基于属性分割的差分隐私异构多属性数据发布①
2022-11-07张小玉沈国华
张小玉,沈国华,3,杨 阳
1(南京航空航天大学 计算机科学与技术学院,南京 211106)
2(南京航空航天大学 高安全系统的软件开发与验证技术工业和信息化部重点实验室,南京 211106)
3(南京大学 软件新技术与产业化协同创新中心,南京 210093)
1 引言
近年来,互联网应用的逐步普及,带来便利的同时,大量数据信息通过个人用户、企业单位、研究机构等源源不断地产生.对产生的数据进行数据分析,挖掘事物潜在的关联,再反馈给互联网应用商,可以为大众提供更好的服务.然而,这些数据中不乏个人隐私数据,诸如医疗信息、金融信息、轨迹数据等,直接向外界发布原始数据存在着巨大的隐私泄露风险.因此,对外发布数据时,需要采取一些隐私保护措施来保障数据安全.
K-匿名[1]及其相关扩展L-Diversity[2]、T-closeness[3]是隐私保护的重要方法,其主要思想是将待发布数据划分为多个等价类,等价类内的k个实体无法相互区分,通过限制数据发布实现数据隐私保护.然而,一旦攻击者具有相当的背景知识,K-匿名就无法提供很好的隐私保护效果,而且无法就其隐私保护程度进行定量分析.差分隐私[4-9]作为一种严格可证的新兴隐私保护模型,其前提是假设数据攻击者具有的背景知识最大化.通过向输出中添加随机扰动,尽可能减小单个记录对输出的影响,保证攻击者无法通过观察不同的输出结果重构真实的数据信息,实现了单个记录是否参与数据集的不可区分性.
从已有的研究可以看出,差分隐私在低维数据发布方面做了诸多努力,但在实际场景中,更为常见的却是多属性数据集,即高维数据集.如果将以往的低维数据发布算法直接应用于多属性数据发布,存在查询敏感度大、隐私预算消耗过快等问题,导致数据发布效用低.
针对高维数据发布场景,常见方法有: 1)根据树结构划分高维数据集,通过平衡分区的近似误差和数据的扰动误差来提高数据发布精度; 2)通过构建数据集的概率图模型计算属性间的条件分布,通过噪声条件分布近似原始数据集的联合分布,以此生成新的合成数据集,避免直接对原始数据扰动产生巨大的扰动误差; 3)利用数据降维技术,将高维数据转化成近似的低维数据,对转化后的低维数据添加噪声扰动,减少扰动噪声量.
在利用树结构发布高维数据集的研究中,文献[10]借助细粒度单元划分和kd-树划分两种分区策略,实现了差分隐私多维直方图发布.文献[11]利用kd-树和quad-tree 设计混合数据结构实现多维数据划分,从而减少了注入的噪声量.文献[12]提出了差分隐私泛化数据发布算法DiffGen,通过构建决策树的过程完成数据的差分隐私保护.基于概率图模型的研究也有所成果,文献[13]提出数据发布方案PrivBayes,该方案通过构建原始数据集的贝叶斯网络模型,分析原始数据属性之间的依赖关系,学习提取近似噪声条件分布,采样生成新的合成数据集.文献[14] 提出联合树算法Jtree,根据样本数据属性之间的关联构建依赖关系图,结合联合树的推理基础,从边缘关系图中学习一组噪声边缘表,以此近似原始数据集的联合分布.通过数据降维来近似高维数据发布的研究中,文献[15,16] 利用主成分分析技术识别高维数据的近似低维,实现了高维数据向低维的转化,并基于低维数据实现差分隐私保护.文献[17]提出了差分隐私数据发布算法DPPro,该算法利用随机投影技术,完成高维数据在低维上的映射,保证了高维数据发布效用.文献[18]提出PriView方法,通过构建一组含噪声扰动的低维View 视图,提取 α-边际分布,生成合成数据集.
然而,前文提到的各种方法对不同属性的隐私保护处理大多隐含地假设同构性,即不考虑属性数据敏感性的异构,不同属性的随机干扰程度均相同.由于不同属性携带的信息量不同,从而对攻击者推理目标对象隐私信息的贡献不同,即隐私泄露风险与属性敏感性呈正相关.例如,性别属性只有两个属性值,与年龄属性相比,携带的信息量更少,对目标对象的刻画程度较浅,对攻击者推理敏感信息的贡献较少,需要的隐私保护强度相对较低,相应的属性敏感性也就较低.不考虑属性信息量差异带来的敏感性异构,会导致没有充分保护高敏感属性数据,或者过度丢失低敏感属性数据的信息.
文献[19]提出了一种加权贝叶斯网络数据发布方法,虽然该方法是根据属性的多样性分配权重,但其目标是借助属性权重构建更好的贝叶斯网络.文献[20,21]均在基于贝叶斯网络的数据发布算法中引入属性聚类,以属性关联强弱分割属性集,在减少隐私预算分割次数的基础上提高算法计算效率.然而,两者在隐私预算的分配上依然采取等分措施,没有兼顾属性敏感性差异.
针对已有方法的不足之处,本文提出了一种基于属性分割的差分隐私异构多属性数据发布算法HMPriv-Bayes (heterogeneous multi-attribute private data publishing via Bayesian networks),主要贡献包括以下3 个方面:
1)根据属性之间的关联程度,引入最大信息系数量化属性之间的相关关系,设计满足差分隐私的谱聚类算法分割属性集,能在一定程度上缩减贝叶斯网络结构空间,提高算法计算效率.
