基于特征学习的双路径红外-可见光行人重识别算法
2022-10-31
(南京邮电大学 自动化学院 人工智能学院, 江苏 南京 210023)
行人重识别是指利用计算机视觉技术来确定一个目标行人是否在图像或视频中存在。近年来,随着社会对公共安全问题的关注越来越多,行人重识别引起了人们极大的研究兴趣。许多行人重识别算法被提出,包括手工特征算法[1]、度量特征算法[2]以及深度学习算法[3],这些算法一定程度上解决了行人重识别问题。深度学习算法目前已成为行人重识别的主流算法,包括单模态和多模态行人重识别算法。
现有的大部分研究[4-6]都专注于RGB模态中的行人重识别,主要集中在RGB模态中外部条件变化的挑战,包括光照条件、视点变化、不对称等方面。文献[4]利用排序优化框架中的相似性和差异性线索进行行人识别。为提高行人重识别的精度,文献[5]研究了跨模态支持一致性和跨模态投影一致性的算法。Chen等[6]利用自然语言描述作为有效的视特征,识别不同身份的额外训练监督。然而,现有的单模态行人重识别算法只能解决RGB图像中的识别问题,不能很好地解决跨模态行人重识别问题。
如图1所示,虽然图1(a)和1(c)是不同的行人图像,但是图1(a)所对应的红外图像图1(b)与图1(c)非常相似,说明拍摄角度、行人姿态和光照变化等因素严重影响对红外-可见光行人重识别的准确性。双模态摄像机很好地弥补了单模态RGB摄像机的缺陷,并且将单模态行人重识别研究延伸至跨模态领域,目前已提出多种针对跨模态行人重识别的方法。文献[7]提出SYSY-MM01大规模跨模态行人重识别数据集,得出零填充有利于提高识别精度的结论。文献[8]引入一种分层跨模态解调算法,有效减少模态间差异。文献[9]提出双向中心约束顶级排序算法,通过引入模态间约束和模态内约束,刻画尺寸变形和类内变化。文献[10]通过在网络中添加X模态,辅助学习不同模态特征,提高识别性能。

图1 红外-可见光行人重识别中复杂的变化Fig. 1 Complex variations in infrared-visible person re-identification
上述算法着重于缩小RGB与红外模态间差异,在模态信息不共享情况下,识别精度不太理想。本研究提出一种基于特征学习的双路径红外-可见光行人重识别算法,在引入注意力机制刻画模态内和模态间特征差异的同时,利用身份损失函数、身份异质中心损失函数和交叉熵损失函数,提高行人重识别准确性。
1 基于特征学习的双路径红外-可见光行人重识别算法
本研究提出的红外-可见光行人重识别的双路径学习算法,通过在RGB分支中引入注意机制来获得更多行人信息,在特征嵌入阶段引入BNNeck(batch normalization neck)模块加快身份损失收敛速度,其双路径网络结构如图2所示。
1.1 双路径局部特征网络
在RGB单模态行人图像重识别中,常用算法是对行人图像进行水平分割,提取局部特征,然后对行人图像进行特征匹配。由于红外图像只有行人的外观信息和姿态信息,没有颜色和光照等信息,故不能解决红外-可见光行人重识别问题。本研究采用的双路特征学习算法主要包括特征提取和特征嵌入两部分。
1) 特征提取。首先,利用卷积注意力机制提取RGB图像特征,并结合红外图像特征构建特征描述子;然后,水平切割具有高层语义信息的红外-RGB行人特征,并将其作为共享层的输入。由于训练数据有限,网络预训练参数通过大规模数据集ImageNet训练得到。

