基于高光谱成像的羊肉掺假可视化无损定量检测
2022-11-01赵静远张俊芹陈兴海刘业林
赵静远 张俊芹 孙 梅 陈兴海, 刘业林,
肉类主要包括畜禽类和水产品类,人体所需的蛋白质、脂肪酸、微量元素等重要能量物质都来源于肉类[1]。随着生活水平不断提高,人们在饮食方面更加注重食品的品质和营养均衡搭配,但一些不法商家将一些低品质的肉类混入高品质肉类中,以次充好,特别是2013年欧洲的“马肉风波”,引发了人们对肉类掺假问题的极度关注[2-3]。肉类掺假检测方法包括感官评测、荧光PCR检测技术、电泳分析法和酶联免疫分析技术等,但大多需要样品前处理,试验操作较为繁琐且费时费力,很难实现较大样品量的现场快速实时检测[2-4]。
高光谱成像技术作为一种能同时表征一维光谱信息和二维空间性信息的综合无损检测技术,已被广泛应用于医药[5]、农业[6]、生态保护[7]等行业。在肉类掺假检测方面,朱亚东等[8]利用近红外高光谱成像技术结合线性回归算法(MLR)建立了牛肉中掺假鸡肉的定量检测模型;刘友华等[9]对羊肉中掺假猪肉在390~1 040 nm波段范围内进行了高光谱图像的采集,最终利用竞争性自适应重加权算法(CARS)挑选出42个波长建立了羊肉掺假定量模型;Zhao等[10]基于可见—近红外高光谱对新鲜牛肉中掺假变质牛肉进行识别,最终利用入侵杂草优化算法(IWO)结合最小二乘支持向量机算法(LS-SVM)建立的模型效果最优;进一步证明了高光谱无损检测技术在肉类品质检测中的可行性。
现有文献研究报道大都采用单一波段的高光谱成像技术对肉类掺假进行判别,但少有同时采用两个波段进行对比分析。试验拟选取高品质解冻状态下的羊肉为掺假对象,以价格相对较低的鸭肉进行掺杂,采集样品在可见—近红外(400~1 000 nm)和短波近红外(900~1 700 nm)两个波段范围内的高光谱信息,通过选取合适的预处理方法建立定量模型,并选取最优的模型进行图像反演,提出一种快速检测羊肉掺假鸭肉的快速定量检测可视化方法,以期为羊肉掺假的定量检测提供数据和技术支撑。
1 材料与方法
1.1 试验样品
新鲜羊肉、鸭肉:京东7fresh生鲜超市,在1 h内全程低温贮藏运回实验室。
1.2 试验设备
高光谱设备:GaiaSoter-Dual型,GaiaField-Pro-V10E型,GaiaField-Pro-N17E型,江苏双利合谱科技有限公司;
电子秤:CN-LQ-C-6002型,昆山优科维特电子科技有限公司;
多功能切碎机:HCP-A9型,中山市小马熊电器有限公司。
1.3 试验方法
1.3.1 样品的制备 从羊肉和鸭肉中去除可见脂肪,以减少对试验结果的干扰。将羊肉和鸭肉切块后,按照一定的掺假比例(10%~90%,掺假间隔为10%,每份样品总量为50 g),称取相对应的羊肉和鸭肉至搅拌机中搅拌4 min,使样品充分混合后放入培养皿中铺平。每个掺假样品制备5个平行样,并同时制备5个纯羊肉样品和5个纯鸭肉样品, 共计55个。
