用可控实验解释评估结果研究
2022-11-15卜先锦毛腾蛟黄其旺
卜先锦 毛腾蛟 黄其旺
(军事科学院 战略评估咨询中心,北京100091)
1 引言
“客观、独立、科学、公正”是评估的灵魂,军事评估也不例外。在实际工作中,评估结果往往取决于主观和客观数据,其中主观数据来源于专家,导致评估结果的公正性、可信度易受质疑。公正是公平的基础,美国学者阿罗提出了“不可能定理”[1],证明了在两条公理和五个假设条件下,找不到一个公平的社会福利函数,表明公平的社会是不存在的。在评估实践中,如何立足于现有客观条件,提高评估结果的可信度,保证评估结果的公正、可信,成为评估的难题。随着数据科学的发展,基于数据统计的因果推断研究,为评估结果的自我质疑、自我解剖、自我说明提供了可能的解释方法路径。
因果推断理论研究,基于数理统计,目前主要有两大学派:一是鲁宾学派,诞生于20 世纪80年代,鲁宾在学者内曼因果模型的基础上,提出了鲁宾模型[2,3](Rubin Casual Model,RCM),度量总体平均因果效应,该模型基于可忽略性假定,实现了从随机对照实验到观察性实验的转变,目前广泛运用于社会、经济、政策以及医疗等领域。二是珀尔学派[4,5],诞生于20 世纪90 年代,美国学者珀尔等人,结合经济领域的结构方程模型(Structure Equation Model,SEM)和鲁宾模型,基于贝叶斯网络,提出了概率推理和因果分析框架下的结构因果模型[6](Structure Causal Model,SCM),该模型采用图形化方式推断和展示变量之间的因果关系,简便易懂,学界认可度较高,但由于变量间的因果关系发现仍然基于人的经验判断,导致混淆变量难以区分。近年来,随着人工智能技术的发展,智能算法的不可解释性成为强人工智能不能实现的瓶颈问题,珀尔提出了用因果科学的理论方法,启发改进机器学习算法,导致因果热再度掀起[7,8]。