基于改进FA算法的河流突发水污染事件溯源①
2022-11-07赵栋梁周晓磊窦志强
赵栋梁,周晓磊,窦志强,武 暕
1(中国科学院大学,北京 100049)
2(中国科学院 沈阳计算技术研究所,沈阳 110168)
3(辽宁省生态环境监测中心,沈阳 110161)
河流突发水污染事件会对河流下游区域的生态系统造成破坏,并且随污染排放时间增加,污染扩散面积逐渐扩大,对人民群众以及生态环境的影响逐渐加大,因此河流突发水污染事件的第一要素是确定污染源位置[1].本文主要通过研究污染物在河流中的扩散规律,并通过监测站所观测到的污染物浓度变化对污染物排放的位置、时间、质量进行溯源[2],从而还原污染物排放的变化过程,研究的难点在于污染源溯源求解过程中的求解不唯一、污染源溯源相关的水文参数测量阶段存在误差,污染物回溯模型参数设置存在误差,并且污染物的传播过程不能通过实验来重复[3].
水污染溯源的方法最初来自于空气污染的溯源,最开始被应用于地下水污染的研究[4],Alapati 等[5]通过最小二乘法结合一维地下水扩散模型研究了的地下水污染源参数,国内的白玉堃等[6]通过卡尔曼滤波方法溯源地下水的污染源个数和位置,张双圣等[7]采用贝叶斯公式结合二维水质的对流模型研究了地下水的污染源瞬时排放模式.在河流污染中也采用了和学者研究地下水污染中类似的方法[8],国内外学者在对河流污染的污染源排放相关参数的求解做了大量的工作,大致可以把研究分为3 大类,分别为数学分析法、模拟优化法、概率分析法,其中,前2 个称为确定性方法,最后1 个称为不确定性方法.
在数学分析法的研究上,辛小康等[9]通过遗传算法和数学分析方法相结合,通过一维水质模型研究了单点源和多点源的瞬时污染源参数识别问题; 饶清华等[10]通过有限元法研究了闽江下游不同地点的污染物浓度情况.在模拟优化法上,刘洁等[11]通过遗传算法在一维对流扩散方程求解目标函数; 吴一亚等[12]通过微分进化算法求解宽浅河道瞬时污染排放迁移问题.确定性方法通过污染物浓度数据反推污染源参数,但是当数据出现一点偏差时通过确定性方法求解结果偏差较大.
在概率分析法的研究上,陈海洋等[13]通过贝叶斯推理和二维水体扩散规律构建模型,并通过马尔科夫链蒙特卡罗法求解污染源相关参数; 程伟平等[2]通过逆向概率密度法求解了一维水质的污染源参数识别问题; 王家彪等[14]通过结合正向位置概率密度和逆向位置概率密度之间的耦合关系建立求解模型,并通过微分进化算法求解模型,能够实现求解参数之间的解耦,降低时间复杂度,并且结合了确定性和不确定性分析方法,一定程度上降低了参数误差造成的影响.概率分析方法在一定程度上能够避免参数误差造成的误差较大,但是受观测误差影响比较大,具有一定的随机性.
上述研究中,污染物浓度监测数据使用所有监测站点不同时刻的数据,不同监测站间数据没有做区分,但实际河流中,污染物浓度也存在水流和污染物混合不均匀导致监测浓度不准确现象,监测站的数据可以分为不准确、相对准确两种数据类型.基于大部分监测站点的数据都是相对准确的事实,本文提出一种基于多萤火虫种群的求解方法,通过在算法初期隔离不同监测站间的数据来避免不准确数据使相对准确数据失真,在算法后期通过不同种群间相互作用通过多数效应来淘汰不准确数据类型的种群,从而避免某个监测站数据不准确对求解造成的系统误差.
本文采用耦合概率密度方法对所需求解的参数进行建模[14],并考虑到观测误差和一维水质模型需要污染物混合均匀条件,代入实时的水文特征,采用改进的萤火虫算法(firefly algorithm,FA)算法,引入多种群机制将多个污染物监测站数据同时代入求解,改进后的算法具有更强的全局搜索能力和跳出局部极值能力,对建模后的目标函数进行求解,寻找污染源排放相关的排放位置、排放时间、排放强度.
1 水动力模型构建
河流水污染问题主要是通过已知的水文参数、监测站监测数据信息对污染物的溯源需要根据具体河道的水文特征进行水动力学模型构建,利用污染物在水流中的正向质量概率密度和逆向质量概率密度之间的耦合概率密度关系,使污染物排放强度与排放位置和排放时间之间解耦.
