云环境下数据挖掘算法的并行化分析
2022-11-11陈雪
陈雪
(广州工商学院 广东省广州市 510850)
数据挖掘是指通过数据统计、在线云分析、专家智库系统以及情报检索、训练学习等多种数据分析工具与经验法则的体系办法,对计算机互联网中待计算解决的程序任务进行分析拆解,进而获取大数据背后隐藏其中的信息量。数据挖掘的任务表现形式主要有分类分析、聚类分析、关联度分析、特异族群分析、异常分析以及演变分析多种。随着90年代互联网技术以及桌面电脑、移动终端产品的普及应用,如今的互联网应用所要调用的数据规模,早已远超以往的数据软件计算能力所能满足。
1 数据挖掘并行化计算技术的应用现状
当前阶段,想要解决数据挖掘算法效率低下的问题,就必须要应用数据并行化技术,将待计算的数据元素分别配置给计算机包含的多组PE处理单元,这样当计算机执行顺序程序任务时,就可以将所有处理单元的数据同时操作了。云计算技术的根本特点在于计算任务的并行与分布,也正因如此云计算技术才能够在极短的时间内处理海量的数据计算任务。这样并行分布式的计算与以往传统的单机编程计算的工作机制完全不同,它更注重多个计算机集群之间的联机运行效率,除了数据挖掘计算的效率与准确性得到了极大提升以外,在计算资源的合理化配置策略下,闲置计算资源将会得到充分的调动,因此计算成本将会得到极大程度缩减[1]。根据权威报告结果表明,2009年由Apache基金会所开发的分布式系统基础架构“Hadoop”,在910个分布式节点构成的集群中,仅需要约193秒即可完成超过1TB容量的数据排序分析计算。上述实例说明了数据并行化技术在互联网数据挖掘用途中拥有着绝对的效率优势,在云环境中实现并行化的数据挖掘计算,可以在分布式文件系统的基础上,为现有的计算任务提供一个分布式且结果输出一致的虚拟对象存储系统,而后再借助综合分布的NET语言集成系统以及运行引擎,以潜在语义分析、神经网格与配置部署策略等多种数据处理方法获得我们想要得到的数据结果。
2 数据挖掘算法并行化的问题需求分析
2.1 规则关联问题
规则关联问题简单理解,就是将所用的用户数据、或数据库事务放在同一个交叉销售条件下,对数据之间在时间性、空间性或其它方面的关联规则进行挖掘与形式化描述。其中事务T与全项集D中的元素t与i的区别就在于,是否符合事务规则“x→y”的描述,而“x→y”规则是通过数据挖掘算法得到的映射结果,因此它需要由支持度与关联度两个要素来共同构成相关规则描述[2]。其中支持度是指在所有商品交易项集中关联规则的频度,它可以用数据x与y的交易数与所有数据交易量的比值来表示,记作“support(x→y)”,用算法语句表示为如下:
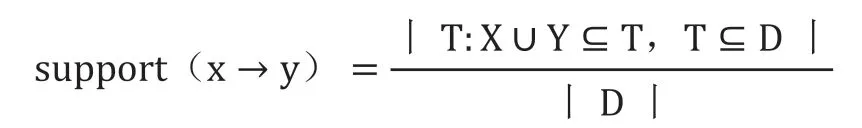
而关联规则的确信度则表示所有商品交易项集中关联规则的强度,它可以用数据x与y之间的交易数与包含x的交易数比值来表示,记作“confidence(x→y)”,用算法语句表示为如下:
confidence(x→y)=丨T:X∪Y⊆T,T⊆A丨
2.2 分类问题
数据分类是云计算在处理、收集以及应用消息时最常使用的一种数据挖掘方法,同关联规则问题不同的是,数据分类还需要在数据的字段类型以及数据结构方面对同属于一个描述维度的数据进行分类归集。以字段类型分类为例,包含全项的D中同时存在着文本类、时间类、数值类等多种字段类型时,由于它们的相关规则并不是可以用量化值来筛选的,无法用四则运算或简单的函数调用的方法来建立分类规则映射。因此需要先对数据的字段类型进行标准化处理,而后再将其以“字符匹配”的方法进行归集处理,除了数值类这种包含可量化属性的数据集合必须要直接进行量化计算以外,其余数据的挖掘处理均可以采用模糊匹配[3]。
以数据仓库的工程师与平台架构师来说,只有理解了数据组件适合处理什么样的数据业务,才能够根据不同的数据分类要求选择合适的数据清洗方法。无论是哪种数据清洗或匹配识别机制,数据分类方法大多情况下存在着如下几个共同点:一是数据清洗时,需要始终将时间类与数值类的数据当做清洗重点,而其余文本数据则要视数据仓使用需求来决定是否需要模糊匹配,例如备注或评价的文字数据通常不具备清洗的必要性;二是建立数据维度模型时,应当根据数据编码型字段以及时间类字段的标准作为清洗维度,以数值的量化属性作为度量,视该种数据对数字业务的重要程度来确定数据分类的量化属性;三是需要明确数据分类清洗的取值范围,例如以年龄大于“0”为分类条件时,若出现与匹配规则的逻辑相悖的不合理数值,应当先用默认值填充后,再对数据项集进行分类清洗处理。
