基于深度学习的单帧图像超分辨率重建综述
2022-11-09叶晓晶陈丽琼王志锋刘文犀
吴 靖,叶晓晶,黄 峰,陈丽琼,王志锋,刘文犀
(1.福州大学机械工程及自动化学院,福建福州 350116;2.福州大学先进技术创新研究院,福建福州 350116;3.福州大学计算机与大数据学院,福建福州 350116)
1 引言
图像超分辨率重建(Super-resolution Reconstruction,SR)是指将同一场景的一张或多张低分辨率(Low Resolution,LR)退化图像恢复成对应的一张或多张高分辨率(High Resolution,HR)清晰图像的技术,是计算机视觉和图像处理领域的重要技术之一.图像SR不仅可以提高图像的感知质量,还有助于提升目标检测、图像去噪等其他计算机视觉任务的性能[1~3].相比于设计更复杂的光学成像系统来提升图像质量,图像SR技术能够在达到相同效果的同时大大降低成本,也能突破衍射极限对光学成像系统的限制,获取更高分辨率的重建图像,因此在视频监控、医疗成像、卫星遥感等领域有着广泛的应用[4~8].
根据低分辨率图像在网络模型中输入数量的不同,可将图像SR技术分为单帧图像超分辨率重建(Single Image Super-resolution Reconstruction,SISR)以及多帧图像超分辨率重建(Multi-Image Super-resolution Reconstruction,MISR).其中,SISR可大致分为3类:基于插值的方法、基于重构的方法和基于学习的方法[9].基于学习的方法按照学习程度的不同,又可分为基于浅层学习的方法和基于深度学习的方法[10].MISR主要可分为频域法和空域法[11].相较于MISR需要多张同一场景具有亚像素位移的LR图像作为输入,且图像间亚像素位移的不可预知性给充分利用图像的混叠信息带来了一定难度,SISR只需输入一张LR图像即可重建出图像的纹理细节,具有较高的实用价值,因此是目前图像超分辨率重建领域的主要研究方向.
早在20世纪60年代,Harris[12]和Goodman[13]就分别提出单帧图像超分辨率重建的相关方法,并称为Harris-Goodman频谱外推法.随后,Tsai等人[14]于1984年提出用于多帧图像超分辨率重建的频域处理法.自此,研究者开始关注并研究图像超分辨率重建技术,各种基于插值的方法[15,16]、基于重构的方法[17~21]也相继被提出.随着机器学习在计算机视觉和图像处理领域的发展,Freeman等人[22]将机器学习应用于图像超分辨率重建领域,并于2000年首次提出了基于学习的图像超分辨率重建方法.此后各种基于浅层学习的方法[23~26]也陆续被提出.然而这些传统的方法大多是通过提取对图像轮廓等纹理细节表达能力有限的图像底层特征来重建高分辨率图像,故在很大程度上限制了图像的重建效果.
近年来,随着深度学习技术的快速发展,研究人员对基于深度学习的图像超分辨率重建技术展开积极的探索和研究.相较于传统方法,基于深度学习的方法能够从数据集中提取到更具表达能力的图像特征,自适应地学习低分辨率与高分辨率图像之间的映射关系,不仅有效地克服了图像获取过程中出现的模糊、噪声等退化因素的影响,同时在各种标准数据集上取得了更好的重建效果并展现出更优的网络性能.
随着图像SR研究成果的逐年增多,综述文献的归纳整理变得极为重要.早期的图像SR综述文献[27~29]主要针对传统SR方法的算法原理及其研究成果进行总结归纳,本文不再赘述.自深度学习应用于图像SR领域以来,相关SR综述文献开始侧重于基于深度学习的图像SR内容的阐述.大多数文献[30~33]从网络结构设计、上采样方式和损失函数等方面对SR研究成果进行论述,并总结分析不同网络模型的相关内容.部分文献[11,34,35]从有、无监督学习等角度出发,阐述分析SR中具有代表性的研究成果.唐艳秋等人[36]从模型类型、网络结构、信息传递方式等方面对各种SR算法进行详细评述,并对比分析不同算法的优缺点.而Wang等人[37]同样从有、无监督SR的角度出发,详细综述了SR最新进展,并介绍了一些特定领域的应用,同时对比部分网络模型的精度、大小和计算代价等内容.Anwar等人[38]则根据网络模型的结构差异,提出了一种新的分类方法,将现有算法分为线性、残差、多分支、递归、渐进等9种类型,并对模型之间的网络复杂性、内存占用等加以比较.Chen等人[39]针对真实世界的单帧图像超分辨率重建(Real-world SISR,RSISR)进行全面综述,并总结出四大类RSISR方法,对RSISR技术的进一步发展和应用具有重要意义.
其中,部分文献[30~32,35,38,39]仅介绍SR中常用的数据集和图像质量评价指标.然而数据集和评价指标对SR网络的训练和重建图像的评价具有重要作用,仅对常用的方法进行介绍是不够的.同时,只有少量文献[37,38]简单提及了SR的相关挑战赛,而挑战赛恰恰是SR发展趋势的一种体现.随着SR方法的逐年更新迭代,前期的综述文献已无法涵盖最新的研究成果,也无法使读者了解到更多的数据集信息及相关图像质量评价指标,且仅从网络模型的发展情况分析SR的发展趋势是不全面的.因此本文在前人的基础上,首先以网络模型的设计、训练、测试为逻辑思路介绍图像SR的相关知识,完善并丰富数据集构建方式、网络模型基本框架以及图像质量评价指标等相关内容;其次根据学习模式的不同将现有方法划分为监督式SR和无监督式SR,并根据模型的网络结构及设计策略,重点对监督式SR典型及最新的研究成果加以评述,力求系统和全面地介绍基于深度学习的SISR方法;最后从数据集构建方式、网络模型研究进展及SR挑战赛等角度分析基于深度学习的图像SR未来的发展趋势,以促进基于深度学习的SISR技术今后的发展及应用.
2 图像超分辨率重建相关知识
图像SR旨在从低分辨率退化图像中恢复出相应的高分辨率图像.通常,低分辨率图像满足式(1)所示的退化过程:

其中,ILR和IHR分别表示LR图像和HR图像,D表示退化函数,θ表示退化过程的参数.根据θ是否已知,可将图像SR分为退化已知的非盲超分辨率重建方法和退化未知的盲超分辨率重建方法,其中盲超分辨率重建方法主要应用于真实世界的图像超分辨率重建.
图像超分辨率重建是图像退化过程的逆过程,可利用低分辨率图像中的信息重建出对应的高分辨率图像,即

其中,F表示超分辨率重建模型,β表示超分辨率重建模型的参数.
2.1 数据集构建方式
数据集作为SR网络的主要数据来源,可用于训练、验证及测试,其中训练数据集作为网络端到端学习的重要数据来源,对网络性能的提升有着重要的作用,一个高质量、多数量、大范围的图像数据集能够在很大程度上提升网络性能.根据SISR网络模型是否使用匹配的低分辨率-高分辨率(LR-HR)图像对进行训练,可以将其分为监督式SISR和无监督式SISR.监督式SISR需要用匹配的LR-HR图像对训练网络,因此训练数据集的构建对监督式SISR至关重要.
现有的数据集主要分为两种类型.一种是只采集HR图像的数据集,如DIV2K[40],DIV8K[41]等数据集,对于此类数据集可采用不同的退化方式获取相应的LR图像,从而构造匹配的LR-HR训练图像对,以这种方式获得的训练数据集一般被称为合成数据集.另一种则是直接采集同一场景不同分辨率的图像,从而获取LRHR图像对的数据集,如RealSR[42],DRealSR[43]等数据集,这类训练数据集一般被称为真实数据集.目前主要有3种方法用于真实数据集的构建,包括基于焦距调整的方法、基于硬件分箱的方法和基于波束分束器的方法[39].相较于合成数据集,真实数据集通常具有更真实的退化过程,适用于真实场景图像的超分辨率重建.但真实数据集的构建存在一定难度,如真实数据集直接采集到的LR-HR图像对通常是不匹配的,需要进行严格的配准操作才能得到具有相同视场且可用于训练的LR-HR图像对,且真实世界图像的退化核会随着景深的变化而变化,通常是不均匀的,往往需要根据实际情况采取不同的策略再进行超分辨率重建.
由于难以获取同一场景下成对的LR图像和HR图像,所以现有数据集大多只采集HR图像,再通过不同的退化方式得到相应的LR图像,以构造合成数据集用于训练SISR网络模型.然而LR图像的实际退化过程未知且复杂,易受到模糊、噪声、下采样、图片压缩等因素的影响,难以对其进行准确的定义.因此,在不同的SISR网络模型中使用的退化方式没有一个统一的标准.根据现有SISR网络模型构造合成数据集时所采取退化方式的不同,可总结出以下几种退化模型.
(1)简单退化模型
简单退化模型通过对HR图像进行简单的下采样操作得到相应的LR图像,如式(3)所示:
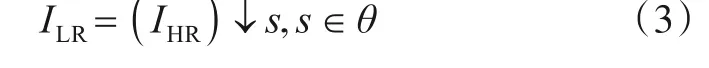
其中,↓s表示尺度因子为s的下采样运算.以往的SISR网络模型大多采用理想的双三次下采样进行退化以获取LR图像.然而简单退化模型获得的LR图像与实际的退化过程存在较大差异,不仅难以应用于真实场景的图像SR,也难以处理与双三次下采样具有不同退化空间的图像.
(2)一般退化模型
一般退化模型对下采样、模糊和噪声等退化因素加以考虑,与简单退化模型相比,退化过程更接近实际场景,如式(4)所示:
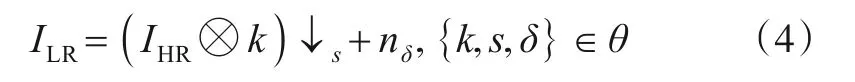
其中,k表示模糊核,⊗表示卷积操作,n表示噪声,通常设置为标准差为δ的加性高斯白噪声.
SRMD(SR network for Multiple Degradations)[44]等网络模型验证了一般退化模型的有效性,但其仍与图像的真实退化过程存在一定差异,且退化范围无法有效覆盖实际场景中的各种退化,因此大规模退化模型应运而生.
(3)大规模退化模型
大规模退化模型是在一般退化模型或其变体的基础上对各种退化因素进行扩展,考虑更真实和更复杂的退化过程,从而获取具有更准确及更大范围退化空间的LR图像.大规模退化模型旨在通过更准确的模糊核估计等方式扩大图像退化空间来模拟图像的真实退化过程以获取相应的LR图像,因此适用于真实图像的SR.
SFTMD(Spatial Feature Transform for Multiple Degradations)[45],DAN(Deep Alternating Network)[46]等网络模型通过有效的模糊核估计,使其设计的大规模退化模型更有利于真实图像的SR.BSRGAN(Blind SRGAN)[47]等网络模型在一般退化模型的基础上设计了一种更加复杂且实用的大规模退化模型,对更复杂的退化模糊、下采样和噪声等退化因素加以考虑,从而构造合成数据集用于训练.而Real-ESRGAN网络模型[48]则是在经典退化模型(式(5))的基础上,对模糊、下采样、噪声和JPEG压缩等退化元素加以考虑,通过“n阶”退化过程(式(6))建模以扩大退化空间,每个退化过程采用不同参数的经典退化模型,从而合成具有更加真实退化过程的LR图像,极大地提升了网络重建质量.

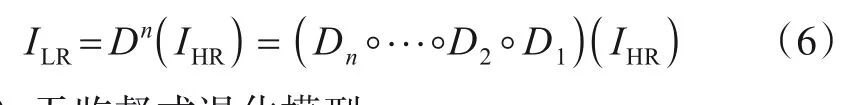
(4)无监督式退化模型
无监督式退化模型通过生成对抗网络(Generative Adversarial Networks,GAN)等无监督的方式模拟图像的退化过程,获取相应的LR图像.相比简单退化模型和一般退化模型,无监督式退化模型能够利用生成对抗网络的对抗博弈性使网络更好地模拟图像真实的退化过程,因此主要应用于真实场景的图像SR.
KernelGAN(Kernel estimation using an internal-GAN)[49],DSGAN(Down-Sample GAN)[50]等网络模型均是通过GAN以无监督的方式得到与原始HR图像有相同分布的LR图像,从而构造合成数据集进行真实图像的SR.FCA(Frequency Consistent Adaptation)[51]则是一种频率一致性自适应方法,通过所提出的自适应生成器以无监督的方式估计图像的退化过程,从而得到与真实场景图像具有频率一致性的LR图像,用于SR网络的训练.
目前,已有很多可用于图像SR的数据集,这些数据集在图像质量、数量、范围和分辨率等方面都存在一定差异,可以为不同的图像SR任务提供数据支持.表1对图像SR中常用的数据集进行总结[40~43,47,49,52~68],以便了解数据集的相关内容并选择合适的数据集用于SR网络的训练、验证和测试.
