一种将深度学习运用在地铁列车外观异常检测领域的方法
2022-11-07吴耿才
吴耿才
(东莞市诺丽电子科技有限公司,广东东莞 523000)
0.前言
现今快节奏的生活模式,使城市的交通系统越来越发达,轨道交通是城市交通系统中必不可少的一部分,它可以有效地缓解城市交通拥堵的现象。城市轨道交通应该保证它的流畅性和便捷性,加强它的服务质量,尽量降低它的事故率,从而推动整个交通系统的发展,间接性地推动社会的进步,并且提高人们的生活质量,城市轨道交通是推动社会发展和经济增长的重要因素之一,先进快捷的轨道交通环境会改善人们的生活,缓解一个城市的交通压力,改善城市的交通结构,让城市的交通方式更加多样化。地铁车辆的运维是保证地铁正常运行的重要一环,每天地铁公司都需要花费大量的人力物力在地铁的日常检修过程中,地铁车辆外观是评估车辆是否有故障的重要一环,大部分的车辆异常都可以通过外观直接观测到,如果外观出现问题长期不解决,可能导致更加严重的故障,所以地铁外观检测对地铁运行维护至关重要。地铁外观检测包括对车顶、车侧、车底、走行部等位置进行检测,包括部件缺失、部件移位、部件干涉、异物、撞击等,地铁日常巡检中同样主要是对车辆外观进行检查,一次日常检测中大约要检测3000多个项点,耗费2个多小时,这对地铁人员造成了很大的检修压力,且大部分时候都在夜间进行,人工检测容易发生疲劳,造成漏检。国内外已经提出了多种检测地铁车辆外观的算法。例如,通过前后两次过车图像差分对比检测异常;通过待检测图像与正常图像相似度对比检测异常;通过目标检测模型直接检测异常等。这些方法都存在误报多,易受自然条件影响,无法具体确定异常类别等问题,地铁检修人员无法通过这些代替日常检修工作,甚至会增加检修人员的工作量。因此,本文提出了一种多阶段的深度学习方法,旨在协助地铁检修人员对一部分地铁外观检测项点进行检测,减少地铁检修人员工作量,降低检测过程中的误报率,同时降低检测过程中的漏报率。
1.总体介绍
我们提出了一种地铁列车外观异常检测的算法,该算法充分将地铁外观异常检测的难点通过深度学习从侧面进行突破,解决了异常样本过少,异常类型难以判断,异常特征随机无法预估等难点,利用现有的深度学习方法实现了比以往方法更高的检测精度和更低的误报率。
我们提出的算法总体可以分为3个检测阶段,在第一阶段对区域进行定位分割,通过一个深度学习语义分割网络将地铁列车按照部件进行区域划分,如轮对区域、空压机区域、辅助逆变箱区域等;第二阶段使用一个编解码结构的网络模型,通过自定义的一个相似度损失函数对待检测区域进行相似度异常分析;第三阶段运用一种细粒度分类方法对异常结果进行进一步筛除,一方面获取异常结果的具体类别,另一方面排除一些误报,主要原理是通过神经网络训练使同类别的距离变小,同时使不同类别的距离变大。其中,第一阶段和第二阶段借鉴了FCN结构,第二阶段中还加入了Transformer结构,增强了模型的泛化能力,大大提高了算法鲁棒性,第三阶段则通过丰富有效的数据增强方式,提高了模型的分类性能。在第二部分中我们将主要对这3个阶段展开介绍。
2.具体过程
2.1 第一阶段
算法第一阶段主要是进行检测区域定位,需要将车辆不同的部分划分出来,使用一种编解码结构的神经网络对图像进行全景分割。由于地铁列车情况较为复杂,某些部位需要单独处理,如车轴、车轮、联轴节等部位在列车行进中会转动,由于转动会导致此类区域在相似度判断时发生较大的影响,需要将其单独分出来进行特殊分析,而以往的全景分割神经网络模型中各类别之间是互斥的,无法赋予同一个区域两种类别属性,所以在神经网络模型最后的类别输出部分使用了多通道的判别方式,将一个多分类问题转化为多个二分类问题,可以使全景分割结果各类别间并不互斥。如车轴部分既属于轮对类别区域,又属于活动类别区域,原本只能将车轴区域划分至轮对区域类别或活动区域类别,现在则可以同时赋予车轴区域两个类别属性。
在损失函数部分,由于将多分类转化为二分类后,每个类别的两个分类之间所占比例会出现不均衡的情况,我们采用根据类别面积比例加权的方式对损失进行均衡化,即根据当前类别在图像中所占的面积比,对当前类别距离进行加权,扩大当前类别的影响因子,损失函数公式如下:
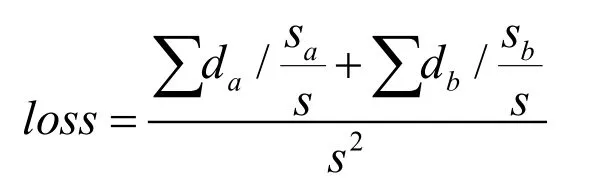
其中da、db分别为两个类别输出与标签的平方差,sa、sb分别为两个类别所占的面积大小,s为输入图像的总面积,即sa与sb之和。
2.2 第二阶段
在第一阶段中,我们已经获取到了需要分析的区域,并对区域做了类别划分,算法第二阶段则是对第一阶段识别到的结果进行初步的异常判断,判断基础是利用第一阶段划分出的区域进行相似度判断,我们的做法是首先将一份正常图像作为对比参考,其次将异常图像与正常图像结合作为一组对比数据,最后利用相似度损失函数进行距离分析,通过对正常图像和异常图像逐像素区域对比,将存在异常的区域从整个分析区域中与正常区域分离开。整体结构同样是使用编解码结构,与第一阶段不同的是输入部分使用一组图像对,标签不单纯作为计算损失,而是作为权重参与到损失函数计算中,即在相似度计算中为标签中的异常区域部分给予一个较大的权重,在计算相似度距离时使用了两个均方差距离共同表示,即输出图异常部分区域与输入图异常部分区域距离最小,输出图正常部分区域与输入图对应区域距离最小,相应的损失函数如下:
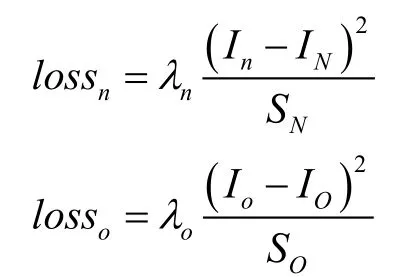
其中,lossn为异常区域的损失,losso为正常区域的损失,λn为异常区域的标签权重,λo为正常区域的标签权重,In为输出中异常区域的图像灰度值,IN为输入中异常区域的图像灰度值,Io为输出中正常区域的图像灰度值,IO为输入中正常区域的图像灰度值,SN为标签中异常区域的面积,SO为标签中正常区域的面积。在训练过程中,设置λn为SN/S,λo为sO/S,IN为 1,IO为 -1。
此外,在编解码结构中,还加入了Transformer模块,Transformer模块中加入了上下文的影响因子,可以为神经网络训练时增加更多的先验条件,卷积是一种局部操作,一个卷积层通常只会建模邻域像素之间的关系。Transformer则是全局操作,一个Transformer层能建模所有像素之间的关系,双方可以很好地进行互补。最早将这种互补性联系起来的是非局部网络,在这个工作中,少量Transformer自注意单元被插入原始网络的几个地方,作为卷积网络的补充,并被证明其在物体检测、语义分割和视频动作识别等问题中广泛有效。我们使用Transformer结构旨在强调异常区域周围图像对相似度判断的影响,使相似度损失不仅仅受当前卷积区域的影响,同时当前卷积区域周围的特征图也会对相似度损失产生一部分影响,我们这样做的原因是,在通过第一阶段后提取到的图像中边缘部分可能会存在一定程度的偏移,而且本身图像在彩图过程中会因为车速变化的影响存在一定程度的畸变,所以异常图像与正常图像无法做到完全对齐,所以在以图像灰度值距离作为相似度判断依据时容易发生较大的偏差,因此在做相似度比较时需要结合待检测区域周围的图像增强相似度距离判断的稳定性。
2.3 第三阶段
在第二阶段完成后,虽然可以将待测图像中与正常图像相似度较低的部分划分出来,但其中仍然会混合一些并不是异常的部分,比如列车的活动区域和灰尘、雨水等容易变化的部分,且并没有对异常情况进行分类区分,为了达到更好的检测效果,在算法的最后加入了第三阶段,算法的第三阶段是使用一个深度学习细粒度分类网络对算法第二阶段的结果进行分类,由于地铁列车在行驶过程中车体外观会发生各种各样的变化,但并不是所有变化都是异常,而变化的出现会使区域与正常图像的相似度变低,为减少因某些变化导致的误报,使用了一个细粒度分类网络对异常检测结果进行二次判断,去除那些在地铁列车行驶过程中发生的正常的外观变化,如灰尘、雨水等。