2019 年,军事科学院杨学军院士向全院科研人员推荐了珀尔的著作《为什么》一书,提出了军事评估要用“因果语言”说话的要求。他认为:评估的首要任务是用数据、模型和结论来支撑和服务决策,简单的票决制无法确保评估的公正性和可信度,只有基于因果推断的方法和模型,才能做到评估过程和结果的可推理、可预测、可解释和可交流。自此,开展因果推断方法研究,助力评估结果的解释,成为军事评估理论创新的又一引点和热点,课题组也开展相关研究,取得阶段性成果[9]。
论文针对还原论方法得出的评估结果公正性和可信度问题,通过解剖评估过程,分析评估流程和影响评估结果的关键因素,采用正交实验,基于获取实验观测数据,构建潜在结果模型,并对影响评估结果的敏感因素、偏差及原因进行分析,最后比较了潜在结果与实际评估结果,并进行合理性解释。
2 评估过程及影响因素分析
2.1 评估流程和步骤
在军事评估中,无论是简单系统还是复杂系统,目前主流方法为还原论和系统论或者两者的结合。其一般过程:给出评估对象及问题,确定评估专家,分析影响因素,确定打分规则,确定评估指标和权重,选择集结模型。如图1 所示。

图1 评估一般流程示意图
这里采集的数据,一是评估指标属性数据,反映了评估对象的客观信息;二是专家打分数据,反映了评价评估对象的主观信息。此外,由于属性数据和指标数据难以直接融合,需要对数据进行筛选、分析、归一化处理,再集结计算。
2.2 影响评估结果的关键因素
影响评估结果的因素很多,其中关键因素主要包括评估专家、评估指标体系及权重、专家打分集结规则,以及综合评价模型。
