基于教与学策略的动态变异花授粉算法①
2022-11-07段艳明肖辉辉谭黔林赵翠芹
段艳明,肖辉辉,谭黔林,赵翠芹
(河池学院 大数据与计算机学院,河池 546300)
1 引言
学者Yang 受显花植物繁殖机理的启发,提出了一种名为花授粉算法(flower pollination algorithm,FPA)[1]的智能优化算法.该算法仿生原理简单、参数较少、易调节,运用转换概率参数p好地解决了探测和开采之间的平衡问题.当前,FPA 算法主要在函数(包括无约束函数和约束函数)优化、能源、通信等应用领域得到了广泛运用,其具体应用如下:
(1)函数优化领域
函数优化是属于连续优化问题,可分为无约束函数优化和带约束的函数优化.郭庆等[2]分析了FPA 算法在求解多模态优化问题时存在的不足,分别利用模拟退火和单纯形法思想对FPA 算法的全局搜索和局部搜索进行了改进了,设计出一种新的FPA 算法框架;最后,利用改进算法对多种类型的测试函数进行求解,并与对比算法进行了对比分析,实验结果说明改进算法是一种具有良好竞争力的新算法.
(2)能源领域
能源是一个国家的经济命脉,如何提高能源的利用率是一个热点的研究话题.为此,众多学者运用元启发式算法来解决该问题,并取得不错的效果.如用FPA算法对能量流管理[3]、能源交易市场单价预测[4]、电力调度[5]等问题进行优化求解,并获得较好的结果.
(3)通信领域
Rajeswari 等[6]把鲍威尔法引入到花授粉算法中,并用改进的花授粉算法解决传感网最小能量传播问题,实验结果表明新算法与对比算法相比,更适合解决此类优化问题.
虽然该算法在众多领域中得到了广泛应用,但该算法与其他智能算法一样,也存在一些不足,如算法演化后期计算速度慢、容易早熟,寻优精度不高,鲁棒性差等缺陷,导致其在解决大量复杂优化问题时获得的结果不尽人意.为了克服这些算法存在上述的不足,提高其收敛能力,当前众多学者依据各种智能算法的特征和优缺点,运用了诸多的策略和方法对其进行了改进,构建了许多优化能力更强的新算法模型,使得大量的工程优化问题得到更好的解决.
Zhou 等[7]在FPA 算法的勘探部分融入精英反向学习策略的组合探测搜索机制,以增加个体之间的差异性,扩展算法的探索领域; 在算法的开发部分加入贪婪搜索机制构造新的局部搜索策略,以提高算法的开采能力; 同时对参数p运用了动态调整策略.实验结果表明改进算法的寻优能力得到了一定提升.一方面,该算法利用精英所具有的丰富信息,可有效提升算法的性能; 另一方面,在该算法演化过程中,由于精英起着重要作用,将引导种群快速向最优解靠近,因此,若精英一旦陷入局部极值,则导致整个种群停滞进化,易造成算法陷入“早熟”问题.
Abdel-Raouf 等[8]把particle swarm optimization(PSO)算法融合到FPA 算法中,即把PSO 算法优化后的种群作为FPA 算法的初始解,同时通过混沌映射对算法的参数进行调节,这使算法解的质量得到了改善,但该算法由于缺乏增加种群多样性机制,使其在演化中种群的多样性不能得到较好的保持,易陷入局部最优.Lenin 等[9]先对和声算法增加混沌策略进行改进,再把其优化后的种群作为花授粉算法的初始解,提高算法初始解的质量,提升了算法的寻优性能,但其同样存在文献[8]的不足.
Tawhid 等[10]利用鲸鱼优化算法的搜索猎物策略和攻击猎物方法替换了FPA 算法的全局搜索策略,构建了一种新的混合算法whale optimization algorithm and flower pollination algorithm (WOFPA),其性能与对比算法相比,得到了一定程度的提升,但该算法增加了较多的参数,降低了算法的灵活性,同时新算法只在低维上验证了其性能的优越性,没有在高维得到验证,使其缺少了说服力.
Draa[11]对FPA 算法进行了定性、定量分析及其改进.首先,从改进的FPA 算法文献中所利用的测试函数、实验验证方式及传统FPA 算法参数值的设置3 个方面进行了详细的定性分析; 其次,依据定性分析的结果,作者对参数p的值设置进行了较全面的实验对比分析,分析结果表明当p的值取0.2 时,该算法的寻优能力获得最佳; 最后,根据上述的定性分析和定量分析实验,作者把反向学习方法引入到该算法中以达到提高其寻优能力,优化结果说明该改进策略是行之有效的.但是,反向学习机制对算法的改善还是很有限的,其原因在于学习机制过于简单,不能很好地提取和利用较劣粒子所隐含的有益信息[12]; 同时在进化后期,大部分反向点及原点都集中到小范围区域,使反向点的适应度值并不比原值较优,所以在演化后期试图通过反向的方式很难跳出当前的极值区域[13],其依然不能解决算法陷入局部最优、收敛精度低的问题.另外,在该算法中是以一定概率采用反向学习策略,扩大了算法的随机性,从而减缓了其收敛速度.
综上所述,目前的一些改进方法对FPA 算法的优化能力起到了一定的提升作用,但这些方法没有对种群个体之间的信息进行有效利用,造成种群的多样性在演化过程中不能较好地保持,使算法易“早熟”,影响了其全局优化能力; 同时,当前改进的FPA 算法在对多模态等复杂问题进行求解时,其求解精度、稳定性及求解速度等方面还有较大的提升空间,且有些改进措施增加了算法的时间复杂度,降低了算法的灵活性,另外一些改进策略对基本的FPA 算法原有的仿生原理做了相应的修改.
为了解决在提高算法的收敛速度、解的质量的同时防止算法“早熟”的问题,本文构建了一种把改进的教与学优化算法[14]中的教与学思想及动态高斯变异融入到花授粉算法中的改进算法(teaching learning Gauss flower pollination algorithm,TLGFPA).
TLGFPA 算法的基本思想: 首先,根据总迭代次数与当前迭代次数的关系对教与学优化算法中的教学因子进行改进,并把改进的教机制作用于花授粉算法中的全局寻优部分,充分利用最优个体(教师)与其他个体(学生或学员)间的促进作用来提高算法的收敛速度;其次,把教与学优化算法中的学机制作用于花授粉算法中的局部寻优部分,通过个体(学生或学员)之间的相互学习来保持种群的多样性,提高其求解精度; 最后,在教与学优化算法的教阶段的进化过程中,由于超级个体(教师)不断吸引其他普通个体(学生),使得种群个体之间的差异性不能到较好的保持,从而易造成算法“早熟”,因此,在进化过程中需要判断算法是否陷入“早熟”进行处理,若“早熟”,则利用动态高斯变异策略对种群的中间个体进行扰动,增加种群个体之间的差异性,防止算法过早收敛.
首先,通过对16 个经典的优化问题进行求解,求解结果显示新算法与FPA 算法相比,其优化能力得到了较显著提升; 其次,选择了3 种FPA 改进算法进行了对比实验,对比分析结果显示新算法的性能总体上要好于对比算法,显示出较好的竞争力.最后,运用TLGFPA 算法对伸缩绳应用问题进行求解,同样也得到了较好的优化结果,进一步验证了TLGFPA 算法的有效性和可行性.
本文的创新工作主要包括:
(1)为了解决教学机制容易导致教与学算法“早熟”问题,本文对该算法的教学因子进行改进,使其随着迭代的进行而动态调整,能够较好地解决其的勘探和开采能力平衡问题.
