结合纹理和多注意力机制的深度人脸伪造检测
2022-11-15赖振强黄丽清黄添强罗海峰
赖振强,叶 锋,2,3,黄丽清,2,3,黄添强,2,3,罗海峰,2,3
(1.福建师范大学计算机与网络空间安全学院,福建 福州 350117;2.数字福建大数据安全技术研究所,福建 福州 350117;3.福建省公共服务大数据挖掘与应用工程技术研究中心,福建 福州 350117)
深度人脸伪造是指利用深度学习技术对人脸图像进行篡改伪造,根据李旭嵘等[1]和王任颖等[2]的综述,深度伪造技术可以分为人脸交换和面部重演.由于生成对抗网络技术的发展,生成的人脸图像越来越逼真,肉眼难以分辨,如图1.该技术的使用门槛极低,人们很容易使用这项技术对图像和视频进行篡改,导致了深度人脸伪造技术的滥用.2017年,一名用户将色情视频女主角的脸替换成某女明星的脸并发布在Reddit社交平台;2018年,BuzzFeed发布了奥巴马的deepfake演讲;2019年,国内的“ZAO” APP利用该项技术进行AI换脸供大众娱乐,后来因为侵犯隐私等原因被下架[3].如果任由此类视频在互联网上传播,将会产生舆论失控和信任危机等诸多问题,因此,迫切需要高效的深度人脸伪造检测方法.

图1 不同篡改方法的样例
为了解决深度人脸伪造带来的问题,近年来,研究人员不断致力于开发各种检测方法来识别伪造视频和图像.Fridrich等[4]利用手工提取的隐写特征和SVM进行检测.Cozzolino等[5]在手工提取的隐写特征的基础上结合CNN分类网络进行检测.Bayar等[6]则使用带约束卷积的网络进行检测.Rahmouni等[7]使用带最大池化的不同CNN网络来计算均值、方差、最大值和最小值4种统计量进行检测.此类主要基于传统方法的检测精度都较差.为了获得更准确、更高效的深度人脸伪造检测模型,Rössler等[8]使用MesoNet网络[9]和带可分离卷积的Xception网络[10]来检测视频中的人脸篡改.Yang等[11]利用多尺度的纹理差异信息进行检测.Li等[12]通过显示图片中是否存在伪造边界的方法进行深度伪造检测.Masi等[13]使用双分支模型进行深度伪造检测.Liu等[14]利用真实人脸和伪造人脸之间在相位谱中的差异,结合深度学习进行篡改检测.上述利用深度学习技术的方法可以实现更佳的检测性能.为了进一步提升人脸伪造检测的效果,本文利用纹理和注意力机制进行检测.
2019年,Zhang等[15]发现深度伪造过程中的上采样操作会产生伪影,可以被网络捕捉并识别真假,并且伪影和区域不一致性在纹理信息中更显著.Liu等[16]研究发现原图和对抗网络生成的人脸图像之间纹理信息统计存在较大差异.基于上述发现,本文提出基于纹理增强和注意力机制的方法进行深度伪造检测.首先,为了提取包含丰富伪影的特征,引入图像分解技术提取图像的纹理部分.其次,结合注意力机制增强纹理信息,然后与相应的图像信息进行融合达到纹理增强的目的.为了消除网络中的噪声等无用信息的影响,在网络结构中设计了一个多注意力机制,让网络关注更加重要的部分,最后使用一个二分类器对网络提取的特征进行真假分类.为了证明本方法的有效性,进行了大量对比实验和消融实验,结果表明,本文设计的各个模块都可以提高深度人脸伪造检测性能,并且优于其他检测方法.
1 研究方法
本节提出了一个基于纹理增强和注意力的网络结构,主要包含3个部分:图像分解模块(IDM)、注意力引导纹理增强模块(AGTE)和多注意力模块(MAM).