评估专家是评估者,其主观价值判断直接影响评估结果,因此,选择专家时,既要考虑专家对评估对象所在领域的熟悉程度,也要考虑他们对评估流程和方法的掌握情况。由于专家自身经验、学识、认知水平、专业领域的不同,评估同样情境下的同一对象,可能会产生不同的结果,尤其是当判断偏差较大时,还会出现颠覆性结果,这时可通过增加评估专家数量“稀释”偏差,此外,为了消除专家打分的不稳定性,还可通过随机抽取专家和制定打分规则等方法予以解决。
评估指标是根据评估目的和任务,准确反映评估对象某一方面的特性,从不同属性和侧面刻画评估对象所具有的特征。指标的集合构成了指标体系,其合理性是评估结果科学性、公正性的重要保证。确定评估指标需要经过研究而非主观臆想,指标通常应具有独立性、完备性和适应性,而实际中指标往往相互关联,导致因果关系难以被发现。
指标权重反映指标在指标体系中的价值高低和相对重要程度,是指标在指标体系中所占比例值,如果总指标为1,其中每个指标占比份额称之为“权重”。由于指标体系指标特性和综合评价模型选择不同,改变指标权重,往往会导致评估结果的改变。
专家打分集结规则主要有对专家打分求均值或求“剪枝均值”等方法,“剪枝均值”即体操打分法,去掉专家打分中的最高分和最低分再求均值,有利于去除专家偏好导致的“异常”值,使打分更客观和公正。
常用的综合评价模型有三种:一是加权求和法,适用于各评估指标相互独立情况;二是指数综合法,适用于各指标有较强关联性的情况,突出权重小的评估指标值的作用,该方法对指标值变化敏感,能体现评估对象整体的均衡性;三是混合法,即加权求和法和指数综合法的综合,适用于部分指标相互关联,部分指标相互独立的情况。
3 可控实验与潜在结果模型
3.1 正交实验设计
在因果效应模型中,主流鲁宾模型基于观测数据。当随机实验不涉及非人的伦理道德时,随机实验数据与观测数据具有相同的物理意义,也称之为可控实验或准随机实验。随机实验方法包括全析因实验、单因素轮换、正交实验、均匀设计等。当实验因素超过3 个时,因素之间会存在相互作用,彼此影响,不同因素、水平的组合会导致实验次数的急剧增加,这无疑增加了实验成本。正交实验设计具有“均匀分散性和齐整可比”的特点,它从全析因实验点中挑选代表性的样本点进行实验,大大减少实验成本。
