基于手机信令数据的用户位置预测方法研究
2022-11-12吴雨佳尹伟石孟品超
吴雨佳,尹伟石,孟品超
(长春理工大学 数学与统计学院,长春 130022)
随着移动通信技术的发展和互联网的普及,人们对手机的依赖性越来越强,由此产生了大量的手机信令数据。手机信令中的用户位置信息可以为各类服务提供重要支持。在近期流行的新型冠状病毒的传染病防控工作中,对传染源移动轨迹的追溯以及武汉封城后大规模人员迁徙的统计监测都利用了手机信令数据中的位置信息。另外在广告投放、店铺推荐、交通状况监测、道路流量分析等问题中,手机信令数据也发挥了重要的作用。其中,位置预测是实现上述应用场景问题的关键,因此提出有效的位置预测方法具有重要意义。
从数据来源上说,位置预测研究大多采用GPS定位数据,因为这部分数据定位精度较高;而利用通信基站测算的位置数据精度相对较低,因此位置预测研究相应较少。从研究方法来说,常用方法有马尔可夫链(MC)模型[1-2]、频繁模式挖掘[3-5]和深度学习方法等。近年来,深度学习中的循环神经网络因擅长时序数据的预测而在位置预测中逐渐得到应用,在基于GPS定位数据的位置预测研究中取得了一定的进展。Liu 等人[6]提出了 ST-RNN(spatial temporal-RNN)算法,用移动对象历史时空数据训练RNN网络,预测用户在某个时刻的位置;许芳芳[7]提出基于时空特性的LSTM模型,在LSTM网络的基础上添加处理用户移动行为时空信息的门,解决了现有研究时空特征关联不足的问题;Yao等人[8]结合用户的时空转移特征以及用户活动,将GPS轨迹转化为具有语义特征的轨迹,提出了基于语义的循环模型(SERM,semantics enriched recurrent model),有效地捕获了基于位置语义的时空移动模式和用户偏好。相对于GPS定位数据,更为丰富的数据来自于蜂窝通信系统基站定位的数据,由于这部分定位数据质量相对较差,定位精度受基站所采取的定位技术的影响而水平不一,因此在位置预测上较有难度。钱琨[9]对基于蜂窝信令数据的位置预测展开相关研究,其采用TDOA定位技术产生的定位数据,该种定位技术相对Cell-ID定位技术误差更小,但是其精度仍然不如GPS定位技术。在轨迹数据预处理上,作者采用聚类算法去除离群点,基于卡尔曼滤波去除噪声数据;在位置预测方法上,采用层次聚类的方式对用户进行分组,建立一种横向的预测方法,基于频繁序列模式挖掘算法挖掘轨迹模式,构建预测树进行预测。崔家祥[10]利用Cell-ID定位技术获取的移动通信数据为研究对象,将状态定义为具有功能属性的基站的集合,使用一种加权马尔可夫模型对用户位置进行预测,综合考虑距离预测时刻最近的k个状态的影响。以上频繁模式挖掘的算法效率低下,多阶马尔可夫模型使得转移矩阵的规模膨胀,预测复杂度高。除此之外,上述基于手机信令数据的位置预测方法都没有考虑轨迹序列位置间的上下文关联。
为了更好地利用手机信令定位数据进行位置预测,本文构建了强化位置间前后关联的LSTM预测方法。首先提出一种循环迭代的数据清洗方法,去除冗余定位数据的同时完整保留了用户的有效位置信息;接着采用时间阈值的方法提取停留点,结合背景地理信息得到用户语义化的轨迹;最后采用降维的方法将稀疏的one-hot位置编码转化成位置嵌入向量,与LSTM网络结合成基于LSTM的位置预测模型。该模型在考虑用户移动行为具有相似性和实效性的基础上,对历史位置序列进行降维并将位置间的语义关联隐含到位置嵌入向量中,从而达到良好的预测效果。
1 LSTM神经网络
LSTM模型是传统RNN模型的一个拓展,存在控制存储状态的结构,有着比RNN模型更好的学习长期记忆信息的能力。LSTM网络主要改进在两个方面:新的内部状态和门机制。LSTM网络引入一个新的内部状态(internal state)ct专门进行线性的循环信息传递,同时非线性输出信息给隐藏层的外部状态ht。