2.3 聚类问题
数据聚类即按照“物以类聚”的思想,将数据中包含相似属性的子项归聚为一类,当前主流的云计算平台采用的数据聚类算法主要包括如下四种:k-means算法、clarans算法、密度聚类算法、k-medoids算法与层次聚类算法。它与数据分类的最大区别在于:分类挖掘是一种数据预测行为,即根据已知的用户信息推断它归属于哪一个潜在的数据管理类别;而聚类挖掘则更关注于数据对象的划分行为,即在事先不知道数据类别的前提下,通过数据自行聚类得到管理模板[4]。以最常使用的k-means算法为例对聚类处理方法进行说明,该聚类算法的基本逻辑为如下:聚类问题的处理目的是将n个样本数集归集为k个数据簇,但除了样本信息以外,数据管理者或数据使用者并不清楚在整个聚类中包含多少个簇。因此需要采用“评价指标法”来衡量聚类算法簇的数目,当簇内样本的相似度较高,而簇间样本相似度低时,用簇间度量属性来表述,就是簇内样本距离小,簇间样本距离大。
2.4 预测问题
数据预测主要是采用如下处理思路:
数据抽样,即在海量数据的全项集D中随机抽取一定量的样本组成新的集合P,并构建相应的数据模型。这种处理方法的优势在于算法并行化时处理难度较低,计算资源占用较小。但当D的样本分布均匀度较差时,数据挖掘的精度与质量也将会受到极大影响。
数据集成,以MapReduce方法为例进行说明,首先对代表海量数据的全项集D进行简单的数据划分,而后再将其以数据块的形式进行并行划分处理,最后再将数据结果进行合并,执行算法并行时需要MPI程序的编写支持,而Mapreduce中专门为数据库开发人员准备了并行程序编写的简单接口,这样在执行算法并行任务的过程中,只要将数据以分片的形式加工处理,就可以在程序reduce阶段重新将算法输出的数据结果进行整合。基于MapReduce的数据集成并行方法在解决了样本数据不均化分布的问题同时,也优化了数据集群节点之间的任务交互与分配流程,使算法并行不再受到本地内存大小的限制,为数据同步与通信预留更多的资源分配空间。
3 实现数据挖掘算法并行化的策略分析——以Hadoop开源云平台为例
3.1 Hadoop开源云平台的源码分析
如表1所示为Hadoop开源云平台的子项目与主要包列表,由上可以看出,Hadoop是一个可提供共享系统与分析系统的分布式数据架构平台,它实现数据挖掘算法并行化的核心组件是MapReduce与HDFS。它的整体架构包括如下内容:由双节点构成的Master/Slave架构,其中一个是NameNode节点,负责维护整个并行程序的元数据,是平台文件系统运行的基础保证;另一个为DataNode节点,主要负责建立起整个数据单元的文件储存模块,它在平台中的主要意义是充当工作节点,由NameNode节点的指令控制,并定期以“心跳机制”的形式向上游DataNode节点发送工作数据块的信息[5]。除此以外,为了实现Hadoop平台在数据挖掘算法并行化任务执行过程中的高可用性目标,在它的基础框架中还增设了一个Secondary DataNode节点作为备份,当DataNode节点发生故障时,可以随时从本地数据库中调取Namespaceimage(命名空间镜像)与Edit Log(编辑日志)文件,替代其重新成为新的元数据维护节点。

表1:Hadoop子项目与主要包列表
3.2 规则关联算法的并行化策略
分析规则关联算法的需求,可以采用基于单层单维与布尔关联规则的Apriori算法,将两阶数集分别在构建器与过滤器中进行迭代,而后再以k项集为频繁项,不断生成新的k+1项集。这样的算法步骤如表2所示,通过剪枝与连接的过程,使不同阶段输出的Lk与Lk-1进行连接。在Apriori算法模式下,若频繁项集的非空子集是连续生成的,那么只需要对Ck+1与Lk的归属关系进行检验,即可获知算法并行化的输出结果是否满足支持度要求。
基于Apriori规则关联算法并行化的步骤流程如下:
(1)输入。D:事务库数据,Min_support:支持度的最小阈值。
