基于位置特征和句法依存树的可度量数量信息抽取模型①
2022-11-07聂文杰黄邦锐郝天永
聂文杰,莫 迪,黄邦锐,刘 海,郝天永
1(华南师范大学 计算机学院,广州 510631)
2(华南师范大学 人工智能学院,佛山 528225)
随着电子病历的快速普及与发展,从电子病历中抽取所需关键信息逐渐成为医学信息学领域研究者关注的热点问题,目前许多研究者关注于从非结构化电子病历文本中抽取医学概念[1]、医学属性值[2]、时间表达式[3]、药物不良反应事件[4]与药物间相互作用[5].对电子病历中的可度量数量信息的抽取却较为匮乏.可度量数量信息广泛存在于各类非结构化文本中[6],例如在临床试验钠排标准文本中的占比超过40%[7].低精度的可度量数量信息抽取会导致药物剂量分析与临床试验资格标准认定等研究的瓶颈[6].
可度量数量信息作为一种量化数据,由实体与相关数量属性组成[8].以语句“心率达120 次/分钟”为例,其中“心率”为实体,“120”为数值,“次/分钟”为单位,数值与单位的组合“120 次/分钟”为数量.图1 显示了非结构化电子病历文本包含的可度量数量信息,其中下划线表示实体,粗体表示数值,斜体表示单位,其中实体与数值、单位之间的相对位置并不固定,以“体温36.0 摄氏度”与“3 600 mL 血浆”为例,其中“体温36.0摄氏度”中的实体在数值与单位之前,而“3 600 mL 血浆”中的实体在数值与单位之后.另外如实体“5%葡萄糖注射液”所示,部分数值信息为实体的一部分,而非单独的数值.现有信息抽取技术尚未对可度量数量信息中的位置信息进行深入的研究,并且难以区分单独的数值与作为实体一部分的数值.

图1 非结构化电子病历文本中包含的可度量数量信息
现有可度量数量信息抽取相关研究主要利用基于规则与传统机器学习模型的方法,然而基于规则的方法需要花费大量时间与精力设计规则,且泛用性往往较弱,无法很好地迁移至其他语料或领域.而传统机器学习模型需要做大量的特征工程,所生成的特征质量很大程度地影响着模型的最终性能.因此可以自动抽取特征的深度学习模型引起了研究者的关注,循环神经网络(recurrent neural network,RNN)被引入用来抽取信息,同时为了进一步提升模型性能,诸如位置特征等外部特征被融入到深度学习模型当中.然而无论是Vaswani 等[9]根据sin 函数与cos 函数生成的位置编码还是Wang 等[10]介绍的位置向量,都没有对所需信息与无关信息进行特殊处理.此外当前大多研究将整个序列作为模型的输入,而Zhang 等[11]已经证明对原输入序列进行适当删减有助于提升模型性能.
本文首先通过相对位置特征来区分实体与数量信息与非实体与非数量信息,并将其融入注意力(attention)机制中,对通过双向门控循环单元(bi-direction gated recurrent unit,BiGRU)获得的上下文特征进行更新,以此识别实体与数量信息.并通过将输入语句转换为句法依存树的同时进行重构,在充分提取输入语句语义信息的同时排除无关信息的干扰,并结合图注意力网络(graph attention networks,GAT)进一步抽取特征,对实体与数量进行正确关联,实现可度量数量信息关联,最终完成可度量数量信息的抽取.综上所述,本文的主要贡献如下:
(1)通过将相对位置特征与注意力机制融合,提出新的RPA-GRU (relative position attention-BiGRU)模型,识别实体与数量信息.
(2)通过对输入语句生成的句法依存树重构,提出新的GATM (graph attention networks for measurable quantitative information)模型,关联可度量数量信息.
(3)实验结果表明所提出的RPA-GRU 与GATM模型相比基线模型获得了最佳性能,验证了其有效性.
1 相关工作
对于可度量数量信息抽取的相关研究,早期为基于规则的方法,如肖洪等[12]通过对量词进行总结得到125 种模式,在利用有限自动机抽取量词的同时构建正则表达式与模板从年鉴文本当中抽取数值知识元.Turchin 等[13]利用正则表达式从临床笔记当中抽取血压值,并通过领域知识校验抽取结果.Hao 等[7]引入领域知识与UMLS 元词典等外部知识设计启发式规则从1 型糖尿病数据集与2 型糖尿病数据集中抽取可度量数量信息.Liu 等[8]对医学文本当中的关键语义角色进行标记,自动学习模式抽取可度量数量信息以减少人工.随着传统机器学习的发展,如条件随机场(conditional random field,CRF)被引入,或单独使用或与规则进行结合.张桂平等[14]在构建模板的基础上利用CRF 对模板进行补充,从而对数值信息进行抽取.随着能够自动抽取特征的深度学习模型的发展,如双向长短期记忆网络(bidirectional long short-term conditional random field,BiLSTM)模型被研究者所关注,王竣平等[15]通过建立数值信息知识库与模板,抽取属性值与单位,并利用BiLSTM-CRF 模型对工业领域中的数值信息进行抽取.Liu 等[16]设计了包含相对位置特征、绝对位置特征与词典特征等多种外部特征,并将其向量化后进行连接送入BiLSTM-CRF 模型进行建模,从而识别电子医疗病历中的实体与数量信息,而后将实体数、数量数、相对位置与绝对距离作为外部特征输入随机森林(random forest)模型,对实体与数量信息进行关联.但以上研究都未对输入信息进行取舍与重要性区分.