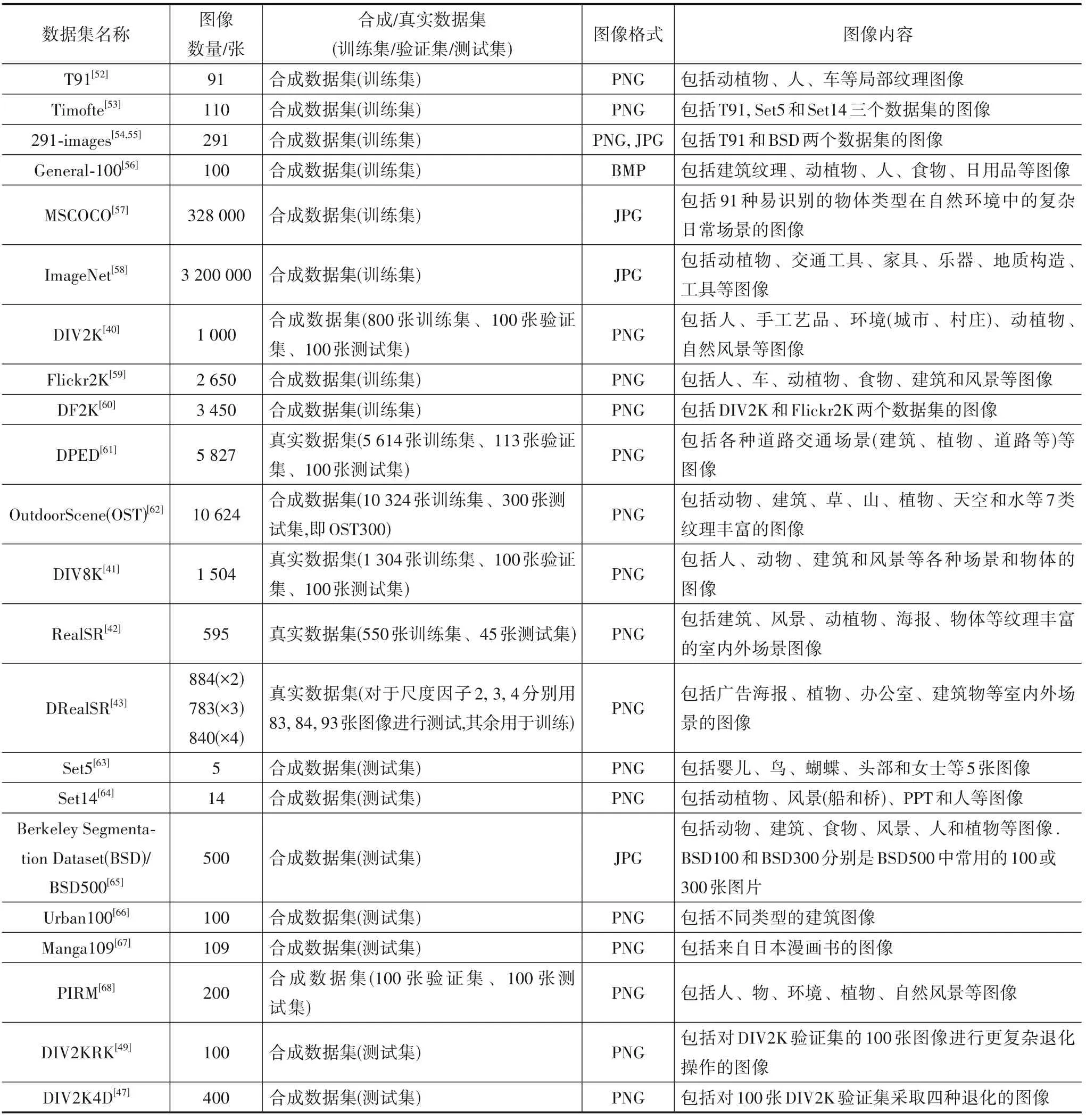
表1 图像超分辨率重建常用数据集概述
2.2 网络模型基本框架
以不同退化方式或采集方式得到合成数据集或真实数据集后,即可对网络模型进行相应的训练.虽然现有SISR的网络模型之间差异较大,但本质上可以将它们看成是网络模型框架、网络设计策略和网络学习策略等模块的不同组合[37],从而简化复杂的网络结构.
网络模型框架是SISR网络模型中最基本的模块,根据上采样层在网络模型中位置的不同,可将模型基本框架划分为4种类型:预上采样、后上采样、渐进式上采样、迭代式上下采样,如图1所示.上采样指的是将原始的LR图像转换为HR图像的操作,它作为SR中必不可少的环节,在网络模型框架中占有重要地位.
2.2.1 预上采样模型框架
预上采样模型框架中的上采样层位于网络前端的图像预处理环节,如图1(a)所示.该框架通常使用传统的基于插值的上采样方法,如线性插值、双三次插值等,最常用的是双三次插值的上采样方法.
早期的SRCNN[69,70],VDSR[55],DRCN[71]等网络模型都是使用预上采样模型框架,先将LR图像上采样为所需尺寸的HR图像,再将其输入卷积神经网络进行SR,以恢复HR图像的更多细节.预上采样模型框架的结构简单,能进行任意尺度因子图像的SR.但它先对LR图像进行上采样后再输入网络进行训练的操作,使网络模型的计算在高维空间中进行,显著增加了计算复杂度,时间及空间成本也随之增加,因此在近年网络模型中的使用逐渐减少.
2.2.2 后上采样模型框架
为了避免在高维空间中计算带来的影响,提高网络计算效率,后上采样模型框架将上采样层放置于网络末端,如图1(b)所示,直接将LR图像输入卷积神经网络中,在低维空间形成映射,最后在网络末端进行上采样后输出重建的HR图像.
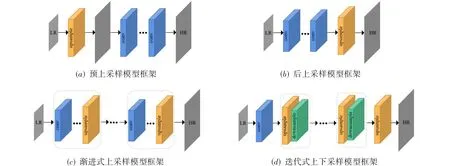
图1 图像超分辨率重建网络模型基本框架
后上采样模型框架在网络末端的上采样层通常使用的是基于学习的上采样方法,如转置卷积(又称反卷积)、亚像素卷积等,以实现端到端的自动学习.此外,元上采样(meta-upscale)[72]等特殊的上采样方法可用于任意尺度因子(1~4倍,步长为0.1)的SR.在后上采样模型框架的影响下,FSRCNN[56],ESPCN[73],BTSRN[74]和RNAN[75]等网络模型实现了网络加速并取得了较好的网络性能.
后上采样模型框架在低维空间计算的方式,能够在维持或提升网络性能的同时,降低网络计算量和空间复杂度,并提高网络计算效率.但对大尺度因子的学习存在一定难度,且无法满足单一模型的多尺度因子图像SR的需求,对不同尺度因子的图像需要训练不同的网络模型.
2.2.3 渐进式上采样模型框架
渐进式上采样模型框架如图1(c)所示,是以级联的方式连接卷积神经网络,并通过多个上采样层逐步重建得到最终的HR图像.LapSRN[76]是典型的采用渐进式上采样模型框架的网络模型,它将网络结构分成三级,每级进行两倍的上采样操作,通过逐级上采样实现两倍、四倍及八倍的超分辨率重建结果.MSLapSRN[77],LP-KPN[42]和E-ProSRNet[78]等网络模型也采用这种框架,实现了单一模型的多尺度因子图像SR.
渐进上采样模型框架采用逐步上采样的方式将困难的大尺度因子SR任务分解为多个简单的小尺度因子SR任务,极大地降低了学习难度,且在不引入过多时间和空间成本的情况下,能够满足单一模型的多尺度因子SR的需求.但存在模型结构设计复杂、训练稳定性差等问题.
2.2.4 迭代式上下采样模型框架
迭代式上下采样模型框架如图1(d)所示,该框架在网络中交替使用上、下采样层,再通过迭代反向投影不断改进重建图像细节,从而得到最终的重建图像.
DBPN[79](Deep Back-Projection Networks)网络模型是首个采用该框架的方法,它利用迭代的上下采样层的误差反馈机制来指导网络重建,获得最终的HR图像.相较于单向前馈神经网络直接学习输入图像到目标空间非线性映射的方法,DBPN网络模型将学习过程分成多个阶段,并为每个阶段的投影误差提供误差反馈机制,使模型具有自校正的过程用于修正重建细节,从而获得更好的重建结果.同时DBPN顺应深度学习发展趋势,将其扩展为多个变体以提升网络性能[80].此外,DSRN[81],SRFBN[82]等网络模型也在网络中交替使用上、下采样层,并通过不同的反馈机制改善HR图像细节.
相比于其他模型框架,迭代式上下采样模型框架能够更好地挖掘LR-HR图像对之间的深层关系,从而获得更多图像细节,构建更高质量的重建图像.但迭代式上下采样模型框架的网络结构较为复杂、发展还不成熟,仍需进一步探索.
2.3 图像质量评价指标
对于完成训练的网络模型,可通过不同的图像质量评价指标评估重建图像质量,验证网络模型有效性,测试网络模型性能.根据评价主体不同,可以将SR的图像质量评价指标分为主观评价指标和客观评价指标.
2.3.1 主观评价指标
主观评价指标是由评价人员根据自己的主观感受对图像质量进行评价的一种方式.根据是否有真实HR图像作为标准参考图像,可以将其分为绝对主观评价指标和相对主观评价指标.
绝对主观评价指标,如平均意见排名(Mean Opinion Rank,MOR)[83],是在无标准参考图像的情况下,评价人员根据自己的主观视觉感受及设定好的评价尺度对几种SR方法的重建图像质量进行排名从而计算得出的.
相对主观评价指标,如平均意见得分(Mean Opinion Score,MOS)[84],是在有标准参考图像的情况下,评价人员将不同SR方法获得的重建结果与标准的参考图像进行对比,并将图像进行组内对比,最后根据评价尺度对这组图像进行评分.
表2所示是主观评价指标两种方法的评价尺度.可以发现,这两种主观评价指标的评价尺度都是根据评价人员的主观感受进行衡量的,评价结果符合人类视觉感受,因此主观评价指标是最直接、最有效的评价方法.但主观评价指标易受评价人员的主观感受及各种因素的影响,有较大的不确定性,可重复性、实时性也较差,且评价过程需要耗费大量的时间、人力、物力、财力等,在实际使用过程中存在一定困难,因此难以被广泛应用.
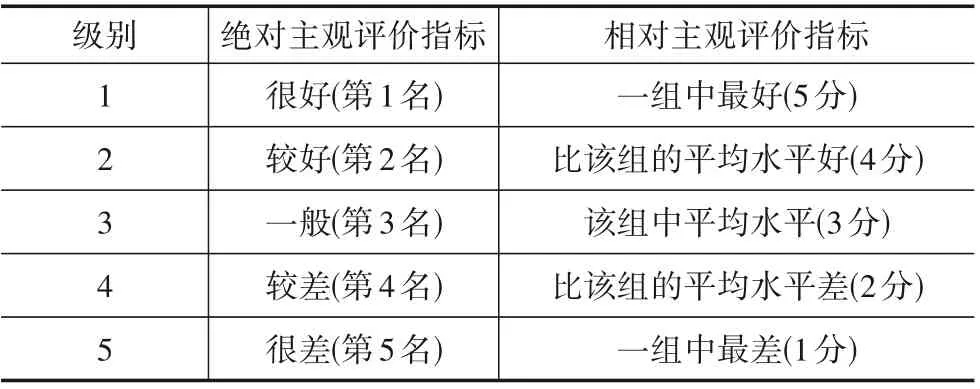
表2 主观评价指标的评价尺度
2.3.2 客观评价指标
客观评价指标是指通过不同的数学模型和算法来评估图像质量的方法[85,86],具有简单、高效、可重复性强等优点,因此SR中通常使用客观评价指标对重建图像进行质量评价.客观评价指标根据是否需要真实的HR图像作为参考图像,可以大致分为全参考型和无参考型两种.
全参考型的客观评价指标是将重建的HR图像与真实HR图像进行比较计算得出的,一般用于监督式SR的图像评估.该评价指标包括峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)、结构相似度(Structural SIMilarity,SSIM)、信息保真度准则(Information Fidelity Criterion,IFC)、学习感知图像块相似度(Learned Perceptual Image Patch Similarity,LPIPS)等,其中PSNR和SSIM是最常用的客观评价指标.
无参考型的客观评价指标无可参考的真实HR图像,因此常用于无监督式SR的图像评估.该评价指标包括自然图像质量评价(Natural Image Quality Evaluator,NIQE)、基于感知的图像质量评价(Perception-based Image QUality Evaluator,PIQUE)、无参考质量指标(No-Reference Quality Metric,NRQM)、感知指数(Perception Index,PI)等.
(1)峰值信噪比
PSNR是指通过计算重建HR图像与真实HR图像对应像素点之间的误差,从而客观地评估重建图像失真程度的指标.PSNR值主要由均方误差(Mean Square Error,MSE)决定,MSE表达式如式(7)所示:
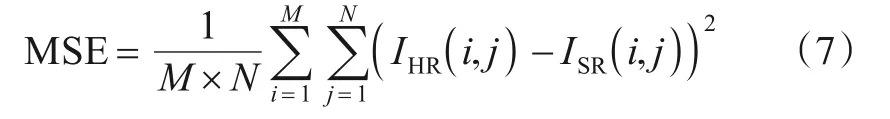
其中,M和N分别表示图像长、宽的像素数;IHR(i,j)和ISR(i,j)分别表示真实HR图像与重建HR图像在空间位置(i,j)处的像素值.
PSNR表达式如式(8)所示,单位为分贝(dB):
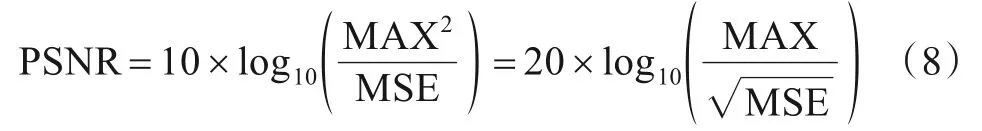
其中,MAX为IHR(i,j)图像的最大像素值,对于8比特(bit)精度的图像,MAX取值为255.
由式(7)和式(8)可以看出,最小化MSE损失函数(即L2损失函数)相当于最大化PSNR评价指标.PSNR值的取值范围为[0,+∞),其值越大,则表示重建HR图像与真实HR图像之间的像素误差越小,重建HR图像相对于真实HR图像的失真越少,重建图像的质量越好.PSNR通过逐像素计算的方法简单、高效,是SR领域最常用的图像质量评价指标.但PSNR仅从数学角度计算图像之间的差异,未从本质上考虑人类视觉系统(Human Visual System,HVS)特性,故PSNR计算结果反映的图像质量情况与人类主观视觉感受的图像质量情况存在一定差异,不能完全、准确地反映重建图像的感知质量.
(2)结构相似度
SSIM是由Wang等人[87]于2004年提出的,从亮度、对比度和结构三个方面来衡量参考图像与失真图像之间结构相似性的方法.SSIM主要由图像间的亮度、对比度和结构三部分信息组成,且三者之间是相对独立的,即亮度和/或对比度的信息变化不会影响图像的结构信息.
