基于访问一体化算法的分布式实时数据库研究
2022-11-05缪燕王和平
缪燕,王和平
(北京许继电气有限公司,北京 100000)
分布式数据库由多个独立的数据存储单元相互连接而成,实时数据库由实时数据模型构成,因此分布式实时数据库是在分布式数据库的基础上建立起来的,是一种用来解决数据模型与数据存储单元之间关系的数据库[1]。分布式实时数据库在数据检索、存储、采集、访问等方面具有实时、可靠、稳定的特点,在对大容量数据进行分类时,首先需要对分布式实时数据库进行分类。目前的分布式实时数据库分类方法存在较多问题,如分类干扰多、数据处理不及时,以及在采用相关算法进行分类时,计算过程复杂、分类精度低、分类耗时长等。为了解决这些问题,国内的专家学者对此展开了研究。有学者提出基于改进粒子群算法的分布式数据库分类方法,将分布式数据库中的数据通过改进粒子群算法进行计算,计算完毕后将计算结果存储在站点中,虽然该方法的计算过程较为简单,但分类精度较低[2]。还有学者提出基于ISE 算法的分布式实时数据库分类方法,建立分布式数据库的自然模型,以数据库自然模型为基础,采用ISE 算法进行分类计算,该方法虽然能够满足分类精度的要求,但是整体计算过程耗时较长[3]。
为了解决以上问题,该文对基于访问一体化算法的分布式实时数据库进行了研究,最后通过实验研究验证了该文研究方法的性能。
1 基于访问一体化算法的分布式实时数据库模型
分布式实时数据库中含有大量的实时数据存储单元,这些实时数据存储单元较为分散,在对分布式数据库进行分类时,会导致实时数据存储单元的分散程度下降,进而造成分布式实时数据库分类耗时过长[4-6]。基于这样的分类背景,在对分布式实时数据库进行分类前,需要建立分布式数据库模型,以提升实时数据存储单元的分散程度。
分布式数据库模型需要按照分布式实时数据库的分类原理来构建,分类原理为将分布式实时数据库中的工作站点设为变量,将实时数据存储单元设定为潜在变量[7-10]。为了计算联合分布概率,可以将数据库的种类设定为N,工作站点的数量设定为K,分布式实时数据库的分类参数设定为α,对于已知的分布式数据库种类,可通过种类索引对其进行标记,而对于未知的数据库种类,可将内部的实时数据存储单元设定为θic,采用访问一体化算法计算联合分布概率为:

式中,θiyj表示分布式数据库与工作站点的数量总和;Cik表示实时存储单元分配至工作站点的估计量,p、E分别表示数据库访问工作站点的参数和分量。实时数据存储单元中的数据流通过数据库中的调度节点进行集合,在对数据流进行分发的过程中,需要对实时数据库中的数据主节点和备份节点进行集中分类,通过分类结果获得数据库种类N的存储单元分配估计量Cik,该值与数据流的调度集合值相同,根据式(1)可获得分布式实时数据库的模型为:
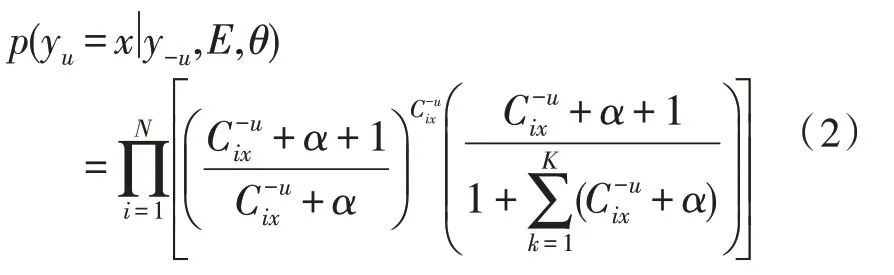
式中,yu表示分布式实时数据库中数据流的调度数量。在实现分布式数据库分类前,需将数据库中的实时数据分配至工作站点的数据流中,图1 为数据分配过程。

