面向共享单车服务调度的流程规划算法
2022-11-07徐悦甡周奕杉黄健斌
徐悦甡,周奕杉,黄健斌,李 莹,黑 蕾
(1.西安电子科技大学 计算机科学与技术学院,陕西 西安 710071;2.浙江大学 计算机科学与技术学院,浙江 杭州 310058;3.西安电子科技大学 期刊中心,陕西 西安 710071)
0 引言
随着经济社会各行业与前沿高新技术间联系的日渐紧密,共享经济悄然兴起。在共享经济模式下,共享单车服务与城市交通逐渐融合,在一定程度上弥补了城市传统公共交通存在的“首尾一公里”问题,有效缓解了交通道路拥堵,构建了低碳出行体系。共享单车服务遍布世界各地,截止2020年7月,全世界已有超过2 000个正在运行的共享单车服务[1],其中拥有悠久历史的有桩共享单车服务占主导地位。
虽然共享单车服务充分利用了社会资源,但是由于人们用车的复杂随机性,以及多种外界因素的影响,共享单车站点经常出现单车资源分布不均衡的情况,如果经常找不到可以满足用车需求的站点,则在极大降低用户用车体验和满意度的同时损害运营商的品牌形象和收入。解决站点单车资源分布不均衡问题的关键在于合理规划共享单车服务调度的流程,具体为:①确定每个站点的用车需求量,这取决于对站点借车和还车需求的准确预测,然而由于时间、环境等多种因素和人们行动的复杂性,难以得到某个站点需求变化的规律;②共享单车服务调度的流程规划是一个多目标优化问题,需要考虑各个供需失衡站点在未来一段时间内的用车需求,以及形式路径、调度成本和调度车容量等约束,再规划出合理的调度流程。运营商通常用一个调度车队为站点重新分配单车,或者运走单车,来满足站点未来一段时间的用车需求,而为每个站点确定未来时间的借车、还车需求,以及为每辆卡车按约束条件规划调度路线,即为共享单车服务调度的流程规划问题。
实际上,每个站点与邻近站点密切相关,因为车站的车桩和单车数量有限,如果站点单车资源短缺,则在运营商重新调整站点的单车资源前,车站将长时间处于不可服务状态,这段时间内站点无法满足用车需求。当人们到达的站点没有足够单车时,通常会前往附近车站借用单车,因此站点及其周围站点组成的合理的站点集群更能反映人们的真实用车需求。在发生单车短缺后,对该站点用车需求进行的预测将不再准确,然而以往研究仅集中于预测站点的用车需求,站点集群对共享单车服务真实用车需求的体现及其在调度流程规划中的价值常被忽略。
本文提出一种面向共享单车服务调度的流程规划算法,具体贡献如下:①结合历史骑行数据中站点的用车需求相关性和位置关系动态挖掘站点集群,从时空和气象数据中提取特征,利用极端梯度提升(eXtreme Gradient Boosting, XGBoost)模型对不同时段站点集群的用车需求进行预测;②提出一种历史时间窗口K近邻与再分配算法估计每个站点的用车需求;③基于蚁群算法(Ant Colony Algorithm, ACA)建立数学约束模型,提出一种解决共享单车服务静态调度的流程规划算法;④通过实验验证了所提算法的准确性和有效性。
1 相关工作
对共享单车服务中资源分配不平衡站点的调度流程进行规划,调整单车数量,已经成为解决单车资源不平衡问题最常用的方式。然而,发生短缺后再向站点重新调度单车资源为时已晚,需要提前规划调度流程,目前对调度流程规划的研究分为动态调度流程规划和静态调度流程规划两类。
动态调度流程规划主要在白天进行,对站点的调度操作依赖于用车需求。ZHANG等[2]考虑车站的实时容量,并建立预测用户到达站点的时空网络流模型,结合混合整数线性规划(Mixed Integer Linear Programming, MILP)模型和数学启发式方法提出动态单车调度流程规划方法;SHUI等[3]利用混动视野法将时间分成一组时间段,每个时间段看作一个静态调度流程规划问题,然后采用人工蜂群算法求解;CHIARIOTTI等[4]对站点的历史骑行数据进行统计,并对借车和还车情况建立统计学模型以确定动态调度的时间,利用图论给出单车资源调度流程的规划策略。
2 基于预测的需求调度
2.1 站点集群动态挖掘
