基于EEG的战场适应性模拟训练情绪分析方法
2022-11-12罗超元
罗超元
(陆军步兵学院 江西省南昌市 330103)
1 引言
残酷激烈的作战情景容易激发一线指战员的高度忧虑和紧张等负面情绪,导致其思维上的迟钝甚至混乱,严重影响作战指挥效能。战场适应性模拟训练系统提供高度逼真的战场环境,能够较好地培养一线指战员在残酷战场环境中的心理稳定能力和承受能力[1]。在适应性训练过程中,了解参训者的情绪状态是验证训练有效性必不可少的环节,施训人员以往通过参训者的自我描述了解人员心理变化,以评估训练的效果,然而,该方法受主观性影响较大,存在较大的弊端。近年来许多学者提出一种基于脑电信号的情绪识别方法,为分析参训者的情绪状态提供了一种新手段。
目前,基于脑电信号的情绪识别主要建立在公开的数据集上,比如上海交大情感脑电数据集(SEED)[2]、生理信号情绪分析数据集(DEAP)[3],MAHNOB-HCI数据集[4]。主要研究路线有两条:
(1)将脑电信号数据直接输入神经网络进行分类器的训练,通过调整网络结构和训练策略来提升情绪识别的准确性[5-8]。比如周双如等[5]提出一种结合卷积残差网络、双向门循环网络与注意力机制网络的情绪识别模型,在DEAP数据集上进行情绪的二分类测试,唤醒度和效价的分类准确率分别达到96.95%、97.22%。贾巧妹[8]等在ScaleNet网络的基础上提出一种结合提升算法与梯度下降法的双策略训练方法,在DEAP数据集上进行情绪二分类测试,有效提升了模型的泛化性能。戴紫玉[9]等提出基于多尺度卷积核的卷积神经网络分类模型,在SEED数据集上进行情绪三分类测试,将分类准确率提升至98.19%。
(2)事先根据经验手动提取数据特征,再利用特征对模型进行训练,通过改变特征的类别、对特征进行组合、模型参数的调整等方式提升准确率[10-14]。提取的特征包括频域和时域特征[14],以及近似熵、模糊熵、微分熵等各种信息熵特征和融合特征[16]。比如,柳长源[13]等将不对称熵特征输入支持向量机进行训练,在DEAP数据集上进行压力与平静情绪状态的二分类测试,准确率最高达到93.75%。廖健熙[10]等提取微分熵及常用的统计特征输入随机森林进行训练,在自建数据集上进行情绪三分类测试,平均准确率达到97.87%。
从上述研究中可以发现,情绪识别研究集中于提升模型的识别准确率,却忽视了识别的分辨率,例如,建立在SEED数据集上的研究多以三分类(消极、积极、中性)研究为主[17-18],建立在DEAP数据集上的研究多以二分类研究为主[6,19-22]。利用这些成果无法精细化了解人的情绪状态,难以在现实应用层面中发挥效用。基于上述研究现状以及战场适应性模拟训练的现实需求,本文提出一种基于排列熵和功率谱特征的卷积神经网络情绪分类模型,从EEG信号中提取特征对模型进行训练,在情绪二维模型的两个维度上分别进行情绪八分类,通过实验结果的对比与分析,以期证明模型在情绪分类准确率和分辨率上的优越性,从而为战场适应性模拟训练提供一种更加有效的情绪分析方法。
2 分析方法描述
脑电是随时间连续变化的序列信号,对脑电信号进行分析,可以了解人员内在的情绪状态。本文基于脑电对情绪进行的分析,建立在情绪的二维模型基础上,第一个维度是唤醒度,用于度量情绪从平静到兴奋的激活程度;第二个维度是效价,用于区分正性和负性情绪。用二者刻画情绪可在二维空间形成一个平面,每一个坐标都有一个值来指代一种状态的情绪,据此可以初步了解人的情绪状态,如图1所示。