(2)把改进的教机制作用于花授粉算法中的全局寻优部分,充分运用最优个体(教师)与其他个体(学生或学员)间的促进作用来提升算法的搜索速度; 同时把教与学优化算法中的学机制作用于花授粉算法中的局部寻优部分,通过种群个体之间的相互交流学习来维持种群的多样性,改进其求解精度.
(3)在算法中融入了动态高斯变异策略来提高种群个体之间的差异性,防止算法“早熟”而导致整个种群进化陷入停滞状态.
本文第2 节对FPA 算法进行了简单描述; 第3 节对教与学优化算法、改进的教与学优化算法、动态高斯变异机制、TLGFPA 算法以及该算法的时间复杂度进行了阐述; 第4 节进行实验评测; 第5 节对本文的研究工作进行归纳,并对今后的研究方向进行展望.
2 FPA 算法
该算法的仿生原理是对花朵植物繁殖过程(异花和自花授粉)的模拟,花朵植物的异花授粉过程是通过昆虫等方式来实现授粉繁殖,具有莱维飞行的特征,FPA 算法的全局搜索策略模拟了该过程,这使其具有良好的全局优化能力,花朵植物的自花授粉是通过同株上的花朵自行传粉繁殖,传播距离非常小,这个过程对应于FPA 算法的局部搜索过程.同时,该算法运用参数p来解决其的勘探和开采能力平衡问题,这使其具有较好的全局寻优能力.为了利用该算法更好地解决一系列实践中复杂的优化问题,还必须对其设定4 条约定,其详情见文献[1].依据上述思路,学者Yang[1]利用以下公式对其实现了数学模型化.
FPA 算法的探索机制(全局搜索策略)是采用式(1)进行模型化:
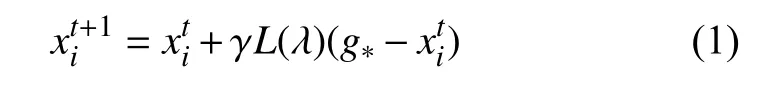
其中,,表示算法进化中第t、t+1 代对应的解,g*表示种群中的最优个体,γ是对步长进行控制的伸缩因子,L(λ)表示种群个体的Lévy 步长,其值运用式(2)计算:

其中,λ取值1.5,G(λ)表示Gamma 函数,s的值通过式(3)计算得到:

其中,μ~N(0,σ2),V~N(0,1),σ2的值采用式(4)计算:
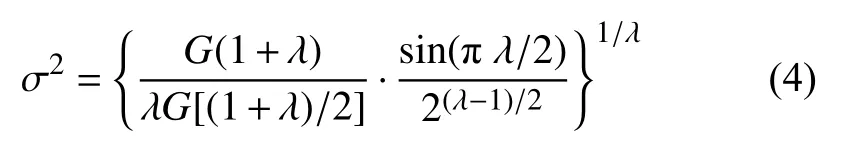
FPA 算法的种群个体采用式(5)实现开发搜索(局部搜索):
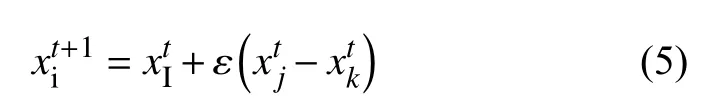
其中,ε∈[0,1]上产生的随机数,xtj,xtk是随机选择的不同于xti的两个不同的种群个体.
3 教与学优化策略的动态变异花授粉算法
3.1 教与学优化算法
受教与学的启发,Rao 等[14]设计了一种名为教与学优化算法(TLBO),该算法模拟了教师的教学过程及学生之间的相互学习和交流的过程.该算法的种群个体分为教师和学生两类,教师是超级个体,学生是普通个体,其所学科目数对应问题的维数.TLBO 算法把进化过程分为“教学”与“学习”两个时段,在“教学时段”是普通个体(学生)向最优个体(教师)不断学习的过程,从而达到提升学生的成绩,同时结合了种群均值的作用,能有效地融合最优个体与普通个体的相互促进作用; 在“学习时段”,随机选取两个种群个体,并比较其优劣,劣者向优者学习.
教与学优化算法的具体实施过程如下.
Step 1.对算法种群(班级)个体的位置利用式(6)进行随机初始化:
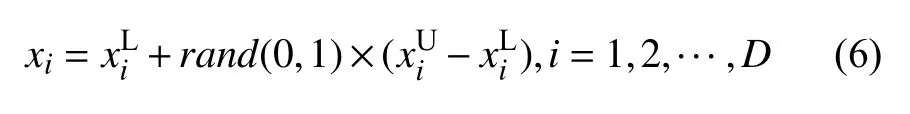
其中,和分别为解空间自变量xi的上界和下界,D为解空间的维数,rand(0,1)∈(0,1)之间的任意数.
Step 2.教学时段.每个普通个体(学生)通过最优个体(教师)和学生平均值之间的差异来向教师(最优个体)学习,首先求解当前种群每一维的平均值xmean,再利用式(7)计算教师与学生的差异,最后利用式(8)实现位置更新,即完成教的过程:

其中,xteacher是种群中的超级个体,s=rand(0,1)为学习步长,tf=round(1+rand(0,1))为教学因子.
Step 3.对普通个体(学生)位置进行更新.每个学生依据学习的效果决定对当前的位置是否更新,若优对其当前位置进行更新,否则保留其原有位置.
Step 4.学习时段.对种群中每个普通个体(学生)xi,随机选取其学习对象xj(i≠j)进行学习,通过计算两者间的目标函数适应度值来进行调整位置,即利用式(9)来进行学生间的学习:
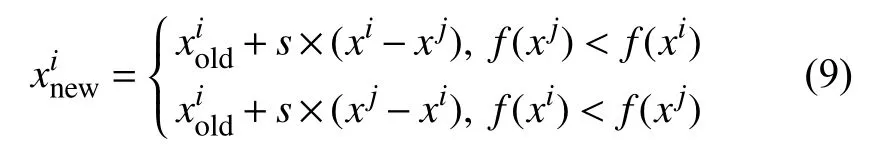
其中,f(xi)和f(xj)分别表示个体xi和xj的目标函数适应度值,s=rand(0,1)为学习步长.
Step 5.对普通个体(学生)位置进行更新.每个学生依据学习的效果决定对当前的位置是否替换,若优,替换,反之保留原有位置.
Step 6.对算法的演化条件进行判断,如条件成立,则优化结束,并输出算法的最优值和其对应的最优解,否则进化继续并转Step 2.
3.2 动态高斯变异
高斯分布是一类重要的概率分布函数,在众多领域得到广泛应用,其计算公式如式(10):

其中,σ、μ为分别表示为方差为1 和均值为0.
动态高斯变异的思想是给原有个体增加一个扰动项,其具体形式如下:
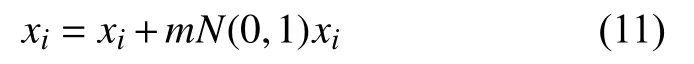
其中,m=(Max_iter-t)/Max_iter,即m∈(1,0]为递减变量;xi表示为算法在进化代数为t时个体i所对应的状态;N(0,1)是服从高斯分布的一个任意向量;Max_iter表示算法的最大进化代数,t表示为算法当前进化的代数.
动态高斯变异机制能在一定程度上增加了种群个体之间的差异性,能使个体有效跳出局部极值进行全局搜索,同时提高收敛速度.