1.3.2 高光谱图像的采集与校正 在进行高光谱图像采集之前,应保证光源的稳定性,消除光谱仪自身的影响,因此试验前先将高光谱仪器开机预热30 min后,再进行图像的采集。首先确定高光谱镜头与拍摄样品之间的最佳物距,随后调整高光谱采集数据的各项参数,具体参数:GaiaField-Pro-V10E型(400~1 000 nm)高光谱仪与样品的物距为300 mm,曝光时间为2.4 ms,扫描速度为0.140 6 cm/s,图像像素为800×769;GaiaField-Pro-N17E型(1 000~1 700 nm)高光谱仪与样品的物距为510 mm,曝光时间为1.2 ms,扫描速度为0.093 2 cm/s,图像像素为640×666。高光谱采集系统示意图如图1所示。
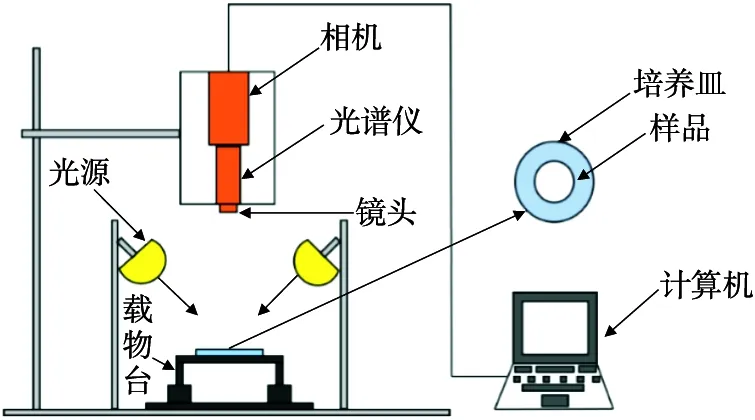
图1 高光谱系统结构示意图Figure 1 Schematic diagram of hyperspectral system structure
对55个样品进行光谱信息采集后,在相同的采集条件下,扫描聚四氟乙烯白板(反射率为99.99%)得到全白的校准板图像,盖上相机镜头盖获取全黑的背景图像,利用黑白校正的方法以减少仪器本身的暗电流和样品本身对光源反射的影响。其中,黑白校正公式为:
(1)
式中:
R——校正后的信号强度;
R0——原始信号强度;
B——全黑的标定信号强度;
W——全白的标定信号强度。
1.3.3 感兴趣区域提取 对55组样品的高光谱数据进行黑白校正后,对感兴趣区域进行提取,具体步骤如图2所示,并对提取的感兴趣区域内每个像素点的光谱反射率值进行平均处理作为样品最终的光谱数据,共获取得到55组光谱数据。数据处理采用Specview软件、ENVI5.3软件和Matlab2020b软件。
1.3.4 样品集划分 在采集样品的过程中,难免会产生异常样品,其在一定程度上影响校正模型的预测能力,因此在建模前须将异常样品从样品集中剔除。试验采用主成分分析(PCA),利用提取的光谱主成分得分向量来代替光谱向量计算样本间的马氏距离,将超出设定的马氏距离阈值的异常样本进行剔除[11]。剔除马氏距离大于3f/n(f为PCA选取前6个主成分数;n为样品数)的校正样品[12],通过3f/n计算得到的马氏距离阈值为0.327 3,最终从55个样本中剔除1个超过阈值的异常样品。然后采用光谱—理化值共生距离算法(SPXY)[13]将剩余的54个样品以3∶2的比例划分成32个校正集和22个预测集。

图2 感兴趣区域提取步骤Figure 2 Extraction steps for regions of interest
