一种编解码结构的车牌图像超分辨率网络
2022-11-02徐胜军邓博文史亚孟月波刘光辉韩九强
徐胜军,邓博文,史亚,孟月波,刘光辉,韩九强
(1.西安建筑科技大学信息与控制工程学院,710055,西安; 2.西安市建筑制造智动化技术重点实验室,710055,西安;3.西安交通大学电子与信息学部,710049,西安)
车牌识别技术作为智能交通系统的重要组成部分,其主要任务是利用采集的车辆图像提取车牌相关特征信息,并有效对车辆进行身份识别。因此,准确的车牌识别技术在智能交通管理系统中显得尤为重要[1],然而室外场景下捕获的车牌图像存在各种复杂干扰因素,主要包括:①恶劣天气如浓雾、雨、雪等环境因素导致车牌成像模糊、污损等问题;②摄像机拍摄角度导致车牌成像存在较大扭曲、倾斜等问题,这些问题为车牌的准确识别带来很大的挑战[2]。
车牌图像重构是解决模糊、污损、扭曲、倾斜车牌图像准确识别问题的重要途径之一。随着计算机视觉的发展,越来越多的研究人员对图像重构问题进行了深入的研究[3-4],车牌重构的研究方法主要分为基于传统机器学习的车牌重构方法、基于图像超分辨率的车牌重构方法和基于深度学习的车牌重构方法。
基于传统机器学习的车牌重构方法主要通过机器学习算法将扭曲、倾斜的车牌图像进行还原和恢复,这些方法主要包括霍夫变换法、色域模型法、投影变换法等[5-8]。霍夫变换法对图像边界的变形较为敏感且受超参数较大,在对含噪声较大的车牌图像,如车牌边框成像不清晰或车牌边框有遮挡时,会造成边缘误检从而导致矫正效果较差。色域模型法主要是利用车牌图像的颜色信息对车牌边缘进行检测,在图像背景颜色与车牌颜色相近时效果较差。投影变化法存在的主要缺陷是对于不同旋转角度的车牌时难以确定投影变换矩阵,如果利用传统方法确定投影矩阵参数同样会导致车牌矫正效果较差,需要根据不同车牌图像动态确定投影矩阵参数。基于传统图像处理算法的虽然车牌矫正运算速度较快,但是传统算法存在泛化能力差、设计复杂等缺点,难以解决真实复杂环境下车牌的矫正问题。
基于图像超分辨率的车牌重构方法在车牌重构领域也得到了广泛关注。Irani等[9]提出了迭代反投影法(iterative back-projection,IBP),对于图像重构有着速度快和计算量小的优点。Rasti等[10]基于迭代反投影法引入了双三次插值和双三次降采样方法,平滑各个连续帧中的脉冲误差,减少每次迭代中的均方误差,从而完成高分辨帧的生成。He等[11]基于空间变换网络(STNet)获取投影变换矩阵的6个主要参数,将投影矩阵坐标系的坐标位置映射到原图的基空间并建立了车牌矫正的投影矩阵。Lin等[12]提出基于生成对抗网络的车牌图像重建方法,该方法引入残差密集网络并采用渐进上采样的方法在车牌图像的超分辨重构上取得了一定的效果,但是模糊车牌图像信息缺失的问题并没有得到改善,因此对于模糊情况较为严重的车牌图像重构效果不佳。Liu等[13]提出一种基于渐进式车辆搜索和域先验GAN的多车牌超分辨率识别方法,利用域先验GAN实现对车牌图像的重构任务,但是该方法并没有关注到倾斜车牌对于生成器的特征提取网络的影响。Zhang等[14]提出了一种多任务GAN框架用于对车牌图像进行超分辨率与识别,所提方法较好解决了常规车牌图像的重构问题,但是同样未能有效解决扭曲、倾斜车牌的重构问题。
综上所述,虽然基于深度学习的车牌图像重构任务中已经取得了显著研究成果,但在实际场景中由于原始车牌图像存在模糊、污损、扭曲、倾斜的问题造成车牌字符关键信息缺失,造成深度特征提取网络难以准确提取车牌识别的关键特征,此问题导致常规基于深度学习的车牌重构方法效果较差。
1 车牌图像超分辨率网络
1.1 网络结构
常规的基于深度学习的车牌超分辨率重建网络主要是利用CNN或GAN模型[15]研究高清图像(HR)和低清图像(LR)的非线性映射关系,并利用该映射关系实现LR车牌的分辨率恢复,然而此类方法没有考虑实际车牌图像存在的模糊、污损、扭曲、倾斜等干扰信息,这些强干扰信息常导致重构网络特征提取的困难,对于这些干扰信息所造成的车牌识别关键特征信息缺失问题,单纯增加车牌图像分辨率并不能有效恢复车牌原始图像。为解决这些问题,提出了一种编解码结构的车牌图像超分辨率网络。
所提网络由基于关键点回归的车牌矫正网络和基于生成对抗网络的车牌图像超分辨率重建网络两部分组成。基于关键点回归的车牌矫正网络利用VGG16提取车牌的4个关键点特征,然后基于投影变换原理对4个车牌图像关键点空间坐标进行回归预测,建立扭曲、倾斜车牌图像的投影变换矩阵,实现车牌图像的空间矫正;基于生成对抗网络的车牌图像超分辨率重建网络由基于编解码结构的生成器网络和基于多层卷积块的判别器网络组成。生成器网络由基于残差块连接的车牌特征提取网络与基于反卷积块连接的车牌分辨率恢复网络组成。车牌特征提取网络捕获输入的LR车牌图像的纹理、字符等特征;车牌分辨率恢复网络对模糊、污损的车牌特征图进行超分辨率车牌图像重建。判别器网络由卷积块组成,主要对生成器网络的生成图像进行质量评估。为了增强车牌生成器网络对车牌图像语义特征的表征能力,在损失网络中引入了对抗损失与CTC[16]损失。本文设计的网络模型整体结构如图1所示。