SSIM的表达式如式(9)所示:
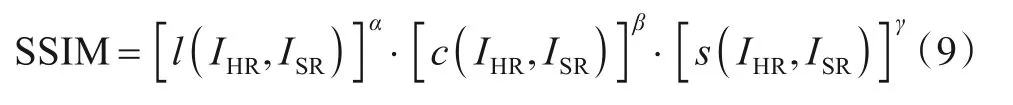
其中,α,β,γ为权重参数,分别用于调整l(IHR,ISR),c(IHR,ISR),s(IHR,ISR)三个分量的相对重要性,且α>0,β>0,γ>0.l(IHR,ISR),c(IHR,ISR),s(IHR,ISR)分别表示亮度、对比度、结构三个分量,它们的表达式分别如式(10)~(12)所示:
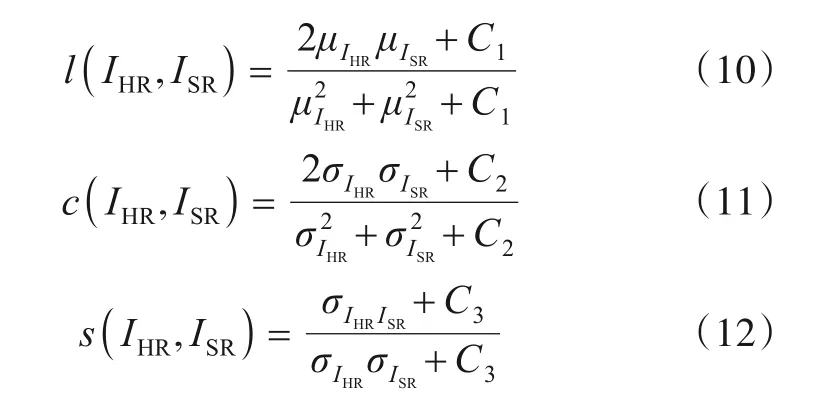
其中,μIHR,μISR分别表示IHR和ISR的均值;σIHR,σISR分别表示IHR和ISR的标准差;σIHRISR表示IHR和ISR的协方差;C1,C2和C3是为了避免计算中出现不稳定而添加的小常数.
特别地,当α=β=γ=1,且C3=C2/2时,SSIM可以表示为式(13),该形式是SR图像质量评价时最常使用的形式:
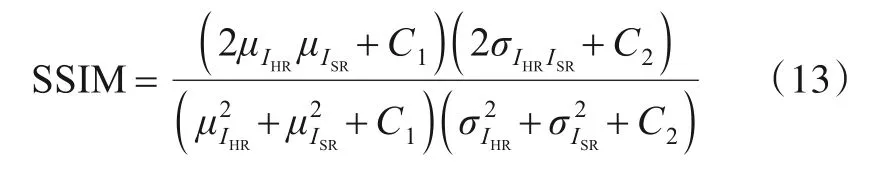
SSIM值的取值区间为[0,1],其值越大,表明图像质量越好.由于考虑了HVS特性,SSIM的计算结果相比PSNR指标能够更有效地反映重建HR图像的感知质量,与人类感知结果具有较好的一致性,因此SSIM被广泛用于SR图像的质量评价.在SR质量评价中通常使用PSNR和SSIM共同衡量重建图像质量.
(3)信息保真度准则
2005年,Sheikh等人[88]提出了一种基于自然场景统计信息对图像质量进行评价的方法,即IFC评价指标,通过结合自然场景模型和失真模型的统计模型,量化参考图像与测试图像之间的相互信息,从而量化图像感知质量,并以此衡量重建图像质量的优劣.
IFC的表达式如式(14)所示,该式量化了参考图像和失真图像之间共享的统计信息:
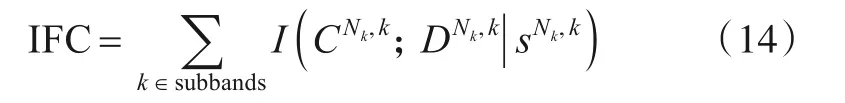
其中,CNk,k,DNk,k,sNk,k分别表示第k个子带RFCk,Dk,sk的Nk系数.
IFC是一个保真指标,而非失真指标,其值的取值范围为[0,+∞),IFC值越大,图像保真度越高,重建图像质量越好.IFC在信息提取过程中使用感知质量建模,因此IFC计算结果与人类视觉感知结果具有较好的一致性.
(4)学习感知图像块相似度
2018年,Zhang等人[89]提出LPIPS感知评价指标,利用预训练的深度卷积神经网络提取参考图像与失真图像的特征,计算图像在深度特征空间上的L2距离,并评估图像间的感知相似度.
LPIPS的表达式如式(15)所示:
其中,l表示深度卷积神经网络的第l层分别表示IHR和ISR从第l层中提取特征,并在通道维度上进行单元归一化的结果,且是用于缩放激活通道的向量,wl∈RCl,当wl=1∀l时,相当于计算余弦距离.
LPIPS是根据人类感知进行训练的,因此LPIPS值可以较好地反映人们对图像的主观感受,LPIPS值越小,图像的感知质量越好.
(5)自然图像质量评价
Mittal等人[90]于2013年提出了基于空域特征的完全无参考型的评价指标NIQE,通过从失真图像提取的自然场景统计特征和从自然图像提取的感知质量特征的多元高斯模型(MultiVariate Gaussian model,MVG)拟合参数之间的距离来评估失真图像的质量.
NIQE表达式如式(16)所示:
其中,ν1和Σ1分别表示自然图像MVG模型的均值向量和协方差矩阵,ν2和Σ2分别表示失真图像MVG模型的均值向量和协方差矩阵.NIQE的值越小,表示图像的质量越好.
(6)基于感知的图像质量评价
Venkatanath等人[91]于2015年提出了一种无参考感知的图像质量评价指标PIQUE,基于测试图像的局部块级别特征,估计给定测试图像中存在的失真量.PIQUE考虑了人类视觉注意力等人类感知图像质量原则,通过对输入图像进行预处理,提取自然场景统计特征,再对图像进行块级别分析以识别不同失真块的类型,并分配不同分数,最后合并块级别分数以确定整体图像质量.
PIQUE表达式如式(17)所示:
其中,NSA表示给定图像中空间活动块的数量,C1是防止数值不稳定添加的一个正常数,Dsk是失真块所分配的失真量.
PIQUE值的取值范围为[0,1],其值越小,图像质量越好.当PIQUE值接近于0(0~0.3)时,表示图像质量良好;当PIQUE值接近于1(0.5~1.0)时,表示图像质量较差;若PIQUE值介于0.3到0.5之间,则可将其视为平均质量图像.PIQUE的计算考虑了HVS特性,因此该评价指标的评价结果接近人类感知质量的评价结果.
(7)无参考质量指标
Ma等人[92]于2017年提出了一种无参考型评价指标NRQM,在一些文献中也将其简写为Ma.NRQM以重建的HR图像作为输入,将频率域和空间域中计算的统计量作为输入图像的特征,在单独的集成回归树中训练特征,并利用线性回归模型对大量的视觉感知分数进行学习,得到图像质量分数以评估输入图像的质量.
NRQM的表达式如式(18)所示:
其中,̂表示最终的质量分数,由3种类型特征的预测质量分数组成;λn表示不同类型特征的权重;表示不同类型特征的预测质量分数,通过对T个回归树的输出进行平均得到,(xn表示不同类型的低级特征,n=1,2,3;pt表示森林中第t棵决策树的概率,t=1,2,…,T).NRQM值越大,表明重建图像的质量越好.
(8)感知指数
PI是Blau等人[68]结合NIQE和Ma两个无参考客观评价指标提出的感知指标,该指标联合量化了准确性与感知质量,与主观评价指标具有高度的相关性.
PI的表达式如式(19)所示:
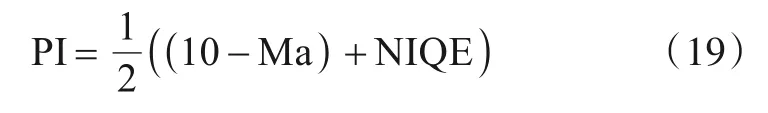
PI值越小,表明重建图像的感知质量越好.
3 监督式单帧图像超分辨率重建
目前大多数单帧图像超分辨率重建技术都是基于深度学习的方法进行研究的,并取得了较为丰富的研究成果.从早期基于卷积神经网络的超分辨率重建方法,如SRCNN[69]等,到很有前景的基于生成对抗网络的超分辨率重建方法,如SRGAN[93]等,再到近来大火于低级(low level)视觉任务界的基于Transformer的超分辨率重建方法,如IPT[94]等,基于深度学习的方法在图像重建效果上实现了很大的提升.图2给出了部分代表性SR算法的发展历程.按照学习模式的不同,可以将基于深度学习的SISR方法划分为监督式SISR(图中黑色)和无监督式SISR(图中蓝色);根据网络结构及图像重建效果的不同,将监督式SISR进一步划分为基于卷积神经网络(Convolutional Neural Network,CNN)的方法(图中轴线上方不加粗)、基于生成对抗网络(GAN)的方法(图中轴线下方)和基于Transformer的方法(图中轴线上方加粗).本节首先从监督式SISR角度出发,对代表性的算法进行评述.
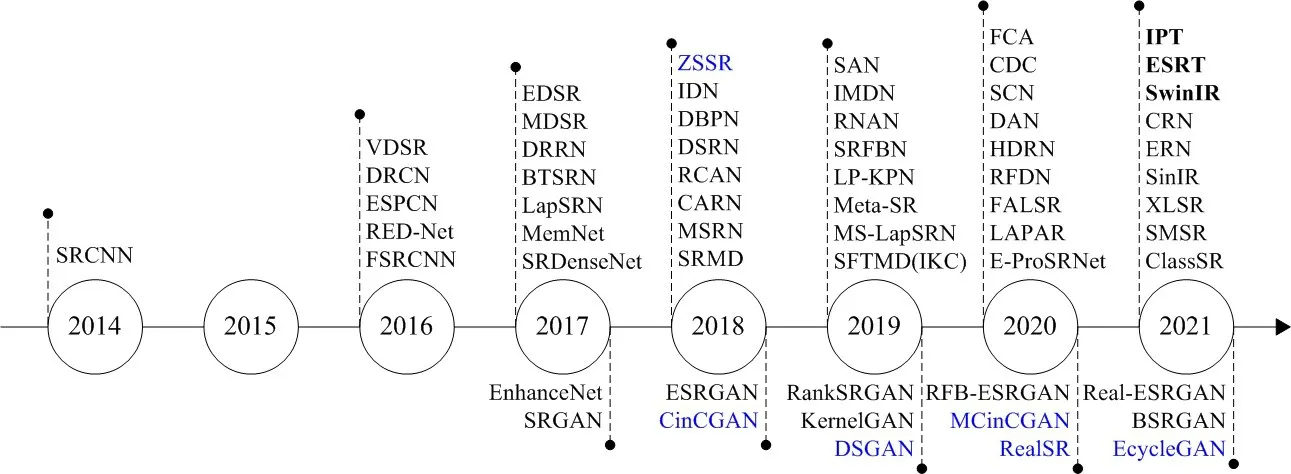
图2 基于深度学习的SISR部分网络模型的发展时间轴线
3.1 基于卷积神经网络的单帧图像超分辨率重建
卷积神经网络(CNN)是一种通过传统梯度下降法训练并学习图像特征的前馈神经网络,局部连接、权值共享等特性使其相较于其他神经网络能够更好地学习与表达图像特征,因此被广泛应用于图像处理领域[95,96].基于卷积神经网络的单帧图像超分辨率重建方法主要采用卷积神经网络的结构,以PSNR最大化为目标,旨在使网络获得更真实的细节、更好的保真度,即PSNR,SSIM等客观指标的提升.虽然基于CNN的方法在评价指标方面表现较好,但其重建图像往往过于平滑,无法带来很好的感知效果.
现有SISR网络模型是在不同模型框架的基础上应用不同的网络设计策略及学习策略构建的.根据网络模型中设计策略的不同,可以进一步将近年来较为经典以及新提出的网络模型分为以下几类:基于浅层卷积神经网络(Shallow Convolutional Neural Network,SCNN)的方法、基于残差网络(Residual Network,ResNet)的方法、基于递归神经网络(Recurrent Neural Network,RNN)的方法、基于密集卷积网络(Dense convolutional Network,DenseNet)的方法、基于注意力机制(Attentional Mechanism,AM)的方法和基于轻量化网络(Lightweight Network,LN)的方法.
3.1.1 基于浅层卷积神经网络的方法
2014年,Dong等人[69]首次将深度学习应用于图像SR领域,提出了第一个基于卷积神经网络的SISR网络模型SRCNN(Super-Resolution CNN).受基于稀疏编码的图像SR方法的启发对网络结构进行设计,得到由图像块特征的提取与表示层、特征的非线性映射层及重建层等简单的三层卷积神经网络构成的SRCNN网络(图3),实现LR图像到HR图像之间的端到端映射.虽然SRCNN相较于传统的SR方法在速度和重建质量上都有所提升,但预上采样的模型框架给它带来了计算复杂、训练收敛速度慢等问题,同时SRCNN还存在结构简单、难以充分利用图像上下文信息等不足之处.

图3 SRCNN网络结构
针对SRCNN计算成本高、难以实时应用的问题,Dong等人[56]又于2016年对其进行改进及加速,提出了FSRCNN(Fast SRCNN)网络模型.FSRCNN由特征提取层、收缩层、非线性映射层、扩张层以及反卷积层构成,它的主要改进是将SRCNN中的预上采样模型框架替换为后上采样模型框架,通过网络末端的反卷积层(图4)实现上采样,以解决计算复杂度高等问题.另外,还通过改变特征维数、共享映射层参数等操作,提高网络计算效率,提升重建图像质量.
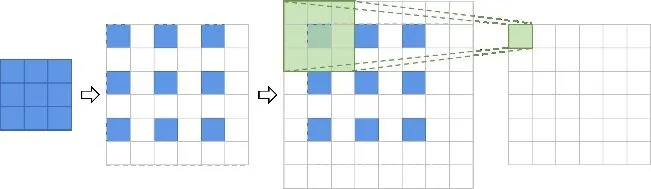
图4 反卷积层卷积过程
为降低计算复杂度、提升网络计算效率,Shi等人[73]也于2016年提出了另一种快速、高效的SR网络模型ESPCN(Efficient Sub-Pixel CNN),与FSRCNN一样采用后上采样模型框架,但ESPCN使用的是亚像素卷积层(图5)对图像进行上采样.ESPCN网络由包含两个卷积层的隐藏层和一个亚像素卷积层构成.它先从隐藏层中提取LR输入图像的特征,再从亚像素卷积层中获取重建的HR图像,从而实现快速高效的端到端学习,得到比FSRCNN网络模型更好的重建效果.