1.3.5 变量筛选方法
(1) 连续投影算法(SPA):从选定一个波长开始,每次循环都计算其在未入选波长上的投影,将投影向量最大的波长引入到波长组合。每一个新入选的波长,都与前一个线性关系最小。算法对每次选择的结果进行MLR建模预测分析,以最小均方根误差(RMSE)来判断所建模型的优劣。试验中选择的最佳变量数范围为5~50,从400~1 000 nm光谱集合选择出14个特征波长,从900~1 700 nm光谱集合选择出13个特征波长。
(2) 竞争性自适应重加权算法(CARS):每次通过指数衰减函数(EDF)和自适应重加权采样(ARS)选取PLS模型中回归系数绝对值大的波长点,在交叉验证过程中选取PLS模型中交叉验证均方根误差(RMSECV)最小子集定义为最优变量子集[14]。试验中将蒙特卡洛采样次数设置为1 000次,交叉验证组数为5,从400~1 000 nm光谱集合选择出10个特征波长,从900~1 700 nm光谱集合选择出14个特征波长。
(3) 区间随机蛙跳(iRF)算法:它是一种可逆的跳跃马尔可夫链蒙特卡罗式算法,通过计算每个区间光谱点的绝对回归系数总和来评估区间,选择误差最小的区间组合[15]。参数设置:移动窗口大小w设置4,子间隔初始值Q为5,最大主成分数为10,迭代次数N设置为500。从400~1 000 nm光谱集合选择出排名前10的波长间隔共29个特征波长,从900~1 700 nm光谱集合选择出排名前19的波长间隔共70个特征波长。
(4) 组合区间偏最小二乘法(SiPLS):在区间偏最小二乘法(iPLS)的基础上[16],将全光谱波段分成的若干个子区间中精度较高的几个子区间联合起来,以RMSECV值为衡量指标并在此基础上建立PLS模型[17]。SiPLS的子区间数均设为10,从400~1 000 nm光谱集合选择的最佳联合子区间(包括2、5、6和7)共47个特征波长。从900~1 700 nm光谱集合选择的最佳联合子区间(包括2、3、4和10)共205个特征波长。
1.4 建模方法与模型评价
利用偏最小二乘法回归(PLS)算法构建样品中羊肉掺假鸭肉的全波段定量分析模型和特征波段定量分析模型。PLS是光谱分析中应用最广泛的化学计量方法,该方法同时可将光谱阵X和浓度阵Y同时进行分解,并将浓度阵Y主成分信息与引入到光谱阵X的分解过程中,增强了两者的对应计算关系[18][19]59-61。
(2)
(3)
(4)
式中:
R2——决定系数;
RMSE——均方根误差;
RPD——相对分析误差;
n——校正集或验证集的样本个数;
yi——第i个样品测量值;
1.2 纳入与排除标准 纳入标准:①患者均符合股骨颈骨折的诊断标准;②患者均进行手术治疗且无手术禁忌证;③患者均配合本项研究。排除标准:①患者合并严重器官功能障碍、免疫系统及传染性疾病;②患者术后有认知障碍;③患有精神疾病的患者。