准确预测站点集群需求量可为后续单车分配和调度流程规划提供指导,这对共享单车服务调度至关重要。为更准确地得到集群中站点的用车需求量,应该尽可能将具有相似使用需求的站点划分到同一个且大小合适的站点集群中。适宜的站点集群能够让集群中的用车需求量更加集中并凸显用车规律,以使预测的用车需求量更加可靠。由站点划分得到的站点集群应该包含相同时间跨度内用车需求趋势相似和地理距离相互邻近的站点,构造邻接图G=(S,E),其中节点集S=(S1,S2,…,Sn)表示数据集中所有的n个站点,E是相应两个站点间的连接边集。构建图时仅需考虑相互邻近的站点,本文用K近邻(K-Nearest Neighbor, KNN)方法为每个站点选取k个具有前k个边权重值的站点来构造一个稀疏的邻接图G。sim(Si,Sj)表示站点间在一组时间段内用车需求向量的皮尔森相关系数,边权重值用站点、使用需求相似度sim(Si,Sj)和站点间的地理距离计算,即
W(Si,Sj)=
(1)
式中:dist(Si,Sj)为站点Si和站点Sj之间的地理距离;τ为站点间的相邻距离阈值。站点集群中的站点应该相互邻近,故式(2)中站点间的地理距离小于阈值τ会被奖励,大于阈值τ会被惩罚。将构建出的邻接图G切分为一组子簇,每次迭代时动态选择两个子簇进行合并,被选择合并成新簇的子簇应该具有较高的相对连通度RI(Ci,Cj)和相对紧密度RC(Ci,Cj)(见式(3))。相对连通度RI考虑了簇和簇之间的距离以及簇内部各数据点之间的距离,相对紧密度RC用于避免将较小的稀疏簇合并到较大的密集簇。
RC(Ci,Cj)=
(2)
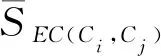
2.2 站点用车需求预测与估计
相对而言,人们更倾向于在晴天和春天骑车出行。本文在天气报告和纽约花旗单车历史出行数据[8-10]中提取特征,将天气类别、星期、工作日、小时、月份和季节映射为One-Hot编码,温度、风速、湿度和降水强度的特征用数值编码表征。然后将提取出的特征组合为矩阵,特征矩阵中的列表示特征,行表示所有类型特征的组合向量。将特征矩阵和历史每小时用车需求量输入XGBoost回归模型预测未来不同时段站点集群的用车需求。
基于站点集群的每小时预测结果,通过历史时间窗口K近邻与再分配(Historical Time Window K-Nearest Neighbor and Redistribution, HTKR)算法估计站群中每个站点在预测时间组TGθ的用车需求量。选取3个高峰期时间组,即工作日早高峰TG1(6:00~9:00)、工作日晚高峰TG2(16:00~20:00)、休息日白天高峰TG3(11:00~20:00),分别计算站点不同时间组内的用车需求。首先选取前K个与TGθ最近的时间组用车需求,采用式(3)计算得到单个站点Si平均用车需求量占站群Cj的比率,再与站群在时间组TGθ内预测的需求量相乘求得站点的基本预测需求量
(3)


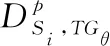
(4)

(5)
站点估计的用车需求量
(6)
当站点的估计用车需求量DSi,TGθ≠0时对该站点进行调度。
3 基于蚁群优化的流程规划算法
为了解决共享单车系统中站点单车资源失衡的问题,运营商通常用一组调度卡车将系统中的单车重新分配到站点或者增加站点空闲车桩容量。共享单车服务调度的流程规划问题如图1所示,在卡车容量限制下,站点的用车需求完全由这组卡车按照调度流程顺序满足,图中括号内的数字表示站点的用车需求,在每一次调度流程中,一辆卡车承载着初始数量的单车出发或者空车出发,经过若干站点后返回仓库。

针对小型静态调度流程规划问题,传统方法[2,5-6]采用MILP模型求解,然而对于中大型规模,如200辆卡车和3辆卡车的场景,传统方法不能在有效时间内得到最优解[11],而元启发式方法则可在有效时间内得到足够好的近似最优解。蚁群算法为一种重要的元启发算法,该算法为解决旅行商问题而提出,在此基础上提出蚁群系统,本文对蚁群算法进行优化来求解调度流程规划问题。
3.1 调度流程规划的约束模型
调度流程规划的优化目标是在给定约束模型下找到调度成本最小的流程可行解,本文将系统中需要调度的站点看作图G=(S,E),其中S={S0,S1,S2,…,Sn},S0为配送仓库,n为站点数量。2.2节对每个站点确认了用车需求量,当DSi,TGθ>0时表示站点在目标时间组内的还车需求更多,站点内的单车需要卡车拾取;当DSi,TGθ<0时表示站点在目标时间组内的借车需求更多,卡车需要将单车运送到站点。dij(i,j∈S)为站点和配送仓库的地理距离,xij(i,j∈S)为二元变量,有卡车经过站点Si和Sj时为1,否则为0。假设车队中最多有V辆最大运载容量为C的卡车参与调度。为了满足各站点用车需求的基本条件,对各站点的调度流程规划进行优化,建立如下数学模型:
(7)
s.t.