在第三阶段的分类网络部分我们的数据是由第二阶段得来的,我们经过分类划分后主要可以分为以下几个类别:缺失异常、异物异常、移位异常、其他异常、列车活动部分、表面脏污、表面水渍4类,这4类数据中差异最大的部分在于表面纹理,所以我们在前期数据预处理时加入了亮度增强、对比度增强、图像灰度值反转、翻转、旋转等一系列方法,可以更加突出图像纹理部分的特征,同时,由于第二阶段的结果图像尺寸大小差别较大,我们对较大的图像进行了裁剪,将尺寸较大的图像裁剪为几个尺寸较小的图像,最后经过等比例缩放变换为64×64的图像作为第三阶段的输入。
为了最大程度上保留和提取到图像的纹理信息,我们在特征提取网络resnet-18的基础上对其做出修改,使用一个下采样和上采样模块替换了原网络模型的基础卷积模块,可以更好地提取图像的纹理信息,在损失函数部分采用Triplet Loss,Triplet Loss显式的在Loss里面要求:不同类别之间的距离至少要超过同类别之间距离的某个阈值。如果能够做到这一点,那么类内距和类间距之间差就有一个明显的鸿沟,那么也可以达到上面提到的目标。同时,由于在地铁列车异常检测过程中,检出异常的任务要比减少误报的任务重要性大得多,所以在几个分类中,异常类别分类的检测准确度显得更加重要,所以我们在损失函数中为异常类别加入了一个较大的权重,使模型更倾向于检出异常,而不是减少误报。
3.试验过程
在试验过程中,我们将算法的3个阶段分开分别对其进行性能分析。
第一个阶段的算法主要为一个深度学习图像语义分割网络,采用MPA(平均像素精度)对检测结果进行评价,MPA公式如下:

模型测试数据集中我们使用1000张图像,平均像素精度可达到92.32%。
第二阶段中,使用第一阶段的输出作为第二阶段的测试数据,算法第二阶段在本质上也可以作为一个深度学习分类网络,只不过其分类标准是我们定义的相似度,而作为地铁外观异常检测,我们关心的是异常被检出多少,以及出现多少误报,所以在第二阶段的试验过程中采用检出率和误报率作为评价指标,其公式如下:
检出率=正确检出的异常个数/真实的异常个数*100%
误报率=错误检出的异常个数/检测项点总数*100%
在试验中,我们共设置了80处异常,模型异常报警为134处,其中正确报警为80处,错误报警为54处,检出率达到了100%,总检测项点数按1000计算,误报率为5.4%。
算法的第三阶段同样是一个深度学习分类模型,其目的主要是为了消除误报和对异常进行分类,第三阶段试验过程中的输入图像为第二阶段的输出结果。在评价模型消除误报的性能时,仍然使用和第二阶段中相同的检出率和误报率作为评价指标,不同的是误报率中基数为检测的图像数量,而不是检测项点总数,在对异常分类作出评价时,采用的是mAP(平均精度)指标,且只考虑前4种类型的类别,即只分析异常类别的分类精度,指标公式如下:
检出率=正确检出的异常个数/真实的异常个数*100%
误报率=错误检出的异常个数/检测图像个数*100%
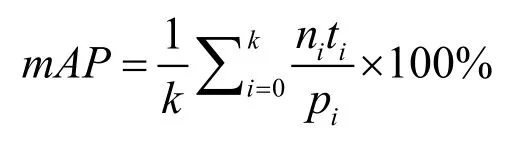
其中,k为类别个数,ni为第i个类别的样本数,ti为第i个类别检测正确的个数,pi为结果中检测为第i个类别的个数。
在实验中,输入的图像共有134张,经过切割处理后共得到452张图像。其中,异常图像共有253张,非异常图像共有199张,正确检出的异常个数共有252个,错误检出的异常个数共有14个,经计算统计后得出,检出率为99.6%,误报率为3.1%,mAP为73.2%。
最后,由于在算法第三阶段有对图像进行切割,所以一些检测结果需要进行合并处理,在对算法第三阶段的结果进行合并处理之后,最终得出正确检出的异常个数为80个,错误检出的异常个数为13个,按照第二阶段的评价指标计算,得出最终的检出率为100%,误报率为1.3%。
4.结语
本文提出的地铁列车外观检测方法主要利用了现有的比较先进的模型结构,同时结合地铁列车的外观异常特点,使用了一个三阶段的异常检测算法,避开了异常检测中异常样本较少带来的影响。同时也考虑到了地铁列车外观异常检测中检出和误报的重要关系,在模型训练过程中做出了相应的平衡性调整。目前算法遇到的问题是异常类别判断准确率偏低,主要原因是由于样本数太少,且样本特征不明显,后续改善可以考虑从数据增强和少样本方向进行突破。