2 结果与讨论
2.1 样品光谱曲线特征
图3为所有样品在400~1 000 nm的原始光谱图像,图4为所有样品在900~1 700 nm的原始光谱图像。通过图3(a)和图4(a)可以看出,未掺假样品和掺假样品的光谱曲线趋势大致相似,但从图3(b)和图4(b)中的10条不同掺假比例(0%~100%)的光谱曲线中可以看出,在500~800 nm波段,1 000~1 400 nm波段,掺假样品相对于未掺假样品的变化趋势和变化幅度均有较为明显的差异,并且在整个光谱范围(400~1 000 nm和900~1 700 nm)内并不存在随着羊肉掺假比例的升高,光谱的反射率曲线明显呈升高或下降的规律,因此需要通过化学计量学方法提取光谱中的有效信息,剔除无用的干扰信息后建立模型[21]。
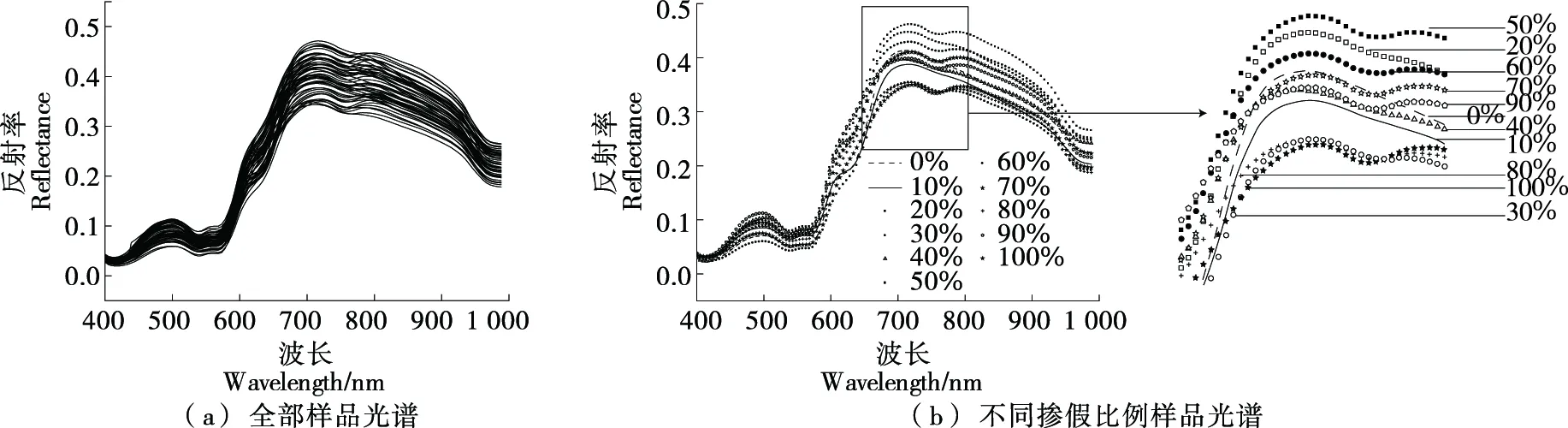
图3 样品在400~1 000 nm的原始光谱Figure 3 Original spectra of samples (400~1 000 nm)

图4 样品在900~1 700 nm的原始光谱Figure 4 Original spectra of samples (900~1 700 nm)
2.2 全光谱PLS建模
制备的肉类掺假样品的光谱中除了包含自身丰富的化学物质信息外,还含有与样品组分无关的信息和噪声,如温度、光的散射、仪器响应以及样品自身混合不均匀等因素。采用小波变换(WT)、多元散射校正(MSC)、标准正态变量变换(SNV)、归一化和Savitzky-Golay卷积平滑法(SG) 5种光谱预处理方法对原始光谱进行预处理,并建立羊肉掺假鸭肉的全波段PLS定量预测模型,建模结果如表1、表2所示。通过比较分析,筛选出适合于400~1 000 nm和900~1 700 nm两个谱段范围的光谱预处理方法。


表1 400~1 000 nm下采用不同预处理方法的全波段PLS模型性能Table 1 Performance of full-band PLS models with different pretreatment methods for 400~1 000 nm
2.3 特征波长选取及建模
在2.2的基础上,对400~1 000 nm波段的光谱数据进行归一化预处理,对900~1 700 nm波段的光谱数据进行SNV预处理后,采用4种变量筛选方法(SPA、CARS、iRF和SiPLS)对模型进行进一步优化。
通过表3对比可以看出,虽然SPA方法和iRF方法的校正集建模效果相当,但SPA方法的预测集建模效果要优于iRF方法。分析其原因并通过图5可以看出,SPA方法选择的波长在整个区间范围内都有分布,但iRF方法选择的波长较为集中且连续,可能包含了一定的无用信息。且在可见光波段范围内的515~700 nm波段附近存在肌红蛋白、氧肌红蛋白和脱氧肌红蛋白等与肉类中色素形成相关的基团吸收[22],SPA方法选择到的特征波长在此区间内均有分布。