3.3 改进的教与学优化机制
3.3.1 TLBO 算法存在的问题
根据第3.1 节可知,TLBO 算法主要由“教学时段”和“学习时段”两个核心部分构成,但由于该算法的搜索机制存在以下问题,使其优化能力受到一定的影响:
问题1.在TLBO 算法的教学时段,教学因子tf左右着学生个体与教师个体的差异,tf的大小决定着算法在该阶段的搜索能力,tf越小,则搜索能力越强.但从基本TLBO 算法的教学因子的计算公式可知,其值随机地在[1,2]中取值,没有考虑到随算法的进化而相应地调整该值,从而使教学阶段易陷入两种极端的状况,学生要么学得很好,要么学得很差,但在实际的教学过程中,学生个体是以任何概率从教师处学到知识.而且,在教学前期,学生个体与教师个体的差距是较大的,到教学后期,学生个体与教师个体的差距就会不断缩小.
问题2: 从TLBO 算法的教学阶段可知,通过普通个体(学生)之间小范围的相互交流学习来提升各自的成绩,这使种群个体之间的差异性能够得到较好的保持,从而保证了算法的持续全局寻优能力.但是,在TLBO 算法的教学阶段,每个学生(个体)都向教师(最优个体)学习,虽然能快速提高搜索速度,但更易导致种群陷入局部最优.
3.3.2 对TLBO 算法进行改进
(1)对TLBO 算法的教学因子tf进行改进
针对第1 个问题,本文对教学因子tf做了改进,使其随着迭代的进行而线性递减,把教学因子tf的计算公式修改为:
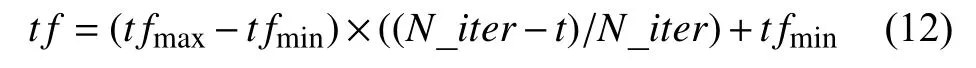
其中,tfmin是tf取的最小值,tfmax是tf取的最大值,N_iter、t分别表示为算法的最大进化代数和当前进化的代数.
从式(12)中可以看出,tf的值在算法进化的前期取值较大,这有利于学生的学习速度和学习能力的提高,从而达到提升算法的勘探能力,提高算法的寻优速度; 在算法进化的后期,学生的学习速度和学习能力显著下降,教学因子tf的值变小,有利于提高算法的开采能力,促进种群个体向理论解靠近,提高解的精度.
(2)融入动态高斯变异机制
针对问题2,本文把高斯变异机制融入到TLGFPA算法中,从而进一步改善算法的优化能力.这是因为TLGFPA 算法的全局授粉部分引入了TLBO 算法的教机制,而TLBO 算法的教阶段在进化过程中,由于超级个体(教师)不断吸引其他普通个体(学生),使得种群个体在进化过程容易同化,从而易造成算法陷入局部最优.为此,在进化过程中需要对算法是否陷入“早熟”进行判断,若“早熟”,则利用动态高斯变异策略对种群的中间个体进行扰动,增加种群个体之间的差异性,防止算法过早收敛.
3.4 TLGFPA 算法
从式(1)可知,FPA 算法采用了Lévy 策略使其具有良好的勘探能力,但该策略也使其求解精度较低及收敛速度慢; 而其局部搜索部分利用了差分进化(DE)思想,这使其在解决高维复杂的优化问题时,性能比较差; 同时,跟其他群智能算法类似,该算法在演化的后期,随着种群多样性的减少,算法容易早熟.然而该算法运用转化概率参数p来平衡该算法的勘探和开采能力.“教与学”优化算法(TLBO)是最近提出的一种新群智能算法,根据其仿生机理,其具有极强的收敛能力且求解速度快、精度高优点,但该算法的教阶段使算法易陷入早熟,且其“探索”与“开采”能力之间的平衡问题没得到较好的处理.依据两种算法的结构及特性,把TLBO 算法引入到花授粉算法中,使其取长补短,提高算法的性能.鉴于此,本文提出了融合教与学优化策略的动态变异花授粉算法TLGFPA,先根据总迭代次数与当前迭代次数的关系对教与学优化算法中的教学因子进行改进,接着把改进的教机制作用于花授粉算法中的全局寻优部分,充分利用最优个体与其他个体间的促进作用来提高算法的搜索速度; 同时把教与学优化算法中的学机制作用于花授粉算法中的局部寻优部分,通过种群个体之间的相互交流学习来维系种群的多样性,提高其计算精度; 最后,如果适应度值连续迭代3 次没有改进或改进很小,则对进入下一代的中间种群个体进行动态高斯变异,增强种群的多样性,避免过早收敛.通过融合多种策略,提高算法的寻优性能.
TLGFPA 算法的伪代码如算法1 所示,其中,n为种群规模,p是算法的全局搜索和局部搜索之间的转换概率,N_iter是算法的最大进化代数,ε∈[0,1]的任意数,fmin为种群个体中的最优值,g*为最优解,fitness 为函数适应度值,xi为种群的第i个体.

算法1.TLGFPA 算法伪代码1.初始化所有参数2.for i=1: n 3.随机产生 n 个个体 {xi | i=1,2,…,n};4.计算每个个体或每个解的适应度值;5.end 6.计算当前种群的最优值7.找出当前种群最优值对应的最优解;8.% TLGFPA 算法开始迭代9.for t=1: N_iter (总的迭代次数)do 10.for i=1: n do 11.if p>rand(0,1)then 12./*全局寻优*/13.根据式(10)计算 tf 的值;14.计算种群个体的平均值 Solmean;15.根据式(7)计算 dif 值;

16.根据式(1)和式(8)产生一个新的候选解;xt+1 i xt+1 i 17.对 进行越界判断18.else 19./* 局部寻优*/xtj xtk 20.随机产生两个个体 和 ;xt+1 i 21.根据式(9)产生一个新的候选解;xt+1 i 22.对 进行越界判断23.end 24.找出当前种群的最优值和其对应的最优解fun(xt+1 i))25.if (t>=3 && abs((-))<δ)|| (t>=3 && abs((-))=0)26.高斯变异xt+1 i fun(xti))fin(xti fun(xt+1 i 27.对 进行越界判断28.找出当前种群的最优值和其对应的最优解29.end 30.end 31.end
TLGFPA 算法的实现过程如下.
步骤1.对TLGFPA 算法的种群规模n,全局和局部搜索转换参数p,最大进化代数N_iter,问题规模D,教学因子的最大值tfmax,教学因子的最小值tfmin,分别进行赋值.
步骤2.对算法的种群进行初始化,求解每个解的值,并记录所有值中的最小值或最大值和其相应的解.
步骤3.若p>rand(0,1),利用式(12)计算教学因子tf的值.
步骤4.计算种群的平均位置Solmean.
步骤5.运用式(7)计算最优花朵与种群的差异dif.
步骤6.利用式(1)、式(8)对花朵个体的位置进行更新,并对新产生的解是否超出解的范围进行处理.
步骤7.如果p<rand(0,1),根据式(9)对花朵个体的位置进行更新,并对新产生的解是否超出解的范围进行处理.
步骤8.对步骤6 或步骤7 产生的新个体进行求解,并更新fmin和g*.
步骤9.如果连续3 次,适应度值没变或变化很小,则执行步骤10,否则跳到步骤11.
步骤10.对种群中间个体进行动态高斯变异.
步骤11.如进化代数大于阈值N_iter,则进化结束,并输出所有解中的最优解和其相应的适应度值,否则,转步骤3 继续进化.
