遥感影像数据和机器学习算法空间分布信息自动分类提取
2022-11-12沈成王洋王红兵蒋俊祎
沈成 王洋 王红兵 蒋俊祎
(海口海洋地质调查中心 海南省海口市 570100)
红树林是大自然最重要的生态系统之一,在海岸带生态保护上有着不可替代的作用。我国红树林主要分布在沿海的河口、泻湖和海湾等地区,其面积在过去几十年经历了“急剧减少-维持稳定-缓慢增加”的变化过程[1]。红树林是汕头湿地生态系统的重要组成部分,而流经于此的韩江,则是我国海岸线最长、红树林面积最大的广东省第二大河流,为我国六大三角洲之一。韩江三角洲地区的生态保护对沿海地区经济发展和生态安全具有重要意义[2]。
历史上韩江三角洲地区红树林分布广泛;改革开放初期,由于人为围垦开发,仅余一些次生林,面积缩减超过50%[3];自2000年开始,当地政府重视沿海红树林生态环境问题,种植了一定规模的红树林,并引种了无瓣海桑等红树林树种,现阶段主要为人工林[4][5]。
近年来,遥感技术的不断发展和机器分类算法的崛起加快了图像识别的智能化进程,当前,已有许多先进的机器集成算法和分类器已经运用到了遥感图像分类。通过对遥感数据进行充分挖掘和分析,不仅优化了了传统图像分类上数据处理信息损失问题,还大大降低了人力消耗和人为主观因素造成的误差。近几十年来,机器学习算法的发展从较为简易的监督分类、BP神经网络分类方法逐渐发展到RF(随机森林)、CNN(卷积神经网络)等高新的机器分类算法,这极大地提高了遥感影像分类的精度以及速率[6]。
我国也已有众多学者将机器学习的图像分类技术用于红树林的种间识别上,并取得了卓越的成绩。马云梅等[7]利用GF-2数据,通过对光谱特征数据重构,基于支持向量机分类方法,对广西海岸带红树林开展种间精细分类研究;蒙良莉[8]等基于哨兵光学影像数据,利用随机森林算法进行特征选择,并构建多种特征组合方案,成功的对区内红树林进行识别和提取;袁胜[9]利用GEE云平台结合广西沿海地区红树林实地调查数据,基于像元的随机森林方法识别、提取研究区红树林,验证了随机森林在红树林识别上的优势。基于此,本研究拟采用随机森林和支持向量机的机器学方法,开展韩江东溪入海口红树林空间分布信息分类提取研究,并横向对比其分类精度。
