iBelt:一种事件日志的可解释聚类分析方法
2022-11-07王桂玲
刘 雯,王桂玲+
(1.北方工业大学 信息学院,北京 100144;2.北方工业大学 大规模流数据集成与分析技术北京市重点实验室,北京 100144)
0 引言
面对复杂的数据世界,针对过程感知的信息系统(Process-Aware Information Systems, PAIS)的过程挖掘算法在处理复杂事件日志时可能会生成难以理解的“意大利面过程”模型[1],难以从中获得有价值的信息。因此,在进行过程发现时,不会试图将所有案例(case)建立为一个庞大复杂的模型,而是通过抽取特征的方式描述案例,然后对案例的轨迹进行聚类[1],使每个聚类结果对应于相关过程执行的连贯集合,每个相关过程的执行情况可以用过程模型表示。
目前,相关研究已经提出几种面向事件日志的轨迹聚类技术[2-4],然而轨迹聚类技术的应用潜力因其可解释性(interpretability)较差而受到很大影响。目前的轨迹聚类技术大都依赖“案例轨迹之间的距离”,采用轨迹距离解释聚类结果时很不直观,经常不被PAIS业务用户认可。PAIS的业务用户更倾向于从领域相关的角度(如控制流的属性、特点)理解轨迹聚类结果[5],而轨迹之间的距离度量对其而言没有明确的领域相关的含义,因此需要一种聚类结果可被业务用户直观理解的日志聚类分析方法。在人工智能和机器学习领域,很多学者关注可解释的机器学习方法的研究,对可解释性则有不同的定义[6-8],一般认为机器学习的可解释性是人类理解决策原因的程度,或是人类可以持续预测模型结果的程度。对于PAIS的事件日志聚类而言,亟需一种可解释的聚类分析方法:其聚类结果基于领域相关的概念、属性、特点、规则等表示,从而可被业务用户直观理解。
针对上述问题,本文定义“过程连接带”来描述对轨迹进行可解释聚类分析的输出结果,并借鉴机器学习中可解释聚类的相关思路,提出一种事件日志的可解释聚类分析方法iBelt(interpretable process belt)。该方法从活动视角和控制流视角提取事件日志的特征构建特征向量,其核心是CLBDT(clustering through boosting decision tree)模型,同时针对从事件日志中提取的活动及控制流相关特征往往存在高维数据的情况,提出基于方差和判别特征选择的无监督特征选择方法来降低聚类结果解释的难度;CLBDT模型利用决策树聚类(又称聚类树)(CLustering through decision Tree, CLTree)方法[9]和提升树(boosting tree)的思想,基于信息增益动态更新构建聚类树,从而获得聚类后簇的矩形区域(由聚类树叶子节点取值组成),使聚类结果能够通过案例活动和控制流属性值组合的方式直观地展示。
为验证方法的有效性,本文使用公开数据集定量分析事件日志聚类后形成的不同过程连接带,得到的过程连接带拥有简洁易懂的可解释规则。通过Alpha算法对聚类后生成的子日志进行过程挖掘,并在拟合度和简洁度两个质量维度上与聚类前的事件日志进行对比,实验表明相比聚类前的事件日志,聚类后的子日志在两个质量维度上得到明显优化。
1 相关概念
定义1事件、属性[1]。设ε为事件空间,即所有可能事件标识符的结合;AN为属性名的集合。对于任意事件e∈ε和属性名n∈AN,#n(e)是事件e的属性n值。如果事件e不含属性名n,则#n(e)=⊥(空值)。
事件由不同属性描述,典型的属性有活动、时间戳和资源,示例事件的片段如表1所示。

表1 某事件日志片段
定义2案例、轨迹、事件日志[1]。设£为案例空间,即所有可能案例标识符的集合。案例也有属性。对于任意案例c∈£和名称n∈AN,#n(c)是案例c的属性n的值(如果案例c没有属性n,则#n(c)=⊥)。每一个案例(case)都有一个特殊的强制属性——轨迹(trace)。
(1)轨迹是事件σ∈ε*的一个有限序列,其中每个事件只出现一次。
(2)事件日志是案例L⊆£的集合,其中每个事件在整个日志中最多出现一次。