3.5 TLGFPA 算法的时间复杂度分析
改进措施对算法性能的提升是否可行,主要从两个方面来衡量: (1)改进策略能较好地改善算法的性能;(2)改进算法的灵活性要好,且算法的时间复杂度值要小.算法的时间复杂度与其进化代数成正比例.倘若f(x)为求解的问题,D为求解问题的规模,则依据算法时间复杂度的求解原则和FPA 算法的优化机理,FPA算法的时间复杂度表示为:T(FPA)=O(D+f(D)).从TLGFPA 算法的具体实现过程可知,步骤3-步骤7 和步骤9 是新算法添加的步骤,即包括计算教学因子tf、计算种群的平均位置Solmean、计算最优花朵与种群的差异dif、更新花朵个体的位置和动态高斯变异.依据上述公式的阐述和时间复杂度的求解规则,则可推导出TLGFPA 的时间复杂度表示为:T(TLGFPA)=T(FPA)+T(计算教学因子)+T(计算种群的平均位置)+T(计算最优花朵与种群的差异)+T(更新花朵个体的位置)+T(高斯变异)=O(D+f(D))+T(1)+T(1)+O(D+f(D))+O(D+f(D))+O(D+f(D))=O(D+f(D)).从上述对改进算法的时间复杂度理论分析结果可知,改进算法与FPA 算法相比,其时间复杂度基本相同.
4 实验仿真及分析
4.1 测试函数仿真及分析
为了验证本文算法的可行性和有效性,本节选用4 类共16 个非常具有代表性的测试函数进行实验,其具体详情见表1.本节实验除了与FPA 算法比较外,还与人工蜂群(artificial bee colony,ABC)算法[15]、动态领域学习粒子群(dynamic neighborhood learning particle swarm optimizer,DNLPSO)算法[16]、TLBO 算法、基于教与学的花授粉算法(teaching learning flower pollination algorithm,TLFPA)进行比较.实验中所有参数的具体设定为: 种群规模n=30,最大进化代数MaxN_iter=5000,FPA、TLFPA 和TLGFPA 三种算法的p的值都取0.2; DNLPSO 算法的其他参数值来自文献[16]; ABC 算法中,limit=100.
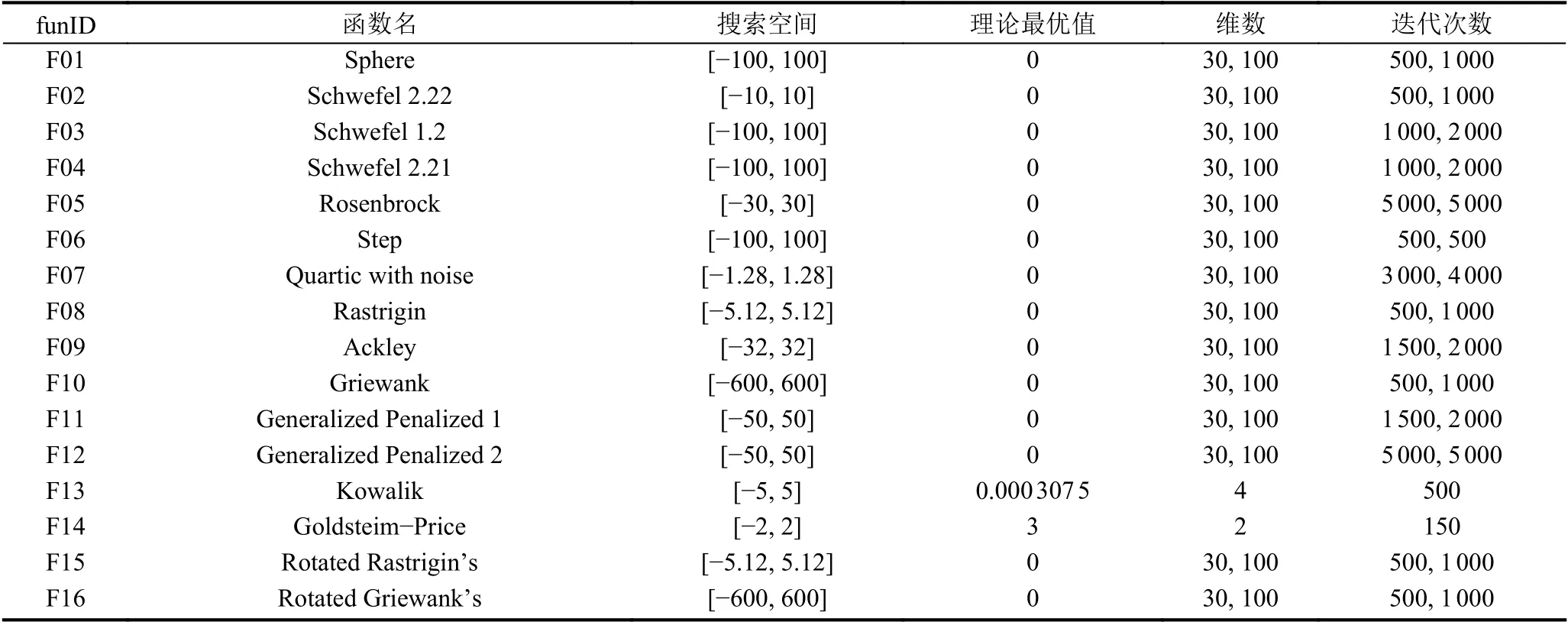
表1 本文使用的实验测试函数
4.1.1 固定迭代次数的性能比较
为了验证本文算法的有效性,佐证其收敛精度(解的质量)的优越性,且能较好地防止陷入局部最优,所有算法在每个求解问题上都独自执行30 次,求解出其对应的Mean error (寻优均值偏差)、St.dev (标准方差)值,并为了判定TLGFPA 算法与其余5 种对比算法寻优性能是否存在显著性差异,利用非参数统计检验(α=0.05 的Wilcoxon 检验)分别对16 个函数的实验结果进行统计分析,其分析结果见表2,其中符号“‡”,“≈”,“†”分别说明TLGFPA 算法的寻优精度逊于、相当于和高于其余算法,“w/t/l”符号分别说明TLGFPA算法与对比算法对比,在求解问题上,有w个的优化结果好于比较算法,有t个的寻优结果与比较算法相当,有l个的优化效果劣于比较算法.