图1 网络整体结构图Fig.1 Schematic ofwhole network
1.1.1 车牌矫正网络
由于车牌图像扭曲、倾斜的程度越大,车牌图像特征提取效果越差[17],进一步导致了车牌重构能力效果变差。为了提升扭曲、倾斜的车牌图像重构效果,基于VGG16网络提出一种基于关键点回归的车牌图像矫正网络。该网络由基于VGG16的车牌特征提取模块与车牌投影变换模块两部分组成,网络结构如图2所示。
基于VGG16车牌特征提取模块由6个阶段组成,第1、2阶段主要提取车牌图像空间细节特征,如倾斜车牌顶角的空间特征与背景特征等;第3到第6阶段提取车牌图像的中、高级特征,如车牌的全局语义特征等。基于VGG16的车牌特征提取网络描述如下
Fo=σ(Wo*X+bo)
(1)
式中:X表示特征提取网络的输入车牌图像;Fo表示网络输出的车牌特征;σ为带泄露线性整流激活函数;*表示卷积操作;Wo为卷积核;bo为偏置数。
为提升分类器对车牌图像空间维度以及车牌图像边沿信息的感知能力,基于VGG16的车牌特征提取模块利用宽卷积层代替VGG16网络的全连接层,并构造车牌关键点分类器,然后对车牌顶角空间坐标进行分类预测,最后利用反归一化获得车牌四顶角坐标位置信息。分类器层可描述为
fpred{[sx,i,sy,i]}=h(Fo)
(2)
式中:h(Fo)为模型对车牌左上、右上、左下、右下4个顶角点的分类预测结果;[sx,i,sy,i]分别为每个顶角点的空间坐标;h(·)为该网络的分类器层。
车牌投影变换模块主要基于投影变换原理构造投影变换矩阵,完成车牌图像坐标空间的变换,实现倾斜、扭曲车牌图像的矫正。由VGG16车牌特征提取模块可得车牌图像中车牌的4个顶角点,然后输入车牌图像中原始顶角点与矫正后顶角点的位置信息,通过构建投影变换矩阵对倾斜车牌进行坐标空间变换,从而得到车牌矫正图像。车牌投影变换过程示意图如图3所示。
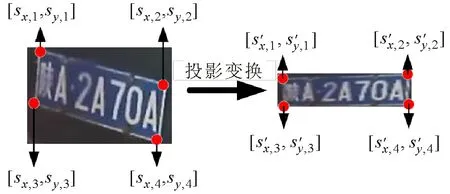
图3 车牌投影变换示意图Fig.3 Schematic of license plate projection transformation
令X表示输入的车牌图像,其大小为M×N。设VGG16车牌分类器模块输出的车牌图像4个顶角点坐标为[sx,1,sy,1]、[sx,2,sy,2]、[sx,3,sy,3]、[sx,4,sy,4],分别代表车牌左上、右上、左下、右下4个顶角点,假定投影变换后的对应像素点的空间位置为[s′x,1,s′y,1]、[s′x,2,s′y,2]、[s′x,3,s′y,3]、[s′x,4,s′y,4],则根据投影变换公式可得