2)针对构建贝叶斯网络随机选取首个属性可能降低数据发布质量的问题,以属性信息熵为权重选择属性,尽可能提高数据发布质量,保留数据实用价值.
3)考虑到属性携带的信息量的不同,基于贝叶斯网络提取属性条件分布时,以属性归一化风险熵为权重分配隐私预算,实现异构多属性保护.
2 基础知识
2.1 差分隐私
差分隐私(differential privacy,DP)保护模型保证在数据集中对一条记录进行增、删、改操作后,查询返回的扰动输出没有明显差异,以至于攻击者不能推断出目标记录是否在发布的数据集中,即数据集中单个记录对输出的影响有限,从而实现保护个体隐私.
定义1.ε-差分隐私[4].设D1和D2为任意两个相邻数据集,即它们彼此相差1 条记录,Range(M)是随机算法M的取值范围,若算法M在数据集D1和D2上的任意输出S∈Range(M),满足:
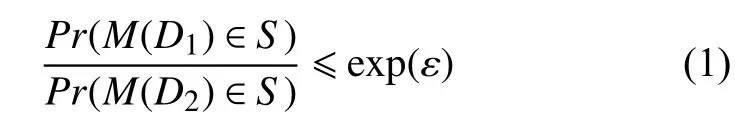
则称算法M满足ε-差分隐私.其中,隐私预算ε与隐私保护程度呈负相关,与隐私泄露风险呈正相关.Pr(M(D1)∈S)和Pr(M(D2)∈S)表示算法M在数据集D1和D2上输出为S的概率.
任何满足定义1 的噪音机制都可以视为差分隐私机制,差分隐私中常见噪音机制有Laplace 机制[22]和指数机制[23],其噪声扰动大小与随机函数的敏感度以及隐私预算参数密切相关.
定义2.全局敏感度[5].设查询函数f:D→Rn,f的全局敏感度定义如下:
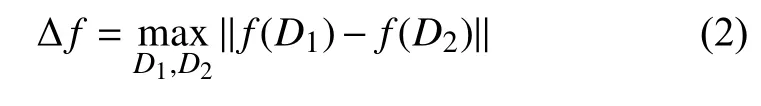
其中,D1和D2表示任意两个相邻数据集,全局敏感度Δf由查询函数f决定.
定义3.Laplace 机制[22].对任意数据集D和查询函数f:D→Rn,若算法M的输出结果满足:
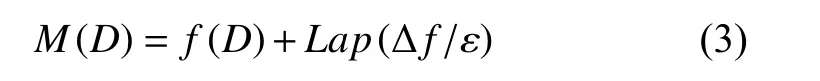
则算法M实现了ε-差分隐私.其中,Lap(Δf/ε)表示添加的噪声量,噪声量与 Δf成正比,与ε成反比.Laplace机制主要用于处理数值型数据.
定义4.指数机制[23].对任意数据集D,给定评分函数u:(D,r)→R,若算法M满足:
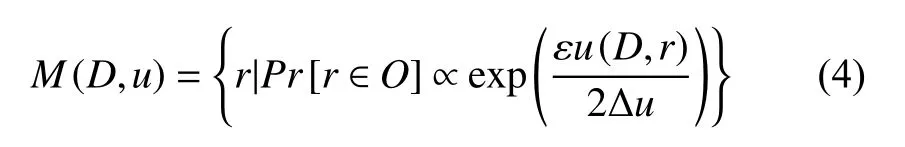
则算法M实现了ε-差分隐私.其中,Δu为u(D,r)的全局敏感度,Pr[r∈O]为评分函数u输出r的概率,评分越高,r被输出的概率越高.指数机制通常用于处理非数值型数据.
对于一组满足差分隐私的随机独立算法,差分隐私的串行组合性质和并行组合性质[24]可以用于证明整体算法满足差分隐私保护.
性质1.串行组合[24].给定数据集D和D上1 组随机独立算法M1(D),M2(D),···,Mm(D),其中每个算法Mi(D)满足εi-差分隐私,则M={M1,M2,···,Mm}满足-差分隐私.
串行组合表明,当一系列差分隐私机制应用于同一数据集时,隐私预算和噪声数量呈线性累积.
性质2.并行组合[24].给定数据集D,将D分割成m个互不相交的子集D={D1,D2,···,Dm}.每个子集中的随机独立算法M1(D1),···,Mm(Dm)均满足εi-差分隐私,则组合算法M={M1,M2,···,Mm}满足max(εi)-差分隐私.
并行组合表明,当一系列差分隐私机制应用于数据集的不同子集时,隐私保护的程度取决于 εi的最大值.
2.2 谱聚类
谱聚类(spectral clustering,SC)[25]是利用图论中的图分割完成数据聚类的算法.它的主要思想是先将数据集映射成一张带权无向图,基于两点之间的距离计算顶点相似度,通过最优划分准则分割图中结点,最大化子图内部的相似度,实现数据聚类.标准的谱聚类算法实现流程如算法1 所示.