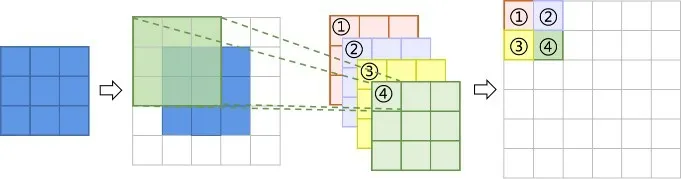
图5 亚像素卷积层卷积过程
尽管早期SRCNN,FSRCNN,ESPCN等浅层卷积神经网络模型的网络层数不超过5层,网络结构相对简单,没有使用过多的网络设计策略,但其重建效果相较于传统的图像SR方法得到了一定提升,对基于深度学习的图像SR的发展具有开创性作用.
3.1.2 基于残差网络的方法
为了提取更多图像特征,提升网络模型性能,最直接的方式是通过增加网络的深度或宽度来增多网络参数量.然而单纯地加深、加宽网络,随之出现的是梯度消失、梯度爆炸和网络退化等问题.对于梯度问题,通常使用批归一化或正则化等操作就能够很大程度地解决,但退化问题却仍然存在.对此,He等人[97]提出了残差网络用于解决深层网络带来的梯度和退化问题,其结构如图6所示,即在普通网络(plain network)中加入快捷连接(shortcut connections)/跳跃连接(skip connections)操作,使普通网络经过残差学习成为对应的残差网络.
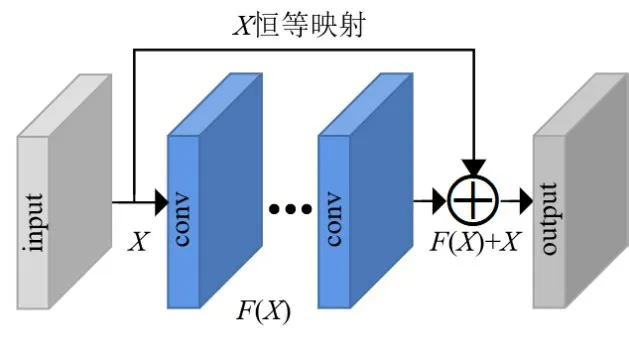
图6 残差网络应用于SR
ResNet具有全局残差学习和局部残差学习两种残差学习方式,主要区别在于全局残差学习是对网络模型的输入和输出之间进行快捷连接,局部残差学习则是对网络模型内部不同深度的层之间进行快捷连接.ResNet不仅能够有效提取图像细节信息,还能解决过深的网络层带来的梯度及退化问题,同时大量减少参数量和训练时间,因此在深层网络中被广泛应用.
受ImageNet分类比赛中深度卷积神经网络VGGnet的启发,Kim等人[55]首次将ResNet(图7(a))应用于图像SR中,于2016年提出了具有20个权重层的深度SISR网络模型VDSR(Very Deep CNN for SR).考虑到低、高分辨率图像之间的低频信息在很大程度上是相似的,他们利用残差学习的思想,在VDSR中学习低、高分辨率图像之间高频信息的残差,从而减少训练时间,提高训练速度.另外,他们还将ResNet与提高学习率、自适应梯度裁剪等策略相结合,使VDSR深度网络模型的训练过程更加稳定.此后,ResNet被广泛应用于图像SR网络模型中.
同年,Mao等人[98]提出了深度全卷积编解码网络RED-Net(Residual Encoder-Decoder Network),不仅可以进行图像SR,还能够解决图像去噪等其他图像恢复任务.受高速公路网络(highway network)和深度ResNet的启发,RED-Net模型在对称的卷积层和反卷积层之间添加了跳跃连接,以解决深层网络带来的各种问题.卷积层用于提取输入图像特征,反卷积层则利用跳跃连接直接与卷积层所提取的特征结合,从而更好地恢复出图像细节信息,也使得训练深层网络变得更加容易.
2017年,Lim等人[99]在SRResNet[93]结构(图7(b))的基础上进行优化,利用ResNet的思想构建增强型深度SR网络模型EDSR(Enhanced Deep SR),创新性地去除了SRResNet结构中的批归一化(Batch Normalization,BN)层(图7(c)).BN层在SR中对图像特征进行归一化的操作,会破坏图像信息,影响图像质量,因此去除BN层不仅可以改善图像质量,还能够在训练期间节省约40%的内存,实现同等计算资源条件下更深层网络的构建.同时,Lim等人采取残差缩放等方法解决深度网络训练不稳定的问题,从而实现深层网络重建图像质量的显著提升.为解决EDSR网络模型只能处理特定单尺度因子SR的问题,Lim等人对EDSR进行扩展,又提出了多尺度深度超分辨率网络模型MDSR(Multiscale Deep SR)用于单一模型的多尺度因子SR,而MDSR不仅能够大量减少参数量与训练时间,还能实现与EDSR相当的网络性能.
2018年,Li等人[100]指出一些网络模型性能的提高不是来自模型结构的改变,而是使用了一些未知的训练技巧,同时,大多数网络模型通过加深网络层数提升网络性能的方法难以充分利用LR图像特征,且无法使用单一模型处理多尺度任务.为此,Li等人在不使用任何训练技巧的情况下,提出了多尺度残差网络MSRN(Multi-Scale Residual Network)用于实现单一模型的多尺度SR任务,旨在通过网络结构的改变来提升网络性能.MSRN引入多尺度残差块(Multi-Scale Residual Block,MSRB)作为网络的基本构建模块,如图7(d)所示,MSRB将ResNet与不同尺度的卷积核结合,以获取不同尺度的图像特征,得到局部多尺度特征,最后将其与全局特征融合,充分利用LR图像特征,得到最终的重建图像.

图7 不同网络模型的残差块
2021年,Lan等人[101]指出大多数基于CNN的网络模型没有充分利用底层特征以致网络性能相对较差,因此提出了两个能够有效提取图像特征的网络模型用于图像SR.一个是包含多个局部共享组的级联残差网络CRN(Cascading Residual Network),该网络通过级联机制促进特征融合和梯度传播,以更有效地提取图像特征.另一个是具有双全局路径结构的增强残差网络ERN(Enhanced Residual Network),该网络通过双全局路径从原始输入中捕获长距离空间特征,以实现更强大的特征表达.通过结构的改进,CRN和ERN网络模型能够以更少的参数量实现与EDSR相当甚至更好的网络性能.
ResNet不仅能够通过局部或全局残差学习有效提取SR网络模型中低分辨率输入图像的特征信息,还可以解决过深网络带来的各种训练及梯度问题,因此许多SR网络模型都将残差学习的思想应用于网络结构中,以实现网络性能的提升,后期的很多SR网络模型也将残差学习思想与其他网络设计策略相结合,以获取更好的超分辨率重建效果.
3.1.3 基于递归神经网络的方法
RNN结构通常由输入状态x、输出状态y和循环状态s组成,如图8(a)所示,可以将其按照时间顺序展开,以上一时刻(t-1)的输出与当前时刻(t)的输入同时作为当前网络的输入,从而得到当前时刻(t)的输出,再不断迭代上述过程得到最终的输出[102].由于RNN的网络层主要用于记忆数据,而不是分层次处理,且每次迭代后新的图像信息都会被添加到每一层中,所以RNN在无限次的网络更新迭代后可以获得无限的记忆深度[103].RNN在SR中是以递归的方式多次应用相同的模块,如图8(b)所示,其内部的模块具有参数共享的特性,使网络模型能够在不引入过多参数的情况下学习更高层次的特征,从而提升网络性能.
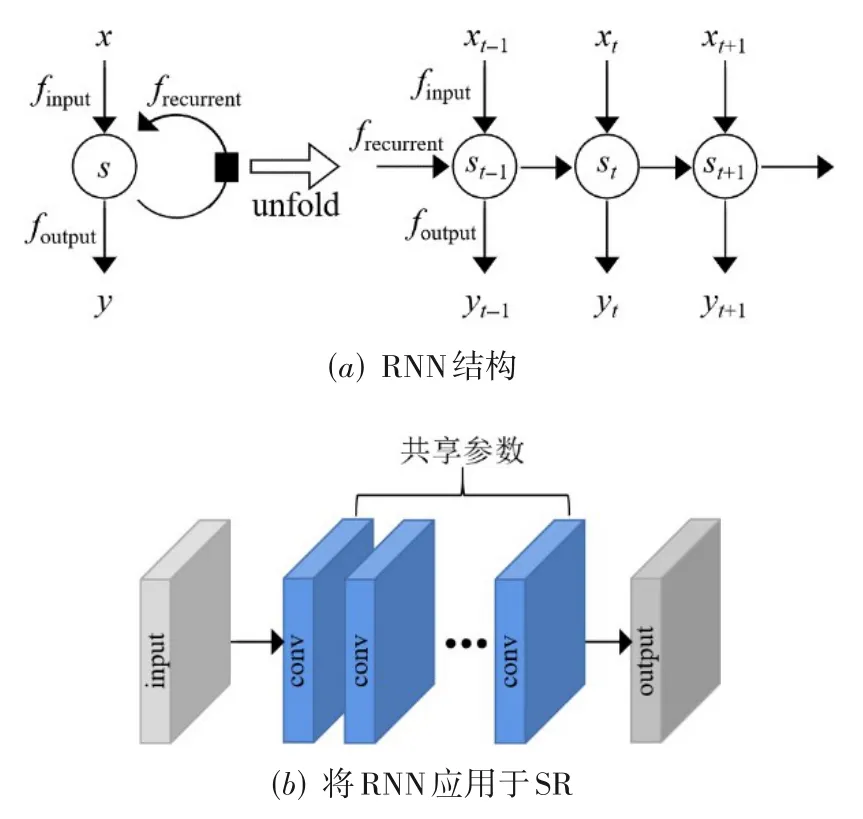
图8 递归神经网络
为了控制深度网络中的参数量,避免增加网络深度带来的过拟合等问题,Kim等人[71]首次将RNN应用于图像SR中,并结合残差学习的思想,于2016年提出了多达16个递归层的深度递归卷积网络DRCN(Deeply-Recursive Convolutional Network),通过对部分卷积层采用递归学习的方式,实现在不引入过多参数的情况下提升网络性能.DRCN由用于特征提取的嵌入网络、用于特征非线性映射的推理网络和重建网络等三个子网络构成,是将全局残差学习、单权重递归学习及多目标优化结合的SR方法.Tai等人[104]在DRCN的基础上,进一步结合ResNet和RNN,提出了多达52个卷积层的深度递归残差网络DRRN(Deep Recursive Residual Network),通过更深层次的网络结构提升网络模型的性能,同时结合多路径模式的局部、全局残差学习以及多权重的递归学习,控制参数量并稳定网络.
Han等人[81]认为许多深层SR网络结构可以表示为具有各种递归函数的单状态递归神经网络的有限展开,并从RNN的角度理解深层结构,如图9(a)~(c)所示.基于此,他们提出了双状态递归网络DSRN(Dual-State Recurrent Network),其RNN结构如图9(d)所示.与使用相同空间分辨率的单状态模型不同,DSRN能够在不同的空间分辨率中运行,在LR和HR空间采用两个循环状态,通过网络中的延迟反馈机制,在LR-HR之间交换循环信号,充分利用LR和HR空间的特征,得到最终的重建图像.
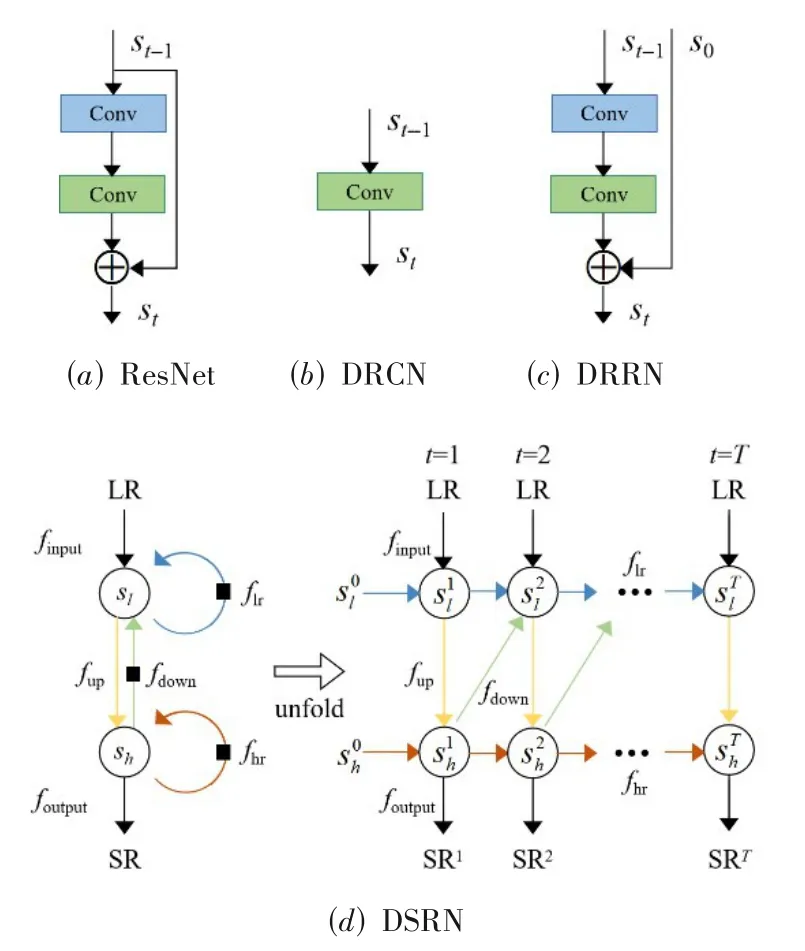
图9 不同网络模型的RNN展开
2019年,Li等人[82]同样利用反馈机制,提出了一种图像超分辨率反馈网络SRFBN(SR Feedback Network),将高阶信息细化为低阶表示,并逐步生成最终的HR图像,实现较少参数量情况下的网络性能提升.图10所示是SRFBN网络模型的反馈机制,反馈方式通过使用带约束的RNN中的隐藏状态来实现.同时,SRFBN网络模型还引入了课程学习(curriculum learning)策略,通过将逐步增加重建难度的目标HR图像依次送入网络进行连续迭代,使网络能够逐步学习复杂的退化模型,从而更好地适应复杂的任务.