表3 400~1 000 nm下采用归一化后的PLSR建模效果Table 3 Effects of PLSR modeling after using normalization for 400~1 000 nm
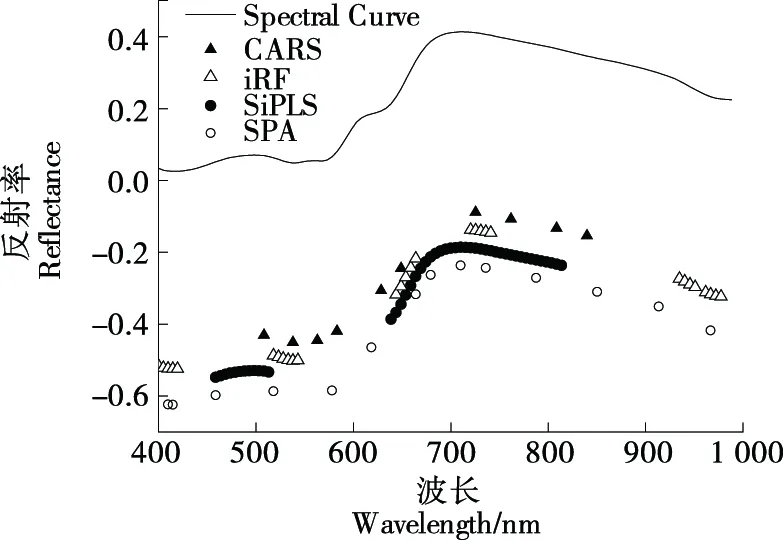
图5 400~1 000 nm波段归一化预处理后挑选特征波长Figure 5 Selection of characteristic wavelengths after normalized pre-processing in the 400~1 000 nm band

图6 400~1 000 nm波段归一化结合SPA建模效果Figure 6 400~1 000 nm band normalized combined with SPA modeling effect
通过表4对比可以看出,SPA方法和CARS方法选择的特征波长数相似,SPA方法挑选了14个波长,CARS方法挑选了13个波长,但SPA的建模总体效果要优于CARS。结合图7可以看出,在980,1 200 nm附近存在O—H键的一级倍频和二级倍频的吸收;在1 235,1 540 nm 附近存在蛋白质中C—H键的三级倍频和N—H键的二级倍频吸收;在990~1 200,1 690~1 700 nm 附近存在于肉类中脂质形成相关的C—H键的二级倍频和合频的吸收[22-23]。SPA方法相较于CARS方法在1 600~1 700 nm波段选择到了更多与肉类脂质形成相关的特征波长,因此其建模效果更优。
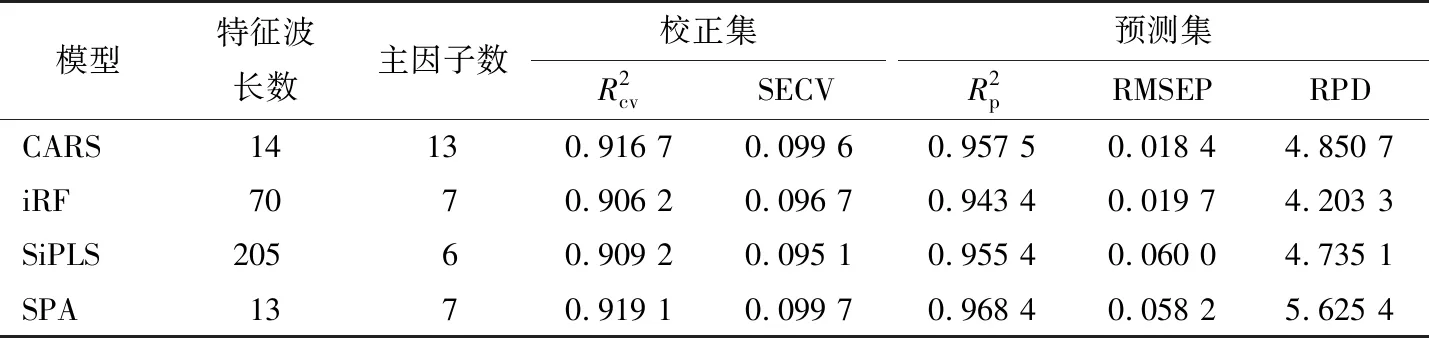
表4 900~1 700 nm下采用SNV预处理方法后的PLSR建模效果Table 4 Effects of PLSR modeling with SNV pretreatment method for 900~1 700 nm
综上所述,对照SPA方法在400~1 000 nm波段选择得到的14个波长点和在900~1 700 nm波段选择得到的13个波长点,它们大都落在与肉类相关的吸收谱带区域内或附近,表明挑选出的各峰位较好地反映了两种不同肉类的吸收特征;从另一个侧面也说明SPA方法挑选出的波长更具有代表性,进一步提升了建模的效果。
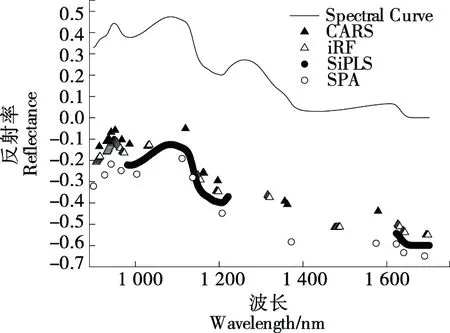
图7 900~1 700 nm 波段SNV预处理后挑选波长Figure 7 Selection of wavelengths after SNV pretreatment in the 900~1 700 nm band
