基于自然语言处理技术和蓝光存储技术的电网数据池构建研究
2022-11-01陈珊珊
陈 骏,刘 敏,陈珊珊,王䶮飞
(江苏苏星资产管理有限公司,江苏 南京 210000)
0 引言
电网业务数据规模的不断扩大,对数据池整体性能提出了更高要求[1]。目前学术界的相关研究已经积累了一定的研究成果,文献[2]利用三维可视化技术方法构建了数据分析模型,提供了较好的分析性能,但是其模型中的数据池储存容量较小,导致响应速度较慢。文献[3]根据区块连接技术进行智能电网数据管理,内容中设计出了较为完善的数据池管理模式,但是由于自然语言处理不到位,所以响应速度慢的问题没有得到有效改善。将基于可视化技术的数据构建模型和基于区块连接技术的数据管理模型融入电网数据池构建,致力于改善电网数据池响应速度较慢的问题,对此展开讨论。
自然语言处理技术是一门融语言学、计算机科学和数学为一体的科学,将自然语言处理技术应用于电网数据池构建,为用户简化了相关使用步骤。蓝光储存技术是一种应用蓝色激光,以改变无机物相位的方式对光盘上的存储载体进行照射与扫描,以此获取数据信息的一种技术,其优势在于存储密度大,存储能耗低并且介质寿命长,能更加广泛地应用到相关领域中。
1 电网数据池构建
1.1 获取电网数据分布式特征
电网业务中的数据结构类型主要包括实时型、关系型以及文本型数据,主要来源是发电、输电、变电、配电以及用电等环节。其中,实时数据主要是来自电力调度环节,是一种经过综合处理后得出的数据。关系型数据主要是相关的管理人员进行参考,并完成相应任务的数据,通常与蓝光存储技术相融合,主要是产生于投资统计数据和电能量信息采集[4]。文本型数据一般是依托自然语言处理技术,包括各环节的操作说明、数据类型描述等。通常情况下,电网数据池需要联合电力发展部门、营销部门、运检部门和调控中心等部门的相关参数进行数据分类[5]。电网数据的分布式结构示意图如图1所示。

图1 电网数据分布式结构示意图
在电力行业的实际发展过程中,电网数据的来源和类型都比较多,包括时间序列数据、文本信息以及图像视频等,不同类型数据的特征空间也不同[6]。为了提高电网数据池的数据质量,需要提取相对稳定并且有效的特征[7]。在原始的数据集合中,筛选出相关的特征数据子集进行数据预处理,选定特征子集后,需要判断数据子集的数据质量,经过双向搜索后,排除无关特征[8]。将给定数据集设定为Q,在数据集Q中,存在着一个i类型样本数据集,并且在总数据集中的占比可表示为qi= {q1,q2,q3,…}i=1, 2, 3,…。若数据集特征皆为离散性数据,设定特征子集为C,根据C的取值范围将Q划分为e个子集,则二者关系可表达为{Q1, Q2, Q3,…, Qe},若特征子集中的数据样本在C上的取值范围相同,则特征子集C的信息评价公式为:

式中:H表示数据集的离散指数;G(C)表示特征子集的信息评价。数值越大,则表示特征子集C中包含的特征信息就越多。在保证数据信息精确性与完整性的前提下,将电网数据通过数学变换得到简化后的表达方式:

式中:以数据线性特征为基础,k∈Lt表示原始特征向量;P∈Lk×t为变换矩阵;k'∈Pk表示线性变换后的特征向量。应用式(2)可以将电网数据的分布式特征具体量化,从而为数据池构建提供数据基础。
1.2 计算数据节点安全等级
电网数据安全是数据池构建效果的主要影响因素,设定电网数据的输入量与输出量共同构成了整个电网数据的数据样本空间,在此空间内的数据通常是输入量大于输出量,并且每个具体的数据都可以用向量表示[9]。将样本空间用线性空间和非线性空间表示,其函数表达式如式(3)所示:

式中:f(y∶λ)为参数λ的函数;λ表示相应的函数线性组合;R表示样本矩阵。在电网运行过程中,电力负荷是影响电网数据质量的关键因素之一,主要受到各种时间、天气以及经济指标影响,利用历史数据信息和相关的特征因素进行预测[10]。其表达式如式(4)所示:

式中:电网数据真实节点的防御等级为wn;被攻击的概率为u,并且满足w+u≥1的条件;n表示安全指数。当电网数据的扩展能力满足分布需求时,电网数据真实节点的期望值可表 达为:

式中:β表示电网数据的发展模块,则电网数据真实节点安全性的表达式为:
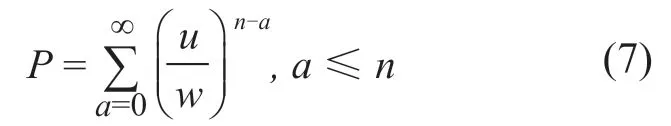
式中:p表示电网数据真实节点的安全等级;a表示相应的数据空间。则电网数据安全可以通过计p的数值来获取,为数据池构建提供安全等级高的数据。
1.3 利用自然语言处理技术标注数据信息
将自然语言处理技术与蓝光储存技术应用到电网数据池构建中,根据相应的技术原理进行电网数据处理[13]。自然语言处理技术在计算机中通常表现为字符串序列,包括语法分析、语义分析和语用分析等要素[14]。用V = {v1,v2,v3,…,vn}表示语句分词后的单词序列集合,词性序列集合用Y = {y1,y2,y3,…,yn}表示,词性标注的含义就是在所有相关的语句中,寻找一个对于V来说最优的Y,并且y1是v1的词性。其中,yi∈ Sy,i=1, 2, 3,…,n,Sy表示词性集合的标注集。在词性标注过程中,将完成标注的文本当成是数据样本集,可观察层包括词语序列,隐藏层包括词性序列,而待标注的词语通常情况下,在其前后都各有一个或多个非兼类序列标签,具体如图2所示。