1.1 污染源扩散关系
对于污染物的排放问题,污染物进入河流后的扩散规律满足质量守恒定律[15],可表示为:

其中,m为河道内点(x,y,z)在t时刻污染物的浓度,单位mg/L;t为污染物排放后的时间,单位s;Dx、Dy、Dz分别为河流长度方向、宽度方向、深度方向的弥散系数,单位m2/s;ux、uy、uz分别为河流长度方向、宽度方向、深度方向的水流的平均流速,单位m/s;k为污染物的降解系数,单位s-1.
对于内陆河流,污染物扩散主要受河流两岸和河流底部的约束,因此污染物在水流中会产生边界反射,水中对流、扩散、吸附等现象.考虑到河流宽度和河流深度远小于河流长度,在非洪讯期,水流速度基本不变,污染物在被投放到河流内后,能在投放点断面附近迅速扩散,扩散后断面附近污染物浓度基本相同.因此可以把污染源在内河扩散问题简化为一维水体扩散模型,排入河流后的污染物浓度随时间和位置的变化情况可忽略y,z方向上的变化[16],将式(1)简化为:

若污染物为瞬时排放模式,则可对式(2)进行傅里叶变换[17],可以得到t时刻在x断面处的污染物浓度关系式:
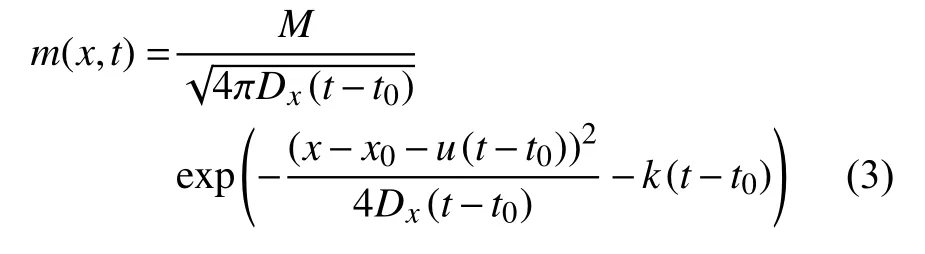
其中,m(x,t)表示污染物在河道x位置时间为t时刻断面的污染物浓度,单位g /L;M为污染物排放处的强度,单位g/m2;t0表示污染物的排放时间;x0表示污染物的排放位置.
由式(3)可知,对于河流突发水污染事件溯源问题,需要确定污染物排放处强度M,污染物排放位置x0,污染物排放时间t0.溯源问题相对于模拟过程具有不能直接求解的特点,但是可以通过监测站的断面信息确定污染源3 个参数的约束范围,然后通过迭代试算寻找最优的参数组合.但是3 个未知数的组合复杂度较高,寻优过程具有运算量大,求解偏差大,求解时间长的特点,因此需要引入降维方法,降低模型的维度.
本文利用正向位置浓度概率密度(从污染源排放断面判断污染源出现在下游的浓度分布情况)和逆向位置浓度概率密度(从监测断面判断污染源在不同断面处的可能性大小)的关系[14],将求解污染源的浓度分布问题转化为求解污染源的逆向位置浓度概率问题,从而将x0、t0的求解和M分开.
1.2 逆向位置关系
设m(xs,xob,t)表示的监测浓度对应的正向位置浓度概率密度为m1(xs,xob,t),逆向位置浓度概率密度为m2(xs,xob,ts),根据文献[2]可知,它们之间存在以下关系:

其中,xs为污染源位置,xob为观测断面位置,t为污染物正向移动的时间点,ts为通过观测断面溯源计算的污染源排放时间点;m(xs,xob,t)表示时间为t时,污染源从排放断面xs扩散到xob观测断面的浓度;m1(xs,xob,t)为污染源从排放断面xs扩散到xob观测断面t时刻观测断面的正向位置浓度概率密度,量纲为m-1;m2(xs,xob,ts)为从观测断面xob推测出污染源在ts时刻处在xs处的逆向位置浓度概率密度,量纲为m-1.