1.1 总体框架
所提算法的总体流程如图2所示,If表示输入图像,大小为H1×W1×C1。其中,C1是通道数,H1和W1分别表示高度和宽度.然后,利用图像分解技术获得输入图像If的纹理信息It,大小为H1×W1×C1,其中包含丰富的伪影信息可用于深度人脸伪造检测.再将纹理信息输入AGTE模块,通过注意力块获得注意力图A用于指导纹理增强,与相应的空间域信息融合作为主干网络的输入.对于主干网络初期的特征图,应用MAM强迫网络专注于更重要的人脸区域,从而提取出更具代表性的特征.最终提取语义特征g用于分类.

图2 基于纹理和注意力机制的网络结构图
1.2 图像分解模块(IDM)
在深度伪造检测领域,纹理特征的差异对检测具有重要意义.为了获取纹理信息,将图像分解算法引入深度伪造检测领域.通过图像分解技术,可以将图像If分解为内容部分Ic和纹理部分It,如下式:
If=It+Ic.
(1)
本文采用非凸低秩纹理正则化方法[17]对图像进行分解,该方法通过最小化问题(2),同时考虑了纹理分量It的自相似性和内容分量Ic的分段光滑性.
(2)
其中,α和β为平滑参数,Φt和Φc分别表示纹理分量和内容分量的正则化项,其表示如下:
(3)
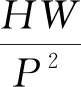
为了解决问题(2),引入交替方向乘子法(ADMM),得到分离后的2个子问题.
对于Ic子问题:
(4)
对于It子问题:
(5)
采用交替迭代法求解上述2个子问题(4)和(5),如图3.首先输入人脸图像If,设置超参数α、β,迭代次数MaxIt设为50,每次循环依次优化公式(4)和(5),最小化内容部分Ic和纹理部分It,最后根据公式(1)得到人脸图像的纹理分量.流程见算法1.

算法1:图像分解算法输入人脸图像If步骤1:设置参数α、β,初始化k=0,MaxIt=50步骤2:循环步骤3:优化公式(4)步骤4:优化公式(5)步骤5:k = k + 1步骤6:判断循环终止条件:k = MaxIt步骤7:根据公式(1)输出人脸图像的纹理部分It

图3 图像分解示意图
1.3 注意力引导纹理增强模块(AGTE)
真实人脸和伪造人脸之间的纹理有很大的差异,但是用肉眼难以分辨纹理差异,因此对输入图像的纹理信息进行增强.将纹理部分It输入到注意力块中,获得像素级纹理增强的权重注意力图A,用于引导纹理增强,其大小为H1×W1×1.如图4所示,设计的注意力块是一个轻量级的模块,包含2个卷积层、2个批归一化层和1个Sigmoid非线性激活函数层.本实验纹理增强只对图像的纹理信息增强,因此,根据公式(6)将纹理信息和空域信息进行直接融合,从而达到纹理增强的目的.
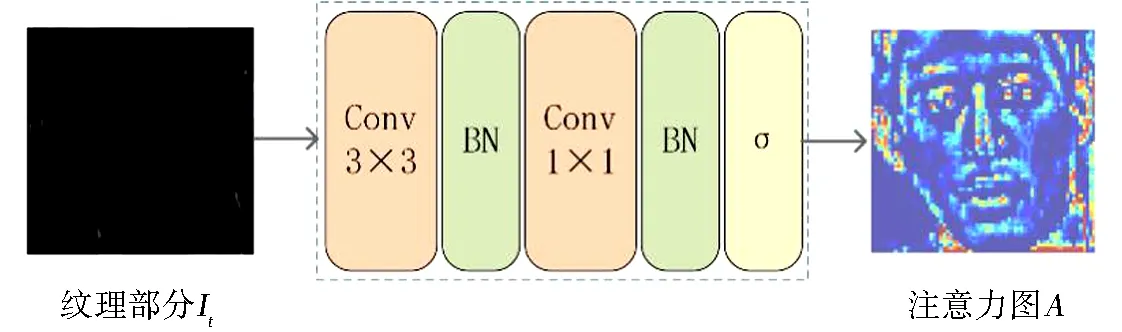
图4 注意力块结构组成
Im=If+A×It,
(6)
其中,Im表示融合后的图像信息.