图2 本研究算法的双路径网络结构Fig. 2 Architecture of the proposed dual-path network
2) 特征嵌入。首先,为更好学习模态间可区分的低维嵌入特征,将提取的特征引入共享层;然后,使用L2正则化方法平滑特征表示;最后,利用提出的BNNeck身份损失函数,以及RGB图像身份损失函数、红外图像身份损失函数、交叉熵、损失函数和中心异质损失函数,得到准确的行人身份。
为减少模态间差异,本算法采用操作:①为表征不同模态的低级特征,RGB特征网络和红外特征网络的ResNet50的第一个卷积块参数不完全相同;②为表征模态的中层特征,每个特征网络共享深层卷积块参数;③在自适应池化卷积层后,使用共享的BN(batch nomalization)层学习共享特征。
1.2 注意力机制
在RGB分支中加入CBAM(convolution block attention module)注意力机制,学习不同图像区域权值获得更有鉴别性的信息。
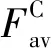
(1)
式中,σ表示sigmoid函数,W0和W1分别为两个全连接层的参数。该通道注意力机制能够较好地从模态层面把握RGB图像的特征信息,减小RGB图像与红外图像的差异,可视为不同的半动态语境选择语义属性的过程。

图3 通道注意力模块结构Fig. 3 Channel attention module structure
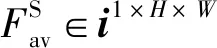
(2)

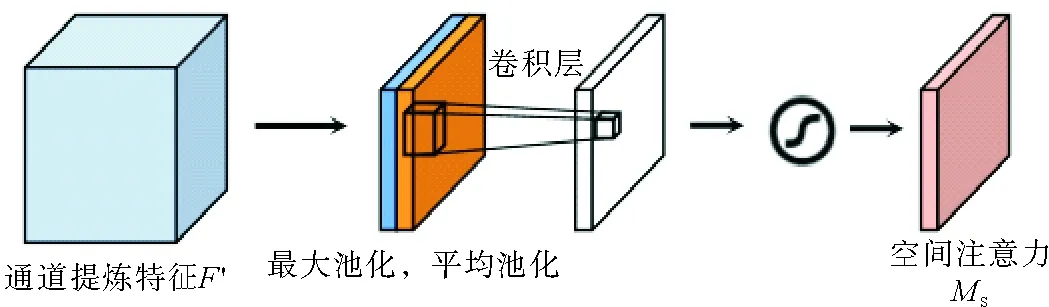
图4 空间注意力模块结构Fig. 4 Spatial attention module structure
红外行人图像是一个只包含语义结构和形状信息的单通道图像[11],而RGB图像是一个包括外观和颜色等高级语义信息的多通道图像。为避免在特征提取中损失重要信息,尽量获得更多行人信息,减少模态间差异,本算法在RGB分支加入注意力机制(如图5所示)进行特征提取。具体的特征提取过程为:①在输入288×144×3的RGB行人图像后,利用注意力机制,针对Conv5_x和平均池化层间的高层特征进行加权,得到18×9×2 048的特征映射,有效扩大感受野范围;②利用提出的平直流行结构,融合18×9×2 048的特征映射和加权后的特征映射,加强全局跨通道交互。

图5 基于注意力机制的特征提取过程示意图Fig. 5 Feature extraction process based on attention mechanism
基于注意力机制提取的特征映射,为后续处理提供包含重要信息和次要信息的全局特征,有助于从模态层面把握RGB图像的特征信息,减少两种模态之间的差异。
1.3 跨模态BNNeck和损失函数
1.3.1 概述
本研究利用RGB图像丰富的信息来学习模态特征,缩小模态间的差异。如图2所示,利用特定模态的网络和身份损失提取模态相关信息,并在RGB分支中引入卷积注意力模块,对行人图像进行特征提取,使其更具有判别特征;将BNNeck模块与模态共享层相结合,提高深度模态共享的协调性。得到的最终总损失函数为:
(3)

1.3.2 身份损失
1) 特定模态身份损失。由于RGB图像和红外图像中行人的视觉特征差别很大,需要在提取每个分支的特征时使用不同的权重来学习每个模态的单一网络。每个网络分支采用特定的身份损失来学习其特征,本研究采用Softmax损失进行身份预测,表示为:

(4)

为更好提取RGB图像的特征并学习其全局不变性,在RGB分支中加入注意力机制,将式(4)改写为:

(5)
则卷积注意力模块在RGB分支特征提取中造成的偏置。
(6)
式中:w和h分别表示图像的宽度和高度,λ用来限制损失。
2) 跨模态BNNeck身份损失。身份损失将识别任务视为一个分类任务,并通过余弦距离优化身份损失。如果直接将两个模态的特征相结合并计算身份损失,很可能导致两种模态下的目标行人身份不一致,损失函数无法收敛。为解决这一问题,在双分支网络的全链接层后引入名为跨模态BNNeck的模块,在共享全连接分类层后增加一个BN层。从网络中提取的原始特征为f,经过BN层后变为f′。在训练阶段,分别使用f和f′计算身份损失,并通过BN层得到正则化后的特征。BNNeck减少了身份损失的限制,使其更容易收敛,同时,正则化进一步缩小了同一行人RGB图像特征和红外图像特征间的差异。跨模态BNNeck身份损失公式为:
(7)

1.3.3 中心异质损失和交叉熵损失
为缩小内在差异,引入中心异质损失和交叉熵损失。中心异质损失公式为
(8)
式中:ci,1和ci,2分别为第i个行人的RGB模态和红外模态特征分布中心,U为行人个数,M和N为第i个行人的RGB图像和红外图像数,xi,1,j和xi,2,j分别为第i个行人的第j个RGB图像和红外图像的特征。
由于中心异质损失仅通过约束每个行人的中心距离提高模态内相似度,并不能通过网络学习判别特征来扩大模态间差异。因此,采用中心异质损失和交叉熵损失联合监管,交叉熵损失函数为:
(9)
式中:K为批次数,xi是第yi类中第i个特征,Wj是W中第j行参数,b表示模态的偏置。
2 实验
实验环境为Ubuntu 16.04,GPU选用NVIDIA GeForce RTX 2070,深度学习框架Pytorch的版本为1.0.0。输入图像大小设置为288×144。为提升训练和测试精度,采用随机裁剪和随机水平翻转对数据集进行扩充,batch size的大小为32,设置总训练周期为60个epoch。
2.1 数据集
本研究选用公开的数据集SYSU-MM01[5]和RegDB[11],使用首位排序精度(Rank-1,R1)、 前10位排序精度(Rank-10,R10)、前20位排序精度(Rank-20,R20)和平均精度(mean average precision,mAP)共同对算法性能进行评估。
SYSU-MM01共有491位行人,其中395个行人用于训练,96个行人用于测试;同时,22 258张RGB图像和11 909张红外图像用于训练,301张RGB图像和3 803张红外图像用于测试。由于单镜头全景搜索方式更接近现实,因此采用该搜索方式进行性能评估。
RegDB共有412位行人,其中206个行人用于训练,206个行人用于测试。测试过程中,RGB图像作为查询示例,红外图像作为图库集用以验证算法性能。
2.2 SYSU-MM01数据集上的测试结果
与本研究所提算法进行性能比较的算法包括方向梯度直方图(histogram of oriented gradient,HOG)等在内的传统算法以及包括cmGAN等在内的深度学习算法共14种,从全景搜索/室内搜索和单镜头/多镜头两个角度进行评估,4个方面的比较数据见表1。可以看出,室内搜索的性能优于全景搜索的性能,这是因为室内环境较为单一,无明显光线变化,行人匹配更容易;全搜索下,多镜头R1的准确率高于单镜头R1,但多镜头R1的mAP低于单镜头排序R1,这是因为多镜头可以从各个角度收集更多的行人照片,更容易进行匹配,而单镜头模式则相反。

表1 SYSU-MM01数据集的实验对比Tab. 1 Comparison with other works on SYSU-MM01 dataset
由表1中可见,HOG/LOMO在R1和mAP中分别只有2.76%/3.64%和4.24%/4.53%,说明传统算法难以在跨行人重识别中取得良好效果;单流(One-Stream)、双流(Two-Stream)和零填充(Zero-Padding)将R1和mAP的性能提高了近8%,说明分类损失有助于特征的学习;在R1和mAP的识别性能上,相比于零填充,cmGAN和D2RL的性能均提高了近10%,说明通过网络优化和训练,算法的有效性得到了很大提高;DDAG和TSLFN+HC的R1和mAP均达55%左右,同时R10和R20也分别高出1.85%和1.07%,这证明了双路径网络的有效性。综上,本研究算法在R1和mAP分别达到59.39%和57.81%,R10和R20分别达到93.35%和97.89%,证明了算法的有效性。