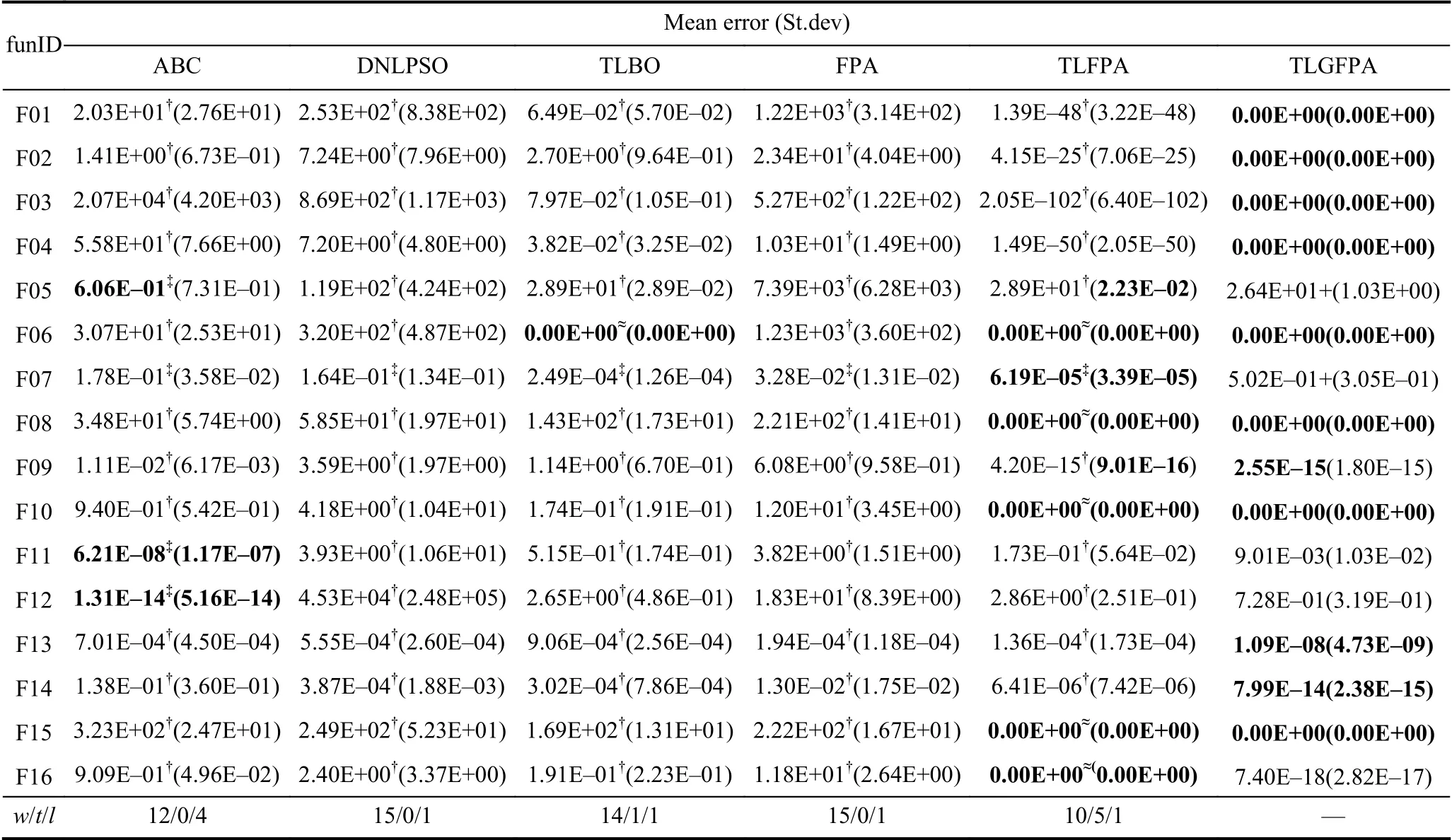
表2 在固定进化代数下算法的寻优能力对比(D=30,4,2)
对表2 分析获得,TLGFPA 算法与ABC,DNLPSO,TLBO,FPA 及TLFPA 算法相比,有8 个函数能找到理论最优值,3 个函数找的值接近理论值.与TLFPA 算法相比,只有在函数F07 上,寻优均值偏差要劣于对比算法,说明加入“动态高斯变异”策略,能使算法避免陷入局部最优,提高了算法的收敛精度,同时也提升了算法的鲁棒性.与ABC,DNLPSO,TLBO 及FPA 算法比较,在16 个函数上,分别有12、15、14、15 个函数的寻优均值偏差要好于对比算法,这说明TLGFPA 算法的优化精度明显优于对比的算法,验证了本文提出的新算法是可行有效的,达到了改进的目的.
为了佐证新算法在高维函数上的优化能力同样表现出色,表3 列出了6 种算法在14 个函数上D=100 的优化结果,并对实验结果从数学角度进行统计分析.从表3 可以获得,TLGFPA 算法有7 个函数能找到理论最优值,2 个函数找的值无限接近理论值,与TLFPA 算法相比,只有函数F03 和F07 的寻优均值偏差要逊于该算法,与其余4 种算法对比,本文算法的求解精度优势较显著.
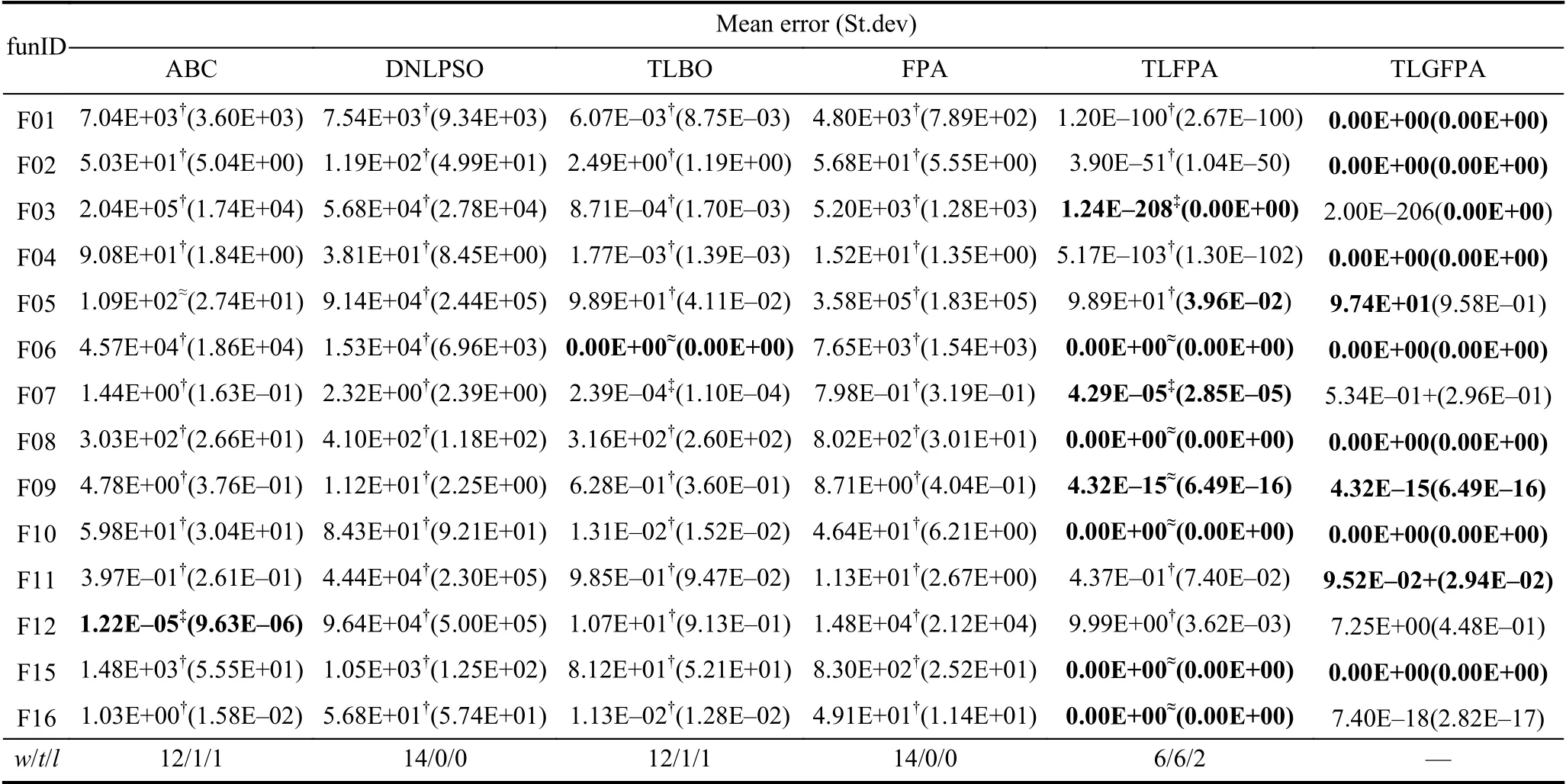
表3 6 种算法在固定迭代次数下的寻优性能比较(D=100)
综上所述,本文提出的新算法在4 类不同求解问题上的寻优能力与对比算法相比,其优化能力要优于对比算法,也说明本文算法能较好地解决“早熟”问题.
