特点。在灾害防治业务工作中,如何从这些海量数据中高效快速的获取防灾减灾需要的相关信息,为防灾减灾工作服务十分重要[3]。
随着涉灾信息数据的网络化和多源化,问题也随之而来:(1)各数据平台灾种单一,如我国相关行业部门建立的地震、地质灾害等平台,此类数据平台通常数据较为详实,但不涉及其他灾种[4]。导致单一平台难以为应急管理相关决策制定或灾害综合分析提供丰富、充足的信息数据支持。(2)数据难以直接获取,各个网站相互独立且数据格式、网页编写规则各不相同。有的网站提供了专门API外部接口供人获取数据,但大多数没有提供专门的外部接口,而仅以网页形式供人阅览。这导致跨平台、多领域、多灾种涉灾信息数据难以直接获取。此外,一些网页中还包含许多目标信息外的混合信息。因此,如何有效地提取并收集这些网页中的信息成为研究的关键。
基于上述背景,文中提出了一种面向万维网的多源涉灾信息数据采集方法,可以充分利用互联网时代提供的数据优势,自动准确地抓取互联网上的涉灾数据和涉灾信息并将其存储在数据库中,为数据分析提供跨领域、多灾种、方便获取、长期真实、实时更新的数据源。
1 技术框架设计
文中将采集对象分为涉灾数据和涉灾信息,信息和数据同样重要。采集的万维网涉灾数据主要应用于科学研究,为保证数据的真实性、准确性,选用国家部门、行业单位和较权威的社会机构的官网作为起始url,设计网络爬虫对万维网中的数据进行抓取。技术框架如图1。
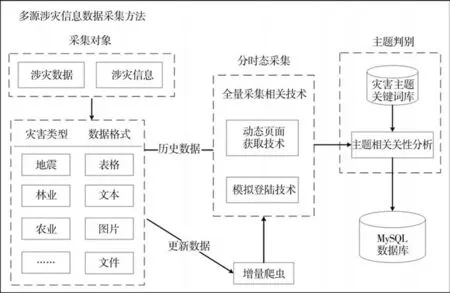
图1 多源涉灾信息数据采集方法技术框架Fig.1 Technical framework of multi-source disaster information data aquisition method
灾害信息涉及国土、地质、水利和气象等部门的不同来源的多源、多时态数据[5]。分析灾害相关网站的网页,发现其以动态页面为主且有些网站需进行登录,因此采用动态页面获取技术获取加载后的网页源码,结合模拟登陆技术进行网站登录,使得数据能够被完整、准确的抓取,且抓取效率最大化。考虑到数据具有时效性强的特点,将数据源分为历史数据与更新数据。历史数据量较大且需全量获取,更新数据则使用增量爬虫,以保证数据的及时获取与更新。其中涉灾数据为灾害监测数据,涉灾信息以新闻为主。新闻是信息传播的重要媒介,但大型综合类新闻网站并没有专门的灾害板块,因此在综合性很强的网站中获取信息时需要对信息有所筛选和过滤。将采集的信息通过主题判别过滤无关信息。涉灾数据和涉灾信息均存储入MySQL数据库中。
2 分时态采集涉灾信息数据
数据采集是文中研究的重点,为简化开发配置,爬虫依托Scrapy框架构建。由于涉灾信息数据具有多来源、多结构的特点,导致其采集有几方面的问题:(1)网页结构多样,获取数据具有一定难度;(2)由于有些灾害信息注重时效性,涉灾信息数据会不定时更新,需处理好全量数据和增量数据的获取关系。