表2 RegDB数据集的实验对比Tab. 2 Comparison with other works on RegDB dataset

图6 不同算法的注意力机制热力图Fig. 6 Heat map of attention mechanism for different algorithms
2.3 RegDB数据集上的测试结果
在数据集RegDB上使用visible2 thermal搜索方式,以RGB图像作为搜索图像库,红外图像作为待搜索图像库,与其他9个算法的测试结果对比见表2。
由表2可见,本算法的R1和mAP分别为85.44%和73.19%,比X Modality算法的相应值分别高出23.23%和13.01%,比性能最好的TSLFN+HC算法的相应值分别高出1.44%和1.19%;同时R10和R20也达到了最高性能。在RegDB数据集上,本算法的R1和mAP优于其他算法。
2.4 注意力机制的可视化
为直观显示注意力机制的性能,比较SYSU-MM01数据集上的红外图像的热力图,如图6所示。由图6可以看出,卷积注意力机制能够很好地保留行人的特征(如行人姿态),在RGB图像中与在红外图像中保持相同的身份,表明融合注意机制可以使网络更好地提取行人特征,提高识别精度;与DSCSN+CCN[19]和RNPR[20]两种算法相比,RNPR算法因只能识别一小部分行人信息而降低了行人重新识别的准确性,而本研究的注意力机制可以更准确地提取行人特征,更好地保留行人特征信息。
2.5 各模块消融实验
本节评估本算法在全搜索和室内搜索方式SYSU-MM01数据集上每个模块的有效性(如表3),并评估RegDB数据集上每个模块的有效性(如表4)。表中,D表示双路径网络的基线网络结果,B表示BNNeck模块,C表示添加到RGB分支中的CBAM注意力机制。
由表3和表4可知:①双路径网络具有明显优势,卷积块共享双路径网络在跨模态行人重识别中可以获得优良的性能。②B的有效性。在两个数据集上,BNNeck模块(D+B)的加入显著提高了算法的性能。③C的有效性。当在网络中加入CBAM注意模块(D+C)时,通过注意力机制将两种模态之间的差异进一步缩小,从而提高算法的性能。④两个模块的有效性。将BNNeck模块和CBAM模块合并到网络中(D+B+C),整体性能进一步提高,说明两个模块相互配合,共同促进。

表3 各模块在SYSU-MM01数据集下的实验结果Tab. 3 Evaluation of each component on the large-scale SYSU-MM01 dataset

表4 各模块在RegDB数据集下的实验结果Tab. 4 Evaluation of each component on the RegDB dataset
2.6 与基准损失函数的比较
将损失函数与基准损失函数进行比较,验证所提算法的性能。比较4种不同的损失函数:Softmax损失、结合图注意力机制的Softmax损失[17]、异中心损失以及交叉熵损失,实验结果见表5。
可以看到,与其他基线损失函数相比,本研究提出算法的性能最好。图注意力机制的Softmax函数比单一的Softmax函数好,说明图注意力机制对于红外-可见光行人重识别性能的重要性。交叉熵的异中心损失增加了模态内相似性,改善了性能。在使用特定模态Softmax和模态共享Softmax进行扩展后,在两个数据集上的识别性能均得到了提高。

表5 双路径网络下,本算法与基准算法间不同损失函数的性能比较Tab. 5 Performance comparison of different loss functions between the proposed algorithm and the baseline algorithm under the dual-path network

图7 训练阶段损失变化趋势Fig. 7 Trend of loss during training
2.7 收敛速度测试
数据集SYSU-MM01上的训练阶段损失变化趋势如图7所示,可见由于网络参数较少,同时采用端到端的设计,使得训练过程中部分参数能够及时得到释放,避免参数量过高的问题,因而使得本算法模型规模小,训练周期短,收敛速度快。
3 结论
本研究提出一种双路径深度学习算法,通过双路径分别提取RGB图像和红外图像特征,获得不同行人的身份信息。引入注意力机制提取RGB图像特征,通过共享层减少RGB图像与红外图像差异,并通过融合跨模态BNNeck得到共享身份信息;通过多个损失函数交互作用,有效提高算法性能。本算法模型规模小、训练周期短,能有效减小红外图像与RGB图像模态间差异,算法识别精度优于现有算法。但由于数据集较少,训练度不够,本算法仅适用于训练周期较短的识别任务。
