基于BERT嵌入和对抗训练的农业领域命名实体识别
2022-10-29费凡杨林楠
费凡,杨林楠
(云南农业大学大数据学院,昆明 650201)
随着人工智能技术不断涌入各个行业,农业领域的服务平台及电商产业也在不断升级。在每天呈几何级数增长的农业文本数据中,高效且无误地找出所需的实体信息以及解析出更复杂的语义知识都是在实现智慧农业道路上所必须面临的挑战。命名实体识别属于自然语言处理领域中基础的信息技术,可以看作是序列标注的一种特殊形式[1],在此主要解决的问题是从海量的非结构化农业文本数据中识别出专有的实体及其类型,常见的实体类型有农作物、病害、虫害等。这为农技服务平台问答系统的实现搭建了基础,也为农业领域中的信息抽取和挖掘研究明确了方向[2]。
在命名实体识别的研究道路中,最初是采用规则和字典匹配的方法。例如Liu等[3]通过设计和调整最佳模板来识别数字和时间表达式。字典匹配方法是通过字典中内置的实体从目标序列中提取所有匹配的字符串。这些方法可能会在某些特定领域取得成功,但是都未能解决OOV(Out-of-vocabulary)问题[4]。另外,这两种方法都严重依赖于耗时的手工特性。后来,统计机器学习的方法逐步兴起,CRF结构[5]成为命名实体识别最常用的方法。Li等[6]和Malarkodi等[7]使用CRF结构在其自构建的注释语料库上识别农业命名实体,如作物、疾病和农药等,通过选择不同的特征组合得到合理的试验结果。统计的机器学习方法虽然有效地提高了中文命名实体识别的精度,但是其仍然依赖于特征工程,导致工序十分耗时和繁琐[8]。
基于深度学习的模型由于其不需要手工设计特征的端到端学习[9]而被广泛应用于命名实体识别。其中,代表性的网络模型就是双向长短期记忆(Bidirectional Long Short-Term Memory,BiLSTM)神经网络[10]。Huang等[11]提出了第一个用于识别命名实体的BiLSTM-CRF机制。此外,Espejo-Garcia等[12]首次提出了一种基于BiLSTM和Softmax的深度学习架构,用来开发一个端到端的序列标签植物检疫规则。研究表明,基于BiLSTM的模型擅长捕获句子的局部上下文特征,但对于更长距离的全局上下文特征的提取能力微弱,在捕获远程依赖关系方面受到限制。因此,最近的研究使用了预训练语言模型,如基于Transformer的双向编码器表示模型BERT[13,14],以此动态生成更长距离的上下文嵌入表示。试验结果表明,BERT预训练阶段在大规模的语料库和较高的硬件性能支持下,可以显著提高许多自然语言处理任务的性能。近年来,深度学习与对抗训练机制[15]相结合的方式在自然语言处理领域开始流行,它作为一种正则化方法成为文本研究的另一条道路。Miyato等[16]利用深度学习技术,首次提出在词向量层添加扰动,进行半监督文本分类任务。Chen等[17]将对抗训练应用到实体识别和关系抽取的联合模型中,取得了跨语言、多数据集的优秀效果。Zhou等[18]则在词嵌入层添加扰动,提升了低资源下命名实体识别模型的泛化能力。