2.4 掺假可视化
通过2.3节可知,最佳的PLS定量模型是在900~1 700 nm 波段范围内,首先对光谱进行SNV预处理后,再利用SPA方法挑选波长后得到。利用该模型建立羊肉掺假鸭肉含量的预测表达式:
y=0.436 4λ899.83 nm+0.186 4λ926.51 nm+0.528 3λ942.2 nm+4.141 1λ965.74 nm-5.771 0λ1 003.4 nm+1.732 7λ1 111.68 nm+2.931 3λ1 136.79 nm-0.961 4λ1 207.41 nm-0.618 9λ1 372.18 nm-3.074 4λ1 574.62 nm-0.796 7λ1 623.27 nm-3.043 6λ1 640.53 nm-1.412 7λ1 690.75 nm-13.727 8,
(5)
式中:
y——预测的掺假率值;
λ——特征波长对应的反射率值。
通过式(5)计算羊肉掺假鸭肉的高光谱图像中每个像素点的掺假率,再使用伪彩色图像处理方法生成掺假率的可视化图像,如图9所示。从图9可以看出,随着掺假比例的增加,颜色由深色变成浅色。高光谱成像技术提供了一种切实可靠的方法来可视化掺假样品的分布,这是其他方法无法实现的。然而,对于每个单独制备的掺假样品,尽管在前期样本制备的过程中已经尽可能地让样品混合均匀,但通过图9仍发现掺假样品的分布还是存在不均匀性。

图8 900~1 700 nm波段 SNV结合SPA建模效果Figure 8 900~1 700 nm band SNV combined with SPA modeling effect

图9 羊肉掺假鸭肉掺假可视化图像Figure 9 Visualization images of lamb adulteration and duck adulteration
3 结论
(1) 对于400~1 000 nm波段来说,采用归一化预处理后建立的全波段PLS模型精度最高;对于900~1700 nm 波段来说,采用SNV预处理后建立的全波段PLS模型精度最高。对最佳预处理方法下的两个光谱波段进行波长选择,发现SPA方法在消除多重共线性的基础上,挑选出的波长之间的共线性最小且具有代表性,能进一步提升模型的精度和简洁度。
(2) 在900~1 700 nm波段范围内含有的与肉类组成相关的基团信息更多,更能反映肉类的特征信息,可能更适合于进行肉类掺假的识别。为扩大模型的全面性和适用性,试验还需延伸至长波近红外谱段(1 700~2 500 nm);同时,试验中选取高品质的羊肉和鸭肉均为当地超市的成品包装,后续模型能否适用于不同环境(温度、湿度、形态等)、不同品种、不同品质、不同喂养方式和不同新鲜度下的羊肉掺假研究,需进一步地验证探讨。