3.2 关键因素及水平的确定
正交实验中,关键因素水平的确定是实验设计的重点,也是评估结果合理可解释性的依据。虽然关键因素及其水平的确定理论上遵循随机原则,但是实际中要依赖于评估对象、需求和经验进行取值。通常,影响评估结果的关键因素主要有评估专家、评估指标、指标权重、专家打分集结规则、综合评价模型等。评估专家的确定,考虑到专家数量以及专业领域,可事先在专家库中将专家分组,随机按组抽取;权重系数按以往经验确定,可事先按典型情形分组;专家打分集结规则采用“剪枝均值”和均值两种;综合评价模型可考虑加权求和法、指数综合法和混合法三种。
3.3 评估结果的解释性
评估结果的解释,主要为正向解释结果、反向回溯过程。正向解释结果,就是专家的选择、评估指标体系及权重的确定、专家打分集结规则的制定,以及综合评价模型的选择,弄清关键因素设置以及设置带来的结果;反向回溯就是一果多因分析,通过实际评估结果,反向回溯专家选择、指标体系构建、专家打分集结规则、综合评价模型选择的合理性,通过改变关键要素的水平,比较潜在结果与实际结果的差异,分析其影响,进而解释实际评估结果的合理性。可控正交实验对评估结果的解释流程如图2。
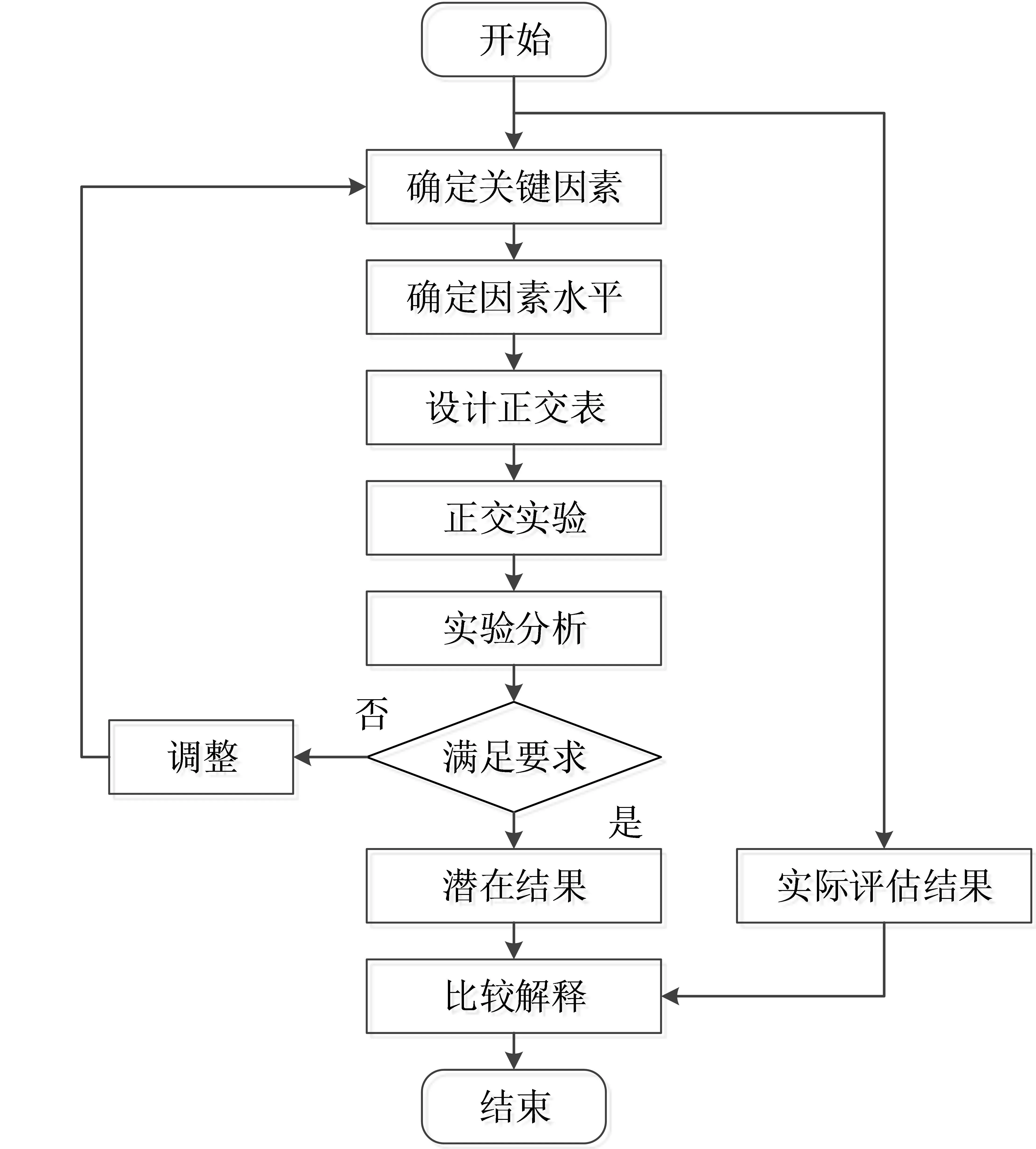
图2 潜在结果与实际结果比较解释流程图
4 评估结果解释案例分析
4.1 案例背景