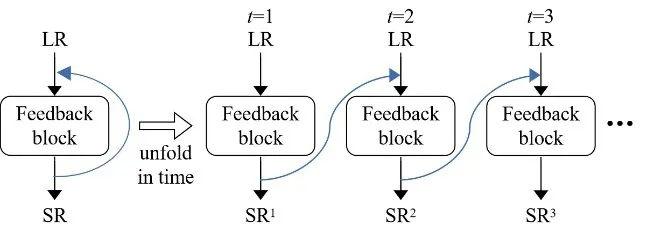
图10 SRFBN反馈机制
RNN参数共享的特性使其能够在不引入过多参数的情况下学习更高层次的特征,但仍然无法避免深层网络带来的梯度和训练等问题,因此RNN通常会与ResNet、多监督学习、课程学习等网络设计及学习策略相结合,以缓解梯度及训练问题,实现网络性能的提升.
3.1.4 基于密集卷积网络的方法
2017年,Huang等人[105]提出DenseNet,并将其概括成一种简单的连接模式,即为了确保网络各层之间的最大信息流,直接连接具有相同特征图大小的任意两个层,并扩展到所有层的连接.DenseNet在SR中应用的结构图如图11所示,对于网络中的每一层,该层前面所有层的特征图都作为该层的输入,而该层的特征图将成为后续所有层的输入之一.
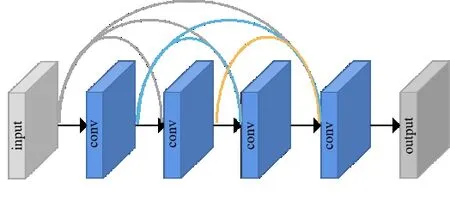
图11 密集卷积网络应用于SR
与ResNet使用求和的方式将浅层特征传递到后续层再组合起来不同,DenseNet是通过连接的方式来组合它们.与传统的连接方式也不同,DenseNet采用密集连接的方式进行组合能够充分利用层间信息.DenseNet通过加强层间特征传播,鼓励层间特征重用,使网络模型中各层的特征被充分利用,从而大大减少参数量,改进网络的信息流动和梯度,有效缓解梯度消失的问题,使网络更容易训练.
2017年,Tong等人[106]首次将DenseNet应用于SR中,提出了SRDenseNet(Super-Resolution DenseNet)网络模型,通过密集跳跃连接将低、高层特征有效融合,再利用反卷积层进一步提升重建图像的细节信息.同年,Tai等人[107]提出了深度持久记忆网络Mem-Net(deep persistent Memory Network),使用DenseNet中的密集连接操作来加强特征传播,弥补信息丢失,进一步增强高频信号.MemNet由特征提取网络、多个堆叠的记忆块以及重构网络组成,其中最主要的结构是由用于模拟非线性函数的递归单元和用于自适应学习不同记忆权重的门单元组成的记忆块(图12).它通过自适应的学习过程来挖掘持久记忆,从而构建深度网络的长期依赖关系.
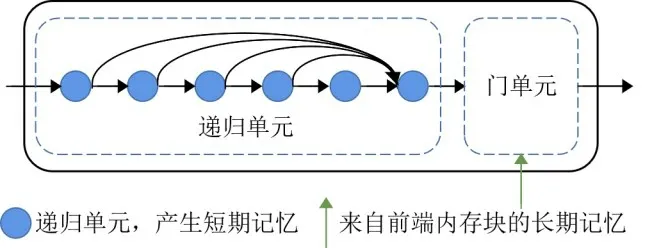
图12 记忆块结构
单一的网络设计策略通常难以获取较大的网络性能提升,因此多策略的有效结合对网络性能的提升至关重要.2019年,Shamsolmoali等人[108]提出基于扩张卷积神经网络的新模型,通过将DenseNet与扩张卷积进行适当的结合,得到性能与效率有效权衡的网络模型.次年,Pan等人[109]提出基于密集残差网络的网络模型,利用基于高斯过程的神经结构搜索(GP-NAS)和异构模型集成等策略在真实图像SR中取得优异性能,并得到高保真度的重建图像.而Jiang等人[110]提出的分层密集残差网络HDRN(Hierarchical Dense Recursive Network)同样在DenseNet的基础上利用分层残差块和全局融合模块实现整个网络由粗到细的特征重建,从而得到准确的重建效果.
DenseNet在SR网络中通过密集连接的方式使网络模型中各层的特征被充分利用,不仅大大降低了网络参数量,而且有效缓解了梯度消失的现象,使得深度网络易于训练.但单一的网络设计策略往往难以实现较大的网络性能提升,将DenseNet与不同网络设计及学习策略进行有效组合,才能使基于DenseNet的SISR网络模型实现更好的重建效果.
3.1.5 基于注意力机制的方法
注意力机制是根据图像特征的重要性程度分配不同的权重,使网络以高权重聚焦重要信息,以低权重忽略无关信息,从而改善图像细节,提升图像重建质量的机制,具有较好的灵活性和鲁棒性[111].目前主流的注意力机制包括通道注意力、空间注意力和自注意力.2018年,Hu等 人[112]提 出 的SENet(Squeeze-and-Excitation Network)将通道注意力机制引入深度神经网络中,通过引入“挤压-激励”块(SE block)显式建模通道之间的相互依赖,提高网络的特征学习能力,其结构如图13所示.
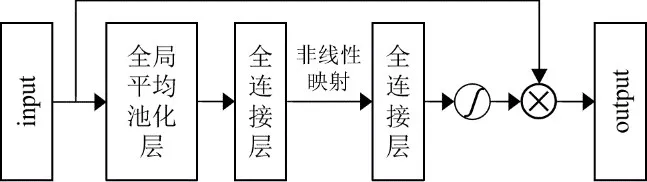
图13 通道注意力机制
前述基于CNN的网络模型在通道中平等对待LR输入图像包含的丰富低频信息,影响了网络的表征能力,因此Zhang等人[113]于2018年首次将注意力机制应用于SR中,提出残差通道注意力网络RCAN(Residual Channel Attention Network).RCAN中的通道注意力机制能够根据通道之间的依赖关系自适应地重新调整每个通道的特征,从而学习到更多有用的通道特征,提高网络表征能力.此外,RCAN中还使用了残差中的残差(Residual In Residual,RIR)结构,通过长、短跳跃连接构建深度可训练网络.
2019年,Dai等人[114]指出现有的基于CNN的网络模型大多通过设计更宽或更深层次的网络结构来提升性能,忽视了对中间层特征相关性的探索,从而限制了网络的表征能力.而RCAN中引入的经典通道注意力机制通过全局平均池化利用特征的一阶统计量,却忽略了高于一阶的统计量,从而阻碍了网络的判别能力,且研究表明二阶统计量较一阶统计量更有助于特征判别性的表示.为此,Dai等人提出了二阶注意网络SAN(Second-order Attention Network)并引入二阶通道注意力(Second-Order Channel Attention,SOCA)机制(图14),通过协方差归一化获取特征的二阶统计量来学习特征的相关性,使网络关注更多特别的特征,提高判别学习能力,从而实现更强大的特征相关学习和特征表达能力.受SOCA机制的影响,SAN网络模型在具有纹理等更高阶信息的图像上表现更佳.
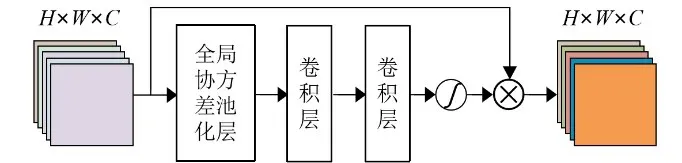
图14 二阶通道注意力机制
2020年,Wei等人[43]没有通过统一处理图像中的所有像素/区域/组件或者侧重处理边缘或纹理来训练SR网络模型,而是受Harris角点检测的启发,根据图像所传达信息的重要性,将图像分为平面、边缘和角点三个低层次部分,并利用沙漏超分辨率网络HGSR(Hour-Glass SR),分别构建与平面、边缘和角点相关的三个组件注意力块来探索不同组件的重要性,从而提出组件分治CDC(Component Divide-and-Conquer)网络模型,旨在以分而治之的方式解决真实世界的SR.另外,Wei等人还提出了一种梯度加权损失函数,根据图像重建难度适应模型训练,以解决图像中不同区域在各个方向梯度不同的问题.
相比于其他类型的基于CNN的网络模型,基于注意力机制的网络模型通常会区别对待图像中的重要和不重要区域,并通过设置高权重加强对图像重要区域的特征提取,从而获取更有效的图像信息.与基于RNN,DenseNet等网络设计策略的网络模型相同,基于注意力机制的网络模型也需要与残差学习、课程学习等其他网络设计及学习策略相结合,才能取得更好的网络性能提升.
3.1.6 基于轻量化网络的方法
轻量化网络指的是通过设计更加紧凑的网络结构或者在原始网络结构的基础上使用一些轻量化策略来减少网络参数量,提升网络速度,并保持或提升原有网络性能的一种高效网络.LN旨在将SR算法应用于实际,实现真正意义上的轻量化及移动设备端的SR任务部署,是对性能与效率的一种权衡.目前,轻量化网络中常用的轻量化策略有很多,如使用扩张卷积(dilated convolution)、群卷积(group convolution)或者深度可分卷积(depthwise separable convolution)等先进卷积来替代传统的卷积操作,从而实现更高效的性能,同时还有网络剪枝(network pruning)、知识蒸馏(knowledge distillation)、神经架构搜索(neural architecture search)和自适应推理(adaptive inference)等轻量化策略可用于轻量化网络的构建.
为实现SR算法的实际应用,2018年,Ahn等人[115]提出了一种精确、高效的深度级联残差网络CARN(CAscading Residual Network)及其轻量化的移动变体CARN-M(CARN-Mobile).CARN网络模型在ResNet的基础上将残差块(图15(a))替换为级联块(图15(c)),并通过局部和全局残差学习传递图像信息,该网络注重网络性能的提升.CARN-M网络模型则在CARN的基础上结合有效的残差块(图15(b))和将级联块进行参数共享的递归块(图15(d))来优化参数量及操作数量,以实现性能与速度的权衡并获得高效的SR网络模型,使其能够应用于移动设备.
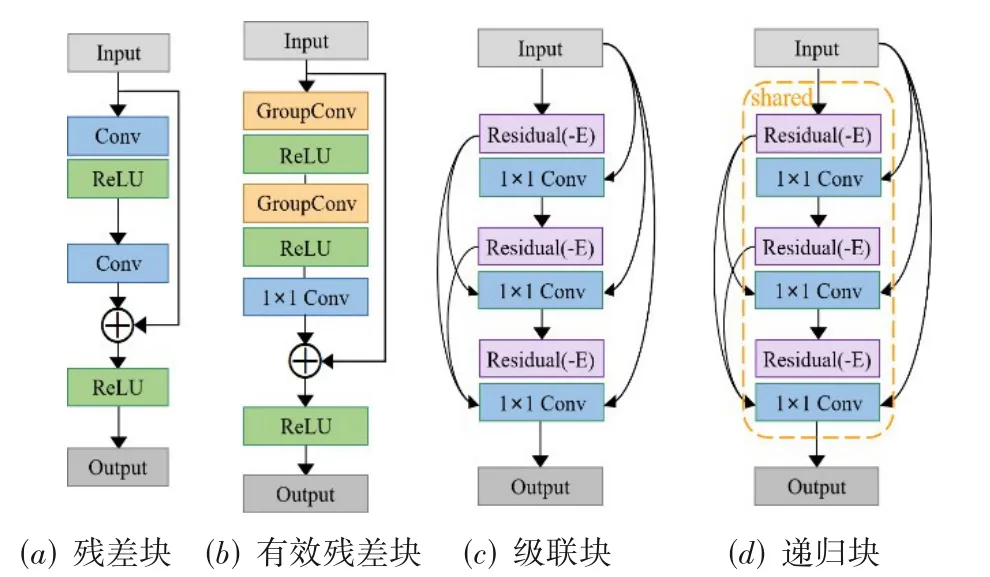
图15 CARN不同模块结构对比
同年,Hui等人[116]为减少网络运行时间,利用群卷积和信息蒸馏块等轻量化策略提出了一种由特征提取块、信息蒸馏块和重建块三部分组成的紧凑且深层的信息蒸馏网络IDN(Information Distillation Network).由增强单元和压缩单元组合而成的信息蒸馏块(图16)作为IDN网络的重要结构,能够逐步提取丰富而有效的图像特征.其中,增强单元利用通道分离策略保留局部信息并处理后续信息,主要用于增强LR输入图像的轮廓区域,而压缩单元则由1×1卷积层构成,主要用于降维及提取相关图像信息.IDN网络模型在群卷积、知识蒸馏和每层过滤器数量设置相对较少等各种策略的影响下,网络速度有了很大的提升.