算法1.谱聚类算法输入: 数据集,降维后的维度k1,聚类方法,簇数量k C(c1,c2,···,ck)D={x1,x2,···,xn}输出: 簇划分1.计算n×n 的相似矩阵S: ;wij=exp sij=‖xi-x j‖2)2.根据相似矩阵S 构建邻接矩阵W:(-sij 2σ2 3.计算n×n 的度矩阵B: ;bij=■■■■■■■■■∑dk=1 wik,i=j 0,i≠j L=B-1/2(B-W)B-1/2 4.计算并标准化拉普拉斯矩阵;5.计算L 最小的k1 个特征值以及各自对应的特征向量;6.将特征向量组成矩阵并按行进行标准化,最终组成n×k1 维的特征矩阵U;7.将U 中的每一行作为一个k1 维的样本,按照输入的聚类方式进行聚类,聚类维数为k;C(c1,c2,···,ck)u1,u2,···,uk1 8.返回簇划分.
在本文中,谱聚类主要用于属性聚类,即根据属性之间的关联程度分割属性集.本文选用最大信息系数(maximal information coefficient,MIC)[26]度量属性之间关联程度.在此之前,互信息是常用的属性关联度量手段,然而,互信息需要考虑连续属性的离散化,而且不同数据集上的互信息计算结果无法相互比较.MIC利用网格划分属性值域,结合属性互信息,可以更准确地识别出大数据集中属性间的线性或非线性关系,以及非函数依赖关系.
定义5.最大信息系数[26].给定属性X,Y和有序对<a,b>,样本数量为N,将当前二维空间在x,y方向上划分为a×b的网格G,将属性数据点离散落入网格G中,属性X和Y的最大信息系数计算如下:
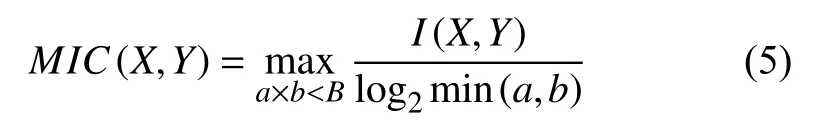
其中,B为网格划分a×b的上限值,通常取值N0.6或N0.55,I(X,Y)为属性X和Y的互信息值,具体计算如下:

其中,Pr(xi,yj)表示属性X,Y取值xi,yj的联合分布.
2.3 贝叶斯网络
贝叶斯网络(Bayesian network)是常用的概率图模型之一,用来表示一组随机变量(属性)之间的依赖关系.形式上,贝叶斯网络N可以表示为N=(G,θ).其中,G表示有向无环图,图中节点代表随机变量,节点之间的有向边代表随机变量之间的依赖关系.在G中,若存在一条从Xj到Xi的有向边,则称Xj为Xi的父节点.Xi的所有父节点构成Xi的父节点集合,表示为θ表示N的参数集合,θ包含每个节点Xi的条件分布,表示为对于一个包含属性集X={X1,X2,···,Xd}的贝叶斯网络N,N可以近似表示X的联合概率分布,具体为图1 表示包含属性节点{X1,X2,···,X5}的贝叶斯网络,图中所有属性节点的联合概率分布为Pr(X1,X2,X3,X4,X5)=Pr(X1)Pr(X2|X1)Pr(X3|X2)Pr(X4|X1,X2)Pr(X5|X3,X4).

图1 含5 个节点的贝叶斯网络示例
3 基于属性分割的差分隐私异构多属性数据发布
3.1 HMPrivBayes 算法概述
HMPrivBayes 算法的整体流程如图2 所示,包括4 个阶段: 属性聚类划分、构建差分隐私贝叶斯网络、生成属性加噪条件分布、生成待发布数据集.为了方便描述,本文假设所有属性均是二进制属性.对于非二进制属性,利用文献[13]提出的等宽法将非二进制属性转化成一组二进制属性.由于等宽法的转化过程只依赖非二进制属性的值域,且属性的值域是公开信息,不涉及隐私数据.因此,属性转化过程不存在隐私泄露问题.