定义3轨迹聚类[10]。设L⊆£为一个事件日志,在L上的一个轨迹聚类是L的一个子日志。一个轨迹聚类T£⊆P(L)是事件日志L上的一组轨迹。
定义4事件日志视角[1-2]。视角是从特定角度描述轨迹的相关项,其用具体数值度量案例中的轨迹,对事件日志进行分析后可用多个视角构成一个聚合向量来描述轨迹行为。
(1)控制流视角 描述活动发生顺序,例如(A,B)表示在事件日志的轨迹中,活动A发生以后紧接着发生活动B,称为直接跟随关系,可以统计轨迹活动之间的直接跟随关系是否发生或者发生的次数。
(2)组织视角 展现资源的组织情况,可以统计事件组织资源者参与的次数或资源者是否参与。
(3)活动视角 关注活动的发生频率,可以统计事件活动发生的次数或活动是否存在。
(4)时间视角 又称性能视角,其关注事件的时间和频率,统计同一个案例中事件发生的次数、案例的持续时间,以及案例中相邻事件持续时间的一些统计量,如最值、均值和众数等。
决策者根据组织数据能够深入了解典型的工作模式和组织结构,利用活动数据能够更好地进行科学决策并分析不同轨迹间的差异,时间戳可以诊断与性能相关的问题,如瓶颈问题。
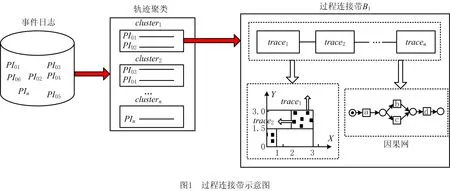
定义5过程连接带。L⊆£为一个事件日志,过程连接带B是一个三元组B=T,I,C,过程连接带中的过程实例可用基于轨迹特征属性的规则直观解释。
(1)T为过程连接带对应的轨迹集合。假设事件日志L聚类后为两个簇,对应两个过程连接带的轨迹集合T1(trace1,trace2,trace3)和T2(trace4,trace5)。
(2)I为对过程连接带的定量描述。对于某过程连接带对应的轨迹集合,假设其特征组合为[X,Y],其特征值经过可解释聚类算法形成的定量矩形区域为{X⊆[x1,x2],Y⊆[y1,y2]},x1和y1是特征值的最小值,x2和y2是特征值的最大值。
(3)C为不同过程连接带经过过程挖掘得到的不同的因果网(C-net)[1]。
过程挖掘的评估主要有拟合度、精确度、泛化度和简洁度4个质量标准(详见5.2节),四者彼此竞争,很难达到平衡。一个拟合度好的模型允许事件日志反映行为发生的过程;精确度避免欠拟合,泛化度则避免过拟合;简洁度意味着得到的模型越简单越好。BUIJS等[11]认为现有的过程发现算法通常最多考虑4个主要质量维度中的两个。拟合度目前是评价过程模型质量最重要的指标,可以在保证提高拟合度、精确度和泛化度的情况下考虑简洁度。
2 相关工作
复杂的事件日志可以通过案例轨迹进行聚类达到简化的目的,而本文希望得到的是具有可解释性规则的事件日志过程连接带。然而,目前常用的轨迹聚类算法得到的结果通常缺乏可解释性或可解释性弱,传统轨迹聚类算法的主要思路有两种:①将事件日志转换到向量空间,执行基于距离的聚类算法;②基于模型的序列进行聚类,基于过程模型识别出相似序列的组。方法①,如文献[2,4]提出的技术,将事件日志中的轨迹转换到向量空间中,其特征由活动、控制流中的直接跟随关系、时间戳等组成,然后应用数据挖掘领域常用的距离聚类算法(如K-means算法)在向量空间中应用不同的距离度量(如欧式距离)进行聚类,然而基于距离的聚类算法方法无法定量描述事件日志的具体视角,缺乏可解释性;方法②,如文献[3]提出的技术,以Markov模型为基准进行轨迹聚类,在该序列聚类中,每个聚类簇都与一个马尔科夫链相关联,但是基于模型的序列聚类算法无法定量描述轨迹序列中实例的取值情况,可解释性较弱。
对于如何对过程实例进行解释说明,WEERDT等[5]提出的聚类过程实例解释搜索(Searching for Explanations for Clustered Process Instances, SECPI)算法能够为过程实例找到最小控制流特征集,从控制流角度提供解释能力,为数据添加集群标签后再应用有监督的支持向量机(Support Vector Machine, SVM)分类器得到解释规则。Case2vec基于Word2vec词嵌入方法对过程实例从活动和案例属性视角进行向量表示,在此基础上进行聚类分析[12]。然而Case2vec对属性的选择很敏感,如果没有先验知识很难找到好的属性,而且在真实的事件日志中,活动属性可能会存在没有实际含义的情况,从而使词嵌入方法得到的聚类结果不能被业务用户直观理解。