由式(4)、式(5)可知,正向位置浓度概率密度和逆向位置浓度概率密度两者在计算中具有高度耦合性,在同一位置,计算方向不同,计算结果概率密度相同[18].因此可以得出:
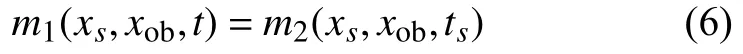
由于m2(xs,xob,ts)具有m-1的量纲,因此也满足式(2),对其也进行傅里叶变换得到逆向位置浓度概率密度为[19]:
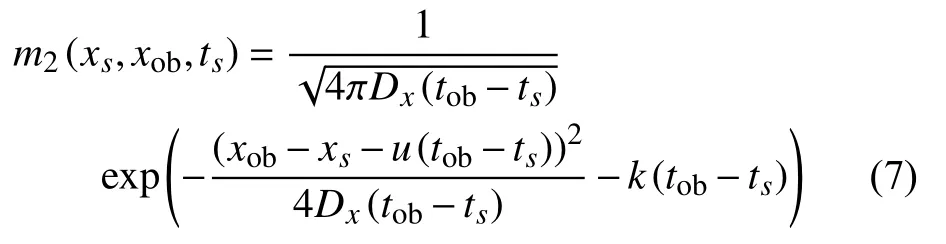
由式(7)可知,污染源的逆向位置浓度概率与污染物排放强度无关,可以通过求解m2(xs,xob,ts)来计算排放位置x0,排放时间t0.
2 溯源优化模型构建
2.1 位置时间模型
由式(4)可知,m2(xs,xob,ts)和m(xs,xob,t)之间具有线性相关性,相关系数为污染物排放浓度的倒数.设mi(i=1,2,3,…,n)为一系列观测断面浓度数据,mi2(i=1,2,3,…,n)为一系列与mi相对于的通过观测断面xob确定的逆向位置浓度概率密度[20].两者相关系数为R(R≤1),R值越接近1 代表此时逆向位置浓度概率密度越接近真实值,可知其有以下相关性:
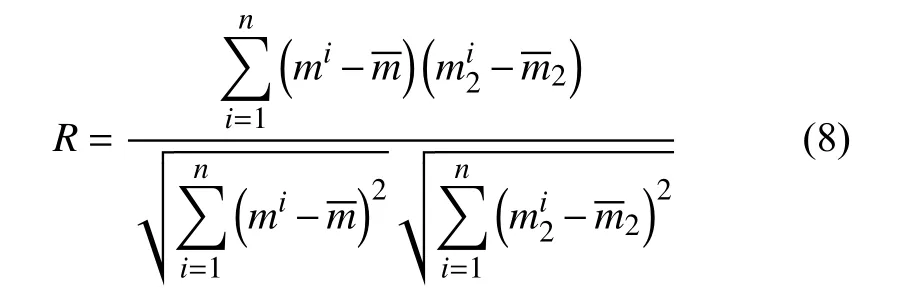
其中,n为观测断面浓度数据和对应的逆向位置浓度概率密度数据的个数,表示观测断面浓度数据的平均值,表示逆向位置浓度概率密度数据的平均值.
设x0,t0为真实的污染源排放位置和排放时间,优化求解的目标是寻找最接近真实值的组合.因此将溯源问题转化求解最优的x′,t′组合使当前的相关系数R最接近1,可通过求解以下目标函数完成求解[20].

目标函数的约束条件是通过已有的监测站断面数据确定的排放位置的范围和排放时间的范围:
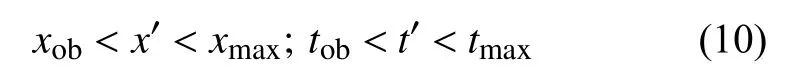
通过求解式(9),寻找其最小值即可得到最近接近x0,t0的x′,t′组合.
2.2 污染物排放强度模型
通过位置时间模型求得的x′,t′组合,可以作为污染源排放量模型的已知条件,因此污染源排放量模型只需要求解污染物排放处的强度M这一个未知参数,根据文献[20]可知,污染物的正向位置浓度概率密度和逆向位置浓度概率密度具有线性相关性,可得式(11):
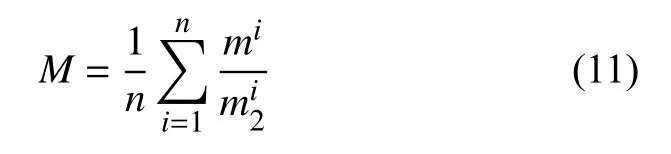
可以通过式(11)估算污染物排放处的强度M的大小范围作为约束范围.
为了进一步确定M的大小,可以通过正向位置浓度概率密度构建目标函数:

目标函数中M的约束范围由式(11)确定的范围确定:
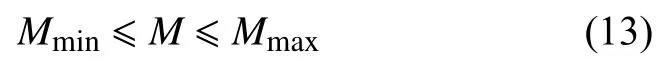
通过求解式(12),寻找其最小值即可得到最接近真实值的污染物排放处的强度M.