1 数据收集与处理
由于农业领域的命名实体识别语料库大多尚未公开[19,20],因此本研究利用Scrapy框架爬取了中国农业科学院版权下的中国作物种质资源网的关于农作物病虫害的相关知识,经过正则表达式、字符格式规范化等操作去除了不必要的字符、网址等非文本数据。经统计,本研究爬取并清洗的文字共800余篇农业文本,5 600个句子。接下来就是标注标签工作,由于是自己定义的标签类别,所以需要人工手动标注,而实体的标注需要大量特定领域的知识,从而又增加了注释的难度。另外,本研究通过查阅资料和咨询专家的方法,选择校验农业领域的专有名称实体,包括了农作物和疾病。基于现有研究本文进一步将疾病类别划分为更细粒度的实体,分别为“病害”和“虫害”。此外与农作物相关的一些实体,比如农药和肥料以及病原也被考虑在内。采取BMES的实体标注方式,B代表实体名称的开始位置,M代表实体名称的中间位置,E代表实体名称结束位置,S代表只有单个字的实体名称,O代表文本中的非实体。后面紧跟的实体类别信息分别用以下英文来表示:CROP(农作物)、DISEASE(病害)、PEST(虫害)、AC(农药)、FERTILIZER(肥料)、MICROBE(病原)。部分语料库标记示例如图1所示。

图1 语料库标记示例
另外,针对数据集中存在的错标现象,选取实体在数据集中标记最多的类别作为真实类别,将错标实体进行矫正,针对存在的漏标现象对实体进行文本匹配,对漏标实体进行标记,以此达到降低数据噪声、优化训练的目的。为了更好地捕捉上下文信息以及预训练语言模型的输入序列长度限制问题,将长文本按照512个字符长度进行切分,同时为保证句子的完整性而不丧失上下文语义信息,以句号作为切分符,对长度为512的子句向前索引进行截断,剩下句子加入到下一个序列中去。
经统计,最终得到的标记实体数目共16 048个,其中农作物名称6 287个,病害名称2 176个,虫害名称1 538个,农药名称3 514个,肥料名称1 425个,病原名称1 108个,为方便后续试验,将所有类别数据按照7∶2∶1的比例划分为训练集、测试集以及验证集,具体详情如图2所示。

图2 农业语料库实体类别的分布
2 模型架构