此外,其他研究者针对可度量数量信息的部分信息如实体进行抽取,商金秋等[17]利用正向最大匹配算法与决策树模型从电子病历当中抽取患者发热相关症状及其具体表现并将其进行可视化,以辅助医生治疗.Hundman 等[18]开发了一个名为Marve 的系统,首先利用CRF 识别数值与单位,然后基于规则识别实体.Berrahou 等[19]则是利用J48 决策树、支持向量机(support vector machines)、朴素贝叶斯(naive Bayes)、判别性多义朴素贝叶斯(discriminative multinominal naive Bayes)等多个分类器对科学文档中的单位进行抽取.Zhang 等[20]通过将字符信息与分词信息融入BiLSTM-CRF 模型,提升了临床实体识别的性能.Xu 等[21]将文档级注意力与BiLSTM 模型结合,从2010 i2b2/VA 数据集当中识别临床命名实体,相比无注意力机制的BiLSTM 模型提高了1.01%的F1 值,证明了注意力机制的有效性.此外,为了进一步抽取实体,Zhang 等[22]在通用领域上提出了Lattice-LSTM,通过在字符级抽取特征避免分词错误,并引入当前字符在外部词典中的匹配词来同时考虑字符信息与词信息.另外,Zhang 等[11]将句法依存树中的最短依赖路径(short dependency paths,SDP)与RNN 相结合,排除无关信息.Lin 等[5]则是将图神经网络(graph neural network,GNN)拓展到知识图谱,以此预测药物之间的反应(drug-drug interaction,DDI).Song 等[23]则是将句法依存树拓展为森林,实现医学关系抽取.上述部分研究虽利用了注意力机制与剪枝方法进行重要性的区分,却并未抽取完整的可度量数量信息.
2 可度量数量信息识别与关联模型
2.1 可度量数量信息识别模型
可度量数量信息识别是将输入语句中的每个字符分别标记为实体、数值、单位与其他,符合序列标记任务的定义.因此本文将可度量数量信息识别任务转换为一个标准的序列标记任务.首先将输入语句编码为X={x1,x2,x3,···,xm},其中xm∈Rde表示语句X的第m个字符,de表示输入向量的维度.语句的输出标签为Y={y1,y2,y3,···,ym},其中ym表示第m个字符所对应的标签.识别任务的目标是寻找一个函数fθ:XY,将输入语句的所有字符映射为对应的标签.对此本文提出RPA-GRU 模型,具体模型结构如图2.模型首先为输入序列生成对应的向量表示并利用BiGRU 模型抽取上下文特征,然后将相对位置向量融入注意力机制对上下文特征进行更新,以此区分实体与数量信息与非实体和非数量信息,最后送入CRF.
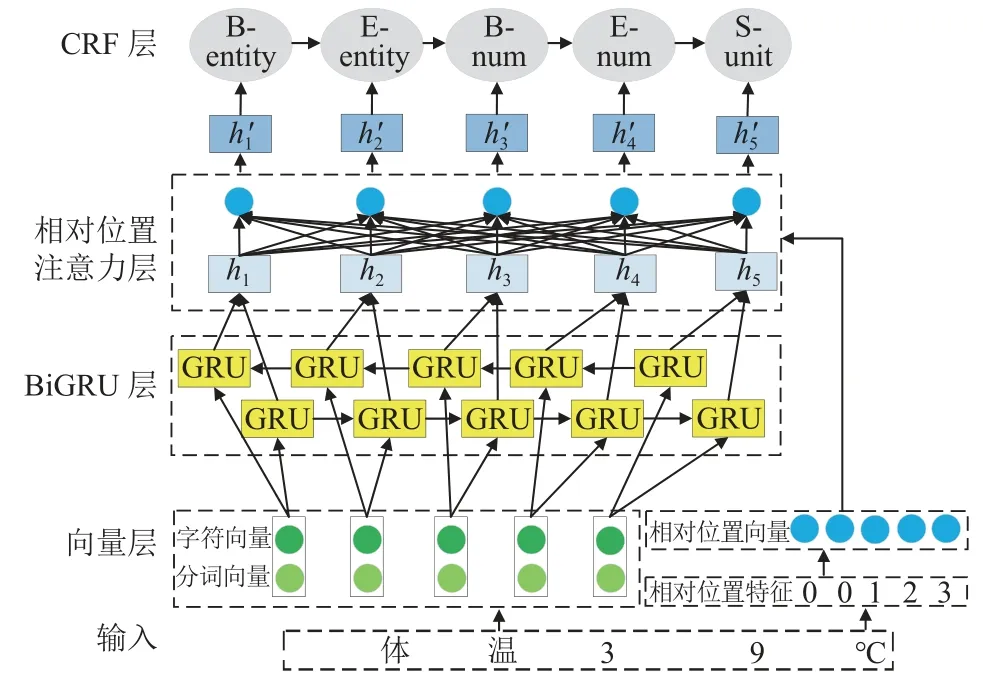
图2 RPA-GRU 模型的网络结构
(1)相对位置特征及向量
为了将实体与数值信息与非实体和非数值信息进行区分,本文对Liu 等[16]提出的相对位置特征进行拓展.具体而言,对于实体与数量信息,以距离最近的实体为中心按照距离分配不同的相对位置特征,对于非实体与非数量信息的相对位置特征而言,为了防止与实体和数量信息的相对位置特征之间的干扰,统一设置为语句最大长度+1 之和的负数,抽取过程如算法1,示例为表1.