复杂事件日志提取特征向量时很容易因维数过高而造成“维数灾难”,而且会使可解释性算法生成复杂的解释规则而降低用户的可读性。针对决策树的降维问题,倪春鹏[13]通过比较条件属性相对于划分类别的重要性来决定保留哪些属性参与建立决策树,其改进的决策树降维方法是有监督的特征选择方法,而真实的事件日志往往无法准确得到条件属性;王伟[14]将原始数据空间转换到主成分空间,利用主成分分析算法的思想改进了传统决策树的C4.5算法,但是破坏了特征数据本身的可解释性。无监督的特征选择方法能够在很大程度上保留特征数据本身的可解释性,其中无监督的最大方差选择方法[15]以特征数据的最大方差为评价标准,按照其特征重要性排序进行选择;无监督的拉普拉斯特征选择方法[16]在最大方差的基础上引入数据的局部结构进行分析。然而,这两种方法仅考虑数据本身的区分度,忽略了特征之间的相关性。考虑特征间的相关性问题,无监督判别特征选择法(Unsupervised Discriminant Feature Selection, UDFS)[17]采用局部类间散度最大化与类内散度最小化的策略获取最优特征子集,非负谱分析无监督特征选择法(Non-negative Discriminative Feature Selection, NDFS)[18]引入非负约束来获得更准确的结果,多聚类特征选择法(Multi-Cluster Feature Selection, MCFS)[19]通过谱分析捕获局部流形结构。
3 iBelt方法
3.1 基本思想
本文用过程连接带定义对过程事件日志进行可解释聚类分析的结果。如图1所示,事件日志由过程实例(PI01,PI02,…,PIn)构成,经过具有可解释性的轨迹聚类算法后产生聚类簇(cluster1,cluster2,…,clustern),聚类簇中各自包含多组不同的过程实例,形成具有可解释规则的过程连接带(B1,B2,…,Bn)。如图1所示,基于定义5,对于轨迹聚类后的cluster1,其过程连接带可表示为B1=T1,I1,C1,其中,对于轨迹组合T1(trace1,trace2,…,tracen),当特征组合为X和Y时,可将其映射到二维空间,轨迹即可表示为二维空间中的点。T1中的点便构成矩形区域I1,可将I1定量描述为{X⊆[2,3],Y⊆[1.5,3]},对T1进行过程挖掘后得到的因果网为C1。
得到过程连接带可解释性规则最关键的一步在于建立可解释聚类模型。目前,典型的聚类算法往往基于距离算法或密度算法对数据点进行分簇,这样得到的簇边界往往是不规则的,而且聚类结果缺乏可解释性。因此,考虑决策树算法规则简单、结果具有可读性的特点,借鉴可解释聚类算法CLTree思想构建CLBDT模型,得到具有可解释性的聚类结果,满足定量描述过程连接带的需求。
CLTree的基本思想是在目标数据Y中均匀地添加一类虚拟数据N,再用决策树对目标数据和虚拟数据进行二分类,将虚拟数据从分类结果移除,剩下的不同特征属性范围的目标数据就成为聚类结果[9]。这种方法之所以有效,是因为如果目标数据中存在聚类,则Y点不可能均匀分布于整个空间。若在该空间中添加均匀分布的虚拟数据点N后,再采用决策树二分类方法对Y点和N点进行分类,则可使在目标数据Y聚集区域内的Y点比N点多,属于Y点聚集区域,而在其他区域N点比Y点多,属于N点聚集的区域。CLTree使用的单棵决策树在聚类时容易受噪声影响而做出错误的决策[20],提升树(boosting tree)[21]是以决策树作为基学习器,通过串行迭代得到强学习器的算法,每一次迭代均以损失函数最小为优化目标学习基函数。相对于提升树,梯度提升决策树(Gradient Boosting Decision Tree, GBDT)是一类结合提升树[21]和梯度提升思想[22]来提高预测准确性的算法,如果能够借鉴GBDT的优点,则可能进一步提升CLTree可解释聚类算法的聚类准确性。