本研究总体模型架构(BERT-Adv-BiGRUCRF)的处理流程是:首先以单个字符作为输入单元,将BERT预训练语言模型作为模型嵌入层,接着对每个嵌入向量进行扰动,将得到的对抗样本radv和嵌入向量T一同输入BiGRU网络,最后连接CRF架构优化输出序列,最终得到所需的实体及其类别标签。整体模型架构如图3所示。
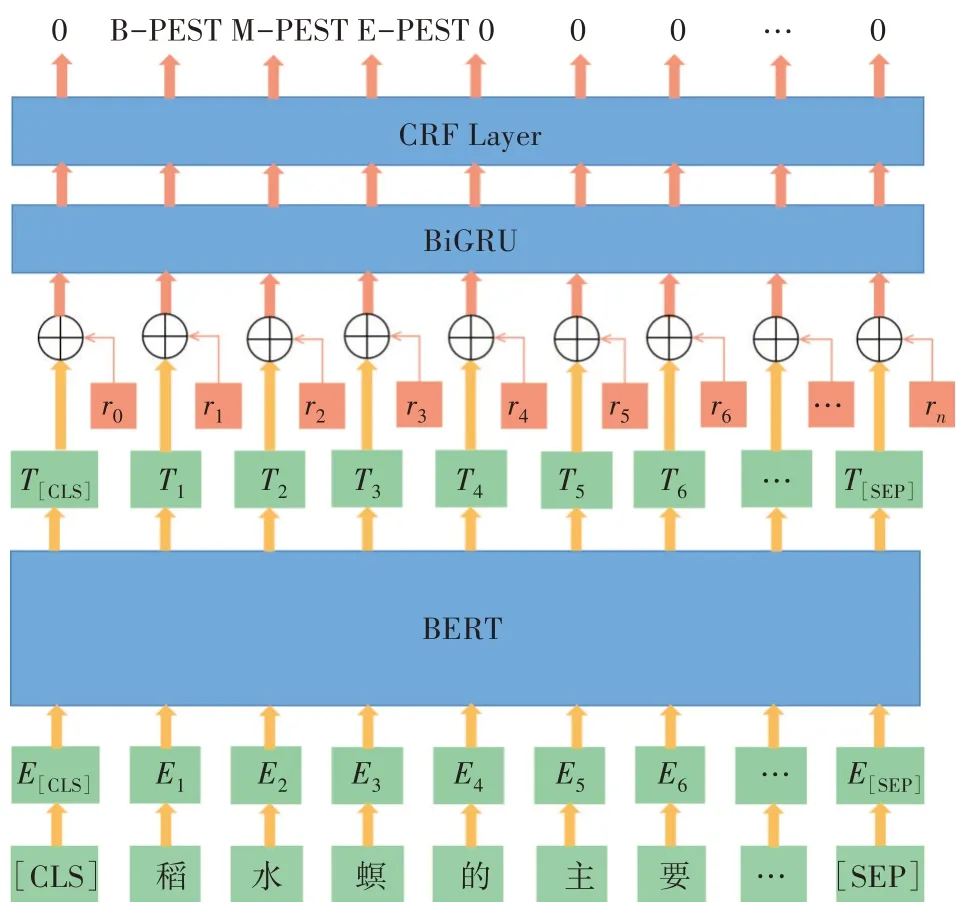
图3 总体模型框架
2.1 BERT预训练语言模型
由Transformer组成的双向编码器表示的BERT,是一种用于预训练的无监督和深度的语言表示模型。为了准确地表示与上下文相关的语义信息,需要调用模型的接口,以获取语料库中每个汉字的嵌入表示。BERT采用深层双向Transformer编码器作为模型的主要结构,它主要引入了自注意机制,并利用了卷积神经网络的残差机制使模型的训练速度更快、表达能力更强。同时,摒弃了循环神经网络(Recurrent Neural Network,RNN)的循环结构,BERT模型的整体结构如图4所示。
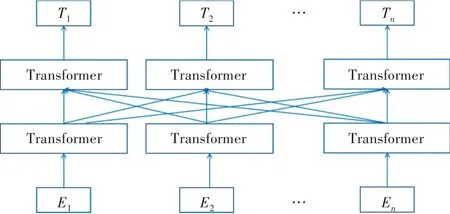
图4 BERT模型
En是单词的编码表示,Tn是经过训练后的词向量。该模型的工作原理是利用Transformer结构构造多层双向编码器网络,一次性读取整个文本序列,使每一层都可以集成上下文信息。模型的输入采用嵌入加法方法,通过添加词向量(Token Embedding)、句向量(Segment Embedding)和位置量(Position Embedding)这3个向量实现了预训练和预测下一个句子的目的,组成结构如图5所示。

图5 BERT模型输入
在中文农业语料的文本处理中,不同位置的字符或词语具有不同的语义,Transformer表明标签序列中嵌入的信息为其相对位置或绝对位置信息,计算公式如下。

式中,Ppos是单词在文本中的位置,i表示维数,dmodel是编码向量的维数。利用余弦函数对奇数位置进行编码,偶数位置也用一个正弦函数进行编码。
为了更好地捕捉词级和句级信息,采用掩码语言模型和下一句预测(Next Sentence Prediction,NSP)2个任务对BERT预训练语言模型进行联合训练。掩码语言模型类似于完形填空,随机屏蔽掉语料库中15%的单词,用[mask]形式来标记,接着要求BERT模型正确预测被屏蔽的单词。训练中采用的具体策略是,对于这15%的单词,其中只有80%的单词被[mask]替换,10%的单词被随机替换为其他单词,剩余10%维持不变。NSP任务是通过训练模型来理解句子之间的关系,即判断下一个句子是否是前一个句子的下一个句子。具体方法是从文本语料库中随机选择50%的正确句子对,并从文本语料库中随机选择剩下50%的句子对来判断句子对的正确性。掩码语言模型的词汇处理和下一句预测的句子处理是联合训练的,确保每个单词的向量都能代表全局信息,使模型表达语义更加准确充分,能够描述字符级、词级、句子级甚至句子之间的关系,从而提高整体模型的泛化能力。