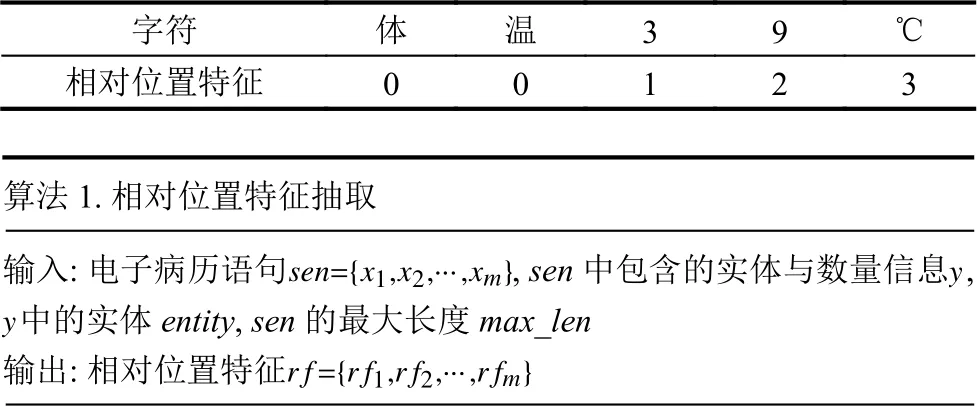
表1 相对位置特征示例

1)For do xiy i=1,···,m 2)If in xi 3)If in entity r fi←4)0 5)Else 6)distance= 与最近的entity 之间的距离xi xi 7)If 在距离最近的entity 左边r fi←8)-1×distance 9)Else r fi←10) distance 11)End If 12)End If 13)Else r fi←14)-1×(max_len+1)15)End If 16)End For
本文对相对位置特征进行随机初始化,并在训练期间进行更新.从而为输入语句X={x1,x2,···,xm}生成对应的相对位置向量
(2)相对位置特征融入注意力机制
本文通过将输入语句中的每个字符对应的字符向量与分词向量进行拼接得到e=[ech:eseg]作为BiGRU模型的输入,其中ech与eseg分别为字符向量与分词向量,[:]表示拼接操作.字符向量由Word2Vec[24]进行初始化,分词向量与相对位置向量类似,随机初始化后于训练期间更新.将e送入BiGRU 模型得到上下文特征H=[h1,h2,···,hm],从而引入字符与分词信息,然后将相对位置向量融入注意力机制[25]中,为不同部分分配不同重要性,进一步捕获信息.计算方式如式(1):

其中,αx为注意力权重,计算方式如式(2):

其中,s为得分函数,计算方式如式(3):

通过融入相对位置向量的注意力机制,得到更新后的上下文特征最后将H′送入标准CRF 得到最终结果.
2.2 可度量数量信息关联模型
对于需要抽取可度量数量信息的语句而言,如果单条语句中只有一个可度量数量信息,那么直接将实体与数量进行关联即可,然而如图1,单条语句中可能存在多个可度量数量信息,因此需要将语句中的实体与相应的数量进行正确关联.又由于实体与数量之间仅存在有关联与无关联两种关系,因此本文将关联任务视作二分类问题.对此本文提出GATM 模型,对实体与数量进行关联,具体模型结构如图3.模型首先将输入语句转换为词向量并生成对应的句法依存树,对句法依存树进行重构后转换为邻接矩阵,然后将词向量送入BiLSTM 获取上下文特征,将上下文特征与邻接矩阵送入图注意力网络进一步抽取特征,最后送入Softmax 得到最终结果.

图3 GATM 模型的网络结构
(1)句法依存树生成与重构
给定输入语句X={x1,x2,···,xl},其中l表示当前输入语句长度.以输入语句“今予输血蛋白100 mL”为例,生成的完整句法依存树示例如图4(a).可以看到当前句法依存树根节点为“输”,“tmod”表示时间修饰语,“dobj”表示直接宾语,“range”表示数量词间接宾语,“nummod”表示数词修饰语.句法依存树描述了各个词语之间的语法联系,包含着丰富的语义信息,另外对句法依存树进行适当修剪有助于模型性能的提升.Xu 等[26]提出基于SDP 的LSTM 模型,通过去除无关信息仅保留两个实体之间的关键路径提升模型的F1 值.Wang等[10]在基于单向SDP 的基础上提出了双向SDP (bidirectional SDP)进一步抽取信息.另外,由于本文关心的重点是可度量数量信息但句法依存树通常不以可度量数量信息为根.因此本文对句法依存树进行以可度量数量信息中的实体为根的重构,在重构的同时对句法依存树进行剪枝,防止无关信息干扰.重构后的句法依存树如图4(b),重构后的句法依存树被转换为邻接矩阵A,Aij=Aji=1表示词i与词j在句法依存树中存在依赖关系.重构过程如算法2.