1.4 多注意力模块(MAM)
为了让网络学习更重要的脸部区域.本方法设计了一个多注意力模块,流程如图5.其中,网络中输出的特征图X大小为H2×W2×C2.通过一个多注意力块,获得k张注意力图M,大小为H2×W2×k,Mi表示第i张注意力图,该注意力块的组成如图4.采用一个在像素级取最大值的操作将多张特征图融合为1张最显著的特征图M′.
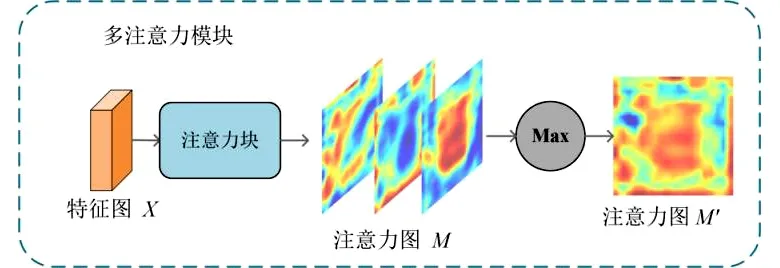
图5 多注意力模块
M′(x,y)=max{M1(x,y),M2(x,y),…,Mk(x,y)},
(7)
其中,1≤x≤W2,1≤y≤H2.X和M′之间进行一个乘法操作,得到输出X′.通过对特征图赋予不同的权重,使网络倾向于学习更重要的区域.将得到的X′作为后续网络的输入以提取全局表示g,最后通过由全连接层组成的分类器进行分类,由交叉熵损失进行监督.
2 实验
2.1 实验设置
深度人脸伪造检测中应用最广泛的是在FaceForensics++(FF++)[8]数据集上进行测试.它包含1 000个真视频和4 000个篡改视频.采用了4种篡改方法的子数据集,包括Deepfakes、Face2Face、FaceSwap和NeuralTextures.每种篡改方法代表FF++中1个子数据集,包含1 000个假视频.此外,FF++数据集有3种不同压缩率版本,即低质量版本LQ、高质量版本HQ和无损版本RAW.本文遵循Rossler等[8]的数据划分,720个视频用于训练,140个视频用于验证,140个视频用于测试.采用准确率(ACC)和RoC曲线下面积(AUC)作为实验对比的评价指标,并取验证集上最佳的模型用于测试.分别进行了单个篡改方法数据集和混合4种篡改方法数据集的实验,与多种检测算法进行对比.
图像预处理上利用dlib[18]提取视频中的人脸图像作为网络的输入,大小为299×299.使用在ImageNet[19]上预训练好的Xception网络[10]作为主干网络,根据实验经验数据,IDM中纹理提取的超参数α和β分别设为0.000 4和0.005 0实验效果最好,MAM中的注意图k的数量设为3,batch size设为32,选择Adam优化器,学习率为1e-4,训练30轮,每5轮学习率衰减为原来的0.9.
2.2 单个篡改方法数据集的对比实验
为了验证本模型可以检测不同的深度人脸伪造,在FF++中4种篡改方法数据集上分别进行了对比实验.使用每种篡改方法的HQ版本数据进行单独实验,每个视频采样30帧.实验结果如表1所示,粗体表示最好结果.实验结果表明,在大多数篡改方法数据集的检测上,本方法优于其他检测方法.在Deepfake、Face2Face和FaceSwap上的准确率都达99%以上,在NeuralTextures上达到95.25%.在Face2Face上,MTD-Net[11]利用了多尺度的纹理差异进行检测,取得了最好的效果.这也进一步说明了真实人脸和篡改人脸的纹理信息差异对检测是有效的.本方法在Deepfakes、FaceSwap和NeuralTextures篡改方法数据集上实现了最优的检测结果,证明对不同篡改方法数据集的有效性.