2.2 BiGRU编码层
门控循环单元(GRU)[21]是长短期记忆神经网络(LSTM)的一种变体,LSTM网络包括遗忘门、输入门和输出门。在传统递归神经网路(RNN)训练过程中,常常出现梯度消失或爆炸问题,LSTM仅在一定程度上解决了梯度消失问题,并且计算耗时。GRU结构包括了更新门和重置门,它是将LSTM中的遗忘门和输入门合并为更新门。因此,GRU不仅具有LSTM的优势,而且简化了其网络结构,可以有效地进行特征提取,其网络结构如图6所示。
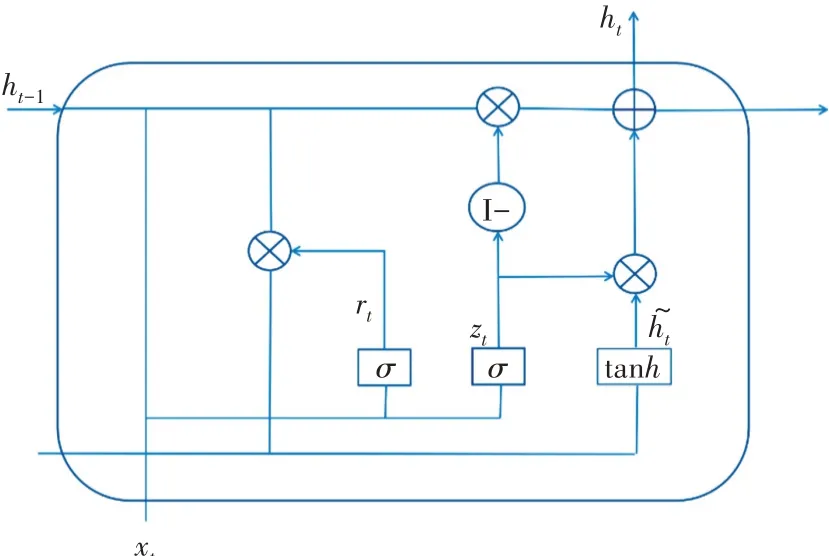
图6 GRU结构单元
xt
在GRU网络结构中,更新门为z,重置门为r,更新门zt是计算需要将多少前一隐藏层的序列信息传输到当前隐藏状态。假设zt取值[0,1],则当值接近于1时表明需要传递,而当值接近于0时表明需要忽略信息。重置门rt的计算公式与更新门原理相似,但权重矩阵不同,zt和rt的计算公式见(3)和(4)。首先,在t时刻输入的序列数据xt,之前时刻隐藏层的状态ht-1,以及相应的权重分别被相乘,并添加到σ函数中。在zt和rt计算完成后,可以计算出在t时刻需要记忆的内容。其次,利用重置门确定t-1处序列信息的隐藏状态,在时刻t需要被忽略的信息,输入rt、ht和xt,并使用tanh函数计算候选隐藏状态。最后,将当前单位保留的序列信息转移到下一单位,即是在t时刻zt和ℎ͂的乘积,ℎ͂表示隐藏单元ht需要保留的序列信息,(1-zt)和ht的乘积则表示需要多少信息,详细计算公式如下所示。
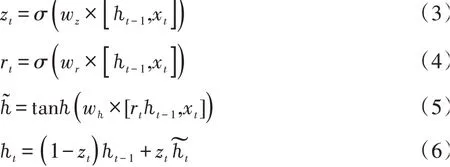
式中,xt表示t时刻序列信息的输入,ℎt-1表示前一隐藏层的状态,ℎt表示t时刻的隐藏状态,w为权重矩阵,wz为更新门权重矩阵,wr为重置门权重矩阵;σ为sigmoid非线性变换函数,tanh为激活函数,ℎ͂为候选隐藏状态。
从GRU单元的工作原理来看,它可以丢弃一些无用的信息并且模型的结构简单,从而降低了计算的复杂度。然而,简单的GRU并不能充分利用文本的上下文信息。因此,本研究设计添加后向GRU来学习后向语义,GRU前向和后向神经网络一起提取序列信息的关键特征,即BiGRU网络模型,如图7所示。
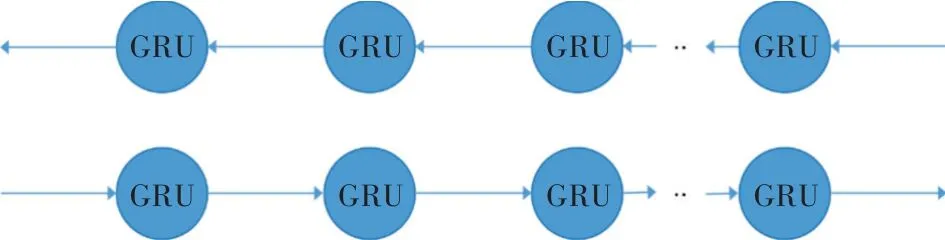
图7 BiGRU网络结构