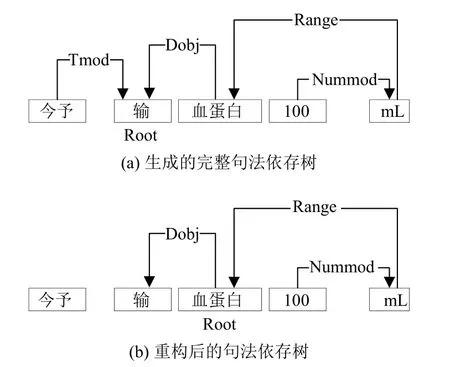
图4 句法依存树示例

算法2.重构句法依存树输入: 包含可度量数量信息的语句,可度量数量信息中的实体ent,数量quantity,原始句法依存树 与直接依赖关系sen={w1,w2,···,wl}T r输出: 重构后以实体为中心的句法依存树TT 1)将ent 作为 的根节点i=1,···,l 2)For do wiTr 3)If 与ent 或quantity 在 中存在直接依赖关系Twir 4)向 中添加 与ent 或quantity 的直接依赖关系5)End If 6)End For
同时为了利用BiLSTM 模型抽取上下文特征,本文利用Word2Vec[24]将输入语句X={x1,x2,···,xl}中的每个词xi转换为相应的词向量wi,从而得到输入语句所对应的词向量序列W={w1,w2,···,wl},并送入BiLSTM 模型进行抽取得到相应的上下文特征H={h1,h2,···,hl}.
(2)图注意力网络
GAT 由Velickovic 等[27]提出,其结合了注意力机制与图卷积网络(graph convolutional network,GCN),利用注意力机制为不同节点分配不同重要性.本文将上下文特征H与邻接矩阵A输入GAT,得到更新后上下文特征H′={h′1,h′2,···,h′l}.然后将H′通过一个线性层,作为Softmax层输入,得到预测向量y,计算公式如式(4):
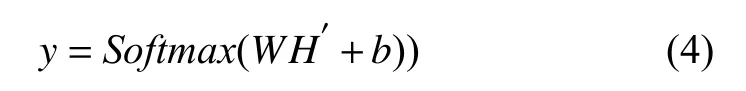
其中,y为当前输入属于每个类别的概率,并利用argmax函数将其中最大概率的类别作为最终输出.交叉熵函数作为GATM 模型的损失函数,计算方式如式(5):
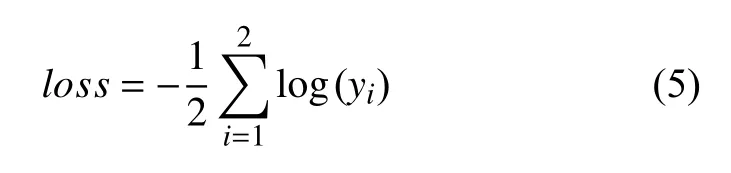
3 实验
3.1 数据集
实验数据来自某三甲医院烧伤科的1 359 份电子病历,最初由两名相关研究人员利用标注工具Colabeler对每个句子中的可度量数量信息进行标注,对于两名研究人员标注不一致的数据,由一名医学信息学的博士进行最终的标注判定,并通过Kappa 检验,得到最终的实验数据集.识别数据集格式为BIOES 标注模式,其中B 为Begin 的缩写,表示该字符处于开始位置,I 为Inside 的缩写,表示该字符处于中间位置,E 为End 的缩写,表示该字符处于结束位置,S 为Single 的缩写,表示该字符单独构成实体、数值或单位,O 为Other 的缩写,表示非实体、非数值与非单位.数据集具体示例如表2,其中Entity、Num 和Unit 分别表示实体、数值与单位,“<e></e>”标识当前实体,“<q></q>”标识当前数量.“Entity-Quantity(e,q)”为正例,表示当前实体与当前数量之间有关联,“Other”为负例,表示当前实体与当前数量之间无关联.

表2 数据集具体示例
最终标注好的数据被随机划分为训练集、验证集与测试集,数据集详细统计信息如表3 所示.
