融合时间特征的虚假评论检测研究*
2022-11-10徐艺苗
徐艺苗,耿 亮,安 彧
(湖北工业大学理学院,湖北 武汉 430068)
0 引言
随着网上购物消费方式不断盛行,许多用户倾向于通过各种电子商务平台发表自己的观点。海量的评论逐渐成为影响电商发展的重要因素,积极正面的评论信息有助于提升商品的销量。然而,有些商家为了追求利润,会雇佣水军发布虚假的评论信息来误导消费者,这些虚假评论会破坏电商市场的秩序,影响其正常发展。因此识别虚假评论具有了重要的现实意义。
对于虚假评论的识别工作,自2008年Jindal[1]等人提出后,已出现了大量的研究。Jindal 等人通过提取评论的文本特征,商品特征,以及评论者的信息,构建模型来区分真假评论。Li[2]等人从评论的文本层面进行研究,发现真实评论在词性特征上会包含更多的名词和形容词,认为可以从词性角度来识别虚假评论,但是该方法难以识别出刻意编写的虚假评论。Burgoon[3]等人指出真实评论与虚假评论存在显著的语言差异,虚假评论者往往避免使用第一人称代词,认为可以根据第一人称代词的频率来检测虚假评论。Ott[4]等人构造一个黄金标准数据集,通过文本的分析工具(LIWC)提取文本特征,利用支持向量机(SVM)进行虚假评论检测。宋海霞[5]等人通过借助行为特征,提出自适应聚类的虚假评论检测方法,构建评论的特征聚类矩阵对K 均值算法进行改进,然后通过聚类分析来进行虚假评论识别。Savage[6]等人通过评分行为这一特征构建二项回归模型,认为评分行为偏离于多数人的评论者是虚假评论者。
先前的工作大多利用评论的评分和文本内容来检测虚假评论,存在许多不足。首先,没有考虑到两者间的一致性问题,即评论评分与评论的文本内容并不一致,仅根据评分不能完全来代表评论者的真实感受;其次,忽略了在不同时间段内评论的不同表现。在某段时间内,评论数量激增或评论整体的评分突然上升或者下降,都可能存在着虚假评论的原因[7]。
针对上述问题,本文首先考虑了时间的爆发性特征,构建一个基于局部异常因子的时间特征指标;然后将评论特征,评论者特征和时间特征三者结合,构建一个虚假评论检测模型;最后针对Yelp 数据集的数量不平衡问题,即虚假评论的数量远小于真实评论的数量,利用集成采样的方法来改进。
1 融合时间特征的虚假评论识别算法模型
1.1 特征指标的构建
我们从评论特征、评论者特征和时间特征三个层面,选取了共15 个特征指标对虚假评论进行识别,分别从多个维度构建初始指标的集合。
⑴基于局部异常因子的时间特征
虚假评论的出现会导致在某段时间内评论的评分和评论数量出现一些异常的波动,所以可以根据时间窗口内评论的数量和评分均值来对虚假评论进行识别,但如果仅以评论数量作为时间序列的筛选指标不够合理。图1显示了从2005年1月1日到2012年12月30日在Yelp网站上的评论数量,如果仅使用评论数量作为筛选指标,认为时间窗口内大于阈值的评论是可疑的评论,可疑的虚假评论的时间窗口大多都在时间的后半段,显然是不合理的。而且如果仅对大于阈值时间窗口内的评论进行分析,会导致大量评论数据丢失。图2 显示了每一天所有评论的得分均值,其分布也不具有显著的识别特征。信息熵可以有效的度量系统参数的分布变化情况,情况越混乱,信息熵就越大,因此可以利用这一特点进行虚假评论的识别。

图1 时间-评论数量图
图2 时间-得分均值图
局部异常因子(LOF)算法,是一种基于距离进行异常检测的方法。通过比较每个点和其邻域点的密度来判断该点是否为异常点。本文利用信息熵,评分均值和评论数三个指标建立一个三维的时间序列,采用局部异常因子算法构建时间特征指标。算法步骤如下。
第1步根据评论发表的时间顺序,按照时间窗口的大小Δt,将评论划分为k段,第j个时间窗口表示为:

第2步计算在每一个时间窗口内,所有评论样本的得分均值X1,评论数量X2和信息熵X3。

第3 步利用欧氏距离计算得分均值、评论数量、信息熵三者间的距离:D(p,oi(p))。
第4步计算点p的第K局部可达密度:

同理,计算在K 近邻领域上点oi(p),(i=1,2,…)的局部可达密度dk(oi(p))。
第5 步根据局部可达密度,计算点p 的第K 局部离群因子LOF值:

指标汇总如表1所示。

表1 特征指标
1.2 基于PCA-SVM的虚假评论识别算法模型
对于虚假评论的识别,是一个二分类问题,将其划分为虚假评论和真实评论。本文将主成分分析(PCA)与支持向量机算法结合应用于虚假评论识别中,考虑时间的爆发性特征,对指标进行特征选择和分类器训练,构建一个较为完备的虚假评论识别框架。
算法步骤
第一阶段:文本数据的预处理。
采用语料库清理,去除停用词,文本分词,标注词性,词频统计等预处理方法。对数据进行格式化处理,提取评论内容的各项特征,构建评论的特征向量。
第二阶段:基于局部异常因子的虚假评论时间特征计算。
根据评论数量,评分,信息熵构建三维时间序列,利用局部异常因子算法得到其LOF 值,构造一个时间特征指标。
设定LOF 的阈值δ,当LOF 值大于δ时,被认为是离群值,即被怀疑为虚假评论。本文设定阈值为1,即当LOF值大于1时我们怀疑该时间窗内的评论为虚假评论,反之则认为是真实评论。然后将被怀疑的评论赋值为1,不被怀疑的评论赋值为0,便于计算。
第三阶段:特征提取。
本文选取了共15 项特征指标,由于指标较多,各指标间可能存在着相关关系,为了消除变量间的相关性,使变量的数量最小化,采用主成分分析对原始的指标进行数据降维。
第四阶段:虚假评论检测。
支持向量机算法是一个二分类模型,利用其对虚假评论进行识别。最后对虚假评论识别模型的效果进行评价检测。算法流程如图3所示。
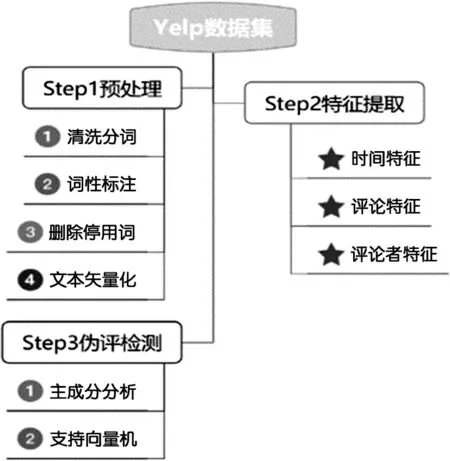
图3 算法流程图
1.3 评价指标
在本文这种类别不平衡的情况下,一般选用的召回率、精确率不适合作为评价指标。本文选择AUC值作为评价指标,AUC 值是ROC 曲线与坐标轴围成的面积大小,取值在0到1之间,通常AUC的值越接近1,则表示分类器效果越好。
2 实验与结论
2.1 实验数据集
对于虚假评论的研究,一个重要的难题就是无法获得标注数据集,很多研究者常常选择人工标注的方式来获取标注数据集,然而,人工标注具有主观性。本文选取了美国版的大众点评网站Yelp 评论数据集进行实验,该网站有自身的检测系统用于过滤虚假评论,从而得到带有标注的评论数据集。经过整理,得到实验数据结果,如表2所示。

表2 实验数据集
2.2 模型实现
⑴时间特征指标的结果
首先,设置时间窗口的大小为一天,将5854 条Yelp 评论划分为1931 个时间窗口。有研究者指出[7],当LOF 的值接近1 时,说明点p 的密度与周围点的密度相差不大;当LOF 的值大于1 时,说明点p 的密度小于其相邻点的密度,此时可以认为这是一个离群值。因此,将阈值设为1,结果如图4 所示,其中,被怀疑为是虚假评论的时间窗口有74个,将这些评论的怀疑程度标记为1,其余评论标记为0,然后将窗口还原,最后得到在5854条评论中,怀疑程度为1的评论有255条,怀疑程度为0 的评论有5599 条。被怀疑为假评论的数据分布更均匀,结果较合理。

图4 LOF局部离群点
⑵主成分分析特征提取
本文采用主成分分析法来消除变量之间的相关性,变量对原始信息的贡献率排名的结果如图5所示,到第八个变量时,其单个的方差贡献率不到0.06,最后选择保留8个变量,可以保留原始信息的84.04%。

图5 方差贡献率图
2.3 实验结果对比分析
为了分析不同特征对结果造成的影响,本文选择不同的特征,在Yelp 数据集上分别进行对比实验。将80%的数据集作为训练数据集,剩下的20%作为测试集合。以AUC为评价指标,实验结果如表3所示。

表3 实验结果
由表3 可知,本文融合时间特征的方法在对比实验中取得了较好的结果,AUC 值达到87.62。在结合时间特征指标之后,能够更加全面的反映评论的异常情况,从而发现潜在的虚假评论,对数据集进行虚假评论识别的效果更好。同时在仅选取评论特征或者评论者特征时,如果加上本文所考虑的时间特征指标来识别虚假评论,模型的AUC值也能有效的提高。
本文数据集属于不平衡数据集,一般采用过采样或欠采样方法处理失衡的样本数据[8]。过采样是对数据集中的少数类数据进行多次重复采样,保留多数类数据,从而使得两个类别数量相当。而欠采样与之相反。本文对数据集进行采样处理的对比实验,具体结果如表4所示。

表4 采样结果
在过采样或欠采样后,模型的分类效果并不好。欠采样会丢失掉一部分数据的信息,过采样会导致新样本与周围的多数类样本产生大部分重叠,致使分类困难。
本文尝试通过集成方法来解决样本不平衡的问题,即每一次生成训练集的时候使用分类中的小样本量,然后从大样本量中随机抽取数据来合并构成训练集,这样反复多次得到多个训练集。在数据集均衡的情况下,对比模型的表现,实验结果如表5 所示,可以得到在对数量少的类别进行重新采样时,模型的性能更好,AUC值达到了88.99。

表5 集成采样结果
3 结束语
本文通过考虑评论的时间特征,将其与评论特征和评论者的特征相结合,构建一个虚假评论识别模型。利用主成分分析法对数据降维,选取重要特征对虚假评论进行识别。对比现有的研究方法,本研究的方法AUC值更高,识别效果更加显著。最后利用集成采样的方法来解决Yelp 数据集中数量不平衡问题。结果表明,集成采样的方法能有效提高模型的AUC值。后期将引入更多的特征指标,深入分析虚假评论的特征,提高虚假评论识别模型的精度。