其中,ft、it和ot分别为遗忘门、输入门和输出门,用来控制信息传递的路径;⊙为向量点乘运算;ct-1为上一时刻的记忆单元;是通过非线性函数得到的候选状态。

在每个时刻t,LSTM网络的内部状态ct记录了到当前时刻为止的历史信息。遗忘门ft控制上一个时刻内部状态ct-1需要遗忘多少信息,输入门it控制当前时刻的候选状态有多少信息需要保存,输出门ot控制当前时刻的内部状态ct有多少信息需要输出给外部状态ht。
三个门的计算方式为:

其中,σ(·)为 logistic 函数,其输出区间为 (0,1);xt为当前时刻的输入;ht-1为上一时刻的外部状态。公式(3)—(6)中的W*,U*,b*为可学习的网络参数,其中*∈{f,i,o,c}。
图1给出了LSTM网络的循环单元结构,其计算过程为:(1)首先利用上一时刻的外部状态ht-1和当前时刻的输入xt,计算出三个门以及候选状态t;(2)结合遗忘门ft和输入门it来更新记忆单元ct;(3)结合输出门ot,将内部状态的信息传递给外部状态ht。

图1 LSTM神经单元结构
2 基于LSTM的位置预测
基于LSTM的位置预测研究主要由四部分组成,即将原始的手机信令数据转化为目标形式数据的预处理部分,划分基站小区范围并标注功能部分,提取停留点生成轨迹位置序列部分和基于LSTM的根据历史位置序列学习运动模式的预测模型部分。
2.1 手机信令数据预处理
运营商采集到的手机信令主要字段如表1所示,采集的信令事件包括接打电话、收发短信、开关机、位置更新、BSC切换和寻呼。