(3)
式中:T为变换参数矩阵;mij为第i行第j列的变换矩阵参数。
由式(3)可知,根据每对坐标点构造4组方程即可求解出变换参数矩阵T,从而得到投影变换后像素点的空间位置坐标[s′x,i,s′y,i],求解过程为

(4)
1.1.2 基于生成对抗网络的车牌图像超分辨率重构网络
针对车牌成像的模糊、污损等干扰信息给车牌识别带来的挑战,设计了一种基于生成对抗网络的车牌图像超分辨率重构网络。所提网络由基于编码器-解码器的车牌生成器网络和基于语义监督的车牌判别器网络这两部分组成。基于生成对抗网络的车牌图像超分辨率重建网络的结构图如图4所示。
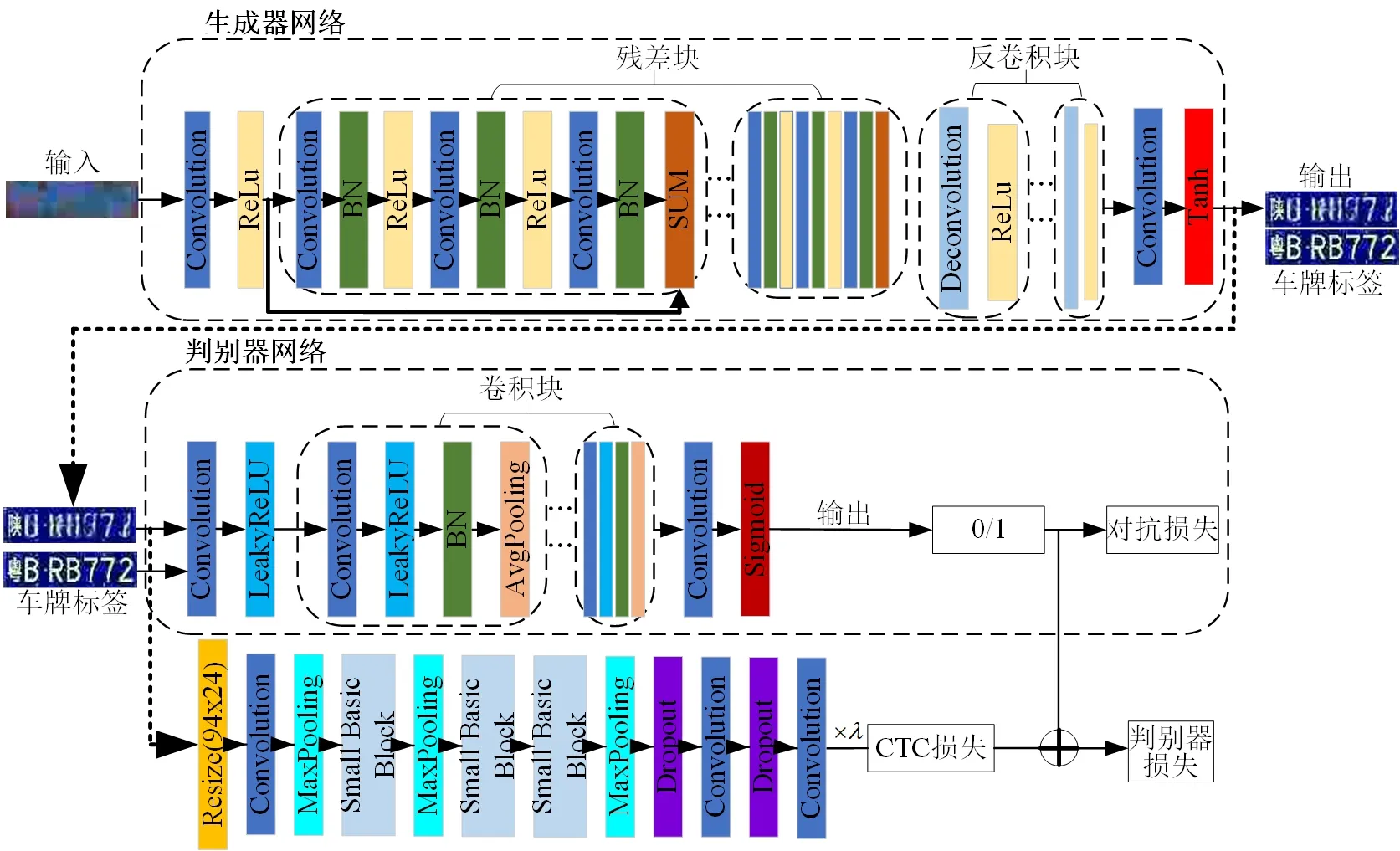
图4 基于生成对抗网络的车牌图像超分辨率重建网络示意图Fig.4 Schematic of super resolution reconstruction network for license plate image based on generative adversarial network
(1)基于编码器-解码器的车牌生成器网络。基于ResNet的特征提取模块的浅层阶段主要对车牌图像的空间细节特征进行提取,ResNet网络的浅层特征受车牌复杂背景干扰噪声影响,难以提取更多的车牌语义特征,而ResNet网络的深层阶段主要对车牌图像的高级语义特征进行提取,深层特征包含的背景噪声较少,因此能够提取到更多的车牌字符全局特征。