基于人工神经网络的MILD 燃烧区域识别
2022-10-29马天顺
谢 凡,鲁 昊,马天顺
(华中科技大学能源与动力工程学院,武汉 430074)
准确地进行燃烧区域识别或划分对于研究湍流燃烧的燃烧特性、传热传质,以及湍流与燃烧的相互作用等问题来说具有重要意义.然而,这很难在瞬态湍流燃烧场中进行.现有的燃烧区域识别方法可大致分为两类:一种是以平面激光诱导荧光(planar laser induced fluorescence,PLIF)技术为代表的,将燃烧产物的分布成像,以此得到火焰结构的方法.如Li等[1]将PLIF 应用于研究湍流预混甲烷/空气喷射火焰的局部火焰前端结构,同时记录了CH、CH2O 以及OH 的PLIF 图像,发现CH 自由基只存在于一个薄层中,CH2O 存在于火焰内部,OH 自由基存在于火焰外部,CH 层将OH 和CH2O 层分开;Zhou 等[2]将PLIF 应用于一系列预混湍流甲烷/空气喷射火焰,选择不同的3 种标量进行了研究,CH2O 提供对预热区的测量,CH/HCO 是对反应区内层的测量,OH 是对氧化区的测量.赖安卿等[3]应用图像FFT 方法,捕捉了振荡燃烧环境下火焰的主要脉动特征.这种将火焰成像的方法只能测量少数组分,在测量时还会受其他组分或者环境因素的影响,因此在实际使用中不确定性较大.
另一种是以数值模拟得到的数据为依据,人为制定识别燃烧区域准则的方法.如Kerkemeier[4]对湍流非预混火焰进行直接数值模拟时,认为预混燃烧的火焰面出现在OH 的质量分数大于10-4的区域;Hasret等[5]在计算湍流分层火焰时,认为火焰面出现在温度扰动的极大值处.这种人为制定识别准则的方法,带有较大的主观性,且选择的组分单一,难以客观、准确地识别燃烧区域.
除此之外,Hartl 等[6]利用一维Raman/Rayleigh对多模式燃烧器的甲烷-空气湍流火焰的温度和主要组分浓度进行了测量,并基于当地预混和非预混反应区相关的局部热释放率峰值的比率,来定义不同的燃烧状态.值得注意的是,Wan 等[7]利用卷积神经网络(CNN)对Hartl 等[6]的实验数据(H2,O2,CO,CO2,CH4,H2O,N2的质量分数和温度共7 维特征)进行训练,来预测该工况中的燃烧状态,其准确率在85%左右.陈培豪等[8]采用Adaboost 算法对运动图像进行疑似火灾区域提取,采用神经网络MobileNetv3 进行火灾识别,平均准确率可达98.1%.可见,引入神经网络,收集特征进行训练的方法是有效的,这也为燃烧区域识别这一问题提供了新的思路.
本研究将以在热伴流射流(jet-in-hot-coflow,JHC)条件下的湍流 MILD 燃烧典型工况HM1[9]为对象,在对其进行数值模拟的基础上,使用K-means聚类算法对燃烧场的区域进行划分,并将分类结果作为标签提供给人工神经网络,然后选择不同的特征进行训练,以此来预测燃烧区域.与Wan 等人的工作相比,本研究的数据源于数值模拟,因此可以得到全流场的数据,避免了他们的实验中只能测量特定位置数据的不足;而且与他们选定了7 维特征相比,本研究讨论了选择不同种类和维数的特征对结果的影响,在将燃烧区域识别准确率提高到97%以上的同时,减少了选用特征的维数,这对于实际应用更具参考意义.
1 研究方法
1.1 数值燃烧模拟
本研究采用的MILD 燃烧模拟工况是Dally 等[9]开展的JHC 条件下的HM1 实验工况.该实验装置外形为环形柱状,内径4.25 mm,外径82 mm.由质量分数为80%的CH4和20%的H2组成的燃料,从中心孔以73.5 m/s 的平均速度喷射入装置,雷诺数为9 482,初始温度为305 K.热伴流由质量分数为3%的O2、6.5%的H2O、5.5%的CO2和85%的N2组成,从孔外的环形区喷射入装置,平均温度为1 300 K;最外层为常温空气,温度为300 K;热伴流和常温空气的平均速度为3.2 m/s.
采用GRI-Mech2.11 机理,该机理包含了48 种组分.根据Lu 等[10]的高精度非线性大涡模拟方法,对该工况进行数值模拟.
1.2 聚类分类
聚类分析是将研究对象分为相对同质的类别的统计分析技术.在分类的过程中,不必人为提供标准,聚类分析能根据样本数据的特征,进行自动分类.其中,K-means 聚类算法容易实施、简单、高效,目前仍然是应用最广泛的划分聚类算法之一[11].