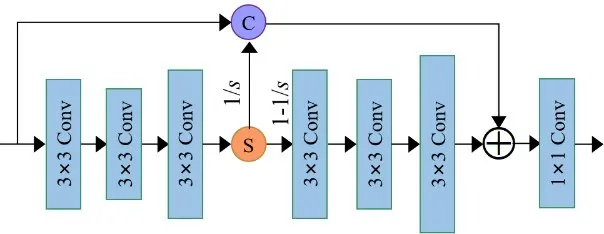
图16 IDN网络模型的信息蒸馏块
2019年,Hui等人[117]在IDN的基础上对信息蒸馏块加以改进,设计出信息多蒸馏块(图17)用于构建轻量化的信息多蒸馏网络IMDN(Information Multi-Distillation Network),并利用自适应裁剪策略解决任意尺度因子的SR问题.信息多蒸馏块由渐进细化模块(Progressive Refinement Module,PRM)、对比感知通道注意层以及能够减少特征通道数量的1×1卷积构成,用于逐步提取更加细腻、更具真实感的图像特征.在各种策略的作用下,IMDN在客观评价指标和推理时间方面都表现良好,并取得了AIM 2019受限超分辨率重建挑战赛的冠军.次年,Liu等人[118]在IMDN基础上加以改进,提出了与通道分离策略具有相同操作的特征蒸馏连接,用于构建残差特征蒸馏网络RFDN(Residual Feature Distillation Network).RFDN在信息蒸馏网络的作用下实现了更轻量化和更灵活的图像SR,并获得了AIM 2020高效超分辨率重建挑战赛的冠军.

图17 IMDN网络模型的信息多蒸馏块
为减少网络参数量和运算量,Chu等人[119]引入一种融合微观和宏观搜索的、新型的弹性神经架构搜索(Neural Architecture Search,NAS)方法,微观搜索空间用于提取特征单元块,宏观搜索空间则使用密集连接将特征单元块连接起来,从而构建能够实现快速、准确和轻量化的三种FALSR(Fast,Accurate and Lightweight SR)网络模型,其中FALSR-A在视觉效果方面表现最好,FALSR-B具有最低的参数量,FALSR-C的网络性能则表现得比轻量化的CARN网络模型更好.而Li等人[120]提出的线性组合像素自适应回归网络模型LAPAR(Linearly-Assembled Pixel-Adaptive Regression)将直接学习LR图像到HR图像的映射问题转化为基于多个预定义过滤器字典的线性回归任务,同时根据特征通道数量(C)和局部融合模块数量(M)提出了LAPAR-A(C32-M4),LAPAR-B(C24-M3)和LAPAR-C(C16-M2)三种模型以评估网络的可扩展性.LAPAR三种网络模型在两倍尺度因子的情况下均表现出比FALSR三种网络模型更高效的重建效果,且在保证运行速度的同时,该模型在图像去噪、JPEG去块等其他低级视觉任务中也表现良好.
2021年,Wang等人[121]提出了稀疏掩码超分辨率重建网络模型SMSR(Sparse Mask SR),通过研究图像的稀疏性减少网络的冗余计算,提高网络的推理效率.相较于独立关注空间及通道维度冗余计算的自适应推理和网络剪枝方法,SMSR提供了一个统一的框架来考虑空间和通道维度的冗余计算,通过将空间掩码与通道掩码结合,使用空间掩码学习识别图像的重要区域,使用通道掩码学习标记图像的不重要区域,因此精确地删除网络中冗余计算的部分,使网络能够有效地降低计算成本,以获得更好的效率,同时保持相当的性能.此外,SMSR在移动设备上的应用也有显著的加速.
轻量化网络能够在维持或提升网络性能的同时,降低网络参数量,提高网络速度,实现更高效的SR网络,使SR算法能够部署在现实应用中.尽管出现了越来越多的轻量化网络并取得了一定的成果,但大多数网络主要关注参数量和浮点运算次数(Floating Point Operations,FLOPs),然而FLOPs越少并不意味着网络效率越好,相反,网络激活的数量是网络效率更准确的衡量标准[122].因此,对于轻量化网络效率的衡量不能只关注参数量和FLOPs,而应该从各个角度进行全面的分析[123],进而实现高效的轻量化网络.
3.2 基于生成对抗网络的单帧图像超分辨率重建
生成对抗网络是Goodfellow等人[124]于2014年提出的一个通过对抗过程评估生成模型的新框架.如图18所示,该框架包含两个子模块:一个是生成器(Generator,G),用于捕获数据分布;另一个是判别器(Discriminator,D),用于判断输入数据的“真伪”.估计输入数据是来自训练数据而非来自G的概率,通过对抗博弈的方法训练两个网络,不断完善G和D,直至D“难辨真假”则完成训练.
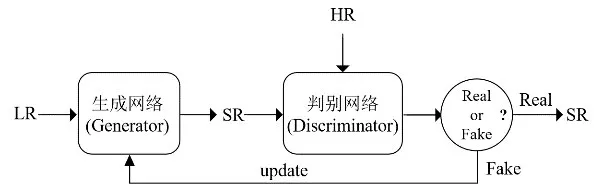
图18 生成对抗网络
基于GAN的方法主要采用生成对抗网络的结构,以感知驱动的方式训练网络,旨在使重建图像获得更好的感知质量、更逼真的视觉效果,在视觉效果上更接近真实图像,但该方法在客观评价指标方面表现不佳,对图像细节的恢复存在误差.
2017年,Ledig等人[93]首次将GAN应用于图像SR领域中,提出了SRGAN(Super-Resolution Generative Adversarial Network)网络模型.SRGAN包含生成网络和对抗网络,生成网络将输入的LR图像进行SR生成重建后的HR图像,而判别网络则判断输入的是重建的HR图像还是原始的HR图像.若判断错误则两者继续相互迭代训练,直至判别网络将输入的重建HR图像当成是原始的HR图像则完成训练.相较于之前基于CNN的网络模型,SRGAN不仅使用GAN改进网络结构,同时也将感知损失应用于SR中,采用感知损失与对抗损失组合的损失函数,从而使重建图像的细节更加丰富、图像更具真实感,在感知质量上得到了很好的提升.但GAN框架的“欺骗性”使它的PSNR和SSIM等客观评价指标相对较低.
为生成纹理逼真、图像自然的SR图像,Sajjadi等人[125]提出了一种结合感知损失的自动纹理合成的增强型网络EnhanceNet.EnhanceNet同样采用了GAN的结构,生成网络部分是一个用于纹理合成的前馈全卷积神经网络,通过GAN与感知损失的结合,能够实现高放大倍数的真实纹理,而判别网络部分则遵循常见的设计模式.同时为证明不同损失函数对重建图像质量的影响,Sajjadi等人还对各种损失函数的重建结果进行比较,验证了以MSE为损失函数的重建图像虽然有最高的PSNR和SSIM等客观评价指标,但其重建结果较为平滑,缺乏高频细节,而将感知损失、对抗损失以及纹理损失相结合的损失函数所生成的重建图像虽然客观评价指标较低,但却能产生具有真实纹理及逼真视觉效果的重建图像.
受SRGAN的启发,Wang等人[126]于2018年提出了ESRGAN(Enhanced SRGAN)网络模型,主要在网络结构、损失函数等方面对SRGAN进行改进.在网络结构方面,生成网络去除了残差块中的BN层,并引入了残差中的残差密集块(Residual-in-Residual Dense Block,RDDB)结构,判别网络则用相对判别器代替原有的标准判别器.在损失函数方面,对感知损失进行改进,通过使用激活层前的特征,增强图像的表征能力,并引入网络插值[127]的方法使重建图像从平滑的重建结果向感知质量较好的重建结果转移.得益于这些改进,ESRGAN网络模型的网络性能及重建图像都得到了很好的提升.
ESRGAN通过对SRGAN的改进,实现了优异的感知重建效果,故此后基于GAN的网络模型大多都是在ESRGAN网络模型上进行改进创新.如BSRGAN[47],RFB-ESRGAN[128](NTIRE 2020感知极端SR挑战赛的冠军模型)和Real-ESRGAN[48]等网络模型的结构都是基于ESRGAN结构进行改进,并取得了优异的重建效果.
Zhang等人[129]指出许多与人类主观评价高度相关的感知质量评价指标(无参考型客观评价指标)通常是不可微的且无法作为损失函数优化网络模型,故提出由标准的SRGAN和Ranker组成的RankSRGAN网络模型.其中Ranker是一个通用和可微的模型,可以通过学习排名的方法模拟任意感知指标的行为,并作为损失函数优化网络.RankSRGAN网络模型在公共SR数据集上使用不同的SR方法生成SR图像,再将成对的图像对根据感知质量得分进行排名后构建排名(rank)数据集用于网络模型的训练.因此RankSRGAN网络模型能够结合不同SR方法的优点,在感知质量方面产生更好的结果,并恢复出比SRGAN和ESRGAN网络模型更真实的纹理.
基于GAN的方法利用GAN结构的对抗性使网络重建效果更具真实感,对不关注细节的整体图像具有较好的应用效果,但该方法存在大量的网络参数,使得网络训练不稳定,推理速度也因此延缓.对于基于GAN的方法要注重图像细节的重建,同时采用合适的策略构造轻量化网络并使其训练稳定.
3.3 基于Transformer的单帧图像超分辨率重建
Transformer是由Google的Vaswani等人[130]于2017年提出的一种用于自然语言处理(Natural Language Processing,NLP)的网络架构,其模型架构如图19所示.它摒弃了RNN和CNN,是一个完全基于自注意力机制来获取输入和输出之间全局依赖关系的转换模型.相较于CNN通过堆叠卷积层扩大感受野以获取全文信息,RNN通过递推捕捉全局联系,却难以捕捉长距离依赖,而自注意力机制能够更好地捕捉全局联系,解决了长距离依赖的问题,同时能够支持并行化计算,加快训练速度,提升网络效率.
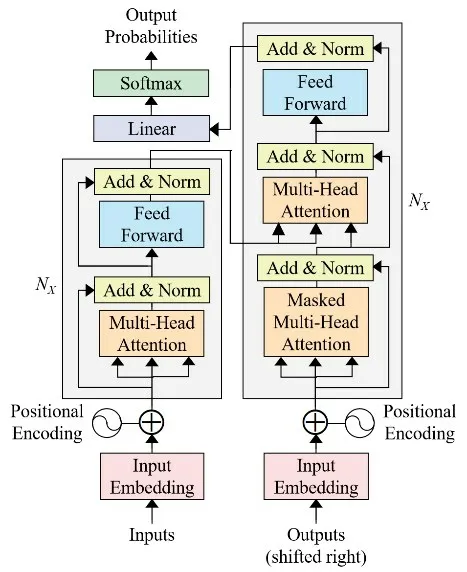
图19 Transformer模型架构
Transformer最初是为了NLP任务中的序列建模而设计的,而后随着ViT(Vision Transformer)[131],DETR(Detection Transformer)[132],ViViT(Video Vision Transformer)[133]等网络模型的相继提出,Transformer逐渐被应用于计算机视觉领域,并取得比CNN、非极大抑制和3D卷积等更好的效果[134].
基于Transformer的方法主要采用Transformer的结构,将自注意力机制引入网络中.由于Transformer强大的图像表征能力和各式各样的结构,此类网络能够得到较CNN更好的重建结果和评价指标.当前基于Transformer的SR方法主要有两种类型:一种是完全使用Transformer结构作为网络架构的纯Transformer网络模型;另一种是将Transformer作为主干网络与CNN相结合的混合Transformer网络模型.
2021年,Chen等人[94]将Transformer架构应用于计算机视觉领域,联合提出了一种用于处理SR、去噪和去雨等多种低级计算机视觉任务的预训练网络模型IPT(Image Processing Transformer).该网络属于纯Transformer模型,以端到端的方式进行学习,网络结构主要由用于从输入退化图像提取特征的头(heads)、用于从输入数据中重建丢失信息的编-解码器(encoderdecoder)Transformer和用于输出重建图像的尾(tails)三部分构成,其中编-解码器Transformer与原始Transformer[130]中的结构相似,不同之处在于该网络利用了特定任务的嵌入作为解码器的附加输入.为了最大限度地挖掘Transformer的潜力,作者采用包含1 000个类别的ImageNet数据集构造了大量的退化图像数据对,并利用这些数据对对IPT模型进行训练.同时,为了使IPT模型更好地适应不同的图像处理任务并将其应用到未知任务上,作者还引入了对比学习(contrastive learning)来学习通用的特征.最后,经过微调后的预训练IPT模型可以有效地用于所需的任务,且在不同任务上的表现超过了大多数现有的方法.
2021年,Liang等人[135]基于Swin Transformer[136]的结构,提出了一种用于图像恢复的网络模型SwinIR(Image Restoration Using Swin Transformer).该网络属于混合Transformer模型,网络结构主要由浅层特征提取、深层特征提取和图像重建三个模块组成.浅层特征提取模块采用卷积层提取浅层特征,并利用残差连接将浅层特征直接传递给重建模块,以保留图像的低频信息;深层特征提取模块主要由多个RSTB(Residual Swin Transformer Block)和一个用于特征增强的卷积层组成,每个RSTB中利用STL(Swin Transformer Layer)进行局部注意和跨窗口交互;而图像重建模块则通过融合浅层和深层特征,实现高质量图像的重建.SwinIR网络模型整合了CNN和Transformer的优势,既能够利用CNN处理大尺度因子的图像SR问题,也能够利用Transformer解决长距离依赖的问题,从而在图像SR、图像去噪和JPEG压缩伪影减少等低级计算机视觉任务上表现出良好的性能.
同年,Lu等人[137]指出Vision Transformer计算成本高、GPU内存占用大等问题导致网络无法设计得过深,为此,提出了一种新的高效网络ESRT(Efficient SR Transformer),以研究在轻量级SR任务中使用Transformer的可行性.ESRT是一个混合Transformer的网络模型,网络结构主要由浅层特征提取、轻量级CNN骨干(Lightweight CNN Backbone,LCB)、轻量级Transformer骨干(Lightweight Transformer Backbone,LTB)和图像重建四个部分组成.其中,LCB通过动态调整映射图的大小,能够以较低的计算成本提取深层图像特征,可用于解决Transformer在小数据集上特征提取能力差的问题.而由一系列高效Transformer(Efficient Transformer,ET)组成的LTB,主要用于获取图像中相似块的长期依赖关系,同时利用ET解决其他Vision Transformer参数大和GPU内存消耗大的问题.通过这些改进,ESRT能够有效地增强图像中相似块的特征表达能力和长期依赖性,从而获得更好的性能,验证了Transformer在轻量级SR任务中的可行性.
无论是纯Transformer网络模型还是混合Transformer网络模型,目前基于Transformer的方法均表现出比基于CNN的方法更好的网络性能,但基于Transformer的方法目前仍处于发展阶段,因此主要注重网络模型重建质量的提升,对于实际的应用考虑较少,后续可结合实际应用考虑更具实用性的轻量化Transformer网络模型.