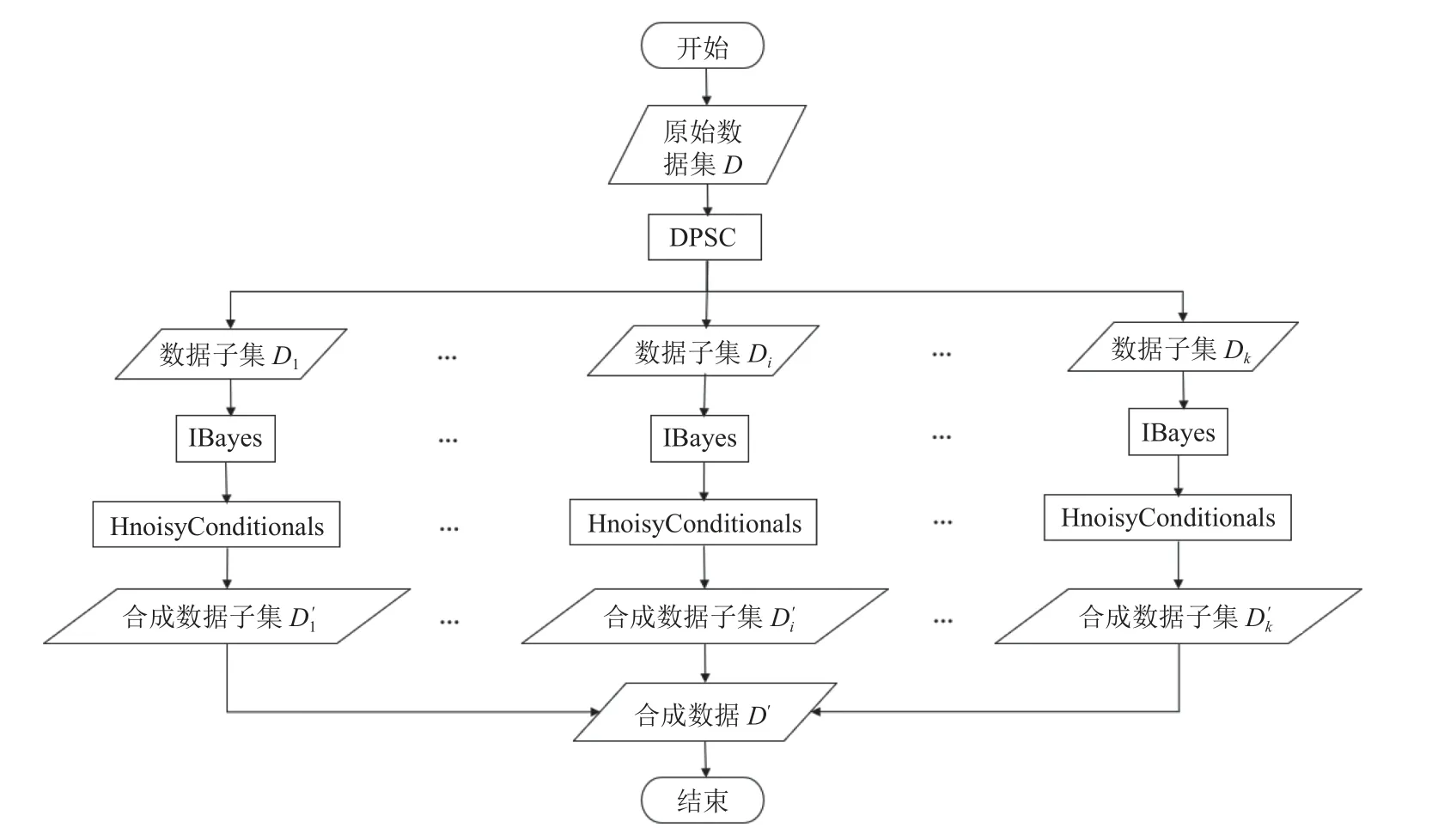
图2 HMPrivBayes 算法流程图
HMPrivBayes 算法的实现过程如算法2 所示.

算法2.HMPrivBayes 算法输入: 数据集,属性集,属性簇个数k,隐私预算ε输出: 数据集D 满足差分隐私的合成数据集D′D={x1,x2,···,xn}X={X1,X2,···,Xd}1.初始化D′= ;2.分配隐私预算ε1+ε2+ε3=ε;∅3.执行算法3,返回聚类结果;D={D1,···,Dk}C={C1,C2,···,Ck}4.依据C 划分原始数据集;5.for i=1 to k do执行算法4,求贝叶斯网络Ni;P*iD′i D′基于 计算Ni 的带噪联合分布,采样得到合成数据集 ,并加入 ;P*i执行算法5,求带噪条件分布 ;end for D′6.返回 .
3.2 差分隐私谱聚类算法
谱聚类算法是根据数据点之间相似性程度进行数据集聚类,对于关联程度不高的属性对,其相似值相应较小,从而分割至不同的子集.本文采用最大信息系数作为属性之间关联程度衡量指标,MIC 不仅能高效检测大数据集中不同类型属性之间关联关系,而且不需要进行归一化处理.选用K-means++聚类算法实现特征矩阵U的聚类划分,K-means++算法选择初始的聚类中心时,要求各聚类中心之间的相互距离要尽可能的远.初始点选择的优化,使得K-means++算法在聚类结果准确性上有较大提升.差分隐私谱聚类算法DPSC如算法3 所示.

算法3.DPSC 算法输入: 数据集,属性集,尺度参数 ,降维后的维度 ,聚类后的维度,隐私预算X C′={C1,C2,···,Ck}输出: 属性集 聚类划分结果D={x1,x2,···,xn}X={X1,X2,···,Xd}σ k1kε1(Δm·d(d-1)■■■■■■■■■)1.计算的相似矩阵:2.执行算法1 的步骤2-步骤6;d×dS sij=MIC(Xi,Xj)+Lap ,i≠j 0,i=j ε1·(2images/BZ_231_2132_2125_2223_2167.png);3.使用K-means++算法对新样本点进行聚类划分得到划分结果 ;C′={C1,C2,···,Ck}4.返回属性聚类结果.U={u1,u2,···,uk1}C
由于在计算属性关联程度时涉及到了原始数据集D的使用,为了保护数据集中的数据隐私不被泄露,采用Laplace 机制对计算结果添加噪声.
首先计算属性间的最大信息系数的全局敏感度Δm,由式(5)可知,MIC 的计算取决于属性间的互信息,故计算相似矩阵S的全局敏感度Δm=ΔI.由文献[13]可知,
从算法3 可以看出, Laplace 机制是通过多次扰动加噪过程实现的, 每次加噪都需要消耗部分隐私预算ε1. 由定义可知, 相似矩阵S是一个对称矩阵, 且对角线元素不需要计算, 所以计算d(d-1)/2个不同元素的值就可以得到矩阵S. 每次访问数据集D可以计算对属性对之间的MIC, 因此, 对数据集D的访问次数, 即扰动总次数为d(d-1)/(2), 每次扰动添加的噪声量为Lap((Δm·d(d-1))/(ε1·(2))). 由定义3 和性质1 可知, 算法3 满足 ε1-差分隐私.