以某防空旅年度训练考核评估为例,以营为单位进行,成绩分为基础训练、专业训练、现场答辩,其中,基础训练、专业训练为客观成绩,现场答辩由专家现场打分获得;然后按照给定权重和综合评价模型进行计算、排名并择优。根据初选情况,某年度防空旅有6 个营(St1-St6)参评,根据考核和评估,已评出年度3 个先进单位,作为实际评估结果。现在通过正交实验设计方法,用问卷调查方式获取实验观测数据,构建潜在结果模型,并对潜在结果与实际评估结果进行比较,解释实际评估结果的可信度与公正性。
4.2 关键因素及其水平
经过对该防空旅往年的考核评估情况研究分析,影响各综合成绩的关键因素主要是单位本身训练水平,从评估过程看,还涉及专家选取、考核方式、综合评价模型、专家打分集结规则和权重等。这里参照该防空旅以往评估经验,关键因素及水平选择如下。
(1)因素1(F1):选取专家。在专家库中抽取18 名专家,随机分为两组,水平1(p1)代表专家组1,水平2(p2)代表专家组2。
(2)因素2(F2):考核方式。该因素有两种水平,水平1(t1)为平时训练考核,关注平时训练成绩,总分300,包括平时基础训练100 分,平时专业训练100 分,现场答辩100 分;水平2(t2)为年度集中考核,以集中考核成绩为依据,总分400 分,包括基础训练100 分,专业训练200 分,现场答辩100 分。
(3)因素3(F3):专家打分集结规则。包括剪枝均值和均值两种水平,水平1(m1)表示“剪枝均值”打分法,水平2(m2)表示均值打分法。
(4)因素4(F4)为综合评价模型。主要有两种水平,水平1(s1)表示加权求和法(总得分S =SE·WE+Sp·Wp+Si·Wi);水平2(s2)表示混合法(总得分·SiWi)。其中,SE,Sp和Si分别代表基础训练成绩、专业训练成绩和答辩成绩,WE,Wp和Wi分别为三者权重。
(5)因素5(F5):权重。按照往年经验,有三种水平:水平1(k1 =(0.1,0.4,0.5));水平2(k2 =(0.1,0.6,0.3));水平3(k3 =(0.15,0.45,0.4))。关键因素及其水平设置见表1。