本研究将利用K-means 聚类算法,对燃烧场区域进行划分,为ANN 提供训练的标签.
1.3 人工神经网络
人工神经网络是一个模拟人类神经结构的机器学习算法[12],它既可以应用于回归问题,也可以应用于分类问题.
在ANN 的实际应用中,最常用的是反向传播(back propagation,BP)算法及其变化形式,本研究也将使用该算法.BP 算法是一种有监督式的学习算法,它的思想是,先通过链式法则递归地计算目标函数对每一个神经元的输出值的梯度,然后再次用链式法则计算边上的权重参数的梯度.具体过程包括[13]:①输入给定的训练数据集,计算网络的输出值,并将其与期望值进行比较的正向传播过程;② 计算同一层单元的误差,修正网络参数的反向传播过程;③正向、反向传播反复进行的网络训练过程;④ 网络的总体误差趋向极小值的收敛过程.
本研究借助开源机器学习平台TensorFlow 来开发和训练模型.
2 研究过程
2.1 聚类分类
根据马天顺等[11]的研究,截取HM1 工况0~140 mm 高度,主要为MILD 燃烧区域的数据.应用K-means 聚类算法,选取所有组分的质量分数和温度共49 维特征,对燃烧区域进行分类.
导出两个时刻下的数据集X 和Y,图1 为对数据集X、数据集Y 分别进行聚类分类,分类数设置为5,得到的同一横截面(高度为140 mm)和同一中心纵截面的结果.
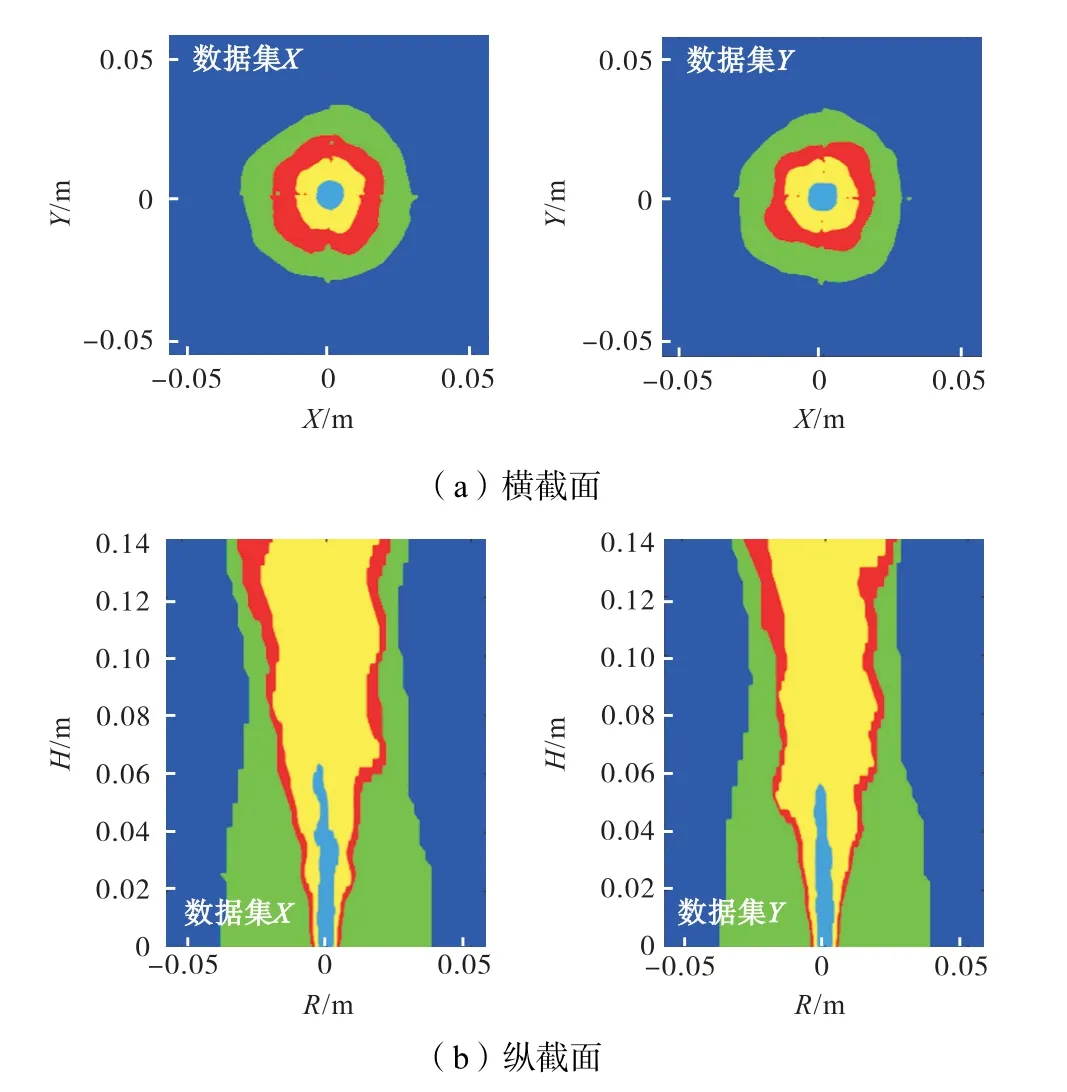
图1 聚类分类结果Fig.1 Clustering classification results
由外向内,从第0 至第4 类,共被分为5 类,即5个燃烧区域,依次是不参与反应的常温空气区、热伴流区、燃烧主要发生的火焰面、预热区和中心燃料区.