4 无监督式单帧图像超分辨率重建
无监督式SISR旨在通过从未配对的LR-HR图像中学习函数来解决SR问题,从而得到更能够处理真实世界场景下SR问题的网络模型.目前,大多数SR网络模型都是采用有监督学习的方法进行网络训练,但监督式SR仍然存在一些难以解决的问题,如真实数据集构造过程存在一定难度,合成数据集采用的退化过程具有一定的人工先验,无法完全符合图像真实退化过程等.而无监督式SR可以对未配对的LR-HR图像对进行训练,相比于需要使用成对的LR-HR图像对进行网络训练的监督式SR,其在真实世界的图像SR任务上更具优势,因此逐渐受到研究人员的关注,如AIM 2019和NTIRE 2020等真实世界图像超分辨率重建挑战赛就旨在以弱监督或无监督的学习方法来实现SR.本章主要将无监督式SISR分为“零样本(zeroshot)”图像超分辨率重建和弱监督式图像超分辨率重建两类进行介绍.
4.1 “零样本”单帧图像超分辨率重建
2018年,Shocher等人[138]认为现实图像是具有模糊、噪声、伪影和压缩等性质的非理想图像,监督式的SR方法无法很好地解决非理想图像的SR问题,因此不适用于真实世界图像的SR.为解决此问题,Shocher等人提出了第一个无监督式的基于CNN的网络模型ZSSR(Zero-Shot SR).ZSSR网络不依赖模型的预训练,而是利用单个图像内部的信息,在测试时直接训练一个小型的特定图像的CNN,仅从输入的LR测试图像中提取内部信息,从而实现各种大小、尺度因子的非理想图像的SR.图20为监督式SR与ZSSR的对比,相较于监督式SR需要花费较多时间对网络进行预训练从而得到图像的先验知识,ZSSR能够在测试时直接进行网络的训练与测试,同时在非理想的图像上表现出比EDSR网络模型更好的性能.但ZSSR存在测试时间较长以及对每张图像都需要训练一个特定网络模型的缺点.
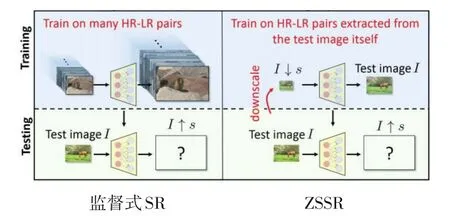
图20 监督式SR与ZSSR对比[138]
4.2 弱监督式单帧图像超分辨率重建
对于未配对的LR-HR图像,弱监督式SR主要是采用不同的方法,在不引入预定义退化的情况下进行SR.根据所用方法的不同,大致可以将其分为两种类型:一种是运用无监督式的退化模型学习图像退化过程以构造合成数据集进行SR,另一种则是在网络中通过不同的循环结构以实现弱监督式SR.
为解决监督式SR方法无法应用于现实世界场景图像的问题,Bulat等人[139]于2018年提出了一个弱监督式的两阶段网络模型.首先利用一个GAN模型以无监督的方法学习HR图像的退化和下采样过程,得到相应的LR图像,再对前一个GAN模型的LR输出图像进行重建,训练一个由LR图像到HR图像的GAN模型,从而实现真实世界图像的SR,有效地提高真实世界LR图像的质量.此外,DSGAN[50]和RealSR[60]等网络模型同样以无监督的方式获取相应LR图像并构造合成数据集,解决LR-HR图像不匹配的问题,再基于改进后的ESRGAN网络模型进行图像的重建,取得了很好的重建效果,并分别在AIM 2019和NTIRE 2020真实图像超分辨率重建挑战赛上获得了冠军.
2018年,Yuan等人[140]受CycleGAN[141]的启发,以生成对抗网络为基本结构,提出了一种无监督式的循环生成对抗网络模型CinCGAN(Cycle-in-Cycle GAN).该模型包含2个CycleGAN:第一个CycleGAN通过将有噪声和模糊的LR输入图像映射到一个双三次下采样的clean LR空间,从而得到去噪和去模糊后的LR图像;第二个CycleGAN则用于学习从第一个CycleGAN中输出的LR图像到HR图像的映射,即通过现有的SR网络模型来重建中间结果到所需的放大倍数,再以端到端的方式对这两个模块同时进行组合和微调,从而得到HR重建图像的输出.此外,为进一步提高CinCGAN的网络性能,Zhang等人[142]又于2020年采用渐进式多循环策略及模糊损失对CinCGAN加以改进,提出了一个多循环网络模型MCinCGAN(Multiple Cycle-in-Cycle GAN),用于处理多种尺度因子、退化未知且复杂和LRHR图像不匹配的SR问题.
Wu等人[143]认为导致无监督式SR模型产生不满意重建效果的关键在于不真实的低频信息和不准确的高频纹理,因此利用数据约束策略从损失函数、训练数据和后处理等方面对CycleGAN的结构进行改进,提出了无监督的ECycleGAN(Enhanced CycleGAN)网络模型.他们通过引入新的图像约束损失函数来补偿无监督学习中像素级监督的缺失,并限制判别器的数据内容,促进其抑制高频纹理或伪影,此外还引入了模型平均策略用于后处理.由于这些改进,ECycleGAN的训练变得更加稳定,同时图像重建能力也得到了有效提升.
5 图像超分辨率重建发展趋势
5.1 图像超分辨率重建网络模型汇总
为便于分析图像超分辨率重建的发展趋势,表3对前述部分网络模型相关内容进行总结对比.表中的类型按照前述网络模型进行分类.LR图像获取方式:Bicubic表示双三次下采样,B表示模糊核,GB表示高斯模糊核,N表示噪声,GN表示高斯噪声,J表示JPEG压缩.由于数据增强[144]能够扩大数据容量,减少迭代次数,并在一定程度上提升网络性能,所以许多网络模型常通过随机翻转、旋转和缩放等操作对数据集进行数据增强.
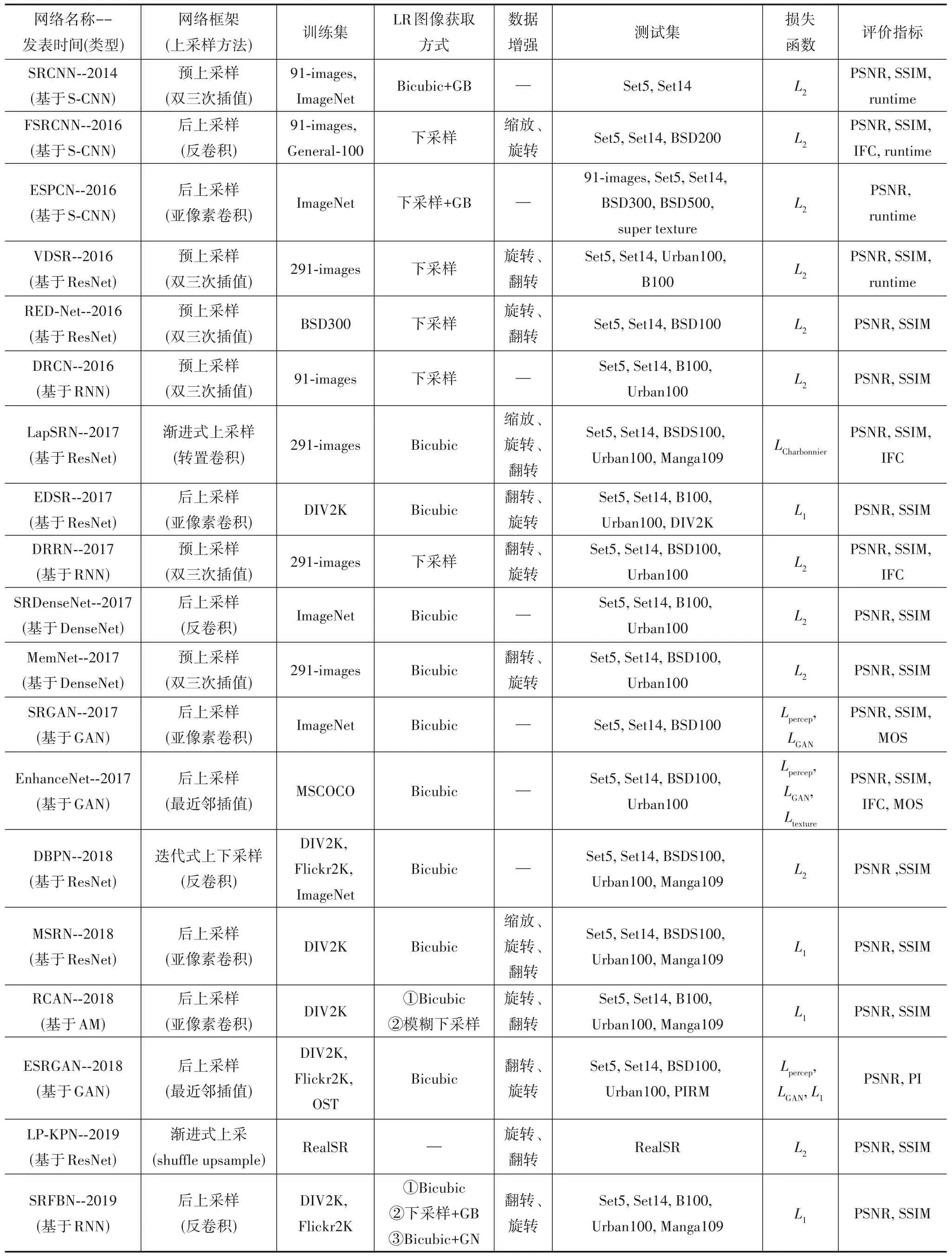
表3 基于深度学习的单帧图像超分辨率重建典型网络模型总结
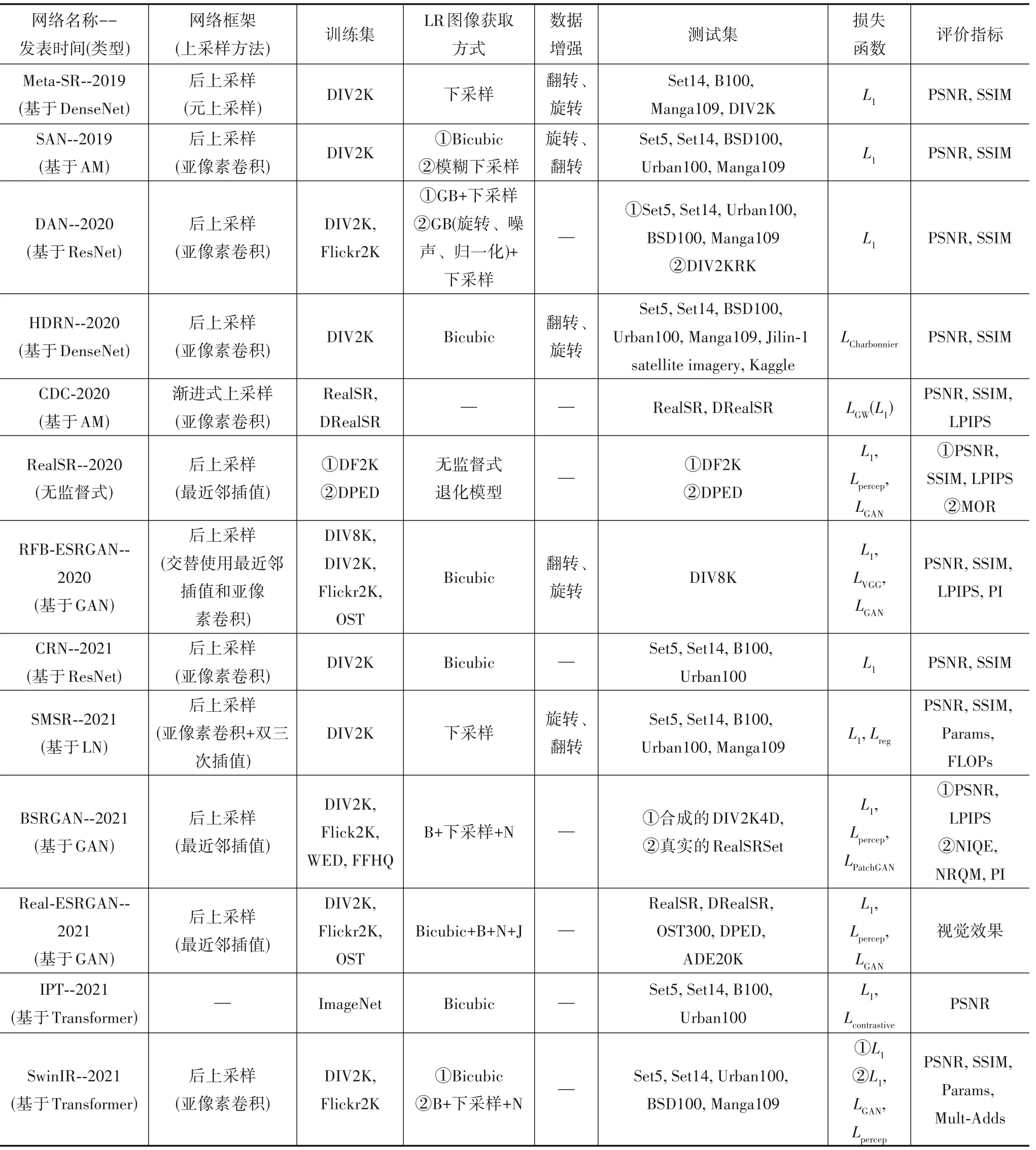
续表
对于网络模型的总结对比,除了表3所示的内容外,本文还在Wang等人[37]的基础上,对最新网络模型的SR精度(即PSNR)、模型大小(即参数数量)和计算代价(即操作数multi-add)进行基础测试对比,如图21所示.SR精度由网络模型在Set5,Set14,B100和Urban100四个基准数据集上的平均PSNR值来衡量,再计算模型大小和计算成本,尺度因子为2.
