基于动态域定界的循环分类模型
2022-11-15邓慧娜叶阿勇张娇美
邓慧娜,叶阿勇,张娇美
(福建师范大学计算机与网络空间安全学院,福建 福州 350117;福建省网络安全与密码技术重点实验室,福建 福州 350117)
随着传统机器学习的不断发展和成熟,从大量有标签的数据中训练得到一个好的分类模型已相对容易[1].但真实的应用场景中,传统的机器学习方法仍然不能完全满足应用需求.一方面,获取带标签的数据相对困难.生活中产生的数据大多不含标签,而人工标签的成本又过高,并且数据采集往往还要考虑个人隐私及安全性问题,这也进一步增加数据获取的难度.另一方面,传统机器学习在每次数据更新时都需要重新建立模型和训练,从而耗费大量的时间和资源.因此,2005年杨强教授提出迁移学习的概念,目标是让计算机把大数据领域习得的知识和方法迁移到其他数据不足的领域,旨在能够通过将已经学习到的知识应用在新的目标任务中,从而提高学习效率和准确率.
迁移学习一定程度上缓解了传统机器学习的数据压力,但迁移学习效果受众多因素的影响,尤其是在多渠道获取数据的情况下.一方面,由于数据相关性差别较大,源域难以包含目标域的完整信息[2].因此,源域的选择对分类结果影响较大.而现有研究大都采用固定划分源域和目标域的机制,导致分类精确度不高,且无法适应异构用户的不同分类需求[3].另一方面,多渠道获取的数据仍存在标签缺失或无标签问题,而常见算法都建立在数据具有完备标签的基础上,对无监督数据分类难以保证精确度.最终在各方面因素的限制下,迁移学习的应用并未得到推广.
本文的研究目标是从数据的采集阶段到产生分类结果建立完整流程的分类模型CAMDOT,其中包括多渠道获取数据的联合源域机制、基于Softmax和CNN的循环分类算法S-CNN.具体贡献有:
(1) 提出一种动态的联合源域机制.传统多源域迁移学习模型往往采用随机或固定的方法来确定源域和目标域,容易导致分类精确度不高.针对该问题,本文引入数据相关性来动态选择源域,从而提高其包含目标域信息的完整性.先利用信息论方法量化不同数据域间的相关性,并依此筛选与目标分类数据相关性较高的源域样本数据,再基于该样本初始化Softmax分类器.此外,分别通过理论和模拟实验证明了相关性系数会直接影响分类准确率,即相关性越大准确率越高,反之亦然.并且源域个数越多准确率越高.
(2) 提出循环分类算法S-CNN(softmax-convolutional neural networks).为了进一步优化多渠道获取的数据差异大及标签不足导致的分类效果差的问题,通过利用有标签的源域数据初始化Softmax分类器,由该分类器给目标域数据加 “伪标签”,从而解决CNN难以处理无标签数据的问题;再利用CNN各层提取并强化数据特征,最后通过Softmax分类器进行分类.由此构建循环分类方法,实现有效利用CNN自动进行特征提取的优势,使结果更接近真实分类目标.此外,通过在人造数据集和真实数据集上的模拟实验,证明该算法具有良好的分类精确度.
(3) 提出基于迁移学习的分类模型CAMDOT.为解决迁移学习模式固定且不能适应多应用场景的问题,建立一个由本地端收集数据并进行数据初处理,服务器端数据整合并根据参与者上传的请求对源域和目标域进行定界,最后进行分类的迁移学习模型.实现能够适应不同用户需求,支持动态调整的可移植数据分类模型.
1 相关工作
数据分类的研究方向依据研究对象的不同主要分为文本数据、图像数据及其他实例或非实例数据的分类研究.其中,文本和图像数据的研究相对成熟和具体,尤其在天气和医疗图像识别和分类上.近几年,不断有研究者将各领域医学图像和大数据预测模型相结合,为现代医学发展作出重大贡献.WANG等[4]提出了一种基于深度卷积神经网络的图像分类算法,用于气胸X射线的高分辨率医学图像分析,可以有效提高气胸的正确诊断率.YANG等[5]提出了一种基于注意力指导的CNN方法,用于乳腺癌组织病理学图像的分类.此外,在其他数据分类研究中,众多研究者致力于基于不平衡的数据集的分类[6],从连续的文本数据流中挖掘用户感兴趣的有价值的信息[7],基于情感分析的自然语言分类[8].所以,无论是在图像分类中,还是在文本数据与其他实例数据分类中,多数研究方案都基本能保证分类精确度较高,且分类效果良好.然而,一方面,自然图像和医学图像具有实质性的差异[9],另一方面,已有方案大都需要大量数据标签来训练分类器,因此现有研究仍然存在局限.
