提升联邦学习通信效率的梯度压缩算法①
2022-11-07田金箫
田金箫
(西南交通大学 计算机与人工智能学院,成都 611756)
1 引言
近年来,随着人工智能技术的快速发展和广泛应用,数据隐私保护也得到了密切关注.欧盟出台了首个关于数据隐私保护的法案《通用数据保护条例》(General Data Protection Regulation,GDPR)[1],明确了对数据隐私保护的若干规定.中国自2017年起实施的《中华人民共和国网络安全法》和《中华人民共和国民法总则》中也对用户隐私数据的使用做出了明确的规定.在机器学习中,模型的好坏很大程度上依托于建模的数据.但由于相关法律法规的限制,数据孤岛问题变得十分普遍,导致企业很难获取训练数据.为此,谷歌在2016年提出了联邦学习的概念.联邦学习是一种基于分布式机器学习的框架,在这种框架中,多个客户端在中央服务器的协调下共同训练模型,并保证训练数据可以保留在本地,不需要像传统的机器学习方法一样将数据上传至中央服务器[2],从而保护了用户隐私.
构建一个高性能的联邦模型通常需要多轮通信,同时规模庞大的神经网络模型,往往包含数百万个参数[3],这导致了巨大的通信开销.此外,相较于传统的分布式机器学习,联邦学习还面临如下问题:
1)客户端数据非独立同分布: 在传统分布式机器学习中的训练数据随机均匀地分布在客户端上[4],即遵循独立同分布(independent and identically distributed,IID).这在联邦学习中通常是不成立的,由于用户的喜好不同,客户端的数据通常是非独立同分布(non-IID)的.即客户端拥有的局部数据集不能代表整体数据的分布,不同客户端之间的数据分布也不同.
2)数据不平衡: 不同的客户端可能拥有不同的数据量.
3)客户端数量庞大且不可靠: 参与训练的客户端为大量的移动设备,通常大部分客户端经常离线或者处于不可靠的连接上,因此无法确保客户端参与每一轮的训练.
本文主要研究联邦学习中的通信效率问题,利用梯度稀疏化的思想减少客户端与服务器之间通信的参数量,并在服务器聚合时使用投影的方式缓解非独立同分布数据带来的影响.经过在MNIST 和CIFAR10数据集上的实验证明,本文提出的算法能够在联邦学习的约束条件下高效训练模型.
2 相关工作
一般来说,减少联邦学习中的通信开销有两种策略,一种是减少训练过程中的通信轮次,另一种是减少每轮传递的通信量.减少通信轮次的经典方案是联邦学习中最常用的FedAvg 算法[2],即令客户端在本地执行多轮本地更新,服务器再进行全局聚合,来减少通信轮数.FedAvg 在每次通信中,客户端需要上传或下载整个模型,由于联邦客户端通常运行在缓慢且不可靠的网络连接上,这一要求使得使用FedAvg 训练大型模型变得困难.在实际应用中,FedAvg 算法可以较好地处理非凸问题,但该算法不能很好处理联邦学习中数据non-IID 的情况,在此应用场景很可能导致模型不收敛[5].因此针对non-IID 场景,Briggs 等[6]在FedAvg的基础上引入层次聚类技术,根据局部更新与全局模型的相似度对客户端进行聚类和分离,以减少总通信轮数.此外Karimireddy 等[7]通过估计服务器与客户端更新方向的差异来修正客户端本地更新的方向,有效地克服了non-IID 问题,能在较少的通信轮次达到收敛.