(2)步骤。L1=find_frequent_1-itemstes(D);//挖掘频繁项集。for(k=2;Lk≠0;k+=){//初始值输入}。Ck= aprior_gen(Lk-1,min_support),//调用aprior_gen(),生成k-1的频繁项集。Foreach transactions t in D{//事务数据库D扫描}。Ct=subset(Ck,t),{//以t的子集为候选集}。Foreach candidates c in Ct。c.count++;//统计候选k-1的计数。Lk={c⊆C|kc.count>Min_support}//最小支持度的满足条件,即输出的k-1项集结果}。ReturnL=UkLk;//频繁项k项集合并。
若事务T中包含着A项集,可以记作“A⊆T”,若A项集中包含K项数集,那么就可以称K为A的数据项集,简称为K项集。而这样的事务T又属于包含所有项的I集合,记作“I={i1、i2、i3....in},T⊆I”,而事务T中又有n项数据,记作“T={t1、t2、t3....in}”。此时就可以将事务T看做在全部项集D中,以某项数据间的线索为标识符的关联集合,记作“T|D”。在这样的关联规则体系下,事务T中所有的元素都相当于交易环节的商品列表,而i1t1、t2、t3....in等集合元素,则可以被视为在“x→y”标识规则下,从全集合D中提取出的所有符合元素。
3.3 分类算法的并行化策略
在Hadoop平台上,首先为分类算法匹配一个算法PFP作为分布式数据处理环节,例如FP-growth算法。可以为不同的计算机服务器分别配置独立的数据分类挖掘任务,这样的数据挖掘结果,每个子部算法输出结果之间是互相平行割裂的,互相之间并不存在依赖关系。
而后采用MapReduce组件将数据进行分片处理,并使用“mapper()->reduce()”指令求得分类数据项集的所有支持度结果计数。再单独将每个mapper的数据分片输入本地的频繁项文件列表“F_List”中,在某个工作节点上将“F_List”项集按照输入数纲规则划分为g个分组,使每个列表分组中均包含至少一个gid样本数据,构成新的分组集合“G_List”。
接着再根据不同的数据业务需求,以不同分组单位构成的FP-Tree(树状文件列表),此时只需要将事务集合转换至归集多个组的数据分片中,就可以在递归构建条件的要求下,使新集成数据被多个组间节点加工为中间结果数据了。
最后是算法并行化的实现关键,当“G_List”列表以组为单位生成数据集事务时,需要启动“mapper()”实例,将一组中间结果读入至hashmap中,并且会同步映射生成一个group_id数据,此时每个mapper()指令的工作对象都与唯一的一个数据分片相对应。在将数据输出结果的格式调整为“key,value=Ti”形式后,将每个被包含于事务集合中的样本Ti,输入如下操作流程:一是使用“group_id”来取缔满足“Tj⊆Ti”条件的输出数值;二是将出现在Ti中的“group_id”数据记为“gid”,并将离散性最大的出现位置记作L,使输出键与算法指令“key=gid,value={Ti[1]、Ti[2]、Ti[3]......Ti[L]}”相契合[5];三是需要在分类算法并行化模型构建完成后,从一组已知类别数据中抽取若干预先定义的分类数据,建立起训练样本,不断检验分类算法并行化模型的预测准确率。
3.4 聚类算法的并行化策略
聚类算法的并行化主要是采用统计学办法,用叶贝斯定理来建立起多个相对独立的属性类簇Ci,将海量数据项集D中的数据按照如下公式进行处理:
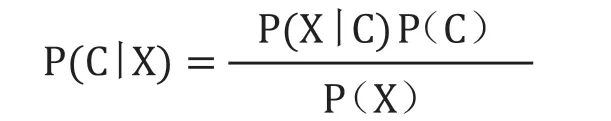
式中C表示为聚类的某种假设前提,代表着聚类数据簇中心的临时特征值;P(X|C)表示为聚类条件为X时,所有由C筛选出的后验概率;P(C)是数据簇的先验概率。
应用该定理时首先需要先为其描述n个基本属性描述,用A1、A2、A3....An来表示;当假设数据挖掘的聚类簇存在m个时,用C1、C2、C3....Cm来表示;为了度量出数据与簇中心的距离,再用X1、X2.......Xo来表示聚类的中心簇定元组。