如果基于CLTree思想将原始数据作为Y类,预先生成均匀的虚拟数据作为N类,采用GBDT思想对数据进行二分类,再将叶子节点作为聚类簇,则难以得到预想的结果。通过实验也发现,该方法聚类子日志的拟合度质量低于未聚类前,且远低于CLTree方法,这是因为预先生成所有的N类数据并不能将原始数据很好地分簇,而是需要在决策树每次分支时动态生成虚拟的N类数据点,以保障添加足够的N类数据点来隔离聚类[9]。然而,如果在梯度提升决策树算法中动态生成N类数据,则又将破坏梯度计算的意义。通过观察CLTree建立决策树的过程发现,在当前决策树中,同一聚类中的点比不同聚类中的点有更高的概率在下一个决策树中仍然属于同一个聚类,也就是说,如果前一棵决策树在分支时将同一个聚类中的数据点分到了不同分支节点上,则可以利用提升树思想,通过下调信息增益提升建立下一棵决策树的准确性[23]。因此,一方面,在生成N类数据时沿用CLTree动态增加虚拟数据的方法,当节点中N点数少于Y点时,将N点增加到与Y点相同的数量;另一方面,在建立聚类树时,通过动态更新信息增益使同一个簇中的点在建立下一棵聚类树的过程中更倾向于被划分到一起,从而提高聚类结果的准确性。
当从事件日志中提取的相关特征维度较高时,CLBDT模型的决策树结构将过于复杂,从而增加聚类结果可解释规则的复杂性,降低计算效率,因此本文在提取模型特征后通过降维来解决该问题。然而,典型的降维方法是将原始高维特征空间转化到低维特征空间,投影矩阵为稠密矩阵,从而将提取的所有特征混合生成新的特征,这样的降维方法会丢失原始特征本身的特点和可解释性,与本文研究目的相悖。因此,为了更好地增强子空间学习的可解释性,考虑特征选择的过滤式和嵌入式方法,提出方差结合判别特征选择[17]的无监督特征选择算法,既能兼顾方差选择出表现能力强的特征,又能利用离散矩阵和特征相关性选择具有判别性的特征。
3.2 方法流程
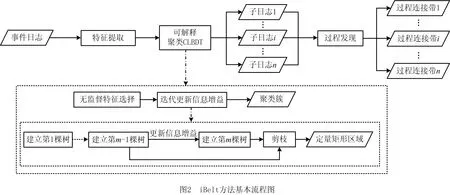
按照3.1节所述的算法基本思想,本文首先对事件日志进行特征提取,将提取后的特征作为可解释聚类模型CLBDT的输入数据,其中通过基于无监督特征选择方法对输入数据进行降维,模型将输出不同聚类簇的可解释规则,用于支持对过程连接带进行定量描述;然后对聚类后的子日志进行过程发现,得到对应的过程连接带。iBelt方法的基本流程如图2所示。
3.3 特征提取
在进行事件日志可解释性轨迹聚类之前,需要对数据进行特征提取,而为了使用户能更直观地理解聚类结果,提取的特征需要能够体现领域相关的概念、属性、特点或规则。其中,领域相关的概念和特点可以通过多个过程实例聚类间具有区别性的特征来体现,这主要依赖于过程的控制流特征[5],同时领域相关的属性以及后续的过程发现主要通过从活动视角提取的特征体现。因此,分别提取活动视角和控制流视角的特征进行CLTree聚类,通过实验结果可以发现,当基于活动视角提取活动出现的频数时,聚类后的轮廓系数更优;当基于控制流视角提取“直接跟随关系是否存在”的特征时,聚类后的轮廓系数更优。
事件日志通过特征提取后的特征向量如表2和表3所示。表2是2013年BPI挑战赛的OProblem数据集(https://doi.org/10.4121/uuid:3537c19d-6c64-4b1d-815d-915ab0e479da)提取特征后构建的特征向量,表3是2020年BPI挑战赛的DomesticDeclarations数据集(https://doi.org/10.4121/uuid:52fb97d4-4588-43c9-9d04-3604d4613b51)提取特征后构建的特征向量。其中,OProblem数据集特征向量为9维,DomesticDeclarations数据集特征向量为56维。

表2 OProblem数据集的特征向量

