改进YOLOv5网络的轻量级服装目标检测方法
2022-11-01陈金广邵景峰马丽丽
陈金广,李 雪,邵景峰,马丽丽
(1.西安工程大学 计算机科学学院,陕西 西安 710048;2.西安工程大学 管理学院,陕西 西安 710048)
人工智能和服装电子商务的结合日益密切,服装图像检索、智能服装搭配等技术应用广泛,但这些应用通常依赖于高质量的服装目标检测技术。与此同时,服装具有柔性特质,极易发生形变,传统的机器学习方法主要通过目标轮廓提取、边缘检测等方法提取特征,再使用贝叶斯、支持向量机等分类器对物体进行模式识别[1-2]。这种传统的特征提取方法鲁棒性不佳。
基于深度学习的目标检测技术具有在较大规模数据集上自动提取图像特征的能力,能够充分挖掘图像信息,较传统方法,减少了人工干预,并且检测精度得到很大提升,受到了广泛关注。Faster-RCNN[3]、Mask-RCNN[4]等两阶段目标检测算法,通常检测精度高但检测效率较低、模型参数量较大,难以在实际场景中得到普及;而单盒多框检测器(SSD)[5]、YOLO等一阶段目标检测方法,检测速度快,检测精度较高,具有更强的实用性。文献[6]提出基于尺寸分割和负样本增强技术的SSD改进算法,能够识别不同的西装目标。文献[7]针对模型占据大量计算资源的问题,提出轻量级服装目标检测模型,为服装目标检测提供一个实用的研究方向。
本文从减少模型参数量和浮点型计算量的角度出发,提出一种改进的轻量级服装目标检测模型,使用移动网络重新构建YOLOv5的主干网络,对于训练集中个别服装类别数据量较少的问题,使用数据增强技术进行数据扩充,并在训练阶段使用标签平滑(label smoothing)防止模型过拟合,研究改进后的模型轻量化程度以及对服装图像的目标检测效果。
1 MV3L-YOLOv5网络结构
MV3L-YOLOv5服装目标检测网络主要包含输入端、主干网络、Neck网络以及预测端4个部分,结构如图1所示。
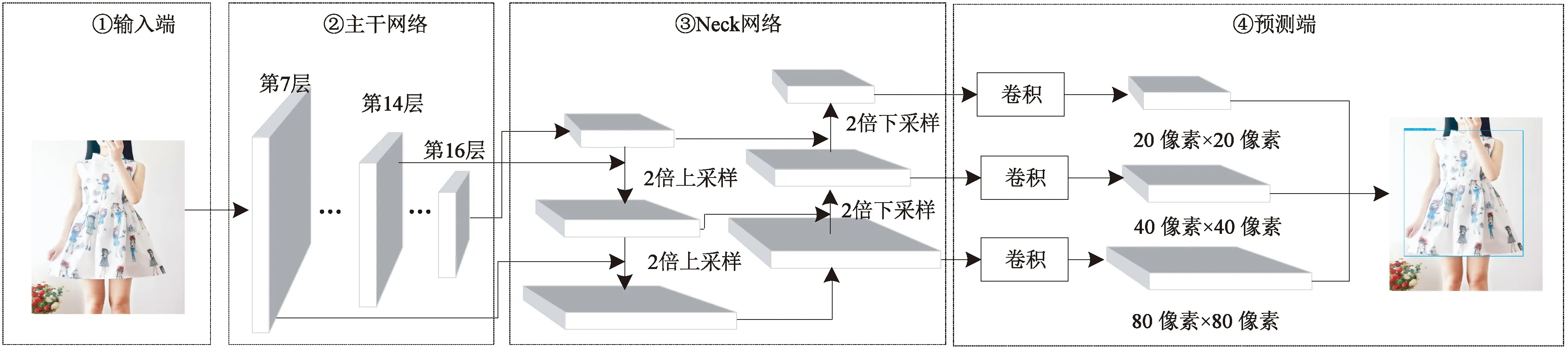
图1 MV3L-YOLOv5网络结构
第1部分是输入端。主要使用了马赛克(Mosaic)图像增强。该方法一次性随机选择4张图片,通过剪裁、缩放等方式将其拼接成一张图片,再送入深度网络中进行训练。Mosaic方法有利于加速网络收敛。
第2部分是主干网络。使用轻量化的MobileNetV3_Large[8]结构重构YOLOv5的主干网络,经过MobileNetV3_Large提取图像特征后,将网络的第7、14以及16层的输出特征图作为Neck网络的输入特征图。
第3部分是Neck网络。该部分将特征层构造成特征金字塔[9](FPN)结构以及路径聚合网络[10](PANet)中的PAN结构。首先,FPN自顶向下将高层语义特征传递到底层;然后,FPN结构后面再添加2个PAN结构,将底层的强定位信息传递到高层,所以整个Neck网络能够同时融合浅层和深层特征信息。
第4部分是预测端。以640像素×640像素的输入图像为例,Neck网络输出的多尺度特征再经预测端的卷积操作后,输出特征尺寸分别为80像素×80像素,40像素×40像素和20像素×20像素。输出不同尺度的特征用来进行目标分类和回归预测,分别检测小、中等以及大的服装目标。
2 标签平滑
过拟合问题在深度学习中比较常见,是指模型在训练集上表现很好,而在未参与训练的数据上表现较差,说明模型鲁棒性不高,难以适应新的数据。数据样本较少或者模型过度训练都可能导致模型的过拟合。此外,数据集中若存在少量错误标签,同样会影响到模型训练以及预测准确度。本文使用标签平滑策略缓解服装目标检测模型的过拟合问题。
3 实验与结果分析
3.1 数据集处理及评价指标
DeepFashion2[11]是一个公开的大型服装数据集,下载到本地的图片共约30万张,包含13种服装类别。数据准备时发现,DeepFashion2中类别数量分布不够均衡,如训练集中,包含短袖衫的图片筛选出7万多张,而包含短袖外衫的图片仅筛选出500余张。为缓解这一现象给模型训练带来的影响,将该数据集作如下处理。
首先,将带有标签文件的训练集图片按照类别进行分类;然后,针对每种服装类别,分别进行随机抽取,抽取过程中根据每种服装类别的数据量大小适当调整抽取比例(短袖外衫数据过少,保留全部图片),并将抽取好的图片再次混合;最后,将混合好的训练集图像对应的标签文件转成MV3L-YOLOv5网络能够识别的格式,得到训练集数据。验证集同样进行如上处理。
此外,在未给标签文件的测试集中筛选出短袖外衫这一类别的图片,并进行水平反转、裁剪、倾斜、噪声、模糊等数据增强操作,将该类别图片由原来的500多张增加到800多张,数据增强前后图像对比效果如图2所示。使用LabelImg工具将没有标签的图像进行手工标注,并补充到训练集中,最终得到训练集图片15 205张,验证集图片7 763张。处理好的数据集中,服装各类别数量分布如表1 所示。