3.3 差分隐私贝叶斯网络算法
在基于贝叶斯网络构建数据发布模型的现有研究中,大多以文献[13]中的PrivBayes 为参照进一步改进贝叶斯网络的构建设计发布算法[19-21].由于PrivBayes在构建贝叶斯网络时,随机选取首个属性加入父节点集合,这样构建的贝叶斯网络不一定能真实反映原始数据集.与此同时,通过枚举的方式选取互信息最大的对会造成大量无意义的计算,影响贝叶斯网络的构建速度.基于此,本文提出改进的贝叶斯网络构建算法IBayes,IBayes 引入信息熵作为选取首个属性的依据,同时缩减候选属性的对,以此达到快速构建“最合适”的贝叶斯网络的目的.IBayes 的实现过程如算法4 所示.

算法4.IBayes 算法输入: 数据子集,属性子集,最大父节点数,隐私预算DiNi Di={x1,x2,···,xn}Ci={X1,X2,···,X|Ci|}l ε2输出: 数据子集 的贝叶斯网络1.初始化,;CiXj(X j,∅)Ni X jV Ni=∅V=∅2.使用指数机制从 中选取信息熵最大的属性 ,将加入 ,将 加入 ;t=2 |Cı|3.for to do Ω=∅初始化;Xs∈CiV for V′=V令;S i(Xs,Xc)=0Xc∈V′If 且XcV′Πs∈■■■■■■■■V′将 从 中移除,且;(Xs,∏s)Ω将加入 ;l■■■■■■■■end for使用指数机制从 中选择互信息最大的加入 ,同时 加入 ;Ω(Xt,Πt)NiXtV end for 4.返回 .Ni
信息熵是对信息不确定性的度量,与信息的不确定性呈正相关.信息熵越大,携带的信息量越多,能更多地反映出数据的多样性,增加数据的实用价值,反之亦然.因此,引入信息熵作为选取首个属性的依据是合理的.
对于数据集Di中的每个属性Xj,其信息熵H(Xj)计算如下:
根据式(7)可知,当取不同值的概率相等时信息熵最大,即Xj中有n个不同的取值时H(Xj)取得最大值,为
通过图3 的实例可以说明属性信息熵的最大差异.
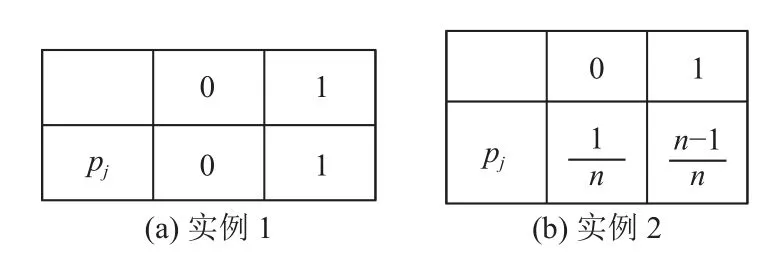
图3 信息熵差异实例
根据图3(a)取值概率分布计算H(Xj)的值为0,通过图3(b)计算H(Xj)的值为.在此基础上,可以得出属性信息熵的全局敏感度ΔH为:
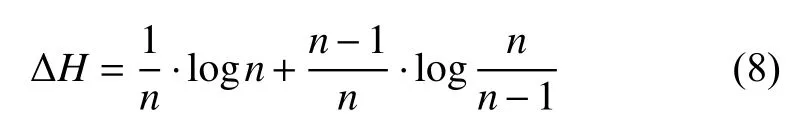
PrivBayes 通过枚举选择互信息最大的属性对时,候选对越多,对算法的时间复杂的影响越大.因此,本文在求解候选属性的父节点集时,筛选关联程度弱的属性对,减少对互信息的计算量.筛选操作通过关联矩阵Si实现.从相似矩阵S中提取出相关属性子集的最大信息系数,根据式(9)得到Si:
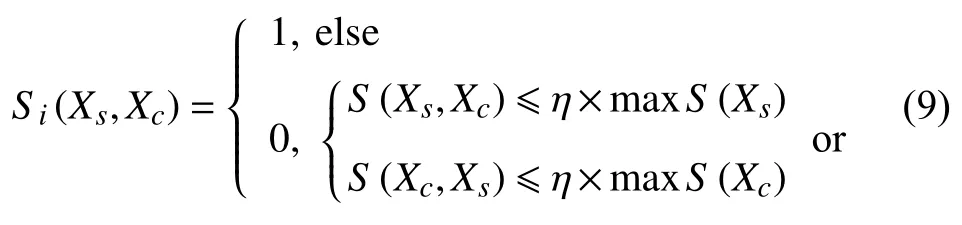
IBayes算法使用指数机制选取加入Ni中的首个属性节点,同时从 Ω中选择对加入Ni,评分函数分别采用属性信息熵和互信息.由于Δu=ΔI=ΔH,除选取加入Ni中的首个属性节点外,选择需要执行|Ci|-1次,故将 ε2平均分为|Ci|份.因此,结合差分隐私指数机制,选择的概率表达式如式(10):

IBayes 算法最终输出一个贝叶斯网络Ni,除了使用指数机制选取首个属性节点和对之外,其他步骤均无需访问原始数据集D.在构建贝叶斯网络之前,HMPrivBayes 算法已经通过算法3 将原始数据集D划分为k个独立数据子集D1,···,Dk.根据定义4 和性质1,指数机制exp(ε2u(Di,r)/(2|Ci|Δu))满足 ε2-差分隐私,因此IBayes 算法满足 ε2-差分隐私.