表3 高维数据集DomesticDeclarations的特征向量
3.4 CLBDT模型
3.4.1 无监督特征选择
实验证明,特征维度过高时不仅会消耗大量时间,还会产生大量噪声点。例如,事件日志InternationalDeclarations聚类后仅有20.20%的点在簇中,事件日志PrepaidTravelCost聚类后仅有39.02%的点在簇中。因此,模型首先要降维,为了不破坏特征本身的可解释性和后续聚类结果的可解释性,本文采用无监督特征选择方法,主要考虑特征本身是否发散以及特征之间的相关性。
方差选择算法考虑特征数据本身的区分程度,简单易行,但忽视了数据间的相关性,而不论控制流视角还是活动视角,不同视角的特征间必然存在一定相关性。当数据集控制流视角的特征矩阵偏向稀疏且零向量过多时,控制流视角特征本身的区分度下降,方差选择算法会偏向于选择活动视角的特征,为了使输入的特征向量能够均衡两个视角的特征解释性,采用UDFS方法计算特征间的相关性,增加控制流视角判别的重要性。最后,将方差选择算法和无监督判别选择算法结合,既能通过方差选择保留本身具有较大区分度的特征,又能通过UDFS算法同时考虑特征间的相关性,选择出具有判别性的特征。
算法1无监督特征选择算法。
输入:事件日志特征提取后的原始特征集F={f1,f2,…,fm}。
输出:特征选择后的事件日志特征集Fs。
1)方差选择计算特征重要性I1;
2)根据I1排序,得到拐点的前t个特征集F1={f1,f2,…,ft};
3)UDFS方法计算判别重要性I2;
3)根据I2排序,得到拐点的前k个特征集F2={f1,f2,…,fk};
4)最终特征集Fs=F1∪F2。
3.4.2 通过更新信息增益建立多棵聚类树
根据3.1节的分析,在当前决策树中,同一聚类中的点比不同聚类中的点有更高的概率在下一个决策树中仍然属于同一个聚类,由此指导决策树的构建,通过更新信息增益使得同一个簇中的点更倾向于被划分到一起,从而提高聚类结果的准确性。采用无监督思想建立决策树时,首先将事件日志特征数据集中的真实数据作为类别为Y的点,然后假设数据空间中均匀分布着类别为N的虚拟数据点,将原始点聚类问题转变为对真实点Y和虚拟点N进行分类,即将聚类问题转换为在空间中把数据点划分到密集区域还是空白区域的问题。决策树用划分前后信息熵的差值(即信息增益)衡量用当前特征对样本集合D划分效果的优劣,信息增益越大,特征属性对样本集合D进行划分所获得的纯度越高。
假设一个原始数据集有q类,即C1,…,Cq,将原始数据集D信息熵定义为
(1)
式中:freq(Cj,D)为类Cj在D的数据点数;|D|为D中的数据记录总数。
对于样本集合D而言,其样本属性A有m个不同的属性值,可根据属性A将D划分为m个子集{A1,A2,…,Am},根据属性A划分样本后的信息熵为
(2)
式中|Di|为分区后子集Di中的数据点数。
最后,属性A对样本集合D分区所得的信息增益为
gain(D,A)=info(D)-infoA(D)。
(3)
CLBDT模型基于提升树的思想,在建立多棵决策树时更新信息增益,即通过计算决策树,在分支时将当前在同一个聚类中、但分到了下一棵决策树不同分支节点上的数据点信息增益作为调整项,调整项的计算公式为
(4)

更新后的新信息增益
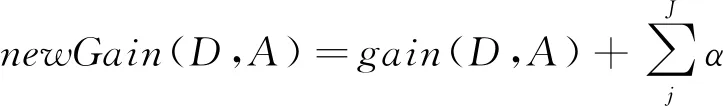
(5)
式中α为学习率,用于控制每棵树对前一棵树信息增益的纠正强度。
算法2CLBDT建立多棵聚类树算法。
输入:事件日志特征选择后的特征集F={f1,f2,…,fk}。
输出:聚类簇C={C1,C2,…,Cn}。
1) 对每个属性遍历特征值,由信息增益标准gain分裂节点得到第1棵聚类树;
2) Repeat:
3) get_GainRes(gainRes)
4) buildTree(Tree) :
5) calculate_Gain(newGain)
6) Until第M棵树与前一次的迭代结果基本不变
7) 返回第M棵树