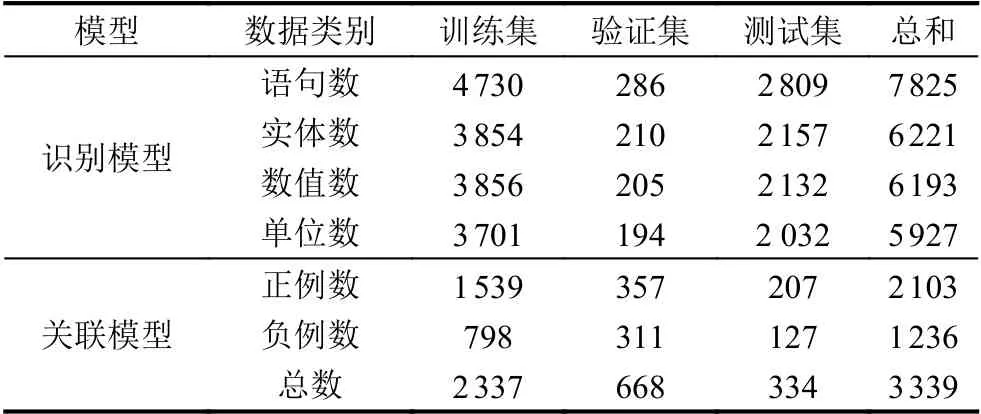
表3 数据集详细统计信息
3.2 评价指标
对于识别与关联任务,本文采用精确率(Precision),召回率(Recall)与F1 值作为评价指标,具体计算方式如式(6)-式(8).
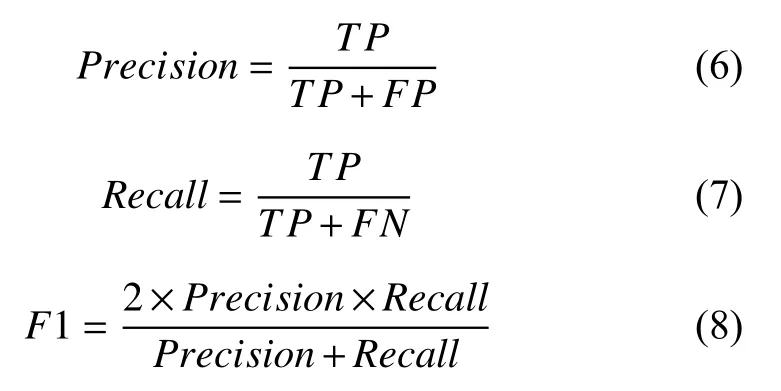
其中,TP表示将正类预测为正类的数量,FP表示将负类预测为正类的数量,FN表示将正类预测为负类的数量.
3.3 基线模型
为了验证RPA-GRU 在识别任务上的有效性,本文使用以下基线进行性能比较.
Extended BiLSTM-CRF: Liu 等[16]将绝对位置特征、相对位置特征与词典特征向量化后进行连接送入Bi-LSTM-CRF 模型,提升模型F1 值.
Lattice-LSTM: Zhang 等[22]利用外部词典匹配句子中的字符,从而获得包含字符的词语,生成包含字符与词的格,从而增强基于字符的模型.
WC-LSTM: Liu 等[28]分别利用最长单词优先(longest word first,LWF)、最短单词优先(shortest word first,SWF)、均值(average)与自注意力(self-attention,SA)4 种方法在输入的字符向量中融入词汇信息.
LR-CNN: Gui 等[29]在卷积神经网络(convolution neural network,CNN)的基础上利用Rethinking 机制合并词汇信息,对匹配语句的字符与潜在单词进行建模.
Soft-Lexicon: Ma 等[30]通过将每个字符所对应的全部词进行合并后进行加权求和,得到词向量并与字符向量进行拼接,引入词汇信息.
另外,为了验证GATM 模型在关联任务上的效果,与以下基线进行比较.
AGGCN: Guo 等[31]将完整的句法依存树送入GCN 当中,并通过注意力机制实现软剪枝,此外其在AGGCN 模型的基础上,利用LSTM 模型捕获上下文特征从而提出C-AGGCN 模型.
Att-BiLSTM: Zhou 等[32]将注意力机制引入BiLSTM模型当中,探究注意力机制对模型的提升.
PA-LSTM: Zhang 等[33]在LSTM 模型的基础上引入位置注意力来考虑实体的全局位置信息.
3.4 实验参数
为防止RPA-GRU 与GATM 模型产生过拟合,本文在训练过程中引入正则化,另外将Adam[34]与AdaGrad[35]分别作为RPA-GRU 与GATM 模型的优化器,其余参数设置如表4.