另一类方法的核心思想在于减少传输的数据量,主要通过量化、稀疏化等一系列方法对模型参数或者梯度进行压缩.量化通过将元素低精度表示或者映射到预定义的一组码字来减少梯度张量中每个元素的位数,例如Dettmers[8]将梯度的32 位浮点数量化至8 位,SignSGD[9-11]则只保留梯度的符号来更新模型,将负梯度量化为-1,其余量化为1,实现了32 倍的压缩.稀疏化方法通过只上传部分重要的梯度来进行全局模型的更新,如何选择这些梯度成为该方法的关键.Strom[12]提出使用梯度的大小来衡量其重要性,通过预先设立阈值,当梯度大于该阈值时对其进行上传.然而在实际情况中,由于不同的网络结构参数分布差异较大,导致我们无法选择合适的阈值.因此目前稀疏化方法通常使用Aji 等[13]提出的固定稀疏率,每次传递一定比例的最大梯度或每次传递前k个最大梯度的Topk 方法[14].上述工作有效地解决了分布式机器学习中的通信开销问题,针对联邦学习的训练环境,Rothchild 等[15]使用了一种特殊的数据结构计数草图(count sketch)对客户端梯度进行压缩.Chen 等[16]将神经网络的不同层分为浅层和深层,并认为深层参数更新频率低于浅层参数,因此提出了异步更新策略,有效减少了每轮传递的参数量.Haddadpour 等[17]在FedAvg 的基础上对每轮传递的参数进行压缩,并针对non-IID 场景采用梯度跟踪技术对客户端梯度方向进行修正,在收敛速度和准确率上都取得了较好的效果.
Sattler 等[18]也针对联邦学习的训练环境提出了稀疏三元压缩(sparse ternary compression,STC),该方法在Topk 梯度稀疏化的基础上进行了量化进一步减少了通信量,并利用错误反馈机制实现了客户端与服务器之间的双向压缩,在联邦学习场景中表现出了良好的效果.该方法考虑了联邦学习中客户端non-IID数据的场景,通过利用稀疏的特性以及减少本地训练次数与服务器端频繁通信去减轻non-IID 数据带来的问题,但该方法对non-IID 数据的优化能力有限.因此本文将在稀疏三元压缩算法的基础上,关注non-IID下的联邦场景,提升联邦学习的通信效率.
3 算法设计
3.1 稀疏三元压缩
常规的Topk 稀疏方法以全精度传递稀疏元素,Sattler 等[19]证明了当稀疏化与非零元素的量化相结合时,可以获得更高的压缩增益.如算法1 所示,当获得Topk 稀疏元素Tmasked后,会将其量化为稀疏元素的平均值,因此最后只需要传递一个包含值{-μ,0,μ}的三元张量.如果将每一层的梯度看做一个矩阵,那么使用Topk 和稀疏三元压缩后得到的结果如图1 所示,原始梯度是一个稠密矩阵,颜色深浅代表值的大小,通过Topk 方法会得到一个保留较大值的稀疏矩阵,值较小的则置为0,而稀疏三元压缩则在Topk 的基础上做了量化,进一步提升了压缩率.
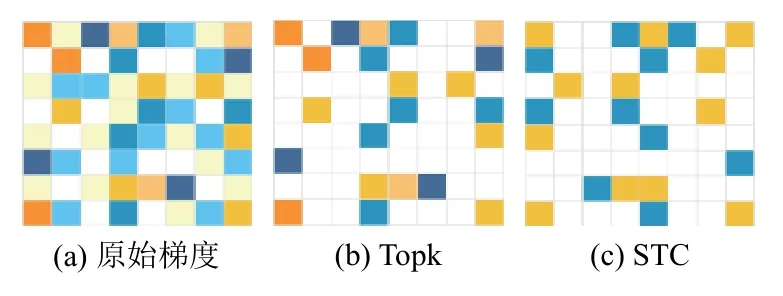
图1 梯度压缩效果