3.4.3 寻找聚类树的最佳分割点
本节分析提取的活动视角和控制流视角特征。显然,活动视角的特征为数值型数据,是一些活动出现的频数,而基于控制流视角提取的特征是“直接跟随关系是否存在”,特征的取值只有0和1,属于类别型数据。传统决策树的信息增益标准不会考虑之前计算的信息增益结果,而CLBDT中的聚类树则会在每个维度上通过信息增益标准找到一个最佳分割,而且通过比较聚类簇的相对密度(r=rY/rN,rY和rN分别为区域中Y点和N点的数量),能够向前寻找(最多两步)切割较少的聚类簇区域,从而找到最佳分割点,将其称为前瞻策略。数值型数据在寻找最佳分割点时要考虑数据点是否稠密,即点和点之间的距离尽可能小,因此需要采用前瞻策略寻找最佳分割点;对于类别型数据,不同取值不存在距离关系[24],控制流视角中的直接跟随关系只有0和1两种取值,根据过程连接带的需求,存在相同流动关系的轨迹应被划分到一个簇中,因此只需分别计算这两种取值分裂时左右子树的信息增益,信息增益最大的即为最佳分割点。
3.5 模型时间复杂度分析
方差选择算法的时间复杂度为O(n),无监督判别特征选择算法的时间复杂度为O(d3+n2c),无监督特征选择算法由这两种算法组成,时间复杂度为O(d3+n2c+n),其中n为样本数,d为特征数,c为聚类中的类数。
数值型特征分裂时采用{取值≤value}和{取值>value}的二分裂方式,决策树分裂一个节点的时间复杂度为O(dnlgn),构建整颗决策树的时间复杂度为O(dn2lgn)。对CLTree时间复杂度影响最大的为其前瞻策略,因为当数据类型为数值型时,前瞻策略最多可能会为一个特征寻找3个切分点,使得分裂一个节点的时间复杂度为O(dnlgn)+O(dn3),其时间复杂度为O(dn4),而当数据为类别型数据时,不需要寻找3个切分点,其时间复杂度为O(dn2)。根据3.4.3节的分析,本文的活动视角为数据型,控制流视角特征为类别型,因此将特征数d分为数值型特征dnum个和类别型特征dcat个,则建立一个聚类树的总时间复杂度为O(dnumn4+dcatn2),CLBDT对迭代的m棵决策树的总时间复杂度为O(mdnumn4+mdcatn2)。再进行特征选择以后,特征数量变为k,时间复杂度则变为O(mknumn4+mkcatn2)。
传统的聚类方法K-means的时间复杂度为O(nkdt),其中k为所选择的聚类中心,t为迭代次数。
4 实验
4.1 实验数据
本文用6个事件日志展示过程活动,验证模型的过程发现质量。OProblem(https://doi.org/10.4121/uuid:3537c19d-6c64-4b1d-815d-915ab0e479d
a,819个轨迹,2 351个事件)和事件日志Incidents(https://doi.org/10.4121/uuid:500573e6-accc-4b0c-9576-aa5468b10cee,7 554个轨迹,65 533个事件)是沃尔沃比利时信息技术公司(Volvo IT Belgium)的真实事件日志,来自VINST的事件和问题管理系统,这两个事件日志来自2013年BPI挑战赛。另外4个事件日志来自2020年的BPI挑战赛(https://doi.org/10.4121/uuid:52fb97d4-4588-43c9-9d04-3604d4613b51),是埃因霍芬理工大学报销过程中的真实事件日志。其中,事件日志DomesticDeclarations(10 500个轨迹,56 437个事件)主要记录国内旅行的声明要求,事件日志InternationalDeclarations(6 449个轨迹,72 151个事件)主要记录国际旅行声明要求,事件日志PrepaidTravelCost(2 099个轨迹,18 246个事件)主要记录预付旅行费,事件日志RequestForPayment(6 886个轨迹,36 796个事件)主要记录付款请求。
4.2 评价指标
