汉民双语智能化农业专家系统开发平台与关键技术研究
2022-11-12高翊胡泽林李淼
高翊 胡泽林 李淼
( 1.云南省少数民族语文指导工作委员会办公室 云南省昆明市 650032 )
(2.赣南师范大学物理与电子信息学院 江西省赣州市 341000)
(3.中国科学院合肥物质科学研究院智能机械研究所 安徽省合肥市 230031)
1 引言
农业专家系统是基于农业专家和模仿农业专家进行推理决策的计算机程序系统。人们预先将农业专家为解决某类问题而长期积累的知识以适当的形式存入计算机,计算机利用这些农业知识和反映当时农情的各种数据和事实,模仿农业专家的思维过程进行推理,对需要解决的农业问题进行解答、解释或判断,使计算机在农业活动中起到类似人类专家的作用。从上个世纪末期以来,国内业界围绕农业专家系统涉及到的农业知识获取、推理、智能化处理及集成应用等方面进行了综合研究,研发成功了多套适合国情的“智能化农业专家系统开发平台(以下简称:平台)”[1][2]。在平台基础上开发的农业专家系统拥有多方面、多层次的农业专家知识,能模仿农业专家的思维进行严密的推理,能够集成多项农业生产新技术,加上计算机高速处理能力,无数新技术(数据库管理、软件技术)的应用,它甚至可以作出单个人类专家难以完成的科学决策。平台还能提供各类产前、产中、产后的实用技术,提供市场信息的发布和获取报务。
偏远的少数民族地区以农业生产为主要产业,且农业信息技术较为落后,更显迫切地需要“平台”的大力推广应用。同时也发现了两个重要的问题:一是农业专家系统应用时民族语言的即时翻译;二是“平台”对多民族语言的开放性结构设计。本文论述了基于“平台”的基础,开展结构性改造,研发“汉民双语智能化农业专家系统开发平台(DET)”(以下简称:“双语平台”)的技术内容[3]。
近几年来基于汉民(汉蒙/汉傣/汉藏/汉维/汉彝)语言的机器翻译取得了一定的成就,统计方法已经成为机器翻译方法的主流[4][5][6]。国内外汉英机器翻译的发展非常迅速,相对来说国内汉民机器翻译的研究因受限于语料库规模以及基础关键技术的研究滞后而落后。研究认为,通过汉民机器翻译的一些主要关键技术的研究,可以为今后的我国少数民族语言自然语言处理和机器翻译打下基础,为其进一步的深入研究起到推动作用。
考虑到农业专家用汉语而民族地区的农(牧)户用民语为主,“双语平台”结构被分为两部分:
(1)农业知识获取与处理阶段,以汉语为主;
(2)农业技术咨询及智能推理阶段,汉/民双语同时显示。
同时,针对“双语平台”对多民族语言的扩展性需求,设计并翻译了35000条汉民双语农业词典词条及10万句汉/民双语对齐语料库。并研发了以下翻译训练工具:词语对齐提炼工具、词语评分工具、短语抽取和评分工具、词性标注工具和基于短语的统计机器翻译解码器。
本文在当前汉语版水稻、橡胶、茶叶、青稞、马铃薯专家系统的基础上,利用“双语平台”(DET),研发傣文版水稻、橡胶、茶叶专家智能与藏文版马铃薯、青稞智能系统。具体包括以下两个方面的研究工作:
(1)对已有汉文专家系统知识的归纳和翻译。在平台中集成统计机器翻译模块,基于傣文和藏文的基础词典以及汉傣、汉藏双语基础语料库(包括分词与相应的词性标注),实现汉傣、汉藏双语语料库的对齐,在此基础上结合汉傣、汉藏双语农业语料库,对相应的汉文农家专家系统知识进行翻译,在专家系统中生成提供汉傣、汉藏双语显示窗口,从而提供对傣文和藏文的支持。
(2)系统的调试、测试、翻译文字校正、翻译结果更新。利用拉丁傣文向传统傣文的转换规则,在系统中集成实现拉丁傣文向传统傣文的转换,并基于提供的傣文、藏文字库和相关的输入法,在专家系统中提供傣文、藏文翻译结果的可再编辑与更新保存操作,以便于专家人工干预翻译文字的校正,并允许校正更新后的译文作为今后的翻译结果,实现翻译质量的提高。
2 汉民语料库对齐技术
本部分把双语句子级对齐的语料库训练成双语词语级对齐的文本文件,总体流程如图1所示。