针对上述问题,提出了全量采集和增量采集策略。
2.1 全量采集
2.1.1 动态页面获取
网页可分为静态页面和动态页面两种类型。在抓取数据时,动态页面无法获取完整的网页源码,因此需要进一步分析请求或使用专业工具。Selenium是一个基于网络爬虫的浏览器自动化测试框架,可模拟人工操作自动化,提供对多种浏览器的支持[6]。
在进行涉灾信息数据相关页面请求时添加Selenium技术,Selenium中的WebDriver组件对浏览器原生的API进行封装,形成一套面向对象的API。用户通过该API可以编写代码对网页元素进行点击、滚动等操作,并直接获取Ajax技术、动态HTML技术和JavaScript渲染后的代码,方便进行后续的元素定位及抓取。
2.1.2 模拟登录
有些网站需要进行用户登录,包括账号、密码、验证码等,一些验证码逻辑复杂导致代码冗余量大。模拟登陆通过增加cookie池将模拟登录单独做成一个服务,达到服务分离、组件分离、服务分别部署的目的,使得代码耦合性降低,程序更加便利和灵活。
整体流程为cookie池产出cookie存储入数据库(类型自选),进行数据采集时随机从数据库中获取cookie进行登录。由于cookie不是长期有效的,因此需要设置cookie检测服务,及时清除失效cookie。需根据具体采集数据量需要,定义cookie池的容量。由于cookie池中存储多个网站,所以需对网站进行管理。cookie管理器起到多网站管理及调度的作用,把需要的网站经管理器进行注册,以有针对性的对网站运行和定时检测,同时设立线程池便于多个网站同时运行(图2)。
不同的网站登录逻辑不同,因此要开发一个通用并统一配置的cookie池接口,便于新加入的网站快速的接入系统。通过设置抽象基类以保证每个网站接入时按照指定的规范来实现特定的方法。
2.2 增量采集
由于有些涉灾信息数据更新频繁会产生增量数据,因此需设置增量爬虫便于及时抓取更新数据。增量爬虫在设计时需考虑2种情况:一种是正在全量抓取历史数据时有更新数据;另一种是历史数据已抓取完毕后有更新数据。由于scarpy-redis有去重的功能,所以可以分辨出增量数据,增量爬虫中所涉及到的两种情况都可以通过修改scarpy-redis源码完成。
针对第1种情况,可以使用优先级队列,将队列类型设置为PriorityQueue,由于增量数据一般会出现在首页或者末页,因此根据数据更新的大致频率,通过自定义脚本嵌入至enqueue_request中,实现每间隔一段时间就将增量数据所在页面的url插入队列中,并将优先级设置的较高,以便于及时发现并优先抓取新数据,而后再继续抓取历史数据。针对第2种情况,scarpy-redis可以在队列为空的时候进行等待,使得爬虫不会关闭,及时发现增量数据并进行抓取。