1 研究区概况与数据预处理
1.1 研究区概况
研究区位于汕头市澄海区韩江三角洲出海口,由北港入海,东北接潮州市饶平县,西北接潮州市,西南毗邻汕头市龙湖区,东与南澳县隔海相望,地理坐标为东经116°50-116°53',北纬23°26'- 23°30'。沿海潮汐为不正规半日潮,平均潮差约1m。沿海潮间带以红树林为主,树种主要为无瓣海桑、秋茄和少量桐花树。如图1所示。
图1:研究区红树林分布图
1.2 数据预处理
本文的遥感影像来自于美国地质调查局(USGS)网站(https://glovis.usgs.gov/),云量低于5%,整体质量较好,获取日期为2021年2月22日(Landsat 8 OLI影像数据)性。在ENVI5.3平台,对影像数据进行预处理,通过辐射定标、大气校正和正射校正,消除大气吸收、大气散射和地形起伏造成的误差,得到可用于研究的数据。如图2所示。
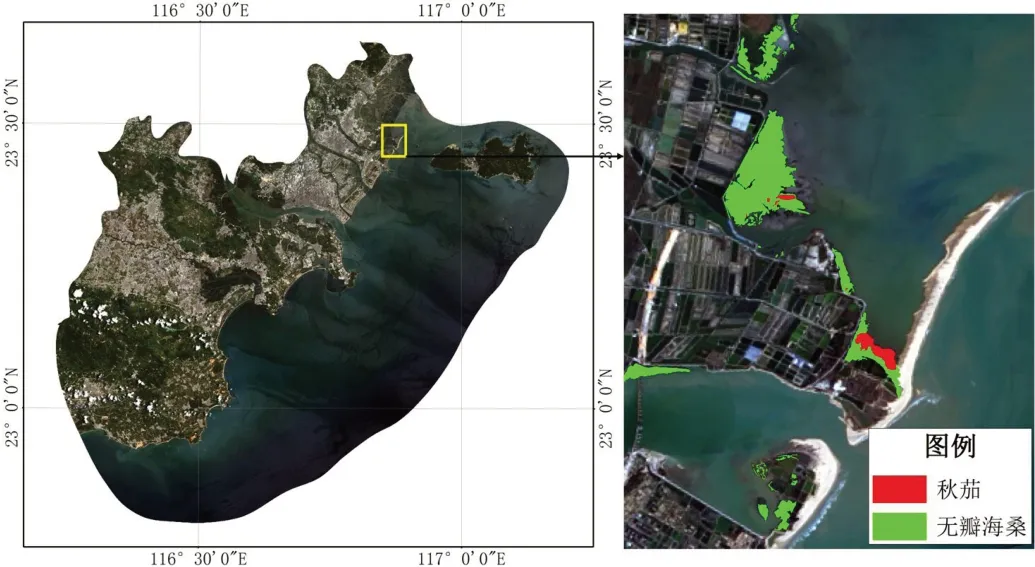
图2:研究区区位图和Landsat8遥感影像图
2 研究方法
2.1 随机森林分类(RF)
随机森林(RF)是由很多决策树分类模型组成的组合分类模型,他的工作思路是:首先,利用bootstrap抽样从原始训练集抽取k个样本,且每个样本的样本容量都与原始训练集一样;其次,对k个样本分别建立k个决策树模型,得到k种分类结果;最后,根据k种分类结果对每个记录进行投票表决决定其最终分类。其实质是将样本不断放回并进行多次取样形成训练集,通过决策树的组合对预测结果求平均来进行预测,这种算法主要考虑决策树数量以及分割结点的数量这2个参数。通常情况下,随着决策树数目的增加,分类的精度为先增加后趋于平稳。
2.2 支持向量机分类(SVM)
支持向量机是非线性模式分类算法中最先进的算法之一,是一种建立在统计学习理论基础上的机器学习算法。支持向量机的基本思想是在特征空间中找到一个超平面,将不同类别的分离距离最大化,离该超平面距离最近的数据样本为支持向量。由此构造出分类器,可以将类与类之间的间隔最大化,因而有较好的推广性和较高的分类准确率。与其他分类算法相比,支持向量机对训练样本的数量要求不高,如果样本数量相对较少,支持向量机可以获得更高的分类精度。