3 溯源优化模型求解
在第2 节将污染物溯源需要求解的污染物排放位置x0,污染物排放时间t0,污染物排放强度M三个参数转化为对式(9)、式(12)两个目标函数求最小值问题,本文选用改进的萤火虫算法[21]求解目标函数,为了使算法更适合河流污染溯源的求解,做了以下改进.
3.1 改进参数控制策略和约束条件
在原始的萤火虫算法中,控制随机扰动的步长 α是一个固定值,主要目的是作为随机扰动项增加算法的搜索能力和一定程度上保持种群多样性.α越大,全局搜索能力越强,但是算法后期可能存在跳过最优解,发生在最优解附近震荡的现象; α越小,局部搜索能力越强.
对应到本问题,在求解目标函数式(7)时,污染物排放位置x的范围相对于污染物排放时间范围较大,因此需要提供一个缩放系数k,来调整不同维度的步长相对值,可表示为:

其中,ki(i=1,…,d),分别表示在1 到d维的缩放因子,大小由不同维度之间的搜索范围比例确定,α0为控制随机扰动的步长初始值,大小为[0,1].
由于污染物溯源问题在初期搜索范围较大需要更大的步长来加快搜索速度和全局搜索能力,在后期需要较小的步长来提升搜索精度,因此针对本问题参考文献[21]提出一种自适应步长改进策略,可表示为:
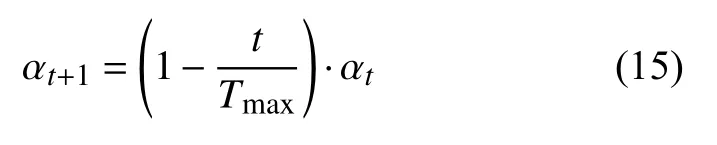
其中,t(t=1,…,n)表示当前的迭代次数,αt表示第t次迭代时随机扰动的步长大小,Tmax表示迭代次数的最大值.
原始的萤火虫算法在移动位置时没有考虑在该维度的搜索范围,对应到污染物溯源问题上,x0,t0,M三个参数都可以通过监测站的参数和河道信息确定其大致范围,因此需要对萤火虫的移动范围做出限制[16],可表示为:
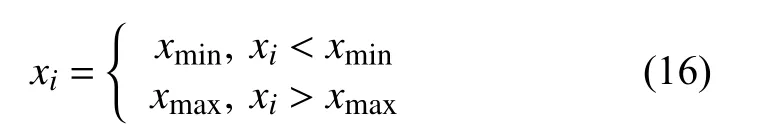
其中,xmin表示在该维度搜索范围的最小值.xmax表示在该维度搜索范围的最大值,xi表示第i只萤火虫的位置.
3.2 改进种群策略
原始的萤火虫算法中,萤火虫亮度较高的个体只会对其附近的亮度相对较低的个体有吸引力,但是对距离较远的萤火虫个体没有吸引力,因此原始算法容易陷入局部极值过早收敛导致求解误差较大.针对上述问题本文参考文献[22]提出的多萤火虫种群的优化策略改进算法,具体内容见第3.3 节算法流程中步骤3-11.
3.3 算法流程
对于污染物溯源问题,早期的学者采用耦合概率密度分析方法建模求解时,没有区分不同监测站的污染物浓度数据,某个监测站的监测值可能因为污染物和河流混合不均匀或者某个设备本身存在系统误差,从而导致通过该监测站数据求解误差较大.
针对本问题提出如下改进: 首先监测站间数据相互独立,使用单个监测站数据依次使用多种群萤火虫算法求解,最后分析各个监测站的求解结果,采用标准差分析法,若通过某一个监测站求解的结果相对于其他使用其他监测站数据求解结果偏差较大,证明该监测站数据为不准确数据,淘汰该结果[23].整体算法结构如图1 所示,具体算法流程如下.