3.4 差分隐私异构条件分布计算
通过贝叶斯网络计算属性的联合分布,生成合成数据集,可以近似原始数据集.尽管贝叶斯网络的构建过程满足差分隐私保护,但仍存在隐私泄露的可能.因此,需要对计算出来的属性联合分布添加噪声扰动,以进一步保护隐私数据.之前的研究均通过均分隐私预算实现联合分布噪声扰动,这种方式没有考虑到属性敏感性差异.属性携带的信息量越多,帮助攻击者推出目标信息的贡献越大,也就意味着它对外发布的敏感性越高.基于此,本文提出差分隐私异构条件分布计算算法HnoisyConditionals,具体实现过程如算法5所示.

算法5.HnoisyConditionals 算法输入: 数据集,贝叶斯网络 ,隐私预算NiP*i输出: 根据 生成的带噪声的条件分布集Di={x1,x2,···,xn}Niε3 P*i=∅l′=min(|Ci|-1,d)1.初始化,令;j=l′+1 |Ci|2.for to do X jPr(X j,∏)构建 的联合分布;j■■■■■■■■■■2 Lap∑|Ci|j=l′+1 exp(-OE j)■■■■■■■■■■nε3×加入拉普拉斯噪声,实现差分隐私;Pr*(X j,∏j)Pr*(X j,∏)exp(-OE j)j中的负值归0 并正常化;Pr*(X j,∏j)Pr*(X j|∏j)P*i从中提取并加入 ;设end for j=1l′3.for to do Pr*(Xl′+1,∏l′+1)Pr*(X j|∏j)P*i从中提取加入 ;end for P*i 4.返回 .
根据式(7),归一化风险熵计算公式如下:
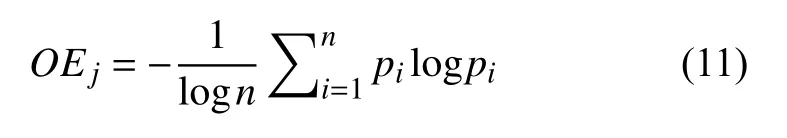
在算法5 中,向联合分布注入噪声不再采取均分策略,而是以归一化风险熵为权重分配隐私预算.由文献[13]可知,联合分布全局敏感度为 2/n.因此,每次对联合分布添加的拉普拉斯噪声大小为:
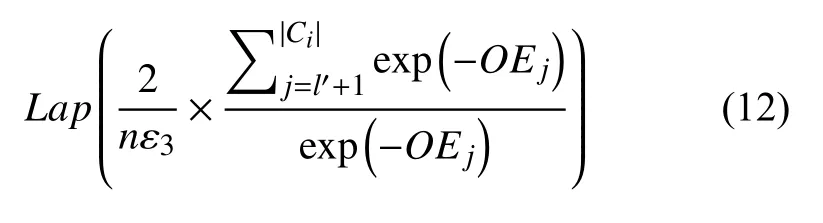
其中,属性归一化风险熵OEj越大,属性敏感性越高,需要的隐私保护强度越大,分配的隐私预算也就越小.由定义3 和性质1 可知,算法5 满足 ε3-差分隐私.
3.5 隐私分析
定理1.HMPrivBayes 算法满足ε-差分隐私.
证明: 在HMPrivBayes 的整个执行过程中,其中有3 步涉及原始数据集的访问,分别是属性分割、构建差分隐私贝叶斯网络和提取属性噪声条件分布,下面分别讨论这3 步的隐私保护强度.
对于属性分割,需要重复访问数据集D计算属性对的MIC,每次访问数据集D可以计算对属性对的MIC,相似矩阵S中有d(d-1)/2个不同的MIC 值需要计算,因此,需访问d(d-1)/(2)次数据集D.MIC计算的敏感度为Δm,故每次扰动添加的噪声量为Lap((Δm·d(d-1))/(ε1·(2))),进而属性分割满足ε1-差分隐私.
在贝叶斯网络构建阶段,需要借助指数机制exp(ε2H(Xj)/(2|Ci|ΔH))从数据子集Di中选取加入Ni的首个属性节点.指数机制用于选择互信息最大的对加入Ni,执行|Ci|-1次,因此贝叶斯网络构建满足 ε2-差分隐私.
从贝叶斯网络Ni中提取属性条件分布时,需要往|Ci|-l′个属性联合分布中添加噪声扰动,进一步保护数据隐私.为了兼顾属性敏感性的差异,隐私预算根据属性Xj的归一化风险熵OEj异构分配,添加的噪声量为,其中联合分布计算的敏感度为 2/n.因此,属性条件分布计算满足 ε3-差分隐私.
综上,HMPrivBayes 算法满足 ε-差分隐私,其中ε1+ε2+ε3=ε.
4 实验评估
4.1 实验设置
本次实验使用Python 编程语言来实现所有的方法,其中贝叶斯网络模型部分的实现参考了Zhang 等人[13]论文的实验相关代码.实验的硬件环境为AMD Ryzen7 4800H (2.90 GHz),操作系统为Windows 10(64 位),内存为16 GB.