图1:情绪二维模型
3 模型构建
如图2所示,在构建模型时,首先对用于模型训练的数据进行预处理和扩展,然后提取排列熵与功率谱作为特征,再将特征输入到两个8分类网络结构,分别以不同的情绪标签(唤醒度、效价)进行网络的训练,从而得到情绪分类器。
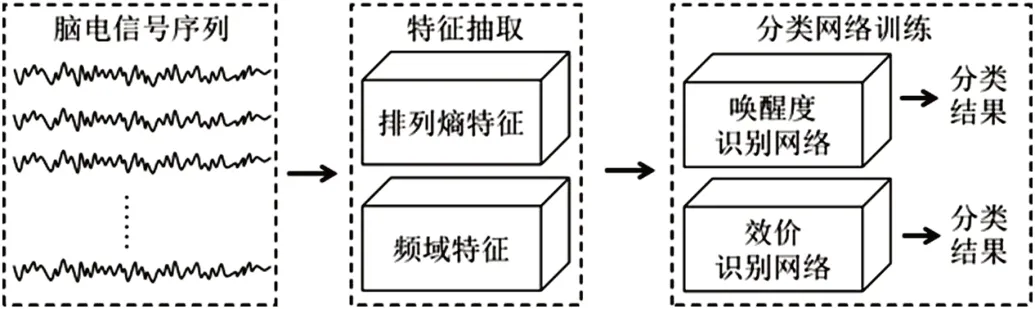
图2:模型主要结构
3.1 数据预处理
本文采用DEAP数据集对模型进行训练和测试,该数据集包含对32名被试在情绪诱发实验中脑电信号的记录[3]。在情绪诱发实验中,每个被试观看40个时长为1分钟的视频,记录了被试观看视频时32个电极的脑电信号。相关研究表明仅使用少量电极通道的信号即可以较高的准确率完成识别[21],为减少信号冗余的并加速模型的训练速度,本文仅使用其中的14个电极信号,包括AF3、F3、F7、FC5、C3、P7、O1、AF4、F4、F8、FC6、T8、P8、O2,因此一共使用32×40×14个脑电信号序列。使用数据为经过预处理之后的脑电信号序列,预处理采用降采样至128Hz、去伪迹、4-45Hz滤波、平均重参考四个过程对原始信号进行处理,最终每个信号序列长度为7680。
此外,对较为庞大的网络模型而言,用于模型训练数据量有限,为减少训练过程中的过拟合的可能性,特征提取之前在原数据的基础上进行分割扩展,在每段分割后的信号数据上抽取特征。数据分割扩展采取以下方法:以16为步长,使用大小为256的重叠式滑动窗口对每个信号序列进行分割,如图3所示,进而将每个信号序列转换为465个子序列。此后的特征提取过程中,在每个子序列上提取N个特征值,14个电极信号特征拼接以后形成长度为14×N的一维特征序列,最终得到595200条特征样本序列。

图3:基于重叠滑动窗口的数据分割
DEAP数据中除脑电信号数据外,数据还包括被试对自身情绪状态的自我评价值,包括唤醒度(arousal)、效价(value),取值区间为[1,9]。为实现8分类的目的,将区间进行8等分,落在每个区间内的值归为不同类别。
3.2 排列熵
熵特征中,排列熵具有算法简单、速度快、能够抵抗环境干扰影响等优点,在机械设备状态监测、故障诊断以及心率、血压信号检测中都比较有用,广泛应用于特征提取的领域当中,本文从多个尺度提取脑电信号的排列熵值,以确保特征的多样性,具体实施步骤如下:

其中k=n-m+1,矩阵有k个重构分量,每个分量中嵌入m个元素。
(2)将重构矩阵中的第j个分量x(j),x(j+τ),...,x(j+(m-1)τ)进行大小排序,得到:
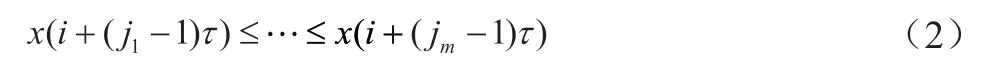
(3)每个重构分量都重复步骤(2),得到k个重构符号序列S(l)=(j1,j2,...,jm),l=1,2,...,k。