2.3 CRF网络
命名实体识别问题可以看作是一个序列标记问题,BiGRU层输出隐藏状态上下文特征向量h,表示为h={h1,h2,…,hn},这个向量只考虑了数据中的上下文信息,而不考虑标签之间的依赖关系。CRF是一种基于EM模型和HMM模型提出的序列标记算法,通过考虑标签序列的全局信息,可以解决标签偏差问题,并更好地预测标签。命名实体识别的CRF模型是使用输入句子中的单词序列作为观察序列,标注过程是根据已知的单词序列推断出最有可能的标签序列。
因此,本研究添加了1个CRF层来对全局最优序列进行标记,并将隐藏状态h={h1,h2,…,hn}转换为最优标签序列y={y1,y2,…,yn}。CRF的计算原理:首先对于指定的文本输入序列x={x1,x2,…,xn},计算每个位置的得分,如公式(10)所示。其次,通过Softmax函数计算归一化序列y的概率,如公式(11)所示。最后,使用维特比算法计算得分最高的标签序列,如公式(12)所示。
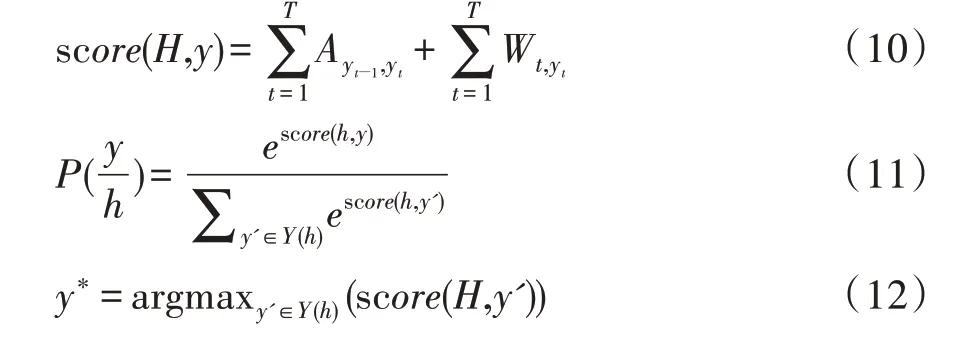
式中,Ayt-1,yt代表转移矩阵,表示从标签yt-1到标签yt的转移概率,Wt,yt代表发射矩阵,表示从词xt得到标签yt的发射概率,T为序列长度,score(H,y)表示输入取值为H的条件下,输出标签序列取值为y的得分函数。y′∈Y(ℎ)为所有可能标签序列表示归一化后得到的关于输出序列y的概率分布。y*表示解码后得到的最大分数的输出序列。
2.4 对抗训练
对抗训练就是在原始输入样本中添加一些扰动,虽然变化不大,但是很容易造成分类错误,然后训练网络来适应这些变化,使得对扰动样本更具鲁棒性,以此提高模型的泛化能力。对抗训练的数学原理可以概括为如下公式。
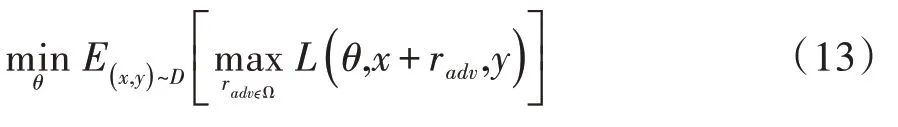
它可以看成由2个部分组成,分别是内部损失函数的最大化以及外部经验风险的最小化。前者目的是寻找最坏情况下的扰动,其中radv表示在输入样本中添加的扰动,Ω表示扰动的范围空间,L表示损失函数,θ表示模型参数,x表示输入样本,y表示样本的标签。后者目的是基于对抗方式的基础上,寻找损失最小的模型参数,使得模型具有一定的鲁棒性,其中,D表示输入样本的空间分布。
关于设计合适的扰动,Miyato等[22]提出了FGSM和FGM算法,思路都是让扰动的方向沿着损失增大的方向,也即梯度提升的方向。它们的区别在于采用归一化方法不同,FGSM是通过Sgn函数对梯度采取max归一化:
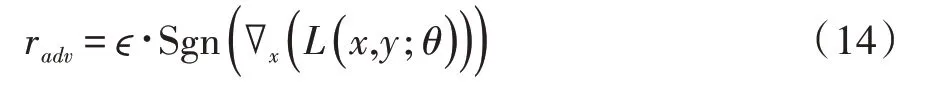