2.2 初步ANN识别
依据BP 算法搭建ANN.
网络结构为全连接神经网络Dense 层,激活函数选用Softmax 函数,使多分类的输出数值转化为相对概率:
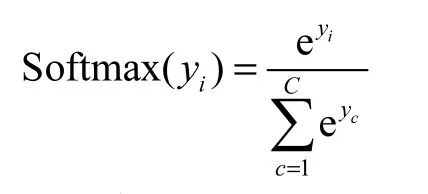
其中,yi为第i 个节点的输出值,C 为输出节点的个数.
训练时,优化器选用Adam,评测指标为准确率,损失函数选用交叉熵损失函数:
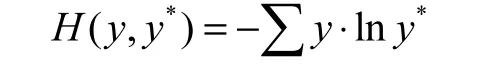
其中,y 表示准确的概率分布,y*表示预测结果的概率分布.
以数据集X 为训练集,数据集Y 为测试和预测集.利用搭建完成的ANN,学习训练集X 的聚类分类结果,并预测测试和预测集Y 的燃烧区域.
将聚类分类结果的5 类作为标签,根据特征的分布云图,初步选取易通过仪器测量的重要组分——CH4、CH2O、CO、OH 的质量分数和温度共5 维特征进行识别.训练、预测的准确率及损失函数如图2 所示,其中预测准确率为98.72%,预测结果如图3 所示.
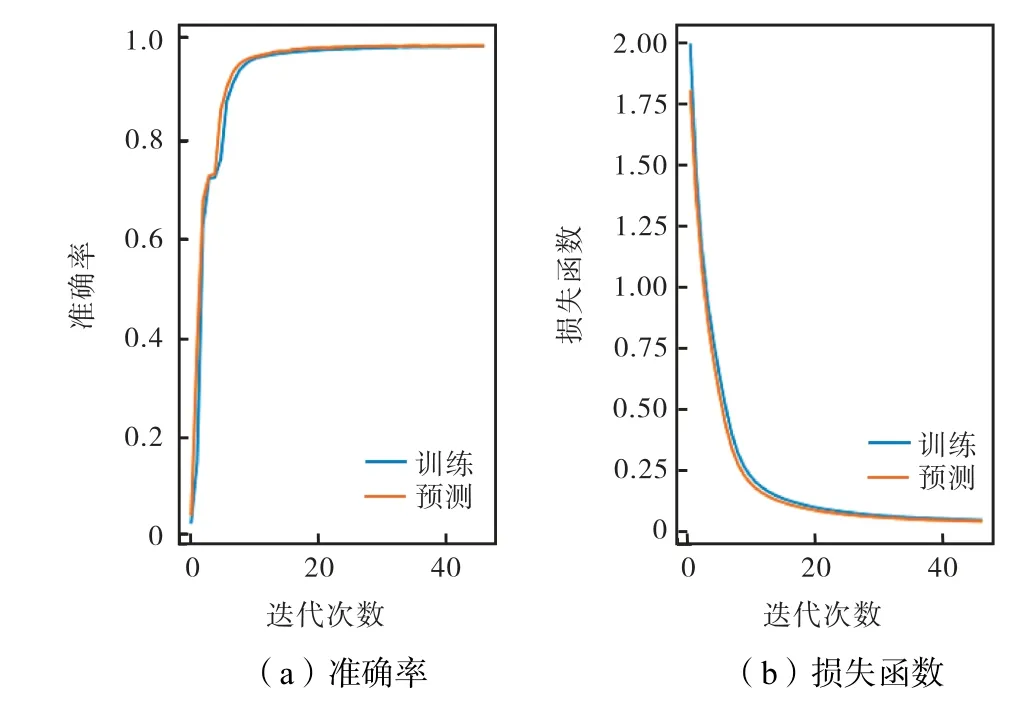
图2 准确率及损失函数Fig.2 Accuracy and loss function
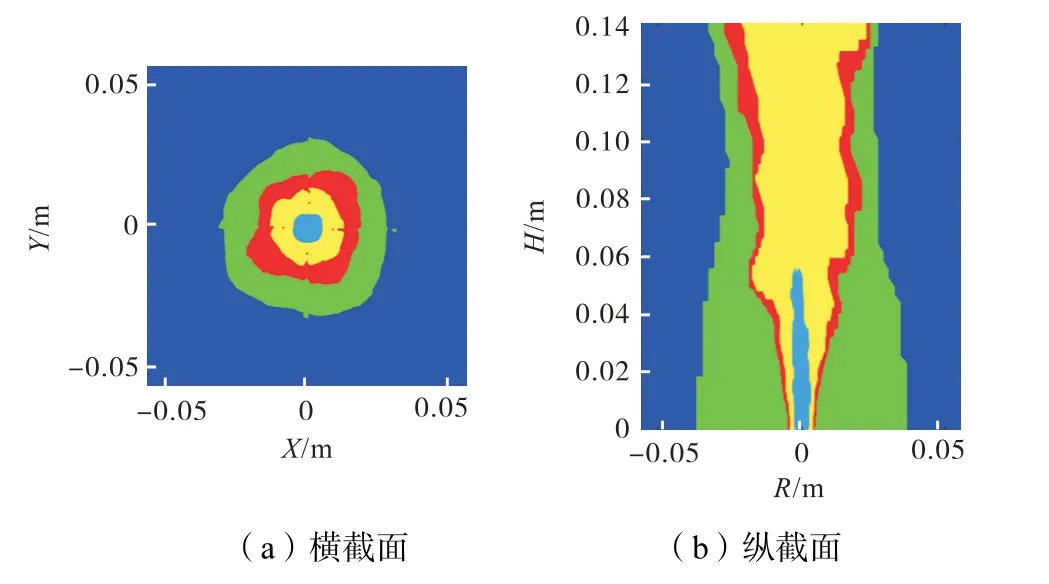