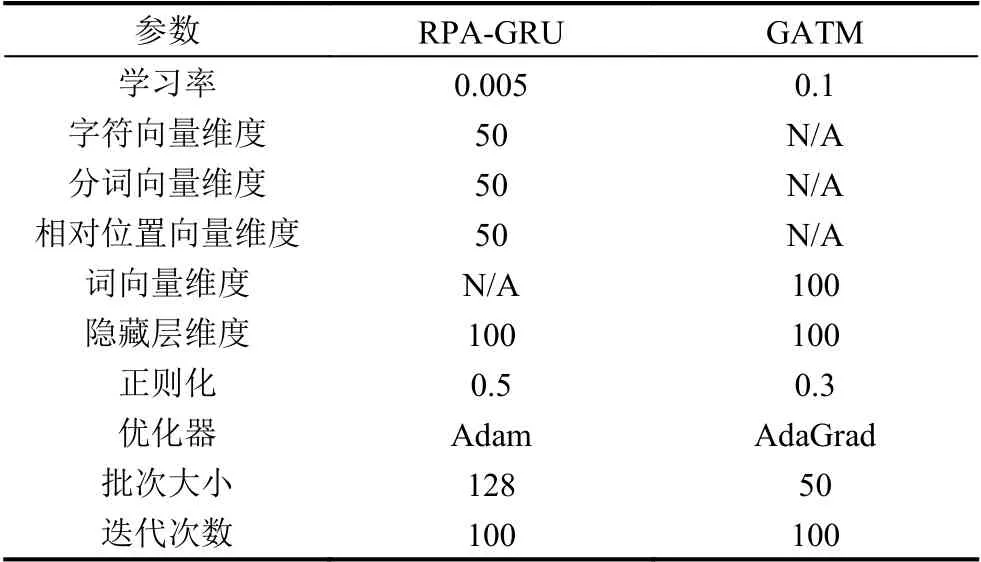
表4 模型的实验参数设置
3.5 实验结果
模型在识别任务上的实验结果如表5,结果表明RPA-GRU 模型取得了98.56%的精确率,96.61%的召回率,97.58%的F1 值,在3 个指标上均超越了其他基线模型.具体而言,与之前将外部特征向量化后并连接送入BiLSTM 模型的Extended Bi-LSTM-CRF 模型相比,RPA-GRU 模型取得的F1 值高3.31%,证明比起简单的特征拼接,本文将相对位置注意力融入注意力机制更新上下文特征取得的效果更优.与之前通过外部词典来引入词信息的模型Lattice-LSTM、WC-LSTM(LWF/SWF/Average)、WC-LSTM (SA)、LR-CNN、Soft-Lexicon 对比,RPA-GRU 模型取得的F1 值分别高2.30%、2.30%、2.17%、3.10%、2.62%,证明本文所提出的模型即使不依赖外部词典获取词信息也能获得更好的性能.
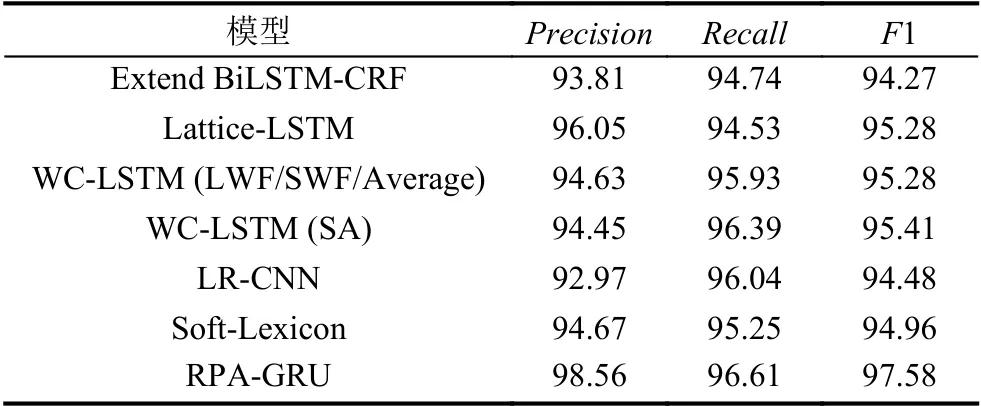
表5 识别任务实验结果对比(%)
模型在识别任务上的混淆矩阵如图5 所示.由于混淆矩阵中的实际标签Other 被预测为Other 的数量对模型性能没有影响,因此为简化矩阵,将其数量置为0.从混淆矩阵中可以看到,对于Entity、Num 和Unit而言,大部分相关信息都已被成功抽取,且彼此之间很少发生混淆,得到了不错的效果,然而无论是Entity、Num 还是Unit 都会与其他信息之间发生一定的混淆,如“D-二聚体”等实体还是难以进行准确抽取,导致模型性能受到些许影响.