为了进一步解决分类的准确性问题,有了深度学习与迁移学习的结合——深度迁移学习,其主要目标是将深度学习的鲁棒性、泛化能力强的特点与迁移学习的领域无关的特点相结合,从而提高准确度问题.2015年后,已经有人作出了相应的研究汇报.冯伟等[10]利用LSC模型基于迁移学习机制,引入自适应迁移策略,有选择地利用前层模型知识辅助当前层的模型构建,提升了模型泛化性能,缓解了负迁移效应.NOOR等[11]基于CNN的体系结构使用迁移学习和微调功能自动对图像进行分类.NGO等[12]为解决在现实世界中多样环境因素影响下,面部表情识别的训练数据集存在不平衡性而导致识别性能不高的问题,基于CNN提出了一种加权簇损失的新型损失函数在微调阶段使用.虽然对深度迁移学习的研究已经越来越深入,但大多数都停留在针对某一领域的数据,且只考虑算法及损失函数的选择和微调.迁移学习对数据量要求比较严格,但是现实数据采集却存在困难,所以没有从数据采集到输出结果的整体模型框架就导致深度迁移学习的应用并不广泛.
2 基本知识
2.1 迁移学习的基本理论
迁移学习是将在某领域学习到的知识迁移到其他领域,迁移的前提是这些领域要有一定的相似性[13].在迁移学习中有2个重要概念,分别是域(domain)和任务(task).一个域包括特征空间X和边际概率分布P(X)两个概念,其中X=x1,…,xn.迁移学习的目标是在给定原始域、原始任务、目标域、目标任务的情况下,借助原始域和原始任务提高目标函数f(x)在目标域的分类效果.其核心任务是找到源域特征集和目标域特征集之间相关性大的特征集合,即能够较好地完成分类任务的特征表示,尽可能地减少不同域之间的分布差异,同时最大程度地保留各领域的独立属性.
迁移学习根据迁移内容与迁移方法有不同的分类方法,根据迁移内容可以分为4种:基于实例的迁移学习[14]、基于特征的迁移学习[15]、基于参数的迁移学习[16]以及基于关系的迁移学习.
2.2 CNN的基本理论
卷积神经网络是神经网络模型的延伸,同样是层级网络结构,主要应用于解决图像问题.但是卷积神经网络区别于一般神经网络的层级结构,其包括:卷积层、激励层、池化层和全连接层.
卷积层:卷积即卷积运算,是固定的权重和不同窗口内数据作内积.卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征.
激励层:该层使用的是线性整流(rectified linear units,ReLU)规则,主要作用是提供激活函数,把卷积层输出结果作非线性映射.
池化层:通常在卷积层之后会得到维度很大的特征,将特征切成几个区域,取其最大值或均值,得到新的维度较小的特征.
全连接层:把所有局部特征结合变成全局特征,用来计算最后每一类的得分.
2.3 PCA算法
主成分分析算法(PCA)是一种常用的特征提取与数据降维方法,将高维度的特征向量合并称为低维度的特征属性,是一种无监督的降维方法.算法目标是通过某种线性投影,将高维的数据映射到低维的空间中表示,并且期望在所投影维度上数据的方差最大(最大方差理论),以此使用较少的数据维度,同时保留较多的原数据点的特性.
3 问题定义
定义1参与者.数据提供者可以是终端设备、公司服务器等,符号表示为u.
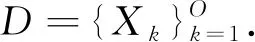
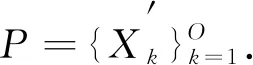