图3 5维特征预测结果Fig.3 5-D feature prediction results
结果显示:以CH4、CH2O、CO、OH 和T 为特征时,燃烧区域预测的准确率达98.72%.可见,这5 维特征可以在很大程度上代表燃烧区域.
为了进一步探寻能用来识别燃烧区域的最基本特征,下面将减少特征维数进行研究.
2.3 最少特征识别
2.3.1 4 维特征
减少1 维特征,依次以缺少CH4、缺少CH2O、缺少CO、缺少OH 或缺少T 的4 维特征进行识别,以此来分辨特征的必需性,预测准确率见图4,预测结果见图5 所示.
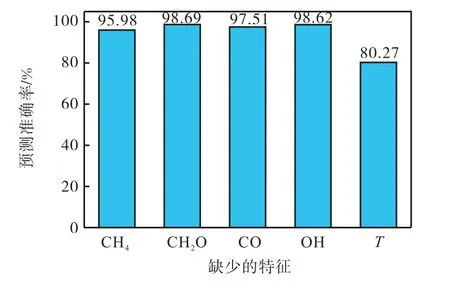
图4 4维特征预测准确率Fig.4 4-D feature prediction accuracy
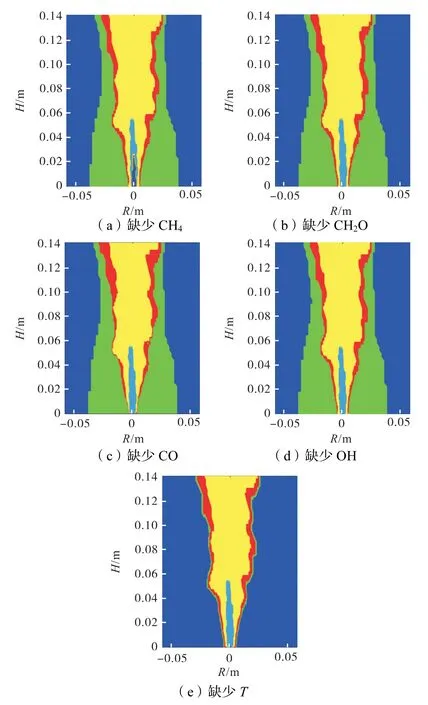
图5 4维特征预测结果Fig.5 4-D feature prediction results
结果显示:当缺少CH4时,燃烧区域预测的准确率为95.98%,发生明显下降,且可以注意到,此时的中心燃料区内有一部分被误识别为其他区域.
当缺少CH2O、CO 或OH 时,燃烧区域预测的准确率均在97.50%以上,仍保持较高水平,区域划分及火焰形态存在细微不同,但都比较准确.
