统计优先级多址接入协议的改进与仿真*
2022-10-28吴皓威吕顺兴欧静兰
吴皓威,吕顺兴,张 扬,欧静兰
(1.重庆大学 a.微电子与通信工程学院;b.通信与测控中心,重庆 400044;2.空天地网络互连与信息融合重庆市重点实验室,重庆 400044)
0 引 言
在无线自组网中,节点的对等性要求它们内部运行相同的网络协议栈,共同维持整个网络的正常运行。介质访问控制(Medium Access Control,MAC)层多址接入协议作为底层网络协议架构的重要组成部分,负责网络资源分配和信道接入控制,对整个网络进行合理的规划和调度,其性能决定系统的信道利用率、端到端时延和吞吐量等关键指标。
在战术数据链和航空自组网中,因为保密、抗干扰等要求,多采用跳频跳时脉冲调制的多通道物理层。这类网络可以使用基于统计优先级多址接入(Statistical Priority-based Multiple Access,SPMA)协议完成接入控制,能够满足大量用户的同时接入,提升增加系统容量,同时具有信息安全、抗干扰等优点。SPMA协议是随机接入协议的一种,是带有冲突避免的载波侦听多路访问(Carrier Sense Multiple Access with Collision Avoid,CSMA/CA)协议的改进。与CSMA/CA不同的是,SPMA协议的信道状态通过负载统计量来衡量,并设置不同的优先级门限值,根据负载统计量与优先级门限的差值来合理限制低优先级分组的发送,从而确保高优先级分组的高传输成功率。SPMA协议可以满足系统的多种服务质量(Quality of Service,QoS)要求[1]:高优先级信息端到端时延尽量短;高优先级数据第一次的传输成功概率不低于99%;支持大量的节点和多优先级分组的接入,且在高业务负载下维持稳定的吞吐量。
经典的SPMA协议中[2-7],存在如下问题:一是固定门限设置导致吞吐量下降;二是退避时间计算过于简单导致接入时延增加;三是高优先级分组持续接入导致低优先级分组“饥饿”。通过对这些问题的分析,本文提出了统计差值退避算法和虚拟时间戳排队算法,完善协议的接入控制流程,从而改善SPMA协议的整体性能。其中统计差值退避算法相比于传统SPMA协议的固定门限设置和简单退避算法,具有更高更稳定的系统吞吐量和更低的优先级平均时延;同时,虚拟时间戳排队算法使得不同优先级的分组都能够保证最低的接入带宽,解决了低优先级分组的“饥饿问题”。通过仿真分析了网络的吞吐量、分组传输成功率和分组接入时延等三个关键指标,验证了改进协议的可行性和性能优势。
1 SPMA协议