表1 参数描述
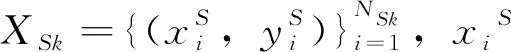
根据Softmax函数:
(1)
定义分类器的损失函数为:
(2)
其中,θ表示分类器模型参数,m表示类别总数,Pzj表示Softmax函数值,即第j类的概率值,pj表示预测为第j类伪标签的概率值.
本文基于ReLU函数定义一个卷积神经网络,形成S-CNN循环分类器.具体地,假设神经网络的第1层是卷积层,则该层的输出可以表示为:
(3)
(4)
其中,z(·)表示池化层的输出,a(·)表示经过ReLU函数激活后的输出,xi表示输入,*表示卷积运算,w表示权重参数,b为偏置参数.
将激活后的卷积层输出作为池化层的输入,选择平均池化方法,则池化层输出可表示为:
(5)

(6)
(7)
(8)
4 本文方案
4.1 CAMDOT框架
CAMDOT包含本地端和云服务器端的两端处理机制,如图1所示.其中,数据采集和初级处理在本地端进行,域定界及分类过程在云服务器端进行.本地数据处理是参与者将数据上传至服务器之前使用主成分分析法对数据进行的本地端降维处理,目的是减少本地与服务器端的通信开销并降低信息敏感度;特征映射是针对不同分类需求(数据分类需求由联合源域的某个或多个参与者提出,并上传至云服务器),筛选数据并确定源域和目标域,提高数据有效利用率;分类核心是采用Softmax分类器为无标签的目标域数据加“伪标签”,CNN强化特征再利用Softmax分类器进行分类的方法.
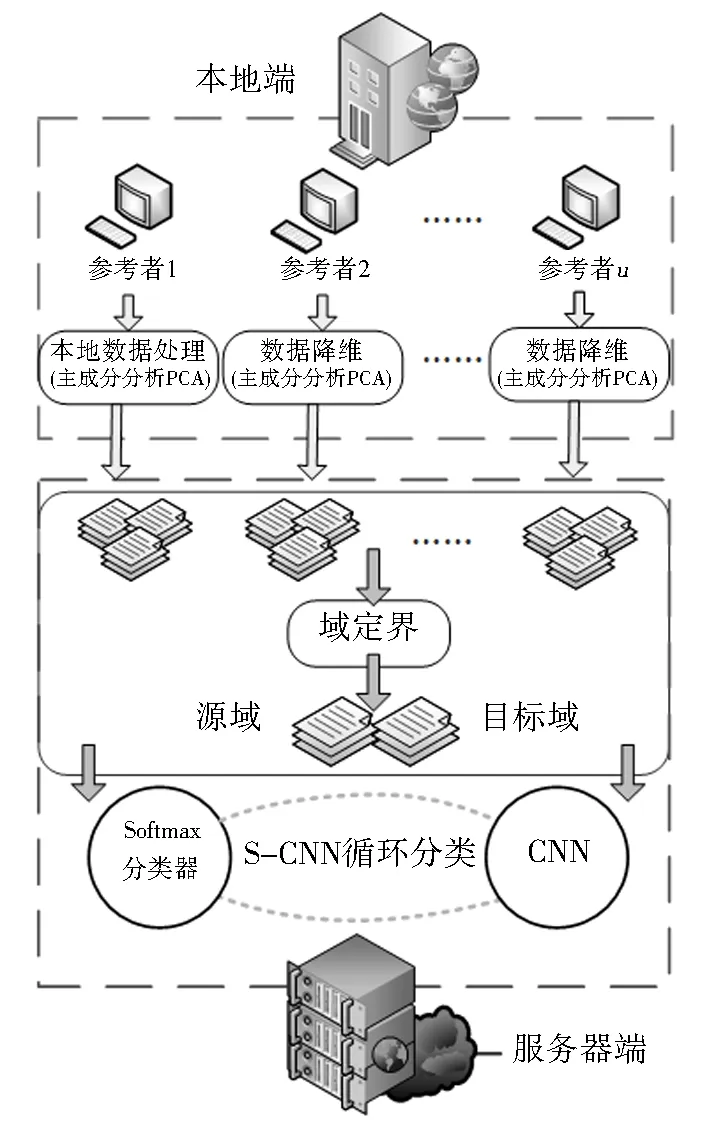
图1 CAMDOT模型框架图
4.2 本地数据采集及降维
模型的训练数据由本地参与者提供,为了在一定程度上保护数据主体的隐私,并减少与服务器的通信开销.参与者在本地使用主成分分析法PCA对数据进行降维处理,将原始数据库中与分类需求相关性较低的特征去除,然后传至云服务器.降维的具体步骤为:
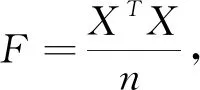
4.3 域定界