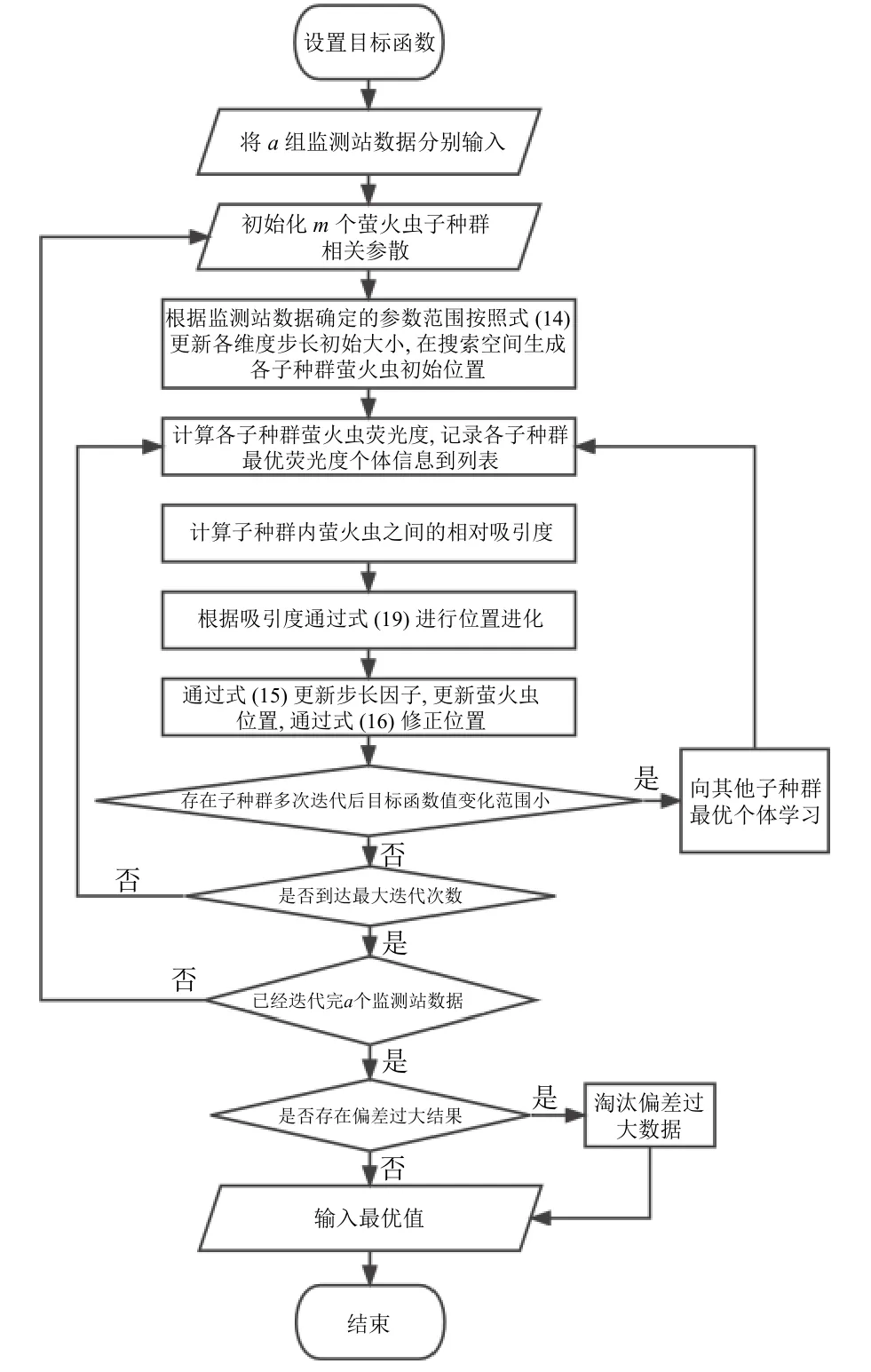
图1 改进的FA 算法流程图
步骤1.确定溯源优化模型求解需要求解的内容,式(9)、式(12).
步骤2.设总共有a个监测站的监测数据,每个监测站的污染物浓度系列为mi(i=1,2,…,n),分别将这a个监测站的数据作为初始条件各执行一次步骤3-12的算法内容.
步骤3.假设所有子种群的萤火虫数目之和为m,子种群数目为n,分别为子种群初始化不同的光强吸收系数 γ、最大吸引度因子 β0,步长因子 α,使各个子种群具有不同的迭代过程.
步骤4.根据监测站数据和河道信息通过式(16)确定需要求解的参数x0,t0,M的上下限.
步骤5.根据参数x0,t0,M的上下限间的大小比例通过式(14)更新各子种群不同维度的步长因子α的初始值.
步骤6.根据步骤4 结果设定不同维度的搜索空间范围,根据该范围在不同维度随机生成萤火虫的初始位置:

其中,j=1,2···,n;i=1,2,···,m/n,Xij表示在子种群j中第i只萤火虫的位置,d表示参数的维度.