(4)计算每一种m维符号序列出现的概率P1,P2,…, Pk,再得出序列的排列熵值:

本文中的嵌入维数m与延时τ的取值定为(3,10)、(4,9)、(5,8),分别从上述3个尺度提取时间序列的排列熵特征,并作归一化。
3.3 功率谱
频域特征中,部分频段与人的情绪活动有着紧密的联系[22],且有相关文献介绍到特定频段内的脑电信号对与情绪识别的准确率较高,比如β(14-30Hz)、γ(31-50Hz)[23]。本文模型中提取多个频段内的功率谱均值作为频域特征,频段区间设定为[4,8],[8,12],[12,16],[16,25],[25,45]。第i个频段区间的功率谱特征可用如下公式计算:

其中,{xi}是原始信号序列,{Xk}是其傅里叶变换系数,N为区间长度。
3.4 网络结构
为能够在唤醒度与效价两个维度上实现预期的分类效果,以卷积神经网络为基础,设计12层的一维卷积神经网络结构,主要参数如表1所示。
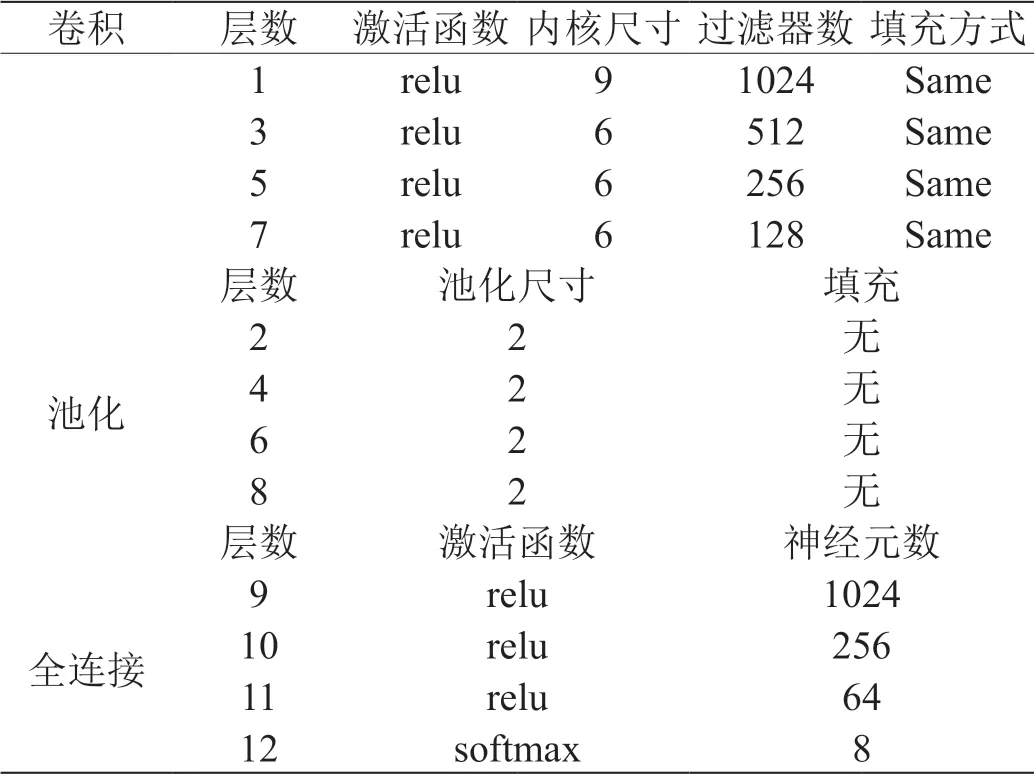
表1:网络主要参数
(1)卷积层:网络输入形状为N×1(特征数量×1),第一层卷积使用1024个大小为9×1卷积核对输入特征进行卷积操作,第3、5、7层卷积核尺寸设置为6×1,每层卷积核数量按比例2递减,所有卷积层的激活函数设置为relu。
(2)池化层:每个卷积层后进行一次最大池化操作,池化尺寸设置为2。
(3)全连接层:最后经过4个全连接层,每层神经元数量分别为1024、256、64、8。其中,最后一个全连接层的输出函数使用softmax,得到输出形状为8×1的分类结果。
3.5 训练策略
为使得输出结果符合预期,在训练网络过程中采取以下几项策略:
(1)输入网络前,将每个特征进行z-score标准化。用全部训练样本对网络进行120次训练,取最优的结果。
(2)将特征样本按照初始顺序,以取7留1的方式分隔为训练样本与测试样本,训练过程软件基于keras2.9.0,硬件基于NVIDIA RTX3060 GPU,网络初始权重默认值,采用adam算法进行权重调整,训练批次大小设置为256。
(3)第8层的最大池化操作后,进行一次平展操作,将第8层的输出平展为一维向量,以便与全连接层衔接。