图1 数据分配过程
实时数据分配至数据流的过程是实现分布式实时数据库分类的基础,在分配过程中,为实现实时数据的同步与转发,数据主节点将根据数据库中元数据的种类进行转发,转发完成后将数据存储在备份节点中,这一转发与存储过程可实现未知数据库的分类,并有效提升实时数据存储单元的分散程度。分布式实时数据库模型的建立,可缩短数据库的分类耗时,根据以上建立分布式实时数据库模型,结合数据流的转发和存储操作,可以实现分布式实时数据库的分类,但当数据库种类数量过多时,由于未考虑潜在变量,因此需要对分布式实时数据库进行优化[11-13]。
2 分布式实时数据库优化
基于以上建立的分布式实时数据库模型中,设定分布式实时数据库中数据流与数据主节点的访问控制信息,根据访问控制信息实现对分布式实时数据库的优化,在优化之前,需要对分布式实时数据库的分布进行设计[14-16]。
设计过程中需要全面考虑数据库中标签点的调度特性,根据标签点的调度特性来处理数据库中的数据主节点和备份节点,以提升分布式实时数据库的分类效率。
由于标签点中的实时数据分布在工作站点内,而工作站点通常位于分布式实时数据库的边缘,因此为了使标签点更加集中,需要将数据库中的数据分配至数据源文件中。随着分布式数据库中数据节点的增加,数据库中的元数据将表现出较强的扩容或缩容,并且元数据将呈现数据重分布的状态,这时元数据的数据均衡性会有所增强。而标签点与元数据间存在一定的关联性,需要通过增加数据节点的数量来控制元数据在数据库中的分散程度。在极端情况下,数据节点中的所有实时数据将存放在备份名片中,并按照分布式实时数据库的分类时间段来接入数据流,考虑到分布式实时数据库的分类特点,元数据与数据节点的数量可能会发生波动,从而导致数据库中的数据文件发生分布不均衡现象,所以需要把多余的数据节点和元数据分配至分布映射表内,这样可以避免由于分类标准过高而出现标签节点分配失败的现象。图2 为分布式实时数据库中的数据节点分布图。

图2 数据节点分布图
根据该数据节点分布结果对分布式实时数据库进行优化。
在实际的分布式实时数据库中,元数据和数据节点在数据区间的分布函数未知,可通过伯努利分布确定元数据是否退化为实数,如果成功退化为实数,则设定数据节点的分布区间为表示分布式实时数据库的分类参数,分布式实时数据库的优化表达式为:
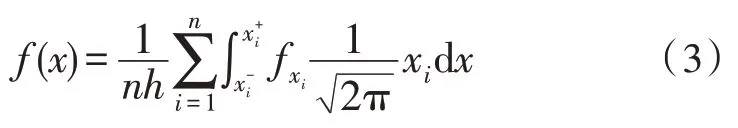
式中,h表示分布式实时数据库的分类数量,n表示分布式实时数据库中数据节点数量,fxi表示分布式实时数据库分类的目标函数,i=1,2,3,…,n。设定分布式数据库优化信息,观察数据库中插值点的概率分布,确定数据库分类原理的可行性。
根据以上建立的分布式实时数据库模型、数据库分布特点以及数据库的优化模型,实现对分布式实时数据库的优化。
3 实验研究
为了验证该文提出的基于访问一体化算法的分布式实时数据库研究方法的实际使用效果,将所提方法与文献[2]基于改进粒子群算法的数据库研究方法进行对比。实验过程中,采用仿真分布式数据库与互联网中的标准分布式数据库进行实验。
贡献率将影响分布式实时数据库的稳定运行,通常情况下,贡献率越低,对分布式实时数据库运行稳定性的影响越小,采用该文研究方法与基于改进粒子群算法的分布式数据库分类方法针对贡献率进行实验,统计分布式实时数据库贡献率的变化,贡献率实验结果如图3 所示。