图1为SPMA协议的算法框图,主要由多个优先级队列、信道负载统计、门限比较与退避和队列调度器四个部分组成。接入控制算法的核心就是比较信道负载统计值和优先级门限值来决定分组接入与否。在必要时将执行退避算法,以缓解网络信道的拥塞,降低分组的碰撞概率。
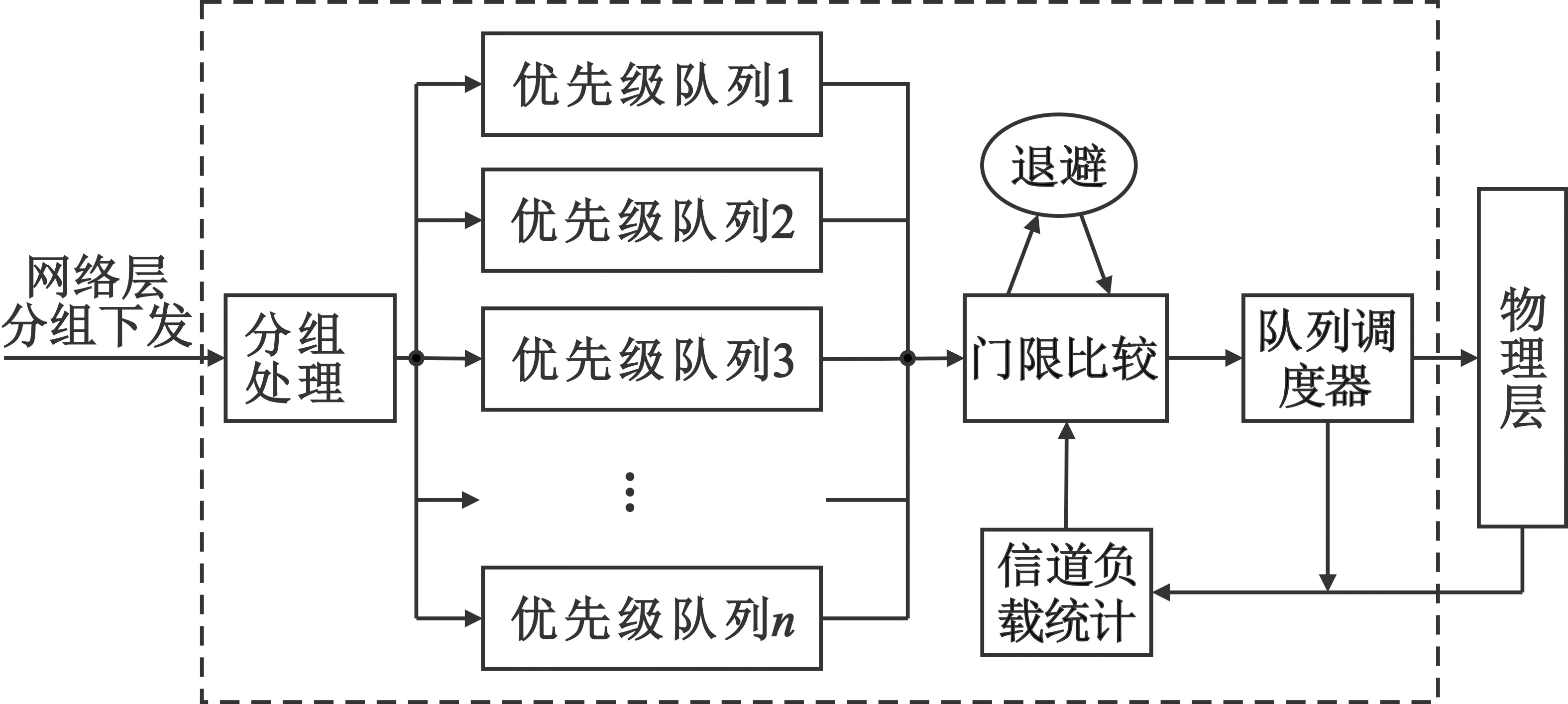
图1 SPMA协议算法框图
协议运行流程如下:
Step1 当网络层数据分组下发到MAC层后,运行分组处理模块,并将处理完的分组插入到对应的优先级队列中。
Step2 SPMA协议状态将从空闲转为工作模式,通过遍历优先级队列,找到非空队列中优先级最高的队列,并获取当前的信道占用情况。
Step3 协议转到门限判决状态,检查信道占用统计值是否大于分组的队列门限值,若是,则执行退避算法,阻塞队列,进入Step 4;若否,检查分组是否超时,进入Step 5。
Step4 如果退避时间结束,再次检查最高优先级队列,重复Step 2~3。
Step5 如果分组超时,将其从队列中移出并删除;若分组未超时,协议状态转到Step 6。
Step6 队列调度算法从所有优先级队列中选出最适合发送的分组,将其取出队列并接入信道。
Step7 分组完成接入后,继续检查优先级队列的状态,若非空,跳转到检查最高优先级队列的状态,执行Step 2;若空,跳转到空闲状态。
当协议处在中间任何状态时,如果有比正在处理分组优先级更高的分组到达,均打断该状态,跳转到Step 2开始执行。
2 SPMA协议改进算法设计
2.1 基于统计差值的退避时间算法
在传统SPMA协议中,节点把获取的信道负载统计值与优先级门限的差值作为节点各优先级业务分组接入网络的参考依据,低优先级分组的退避时间和接入门限值将会影响高优先级分组的传输成功率和端到端时延,同时对网络吞吐量的稳定性造成影响。所以,门限设置与退避时间算法往往是SPMA协议中一个重要的研究问题。
SPMA协议的门限设置算法包括基于业务量比例的静态门限设置[4]和动态门限设置[8]。同时,结合固定门限设置,现有文献中提出的退避时间算法要么因为设计过于简单而增加系统时延,要么与优先级门限值的设置息息相关,无法很好地控制低优先级分组的接入。而且在网络初始化时,业务量比例往往无法提前得知,采用动态获取的方式又会耗费时间,这给优先级门限值的设置带来了困难。所以,本文摈弃了信道负载与多优先级门限比较这一思路,采用单一门限阈值,然后通过控制低优先级分组的接入速率来限制网络负载量,可以很好地解决传统方法信道利用率低的问题,分组接入速率的倒数就是分组的退避时间。