其中,ϵ为常数,通常设为0.25。∇x(L(x,y;θ))表示损失函数L对于输入x的梯度,Sgn为符号函数,即如果梯度上的某个维度的值为正,则为1,如果为负,则为0。FGM则是采取L2归一化:

式中,g为梯度,||g||2表示梯度的L2范数,即用L2范数做了1个scale,从公式(15)来看,L2归一化更加保留了梯度的方向,而max归一化不一定和原始梯度的方向相同。当然它们都有1个共同的前提,就是损失函数L必须是线性或至少是局部线性的,以此保证梯度提升的方向是最优的方向。
选用FGM对抗训练算法,在模型训练过程中,直接对由BERT模型得到的每个嵌入向量组成的参数矩阵进行扰动,并且是将1个batch数据当成整体,统一进行归一化计算,因为本来范数的计算也只是起到scale的作用,所以这样做影响很大,还能实现更加高效的调用。
3 结果与分析
3.1 试验参数和环境配置
模型的参数配置都经过了反复的试验证明。采用ADAM优化算法,模型训练的批处理参数为24,迭代次数设定为8,学习率为2e-5,还引入了dropout机制以减轻模型的过拟合问题,dropout的值对模型的性能有直观的影响,设定为0.5。模型训练最大序列长度为128,评估最大序列长度为512。此外,试验的运行环境配置如表1所示。

表1 试验环境配置
3.2 试验结果与分析
在不依靠人工设计特征的情况下,通过不断地调整模型参数,在自构建的农业注释语料库上测试模型的识别效果。语料库中的训练集、测试集、验证集的划分比例合理,三者之间无重叠部分,因此,将测试集的输出结果作为实体识别效果的评价指标是恰当的。农业领域中的实体抽取和类别标注的试验结果常采用以下3个评价指标,分别是准确率、召回率和F值。其中,准确率是指正确识别命名实体的识别率,召回率是指测试集中正确识别命名实体的识别率,F值是以上两者的调和平均值,这是模型的综合评价指标。
为了表明本研究提出的BERT-Adv-BiGRUCRF模型在农业领域命名实体识别的表现效果,在其他模型上进行对比和消融试验,其他模型包括IDCNN-CRF、BiLSTM-CRF、BiGRU-CRF、BERTSoftmax、BERT-CRF、BERT-BiLSTM-CRF、BERTBiGRU-CRF、ERNIE-BiGRU-CRF和RoBERTa-WWM-BiGRU-CRF,其对比识别结果如表2所示。
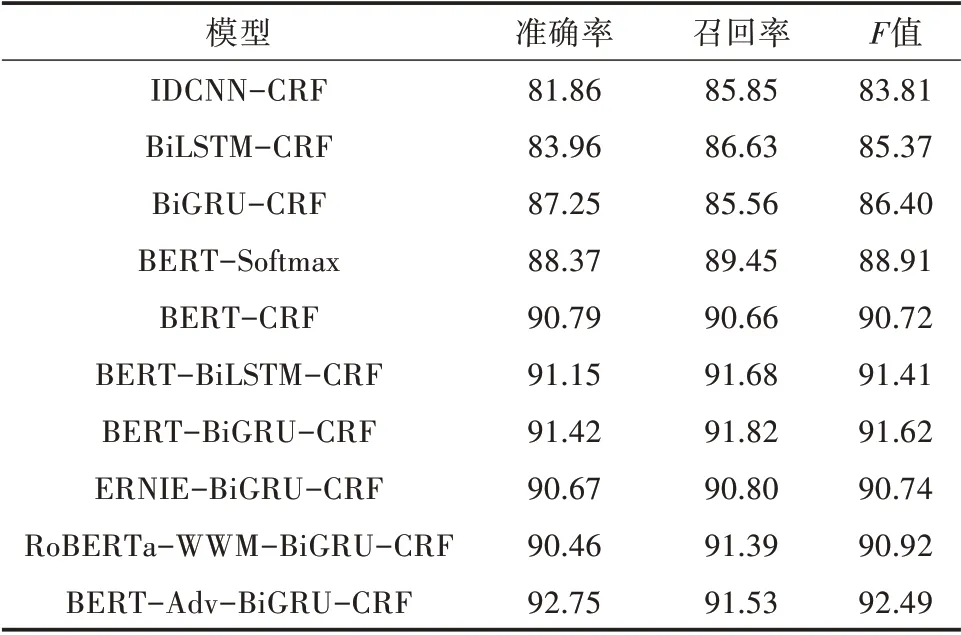
表2 不同模型试验结果对比(单位:%)