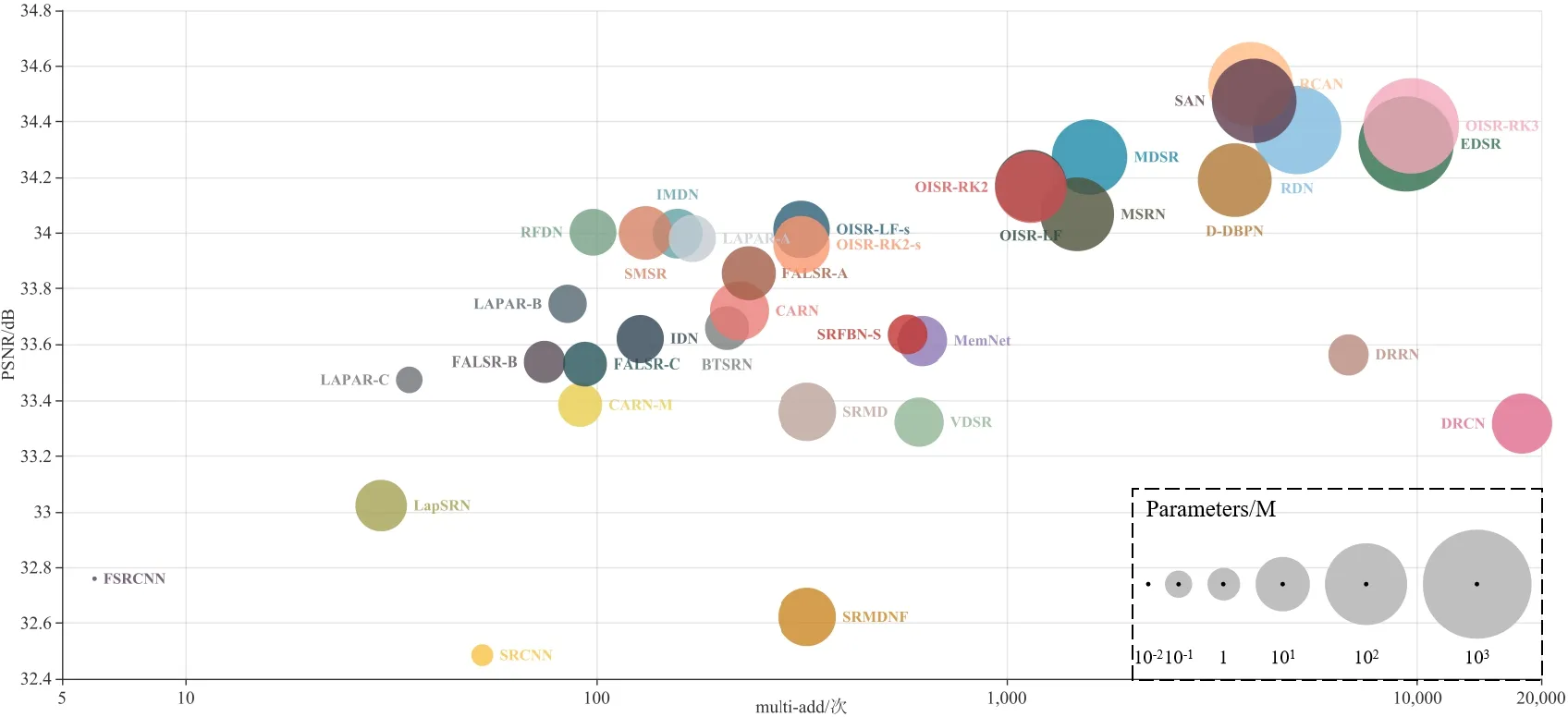
图21 图像超分辨率重建基准测试
5.2 图像超分辨率重建挑战赛
ICCV(IEEE International Conference on Computer Vision,即国际计算机视觉大会)、CVPR(IEEE Conference on Computer Vision and Pattern Recognition,即国际计算机视觉与模式识别会议)和ECCV(European Conference on Computer Vision,即欧洲计算机视觉国际会议)是世界三大顶级的计算机视觉会议.近年来,利用深度学习技术的图像SR研究取得了显著进展,相关挑战赛也层出不穷.其中最有影响力的图像SR挑战当属三大顶会所组织的NTIRE(New Trends in Image Restoration and Enhancement,即图像恢复与增强的新趋势)挑战赛、AIM(Advances in Image Manipulation,即图像处理的进展)挑战赛以及PIRM(Perceptual Image Restoration and Manipulation,即感知图像恢复与处理)挑战赛.
NTIRE挑战赛一般是与同年的CVPR会议同期开展,研究图像恢复与增强的新趋势,聚焦图像、视频的质量改进与评估,涉及图像及视频的超分辨率重建、去噪、去雾、去模糊等内容.NTIRE挑战赛自2017年开始举办至今,吸引了不少图像处理领域的研究者和爱好者的关注,是近年来计算机视觉领域非常有影响力的一场赛事.2021年,NTIRE挑战赛在图像处理挑战方面没有关于SISR的相关挑战,但在视频处理挑战方面有一场关于MISR的挑战.另外,还有一场与CVPR 2021联合举办的首届Mobile AI 2021挑战赛,旨在从移动设备端开发端到端基于深度学习的图像SR的解决方案,并在移动或边缘NPU上实现实时性.
AIM挑战赛是关于图像处理类的国际挑战赛,涵盖了图像、视频处理的多个热门研究方向,例如超分辨率重建、重光照、图像补全等.AIM挑战赛中关于图像SR的挑战主要涉及真实世界的图像SR和高效的图像SR.AIM挑战赛与NTIRE挑战赛一样在计算机视觉领域有很大的影响力,自2019年起连续举办了两年,2021年由于时间和资源的限制没有举办.
PIRM挑战赛是2018年与ECCV 2018 PIRM研讨会联合举办的第一个关于感知图像超分辨率重建的挑战.PIRM挑战赛中提出的无参考型客观评价指标PI联合量化了准确性和感知质量,且与主观评价指标具有较强的相关性,为感知SR的图像质量提供了有效的评价指标.虽然PIRM挑战赛只举办了一届,但它为感知图像SR今后的发展奠定了坚实的基础.
为分析图像超分辨率重建的发展趋势,表4[59,68,83,123,145~153]从赛道设置、数据集使用、评价指标等方面总结了近年来上述挑战赛的相关信息.
5.3 图像超分辨率重建发展趋势
从基于CNN到基于GAN再到基于Transformer的单帧图像超分辨率重建的发展,表明了基于深度学习的图像超分辨率重建技术取得了阶段性的成功,开始从PSNR目标最大化的SR向感知驱动的SR再到性能显著提升的SR转换.虽然现阶段基于深度学习的图像超分辨率重建技术已有很多表现优异的成果,但仍存在很大的发展空间.根据表3对现有研究成果的总结和表4对近年相关挑战赛的相关内容总结,可以从以下几个方面对图像超分辨率重建领域未来的发展趋势进行展望.
(1)性能提升
当前,影响SR网络性能的主要因素是训练数据集以及网络结构等.网络结构包括网络模型中使用的网络框架、损失函数、网络设计及学习策略、网络深度及宽度等.改善这些因素可以提升网络性能,获得重建效果更好的网络模型.
(a)训练数据集.数据集是影响网络性能的重要因素,如何采集数据集并构建训练数据集则至关重要.目前,训练数据集可以通过合成数据集以及真实数据集的两种方式获取.
从表3和表4可以看出,近年来训练集中LR图像的获取方式已逐渐从简单的双三次合成数据集向真实数据集以及无监督式模拟退化过程的合成数据集转变.在网络结构变化较小的情况下,通过转变训练集获取方式的网络模型性能也能有所提升,如RealSR[60]网络模型在网络结构方面只对ESRGAN判别网络进行改进,并通过无监督式退化模型合成数据集,就得到了很大的性能提升.因此为了获得更好的图像质量,可以通过改善训练数据集的构建方式,模拟图像真实退化过程,扩大退化空间使模型更具泛化性,以便对各种真实场景进行SR.

表4 图像超分辨率重建相关挑战赛内容总结
(b)损失函数.损失函数作为网络结构的一部分,在网络模型中也占据重要地位.相较于之前单纯使用一种损失函数(L2损失或L1损失)的方法来看,多种损失函数的组合已表现出明显优势,能给图像带来更好的感知效果[125].但目前尚未出现标准的组合型损失函数.如何进行损失函数的有效组合得到最佳的重建结果,仍需继续探索研究.
(c)评价指标.图像质量评价指标作为衡量图像质量的重要方式之一,在SR图像的质量评价中具有重要地位.MOS和MOR等常用的主观评价指标虽然能够较为准确地衡量图像的感知质量,但昂贵的人工成本及不可复现性,使该指标并没有被广泛应用.尽管PSNR和SSIM等客观评价指标通过计算图像间的像素差距对图像质量进行衡量的方式,与主观评价指标存在反相关的关系,无法准确反映人对重建图像的主观评价,但从表3、表4中可以看出,PSNR和SSIM仍然是目前主流的SR评价指标,同时,从表中可以发现,近年来的评价指标有从全参考型的客观评价指标向无参考型客观评价指标转变的趋势.由于现有的客观评价指标与主观评价指标存在一定的差异,所以探索一种符合人类视觉感受且便于使用的客观评价指标也将是一个重要的研究方向.
目前,评价网络模型视觉效果的测试图像通常是采用一些自然图像,如动物、建筑、文字等,并通过放大图像,观察动物毛发、建筑框架、文字信息等图像细节来衡量重建图像的视觉效果,该方法从整体及局部对图像质量进行评估,虽然能够较为准确地评价图像重建质量,但对于一些视觉效果较为相似的图案就难以辨别其重建质量.因此,可以通过引入西门子星图(图22(a))、USAF-1951分辨率板(图22(b))等靶标图对网络模型的性能进行评估,并通过图形的线对关系等判断空间分辨率,从而更为准确地评估网络模型的性能.
图22 不同类型靶标图
(d)算法结合.目前,已有将SR算法与其他计算机视觉任务相结合共同处理图像问题的应用,如SCN[154],SinIR[155]和IPT[94]等网络模型.图像的退化过程是由模糊、噪声等各种因素造成的,相较于单独训练网络处理去模糊、去噪等单个图像问题后再进行图像SR,组合处理的方式能够更有效地一次性处理各种图像问题,很大程度上节省了存储空间,提升了计算效率.因此,可以进一步研究SR算法与其他计算机视觉任务结合共同处理图像恢复问题的方式.
(e)通用插件及框架.除了从整体的网络结构上进行改进实现特定网络模型的SR,也有不少研究人员研究通用的插件和框架旨,在从局部上对网络进行改进,从而实现网络性能的提升.如Kong等人[156]提出的一种利用数据特性加速SR网络的通用框架ClassSR,通过类模块将子图像按照难易程度分类,用不同分支处理不同难度的类,最终实现几乎所有基于学习的大图像SR方法的加速.又如Wang等人[157]利用条件卷积开发的插件模块,不仅可以处理任意尺度的SR问题,还可以处理非对称的SR问题.
(2)实际应用
一个好的网络模型不仅要具有良好的网络性能,且要能够将算法应用于实际才能真正起到作用.尽管现有的大多数网络具有良好的性能,但很多却无法应用于实际.因此现有的网络模型越来越重视实际的应用,追求高效、实时、轻量化.从表4所示的挑战赛发展趋势可以看出,SR算法正在从学术研究向工业产品应用转化.
(a)注重网络效率,构建轻量化SR网络模型.从AIM 2019受限SR及AIM 2020高效SR的挑战赛中可以看出当前网络对实时性的需求,同时从评价指标的变化也可以看出实时性不仅仅是由参数量、运行时间以及浮点运算次数(FLOPs)等决定的,网络激活的数量等也具有一定的影响.所以衡量一个网络的效率不仅是从运行时间、参数量和FLOPs方面考虑,还要从其他方面考虑并进行全面的分析.近来,SR网络模型已实现较好的性能,但却难以实现实时性需求,因此往后的发展要注重轻量化网络模型的构建,使SR算法能够应用于实际.
(b)注重网络质量,构建应用于真实场景的SR网络模型.从基于CNN到基于GAN方法的转变,是从PSNR目标最大化的SR向感知驱动的SR转变,同时也表明了感知SR的重要性.从表3、表4中训练数据集构建方式的转变可以看出,SR的发展逐渐从经典SR转向真实世界的SR,网络模型更加注重对现实场景SR的应用,可见能够实现真实场景图像而非合成场景图像的应用才是各项SR技术的最终落脚点.
(c)注重网络应用,构建基于移动设备的SR网络模型.从Mobile AI 2021挑战赛中可以看出,目前超分的一个发展趋势是从硬件设备端转向移动设备端,使相关的SR网络模型能够应用于实际,实现算法的落地.如Ayazoglu等人[158]针对现有模型在移动设备端运行的限制因素对网络构建块加以改进,提出了一个极轻量化的超分辨率网络XLSR(Extremely Lightweight SR),在运行时间和模型参数等方面得到很大提升,并且能实现移动硬件端的高效运行,最终获得了Mobile AI 2021挑战赛的冠军.
(d)特定领域的应用.目前大多数的SR网络模型主要用自然图像进行训练,虽具有一定的泛化性,但对于红外图像、遥感图像等特定场景图像的SR依旧存在局限性.如何将这些特定场景的先验知识与深度学习的框架结合起来应用于SR中是一个值得探索的方向.
6 总结
本文对基于深度学习的单帧图像超分辨率重建的相关知识及现有研究成果进行综述.随着单帧图像超分辨率重建技术的发展,构建数据集的方式已逐渐从简单的双三次合成数据集向真实数据集以及大规模和无监督式合成数据集转变,旨在构建具有更大退化空间和更真实退化过程的退化模型.模型框架仍然以后上采样模型框架为主.评价指标虽有向无参考型客观评价指标转变的趋势,但目前仍以PSNR和SSIM为主.单帧图像超分辨率重建从最初的以PSNR最大化为目标到以感知驱动为目标再到以Transformer为主干的发展,是图像超分辨率重建算法的一大进步,也为后续超分辨率重建网络的发展提供了新思路,促进了图像超分辨率重建技术的进一步发展.目前,单帧图像超分辨率技术已在学术研究上取得了较好的成果,后续的研究重点会向算法的应用部署以及工业产品研发方面转移.