图2 待标注的兼类词序列
根据图2可以看出,待标注的兼类词附近都有若干个标签,以便对数据集进行语义和序列调整。在最终标注结果为所有可能标注序列中最优结果的理论基础上,则:

式中:Ym表示最终的标注结果集合;P表示被标注的概率。则:

式中:P(V)代表电网数据集中的常数,若式(9)成立,则式(8)变为:

至此,有效将电网数据的文本信息标注问题转化为公式识别与计算问题。将电网数据的文本文档信息应用自然语言处理技术进行标注处理,为电网数据池构建提供语义信息。
1.4 运用蓝光存储技术布局数据存储密度构建数据池
蓝光储存技术包括认证节点、代理节点和存储节点,认证节点主要负责对电网数据进行反馈信息认证,并设定有效时间;代理节点主要负责将通过认证的电网数据进行请求信息和分发任务管理;存储节点主要负责将电网数据以账户、对象、容器以三层结构进行逻辑架 构[15-17]。由于电网数据的规模较大且比较密集,若电网数据未经过处理就直接放入数据池会造成提取步骤繁琐的问题,运用蓝光存储技术,计算电网数据样本集的密度分布概率以及带宽参数的数值对电网数据密度的影响。函数表达式如下:

式中:x1,x1,…,xc表示电网数据中未知概率g的样本数据集;h(x,xc)代表核函数。当满足核函数的对称性要求时,其积分和等于1[18-19],则:

式中:δ表示带宽参数。带宽参数的数值大小会影响电网数据集的密度分布概率,当数值过小时,数据集整体偏差降低,估计结果较不稳定;当带宽参数的数值过大时,数据集的整体偏差变大,导致电网数据过于密集,不符合电网数据池的构建要求,因此需要将式(12)的计算结果控制在0~1的范围内[20-21]。综合上述描述与计算,实现基于自然语言技术与蓝光储存技术的电网数据池构建。
2 实验研究
2.1 搭建实验环境及参数设置
实验选取两种传统电网数据池构建方法(文献[2]方法和文献[3]方法)与此次设计的构建方法进行实验对比,得出实验结果。根据实验需求搭建实验环境以及设置相关参数,操作系统使用Windows8.1,SybaseIQ16.0,并且使用C#语言作为电网数据集语义分析的工具,同时,其他相关配置见表1所列。

表1 实验设备配置
根据上述实验环境,进行实验参数设置。由于单个模块的容量直接影响着数据池的响应速度,因此分别对电网数据池的扩展模块、移植模块、伸缩模块、以及共享模块的容量进行设置。随着电网业务的不断更新与发展,对应的电网数据池的扩展模块参数也需要不断更新,在出现新的业务需求时,可设定标准区域与非标准区域,二者之间的区别在于标准区域内的参数是固定的不能修改。非标准区可修改部分参数具体见表2所列。

表2 扩展模块容量参数设置
电网数据池的移植模块主要负责数据池数据的底层数据交换,在数据平台与格式发生变化时,无需再进行整体数据池重构,具体参数设置见表3所列。

表3 移植模块容量参数设置
一旦出现了新的电力业务,电网数据池需要具备相应的伸缩能力,实现数据的新建、删除和提取等操作。即便是用户操作失误的情况下也能确保用户历史数据完整无损,具体参数设置见表4所列。

表4 伸缩模块容量参数设置
在保证电网数据标准化的基础上,根据相应需求提取数据池的数据,具体参数设置见 表5所列。

表5 共享模块容量参数设置
2.2 电网数据池响应时长测试
分别对比基于可视化技术的数据构建模型(以下简称“当前构建方法1”)和基于区块连接技术的数据管理模型(以下简称“当前构建方法2”)的电网数据池与此次基于自然语言处理技术与蓝光储存技术构建的电网数据池,在不同的用户并发数下的响应时长,测试结果如 图3所示。

图3 响应时长测试结果
根据图3可以得出基于可视化技术的数据构建模型、基于区块连接技术的数据管理模型以及此次构建的电网数据池在不同的用户并发数条件下的响应时长,并求出三种构建方法下电网数据池响应时长的平均值,具体见表6所列。

表6 响应时长均值ms
此次构建的电网数据池响应时长在5000~20000用户并发数的测试条件下,其响应时长的平均值分别比当前两种构建方法下的电网数据池少2.82 ms和3.58 ms,证明此次融合了自然语言处理技术与蓝光储存技术的电网数据池响应时长更短,说明该方法构建数据池的速度更快,性能更佳。
3 结语
为改善现有的区块连接下的数据管理方法响应速度较慢问题,提出基于自然语言处理技术和蓝光存储技术的电网数据池构建方法。预测电力负荷,计算数据节点的安全等级,利用自然语言处理技术标注电网数据信息,实现电网数据池构建。
经过实验测试可知,在5000~20000用户并发数的测试条件下,研究构建的电网数据池响应时长的平均值分别比两种传统方法缩短了2.82 ms 和3.58 ms,验证了本文数据池速度更快,性能更佳。
但由于研究时间的限制,本次研究还存在缺乏统一数据管理平台的缺陷。为了进一步提升配电网发展业务信息化水平,在日后将针对此问题不断深入研究。