xij∈{0,1},i,j∈S;
(8)
(9)
(10)
其中:目标函数式(7)为多目标优化的加权度量,第1部分表示调度路径的成本,为路径长度乘以每公里调度单价λ,第2部分表示调度用车成本,为调度卡车数量p乘以每辆调度卡车的成本φ。式(8)表示每个站点只能被调度卡车服务一次;式(9)表示从配送仓库出发调度的卡车最多有V辆,而且所有从配送中心出发的卡车都会回到调度中心;式(10)表示一条调度路径上所有站点的需求量不会超过调度卡车的最大车载容量C。
3.2 蚁群系统优化
在共享单车服务场景下,普通蚁群算法首先将a只蚂蚁放在调度仓库S0上,并将每条路径上的信息素量初始化为相同的常数值。在每只蚂蚁的寻路过程中,根据各路径上的残余信息素浓度τij(t)和路径启发式信息ηij选择下一个没有访问且需要调度的站点。蚂蚁k在第t次迭代时从站点Si到Sj的概率
(11)
式中:α为路径(i,j)上残余信息素的重要性,β为路径上启发式信息的重要性;allowedk={C-tabuk}表示对于蚂蚁可以访问的下一个站点集合,tabuk记录蚂蚁k已经访问过的站点。当所有站点都被访问后,蚂蚁k即完成对一次站点的遍历,记录蚂蚁k这次遍历的站点便得到一个调度可行解。
启发式信息ηij用站点之间路径距离的倒数计算,即ηij=1/dij。路径上的信息素随时间消散,ρ(ρ∈(0,1))为信息素的挥发比率,1-ρ为信息素的保持比率,蚂蚁对所有站点每完成一次遍历,站点之间路径上的信息素即按式(12)进行更新。
τij(t+1)=
(12)
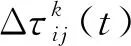
(13)
通过轮盘赌方法选择下一个站点(式(11)),然而随着问题规模的扩大,受路径上所累积信息素的影响,轮盘赌法后期选择的站点容易被局限于固定的站点范围,普通蚁群算法易陷于局部解空间,导致收敛速度变慢,本文结合蚁群系统[12]的站点转换规则对普通蚁群算法进行优化,赋予路径上的启发式信息更多重要性,并使选择站点的过程具有一定随机性,从而使蚂蚁有机会跳出局部解空间。与普通蚁群算法和蚁群系统不同,当q>q0时蚂蚁k用式(12)选择下一个待处理站点,当q≤q0时用式(13)选择下一个待处理站点,即
j=argmax{[τij(t)][ηij(t)]β}。
(14)
(15)
3.3 混沌扰动优化
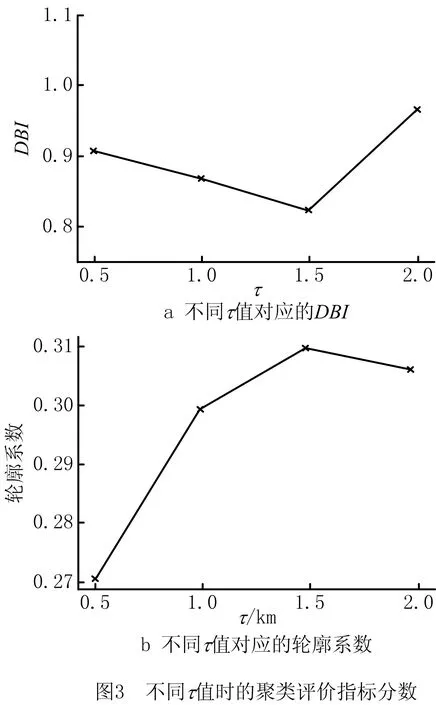
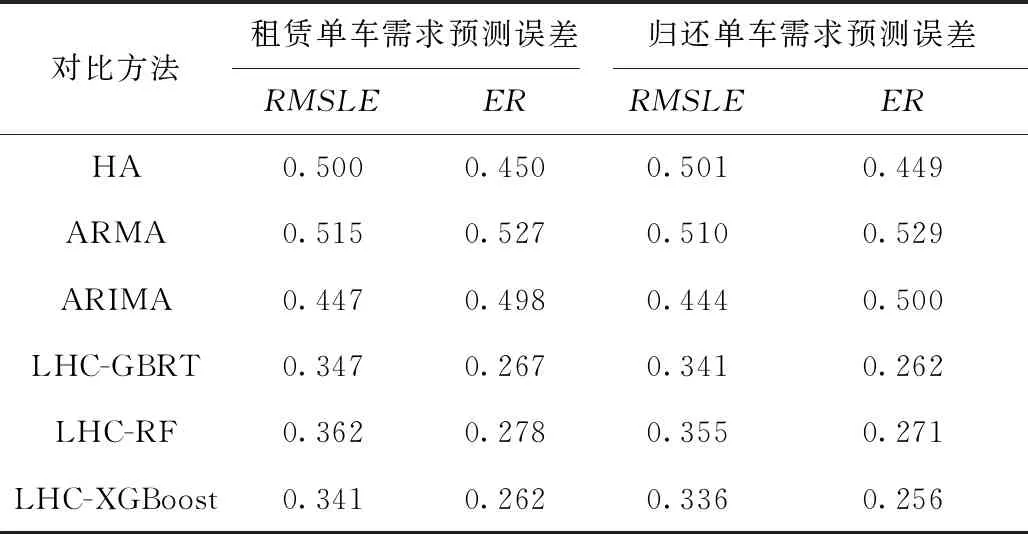
在确定性系统中发生的具有随机性的状态称为混沌状态,混沌系统拥有不同的系统特性,可以在指定范围内遍历所有状态而不发生重复[13],经典的混沌系统Logistic映射根据混沌变量z第t次迭代的值,通过公式z(t+1)=μ×z(t)×(1-z(t)),0 本文算法在后文称为HTKR-ACO,用HTKR-ACO对纽约市花旗单车2018年11月1日~2019年11月30日的历史骑行数据集[8]、花旗单车系统站点状态数据集[14]和气象数据集[9]进行处理,历史骑行数据集中共有706个站点和2 375万条骑行记录,站点状态数据集包括共享单车服务中站点的运行状态、可用车桩、可用单车、站点用量记录,气象数据集包括纽约市每小时的气象报告数据。 