基于检索与生成混合模型的个性化聊天机器人系统的设计与实现
2022-11-04孔繁恒高永祺张子帅阮俊豪
孔繁恒,高永祺,张子帅,阮俊豪,冯 时
(东北大学计算机科学与工程学院,辽宁 沈阳 110819)
kongfanheng426@163.com;905323742@qq.com;1060876095@qq.com;954369920@qq.com;fengshi@stu.neu.edu.cn
1 引言(Introduction)
伴随着互联网数据的爆发式增长,聊天机器人产品出现在人们的视野中。聊天机器人是经由对话或文字进行交谈的计算机程序,能够模拟人类对话,为用户提供了智能、自然连贯的对话服务。聊天机器人根据其对话生成技术主要分为检索式和生成式。检索式模型使用信息检索的技术,从事先处理好的语料库中选择匹配的对话作为应答。生成式模型使用深度学习的技术,通过预先训练的模型合成适当的应答。
在对话中保持一致的个性对于人类来说是很自然的,但对于机器来说却不是一件平凡的任务,由于在自然语言中体现个性的困难,以及在大多数对话语料库中观察到的人物角色稀疏问题,仍然没有得到很好的探讨。本文设计了一种检索-生成混合模型,该模型可以利用人物角色稀疏对话数据生成连贯的响应。通过对说话人的角色和对话历史进行编码,设计个性属性嵌入,来模拟更丰富的对话语境,从而实现个性化的聊天机器人系统。
2 需求分析(Requirements analysis)
作为人机交互领域一个非常重要的研究方向,人机对话系统正处于蓬勃发展的阶段。传统的问答系统已经不能满足人们的要求,如今人们更偏向于系统拥有更广泛的知识领域并能够具有特定的个性,使得人机对话更加生动、顺畅。聊天机器人,主要任务是利用自然语言完成与人在任意话题上的交流,其涉及的话题之广、表达方式之多更能符合用户的需求。
本系统所要实现的目标为个性化的智能聊天机器人系统,拥有进行个性化聊天的功能。用户在与本系统交互时,可以设置聊天机器人的个性信息。系统会通过对用户设置的角色和对话历史进行编码,模拟对话语境,分别得到检索式和生成式两种回复方式,将两者评价比较后选择最优回复,并显示在聊天界面上,实现个性化的聊天。本系统的各功能模块如图1所示。
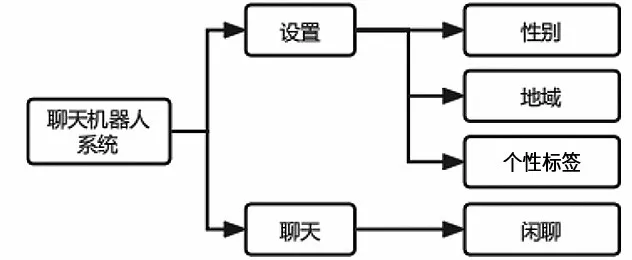
图1 系统功能模块图Fig.1 System function block diagram
3 系统设计和实现(System design and implementation)
3.1 总体设计
本系统以PyTorch为开发框架,采用深度学习的技术,使用检索-生成混合模型,构建了一个个性化的智能聊天机器人系统。前端采用Tkinter模块接口,后端采用PyTorch开发框架,均使用Python语言编写。前端为Graphical User Interface(GUI),分为两部分:设置界面(可供用户设置聊天机器人的个性信息,包括性别、地域和个性标签)与聊天界面。后端使用检索-生成混合模型,检索模型采用Elasticsearch搜索服务器,检索速度极快,大大降低了整体系统的回复生成时间;生成模型采用PostKS模型,可以定向设置聊天机器人的个性并生成具有特定个性的回复。通过混合两种模型提高了回复的相关性和流畅性,语句质量较高。
在后端设计中,选择具有个性信息的2019 年社会媒体处理大会中文人机对话技术评测(SMP2019-ECDT)对话集和质量较高的小黄鸡语料库作为数据集,然后进行数据预处理,包括筛选高频个性标签、数据清洗、调整数据格式等。检索模块使用Elasticsearch搜索服务器及小黄鸡语料库构建检索模型,生成模块首先构建PostKS个性化生成模型,然后利用SMP2019-ECDT对话集进行训练。前端为用户提供窗口输入个性信息与对话,以字符串的形式传送到后端。后端接收到用户发送的信息,分别传送到检索和生成模块中生成应答,在回复选择模块比较两种模型生成的应答并选择合适的应答,同时将此应答传回前端并展示到界面上。系统总体结构如图2所示。
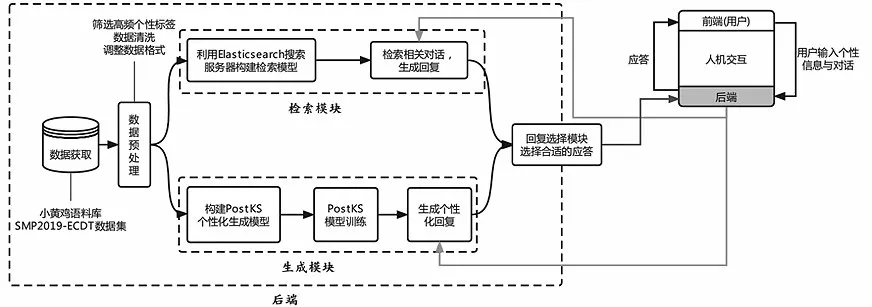
图2 系统总体结构图Fig.2 System overall structure diagram
3.2 数据集获取及预处理
本文选取SMP2019-ECDT提供的数据集作为生成模型的原始数据,数据集中包含约500万轮次的对话(既包含单轮对话又包含多轮对话),以及参与这些对话的发话人的个性化信息(包括性别、个性标签、所属地域)。数据集为JSON格式,如{"dialog":[["疯了疯了"],["我要带到教室去上课你就羡慕我吧!"]],"profile":[{"tag":["美食"],"loc":"四川成都","gender":"female"},{"tag":["娱乐;旅游"],"loc":"四川","gender":"female"}],"uid":[0,1]},其中dialog为对话,profile表示对话人的个性化信息,包括tag——个性标签、loc——所属地域、gender——性别、uid——对话人id。
由于生成模型需要个性信息作为特征,标签的筛选十分重要,因此要对数据集进行预处理。首先将相似的标签进行合并,例如“电影”“爱电影”“电影爱好者”这类标签可以合并成一类。然后筛选出高频出现的标签,得到高频标签字典。算法描述如下所示。