由表2可知,IDCNN-CRF、BiLSTM-CRF和BiGRU-CRF模型通过隐藏层获取了丰富的上下文的序列信息,通过添加CRF层,动态规划实体间相邻的标签获取最优的序列标注,模型识别F值分别达到83.81%、85.37%和86.40%。但由于它是基于词向量的输入,会出现实体被错误拆分的情况,导致有些复杂的实体不会被正确识别。例如:水稻品种鄂汕杂1号会被错误拆分成鄂汕/杂/1号。另外分析结果发现,同一文本中,部分农药实体“顺天星1号”会被错误标记为农作物名称,出现这种标记不一致的现象,是由于“顺天星1号”与许多农作物名称构词方式相同,都是词语加上数字的形式,在识别过程中,虽然这些模型获得了上下文的局部特征信息,但是并没有考虑到更长距离以及全局的语境,从而导致整体识别效果不够理想。
基于BERT模型的输入是基于字向量且完整保存了全局的语义信息,它很好地解决了不同语境下同一词语的不同语义以及指代问题,与前3个模型相比,准确率、召回率和F值均得到明显提升,BERT-BiLSTM-CRF和BERT-BiGRU-CRF准 确 率分别达到91.15%和91.42%,召回率分别为91.68%和91.82%;F值 分 别 为91.41%和91.62%,其 中BERT-BiGRU-CRF模型相比较BERT-BiLSTMCRF稍优一点。在BERT-BiGRU-CRF模型基础上,依次去掉上下文编码层BiGRU和输出层CRF,以此进行消融试验,得到的BERT-CRF和BERT-Softmax模型识别的F值分别降低了0.90和2.71个百分点。这表明了BiGRU网络是提高编码质量的有效方法,以及CRF层对于中文命名实体识别至关重要。
在BERT-BiGRU-CRF模型的试验结果基础上,进一步将预训练语言模型换成ERNIE和Ro-BERTa-WWM,以此进行其他预训练语言模型的效果评估,结果显示F值分别下降0.88和0.70个百分点,这表明BERT模型对于本研究自构建农业数据集的识别效果最优,其他改进预训练语言模型在农业命名实体识别上可能不一定会奏效。
最后,加入对抗训练后的BERT-BiGRU-CRF模型的准确率提升了1.33个百分点,召回率下降了0.29个百分点,F值提升了0.87个百分点。这表明本研究添加的对抗训练算法确实可以在一定程度上提高识别结果。为了验证对抗训练机制的通用性,选用中文领域的命名实体识别数据集Resume NER进行试验,该数据集是根据新浪财经网(https://finance.sina.com.cn/)关于上市公司的高级经理人的简历摘要数据进行筛选过滤和人工标注生成的。它包含1 027份简历摘要,实体标注分为人名、国籍、籍贯、种族、专业、学位、机构、职称8个类别,试验结果如表3所示,它成功验证了对抗训练机制对于提升模型泛化性和鲁棒性的作用。
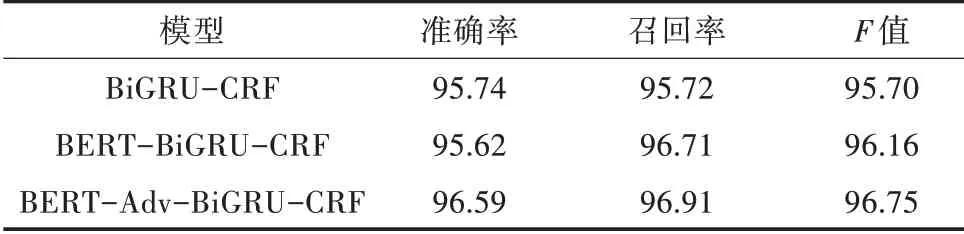