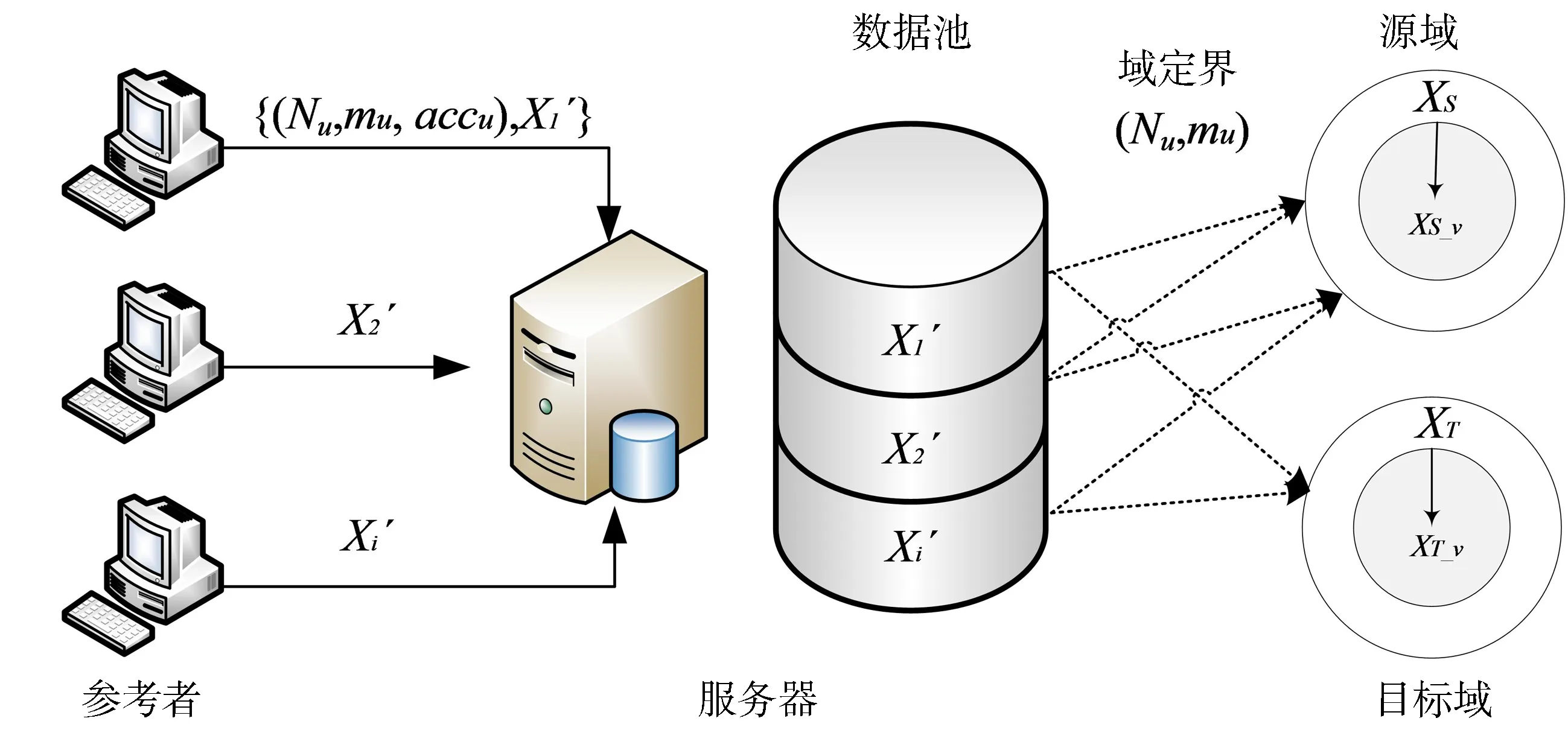
图2 域定界流程图
KL(p(xXi,xXu)‖p(xXi)p(xXu))=
(9)
其中,KL表示距离,是Kullback-Leibler差异的简称,它衡量相同空间里的两个事件概率分布的差异情况.
4.4 分类核心
在S-CNN算法中,将特征迁移学习和实例迁移学习相结合,强化筛选出符合评估要求的数据特征,由有监督学习指引无监督学习定义标签,最终由2个分类器循环遍历数据,得到符合应用要求的分类结果,如算法1和图3所示.