2.3 归一化植被指数(NDVI)
归一化植被指数(NDVI)是红光波段和近红外波段的数学计算,主要用于监测植被生长状态、植被覆盖度,是目前是应用最为广泛的指数之一。本研究在ENVI5.3上利用Landsat8近红外和红外波段进行计算,公式如下:

式2.3中,b5为OLI数据的近红外波段反射率值,b4为OLI数据的红外波段反射率值。
3 结果与分析
3.1 分类结果
此次研究,通过RF和SVM的分类方法,对韩江东溪入海口的红树林空间分布信息进行自动分类提取,分类结果中不可避免地会产生一些面积很小的图斑,为提高分类精度,利用Majority/Minority分析进行类后处理,从而得到研究区红树林RF和SVM自动分类提取结果,如图3。
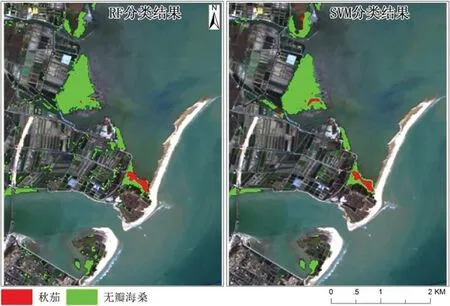
图3:研究区红树林自动分类结果(做:RF 右:SVM)
3.2 精度评价
结合野外踏勘建立解译标志,利用高分辨率遥感影像进行遥感解译,得到红树林高精度分类结果图,以此作为检验样本,通过利用秋茄和无瓣海桑的分类结果,构建混淆矩阵。总体分类精度(OA)和Kappa(K)系数作为评价标准,其中,总体分类精度等于被正确分类的像元总和除以总像元数。具体表达式如此下:
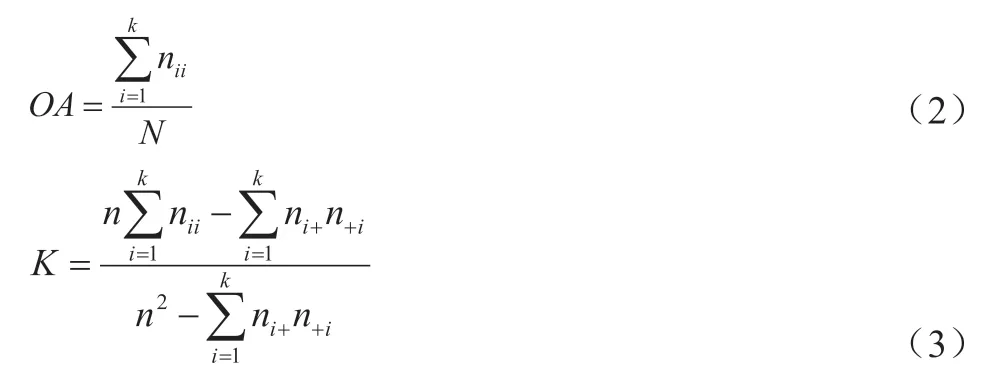
其中,n表示总的样本点数,对角线样本为nii,ni+为某一类中地表真实像元总数,n+i被分类像元总数,k表示总的分类类别数目。
由表1可得出,利用RF分类模型对红树林空间分布信息的自动提取分类精度为94.5066% ,Kappa系数为0.6939,利用SVM分类模型对红树林空间分布信息的自动提取分类精度为92.9253% ,Kappa系数为0.6409,由此可得出,针对研究区利用RF分类模型的红树林空间分布的提取效果优于SVM方法。结果显示,两种分类方法均对无瓣海桑有较好的提取精度,均优于95%。针对秋茄的分类精度较低。
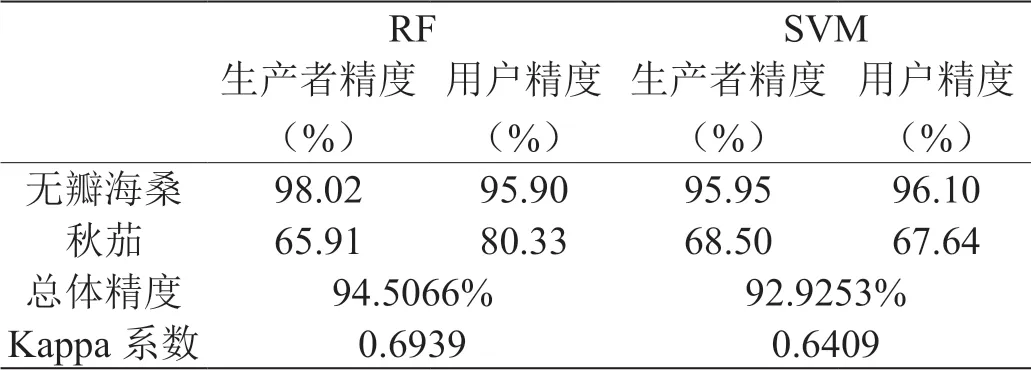
表1:基于RF和SVM的红树林分类结果精度评价
在分类中,错分误差和漏分误差也是两种比较重要的评价指标。