当缺少T 时,燃烧区域预测的准确率骤降至80.27%,此时难以区分常温空气区与热伴流区,但不影响对火焰面、预热区和中心燃料区的预测.
可见,以CH4为特征,可以识别中心燃料区;以T 为特征,可以识别常温空气区与热伴流区的分界面,这两者在燃烧区域预测上是必需的.
2.3.2 3 维特征
继续减少1 维特征,CH4和T 为必需特征,依次以加入CH2O、CO 或OH 的3 维特征进行识别,预测准确率如图6 所示,预测结果如图7 所示.
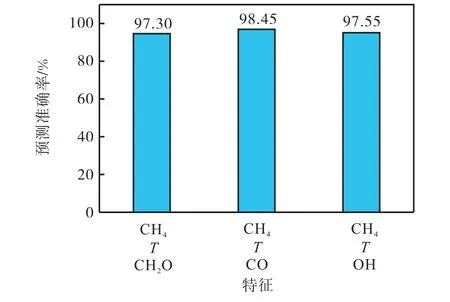
图6 3维特征预测准确率Fig.6 3-D feature prediction accuracy
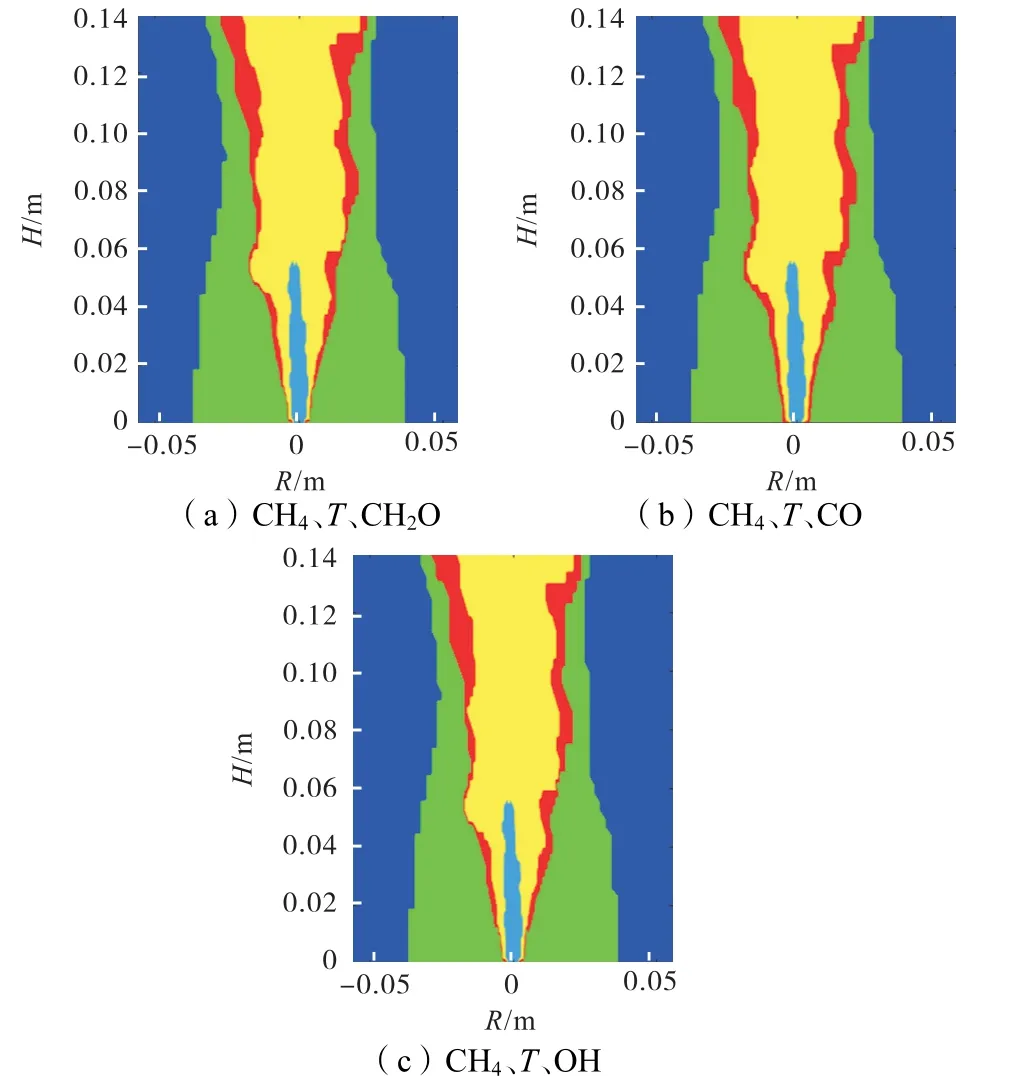
图7 3维特征预测结果Fig.7 3-D feature prediction results
结果显示,以3 维特征进行识别,燃烧区域预测仍较准确,选择CO 时,准确率较高,为98.45%;选择CH2O 或OH 时,准确率有所下降,分别为97.30%和97.55%.