算法1INPUT:源于数据集XS={(xSi,ySi)},目标域数据集XT={(xTi)},批量大小v,总轮次数Q.OUPUT:S-CNN分类模型1.从XS中随机选取v个有标签的样本数据{(xSi,ySi)}vi=1,记为XS—v2.根据XS—v初始化Softmax分类器 Softmax(zj)=ezj∑mj=1ezm,(j=1…m)3.For qi in 1:Q do4.从XS中随机选取v个有标签的样本数据{(xSi,ySi)}vi=1,记为XS—v;从XT中随机选取b个有标签的样本数据{(xSi)}vi=1,记为XT—v5.XT—v通过Softmax分类器,得到预测不同类别的预测概率值Pzj={pzj}6.根据max(Pzj),为XT—v数据定义 “伪标签”,得到X'T—v={(xTi,yTi)}7.XS—v通过卷积神经网络计算得到f=F(XS—v);X'T—v通过卷积神经网络计算得到f=F(X'T—v)8.根据损失函数计算误差,并更新权值w和偏置参数b9.End for10.输出S-CNN模型

图3 分类核心流程
5 方案分析
5.1 模型复杂度分析
CAMDOT在本地端使用PCA方法,其矩阵的完整的特征向量分解的时间复杂度为O(n3).将数据集投影到前k个主成分中,即只需要前k个特征值和特征向量,所以它的时间复杂度为O(k·n2),这使得本地端上传数据更高效.Softmax分类算法的时间复杂度为O(n),CNN的时间复杂度也是O(n),但是由于数据分批次输入,二者可以看作是并行工作,所以分类算法的时间复杂度无需累加,还是O(n).
5.2 相关性与准确率分析
本文使用分类正确的数据量与所有数据量的商值计算分类准确率,如下式:
(10)

(11)
定理1在多源域数据可选择的情况下,选择的源域个数Nu越多,源域数据量NS越大,则分类精确度越高.
证明

已知式(8)中NT和NTg为固值,0<β<1,且β越大,分类结果越好.可得变量NS越大,则acc的值越大,即分类精确度越高.
式(11)中,源域数据量NS由用户需求数据量Nu决定,而用户源域数据个数Nu和相关系数β反向相关,即相关系数β越大,对源域数据与分类需求数据的相关性要求越高,那么可选择的Nu越小;相反地,相关系数β越小,对源域数据与分类需求数据的相关性要求越小,那么可选择的Nu越大.
6 实验与分析
6.1 实验数据
(1)人造数据集
在本文的硬件环境中,CPU使用Intel i5,GPU使用NVIDIA GeForce RTX 3080Ti,采用Python 3.9来构造一个无数据标签的人造数据集,作为迁移学习的数据池.该数据集的类别为4,每个类别的样本数为300,维度为2.本文的卷积神经网络由4个卷积层、4个池化层、1个分类器组成,卷积层采用了3×3大小的卷积核,卷积核的个数分别为16、32、64、128,步长为1,填充为0,Softmax作为分类器.本次实验总共训练迭代10 000次,初始学习率设为0.001,动量系数为0.9,权重衰减系数为0.005.此外,为了更直观、更清晰地验证分类算法,数据分布形式为螺旋分布.将数据集映射到空间中实现可视化,如图4所示.实验中,将数据集随机分为10个数据组,模拟迁移学习中的多个源域,即本文中的多个用户数据,其中一组数据作为目标域数据,其余分组作为源域数据.