表1 在4种不同篡改方法数据集上的准确率对比实验结果
2.3 混合篡改方法数据集的对比实验
本文还在FF++中不同压缩率版本的混合篡改方法数据集上进行了实验.具体来说,在包含4种篡改方法的高质量版本HQ和低质量版本LQ的数据集上进行实验.为了保证真假类别标签的平衡,在原始视频上取40帧,篡改视频取10帧.实验结果如表2所示.本文在HQ和LQ上的检测准确率分别达到95.83%和84.23%,在低质量版本上相较于次优的SPSL算法[14],检测准确率提高了2.66%.在AUC指标上,本方法在HQ和LQ上的准确率分别达到了99.11%和91.86%,同次优的方法Two-Branch[13]相比,在低质量版本上提升了5.27%,在高质量版本上提升了0.41%.本方法在HQ和LQ上都取得了最好的性能,进一步证明了在混合篡改方法数据集上优秀的检测能力.

表2 混合篡改方法数据集在不同压缩率版本上的对比实验结果
2.4 消融实验
2.4.1 纹理信息的有效性
根据公式(1),图像由纹理成分和内容成分组成.因此,为了验证纹理成分在检测中的作用,使用不同成分在混合4种篡改方法的HQ和LQ版本上进行实验.设置如下:(1)只使用图像的内容成分进行训练;(2)仅使用图像的纹理成分进行训练;(3)使用人脸图像进行训练,其中包括内容成分和纹理成分.
此实验所用的模型没有应用AGTE模块,因为该模块是为融合纹理信息和空间信息而设计的.然而,消融实验中仅使用了两种成分中的一种.实验结果如表3所示.与仅使用内容成分(表3第1行)相比,使用人脸图像训练(表3第3行)在HQ和LQ上都有更好的效果.证明了纹理信息对深度伪造检测具有辅助作用,说明通过纹理增强来提高模型的检测能力是可行的.然而,仅使用纹理成分进行训练(表3第2行),HQ的准确率仅为72.31%,LQ的准确率为63.73%.而仅使用内容部分进行训练,在HQ上准确率达到95.09%,LQ上达到83.16%.这是因为内容部分包含了丰富的空间信息,这有利于网络学习更具判别性的特征.因此,本文通过结合内容成分和纹理成分进行深度人脸伪造检测的模型设计.

表3 不同数据成分在FF++全数据集上的消融实验结果
2.4.2 设计模块的有效性
为了确认AGTE和MAM的有效性,在HQ版本的混合篡改方法的数据集上进行了消融实验.结果如表4所示.基线在HQ上准确率为95.25%.当分别应用AGTE和MAM模块时,准确率提升到95.56%和95.41%.与基线相比,检测准确率都有提升,这证明了AGTE和MAM模块的有效性.应用所有模块时,准确率达到95.83%,优于只应用AGTE模块或MAM模块的实验结果,进一步证明了MAM和AGTE模块的有效性.
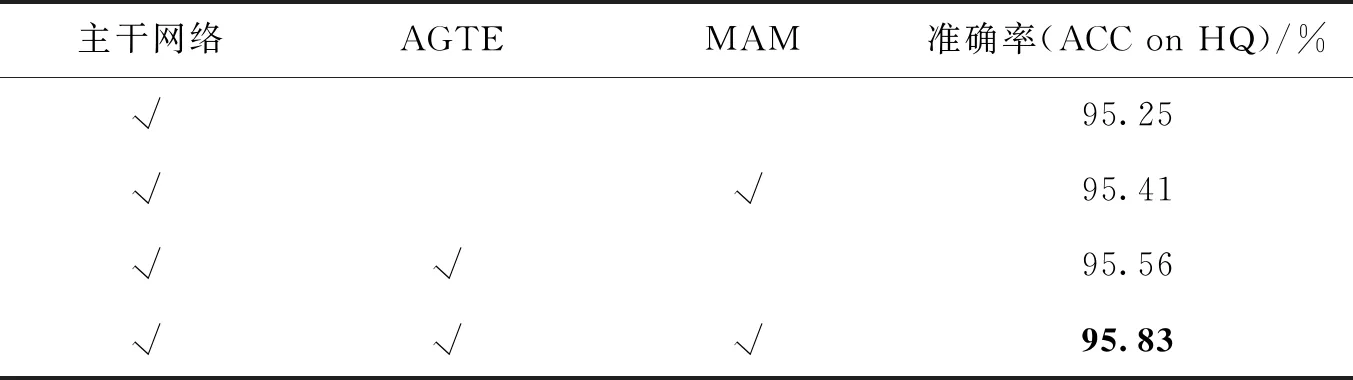
表4 不同模块的消融实验结果
2.4.3 多注意力图数量k的影响以及可视化
为了研究不同数量的注意力图对网络的影响,对不同数量k的注意力图在HQ版本上进行了消融实验.实验结果如表5所示,发现k=3时性能最好.图6对网络中的注意力图进行了可视化.图6第2行是AGTE模块中注意力图A的可视化结果,可知AGTE模块更加关注面部区域,并通过注意机制学习纹理增强的权值,使AGTE模块可以自适应地增强纹理.图6第3行表示MAM中在像素级取最大值的操作后的注意力图M′.可以观察到,它们都更注重面部区域,因为面部是深度人脸伪造的主要篡改区域.