步骤7.将生成的Xij代入式(9),将式(9)计算结果设置为子种群j中第i只萤火虫的荧光度I0ij,分别记录各个子种群中萤火虫个体荧光度的最大值,将各个子种群和位置Xij记录在全局信息List列表内.
步骤8.计算子种群内萤火虫之间的相对吸引度:

其中,rii′表示子种群j中第i和第i′只萤火虫之间的空间距离,定义为rii′ =||Xij-Xi′j||,Xi′j表示子种群j中第i′只萤火虫的位置.
各子种群中萤火虫个体开始位置进化,根据式(19)更新空间位置:
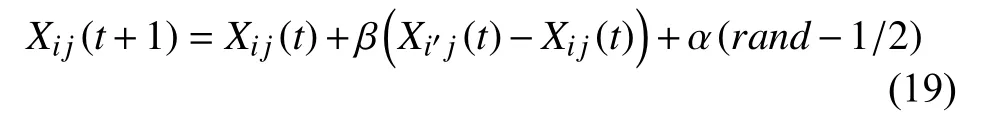
其中,α通过式(15)在每一次迭代前更新大小,rand为在[0,1]内服从均匀分布的随机因子,t表示当前为第几次迭代.
根据式(16)修改Xij(t+1)的值,使其不超过步骤4结果中的上下限.
步骤9.查询List列表数据,若存在某个子种群值在最近10 次迭代变化范围小于10-3,在List列表中寻找其他子种群中最优秀的萤火虫个体.
步骤10.如果步骤9 结果存在则向其学习,如果不存在则通过遗传算法中的变异操作来调整该种群最优萤火虫个体的位置,从而增加该子种群的种群多样性,如式(20)、式(21)所示:
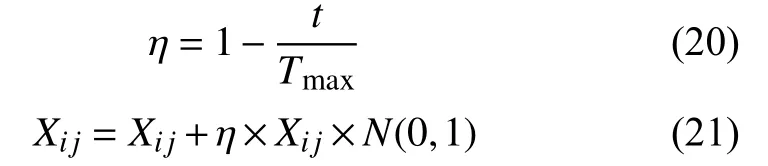
其中,η为根据迭代次数t不断调整的值;N(0,1)为满足高斯分布均值为0,方差为1 的随机值.
步骤11.判断是否达到最大迭代次数,若达到转步骤12,没有达到转步骤7 继续迭代过程.
步骤12.收集步骤2 中的a个监测站分别迭代后获取的a组污染物位置x,污染物排放时间t污染物排放浓度M的数据[24].由式(2)可知,在一维模型情况下,给定x时,t也唯一确定,并且M是由确定的x0,t0作为前提条件求得,因此污染物位置x对其他参数有直接影响,求a组数据中污染物位置x的标准差,若标准差过大,代表某个监测站存在不准确浓度数据,将其溯源结果排除,输出排除后的结果.
4 案例分析
为了验证提出的改进FA 算法的可行性,本文采用文献[25]美国地质勘探局公布的2006年在特拉基河做的染料示踪实验数据.为了研究混合不均匀情况下监测值对溯源结果的影响[24],采用文献中低流量(4.05-18.04 m3/s)情景,在监测点1 处投放rhodamine WT 染料0.82 kg、在监测点2-6 处设置监测断面,监测点1-12 位置如图2 所示,在监测断面2 处染料与河流混合不均匀,不同断面不同时刻的染料浓度系列为文献[25]中数据,监测点2-6 距染料投放点1 处的位置关系如表1 所示.
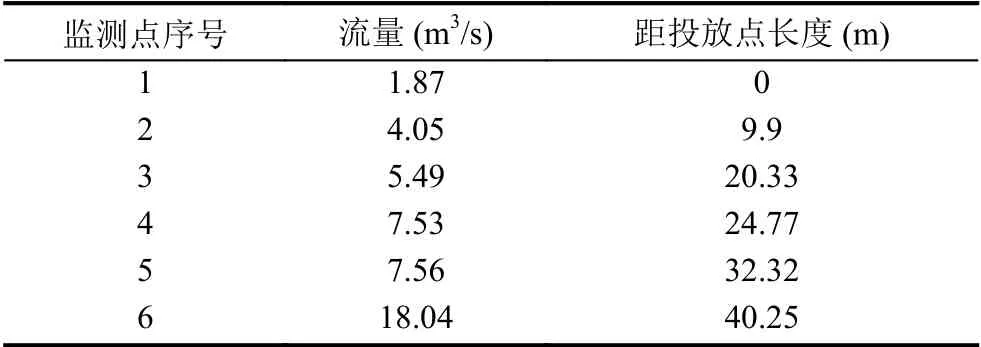
表1 示踪剂投放监测断面分布情况
图2 特拉基河监测站点图
4.1 溯源参数优化调整
本文使用特拉基河监测断面的数据,采用改进的FA 的算法对污染物的排放相关的x0,t0,M进行求解.由于算法设置萤火虫子种群个数n,每个子种群萤火虫的个数m/n,光强吸收系数 γ、最大吸引度因子 β0,步长因子 α和最大迭代次数Tmax等参数对目标函数,求解时间等有较大影响.因此本文通过多次运行实验程序,代入不同的萤火虫算法相关参数,进行对比实验,最终选取的相关参数如表2 所示.