为尽可能保留字符语义特征,消除复杂背景干扰噪声影响,所构造的反卷积结构只针对特征提取网络的最后1层(ResBlock4)进行重构。同时为了消除转置卷积造成的棋盘效应,本文采用使用双线性插值填充元素,再进行卷积的策略完成对特征图的分辨率恢复任务。构造的车牌生成器网络的残差块数均为2,残差块中卷积层数为2,卷积核大小为3×3。反卷积块的反卷积层数均为1,前3层反卷积层的卷积核为3×3,然后增加1个ReLu激活层,最后1层反卷积层的卷积核为2×2,其后为Tanh激活层。
(2)基于语义监督的车牌判别器网络。为了进一步增强生成器网络的重构能力,提高车牌判别网络对于车牌图像质量与车牌图像语义信息的判别能力,提出了一种基于语义监督的判别器网络。车牌特征判别网络由两阶段组成:第1阶段为全卷积特征提取,卷积层数分别为1、4、1,前5层卷积层的卷积核均为3,第1层后跟有带泄露修正线性单元(Leaky ReLu),中间4层带批归一化层(BN)和核大小为2的平均池化层;第2阶段由卷积核大小为1×7卷积层构成,其后跟有Sigmoid激活函数,实现判别器网络的判别预测任务。该网络通过在对抗损失中融合带权重的CTC损失,引导判别器网络进一步关注重构车牌图像的识别效果,从而增强重构网络对车牌语义特征的关注,提升生成器网络对车牌图像的特征表征能力。
1.2 损失函数
1.2.1 车牌矫正网络损失
建立车牌矫正网络损失的目的是量化评估网络预测车牌4个关键顶角点空间坐标值与其真实标签值的损失。车牌矫正网络的平滑平均绝对误差损失函数定义为
(5)