表1 手机信令主要字段
2.1.1 数据筛选
原始信令数据存在字段缺失、每日数据量过少、位置超出研究范围等问题,为了提高数据质量,首先对手机信令数据进行筛选,方法如下:①删除存在字段缺失的数据;②删除多余字段,只保留用户编号、信令发生时间和基站编号;③筛选出一天大于100条信令的用户;④用基站编码将手机信令数据表和基站位置数据表匹配,筛选出密集城区的用户。
2.1.2 数据预处理
当蜂窝网络系统处于非理想信道环境时,无线信号的传播受到干扰而产生定位误差,使得采集到的手机信令数据存在大量的噪声,包括漂移、乒乓切换和静止冗余定位数据,不利于用户真实轨迹的提取,需要根据各类噪声数据的特征予以去除。
去除噪声数据后仍然存在不利于停留点提取的冗余位置信息,本文以基站小区作为停留点提取的最小单元,目标是对于连续的相同位置,只保留第一条和最后一条,并删除未连续出现的定位点。针对上述任务设计了一种如图2所示的可以多次循环迭代的数据清洗算法,该算法可以有效减少不利于停留点提取的冗余位置信息,在对每个用户的数据进行瘦身的同时,完整保留了用户有价值的位置信息。多次循环迭代清洗算法,能够得到良好的数据沉降效果。
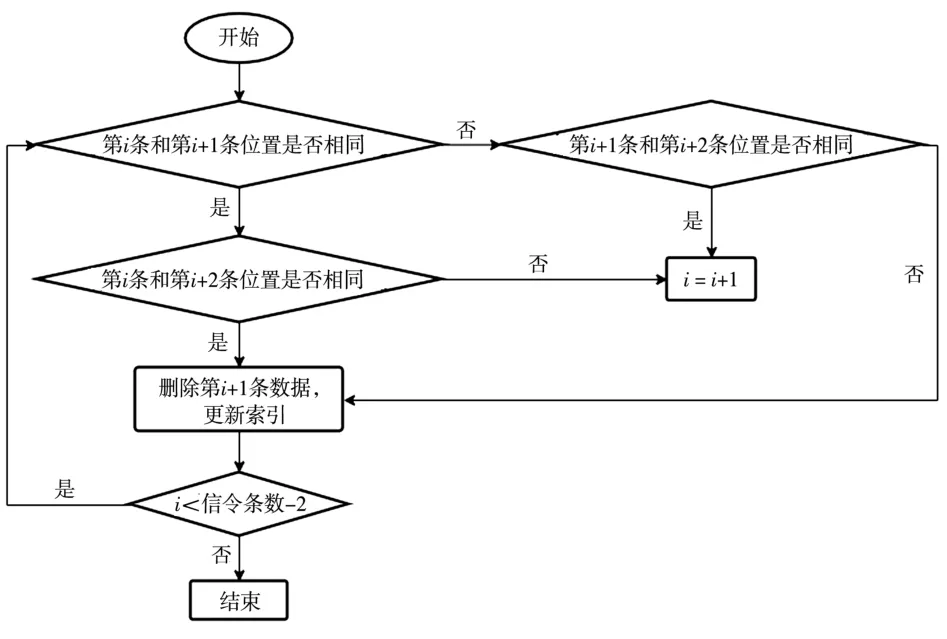
图2 可迭代的数据清洗算法
2.2 区域功能标注
泰森多边形又叫Voronoi图,是根据平面上分散的点对空间平面进行剖分的方法,其特点是每个多边形内仅包含一个样点,且多边形内的任何位置到该多边形的样点的距离最近,到相邻多边形内样点的距离远。由于用户通讯时所连接的基站默认是离用户最近的基站,因此选用泰森多边形法对基站小区的覆盖范围进行划分。对于每一个Voronoi区域,利用高德地图周边搜索服务API抓取兴趣点信息,统计各类兴趣点的数量,将占比最高的那一类作为该基站小区的功能标识。
2.3 停留点提取
本文所研究的手机信令定位数据采用Cell-ID的定位技术,即以基站的位置粗略表示用户的位置。考虑到基站的服务半径在城市约为几百米,这个地理空间大小符合用户停留点的活动范围,因此本文以基站小区作为停留点提取的最小单元,以1小时为时间阈值,将在基站小区内停留时间大于1小时的位置点提取出来,并记录其开始时间和结束时间,得到用户停留点位置序列。构建移动对象所有n个位置的集合S={L1,L2,…,Ln},用户的停留点由位置Li和开始时间ti构成的二元组表示,Ti=<Li,ti>。用户停留点构成的长度为h的历史位置序列如式(7)所示。
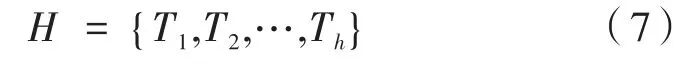
将历史位置序列匹配上一步中标注的基站小区功能,可以得到直观的含有用户语义信息的位置序列,如式(8)所示。
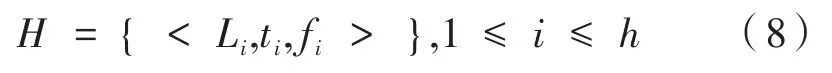
移动对象的位置预测问题定义为:设h个历史位置序列构成的历史轨迹为H={T1,T2,…,Th},当前轨迹为T′={<Li,ti>},0≤i≤t,预测移动对象在t+1时所在的位置Lt+1。
2.4 基于LSTM的位置预测模型
图3是基于LSTM的位置预测网络结构。
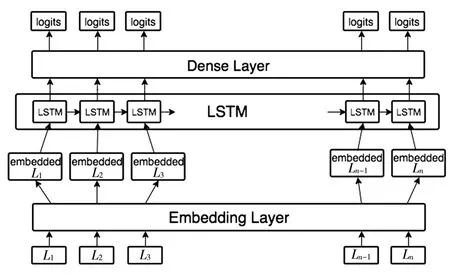
图3 基于LSTM的位置预测网络结构
不同于粒子的无规则运动,移动对象在每个时刻出现的位置是存在某种关联的,即当前时刻的位置与之前时刻的位置是相关的,可以用条件概率表示。设一个长度为N的位置序列出现概率为P(L1,L2,…,LN),假设在一段位置中,移动对象的位置与前t个位置有关,条件概率如式(9)所示。