算法1.STC[18]: 稀疏三元压缩算法T∈Rn输入: 张量,稀疏率p 1.v←topk(|T|)k←max(np,1)2.mask←(|T|≥v)∈{0,1}n 3.Tmasked←mask⊙T 4.μ←1∑ni=1|Tmaskedi|5.T*←μ×sign(Tmasked)6.输出k
Sattler 等[18]在联邦学习中使用稀疏三元压缩对客户端和服务器之间通信的梯度进行双向压缩,并结合错误反馈机制[20]在客户端和服务器保留压缩前后的误差累加至下一轮训练过程.

其中,gti为第i个客户端第t轮训练得到的原始梯度,为压缩后的梯度,errort为压缩前后的误差.该方法取得了与非压缩算法相似的收敛速度并大大减少了每一轮的通信量,因此本文也将使用稀疏三元压缩方法进行梯度压缩.
3.2 Non-IID 数据的处理
目前在联邦学习中,我们通常采用平均各个客户端梯度的方法计算全局模型.当不同客户端数据满足IID 条件时,各客户端梯度更新方向相近,且聚合后梯度与基于传统的集中式学习获得的梯度相似性较高.故此方法能获得全局目标函数的最优解.若客户端数据non-IID 且数据量差异较大,各客户端梯度差异性较大,存在相互干扰的情况,导致全局模型收敛速率降低.同时,简单平均各方梯度易使数据量多的客户端占主导作用,使得全局模型无法较好地处理数据量较少的客户端,最终导致全局模型整体性能低下.
Wang 等[21]提出使用梯度投影处理non-IID 数据的问题,服务器端在进行梯度平均之前,通过修改梯度方向减轻non-IID 数据带来的影响.该方法首先对客户端之间的梯度冲突做出定义,当客户端i的梯度gi和客户端j的梯度gj满足gi·gj<0时,则称为客户端i和客户端j之间存在梯度冲突.当客户端之间存在梯度冲突时,梯度方向差异性较大,这时可以通过将一个客户端的梯度投影到另一个有冲突的客户端梯度平面上,使用原梯度减去投影来缩小客户端之间的梯度差异,如式(3)所示:
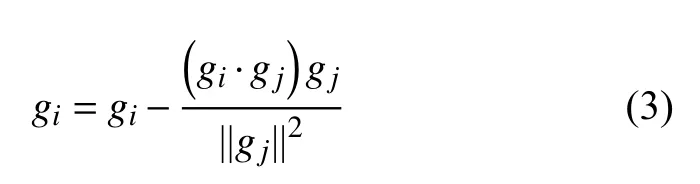
此外,该方法定义了内部冲突和外部冲突,分别对其进行投影处理.将参与训练的客户端之间的梯度冲突定义为内部冲突,将客户端梯度按照训练损失从小到大排序得到并引入参数 α来控制每轮参与投影的客户端数目.从POt中选择损失较小的客户端Sαt迭代的判断与其他客户端之间的梯度冲突,并进行投影修改梯度方向以缓解内部冲突.对于未选择的损失较大的客户端则保持原有的梯度,此后进行梯度平均得到聚合后的梯度gt,如算法2 所示.
在实际联邦场景中,客户端non-IID 程度较大,在每轮聚合中,若对所有客户端统一采用投影方案,则导致训练损失大的客户端的梯度方向不断靠近损失小的客户端.这将导致聚合模型无法学习到所有客户端的信息.但通过调整参数 α,自适应地让部分训练损失较大的客户端直接参与最终的聚合阶段,有效地缓解了上述问题.

算法2.MitigateInternalConflict[21]: 缓解内部冲突算法输入: 客户端梯度投影顺序,参数POtα POtS1-αtα 1.服务器从选择损失较小的客户集合参与投影,保留 比例损失较大的客户端梯度k∈S1-α t 2.for each client in parallel do gpc k ←gtk 3.gti∈POti=1,···,m 4.for each ,do k ·gti<0k≠i 5.if and then gPC||gti||2 gti 6.投影修正客户端梯度:gPC k ←gPCk -(gti)·gPC k 7.end if 8.end for 9.end for ∑mk=1 gPCk 10.计算聚合梯度:gt←1 m 11.返回聚合梯度gt
由于联邦学习中客户端的部分参与和不可靠连接,在第t轮未被选中参与训练的客户端可能会遭受被全局模型遗忘的风险, 因此可以在服务端保留其最近一次参与训练的梯度根据它们的近邻历史梯度来估计真实梯度以避免客户端被遗忘, 如算法3 第6 步所示.第t轮未被选中客户端的估计梯度gcon与参与更新的客户端平均后的梯度gt之间的冲突称为外部冲突, 通过将gt迭代的投影到不同轮次的估计梯度gcon的法平面以缓解外部冲突, 通过参数τ控制投影的轮次. 具体步骤如算法3 所示.