1.2.2 基于生成对抗网络的车牌图像超分辨率
重构网络损失
判别器网络损失主要来自于生成器网络生成的车牌图像与标签图像的误差,生成器网络的损失主要来自于生成器网络生成的车牌图像与标签的误差和判别器网络损失,即

(6)

(7)

生成器网络生成车牌图像的质量取决于判别器网络的判别能力,为了增强判别器网络对车牌图像语义信息的关注,所提损失函数在对抗损失的基础上引入带权重的CTC损失,从而加强了重构网络对车牌语义信息的关注,所提生成器网络损失和判别器网络损失为

(8)
(9)

2 实验结果与分析
2.1 实验数据集
实验数据集采用中国城市停车数据集(Chinese city parking dataset,CCPD)[18]和XAUAT-Parking自建数据集。CCPD各类子数据集如表1所示。

表1 CCPD数据集
近年来新能源车辆迅速增多,而现有车牌数据集中,蓝色车牌数量占据主导,新能源车牌的占比少。由于两类车牌长度不一致且外观颜色相差较大,在训练样本不充足的情况下常规深度学习网络难以有效提取绿色车牌特征,从而导致基于常规深度学习网络的车牌重建算法的泛化能力较弱。为了解决上述问题,自建XAUAT-Parking数据集、XAUAT-Parking数据集共有40 795张车牌车辆数据,大小约为1 536×960像素,主要涵盖了不同实际场景下的停车场进出卡口的各种车牌图像数据,其中蓝色车牌30 158张,新能源绿色车牌10 637张。该数据集不仅涵盖了各类实际场景下停车场进出口的蓝绿色混合车牌图像数据,而且具有大量较大差异的蓝绿色混合车牌数据。因此,自建数据集可以有效验证基于不同深度学习网络的车牌识别算法的鲁棒性。
2.2 训练设置
实验平台搭载Inter Xeon E5 2650处理器,376 GB内存,4个NVIDIA 2080Ti 12 GB显卡;深度学习框架采用pytorch-1.8、NVIDIA公司CUDA11.2的GPU运行平台以及cuDNN8.0深度学习GPU加速库。网络训练过程中,本文所提网络设置训练批数量为256、轮数为51、初始学习率为0.001,使用Adam优化器进行优化。网络训练过程中,学习率调整策略采用每10个epoch指数衰减一次,衰减系数为0.1。
2.3 实验量化指标及分析
为验证车牌重构后的效果,采用峰值信噪比(PSNR)[19]、结构相似性(SSIM)[20]进行量化评估。同时,为进一步对比验证本文所提车牌图像超分辨率重构算法的有效性,采用LPRNet作为车牌字符识别网络来验证车牌重构前后的车牌识别效果。PSNR指标定义为

(10)