图2 数据增强图片示例

表1 训练集和验证集中服装目标的数量分布
采用精确率P、召回率R、平均检测精度PA以及平均检测精度均值PmA作为模型的评价指标,计算公式如式(1)~(4)所示。
(1)
(2)

(3)
(4)
式中:NTP为将正例预测为正例的个数;NFP为将反例预测为正例的个数;NFN为将反例预测为反例的个数;PA为模型对单个类别的平均检测精度;PmA为模型对数据集中总类别的平均检测精度均值;N为数据集中的类别总数,在本文中N为13。PA和PmA的数值越大表示模型检测效果越好。
3.2 模型训练
实验环境:Intel(R)Xeon(R)CPU E5-2630 v4@ 2.20 GHz;GPU型号为TITAN XP,使用CUDA9.2进行加速;操作系统为Ubuntu16.04;深度学习框架版本为Pytorch1.7.1。
参数设置:模型采用多尺度训练方法,初始学习率为0.01,warm_up为3,权重衰减系数为0.000 5,使用随机梯度下降法(SGD)进行优化,动量等于0.937,标签平滑指数设置为0.001,batch_size等于16,总训练轮数为600轮。
模型训练时的损失由置信度损失、类别概率损失以及边界框回归损失3个部分组成,MV3L-YOLOv5模型使用二值交叉熵损失计算前两部分的损失;采用完全交并比损失(CIoU Loss)[12]计算边界框损失值,该损失计算公式如式(5)~(7)所示。
(5)
(6)
(7)
式中:b和bg分别为预测框和真实框的中心点坐标;ρ(b,bg)为预测框和真实框2个中心点间的欧式距离;c为两框之间的最小外接矩形的对角线长度;wg和hg分别为真实框的宽和高;w和h分别为预测框的宽和高;pIoU为两框之间的交并比。
MV3L-YOLOv5模型训练过程中的损失L以及平均检测精度均值PmA变化曲线如图3所示。可看出:在训练约500轮以后,损失基本不再下降,说明此时模型基本达到收敛,PmA值也趋于稳定。