2.3.3 2 维特征
继续减少1 维特征,以CH4和T 这2 维必需特征进行识别,预测准确率为97.29%,预测结果如图8所示.
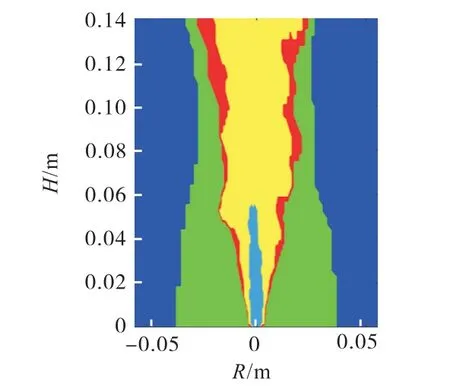
图8 2维特征预测结果Fig.8 2-D feature prediction results
结果显示,以CH4和T 为特征进行识别时,燃烧区域预测的准确率为97.29%,与以CH4、T、CH2O 这3 维特征识别的准确率97.30%非常接近,整体上保持了较高的准确率.此时,误识别主要发生在火焰面上的几块小区域.
可见,凭借CH4和T 这2 维特征,便可以完成较为准确的燃烧区域识别,CO 和OH 可以提高在火焰面上的识别准确率,而CH2O 对燃烧区域识别的准确率几乎没有影响.
2.3.4 1 维特征
继续减少1 维特征,依次以CH4、CH2O、CO、OH 或T 仅1 维特征进行识别,预测准确率如图9 所示,预测结果如图10 所示.其中,以CH2O 为特征时,所有区域被识别为第0 类,无法进行预测.
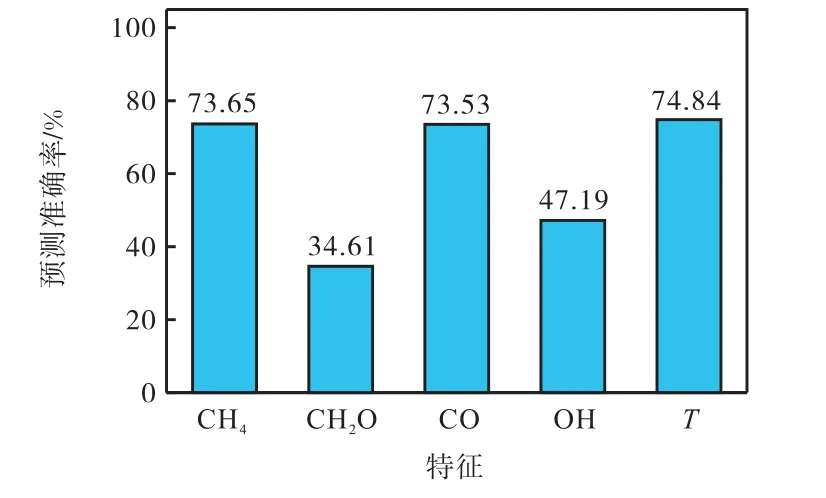
图9 1维特征预测准确率Fig.9 1-D feature prediction accuracy
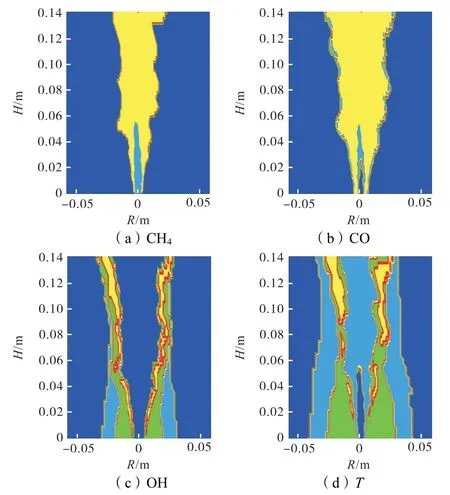
图10 1维特征预测结果Fig.10 1-D feature prediction results
结果显示,以CH4为特征,可以识别中心燃料区与预热区的分界面,以及预热区与火焰面内侧的分界面;以CO 为特征,可以识别火焰面外侧与热伴流的分界面;以T 为特征,可以识别常温空气区与热伴流区的分界面;以OH 为特征,虽然无法正确划分各区域,但识别出了某些分界面的位置和形状;以CH2O为特征,对燃烧区域识别没有效果.