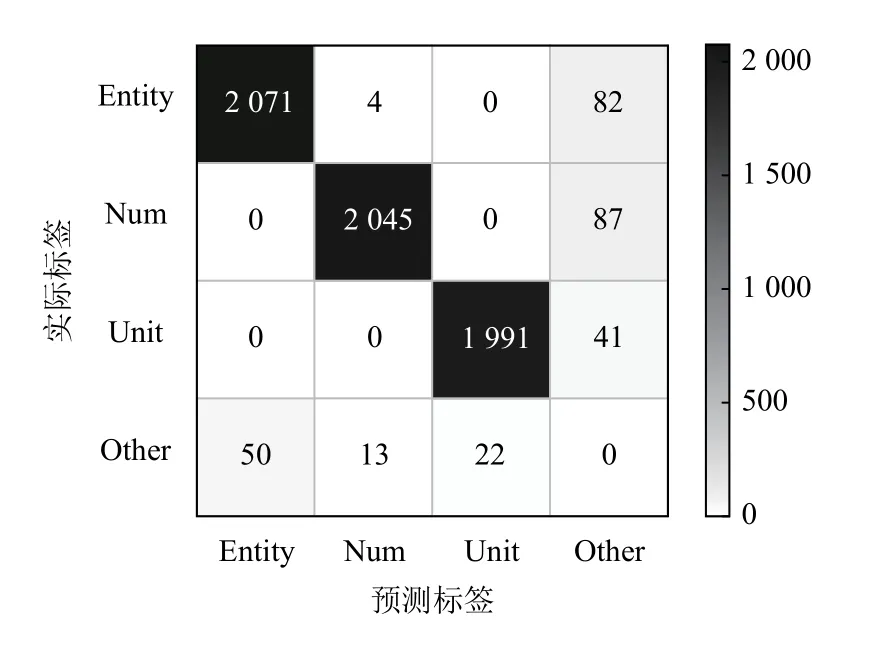
图5 识别任务混淆矩阵
模型在关联任务上的实验结果如表6 所示,结果表明GATM 模型取得了96.26%的精确率,99.52%的召回率与97.86%的F1 值,在3 个指标上均超越了其他基线模型.具体而言,与之前利用注意力机制的软剪枝方法(如AGGCN 与C-AGGCN)相比,GATM 模型高3.52%与2.60%的F1 值,证明本文针对句法依存树的重构策略更优.与仅引入注意力机制的模型如(Att-BiLSTM、PA-LSTM)相比,GATM 模型高3.42%与1.74%的F1 值,表明GATM 模型通过引入句法依存树中的句法信息,有效提升了模型性能.
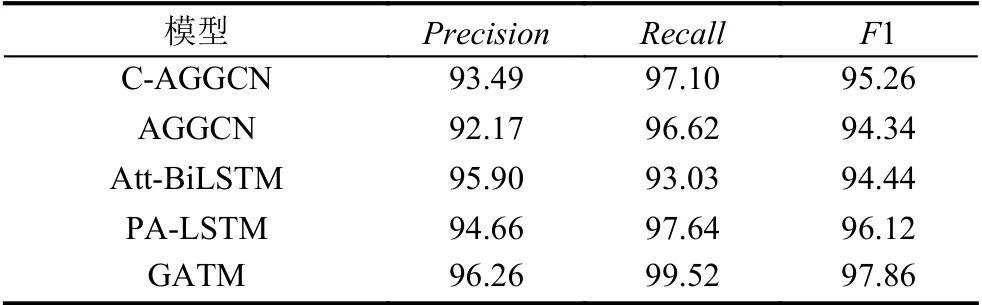
表6 关联任务实验对比(%)
模型在关联任务上的混淆矩阵如图6 所示.从混淆矩阵中可以看到,得到的最终结果较为理想,未发生大规模的混淆情况,进一步验证了模型的有效性.
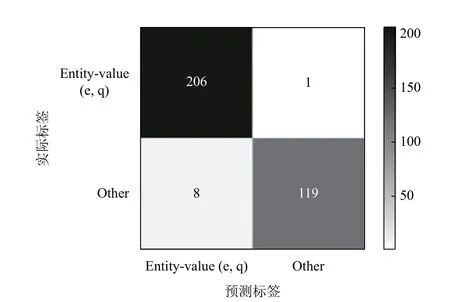
图6 关联任务混淆矩阵
随着迭代次数的不断增加,RPA-GRU 模型与GATM模型的准确率与损失函数曲线分别如图7 与图8 所示.可以看到,两个模型的准确率逐步上升,而损失函数的值逐步减少,最终都趋于稳定.
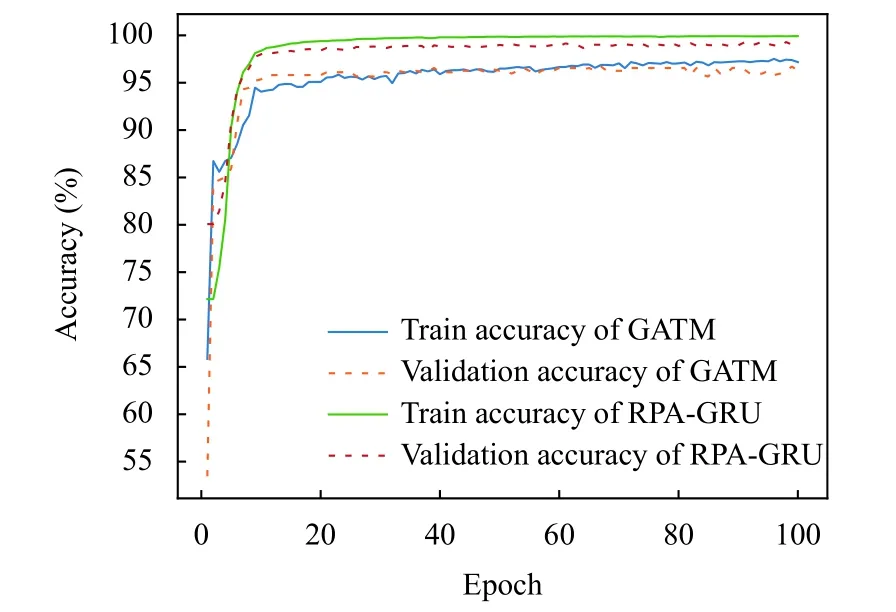
图7 准确率变化曲线