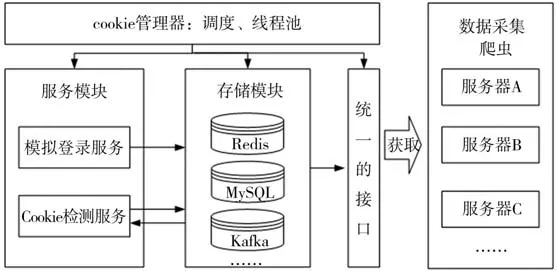
图2 动态数据获取中的模拟登录Fig.2 Simulated login in dynamic data acquisition
3 主题相关性判断
新闻为信息的重要载体,新闻内容包括救援信息、灾情报道、科普文章、政府报告、人文关怀和防灾演习等丰富的涉灾信息。在面向海量的网络信息时需通过主题相关性判断筛选出涉灾信息,确保获取信息的纯粹性。主题词库是判断信息是否与灾害相关的重要工具,由于目前没有针对灾害领域的关键词库,因此文中采取计算机和人工相结合的方式进行关键词提取,形成灾害主题词库。
通过网络爬虫和人工搜集的手段对中国地震局、天气网、中国农业信息网等灾害相关官网的新闻报道进行收集形成语料库。由于新闻标题含有主要信息,因此采用信息熵的方式对语料库中标题进行关键词提取,词A信息熵的计算公式为:

其中,w为词A出现的频率。当一个词语左右搭配越丰富,说明该词汇为关键词的可能性越大,因此一个词左右搭配词的信息熵越大,则认为该词为关键词的可能性就越高。
所选取的关键词既要有主题代表性,又要减少误判的概率,通过计算机提取的关键词并不完备,因此结合人工的方式对关键词进行补充和调整。一些关键词具有歧义,如“台风”既可以表示自然灾害,又可以理解为人的舞台表演风格,这种词会降低主题判断的准确性。为了使采集的信息更准确,对词库进行进一步改进,将主题词分为一级关键词和二级关键词。一级关键词为强相关无歧义关键词,单词即可实现灾害主题判断。二级关键词为次相关或有歧义关键词,须通过组合的形式对主题进行判断,当标题中出现2个及以上的二级关键词,才判断其与主题相关进行采集。灾害主题关键词库如表1。
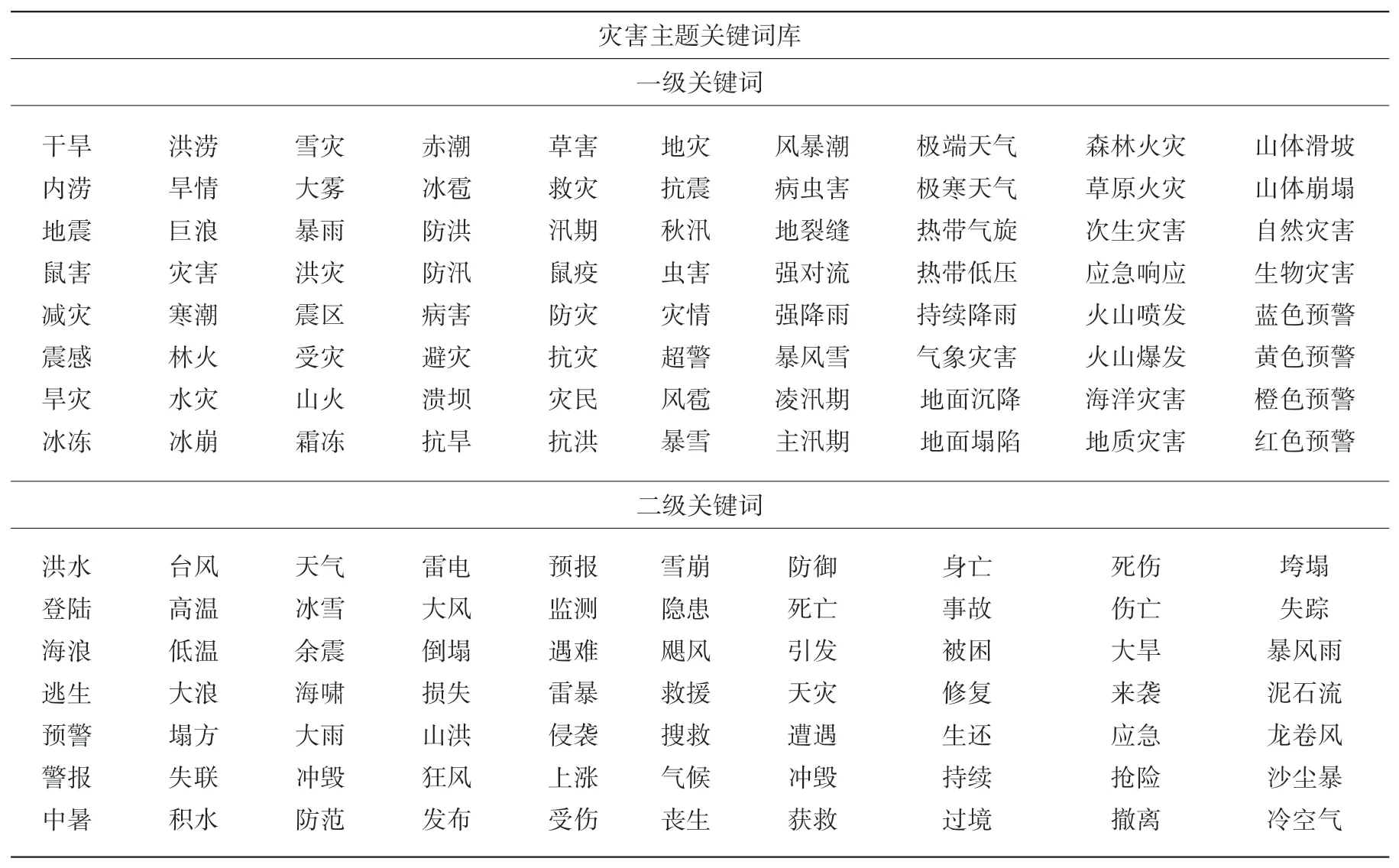
表1 灾害主题关键词库Table 1 Keyword thesaurus of disaster theme
采集新闻标题后,将灾害主题关键词库中的词语加上词性形成用户自定义字典,用以辅助标题的中文分词。将标题分词后形成的词序列先与一级关键词进行比较,若含有关键词则直接抓取,若不包含一级关键词则进行二级关键词判断;标题中若包含超过设定阈值的二级关键词则与主题相关,进行抓取保存,否则舍弃。通过两级主题判断后主题相关性进一步提高。
4 方法应用实验
由于文中的采集对象为涉灾数据和涉灾信息,因此针对不同对象分别展开采集实验。由于我国地震灾害频发,有专门的网站发布和管理地震数据,使得地震历史数据较多且数据更新及时,在涉灾数据中具有代表性,因此文中实验以中国地震局的地震监测数据为例。涉灾信息以新浪新闻为例。