表2 中FA 算法为单种群算法,只需要输入一组参数;而本文采用的改进FA 算法在案例分析中子种群数量设置为3,3 个子种群各代入一组参数,由于每组参数中 γ 、 β0,α值不相同,因此各个子种群具有不同的迭代过程,从而避免各子种群同时陷入局部极值的情况,当某个子种群陷入局部极值时可向其他子种群的较优个体学习,跳出局部极值,增加了整个算法的种群多样性,增强了改进的FA 算法跳出局部极值能力,提高了通过改进FA 算法溯源的准确性.
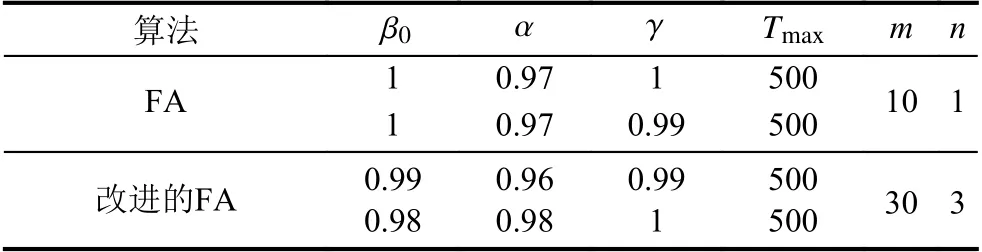
表2 算法参数表
针对河流的水文参数,由文献[22]可大致估计,污染物的降解系数k为1.7×10-10s-1,监测点2-6 号处河流平均流速u为15 m/s,河流长度方向扩散系数Dx为40 m2/s.Dx为估计值,实际河流中存在Dx、Dy、Dz三种扩散方向,因此需要对参数进行调整.为保证结论正确性,将监测数据分为两组: 监测断面2-监测断面5 号数据设置为实验集,用来验证改进FA 算法溯源的准确性; 监测断面6 号数据设置为训练集[25],用来调整河流的水文参数.计算方式采用式(9),将Dx设为待求参数,污染源相关参数设为已知,通过改进的FA 算法通过Matlab 软件进行100 次迭代试算,选取可以使目标函数相对最优的Dx数据为 15.63 m2/s.
4.2 改进FA 算法结果分析
将修正后的水文参数应用到实验集监测断面2-监测断面6 号数据中,分别采用改进的FA 算法和FA 算法对目标函数式(9)、式(12)进行求解,从而对污染源参数排放位置x0、排放时间t0、排放强度M进行求解,改进的FA 算法和FA 算法的迭代过程图如图3、图4所示,其中图3 为求解目标函数式(9)即求解参数排放位置x0、排放时间t0的迭代过程图,图4 为目标函数式(12)即求解参数排放强度M的迭代过程图.表3 为通过Matlab 软件运行100 次,去掉偏差过大数据后对剩余数据求平均值得到的数据.