图4 原始数据分布
(2)真实数据集
采用Caltech和Office[17]两个真实数据集进行模拟实验.其包括4个域,即C(Caltech-256)、A(Amazon)、W(Webcam)和D(DSLR),具体情况参考表2.对于数据集,实验中选取1个子集作为目标,剩余的子集计算与该目标域的相关性并排序,按照相关性从高到低分别构造1、2、3个源域的分类任务;分别选A和C为目标域构造A组和C组2组多源迁移任务.在实验中,分别将2个多源迁移学习算法A-SVM、Multi-KMM及MTL-BDI[17]与本文分类算法S-CNN进行对比.

表2 Caltech和Office数据集分布情况
6.2 结果分析
(1)人造数据集
分别计算人造数据集中不同源域与目标数据的相关系数,并模拟了源域个数Nu为9、6、3的分类效果;然后,将二维数据映射到坐标系中,实现可视化,如图5所示.从实验结果可以明显看出,Nu=9的分类效果最好,这在一定程度上验证了定理1.而根据表3的准确率,发现Nu=9和Nu=6的结果相差并不大.其原因可能是数据随机分割为10组,其中一些组包含数据分类边界的点,也有一些组包含数据分类内部的点.而本文的模型在确定其中一组作为分类目标后,利用数据分布概率计算各组与目标分组的数据相关性,并令相关性高的分组优先被选择.所以当Nu=6时,可能被选择的6组源域数据已经包含大多数目标域数据的信息,因此训练得到的模型获得较高的准确率.

图5 S-CNN分类结果

表3 人造数据集实验准确率表
(2)Caltech和Office数据集
根据数据相关性计算,得到针对A组分类任务源域相关性排序为C>W>D,所以构建了CWD→A、CW→A、C→A共3组实验,而为了证明本文提出的源域相关性与分类结果相关,增加了1组对比实验D→A.同样的方法,得到针对C组分类任务源域相关性排序为A>W>D,所以构建了AWD→C、AW→C、A→C和D→C共4小组实验.
模拟实验以分类任务为自变量、分类准确率为因变量得到的实验结果,并使用ROC曲线下面积(AUC)来评估模型的准确性,如图6所示.从图6可以看出,利用相关性排序选择的前3小组与对比小组的实验结果差别较大,且A→C和D→C组的分类准确度较差.这说明提出的相关性计算进行域定界的方法能够有效地选出与目标域数据最相似的源域数据,得到较好的分类结果.此外,在A组和C组内,随着源域数量的增多,分类精确度也在不断提高,这也表明一般情况下,多源域数据分类还是需要有足够的数据量才能训练较好的分类模型.不仅如此,在与其他多源域分类方法的对比中,本方案在CW→A、AW→C两个小组的分类准确率比较中,有较明显的优势.其原因可能是A、C和W数据的相关性较高,所以选择其中一个子集的数据作为目标域都可以得到较好的分类结果,而本文提出的S-CNN算法是基于数据相关性基础上,由源域数据初始化分类器,所以相关性较高的3个数据子集的分类结果就会表现良好.

图6 数据集分类准确率比较
7 总结
本文基于多源域迁移学习机制,提出了分类模型CAMDOT.本地端通过PCA降维增加了数据安全性,同时降低与服务器的通信开销.服务器端针对用户分类需求利用数据相关性选择源域数据,增强了分类模型的泛化能力.此外,使用S-CNN循环分类方法,提高了分类的精确度.在人造数据集和真实数据集上的实验结果均验证了本文所提出的分类模型的有效性.最后,联合源域中参与者的共识机制是本文进一步研究和讨论的问题.