构成轨迹序列的各个位置是离散的编码,比如1表示XX大学,2表示商业区,3表示景区,4表示高铁站,对于[1,2,3]和[1,2,4]两种轨迹情况可能蕴含不同的语义信息。向量[1,2,3]和向量[1,2,4]通过欧式距离计算相似度会比较接近,但实际是两种完全不同的语义轨迹,这种离散的编码无法直接进行训练,需要先转换成向量。Embedding是把离散的编码转化为向量的关键路径。
设移动对象历史位置序列共有n个位置,将所有位置按出现次数降序排列并赋予从1到n的编号,再对所有位置进行one-hot编码。One-hot编码将n个离散的编号转化为长度为n的向量,在编号对应的位置上赋值为“1”,其余位置赋值为“0”。Embedding层的训练任务是找到一个矩阵Vn×m,将n维的one-hot位置向量降成m维的位置嵌入向量,并将位置间的语义关联隐含到位置嵌入向量中,使得P(Li|Li-t,Li-t+1,…,Li-1)最 大化,如图4所示。权重矩阵Vn×m由神经网络结构结合下游预测任务随模型一起训练,通过反向传播不断地调整网络参数,位置嵌入向量实际就是权重矩阵中对应位置上的向量。
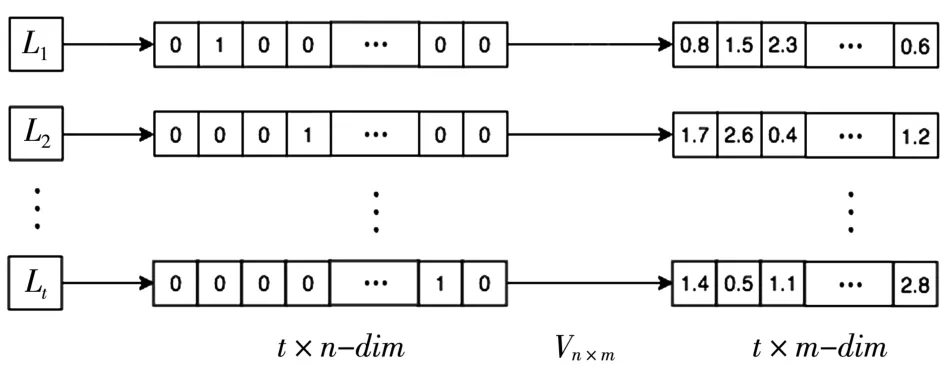
图4 Embedding层任务示意图
经过embedding层对稀疏的one-hot向量降维后,离散的位置编码被转化为低维度的含有上下文信息的位置嵌入向量,从而使得基于LSTM的位置预测算法可以更好地处理位置预测问题。
根据上文对位置预测问题的定义,采用滑动窗口的方法构建训练数据,将所有的移动对象的轨迹序列分割并转化为可训练的固定长度的输入和输出样本集,如图5所示。