(11)
式中:CMAX为图像颜色的最大值;EMS为均方误差;L(i,j)、P(i,j)分别为坐标(i,j)处的标签车牌图像与重构车牌图像像素强度值;M、N分别为车牌图像的宽、高。结构相似性(SSIM)指标分别从亮度、对比度、结构3方面度量图像相似性。结构相似性(SSIM)指标定义为
ISSIM=l(P,L)×c(P,L)×s(P,L)
(12)
式中:l(P,L)、c(P,L)和s(P,L)分别为重构车牌图像P及标签车牌图像L的亮度相似性、对比度相似性和结构相似性。
2.4 消融实验
为进一步验证所提网络中各模块的作用,在XAUAT-Parking数据集上开展消融比对实验。消融实验主要从重构后的PSNR、SSIM指标以及重构后基于LPRNet的识别率两方面进行对比,各变种的相关参数设置和训练策略均相同,消融实验对比结果如表2、3所示,表中KPRN表示车牌矫正网络,SRRN表示车牌图像超分辨率网络。同时,为了验证损失函数中的加权超参数ω、λ对超分辨率重建效果的影响,进而确定超参数ω、λ的最优或较优取值,以XAUAT-Parking数据集为例,图5给出了PSNR与SSIM指标随ω、λ的变化情况。

表2 XAUAT-Parking数据集上本文提出各子网络超分辨率重建消融实验的结果

表3 XAUAT-Parking数据集上不同网络识别率消融实验的结果
从图5可以看出,当超参数ω、λ分别取1.1、1.35时,网络的性能最优。通过对于超参数的实验验证,可以看出ω≤1、λ≤1.3时较为显著影响了网络的性能,同时在ω≥1.2、λ≥1.4时,网络的性能同样出现了下滑,所以超参数的ω的较优取值区间应该为[1.05,1.2),λ的较优取值区间应该为(1.3,1.4)。实验中ω统一选择为1.1,λ统一选择为1.35。

(a)λ对PSNR的影响 (b)λ对SSIM的影响
2.5 CCPD数据集对比实验
为了验证所提网络对车牌重构的有效性,在CCPD数据集中采用本文所提网络分别与SRGAN、VDSR、REDNet、DPGAN等[21-22]网络进行了重构效果对比。同时,为进一步验证重构后的车牌图像对车牌识别率的有效性,所提网络分别与文献[23-24]所提网络进行了重构后车牌识别率对比实验,所有对比网络采用相同的LPRNet作为车牌识别网络。
图6为CCPD数据集部分矫正重构结果,图6中,各子图从左到右,第1列Input为输入车牌图像,第2列Correction为矫正后的车牌图像,第3列到第6列分别为SRGAN、VDSR、REDNet、DPGAN等算法的车牌重构图像,第7列Ours为本文所提网络的重建车牌图像,第8列Ground Truth为真实标签图像。
从图6可知,相较于SRGAN、VDSR、REDNet、DPGAN等对比算法,本文所提网络能更好地解决不同噪声影响下的车牌成像模糊问题,实现较高质量的车牌图像重构。由图6(e)、6(f)可知:对于光线变化大、光照过暗与成像过曝光情况的车牌图像,SRGAN算法在较差的光照与曝光条件下车牌重构效果受各种背景噪声的影响较大;VDSR算法受过曝光影响显著降低了车牌重构效果;REDNet、DPGAN重构效果虽然优于SRGAN和VDSR算法重构效果,但是REDNet、DPGAN在重构后车牌图像中的字符中仍然出现部分字符模糊现象。最具挑战的车牌图像如图6(g)所示,车牌图像中一般为运动模糊、过曝光、模糊等多种噪声的叠加,同时车牌图像中也包含明显的距离变化,这些因素导致SRGAN、VDSR、REDNet、DPGAN等对比算法在对此类极端条件下的车牌图像进行重构时效果较差,而本文设计的网络通过引入语义监督与生成对抗的方法,有效消除了车牌图像的背景噪声,同时加强了生成网络对于语义特征与空间纹理信息的提取能力,因此在重构效果上明显优于SRGAN、VDSR、REDNet、DPGAN等对比算法。

(a)Tile子数据集对比结果
在CCPD的Challenge子数据集中重建结果的定量分析如表4所示,定量分析所采用的指标主要是PSNR和SSIM,由表4可知,所提车牌图像超分辨率网络在推理速度指标平均值为61,PSNR平均值为25.5 dB,SSIM平均值为0.988。第1~4行分别为SRGAN、VDSR、REDNet、DPGAN等对比算法重构量化指标。实验表明所提算法在CCPD数据集具有较好的重构效果,相较于SRGAN、VDSR、REDNet、DPGAN等对比算法,指标PSNR分别提升了48%、63%、14%、58%,指标SSIM分别提升了17.6%、8%、2.9%、15.5%。