为了评估不同方法对集群站点用车需求量预测结果的表现及其有效性,采用均方根对数误差RMLSE和误差率ER作为评价指标,RMLSE和ER被广泛用于评价共享单车服务问题[2,15]: RMLSE= (16) 4.2.1 参数k的敏感度分析 在构建稀疏的邻接图时,KNN方法中的k值表示为站点筛选出的相邻站点的数量。若k值太小,则选取连接的站点少,在周围寻找相似站点不充分;若k值太大,则构建的邻接图过大,后续需将邻接图切分为小簇,但会增加计算量。本文分析k值在6~14区间时的聚类效果,聚类评估指标选用轮廓系数分数和戴维森堡丁指数DBI。 轮廓系数用于评估集群的内聚度和分离度,取值范围为[-1,1],一个较大的轮廓系数分数表示聚类能够更好地与其他集群分离,且在集群内部有更高的内聚性[16]。定义DBI为集群内部离散度与集群之间分离度的比率,DBI分数越低,集群的边界越清晰[16]。图2所示为不同k值下两个评价指标的得分情况。 图2中,k=6时轮廓系数分数较低,原因是邻接图构造中的相邻站点规模太小,而且这些较小的相邻站点无法成功挖掘站点之间自行车需求的相关性;k=12,14时轮廓系数分数也较低,可以推断,较大的k会增加邻接图中的相邻站点,进一步增大邻接图的复杂性,从而影响子簇划分的有效性;当k=8,10时,可以获得较高的轮廓系数得分,即集群结果较好。同时,因为单个站点中的单车使用需求经常变化,而且同一个集群中的其他站点可以为目标站点用车需求预测的准确性提供有价值的信息,所以本文设k=10。 4.2.2 距离阈值τ的敏感度分析 在边权重计算式(1)中,右边第2部分表示站点间距离的权重,站点间距离超过距离阈值τ时会被惩罚。聚类指标DBI评估了τ在0.5 km~2 km取不同值时的聚类表现,图3所示分别为不同τ值下的DBI和轮廓系数,当τ=1.5 km时,DBI取得最小值且轮廓系数达到最大,因此本文设邻域距离阈值τ=1.5 km。 (1)对比方法 本文预测了站点集群的用车需求量,并设计实验与多个常用或经典的基准预测方法进行比较来验证预测准确度:①HA,为历史均值方法,其通过每个历史时间段租赁和归还的单车需求量的平均数来预测当前的租车和还车需求[16-17];②自回归滑动平均模型(Auto-Regressive and Moving Average model, ARMA),该模型将租赁和归还单车需求量看作为时间序列,预测该时间段内未来的需求;③自回归积分滑动平均模型(Auto-Regressive Integrated Moving Average model, ARIMA),该模型适用于处理不稳定数据[18];④梯度提升回归树(Gradient Boosted Regression Tree, GBRT),该模型采用输入样本值中代价函数的负梯度作为残差的近似值来拟合回归树,以预测未来时期的租赁和归还单车需求量;⑤随机森林(Random Forest, RF),该模型由多个随机树组成,随机树输出的平均值用作单车需求的预测值。 (2)预测结果对比 基于上述站点集群聚类结果,对比不同预测方法的用车需求预测误差,包括HA、ARMA、ARIMA、基于位置敏感的层次聚类的梯度提升回归树(Location-aware Hierarchical Clustering-Gradient Boosted Regression Tree, LHC-GBRT)、基于位置敏感的层次聚类的随机森林(Location-aware Hierarchical Clustering-Random Forest, LHC-RF)、基于位置敏感的层次聚类的极端梯度提升方法 (Location-aware Hierarchical Clustering-eXtreme Gradient Boosting, LHC-XGBoost)。实验对基于机器学习的方法使用相同的样本特征,包括XGBoost,GBRT,RF,并利用网格搜索选择最优的参数组合。表1所示为数据集需求量预测的所有时刻的平均RMSLE和ER,其中LHC-XGBoost产生的预测精度最佳,因此本文采用LHC-XGBoost预测得到的站点用车需求来预测结果。 表1 不同预测方法的用车需求预测误差对比 为评估HTKR-ACO寻找最小调度成本的流程规划的有效性,与以下方法进行对比:①普通蚁群算法ACA;②适应参数的蚁群算法(Adapt-AS)[19],修改AS的信息素更新公式,每次迭代参与更新的信息素挥发率ρ正比于信息素浓度τij(t);③基于蚁群系统站点转换规则的蚁群算法(Station Transfer Regulation-Ant System, STR-AS),利用蚁群系统(Ant Colony System, ACS)算法的站点转换规则对ACA进行修改;④ACS算法[12]。 4.4.1 调度流程规划结果对比 根据LHC-XGBoost得到的站点集群预测结果,观察早晚高峰期站点集群的用车需求量,如图4所示。图中(0~800)表示还车数量大于借车数量,(-800~0)表示借车数量大于还车数量。图4a和图4b中同一个站点的红蓝两色对比显示早晚高峰期用车需求的差异性和对称性,例如早高峰借车需求高的站群在晚高峰还车需求高。为验证本文所提流程规划算法的性能,取图中实线圆圈圈住的早晚高峰用车需求差异大、用车需求旺盛的6个站点集群共143个站点进行调度流程规划,其他站点的流程规划与其类似。 实验为所有方法设置相同的参数,由4.2节可知参数取值会直接影响蚁群算法的收敛效果和速度,参照文献[12-13],本文在数据集上对不同参数取值进行了预实验,最终选取参数α=2,β=5,Q=10,q0=0.9,a=100,ρ=0.4;同时,为了对比最小成本调度的流程规划结果,本文将式(7)的目标参数设为λ=1和φ=0,卡车调度容量C=100,通过规划得到调度流程的路径长度来直观地比较算法性能。为提高实验结果的可靠性,将每个方法运行30遍,每一遍运行迭代150次,对所得结果求平均值。 