4.1.2 固定寻优精度的性能对比
为了比较TLGFPA 算法的稳定性和寻优速度,在寻优精度固定下,检验其收敛速度和鲁棒性的优越性,其实验结果如表4 所示.本节所有算法在每一个求解问题上都设置了一个固定的寻优精度边界值,若算法收敛到上述设定的阈值(边界值)且进化代数已大于一定的代数(本文设置为3 000),则断定该算法对该求解问题寻优失败; 其他参数设置同上,对比算法在每个求解问题上独立执行30 次; 计算出SR(执行成功率,执行成功率=算法找到求解精度边界值所需要的代数/算法总的执行代数)值和mean_iter(平均进化代数)值,对比算法的SR越大且mean_iter越小,其性能越优,表4 中符号“NA”表示对比算法寻优受挫,最好结果用加粗突出显示.从表4 中可获得,FPA 算法只有在2 个求解问题上的寻优成功率达到100%,其余都是0,对于函数F05,所有算法都寻优失败,这是由于该函数的特殊属性,使得很多群智能算法很难找到其全局极小值.TLGFPA 算法和TLFPA 算法在16 个函数上,都有11 个函数的寻优成功率是100%,但是TLGFPA 算法在这11 个函数上的平均收敛迭代次数都小于TLFPA算法,尤其在函数F01、F15、F16 上,TLGFPA 算法的平均收敛迭代次数比TLFPA 算法小1 个数量级,这说明加入“动态高斯变异”机制,能有效提高算法的收敛速度.与其余4 种算法相比,TLGFPA 算法的mean_iter和SR值明显好于对比算法,说明TLGFPA 算法的求解速度和稳定性要优于比较算法.
由表4 可知,FPA 算法的总的平均寻优成功率只有12.5%,通过在FPA 算法中引入新的策略,TLFPA和TLGFPA 算法的寻优成功率得到大幅度提升,其中TLGFPA 算法的寻优成功率为65%,是6 种算法中最高的,说明TLGFPA 算法的稳定性最强.

表4 6 种算法的寻优成功率、平均迭代次数比较
4.1.3 Friedman 与Wilcoxon 检验
为了更客观评价对比算法的综合优化能力,本节从数学统计的角度(非参数Friedman 统计检验)进行对比实验,其对比结果见表5 和表6 所示,分别是所有算法在16 个函数(维数D=30,函数F13、F14 的维数分别为4 和2)和14 个函数(维数D=100)上的Friedman的检验结果,从表5 和表6 可以看出,TLGFPA 算法不管在低维还是在高维上,总体性能最好,则进一步说明改进的算法是有效的.

表5 对比算法在16 个函数上的Friedman’s test (D=30,4,2)

表6 对比算法在14 个函数上的Friedman’s test (D=100)
为了更深入地对算法的优化能力进行综合评价比较,运用a=0.05 的Wilcoxon 检验分析,其对比分析结果见表7 和表8,从两个表中获得,TLGFPA 算法与ABC,DNLPSO,TLBO 和FPA 算法之间的优化性能的差于性比较显著,与TLFPA 显著性差异要弱一些,但也小于0.05.这表明改进策略对提升FPA 算法的寻优性能是可行有效的.

表7 对比算法在16 个函数上的Wilcoxon’s test (D=30,4,2)

表8 对比算法在14 个函数上的Wilcoxon’s test (D=100)
4.1.4 寻优性能对比分析图
为了更直观地表明TLGFPA 算法的整体寻优性能优于其余对比算法,本文画出了部分求解问题上的算法求解过程曲线图,具体见图1.从图1 可知,TLGFPA算法与其他5 种对比算法相比,其优化能力明显好于其他算法,其经过少量的进化代数就能找到理论最优值或接近理论上的最优值; 在F06 和F16 求解问题上,TLGFPA 算法和TLFPA 算法的优化能力旗鼓相当,但明显好于其余对比算法,在F05 和F11 函数上,TLGFPA算法的求解精度要劣于ABC 算法,但比其他对比算法好; 对于函数F07,TLGFPA 算法要劣于TLBO,FPA和TLFPA 算法,但略好于其他2 种对比算法.这说明TLGFPA 的优化过程得到提速,寻优精度得到提高.
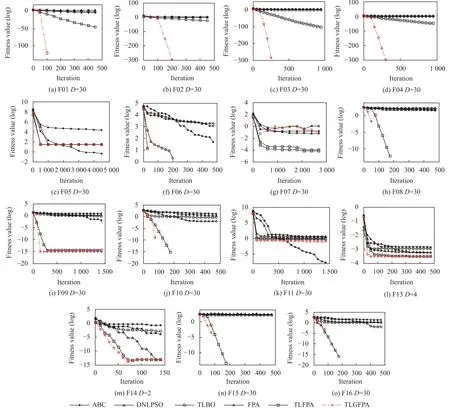
图1 6 种算法的适应度值收敛曲线
同时,为了进一步深入地说明TLGFPA 算法在求解问题过程中的鲁棒性和解的质量优于FPA 等对比算法,本文也画出了对比算法在部分求解问题上执行30 次的优化结果变化对比图和所有算法在求解问题上的方差对比分析图,具体分别见图2 和图3.可见在这4 类函数上,TLGFPA 算法的求解精度、稳定性要好于DNLPSO,ABC,TLBO 和FPA 对比算法,而略好于TLFPA 算法.这进一步显示改进算法在求解精度、稳定性上都得到了较好的提升.