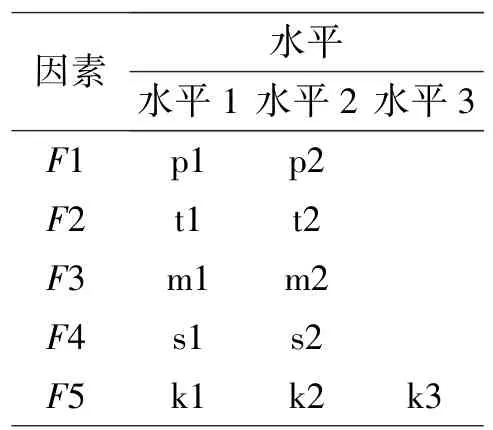
表1 关键因素及水平一览表
4.3 评估数据的获取
实验中评估数据主要为各单位的基础训练成绩、专业训练成绩和现场答辩成绩,其中客观成绩部分(基础训练成绩和专业训练成绩)采用各单位的实际数据。现场答辩的成绩主观成分较大,为了尽可能还原实际的答辩场景,更加真实地反映各单位的实际水平,实验从实际专家库中选取18 名专家,分为两组,采用问卷调查的形式,提供各单位的基础资料、客观训练成绩和实际的现场答辩录像,由专家再次进行打分。具体数据见表2。
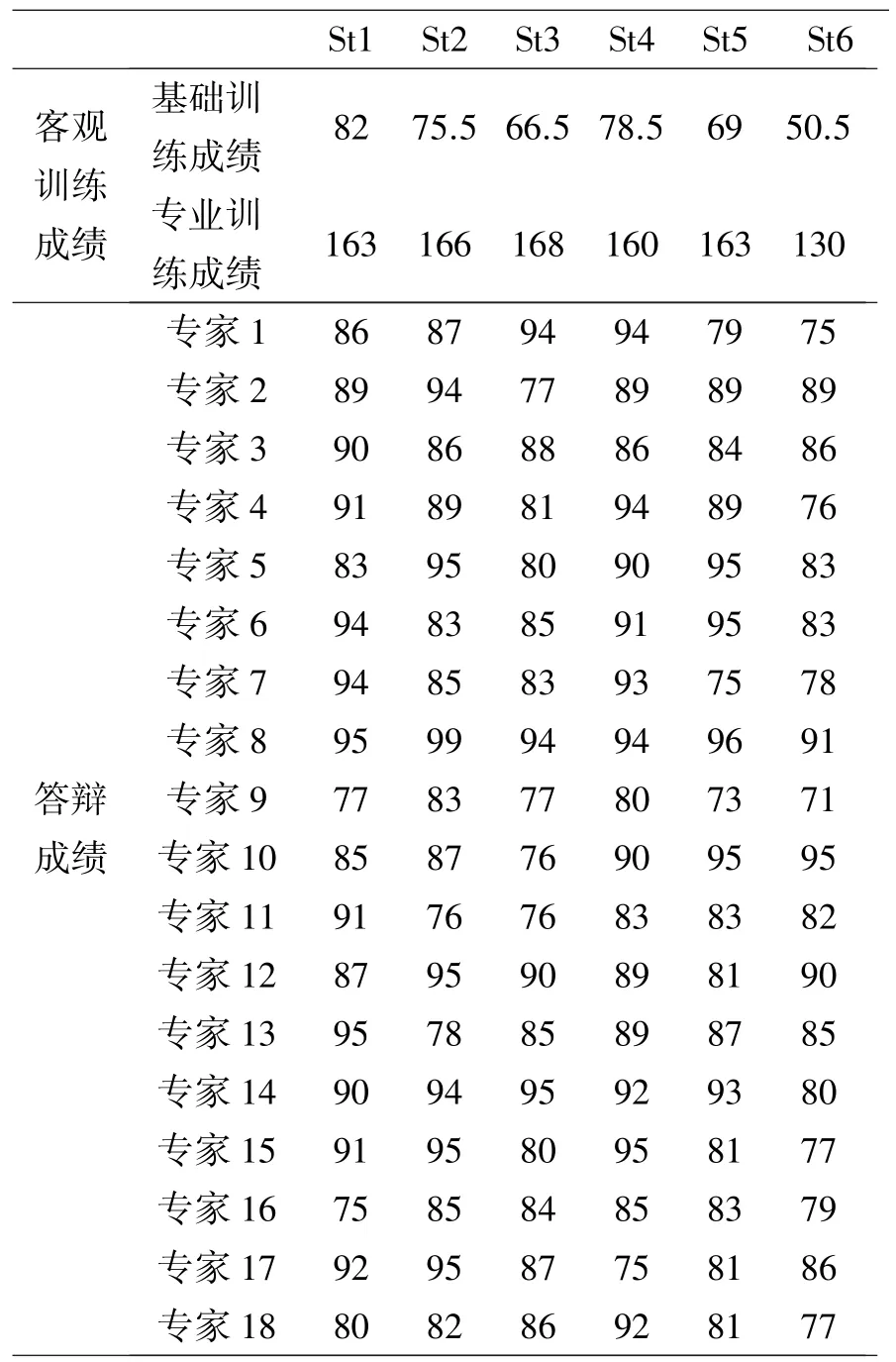
表2 单位考核成绩数据表
4.4 实验结果
采用正交实验设计助手软件进行实验设计,根据因素和水平数,生成正交表,如图3 所示。
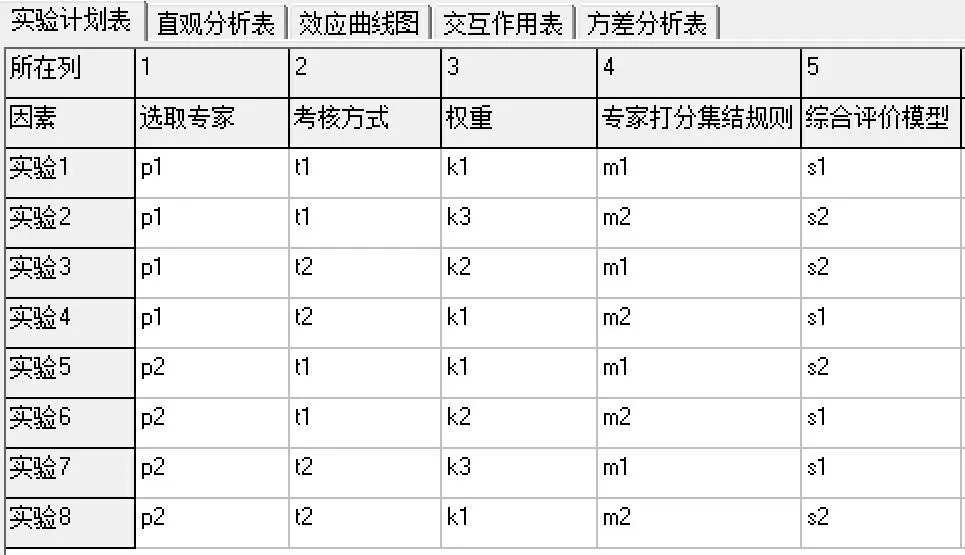
图3 正交实验正交表
按照正交实验设计,对表2 中数据,计算给出每个单位的总得分。需要注意的是,由于各组实验是不同因素不同水平的组合,为解决结果统计中量纲不一致的问题,需要对结果进行归一化处理,得到各单位的潜在结果成绩。使用正交设计助手软件得出单位的潜在结果成绩和极差值,见表3。
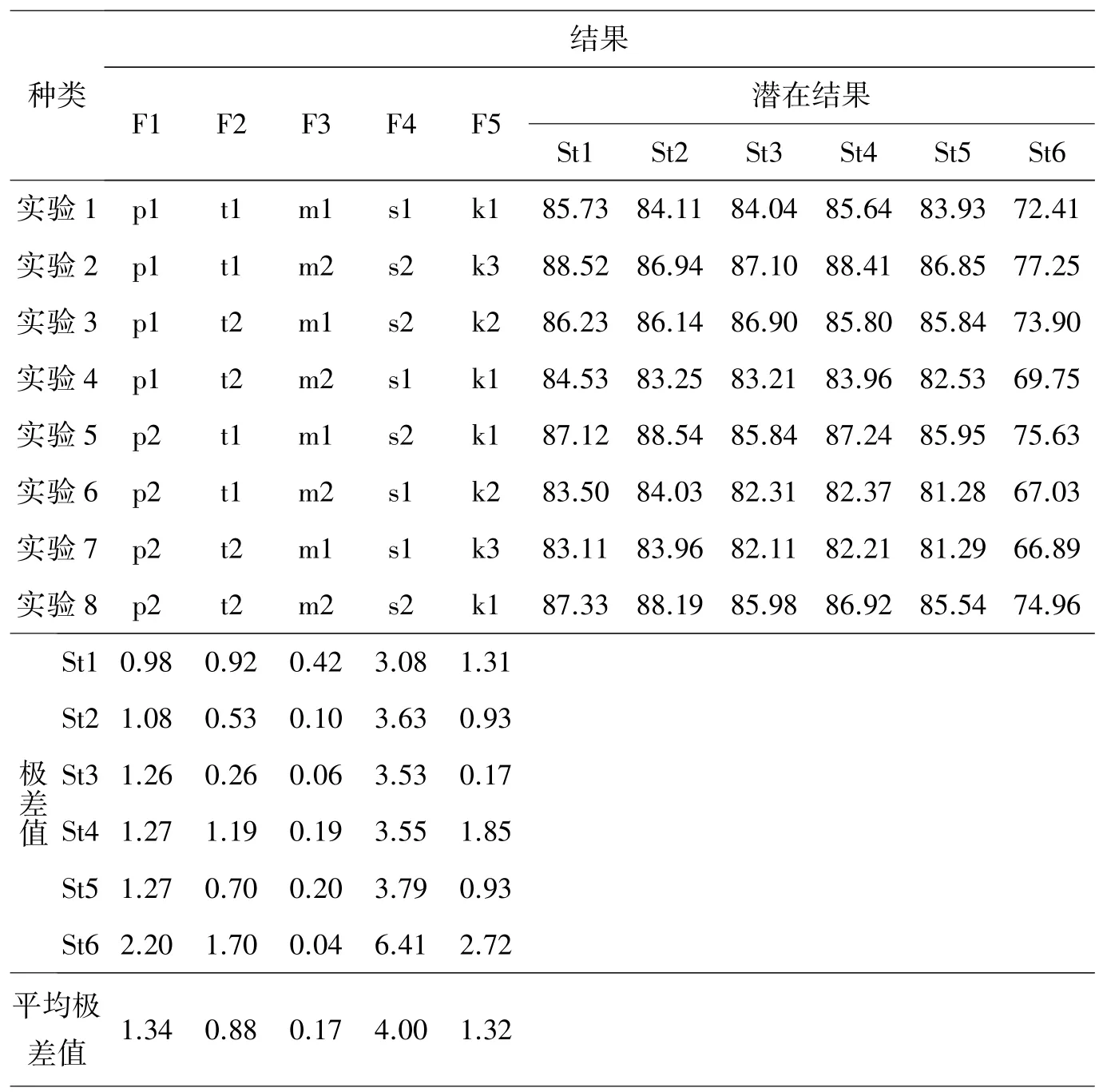
表3 正交实验方案及实验结果
以St1 为例,实验结果如图4 所示。
图4 正交实验极差分析表
本案例的实际结果完全由各单位实际成绩依据实际选取的水平计算获取。实际的水平选取如下:采取了年度集中考核方式(t2),按照“剪枝均值”的专家打分集结规则(m1),运用加权求和的综合评价模型(s1)。对每个单位的8 组实验成绩求均值和方差,可从均值意义上比较潜在结果和实际结果,见表4。