由于数据集中存在很多个性信息不完善(缺少性别/地域/个性标签)的对话,因此需要对数据集进行清洗,并且保证对话中的每个单词都在单词表中,以此来提升数据集的质量。算法描述如下所示:

对于检索模型,SMP2019-ECDT提供的数据集对话噪音较多,在语意连贯、流畅性等方面有所欠缺,因此本文采用小黄鸡语料库作为检索模型的数据集。该数据集只需调整数据格式即可使用。
3.3 检索模块
Elasticsearch是一个分布式、可扩展、实时的搜索与数据分析引擎。由于Elasticsearch是在Lucene基础上构建而成的,所以在全文本搜索方面表现十分出色。Elasticsearch是一个近实时的搜索平台,这意味着从文档索引操作到文档变为可搜索状态之间的延时很短,相比一些传统的检索方法回复速度提升了10%以上。Elasticsearch提供了强大的索引能力,其使用的倒排索引相较于关系型数据库的B-Tree索引更快。
通过文本匹配的相关度分数来判断检索对话的相关性。其相关度评分的计算规则涉及布尔模型(Boolean Model)、词频-逆文档频率(TF-IDF)和向量空间模型(Vector Space Model)。Elasticsearch使用布尔模型查找匹配文档,并用一个名为实用评分函数(借鉴TF-IDF和向量空间模型)的公式来计算相关度,同时也加入了协调因子、字段长度归一化、词或查询语句权重提升。
映射(Mapping)是定义文档及其包含的字段如何存储和索引的过程。每个文档都是字段的集合,映射数据时,将会创建一个映射定义,其中包含与文档相关的字段列表。
本文检索的映射规则设置如下:


其中,type 表示每个字段的数据类型,常用的有keyword和text等,可根据检索的目的设置。analyzer表示索引时用于文本分析的分析器,search_analyzer表示搜索时使用的分析器,本文分别设置为ik_max_word和ik_smart。IK分词器是一款中文分词器,ik_max_word算法是最细粒度切分算法,比如将“中华人民共和国人民大会堂”拆分为中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。而ik_smart算法是最粗粒度切分算法,比如将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。对于中文内容,在索引时用ik_max_word,在搜索时用ik_smart可以使检索的效果达到最佳。
3.4 生成模块
生成模块中使用PostKS模型,这是一个可以利用知识的先验和后验分布来促进知识选择的神经模型。通过使用先验分布有效地逼近后验分布,该模型可以在推理过程中产生适当的回答。根据用户输入的个性化信息通过知识管理器来设定聊天机器人的个性,使得系统能够生成具有特定个性的回复。

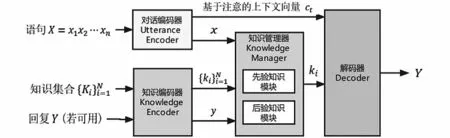
图3 PostKS模型图Fig.3 PostKS model diagram
(1)对话编码器和知识编码器