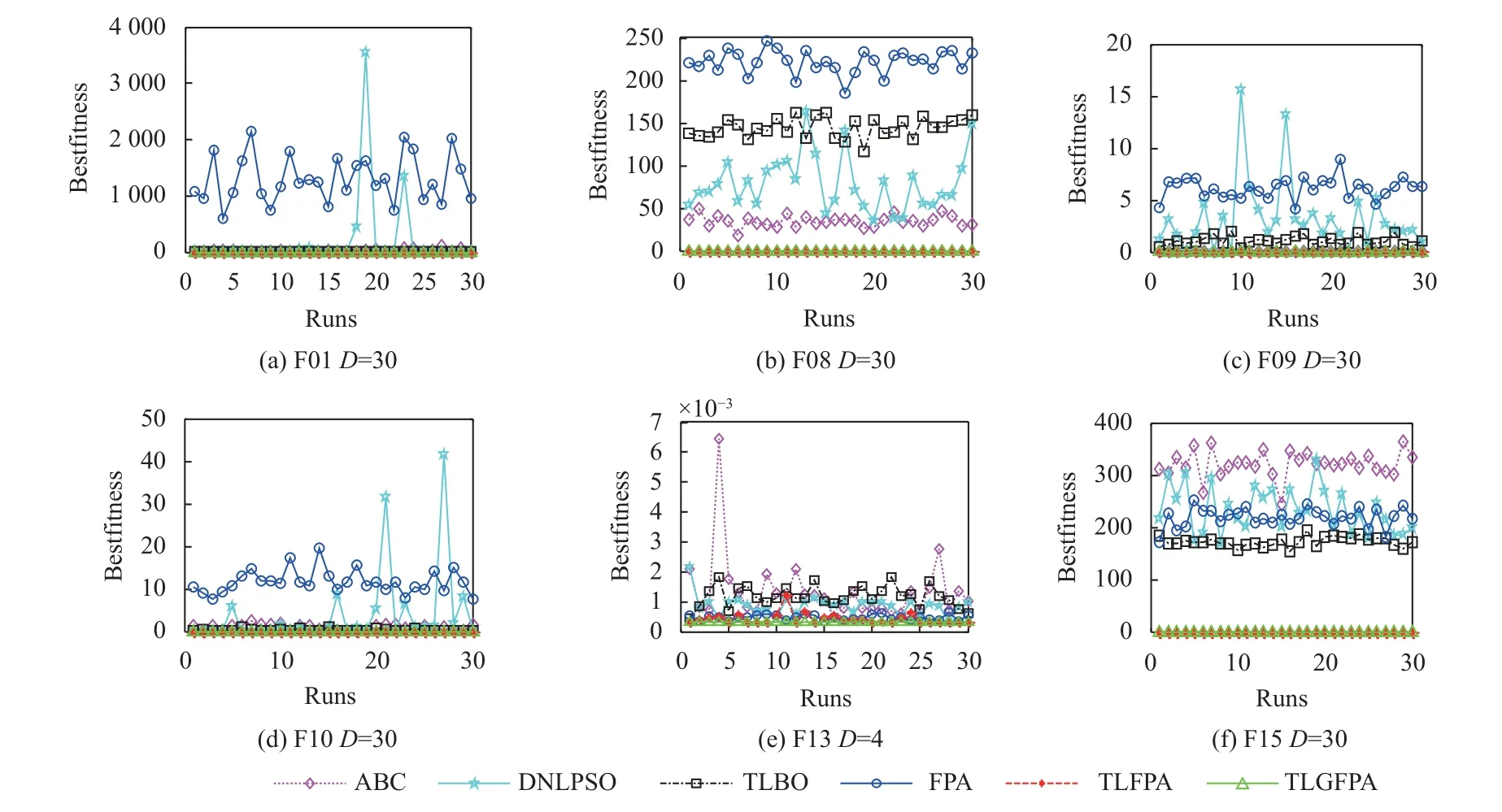
图2 6 种算法在部分函数上的最优适应度值比较图
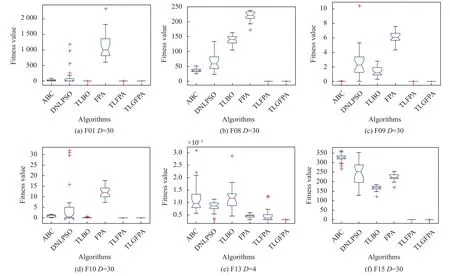
图3 6 种算法的全局最优值方差分析
综上所述,TLGFPA 算法的优化能力表现比较突出,验证了本文改进算法的可行性和有效性,也证明了加入动态高斯变异的有效性.
4.2 与现有改进的FPA 算法比较
为了测试TLGFPA 算法与现有改进的FPA 算法在性能上是否具有不错的竞争力,本节选用3 种改进的FPA 算法进行对比,分别是改进的花授粉算法(modified flower pollination algorithm,MFPA)[11]、基于广义反向学习的改进花授粉算法(modified genera-lised oppsition-based flower pollination algorithm,MGOFPA)[11]及基于精英反向学习的花授粉算法(elite oppositionbased flower pollination algorithm,EOFPA)[7],为了更好突出本文算法的优势,在迭代次数较少(最大迭代次数为500)的情况下比较4 种算法的寻优性能.其中,对于TLGFPA 算法除迭代次数外,其余实验参数和求解问题同第4.1 节; 对于MFPA、MGOFPA 和EOFPA 算法的参数p取相同的值0.8、种群规模n=30 和进化代数不同于相关文献外,其他参数取自相关文献中,为了避免实验的偶然性误差,每种对比算法在其每个求解问题上都单独执行30 次,各种对比算法的优化结果如表9所示.
从表9 可知,改进算法在所有求解问题上的优化能力明显好于MFPA 算法; 与MGOFPA算法相比,TLGFPA算法的寻优能力在93.75%的求解问题上要优; EOFPA和TLGFPA 算法相比,TLGFPA算法在7 个求解问题上的优化能力要比EOFPA 算法优,尤其是在F02 求解问题上,TLGFPA算法能找到理论上的最优解,两种算法在4 个求解问题(F06、F08、F14 及F15)上的优化能力旗鼓相当,而TLGFPA 算法在剩余5 个求解问题上的寻优能力要逊色于EOFPA算法.
为了更直观地说明TLGFPA算法的优化性能好于其余对比算法,本文画出了对比算法在部分求解问题上的收敛过程曲线图,具体见图4.从图4 可看出,本文算法的求解速度在7 个函数上是4 种算法中最快的.借助表9 中“†”的数学统计结果和图4 的收敛曲线可以看出,TLGFPA 算法的性能总体上要优于其他改进算法,显示出较好的竞争力.