3 结果分析
在上一节中,搭建了ANN,应用BP 算法对燃烧区域聚类分类的结果进行学习.通过调整特征种类并逐步减少维数,在保证高准确率的前提下,将维数减少至2 维.
当以较少维数的特征进行识别时,虽然准确率高,但其误识别发生在了最值得关注的火焰面上.为了研究火焰面识别结果是否可靠,下面将对比以49维聚类的火焰面,基于ANN 以2 维、3 维、4 维、5 维以及49 维特征识别出的火焰面,并比较相关系数.
利用相关系数来判断结果的相关性,相关系数计算方法如下:
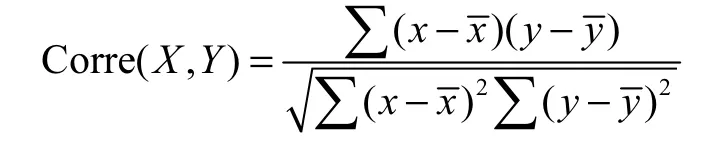
ANN 不同特征维数识别与聚类识别结果的相关系数如图11 所示,火焰面识别结果对比如图12所示.
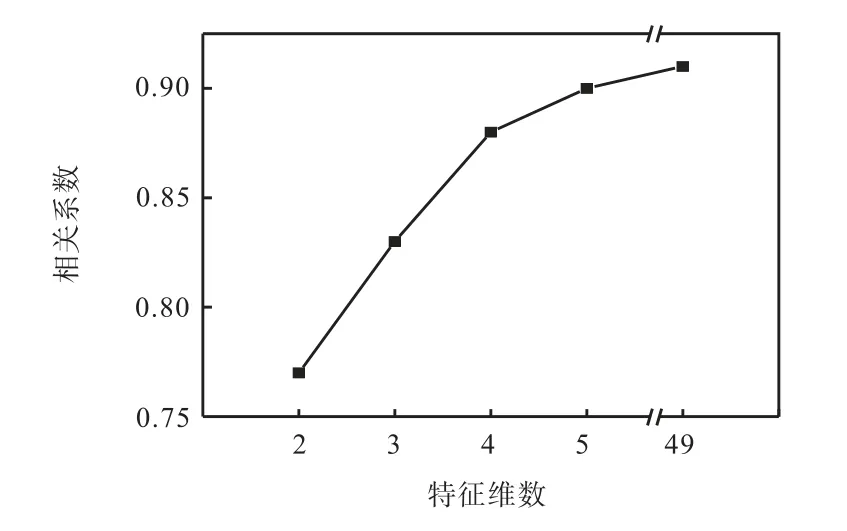
图11 ANN 不同特征维数识别与聚类识别结果的相关系数Fig.11 Correlation coefficients between ANN recognition of different feature dimensions and clustering results
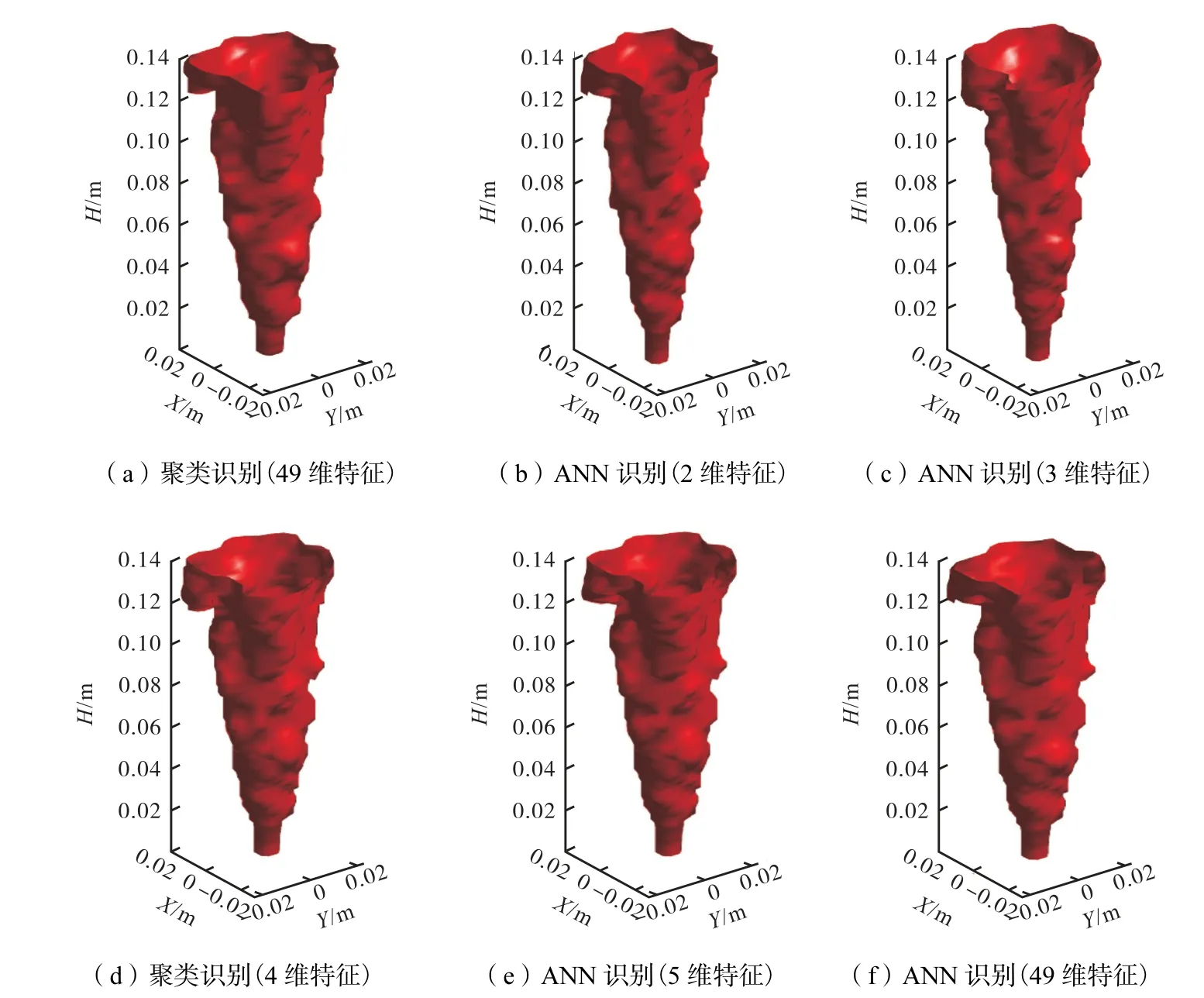
图12 火焰面识别结果对比Fig.12 Comparison of flame surface recognition results
可见,通过ANN 识别出的火焰面与聚类算法得到的火焰面,在整体形态上非常相似.即使以2 维特征进行识别时,ANN 与聚类结果的火焰面相关系数也在0.7 以上,可以认为二者高度相关.在逐渐增加特征维数时,可以进一步提高火焰面的相关系数,火焰面的细节得到优化,形态也越来越接近.