图5 滑动窗口法生成样本集
构建好训练数据后就有了理想状态下的输出向量。用softmax激活函数对全连接层输出的logits向量进行归一化处理得到一个n维的概率分布,代表在各个位置上取值的概率,如式(10)所示。
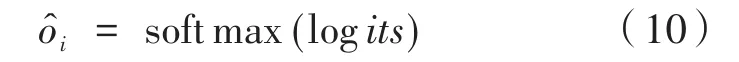
将目标位置以one-hot向量表示,记为oi,于是损失函数为:
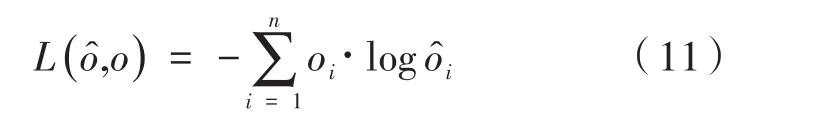
使用梯度下降的方法反向传播更新网络的参数。经过LSTM根据训练数据调整神经元之间权重的学习过程,得到一个全局的位置预测模型。该模型利用语言模型中学习词嵌入的思想构建Embedding层,将位置间的语义关联隐含到位置嵌入向量中,同时降低输入LSTM网络结构的训练向量的维度,降低了模型训练的复杂度。通过LSTM网络的门控机制,解决了处理长序列时容易产生的历史信息损失、梯度消失和梯度爆炸等问题,能够较好地应用于移动对象的位置预测。
3 实验与分析
3.1 实验数据
本文以长春市联通用户2019年8月份的手机信令数据作为实验数据,该数据集共有约524.56万个用户,考虑到每天产生信令数小于100条不足以准确反应用户的移动轨迹,过滤掉这部分用户后剩余共15 231人的13 281.90万条数据。将用户的手机信令数据与基站经纬度进行匹配,结果显示有14 198人在这1个月期间有长春市市区以外的活动轨迹,本实验以长春市区作为研究范围,最终符合条件的有1 033个用户的共708.15万条数据,从中随机选择180个用户的手机信令数据作为本次实验的最终数据。
3.2 预测评价标准
本文的预测目标是用户下一个可能去的位置,但是为了体现LSTM模型在预测长序列方面的能力以及以往在文本生成中的良好表现,除了下一步位置的预测精度,尝试展示以下连续多步位置的预测精度。为此定义一个n单位步长精确度(n-gram precision),设n为当前位置后面想要预测的长度为n的位置序列,pli为第i个位置的预测结果,tli为第i个位置的真实结果,若当i≤k,(1≤k≤n)时,对于任意的i满足pli=tli,则预测步长记为k-gram。设共有K个测试样本,用 num()计数,num(k-gram)表示预测步长为k-gram的样本数,则k(k≤n)单位步长精确度k-gram precision计算方式如式(12)所示。

3.3 预处理数据沉降效果
数据预处理各阶段的效果可以用数据经过每一步处理后的数据减少率来描述。统计每个用户信令数据在依次经过去漂移、去冗余、去乒乓切换和再次去冗余后剩余的信令条数,用绝对数据沉降率Ai来表示各阶段处理后信令数据累计减少的程度,用相对数据沉降率Ri来表示各阶段本身对数据的沉降能力,计算公式如下:
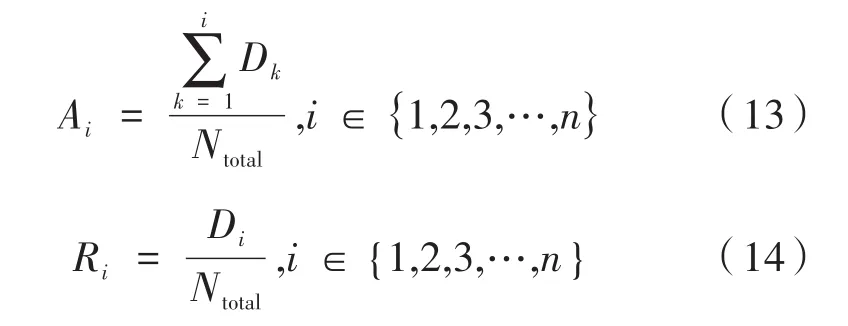
其中,D*为用户数据在预处理各阶段后信令减少的数目;Ntotal为原始信令条数;i取 1,2,3分别表示去漂移、去冗余、去乒乓切换,i>3时每增加1表示迭代一次数据清洗算法。
数据预处理各阶段后,数据量的变化情况如图6所示。从图中可以看出,在去乒乓步骤后,数据沉降率在30%~60%的人占比最大,经过一次迭代清洗冗余数据的算法后,几乎所有人的数据沉降率都达到了50%~100%之间,经过两次迭代后,此时相对第一次清洗后的数据量减少量大部分在0%~30%之间,说明再次清洗仍然可以去除冗余数据,经过二次迭代后,绝对数据沉降率整体相对第一次有了提升,说明数据清洗算法具有良好的效果。