实验采用两个公开可用的数据集Adult[27]和Big5[28].其中,Adult 为美国人口普查数据集,包含45 222 条个体信息记录,每条记录包含15 个属性.Big5是包含19 719条人口普查记录的信息集合,每条记录包含57 个属性.利用等宽法完成属性转化后,二进制属性的数量分别为52 和175.两个数据集的详细信息如表1 所示.

表1 数据集属性信息描述
对于这两个数据集,隐私预算分配策略为ε1=a1/aε,ε2=a2/aε,ε3=a3/aε,其中a=a1+a2+a3,属性分类簇个数k默认值为3,贝叶斯网络的最大入度数l默认值为3.
4.2 评价指标
本文通过 α-边际分布[29]和SVM (support vector machine)分类[30]来评估算法的性能.实验选取2-边际分布和3-边际分布作为 α-边际分布评估的实例,通过计算生成的噪声边际分布和原始边际分布的平均变量距离(average variation distance,AVD)[31]确性.L1距离的一半:
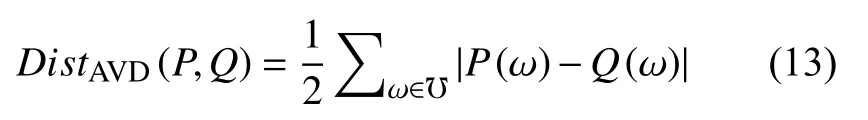
其中,P(ω)和Q(ω)分别表示加噪前后的边际分布,℧表示边际分布集合.
实验通过度量SVM 分类的准确性,分析生成的噪声数据集的有效性.本组实验在噪声数据集上同时训练2 个分类器,通过分析合成数据集的其他属性预测目标属性的分类结果.对于Adult 数据集,选取salary作为分类实例,预测个体每年收入是否超过50k.对于Big5 数据集,选取age 作为分类实例,预测个体年龄是否在50 岁以下.每个分类任务,将合成数据集按照8:2 分为训练数据集和测试数据集,重复运行50 次,并记录实验结果的平均值.
4.3 实验结果
本文将通过3 个不同的实验来分析HMPrivBayes算法的可用性和高效性.为了更好地评估HMPrivBayes方案的性能,本节采用的对比算法包括: PrivSCBN、PrivBayes、Jtree、NoPrivacy.其中,PrivSCBN 算法[20]、PrivBayes 算法[13]均是基于贝叶斯网络的数据发布算法,Jtree[14]是基于联合树的数据发布算法,NoPrivacy是HMPrivBayes 不添加噪声扰动的数据发布情况.
第1 个实验是为了验证HMPrivBayes 算法的安全性,比较在不同记录数量下,敏感属性隐私泄露的可能性.在Adult 数据集原有的45 222 条记录的基础上,随机产生54 778 条记录,生成包含100 000 条记录的数据集,并将salary 作为敏感属性.由于隐私预算ε不是该实验关心的变量,故将ε固定为0.2.实验结果如图4 所示,从图中可以看出,随着记录数的增加隐私泄露概率逐渐下降,即攻击者根据其他属性信息推断出salary 属性值的概率逐渐下降,而且HMPrivBayes算法安全性高于PrivBayes 算法和PrivSCBN 算法.这是因为,HMPrivBayes 算法根据属性敏感性决定隐私预算分配大小,能对多属性数据发布提供更安全的隐私保护.
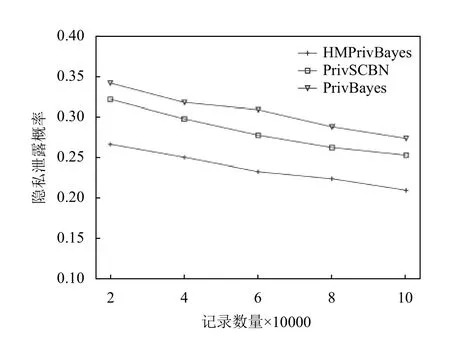
图4 数据安全性分析
第2 个实验是对HMPrivBayes 算法数据性能的分析,图5(a)-图5(d)分别对比了在不同ε取值下,算法HMPrivBayes、PrivSCBN、PrivBayes、Jtree 的合成数据集的边际分布与原始数据集边际分布之间AVD 的变化.图5(e)-图5(f)显示了算法HMPrivBayes、PrivSCBN、PrivBayes、Jtree 的合成数据集训练2 个分类器的误分类率在不同ε取值下的变化趋势.

图5 算法HMPrivBayes、PrivSCBN、PrivBayes、Jtree 在不同隐私预算下的性能分析
可以看出,对于NoPrivacy,边际分布之间的AVD和分类器的误分类率均与隐私预算 ε的取值无关,且NoPrivacy 的性能均优于其他方法的性能.随着隐私预算ε取值的增大,隐私保护强度下降,合成数据的两项指标越来越接近NoPrivacy 的情况,这符合差分隐私的规律.在多数情况下,HMPrivBayes 的性能均优于PrivSCBN、PrivBayes、Jtree 的性能,仅当隐私预算ε足够大时,HMPrivBayes 与PrivSCBN 性能趋于接近.这说明本文提出的各种贝叶斯网络改进策略以及异构属性发布策略是有效的.