无监督特征选择的CLBDT模型用轮廓系数(Silhouette Coefficient, SC)、程序执行时间和最终在簇中的数据点占比评估事件日志的案例轨迹聚类后的效果,预先将案例属性作为类标签的Case2vec方法[12]用归一化互信息(Normalized Mutual Information, NMI)作为评价指标,具体说明如下:
(1)SC指标根据簇内所有点之间的距离计算簇内紧密度,根据不同簇样本点之间的最近距离计算簇间分离度,其值的取值范围为[-1,1],越接近1,聚类效果越好。
(2)NMI指标度量算法结果与标准结果之间的相似度,结果越相似,NMI值越接近1;如果算法结果很差,则NMI值接近0。
(3)程序执行时间指进行聚类的整个时间,单位为s。
(4)簇中的数据点占比指聚类后簇中的数据点总数比原始数据点总数。
将聚类以后形成的簇对应的案例生成子日志,分别用Alpha挖掘算法进行过程发现,其中质量评估标准拟合度和简洁度定义如下:
(1)拟合度指标fitness用于评价挖掘得到的过程模型能够重现事件日志的能力[1]。能被模型重现的轨迹越多,该模型的拟合度值就越高。拟合度目前是评价过程模型质量最重要的指标,定义为
(6)
式中:m为缺失的token;q为消耗的token;p为产生的token;r为遗留的token。拟合度的取值范围为[0,1],值越大,拟合度越好。
(2)简洁度指标考虑奥卡姆剃须刀原则,根据该原则,最好的模型不仅是能解释事件日志中所见行为的执行过程,而且是最简单的模型。首先考虑Petri网的转换平均度meanDegree,将其定义为输入弧和输出弧的数量之和。在0~∞之间选择一个数字h,然后将基于反弧度的简洁度定义为
(7)
简洁度的取值范围为[0,1],值越大,结构越简洁。
4.3 实验过程
4.3.1 特征提取结果
对6个事件日志进行活动和控制流视角转换关系的特征提取,先采用方差特征选择算法选择出区分度大的特征,因为当控制流视角矩阵过于稀疏时,结果会偏向活动视角的特征,所以进行UDFS选择,为控制流视角的特征增加判别重要性。特征提取后的降维结果如表4所示。

表4 事件日志特征提取情况
4.3.2 方法结果分析
相比传统的聚类方法K-means,CLBDT模型的聚类结果具有可解释性,其能够清晰地了解如何决策得到每个簇,而且满足过程连接带的需求。因为K-means算法本身属于黑盒模型,即不提供直接的、可由人类解释的决策规则,所以在选择降维方法时,不用考虑其是否破坏特征本身的可解释性,因此选用最传统的主成分分析(Principal Component Analysis, PCA)降维方法与之搭配。聚类最终的K值由最优轮廓系数决定,如表5所示。

表5 K-means算法结果对比
将CLBDT模型与文献[12]中的Case2vec方法对比,Case2vec方法能够根据轨迹和事件的语义信息进行聚类,其需要预先决定用案例的某个属性作为类标签,其NMI值受类标签的影响很大,而在真实的数据集中很难找到合适的案例属性作为类标签,因此,该方法在真实数据集的应用中具有局限性。如表6所示,在InternationalDeclarations数据集中使用不同的类标签,得到的NMI值相差较大。数据集OProblem和Incidents的事件日志轨迹中只有一个案例属性concept:name,表示案例编号具有唯一性,并没有其他额外的案例属性可以作为类标签,因此无法采用Case2vec方法。对于2020年BPI挑战赛的4个数据集,首先需要分别通过具体数据集的实际情况设置类标签,然后选择其他属性,如案例的concep:name、事件的concep:name等构成特征向量,最后对比聚类后的NMI效果、程序执行时间等评价指标,对比结果如表6所示。

表6 Case2vec聚类结果对比
4.4 iBelt方法结果分析
4.4.1 可解释聚类结果分析