算法3.MitigateExternalConflict[21]: 缓解外部冲突算法gtGHτ输入:聚合梯度 ,所有客户端近邻历史梯度,参数1.for round do gcon←0 t-i,i=τ,τ-1,···,1 2.初始化估计梯度:k=1,2,···,K 3.for each client do tk=t-i 4.if then gt·gtkk <0 5.if then gcon←gcon+gtkk 6.计算未被选中客户端的估计梯度:7.end if 8.end if 9.end for gt·gcon<0 10.if then 11.对聚合梯度投影修正:12.end if 13.end for gt 14.返回聚合梯度gt←gt- gt·gcon||gcon||2 gcon
3.3 基于投影聚合的稀疏三元压缩算法
鉴于投影能够有效地处理联邦学习中的non-IID数据问题,因此本文将在稀疏三元压缩的基础上,在服务器端使用投影聚合的方式,进一步提高模型的正确率与收敛速度,具体步骤如算法4 所示.
服务器端接收到客户端梯度与训练损失后,首先在算法第14 行更新每个客户端最近一次参与训练的梯度以便在缓解外部冲突时使用,其中K是所有客户端个数,tK是客户端最近一次参与训练的轮次.之后在第15 行根据训练损失的大小对本轮参与训练的客户端梯度进行排序得到其中m是本轮参与训练的客户端个数.然后依次根据算法2 中的缓解内部冲突算法和算法3 中的缓解外部冲突算法得到聚合梯度gt.算法2 和算法3 的主要作用是对聚合梯度gt的方向进行修正以缓解non-IID 问题,因此在第20 行中,保留修正后的聚合梯度gt的方向与原始聚合梯度的大小得到最终的聚合梯度.最后使用与客户端相同的STC 压缩算法压缩聚合梯度并发送至客户端.

算法4.基于投影聚合的稀疏三元压缩算法输入: 初始化模型w 1.for do 2.服务器从K 个客户端随机选取m 个客户端参与训练i=1,···,m t=1,···,T 3.for in parallel do Ci 4.客户端 :5.从服务器端下载聚合梯度wti←wt-1i -g¯g 6.)-wti 7.gti←S TC(gti+errort-1,p)8.errort=gti-ˆgti 9.ˆgtilti 10.上传客户端梯度 和训练损失至服务器11.end for 12.服务器器端:ˆgtilti 13.接收参与训练的客户端梯度 和训练损失gti←SGD(wti,Datai

GH={ˆgt11 ,ˆgt22 ,···,ˆgtKK 14.更新所有客户端近邻历史梯度信息:POt={ˆgt1,ˆgt2,···,ˆgtm}15.根据客户端训练损失对梯度排序:gt←MitigateInternalCon flict(POt,α)16.缓解内部冲突:t≥τ}17.if then gt←MitigateExternalCon flict(gt,GH,τ)18.缓解外部冲突:19.end if gt=gt/||gt||*|| 1∑mi ˆgti||20.m g=S TC(gt+error,p)21.22.error=gt-g 23.发送聚合梯度 至客户端24.end for g
算法4 中的步骤可简化为图2,在客户端,首先接收聚合梯度,然后根据模型和客户端数据进行本地训练得到客户端梯度,本地训练完成后使用STC 算法压缩梯度上传至服务器,并计算压缩误差存储在本地,在下一轮被选中训练时进行梯度修正.

图2 基于投影聚合的稀疏三元压缩算法流程
服务端接收到所有参与训练的客户端发送的梯度后判断客户端梯度之间是否存在梯度冲突,并依次通过缓解内部冲突和外部冲突的算法对梯度方向进行修正.最终聚合投影后的梯度生成全局梯度gt,采用STC 算法压缩全局梯度gt得到发送至客户端.该算法实现了客户端与服务器之间的双向压缩,并且在服务器端进行投影缓解数据异构的问题.
4 实验分析
4.1 实验设置
本文的实验使用了MNIST 和CIFAR10 数据集.MNIST 数据集包含60 000 张训练图片,10 000 张测试图片,每张图片是2 828 的灰度手写数字图像,实验使用带有3 个卷积层的CNN 模型对MNIST 进行训练.CIFAR10 数据集包含50 000 张训练图片,10 000 张测试图片,每张图片是3 232 的RGB 图像,使用文献[18]中简化的VGG11 网络进行训练.客户端数据集划分参照文献[2],首先按照数据集的类别进行排序,然后将数据集划分为200 个分片,每个客户端随机选择两个不会替换的分片来模拟客户端数据非独立同分布的场景.实验中部分参数设置如表1 所示.