表4 不同网络在CCPD Challenge子数据重构定量对比
不同网络在CCPD数据集中的识别率定量对比如表5所示。 由表5可知,本文所提网络重构后的车牌图像在CCPD数据集上有较高的识别准确率,尤其对于具有较大水平、垂直倾斜以及模糊干扰的Rotate、Tilt、Blur数据集有较好的效果,准确率分别达到了98.7%、97.8%和95.7%。对比文献[27]所提算法,在Rotate、Tilt子数据集上提升了3.8%、1.4%,在Weather、Challenge子数据集上提升了2.3%、7%;与文献[17]所提网络相比,在Rotate、Tilt子数据集上提升了6.4%、1.4%,在Weather、Challenge子数据集上提升了0.1%、4.4%。

表5 不同网络在CCPD数据集上的识别率定量对比
2.6 XAUAT-Parking数据集对比实验
自建XAUAT-Parking数据集部分矫正重构对比结果如图7所示,停车场进出场蓝绿色车牌数据集的重构效果图中,从左到右第1列Input为输入车牌图像,第2列Correction为矫正后的车牌图像,第3列Reconstruction为重构车牌图像,第4列Ground Truth为标签图像。由图7可知,所提算法不仅能较好解决字符污损、车牌扭曲、倾斜的蓝色车牌的重构问题,而且对于车牌扭曲、模糊、倾斜与字符磨损、污损的新能源绿色车牌也能进行高质量重构。

图7 XAUAT-Parking数据集部分重构结果Fig.7 Results of partial reconstruction of the XAUAT-Parking dataset
XAUAT-Parking自建数据集中重构结果的定量分析如表6所示,定量分析所采用的指标为PSNR和SSIM,由表6可知,入场车牌数据集SSIM指标平均为0.991,PSNR指标平均为26.2 dB;出场车牌数据集SSIM指标平均为0.997,PSNR指标平均为26.6 dB。

表6 XAUAT-Parking数据集重构定量分析
同时为了验证重构后的车牌图像对车牌识别率提升的有效性,对XAUAT-Parking数据集车牌图像进行重构后,利用LPRNet算法对重构车牌进行识别,实验结果如表7所示。由表7可知,所提算法在XAUAT-Parking数据集上有较高的识别准确率,平均识别率达到了97.5%。原始LPRNet算法加入提出的车牌关键点矫正模块后识别率也有显著的提升,平均识别准确率提高了2%~3%,7位蓝色车牌的识别率达到99.3%,对比原始LPRNet识别率提高了5.7%;8位绿色车牌的识别率达到96.1%,对比原始LPRNet识别率提高了6.9%;7、8位混合车牌的识别率达到97.3%,对比原始LPRNet识别率提高了6.3%。因此,从定性指标上分析可知,所提车牌图像超分辨率算法对于复杂实际场景下的停车场进出场车牌图像有着较好的重构能力。

表7 XAUAT-Parking数据集识别定量对比
3 结 论
针对复杂实际场景中模糊、污损、扭曲、倾斜车牌图像的重构问题,提出了一种编解码结构的车牌图像超分辨率网络。所提算法首先利用投影变换方法设计了一种车牌矫正网络,对扭曲、倾斜车牌图像进行有效矫正;然后设计了基于编解码结构的车牌图像超分辨率网络,对模糊、污损等难以识别车牌图像的关键特征进行提取,并利用基于反卷积块的车牌分辨率恢复模块实现了车牌图像的重构。通过在公开数据集CCPD和自建数据集XAUAT-Parking上的定量、定性实验证明了所提算法的有效性和鲁棒性。