本节以数据集DomesticDeclarations进行CLBDT聚类后簇的情况为例分析数据集DomesticDeclarations聚类后簇所对应的过程连接带。分析数据集DomesticDeclarations所提取的特征矩阵,一共56维,分为数值型和类别型两类数据,如表3所示。通过无监督特征选择方法从原本的56个特征中保留9个区分度大且具有判别性的特征(如表7),通过可解释聚类方法生成3个簇。
聚类结果的3个簇对应3个过程连接带(B1,B2,B3),其轨迹组合分别为(T1,T2,T3)。第1个过程连接带B1的轨迹组合T1共有9 775条轨迹,第2个过程连接带B2的轨迹组合T2共有133条轨迹,第3个过程连接带B3的轨迹组合T3共有161条轨迹,案例轨迹点最多的连接带轨迹组合为T1。
过程连接带的定量描述I如下:B1和B3控制流角度的跟随关系(0,9),(9,7),(10,9),(10,15)都不存在,B2的跟随关系(0,9)和(10,15)不存在,但是(9,7)和(10,9)一定存在;相比B1和B2,B3中Declaration REJECTED by SUPERVISOR活动必然发生1次,活动特征Declaration APPROVED by ADMINISTRATION在3个过程连接带中的取值范围各不相同,其中B1∈[0,1],B2∈[1,1],B3∈[2,2]。
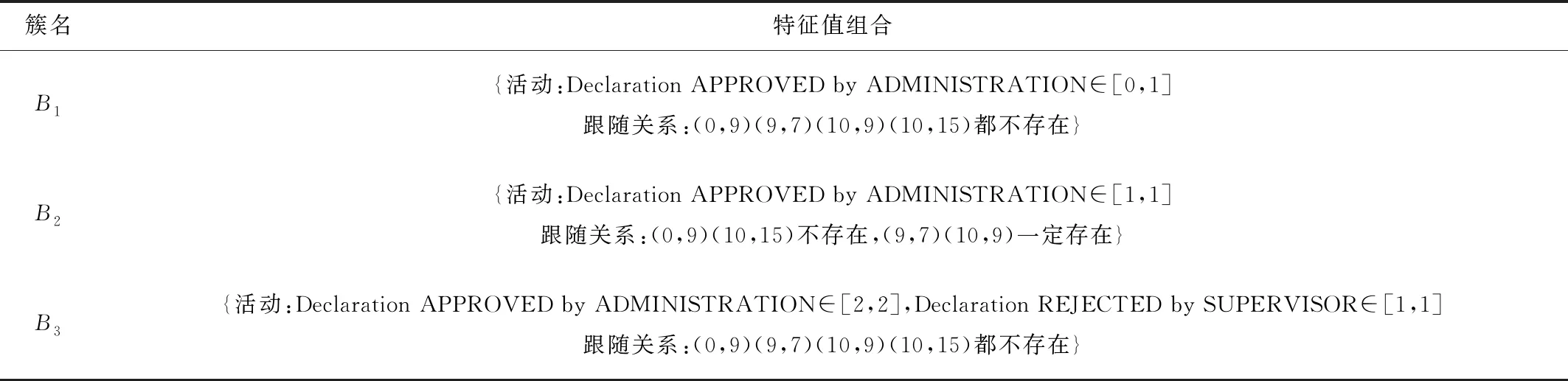
表7 DomesticDeclarations的过程连接带
4.4.2 聚类评价指标分析
分别使用CLTree和CLBDT对事件日志进行聚类,结果如表8所示。对于特征维度低的数据集(如OProblem),CLBDT模型的程序执行时间降低得相对较小,效果不够明显,而对于特征相对较多的数据集(如DomesticDeclarations),CLBDT模型能够极大减少程序执行时间,明显提升聚类效果轮廓系数,同时解决产生大量噪声点的问题。例如,InternationalDeclarations聚类后仅有20.20%的点在簇中,而经过降维后簇中点总数的占比为84.77%;PrepaidTravelCost聚类后仅有39.02%的点在簇中,而经过降维后簇中点总数的占比为92.85%。
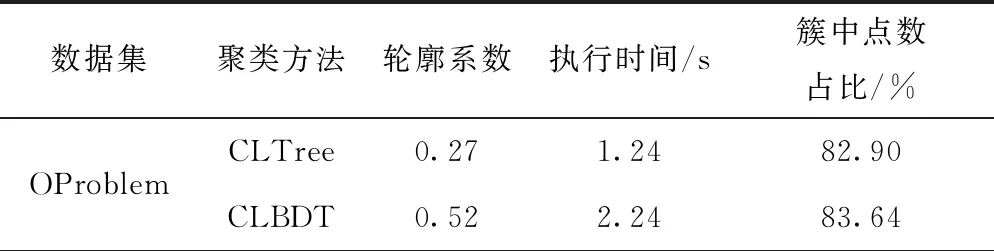
表8 模型聚类结果对比
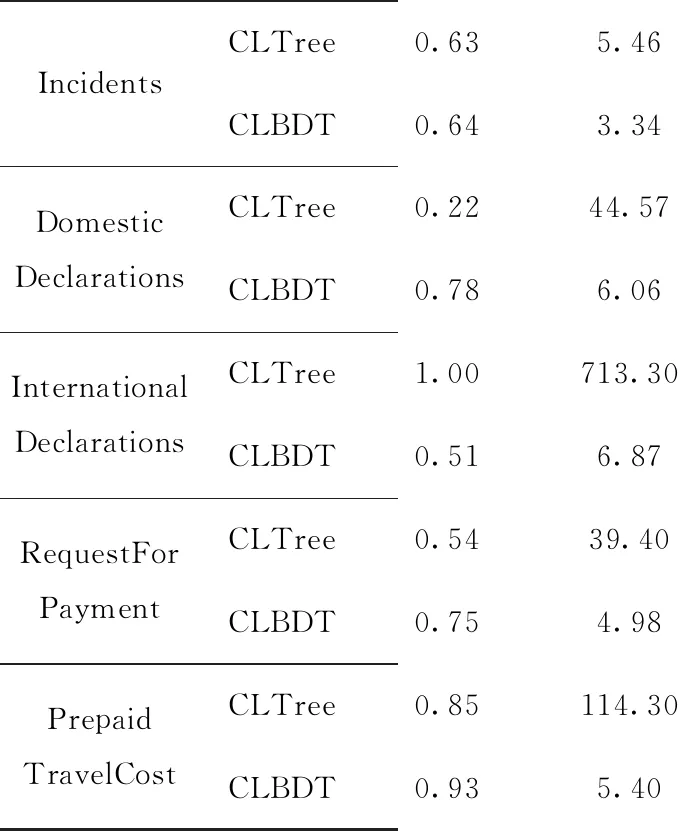
续表8
4.4.3 过程发现结果分析
对6个事件日志的原日志以及经过可解释聚类后的子日志进行过程发现,结果如表9所示。
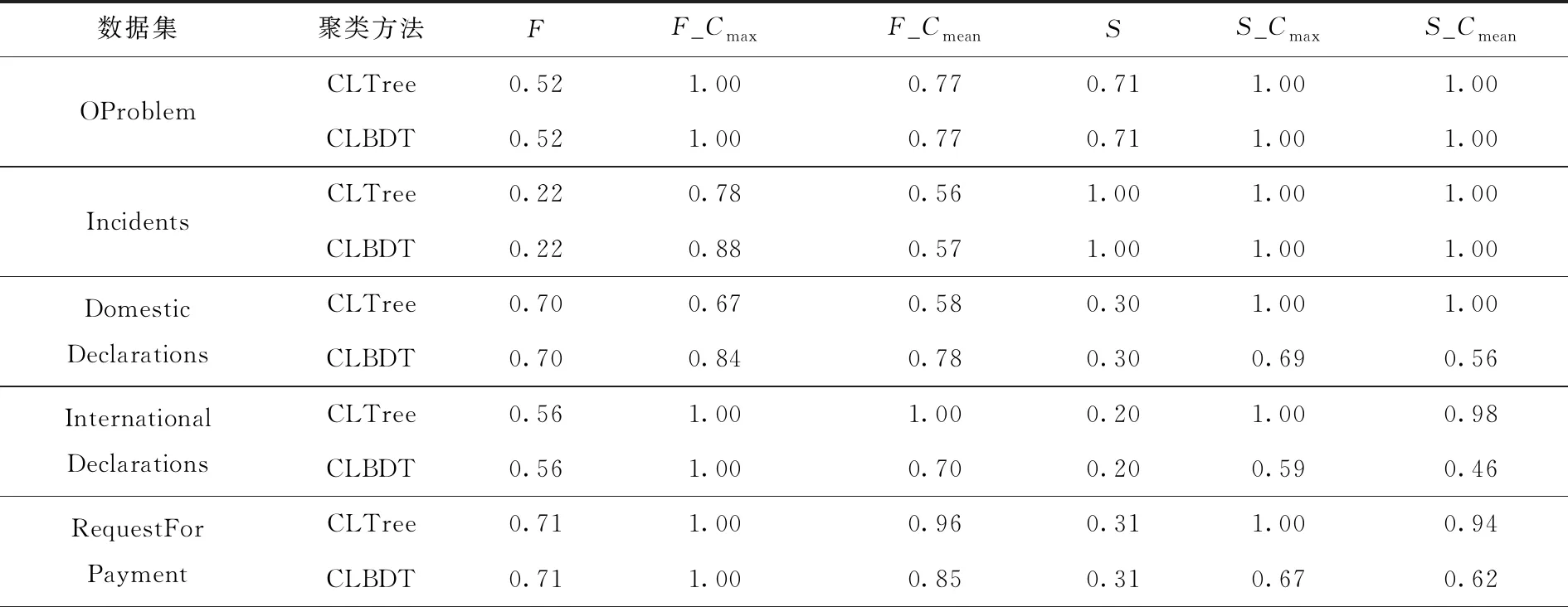
表9 过程发现结果

续表9
由表9可见,过程相对复杂的事件日志,其提取的特征维度相对较高,基线简洁度相对较低。如果不进行降维,维数过高的数据集会产生大量噪声点,最终结果的拟合度和简洁度虽然表现良好,但是牺牲了大量的过程实例。高维数据集降低维度后,虽然拟合度和简洁度表现不如降维前,但也远优于基线。从过程发现结果的拟合度质量来看,CLBDT模型基本优于基线质量和CLTree模型;从过程发现结果的简洁度质量来看,CLBDT模型和CLTree模型的简洁度均优于基线质量,在部分数据集(如DomesticDeclarations)上CLBDT模型会低于CLTree模型。如果追求Petri网的一致性,则看重拟合度,选择CLBDT模型不但合适,而且简洁度也会优于本身结构;如果单纯只追求过程简单,则CLTree模型已经满足需求。
6 结束语
本文提出一种可解释聚类分析方法iBelt来解决过程发现的事件日志结构复杂和可解释性差的问题。该方法中定义了“过程连接带”描述对事件日志分析的结果,并基于聚类树思想设计了梯度提升聚类树CLBDT模型,该模型能够通过动态更新信息增益提高已有方法CLTree的聚类效果和拟合度,同时还能够处理高维数据,提高模型的执行效率。从实验结果来看,iBelt方法成功地降低了算法的时间复杂度,找到了事件日志的过程连接带,过程发现的拟合度和简洁度均优于基线。下一步工作主要集中在优化构成的特征向量,并根据特征特点优化模型。