表1 参数设置
4.2 实验结果
我们将本文提出的算法与FedAvg 以及稀疏三元压缩算法进行了对比,图3 和图4 是在MNIST 数据集上的结果,图3 是全局模型在所有客户端上的平均测试准确率,图4 为测试准确率的方差,其中稀疏三元压缩以及本文提出的算法在实验中设置了0.1 的稀疏率,也就是每轮传递10%的参数进行训练,根据图1 的实验结果可以看到本文提出的算法相较于其他算法收敛速度和收敛精度都略有提升,特别是相较于STC 算法,在相同压缩率的条件下本文提出的算法大约在第75 轮收敛,而STC 算法在训练过程非常震荡,并且在大约100 轮才收敛.
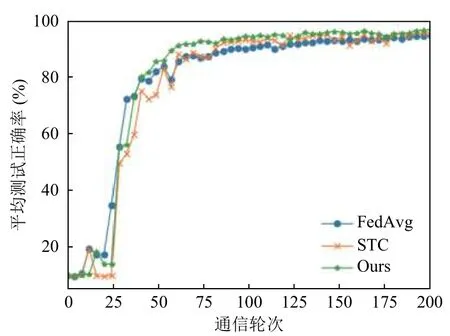
图3 MNISTS 数据集测试正确率
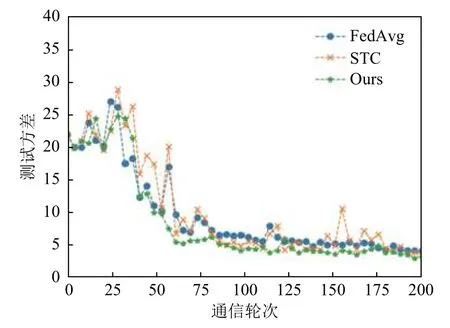
图4 MNISTS 数据集测试方差
图5 和图6 是在CIFAR10 数据集上的测试准确率和测试方差,稀疏率同样为0.1,与MNIST 数据集相比,在CIFAR10 数据集上的训练过程更加震荡,但是本文提出的算法相较其他算法收敛速度和收敛精度都有大幅度提升,并且训练过程中的震荡幅度远远小于FedAvg 和STC 算法,这说明本文的算法是非常有效的.

图5 CIFAR10 数据集平均测试正确率

图6 CIFAR10 数据集测试方差
表2 中记录了客户端与服务器之间每轮通信的参数大小,通信轮次是达到固定正确率(MNIST 95%CIFAR10 50% )大约所用的通信轮数,以FedAvg 作为基线算法,本文提出的算法在上传和下载时都进行了压缩,在MNIST 数据集上相较于FedAvg 每轮的通信量减少了45 倍,并且本文的算法在第100 轮时就达到了指定的正确率,相较于FedAvg 和STC 分别减少了97 和57 个通信轮次,在CIFAR10 数据集上每轮的通信量更是减少了47 倍,通信轮次相较于FedAvg 和STC 减少了295 轮和300 轮.
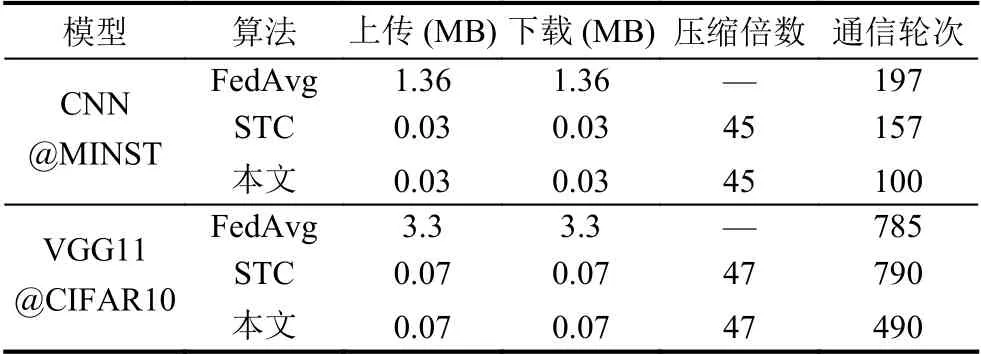
表2 通信开销计算
5 结论
本文提出了基于投影聚合的稀疏三元压缩算法,提升联邦学习的通信效率.该算法在客户端和服务端采用稀疏三元压缩减少客户端在每一轮训练过程中上传和下载的通信量,同时在服务器端利用梯度投影的方式缓解了由于客户端数据异构以及部分参与导致的梯度冲突问题.通过在MNIST 和CIFAR10 数据集上的实验验证,本文提出的算法在通信量、收敛速度和正确率3 个方面都要由于传统的FedAvg 算法和稀疏三元压缩算法.由于梯度压缩会略微改变原始梯度的方向,在未来我们将针对不同的压缩方法对投影聚合的方式做进一步的研究,进一步提高算法的有效性.