表3 不同模型试验结果对比(单位:%)
如图8所示,利用本研究模型对于农作物、病害、虫害、农药、肥料以及病原六类实体的识别结果F值,可以看出模型对农作物和虫害的识别结果F值普遍较高,其余类别则相对降低一些。分析其原因,农作物的实体数目众多,所以训练程度较为充分,而且一些培育品种名称常常是词语加数字的组成方式,例如豫粳6号、桂引901,这些明显的特征信息在一定程度上提高了农作物实体识别的准确率。大部分虫害名称也具有较为规则的后缀组成词,例如叶蝉、蓟马等,因此识别准确率也比较高。而对于一些病害名称,它们往往存在实体嵌套情况,例如水稻倒伏等,模型还不能获取相关特征信息来有效解决此类问题。肥料名称大多构词比较单一,比如氮肥、钾肥等,但是却存在大量的一词多义现象,比如氮、磷、硫酸铵、过磷酸钙等,它们在某些地方只是化学名词,并不代表肥料的意思,模型不能有效地区分干扰信息。病原名称构词复杂、冗长且边界模糊,而且大部分存在实体嵌套情况,如茶拟盘多毛孢、水稻条纹叶枯病毒等,模型很难得到较好的语义和边界信息,所以识别效果普遍较差。对于上述提及的问题,可以通过提升模型整体的复杂度方法,以此获取更丰富的额外特征信息,或者构建相关的领域词典等方法以期达到更高的识别效果。

图8 农业实体试验结果F值对比
总体来说,本研究提出的BERT-Adv-BiGRUCRF模型对农作物、病害、虫害、农药、肥料以及病原六类农业实体的识别结果F值分别达到了95.30%、84.00%、94.68%、84.96 %、86.67%、86.27%,表明模型在不使用任何字典或外部注解资源的情况下,在自构建的农业标注语料库上对于命名实体识别任务的有效性和合理性。
4 小结
针对农业领域标注语料库稀缺有限的问题,首先自构建了一个农业领域的注释语料库,其中包含了6类实体和16 048个样本。此外,对于农业领域中文命名实体识别任务,提出了引入BERT预训练语言模型的识别方法,提升了模型的识别效果。最后,对输入样本进行对抗训练,以此提高模型整体的泛化性和鲁棒性,一定程度上提升了命名实体识别效果。总体模型架构BERT-Adv-BiGRU-CRF在自构建的农业注释语料库中对6类农业实体都达到了良好的识别效果。今后的工作将集中在以下3个方面:一是将自构建的农业注释语料库进一步扩充以及对于存在的噪音误差进行修正或增强,对类别数目少的样本进行平衡处理,以此达到模型的更好识别效果。二是引入更加丰富的特征信息,比如radical-level特征[23]和工业词典等,提升对于构词复杂冗长和边界模糊实体的识别效果。三是尝试一些模型压缩方法,比如知识蒸馏、剪枝等以此来减少训练时间和算力,降低模型空间复杂度,以此达到工业级的需求和应用。