由表2可知,无瓣海桑的分类误差较低,秋茄由于光谱特征的弱特征性,易被识别为无瓣海桑及其他地物。
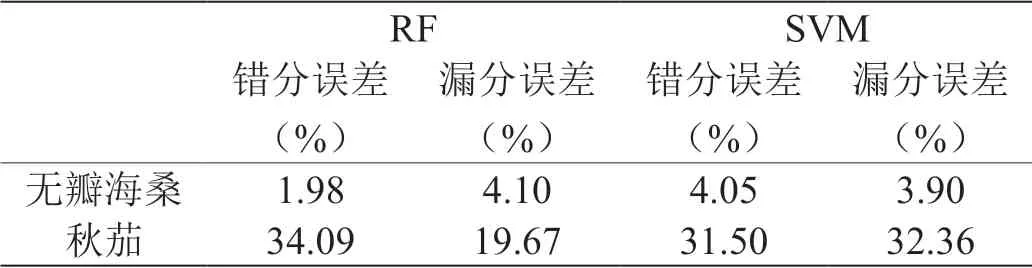
表2:基于RF和SVM的红树林分类结果误差比较
3.3 投入NDVI评价因子分类结果评价
上述对比结果表明, 随机森林在分类结果上优于支持向量机。因为NDVI对于区分植被生长状态有着良好的优势,为了进一步提高随机森林的分类结果准确性,有效增加无瓣海桑和秋茄的光谱特征分异性,利用Landsat8数据计算研究区的NDVI,并作为分类指标因子投入到RF模型中,利用机器学习对红树林进行进一步分类,分类结果如图4。

图4:结合NDVI的RF自动分类结果
构建投入NDVI评价因子分类的混淆矩阵,评价结果如表3所示。
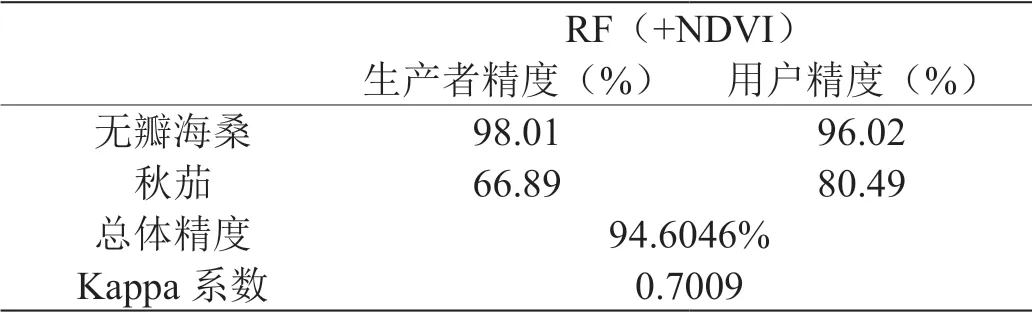
表3:投入NDVI进行RF分类精度评价结果
由表3可知,在分类体系中加入NDVI评价因子后,自动提取分类精度为94.6046% ,Kappa系数为0.7009。相较于直接利用RF模型进行分类提取,分类精度提高了0.098%,Kappa系数提高了0.007。结果显示,投入NDVI评价因子参与红树林空间分布信息自动提取分类,精度有所提高,虽然增幅较低,但为提高红树林分类精度提供了一种可行性。
4 结论
以汕头市澄海区韩江东溪入海口红树林分布区为研究区,利用Landsat8遥感影像,结合红树林实地调查数据,分别采用随机森林和支持向量机分类方法进行红树林空间分布信息自动识别提取,并构建混淆矩阵进行精度验证及对比。研究结果表明:
(1)在光谱特征基础上,利用多光谱遥感影像,基于机器学习方法对红树林空间分布进行了自动分类和提取的方法是可行的。
(2)随机森林算法对红树林的提取精度更高,对比支持向量机算法,随机森林算法无论是总体分类精度还是kappa系数均高于支持向量机,分类精度为94.5066% ,Kappa系数为0.6939,分类效果也显著。
(3)在随机森林算法加入NDVI评价因子,可有效提高随机森林算法的分类精度。
通过此次研究,笔者认为可选用湿度、温度、纹理特征等更多的评价因子,投入到分类模型中,可进一步提高随机森林算法的分类精度。