表3:基于不同特征的效价分类指标
(4)为防止网络深度增加而导致的层间特征值分布逐渐向激活函数的输出区间的两端聚集,进而引起导致梯度消失。在1、3、5、7层的每次卷积操作后,进行批次归一化处理(BN),将每层的输出值分布重新调整回标准正态分布,输出值将落在激活函数自变量的敏感区间,使损失函数产生较大的变化,避免梯度消失,加快模型的收敛。
(5)由于网络规模较大,为加速训练过程及避免网络过拟合问题,在训练该网络时,使用随即丢弃策略冻结9至11层中的部分神经元(Droupout),概率取20%。
3.6 模型评价指标
从准确率、查准率(P)、查全率(R)与F1分数(F1-score)几个指标对模型进行评价,由于该模型属于多分类模型,因此在评价中以Macro-average方法对P、R与F1-score进行了处理,Macro-average适用于多分类问题,不受数据不平衡影响,核心计算过程如下:
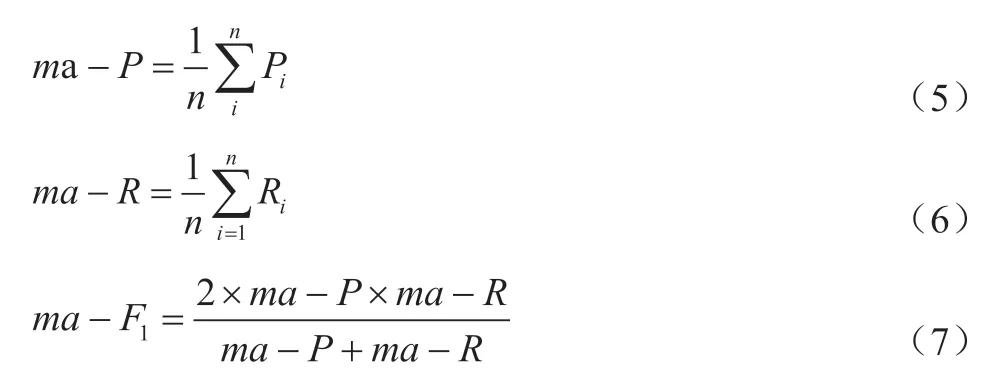
其中n=8,Pi、Ri为第i个类别的查准率与查全率。
4 模型测试
将训练好的模型用于测试数据,对其进行8分类测试,从分类结果中计算各项评价指标对模型进行对比分析。
4.1 基于不同特征的模型对比
分别用排列熵、功率谱以及二者拼接后的特征训练出的模型对测试数据进行分类,从表2、3所记录的结果中可以看出:

表2:基于不同特征的唤醒度分类指标
(1)单一特征与组合特征训练出的模型,二者的查准率皆高于查全率,说明模型在分类时表现的比较谨慎。
(2)排列熵与功率谱二者组合后训练出的分类器,在唤醒度和效价上的分类准确率达到96.30%、96.23%,效果明显优于用单一特征训练出的分类器。此外,查准率、查全率、F1-score均有明显的提升。结果表明将两种特征进行组合可有效提高情绪分类器的准确率。

表6:不同分类器效价分类指标(单位:%)
4.2 多模型对比
为验证本文模型的优越性,将排列熵与功率谱特征组合后输入4种常用的分类器进行训练,包括K邻近(KNN)、随机森林(RF)、逻辑回归(LR)、朴素贝叶斯(NB),并对分类结果进行对比。训练过程依托Scikit-learn1.0.2进行,4种常用的模型的主要参数设置如表4所示。

表4:模型参数设置
对分类结果测试指标进行计算,得到表5、6中的一系列结果,从结果可以看出:
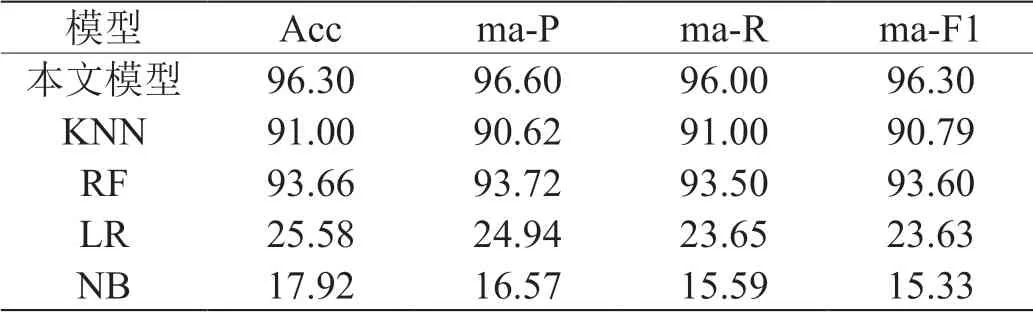
表5:不同分类器唤醒度分类指标(单位:%)
(1)本文中构建的模型在各项指标上的表现最佳,RF综合表现较好,仅次于本文中提出的分类模型,主要原因在于,研究中训练数据包括520800条样本,特征维度为112,属于比较大的数据量,因此RF比较适用于数据量较大时的情况,且能够处理高维度的特征数据,因此其准确率等各方面表现较好,KNN表现仅居其后。
(2)LR与NB的表现较差并不理想,一方面是为特征空间较大;另一方面是文中使用的特征之间不能保证相关性大小,部分特征可能具备一定较强的相关性,比如从多个尺度提取的排列熵特征,因此LR与NB不适用于本文的分类任务。
综上所述,本文提出的基于排列熵与功率谱特征的卷积神经网络分类模型用于情绪分类的效果最好,在唤醒度和效价上的分类准确率达到96.30%、96.23%,比表现最好的RF分别提升了2.64%、2.43%。
5 结论
本文构建了一种基于排列熵与功率谱特征的卷积神经网络情绪分类模型,并用DEAP数据集对模型进行了测试,研究结果表明:
(1)本文模型能同时保持以较高的分辨率和准确率,从唤醒度、效价两个情绪维度上的对脑电信号进行分类。
(2)本文构建的12层网络模型比传统的分类模型更具优越性:与传统分类模型中表现最好的模型相比,本文模型在唤醒度和效价分类上的准确率分别提升了2.64%、2.43%。
(3)将排列熵与功率谱特征进行组合后,有助于提升模型的性能,利用组合特征训练出的模型在各项测试指标上都有明显的提升,综合表现比利用单一特征训练出的模型表现更好。
研究成果为战场适应性模拟训练情绪分析提供了一种可行的手段,同时,为后续情绪识别研究提供了研究思路,下一步情绪分析研究可以向更高分辨率的方向发展,从而更精准的识别人在各种活动与作业过程中的情绪状态。