图3 模型训练损失和平均精度均值PmA变化曲线
3.3 模型验证与分析
使用验证集对模型进行验证,得到模型改进前后在每种服装类别上的PA值,数据对比如表2所示。
由表2可看出,MV3L-YOLOv5模型的PA值普遍高于改进前YOLOv5s模型的PA值;短袖衫和长裤2种类别的PA值均达到了90%以上,同时MV3L-YOLOv5对吊带、长袖连衣裙以及吊带裙这 3种类别的检测精度提升较为明显。通过观察服装数据集可知,吊带和背心,吊带裙和无袖连衣裙图像本身就具有很大的相似性,特征提取较为困难,YOLOv5s对此类目标的检测效果一般,而MV3L-YOLOv5能够提高吊带和吊带裙的PA值,说明该模型挖掘到了更深层次的服装特征信息,能够更好地区分出这 2种服装类别。

表2 模型改进前后在每种服装类别上的PA值对比
3.4 模型对比分析
使用上文处理过的服装数据集同时训练并验证了其他YOLO系列的检测模型,模型结果及性能对比分别如表3、4所示。

表3 模型训练结果对比

表4 模型性能对比
结合表3、4可看出,对比YOLOv5s网络,MV3L-YOLOv5 的PmA提高了1.3%;参数量和浮点型计算量分别下降了27.8%和39%;模型体积压缩了26.4%;综合对比MV3L-YOLOv5、YOLOv5s、YOLOv4-Tiny以及YOLOv3-Tiny这4种轻量级网络,MV3L-YOLOv5网络整体性能表现最优。MV3L-YOLOv5和网络结构较大并且占用计算资源也较多的YOLOv5l、YOLOv3-SPP相比,PmA虽然有所下降,但其参数量、浮点型计算量以及模型体积约为这些大型网络的十分之一,并且推理时间约为二分之一,对比之下MV3L-YOLOv5对计算资源的占用更低。
YOLOv5s与MV3L-YOLOv5这2种模型的服装目标检测效果对比如图4所示。当服装遮挡比较严重或目标之间特征区分不够明显时,MV3L-YOLOv5对服装的漏检、误检的情况对比YOLOv5s有所改善。

图4 2种模型的服装目标检测效果对比
4 消融实验
该部分的消融实验将YOLOv5s、以MobileNetV3_Small作为主干网络的YOLOv5和本文所提出的MV3L-YOLOv5网络进行对比,主要实验使用标签平滑(记为LS)策略以及不同的非极大值抑制方法对模型产生的影响,证明改进的服装检测模型的有效性。目标检测任务通常使用标准非极大值抑制(NMS)、柔性非极大值抑制(Soft NMS)以及加权平均非极大值抑制(NMW)等方法将网络预测端绘制的多余的预测框滤除。消融实验的设计如表5所示。消融实验结果如表6所示。表中最后1列处理时间表示分别使用NMS、Soft NMS以及NMW方法滤除多余预测框的操作所消耗的时间。

表5 消融实验设计
对比表6中的①②、③④和⑦⑧可知,引入LS后,YOLOv5s、MobileNetV3_Small-YOLOv5以及MobileNetV3_Large-YOLOv5网络的PmA分别提升了0.3%、0.2%和0.1%,实验结果证明使用LS对网络的PmA有提升作用。对比⑤⑥⑧可知,使用Soft NMS或NMW的网络处理多余预测框的处理时间比MV3L-YOLOv5少了数倍,并且PmA也有略微的下降。对比①③⑦可看到,使用MobileNetV3_Small作为YOLOv5的主干网络,虽然模型体积最小,但PmA比YOLOv5s低了3.9%,模型的检测性能损失较大,而MobileNetV3_Large作为YOLOv5的主干网络,PmA比YOLOv5s提升1.2%,模型体积依然减少了3.67 MB。综上考虑,MV3L-YOLOv5模型使用MobileNetV3_Large构建主干网络,引入LS策略,并采用标准的NMS滤除多余预测框。

表6 消融实验结果
5 结 论
为进一步减少服装目标检测模型对计算资源的占用,本文提出了一种改进YOLOv5网络的轻量级服装目标检测方法。使用MobileNetV3_Large构建YOLOv5的主干网络;在训练阶段引入标签平滑策略来校正模型;针对服装图像较少的类别,使用数据增强技术扩充数据量。模型经训练和验证表明,改进后的模型有效降低了运行所需的参数量和浮点型计算量,对比表3中已有的检测方法,检测准确率有所提升并且模型较为轻量,更适合在移动或嵌入式设备中使用。