第3 个实验是对HMPrivBayes 算法计算效率的分析,比较在贝叶斯网络不同最大入度数l下,算法的整体运行时间.由于隐私预算ε不是该实验关心的变量,故将ε固定为0.2.实验结果如图6 所示,随着最大入度数l的增加,整体运行时间大幅上升.比较图6(a)-图6(b)可以看出,随着属性数目的增加,算法整体运行时间也大幅增加.不过,HMPrivBayes 的运行时间远低于PrivBayes 算法,而且属性越多,两者运行时间的差距越大,这说明HMPrivBayes 的效率得到了较好的提升.效率的提升一方面在于,HMPrivBayes 利用聚类算法分割属性集,缩减了单个贝叶斯网络的节点空间; 另一方面在于,借助属性关联强度,缩减了候选属性对集合.
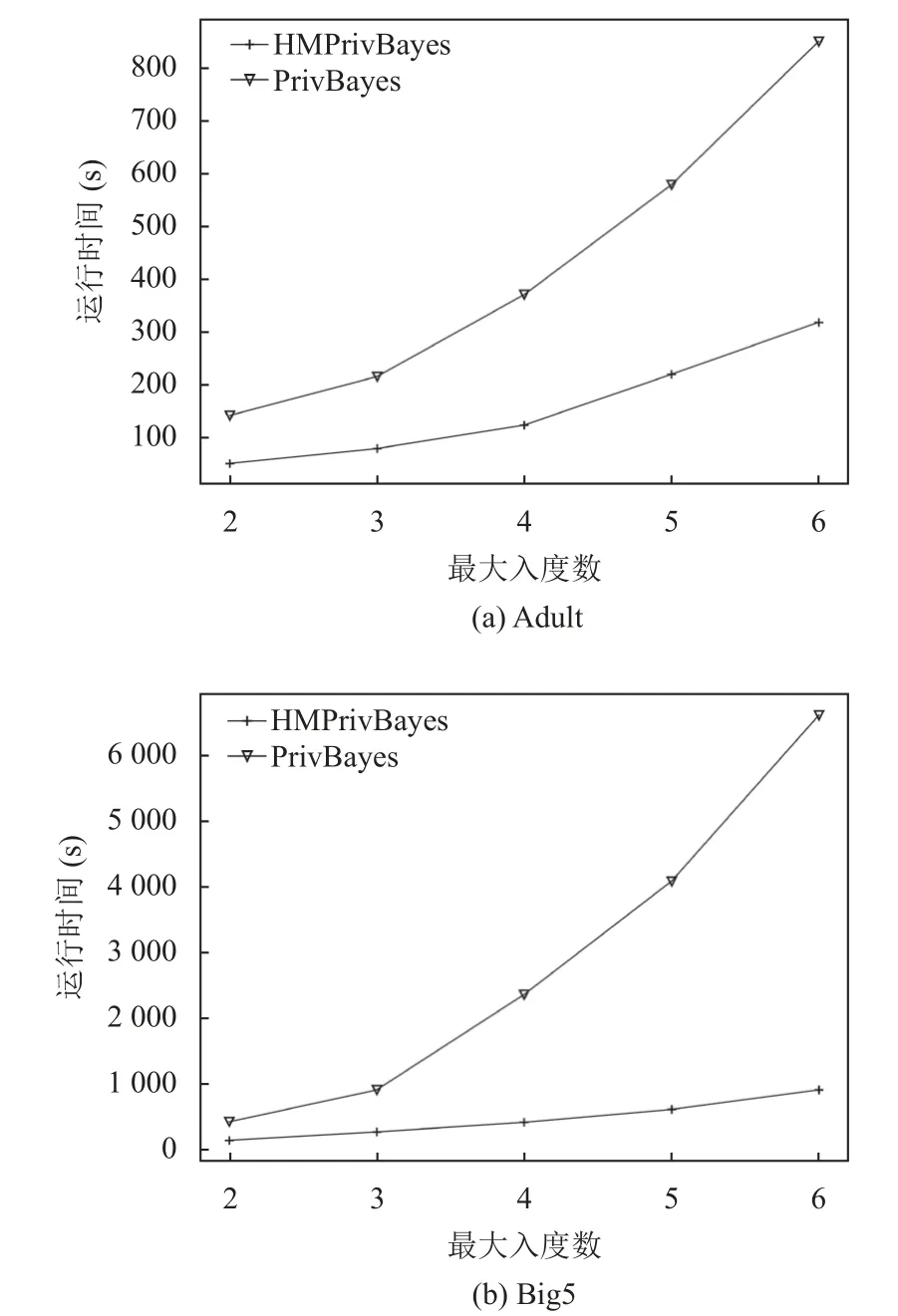
图6 算法运行时间分析
5 结束语
针对差分隐私异构多属性数据发布问题,本文提出了一种基于属性分割的异构多属性数据差分隐私发布方法HMPrivBayes.与已有多属性数据发布算法不同的是,HMPrivBayes 基于属性敏感性差异给予属性数据相对应的隐私保护强度,避免了多属性数据隐私保护不均匀的问题,进而提高数据可用性.与此同时,该方法通过引入属性分割、改进贝叶斯构建过程等都实现了算法整体计算效率的提升.在不破坏属性关联的前提下,以属性归一化风险熵为权重分配隐私预算,实现异构多属性数据发布.理论证明,HMPrivBayes 满足ε-差分隐私.实验结果表明,HMPrivBayes 方法在提升算法整体计算效率的基础上,保证了数据发布的可用性在未来的研究中,我们将考虑基于差分隐私的分布式异构多属性数据发布,即如何在多方设置中实现异构多属性数据发布.