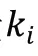

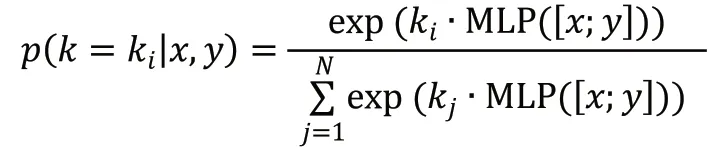
显然,后验分布在选择知识时是优于先验分布的,但在推理生成应答阶段中,后验分布是未知的,因此期望先验分布能够尽可能地接近后验分布。为此,引入了KLDivLoss(Kullback-Leibler Divergence Loss)作为辅助损失函数,用来衡量先验分布和后验分布的接近性:
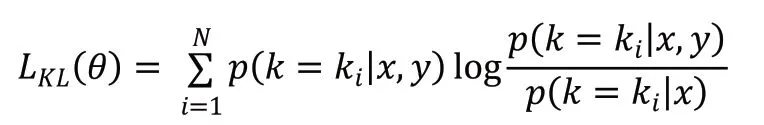
(3)解码器
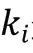

然后,融合单元将它们组合在一起,生成整体的隐藏状态:

3.5 回复选择模块
检索模型与生成模型各有利弊。检索模型直接使用语料库中的对话,选择匹配度较高的对话进行回复,回复语句的质量较高,保证了对话的信息性,但无法回复语料库中未出现的问题;生成模型将对话经过一系列处理从而产生相应的回答,且PostKS模型能够根据特定的个性产生对应个性的回复,具有多样性,但相较于检索模型产生的回复可能会出现缺乏相关度或语义不通等问题。
为使聊天机器人系统既能保持检索模型的信息性,也能保持生成模型的多样性,且尽可能地克服两种模型的缺点,因此设计了一种检索-生成混合模型,结构如图4所示。

图4 回复选择模块流程图Fig.4 Reply selection module flowchart
当接收到用户发送的对话时,先在检索模块通过Elasticsearch搜索引擎进行检索并进行相关度评分,设定一个适当的阈值(本文设为5),若存在相关度评分高于阈值的对话,则将评分最高的回复发送给用户,否则调用PostKS个性化生成模型,依据用户设置的个性化信息,生成具有特定个性的回复发送给用户。
由于用户设置过聊天机器人的个性信息,当询问聊天机器人的性别与地域相关问题时,为防止机器人的回复与先前用户设置的信息不一致,机器人的回复不应通过检索或生成模型来获取,而是调用回复性别或地域的函数。
3.6 前端设计
前端使用Tkinter模块,是Python标准Tk GUI库。前端包括设置界面(可供用户设置聊天机器人的个性信息,包括性别、地域和个性标签)与聊天界面。
在设置界面(图5)分别输入性别、地域和个性标签即可设置聊天机器人的个性,点击“确定”后进入聊天界面(图6),在输入框中输入语句,点击“发送”即可生成应答并显示在界面中,点击“返回”将退回到设置界面,可重新设置聊天机器人的个性。
图5 设置界面Fig.5 Interface for settings
图6 聊天界面Fig.6 Interface for chatting
4 系统展示(System display)
系统运行结果如图7和图8所示。
图7 设置界面展示Fig.7 Display of setting interface
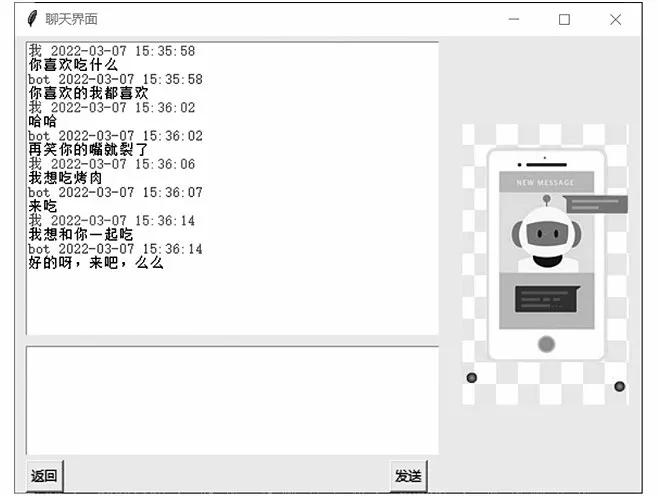
图8 聊天界面展示Fig.8 Display of chatting interface
5 结论(Conclusion)
本文设计了一种可以实现个性化回复的聊天机器人系统。本系统基于PyTorch开发框架,后端各个模块结构清晰简洁,易于修改、扩展。使用检索-生成混合模型,既保留了检索模型的信息性,语句流畅、质量高,也保留了生成模型的多样性,且可生成特定个性的应答。检索模型使用Elasticsearch搜索引擎,检索速度极快,大大缩减了整个系统生成应答的时间,通常情况下1 s内即可产生应答,对话具有实时性。生成模型使用PostKS模型,可以生成具有特定个性的应答。本系统可供用户闲聊,同时也可以应用到多种不同的场景中。在面向特定的应用场景时,依据实际场景采取相应的个性,会使交流过程更为顺畅和专业,这无疑具有一定的社会价值。