图1:统计机器翻译语料对齐总体流程
主要有三个训练步骤如下:
(1)训练mkcls,用来生成汉语和民语的word class文件,作为GIZA++的辅助程序;
(2)用plain2snt.out训练汉语和民语生成vcb和snt辅助文件;
(3)把上述两个步骤生成的文件作为GIZA++的训练输入文件,用GIZA++双向训练得到两个双向对齐文件,即为我们需要的词语对齐的语料库文件。
词语对齐目的在于找到平行文本中汉/民词汇之间的对应关系。语料需要经过词语对齐的处理,才能成为最重要的、与翻译相关的资源,因此对于统计型机器翻译而言,词语对齐技术十分关键。对齐训练主要的功能是,把双语对齐的语料库训练成双语词语级的对齐,作为翻译模型训练的基础。
3 汉民机器翻译技术
基于统计的汉民机器翻译技术主要包括:语言模型训练、翻译模型训练和解码三方面的内容。
3.1 语言模型训练
语言模型训练首先对目标语言文本文件进行分词,然后交给语言模型训练模块进行训练,训练速度平均为2MB/S。训练时可以选择不
同的平滑算法以生成不同的语言模型。工作流程为:对文档进行概率统计和数据稀疏平滑处理,得到经过平滑处理后的N元语言模型,储存时以ARPA格式表示该N元语言模型,以文本文件或二进制文件格式存储该语言模型,如图2所示。
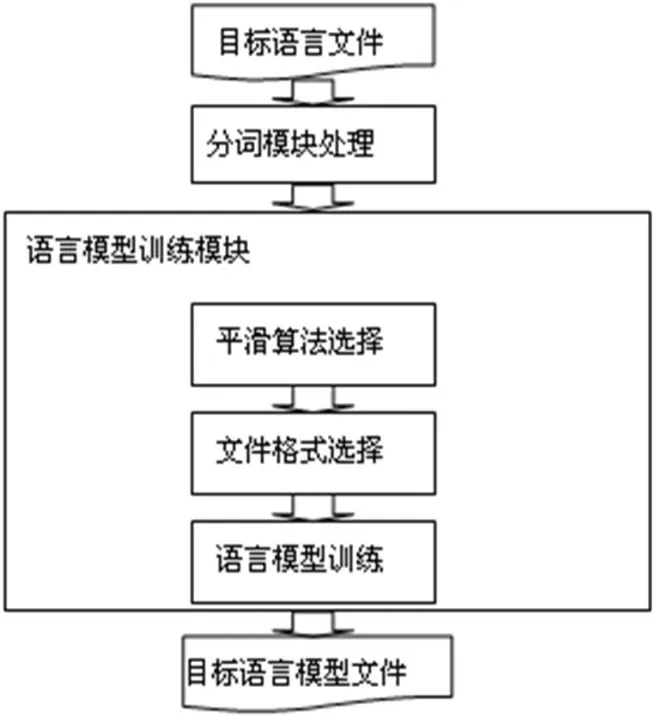
图2:语言模型训练工作流程
该模型包括以下外部接口:
(1)-order:该参数用来设置语言模型的N元大小;
(2)-text:该参数用来设置的读入的目标语言文件格式为文本文件格式;
(3)-gtn:该参数用来设置平滑算法为Good-Turing加Back oあ平滑算法;
(4)-interpolationn:该参数用来设置平滑算法为插值平滑算法;
(5)-knn: 该参数用来设置平滑算法为Kneser-Ney平滑算法;
(6)-lm:该参数用来设置生成目标语言模型文件。
3.2 翻译模型训练
翻译模型训练是使用已将汉/民两种词语对齐的语料库训练出系统所需的短语翻译模型。在将双向词语对齐的语料库基础上,首先利用对齐提炼技术从双向对齐结果中提高双语词语对齐的精度,再在对齐提炼的基础上计算出词典概率评分,同时抽取双向对齐的短语对。最后,在短语抽取和词典评分的基础上构建出双向短语翻译模型。整个训练过程为:从双向对齐结果中进行词语对齐的提炼,对词语对齐的双语语料库进行双向的词典概率计算和短语抽取[7],利用抽取的短语和词典概率构建短语翻译模型,具体如图3所示。

图3:翻译模型训练流程
该模型包括以下外部接口:
(1)对齐提炼的接口:--forward 源到目标的对齐输入;--reverse 目标到源的对齐输入;--alignment 指定提炼方式,取值为intersect、union、grow-diag-final,分别表示求交集、并集以及对齐提炼结果;
(2)词典评分的接口:-i选项指示对齐结果文件;-s选项指示源语言文件;-t选项指示目标语言文件;
(3)短语抽取的接口:-i选项指示对齐结果文件;-s选项指示源语言文件;-t选项指示目标语言文件;
(4)短语评分的接口:-extr选项指示短语抽取结果文件;-lexs2t选项指示源到目标的词语翻译概率文件;-lext2s选项指示目标到源的词语翻译概率文件。
3.3 即时解码技术
解码器的作用是根据从训练语料文本中学习到的语言模型、翻译模型以及其他附加模型的信息来确定被翻译的源句子最可能的目标翻译句子。其输入是翻译模型、语言模型、其他模型以及源语言句子,输出源语言句子最可能的对应目标句子。由于可能的目标句子很多,通常解码算法只能搜索n个最好(N-best)的可能目标语言句子。整个解码过程为:加载目标语言语言模型,加载短语翻译表,生成翻译选项表及将来概率表,对输入的源语言句子进行柱搜索解码,搜寻最佳翻译,回溯生成N-best译文,如图4所示。