图3 贡献率对比结果
实验结果中,包括实验时间和实验方法,实验时间的单位为ms,A 表示该文提出的研究方法,B 表示基于改进粒子群算法的方法。一般情况下,当分布式实时数据库的贡献率低于40%时,该方法对分布式实时数据库的稳定状态不产生影响。由上述结果可知,该文提出的基于访问一体化算法的分布式实时数据库研究方法的贡献率最高不超过36%,说明该文提出的基于访问一体化算法的分布式实时数据库研究方法不会对数据库的稳定运行产生影响;而基于改进粒子群算法的分布式数据库分类方法的贡献率远高于40%,说明基于改进粒子群算法的分布式数据库分类方法对数据库的稳定运行影响较大。
不同方法的分类耗时也会影响分布式实时数据库的分类效率,因此,需要对该文提出的研究方法与基于改进粒子群算法的研究方法的分类耗时情况进行对比。对比实验中,以8 次数据库分布结果为1 组实验,共统计6 组实验结果,分类耗时实验结果如图4 所示。
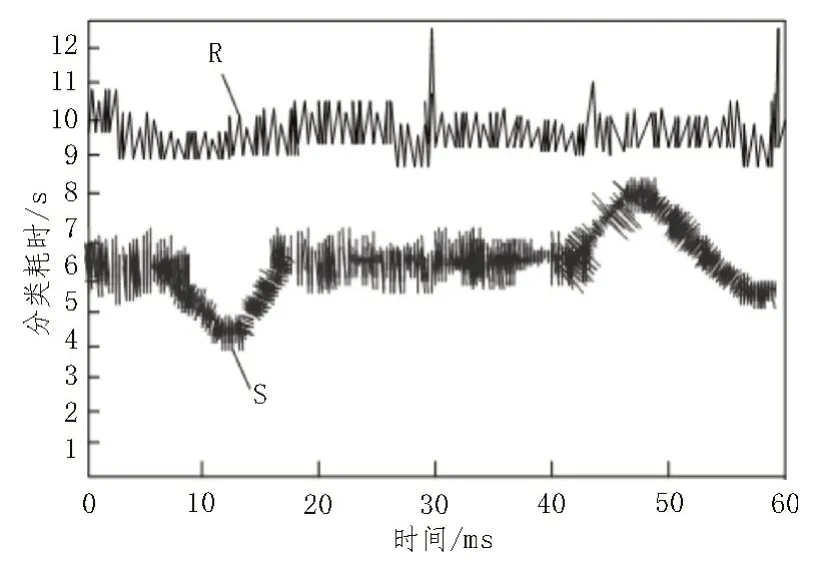
图4 分类耗时情况实验结果
由实验结果可知,S 表示该文提出的基于访问一体化算法的分布式实时数据库研究方法,R 表示基于改进粒子群算法的分布式数据库分类方法。由实验数据可知,该文提出的基于访问一体化算法的分布式实时数据库研究方法的分类耗时最短,说明该文提出的研究方法更容易实现数据库的分类,访问一体化算法的采用降低了数据库分类的复杂度,从而降低了分类耗时。而基于改进粒子群算法的分布式数据库的分类耗时较长,不能提高分布式实时数据库分类的效率。
基于以上得出的贡献率以及分类耗时结果,对文中提出的研究方法与基于改进粒子群算法的分布式数据库分类方法的分类精度进行对比实验。实验中,需要采集20 个分布式实时数据库,采用两种方法对采集的分布式实时数据库进行实验,分类精度对比结果如图5 所示。

图5 分类精度实验结果
由图5 实验结果可知,该文提出的基于访问一体化算法的分布式实时数据库研究方法的分类精度较高,最高可达90%以上,而基于改进粒子群算法的分布式数据库分类方法的分类精度较低,最高只有70%,由此可知,该文方法的分类精度高于基于改进粒子群算法的分布式数据库分类方法。
综上所述,以上的对比实验验证了该文提出的基于访问一体化算法的分布式实时数据库研究方法优于基于改进粒子群算法的分布式数据库分类方法,该文方法的贡献率较低,不会对数据库的稳定运行产生影响,并且该文方法的分类耗时较短、分类精度较高。
4 结束语
为了解决传统分布式数据库分类方法出现的数据库贡献率较高、分类耗时较长、分类精度较低等问题,该文提出基于访问一体化算法的分布式实时数据库研究方法。建立了分布式实时数据库模型,并介绍了分布式实时数据库分类原理以及数据流的分配过程,然后建立了优化模型对分布式实时数据库进行优化。最后通过对比实验,验证了该文提出的基于访问一体化算法的分布式实时数据库研究方法优于传统方法,该文提出的研究方法具有较低的贡献率,且分类耗时较短、分类精度较高,实现分布式数据库的分类较为容易,具有一定的应用价值。