4.1 涉灾数据采集
中国地震局为我国国家官方网站,其历史数据时间跨度从2001年5月至今,共11 150条监测数据,并且随着新的地震事件的发生而不断增加。由于监测数据多以表格的形式展示在灾害相关的网站上,因此不需要进行主题判断,直接进行全量采集和增量采集即可。由于其历史数据量较大,在全量采集时花费了较多的时间。考虑到地震的时效性较强,因此设置每分钟访问网站,并判断数据是否有更新。经实验,可以较好的实现地震数据的采集。采集效果图如图3。

图3 国家部门地震监测数据采集实现效果Fig.3 Implementation effect of earthquake monitoring data aquisition in national departments
4.2 涉灾信息采集
新浪新闻为我国较大的新闻媒体平台,涵盖领域较广,提供信息丰富且信息较为可靠。经过信息重要程度的考虑最终选取发布时间、新闻标题、新闻链接、发布媒体和新闻内容5个字段进行采集。设定全量采集新浪新闻前100页新闻,并进行主题判断。由于新闻中涉灾信息相对其他信息较少,因此增量采集设定时间不用非常频繁。通过实验可以发现采集的信息主题相关度非常高,极少有与主题不符的情况。采集效果如图4。
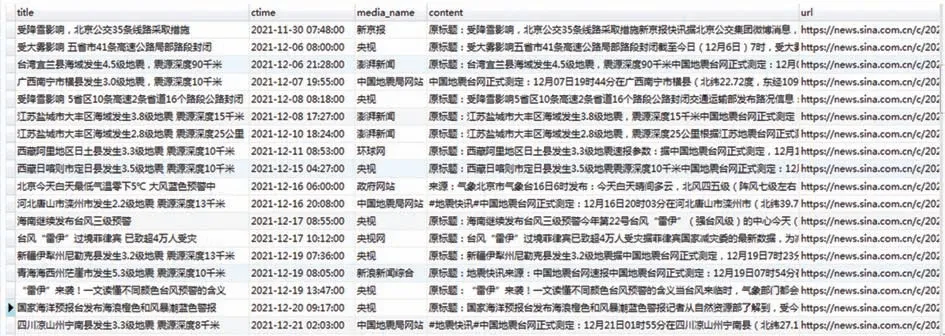
图4 新闻媒体涉灾信息采集实现效果Fig.4 Implementation effect of disaster related information aquisition in news media
5 结论
文中以万维网为载体的国家部门、较权威的新闻媒体的涉灾信息数据服务为采集对象,在充分研究网页结构和涉灾信息数据特点的基础上,阐述了全量采集与增量采集的技术要点,并针对灾害领域建立了灾害主题关键词库用以进行灾害主题相关性判断,保证采集信息的主题纯粹性。实验验证了涉灾信息数据采集方法的效果,较好地采集了监测数据和涉灾信息。有效解决了信息混杂、不易获取的问题,使得涉灾信息数据采集策略更加清晰和更易实现,为灾情评估、灾害相关产品制作、应急管理计划制定等研究提供了数据采集技术支持,为搭建涉灾信息数据采集及共享平台提供了新思路。
文中的主题相关性判断方式目前适用于标题这种短文本中,对于没有标题,只有内容的长文本信息适用性较低。长文本主题判断还需进一步研究。同时文中只针对网络涉灾信息数据进行采集,涉灾信息数据采集的对象还有待扩展和提高,现实中国家各部门有一些数据并不予网络呈现,这些部门数据在应急管理、防灾减灾中也具有十分大的应用价值,因此部门也可以作为一种数据来源。如何打破各部门间的壁垒,使得数据能被获取、共享并保证数据传输过程中的安全性和保密性,还需在国家的支持和专家的研究下共同解决。