图4:解码过程
该模型包括以下外部接口:
(1)配置信息输入接口,主要负责从配置文件和用户终端读取用户指定的配置参数,并提供配置参数的获取接口,此外接口处理模块还提供各类信息的打印功能。
(2)翻译结果输出模块,负责将翻译结果输出。
该模型包括以下内部模块:
(1)配置信息处理模块:一方面负责从接口类中读取配置的结果,并将结果进行处理获取最终配置信息;另一方面对配置信息的输出,以及各类结果的输出。
(2)语言模型处理模块:本模块主要是加载目标语言模型资源,并提供各种对语言模型评分的计算接口。
(3)短语翻译模型处理模块:主要是从短语翻译表中读取短语翻译模型资源,并提供对外的获取短语翻译值的接口。
(4)翻译选项处理模块:本模块负责从源语言句子中,根据短语翻译模型抽取出所有可能的短语翻译选项(包括未登陆词)。
(5)将来概率处理模块:根据所收集的翻译选项及其评分值,采用动态编程的方法构建一个将来概率表,将来概率表中的内容代表所指源句子词语翻译围内语言模型与翻译模型评分和最小的翻译选项的值。
(6)假设处理模块:假设处理模块封装了假设的动态构建、假设的评分、假设基本信息设置与获取以及假设栈的管理功能。
(7)栈解码算法模块:此模块为解码器的解码算法核心,根据配置参数模块的要求,调用翻译假设处理模块的功能,根据beam search算法的思想进行假设扩展,完成动态翻译的过程。
(8)Nbest回溯模块:此模块的功能就是负责从扩展的最后一个假设栈中开始回溯,找到要求的所有Nbest结果。
在统计机器翻译中,解码器利用训练得出的统计模型和附加语言特征模型,从语料文本中获得最可能的译文。解码搜索目标数据量很大,导致解码工作效率都比较低,统计机器翻译研究的关键就是解码器的研究。基于短语的统计机器翻译方法是目前广泛研究的方法,在此基础上,我们结合多个模型因子,开展解码器的设计与优化技术的研究。
4 知识搜索与即时翻译技术
即时翻译就是在运行过程中,针对人机交互中出现的汉语提问和回答,进行相应民族语言翻译,即在屏幕上同时出现汉/民双语的交互文字。出于提高速度的目的,对即时翻译我们采用了C/S结构和消息传递,对于运行过程中出现的每一个中文语句,经过文本断句、中文分词后,翻译请求模块发送消息给翻译服务模块,翻译过程结束后,结果返回到翻译请求模块,通过消息传递,将翻译结果发送到民族语言显示模块,在人机交互的屏幕上显示出来。为了避免重复翻译并提高翻译速度和精度,在模块中我们增加了翻译记忆功能,该功能程序是以DLL+数据库+推理界面共同构成的。DLL是一个将文本断句、中文分词、翻译服务等程序共同组成的动态连接库,数据库用于存储翻译记忆,与平台的农业知识推理模块进行汉/民翻译交互。
4.1 文本断句与分词
本部分主要用来对需要短句和分词的文本文件进行加工,将文本文件断句,然后把断句结果交由分词模块处理,分词模块首先通过切词算法并配合词典检索算法对一个句子进行预切分处理,这样得到一个句子的多种切分可能,然后所有这些可能交由后面的概率平滑处理模块处理,经该模块处理之后,需再将处理结果交由后面的分词最终结果确定模块,这样分析并最终生成一个分好词的文件。总体流程如图5所示。该模型包括以下外部接口:

图5:文本断句与分词流程
(1)文本断句接口;
(2)文件处理接口;
(3)句子处理接口。
该模型包括以下内部模块:
(1)文本加载模块:用于加载待断句和分词的文本文件;
(2)文本断句模块:用于对文本文件进行断句;
(3)词典加载和检索模块:用于加载分词词典同时提供词典检索接口;
(4)特定领域支撑系统模块:用于提供对特定领域词汇切分的支持;
(5)词语预切分模块:用于对待分词的文本进行预切分;
(6)局部歧义词网格模块:用于对预切分生成的词构建局部歧义词网格;
(7)最短路径生成模块:用于确定局部歧义词网格的最短路径;
(8)最终结果输出模块:用于输出分词的最终结果。
4.2 翻译请求与服务
采用C/S的结构实现翻译请求和服务功能。通过客户端发送翻译请求,服务端接受请求并调用解码过程进行翻译将翻译的结果返回给客户端。这种结构可以实现本地或远程之间的进程间通信。为了提高传输速度,本地请求可以直接发送本地的文件名指定要翻译的文件和翻译结果文件,远程请求利用进行逐句的翻译。在请求完成后,服务端发送完成信息关闭请求。工作流程如图6所示。

图6:翻译请求和服务工作流程
该模型包括以下外部接口:
(1)翻译请求接口:-sfile:制定要翻译的源文件;-tfile: 指定要接收的翻译结果文件;-port: 指定翻译服务端的端口;-serverIP: 指定翻译服务端的IP地址,可以使用127.0.0.1和local host指定为本地。
(2)翻译服务接口:参数: -port: 翻译服务要侦听的端口,用于侦听翻译请求。
该模型包括以下内部模块:
(1)翻译请求发送模块:用于翻译请求端向翻译服务端发送正确的翻译请求信息。
(2)翻译结果接收模块:用于翻译请求端从翻译服务端接收翻译结果。
(3)翻译服务接收模块:用于接收翻译请求信息并提交给解码器进行翻译。
(4)解码模块:利用模型资源,采用beam search算法根据对输入的源句子进行翻译,返回翻译结果。
(5)翻译服务发送模块:从解码模块中获取翻译结果发送给翻译请求模块,同时控制翻译结束时翻译请求的关闭。
4.3 民文显示与推理
本部分把知识搜索及推理过程中出现的汉文翻译成民文,并按民文的语法习惯正确的显示出来。其主要功能包括:
(1)知识搜索:根据提供的知识库按照要求搜索出相应的知识;
(2)推理结果翻译:把推理过程及推理结果出现的农业知识文本翻译成民文的知识文本;
(3)民语显示:把民族语言推理结果在网页中按民文的语法正确地显示出来。在构建汉民机器翻译系统时,需要将民语转换为拉丁形式。对于翻译出来的拉丁民语,再转换成传统民语。
整个搜索及其翻译流程的具体步骤为:
(1)把咨询及智能推理工作中的汉语推理结果进行文本断句。
(2)把咨询及智能推理工作中的信息记忆在数据库中。
(3)对进行文本断句得出的结果进行汉语分词。
(4)分词后,把结果传给发送请求模块并由发送请求模块对分词后的结果进行打包。
(5)建立客户端并通过它向翻译服务模块发送要翻译的文件。
(6)翻译服务器端响应翻译请求,把应答的结果返回给接收端。
(7)接收端接收到翻译后的结果进行民族语言的内码转换。
(8)转换后的民文就可在结果显示界面上正确显示,即为推理后的汉/民双语咨询结果。
1.推理路径显示窗:左边的窗口用来显示推理路径,并且允许用户进行跳跃式推理;
2.交互视图:右边的视图用来与用户交互信息,包括不同类型视图的转变及切换都在此进行。右边有两个窗口,一个显示中文,一个显示民文,推理过程还可以用民文操作。如图7所示。

图7:推理过程中的汉蒙、汉藏、汉傣、汉彝双语交互视图
3.最终推理结果视图,包括两部分,一是汉文的推理结果,以WEB的形式显示;二是民文的推理结果,以对话框的形式显示。推理结束时同时显示汉文和民文的推理结果,民文显示直接弹出一个对话框,两种文字的推理结果都有保存和打印功能。在民文的窗口的右边是保存和打印的按钮,可以把民文的推理结果保存在指定的路径。如图8所示。

图8:最终推理结果傣文视图
5 结束语
智能化农业专家系统开发平台是机器翻译技术在农业智能系统中的一个基本应用,平台中集成了汉民翻译模块,基于傣文、藏文和彝文的基础词典以及汉傣、汉藏、汉彝双语基础语料库(包括分词与相应的词性标注),实现汉傣、汉藏双语语料库的对齐,在此基础上结合汉傣、汉藏双语农业语料库,对相应的汉文农家专家系统知识进行翻译,在专家系统中生成提供汉傣、汉藏双语显示窗口,从而提供对傣文和藏文的支持。主要包括语料库对齐技术、民文编码转换技术、汉民机器翻译技术/汉民对应文本查找技术。在原DET推理机的基础上融入了汉民机器翻译与对应文本查找功能:一方面可以使用机器翻译机制对知识库汉文进行翻译得到对应的民文;另一方面能够直接查找汉文对应的已翻译的民文文本实例,并进行相应的结构化显示。