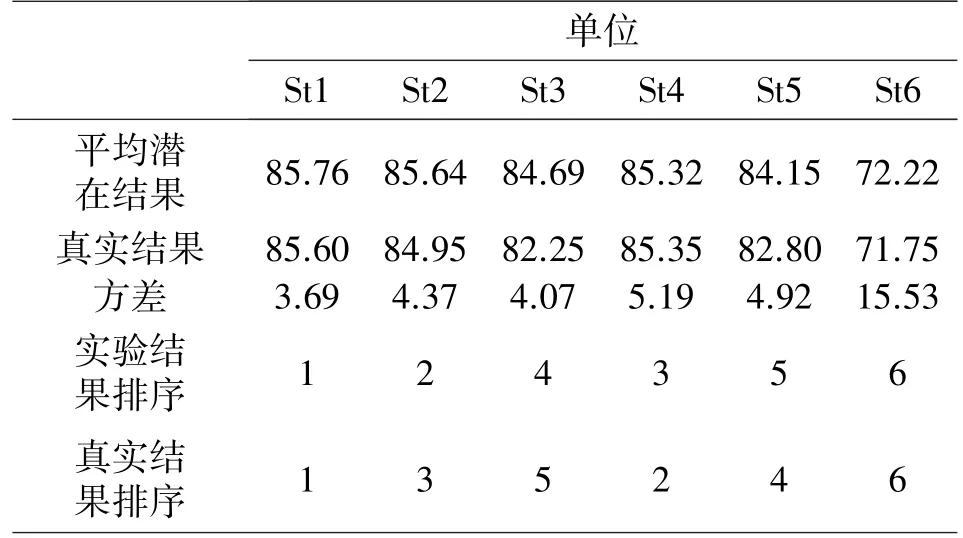
表4 潜在结果与实际结果对比
4.5 结果分析
4.5.1 关键因素分析
极差值衡量因素对结果的敏感程度。根据表3 中的平均极差值,以柱状图方式对各因素的平均极差值进行直观对比,见图5。
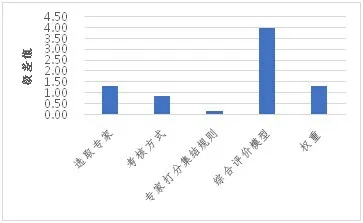
图5 各因素极差对比图
由图5 可知,综合评价模型的极差值最大为4,专家选取和权重极差值次之,分别为1.34 和1.32,考核方式极差值为0.88,专家打分集结规则极差值最小为0.17,表明:一是综合评价模型对结果最敏感,会对结果产生较大影响;二是专家和权重的选择对结果也较为敏感,说明专家和权重选择的差异会在一定程度上影响结果;三是专家打分集结规则对结果最不敏感,无论是剪枝均值还是直接求均值,对于结果的影响不大,这说明几乎不存在刻意打高分(或低分)的专家,专家的打分结果相对比较公正。
4.5.2 实验偏差分析
由表3 得出各组实验的潜在结果,如图6 所示。表明各单位在不同实验中成绩的变化趋势基本一致,但在实验3 中,St3 的成绩相比于其他单位有提高,这与总体趋势有差异。
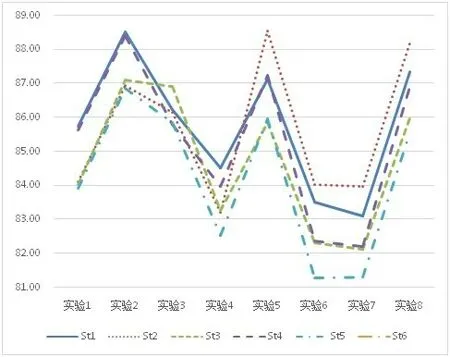
图6 各组实验潜在结果对比图
进一步分析实验3 中St3 成绩“异常”的原因。通过上面的极差分析,综合评价模型和权重是对结果最为敏感的两个关键因素。由表2,St3 的专业训练成绩最高,而实验3 中综合评价模型选择了水平s2(混合法),权重选择了水平k2(基础训练权重0.1,专业训练权重0.6,答辩权重0.3)。水平k2 放大了专业训练的权重,水平s2 又增强了专业训练和现场答辩的相关性,两个关键因素水平的选择均对St3 总成绩提升“有利”。