通过上述研究,可以发现:①凭借CH4和T 这2维特征,便可以完成较高准确率的燃烧区域识别,但在火焰面上的识别存在细小问题;②当以CO、OH 为特征时,对燃烧区域识别准确率有了一定程度的提高,这主要体现在火焰面上,而以CH2O 为特征时,对准确率的提高没有帮助;③火焰面的准确识别,相比于其他区域来说,需要提供更多维数的特征.
4 结论及展望
本研究对MILD 燃烧的HM1 工况大涡模拟数据进行了基于ANN 的燃烧区域识别,得到以下结论:
(1) 将ANN 应用于燃烧区域识别是可行的,且在不同维数的特征下都可以进行识别,只需燃烧空间某点的极少数特征,如某些组分质量分数、温度等,即可识别出该点属于燃烧的哪一区域.
(2) 在HM1 中,凭借CH4和T 这2 维特征,便可以完成较高准确率的燃烧区域识别,但在火焰面上的识别存在细小问题,加入更多维数的特征,能够使火焰面的识别变得更加精细.
(3) 与以往学者如Wan 等人的工作相比,基于ANN 的燃烧区域识别所需的特征数更少,可根据具体工况灵活选择维数,而不必完整收集7 维数据.在减小数据收集难度的同时,提高了识别准确率,因此该方法更适合在实际生活、实际工业中使用.举例如下:在易燃区域加装某些实时测量重要特征(CO、OH、T 等)的仪器,进行燃烧实验测量,提取数据给识别系统,用于训练学习,一旦着火,识别系统可以立刻发现火情,判断燃烧的范围和程度,并发出警报;在应用中,尤其是如MILD 燃烧这类分布式燃烧,仅凭借肉眼和普通装置难以寻找火焰结构,可使用识别系统,准确区分火焰面、预热区、燃料区等火焰形态特征,这将有助于分析火焰的变化规律.
本研究还有一些工作尚未深入,如仅以单一燃烧工况作为研究对象,未来会将此方法推广至其他工况;仅对固定时刻的瞬态燃烧场进行了识别,未来将进行持续一段时间的燃烧区域识别,以此分析不同区域的动态变化;使用的浅层ANN 依赖于监督信息的支撑,未来可以增加神经网络层数,通过深度学习来进行无标签燃烧场的区域识别,这将进一步减少工作量.