表5 不同注意力图数量k对模型的影响
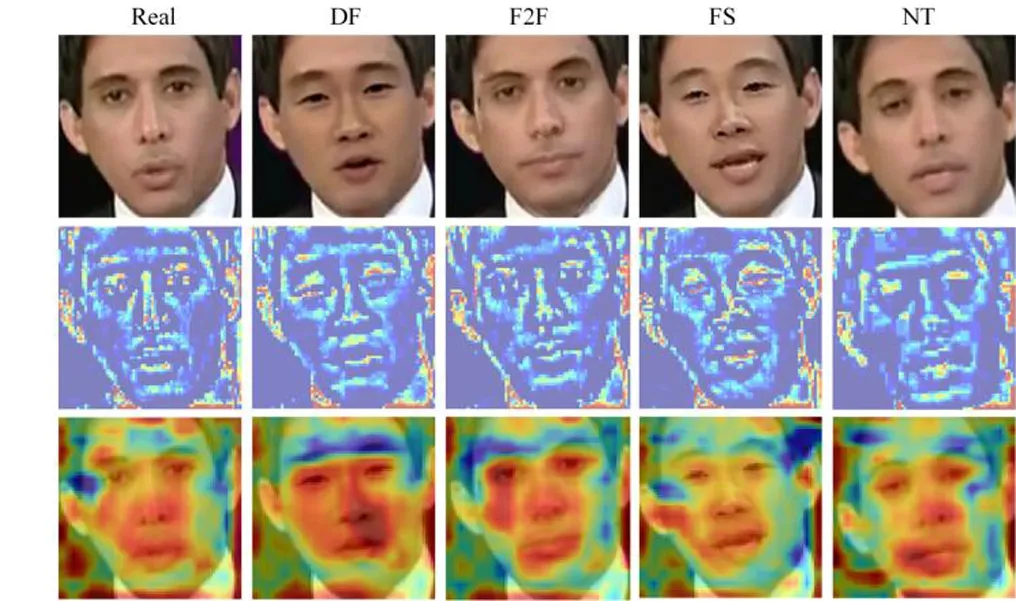
图6 注意力图可视化
3 总结
本研究从真脸和篡改人脸之间的纹理信息出发,通过增强纹理获取更多的伪影信息,从而实现更佳的检测性能.具体来说,本研究将图像分解方法引入到深度人脸伪造检测任务中,并提出了一种基于纹理和注意力机制的深度人脸伪造检测网络.该网络由注意力引导纹理增强模块和多注意力模块组成.实验表明,本方法在不同篡改方法数据集上的检测准确率都较高,但该方法还存在不足,比如泛化性和鲁棒性不强.现有方法的泛化能力都比较弱,即只对单一数据集有较好的结果,当检测其他未见过的数据集时,检测准确率急剧下降.在鲁棒性方面,当模型检测高度压缩的图片或视频时,检测准确率较低.未来要着力提升现有模型的泛化性和鲁棒性.