4.5.3 实验潜在结果与实际结果对比
由表4 可知,从均值意义上比较实验潜在结果和实际结果,如图7 所示。潜在结果各单位成绩排序为St1>St2>St4>St3>St5>St6,实际结果各单位成绩排序为St1>St4>St2>St5>St3>St6。按照成绩由高到低,实验结果和实际结果的评选结果一致,评选出的先进单位均为St1、St2 和St4。
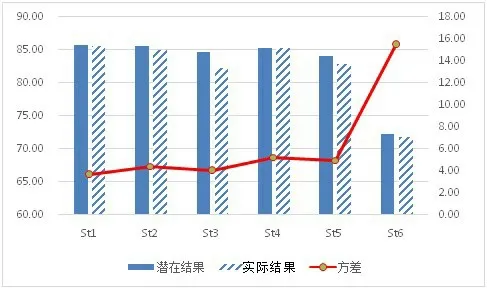
图7 潜在结果与实际结果对比图
单位成绩排序具有一定的差异性,主要是St2和St4 的顺序发生改变,St3 和St5 的顺序发生改变。从实验结果来看,St2(85.64)和St4(85.32)、St3(84.69)和St5(84.15)成绩非常接近,从侧面反映了这两组单位的实力相近。由于实际结果选择的水平一定,可能对某一单位更有利,容易产生实力相近单位成绩排序上的差异,因此,在不影响实际评选结果的前提下,排序差异可以解释。另一方面,单位成绩的方差越大,表明该单位成绩更容易受关键因素水平选取的影响,从侧面反映出单位成绩不稳定、实力水平相对较弱,图7 中St6 的方差最大,成绩却远低于其他单位。
5 总结及展望
基于正交实验的潜在结果模型计算得出的结果与实际结果一致,说明实际评估过程中制定的规则、权重、选择的专家组和综合评价模型等是比较合理的;通过极差分析,能够找到对结果影响敏感的关键因素;从均值意义上比较实验结果和实际结果,能够在一定程度上解释结果的差异和合理性。但也发现一些问题,一是观测数据获取过程中,重现答辩过程是基于重新抽选专家进行问卷调查,与真实情况有一定的误差;二是不同量纲归一化过程中容易放大或缩小实际的差异,造成潜在结果数据的差异。如何减少主观数据的差异,以及评估对象裁剪的独立性,是一项探索性研究工作,需要进一步研究深化。