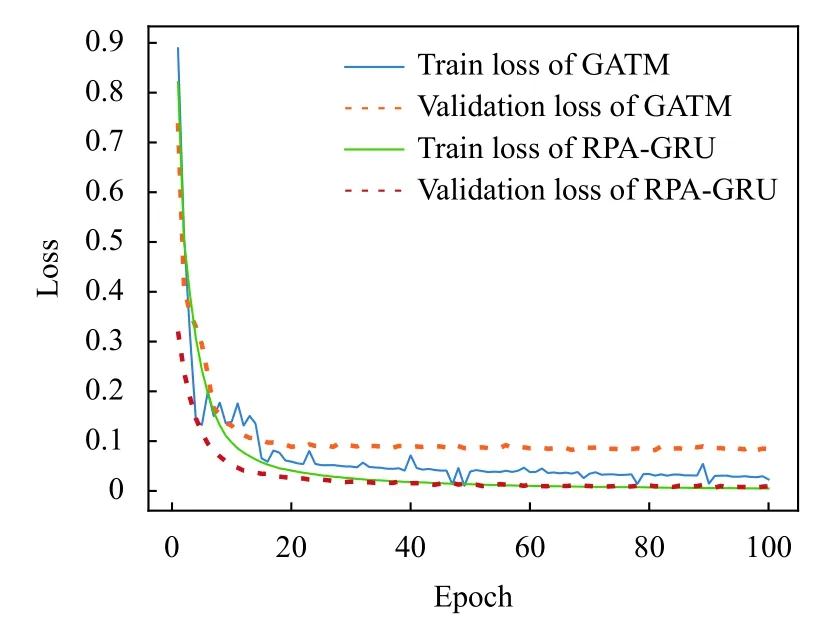
图8 损失函数变化曲线
为了分析不同训练集大小对RPA-GRU 模型与GATM 模型性能的影响,本文通过随机抽取的方法设置6 个不同规模大小的训练集,数据集大小分别原始数据集的0.10、0.15、0.25、0.50、0.75、1.00.图9 显示了在不同训练集大小上训练得到模型的F1 值,从图中可以看到当训练集大小占比小于0.25 时,随着训练集大小的增加,RPA-GRU 模型与GATM 模型的性能均有着显著的提升,当训练集大小超过0.25 时,RPAGRU 模型逐渐稳定,GATM 模型则是在训练集大小达到0.75 时逐渐稳定.
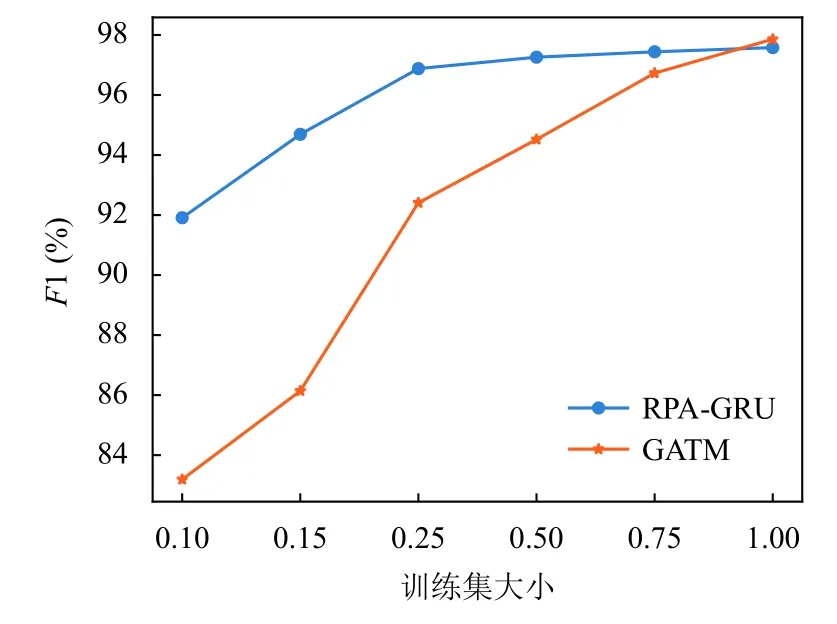
图9 不同训练集大小的模型性能
4 结论与展望
本文通过对可度量数量信息进行识别与关联完成对于可度量数量信息的抽取,分别提出了RPA-GRU模型与GATM 模型,其中RPA-GRU 模型将相对位置特征融入注意力机制,对上下文特征进行更新,有效地提高了模型的性能,达到了97.58%的F1 值.GATM模型则是以可度量数量信息中的实体为中心重构句法依存树并排除无关信息干扰,最终取得了97.86%的F1 值.与其他基线模型对比两个模型均取得了最优性能,证明了其有效性.此外,本文还对模型的稳定性进行了探究,结果证明RPA-GRU 模型与GATM 模型在对应的任务中具有稳定的性能.