图6 数据预处理各阶段数据量变化分布图
3.4 实验设置
随机抽取180个用户的原始信令数据共有132.89万条,位置集合S共3 296个位置。在对实验数据进行预处理后,将180个用户的前27天的手机信令数据作为训练集,后3天数据作为测试集,对用户轨迹数据提取停留点,转化为停留点位置序列。对训练集和测试集中提取出的停留点位置序列,使用滑动窗口的方式划分输入和标签,设滑动窗口长度len=5,滑动步长step=1。输入一段待预测位置序列,模型输出一个预测结果的概率分布,采用随机采样策略生成一个位置;把这个位置加入到输入位置序列并将滑动窗口前移,生成新的输入再预测下一个位置,依次类推,生成一个长度为5的预测结果序列。通过多次实验调整模型参数,最终确定LSTM位置预测模型中部分参数的最优值如表2所示。

表2 LSTM模型参数
3.5 模型评价
加载上一小节中用最优参数进行训练时保存的模型,对测试集中的待预测位置序列进行预测。遍历测试集所有样本,对每个待预测位置序列预测下5个单位步长的位置,保留每次的预测结果,计算n-gram precision(此时n取5)。为了验证基于LSTM的位置预测模型具有更好的预测效果,本文将基于LSTM模型的预测结果与文献9中横向的频繁序列模式挖掘算法、文献10中加权马尔可夫模型当阶数为5时(阶数为5时模型达到最高准确率)的预测结果进行对比分析。为了统一评价标准,将加权马尔可夫模型在不同时段的预测准确率的均值作为该模型准确率,结果如图7所示。

图7 位置预测模型的n步预测精度
由图7可知,本文的LSTM位置预测模型对下一个位置(1-gram)的预测精度高达79%,明显高于加权马尔可夫模型(weighted-MM)的70.1%和频繁序列模式挖掘(FSPM)模型的61%,说明本文的LSTM位置预测模型在位置嵌入向量的加持下,能够较好地表达位置间的上下文关联,得到更加准确的预测结果。随着预测步长的增加,加权马尔可夫模型预测准确率迅速下降,而LSTM模型和FSPM的准确率下降相对缓慢。这是由于FSPM模型利用分组的方法对用户聚类,使得可预测距离有了一定改善;LSTM模型得益于门控机制对历史信息的记忆,对较长的可预测序列也具有一定潜力。总体来说,本文基于LSTM的位置预测模型具有较高的预测精确度。
4 结论
本文提出一种基于手机信令数据的LSTM位置预测方法。使用运营商提供的真实的用户手机信令数据进行实验。针对手机信令数据的特点,提出一种循环迭代的数据清洗方法,经实验数据验证,在预处理后期多次迭代该算法能够达到良好的数据沉降效果,有利于停留点提取。本文建立一个强化位置间语义关联的LSTM位置预测模型,采用矩阵降维的方法构建embedding层,将稀疏的one-hot位置编码转化成位置嵌入向量,强化位置间的语义关联,并降低输入LSTM网络的数据维度。实验证明本文的基于手机信令数据结合LSTM的位置预测算法具有良好的预测效果。在今后的工作中希望可以将降维程度与预测精度的关系进行量化,进一步优化模型。