其次是对每个聚类后验概率的输出值P(C|X)进行验证,只有当P(C|X)满足条件“P(C|Xo)>P(Cm|X)[o>m>1]”时,才可以将预测的定元组X作为数据簇中心的特征值,此时将P(C|X)所对应的簇Ci输出[6]。
而它的工作过程则分为如下:第一步是在全项集D中随机抽取n个样本作为取样区C,再在集合C中继续抽取k个样本组成集合K,我们将这样的集合K称作“初始簇中心”,此后每形成一个簇中心都用其来表示一个数据簇。
第二部是为每个样本集合中心匹配一个可供参照的数据样本,根据数据与中心簇可度量的属性值来计算它们的相似度,并将该样本暂时归集至该簇中。此后每出现一个新的数据簇,都与中心簇的样本进行相似度比较,一旦出现高于中心簇的新簇时,再将样本归聚至这个与中心簇特征值最相似的新簇中,作为该类样本的聚类簇输出结果。
第三部每新增一个簇后,都需要将每个簇中样本均值作为衡量基准,重新计算聚类簇中心的特征值。并重复如上步骤,采用标准测度函数与均方差的方法对簇中心的特征值进行收敛处理。
第四部是将簇内样本的相似度S1、S2.....Sn,与簇间样本的相似度I1、I2、I3...In输出,若采用密度度量法计算聚类簇的样本均值,则是将每个簇抽象处理为以簇中心为圆心的,以距离簇中心最远样本的偏差距离为半径作圆。再次以簇中心为圆心,以任意距离n(n小于最远样本距离)为半径,逐渐增加簇半径的距离,将两个圆在同一平面内形成的圆环作为参考量,计算出环形区域内的数据点个数与圆环面积的比值,即为数据聚类样本密度。
3.5 预测算法的并行化策略
预测算法的并行化则主要是依靠LSTM时间序列的处理工作流程,LSTM是一种可以用于深度学习领域的人工递归神经网络,它与以往前馈式的神经网络不同,在整个网络节点中还包含有反馈连接功能单元,因此它除了可以用于挖掘图像、数据表等单一数据点的预测信息以外,还可以挖掘带有“数据序列”属性的数据,例如视频、音频以及语音文件。
需要先为LSTM创建一个床柜的分布式数据架构,以Hadoop平台组件HDFS为例,这样的平台架构由一个TensorFLow分布式集群,与若干个TensorFlow子服务器构成[7]。而在执行数据预测算法的并行化任务时,除了需要根据数据业务需求匹配相应的数据挖掘算法以外,还要执行如下几种主要的算法并行策略:
多工镜像策略,通常情况下为了确保数据预测分析的准确性,在整个数据模型中可能布置存在一个预测算法,因此需要针对多Worker情景的算法调用需求,通过跨Worker的同步分布式算法训练,使每个Worker对应的服务器组都可以调用资源参与程序计算。它的基本原理就是在所有程序Worker的计算机设备上分别创建一组包含数据变量信息的副本,构成与Worker调用算法数据模型对应的镜像,为中央存储策略实例的语句调用提供架构环境。
TPU策略,它的主包路径应当设置为“tf.distribute.experimental.TPUStragy”,该策略的主要作用是使预测算法并行化执行程序以及算法训练流程可以在Tensor处理单元,即TPU上运行。与镜像策略最大的不同之处在于它不是以调用多组Worker计算机的形式实现同步分布式培训的,而是将算法训练形式转换为TensorFlow后,使其可以在TPU单元运行。
参数服务器策略,主包路径应当设置为“tf.distribute.experimental.ParameterServerStrategy”,在该策略模式下整个用于数据预测挖掘的云网络中,部分计算机会被指定为WorkerServer,即工作服务器组;而另外一部分则会被指定为ParameterServer,即参数服务器组。将预测算法的数据模型中的频繁变量文件统一放置于一个参数服务器组中,再由工作服务器组通过工作程序以复制的形式进行调用,实现在多个服务器对预测算法数据模型进行分布式训练的需求。
4 结语
综上所述,如何在合理的时间内攫取、管理以及加工处理更庞大的数据量,一直以来都是大数据时代网络应用所追求的首要目标,在这种背景下“大数据云计算”技术应运而生。而云环境下数据挖掘算法的并行化就是指利用多种不同的数据模型策略,实现数据关联规则、分类、聚类与预测四种数据挖掘方法的并行化执行功能。若待处理的计算数据规模继续增加,就需要由多台计算机处理机共同执行并行计算,而此时再配置计算任务时,就需要考虑到数据通信、数据段间同步以及算法选取的问题。