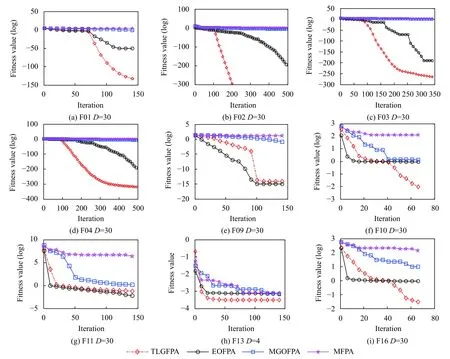
图4 4 种改进的FPA 算法收敛曲线图
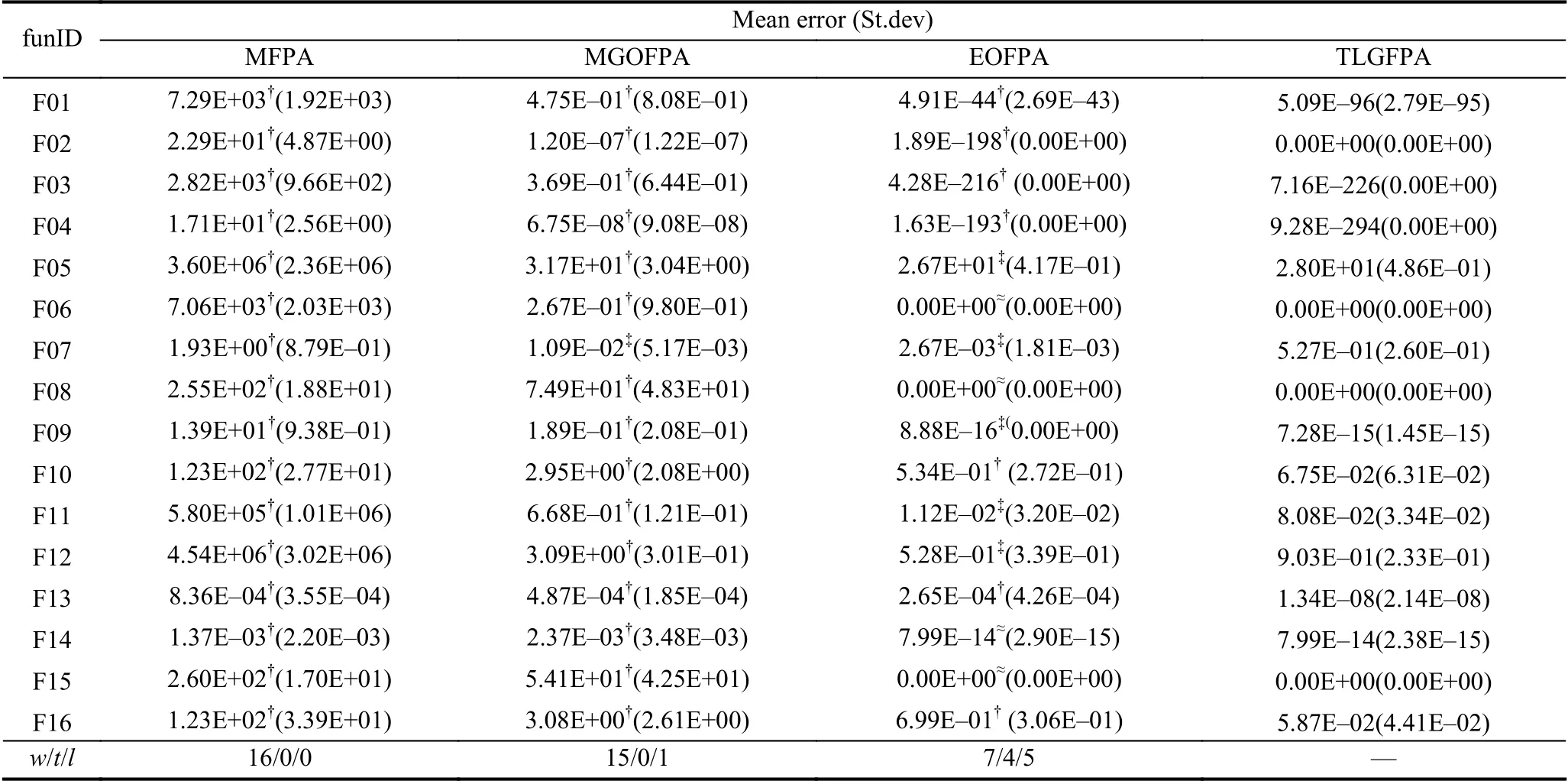
表9 4 种改进算法的寻优性能对比
4.3 利用改进算法对伸缩绳应用问题进行求解
为了验证新算法在应用优化问题上的寻优性能,检验其可行性和有效性,本文选用伸缩绳应用问题进行测试.
4.3.1 伸缩绳问题的描述
在满足x1(d)、x2(D)和x3(P)三个约束条件下使设计的绳最轻,其中d、D及P分别表示为“线的直径”“平均卷的直径”及“卷数”.该问题利用式(13)对其进行数学模型化,其对应的结构如图5 所示.
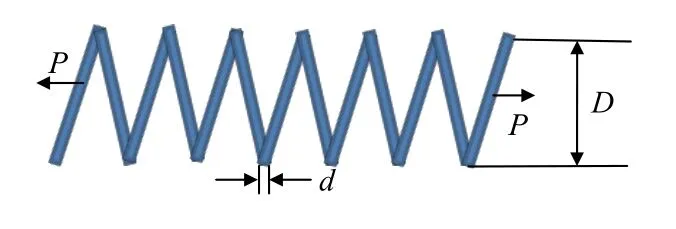
图5 伸缩绳的结构图

4.3.2 实验结果及对比分析
为了进一步佐证本文算法是否行之有效,本节利用TLGFPA 算法对上述伸缩绳设计问题进行求解,并与文献协同进化差分进化算法(co-evolutionary differential evolution,CDE)[17],一种基于可行性规则的混合粒子群约束优化(hybrid particle swarm optimization with a feasibility-based rule for constrained optimization,HPSO)[18],加速自适应权重模型(accelerating adaptive trade-off model,AATM)[19],社会和文化算法(society and civilization algorithm,SCA)[20],精英教学优化算法(elitist teaching-learning-based optimization,ETLBO)[21],
反馈精英教学优化算法(feedback elitist teachinglearning-based optimization,FETLBO)[22],基于精英反向学习的花授粉算法(elite opposition-based flower pollination algorithm,EOFPA)[7]求解结果进行比较.本节的实验参数分别设置为: 种群规模都为25,进化代数为2 000,其余参数设置同第4.1 节,实验结果如表10 所示.从表10 可以看出TLGFPA 算法对伸缩绳问题的优化效果要优于其他5 种算法,这表明本文的改进策略是可行和有效的.
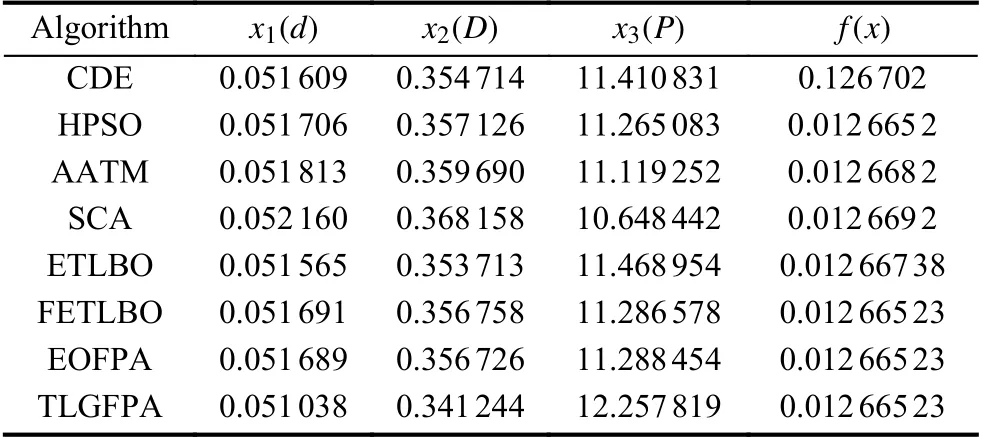
表10 8 种算法对伸缩绳优化问题的求解结果
5 结论与展望
为了进一步解决花授粉算法的优化能力还不太理想的问题,本文提出了先对教与学优化算法中的教学因子进行改进,再把改进的教与学优化机制和动态高斯变异融入到花授粉算法中的混合算法(TLGFPA).首先,通过对16 个无约束函数的仿真实验显示新算法能够较好地解决“早熟”问题,有效地提升了FPA 算法的求解精度和求解速度等性能.其次,选择了3 种FPA改进算法进行了对比实验,对比分析结果显示TLGFPA算法的性能总体上要优于其他改进算法,显示出较好的竞争力.最后,用TLGFPA 算法求解伸缩绳应用优化问题,实验结果进一步验证了本文算法在解决应用问题时,也比FPA 算法和其他对比算法具有更好的优化能力.
虽然本文算法性能还不错,但在解决大规模优化问题时,其优化能力还有待提高,后续将针对此问题进一步研究.在今后的研究工作中,可以尝试利用改进差分进化算法的思路来对其局部搜索部分进行改进,增强其开发能力.因为其局部搜索部分是采用了传统差分进化算法的思想,在优化复杂多维的优化问题时,性能较差.同时,将其应用领域进一步地进行推广,如解决动态组合优化问题.其次,目前“二进制的花授粉算法”研究很少,如何将二进制的花授粉算法运用到软件工程、大数据、量子计算等领域将是值得研究的问题.