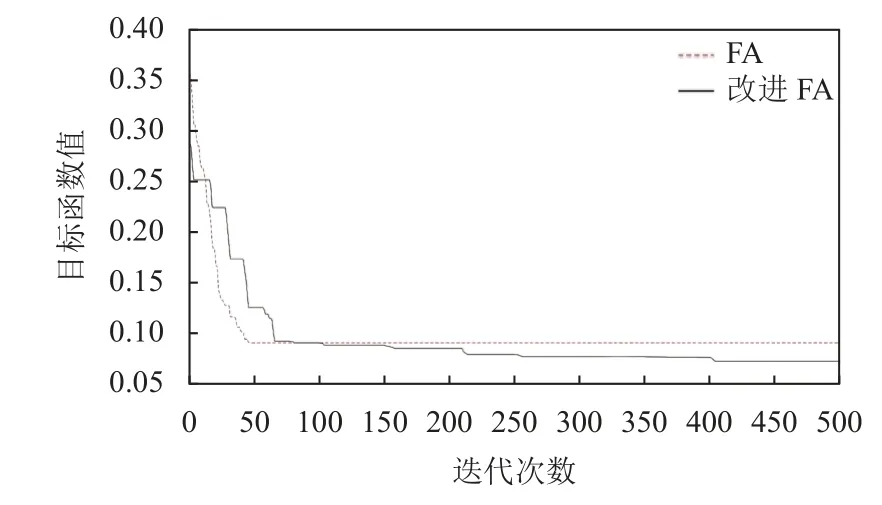
图3 目标函数1 迭代过程图
通过图3、图4 和表3 可知,FA 算法在迭代到50 代左右时,开始快速收敛,但与真实值相比求解结果偏差较大,问题为陷入局部极值,种群多样性较低,没办法跳出局部极值.改进的FA 算法在300 代左右开始收敛,并且图像呈现阶梯下降趋势,虽然迭代速度相对于FA 慢,但求解精度高,具有以下优点: 由于引入了自适应步长策略,使算法前期全局搜索能力较强,后期局部搜索精度更高所以具有更好的种群多样性,全局搜索能力更强; 引入了多种群互相学习策略,当某个种群陷入局部极值时会向其他种群学习或者自身进行高斯扰动,所以具有更好的跳出局部极值能力.

图4 目标函数2 迭代过程图
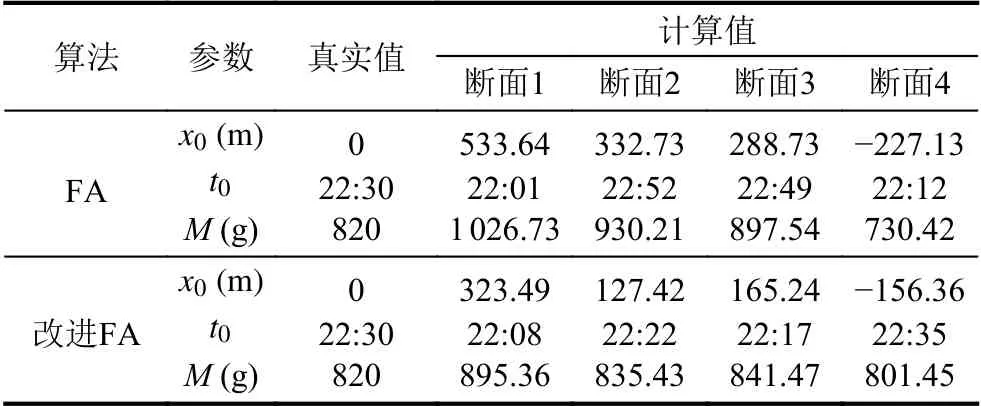
表3 多断面溯源结果
由表3 可知,断面2 计算值明显偏大,根据本文第3.2 节算法步骤,对断面2-5 溯源得到的污染源位置x0的标准差和去掉断面2 数据溯源结果对比如表4 所示,排除断面2 的数据后,标准差明显降低.

表4 多断面溯源位置标准差
通过上述溯源结果分析,改进的FA 算法溯源结果污染源位置范围[-156.36,165.24] m、污染源排放时间范围[22:17,22:35]、污染源排放强度范围[801.45,895.36] g 相对于污染源真实值排放位置0 m、排放时间22:30、排放强度820 g 偏差不大.本文方法在实际的河流污染物溯源分析中具有相对的准确性,并且在通过标注差排除异常监测断面溯源结果后,不同断面溯源结果相对真实值偏差范围在可接受范围内.
5 结论与展望
本研究采用耦合概率密度法和一维水质扩散模型进行建模,通过改进的FA 算法对模型进行求解,为了检验算法可靠性采用特拉基河的示踪剂实验真实场景数据.在实验求解过程中通过多次试算的形式对改进FA 算法的最大迭代次数、子种群个数等参数进行合理选取,在确定河流水文参数时,结合资料给定的水文参数(水流速度、降解系数、扩散系数)和通过算法分析对河流长度方向扩散系数进行修正,进一步提高在对河流突发水污染事件溯源的可靠性.最后通过多监测断面分别进行溯源求解,采用标准差分析法,排除了因为污染物混合不均匀导致的监测数据偏差.通过特拉基河染料示踪实验表明,该方法在单污染源识别问题上,其精度高于原始的FA 算法,具有一定的可靠性.