每次迭代的平均路径长度和每遍运行的最短调度路径长度对比如图5所示,Adapt-AS曲线表示动态调整ρ值和Q值虽然使算法没有过早收敛到局部最优解,但是相比AS曲线表示的AS平均最优解,并未表现出优越性;STR-AS曲线表示STR-AS结合了ACS的站点转换规则;HTKR-ACO曲线表示HTKR-ACO基于STR-AS算法,但加入了混沌扰动;ACS曲线表示ACS算法收敛速度最慢,150次迭代仍不能收敛,其在前30次迭代优化处于停滞状态,可能由于更新信息素时以1为分子,而将实例中的路径长度作为分母数值太大,导致迭代时路径上的信息素累积缓慢,信息素正反馈效果不好。 由图5b可见,HTKR-ACO每次运行找到的路径较短且寻优表现更稳定。结合图5a可知,HTKR-ACO在所有方法中求解得到的平均路径最短,收敛速度较快,能为系统有效规划出较短的调度路径。不同对比方法规划的调度流程路径长度如表2所示。 表2 不同方法规划的调度流程路径长度 实验预设站点中编号最小的站点为配送仓库,运行HTKR-ACO取得两个调度流程可行解的实例如图6所示,图中圆点和线段分别表示站点和流程路径,圆点表示配送仓库,实例中的共享单车服务调度共规划出2个流程,需要2辆卡车完成调度流程。站点上方括号中的数字表示站点在调度流程阶段的需求量,可见HTKR-ACO可以规划出满足站点需求且合理的调度流程。 4.4.2 调度流程的需求满足验证 在调度流程中要尽可能满足各个站点的用车需求,因此将HTKR与历史时间窗口K近邻(Historical Time windowKnearest neighbor, HTK)方法进行对比,并通过需求满足率DSR来评估调度时满足站点集群用车需求的比例。在2019年8月5日~2019年8月12日连续一周的真实数据集上设计实验,图7所示分别为其中4天经过HTKR和HTK分配后未满足的需求量,以及预测站点集群总使用需求量的对比情况。 可见,每一天HTKR-ACO分配后未满足的需求量均比HTK更少,说明利用站点集群内空余的车桩和单车可以有效减少站群中未满足的用车需求。本文分别计算单车需求及车桩需求的DSR并取两者均值得到7天内不同时间组的DSR,如表3所示,可见HTKR的平均DSR在7天中均高于88%,证明通过HTKR分配后可以极大地满足预测站点集群的用车需求。 表3 HTKR和HTK分配后的DSR对比 为解决共享单车服务调度流程的优化问题,本文分别从调度需求估计和流程规划两方面考虑,首先为共享单车服务站点划分站点集群,预测站点集群用车需求并估计各站点的用车需求,然后建立调度流程优化目标的问题模型,提出一个蚁群优化的调度流程规划算法,通过蚁群系统更强的信息素正向反馈机制、启发式信息更快的局部搜索能力和混沌理论较强的全局搜索能力,改善了蚁群算法易陷入局部解空间和蚁群系统收敛速度过慢的问题,从而快速收敛到全局近似最优解。实验验证,所提算法在用车需求分配和调度流程规划上均能取得较好表现,可以有效指导共享单车服务调度流程规划,提高共享单车服务的可行性。4 实验验证与分析
4.1 评价指标
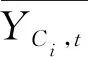
4.2 聚类参数敏感度分析

4.3 需求量预测验证
4.4 调度流程规划验证






5 结束语