根据SPMA协议原理,接入模块只要能够控制接入网络中的分组数目,使得整个网络负载量处于最低优先级门限以下,就能够保证99%以上的传输成功率。同时,为保证高优先级的QoS要求,需要按照分组的优先级从高到低依次接入网络。本方法将待发送业务量分为三个部分:高优先级业务量、待退避业务量和限制发送业务量。统计差值调度模型如图2所示。

图2 统计差值调度模型
设业务的优先级序号为i,从小到大对应的业务优先级依次降低。用Tth表示分组成功率维持在99%以上的最低优先级对应的门限,Li表示全局网络中各优先级待发送业务量。用pback表示待退避的优先级,则pback满足如下关系:
(1)
将低于门限值的待退避业务量定义为统计差值VSD,其表示为
(2)
节点通过统计网络中各优先级的待发送业务量Li计算pback和VSD:当优先级高于pback的业务到达时,直接接入网络,不必回退等待;当优先级等于pback的业务到达时,调度器使用VSD计算业务分组的退避时间,按照退避时间依次接入该优先级队列中的业务;当优先级低于pback的业务到达时,阻塞在该优先级队列中,等待队列调度算法的处理。
经过上述业务量的统计可知全局网络中退避优先级pback的所有业务量Lback和本地节点的退避业务量Lback,0。本地节点的待退避业务量将退避一段时间后,再尝试发送。定义待退避优先级分组的退避时间为td,则有
(3)
式中:T为分组的统计周期。
使用统计差值调度算法后,接入模块可以根据实际的业务负载统计量计算出与最低优先级门限的统计差值VSD,然后得到退避优先级分组的接入间隔(即退避时间),从根本上限制信道的业务接入量处于最低优先级门限以下,使得传输的高优先级分组达到99%的预期成功率。
2.2 虚拟时间戳排队算法
在无线自组织网络中,为保证高优先级业务的传输成功率,SPMA协议的接入控制模块将对低优先级数据分组进行退避。如果高优先级业务量很大,长期占有信道资源,将导致低优先级分组一直退避或等待,在分组有效期到达后将被删除。而实际网络中,低优先级分组如果长期丢失,却可能导致系统运行出现问题,这种现象称为“饥饿问题”。MAC层接入协议中希望能够添加合适的队列调度算法,来解决低优先级分组的“饥饿”。本文引入虚拟时间戳(Virtual Timestamp,VT),作为分组到达时间的一个参考值。队列调度器将按照一定增长率递增系统的“虚拟时间戳”。已知虚拟时间戳TVT的变化率∂TVT(t+τ)/∂τ为r/∑Bi,系统维护的虚拟时间戳更新公式为
(4)
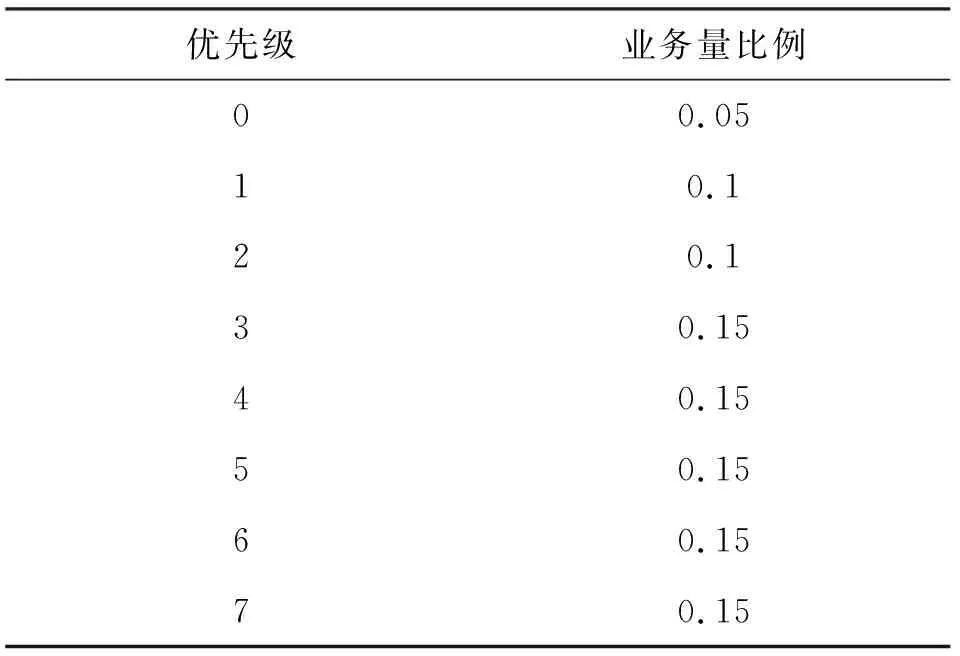
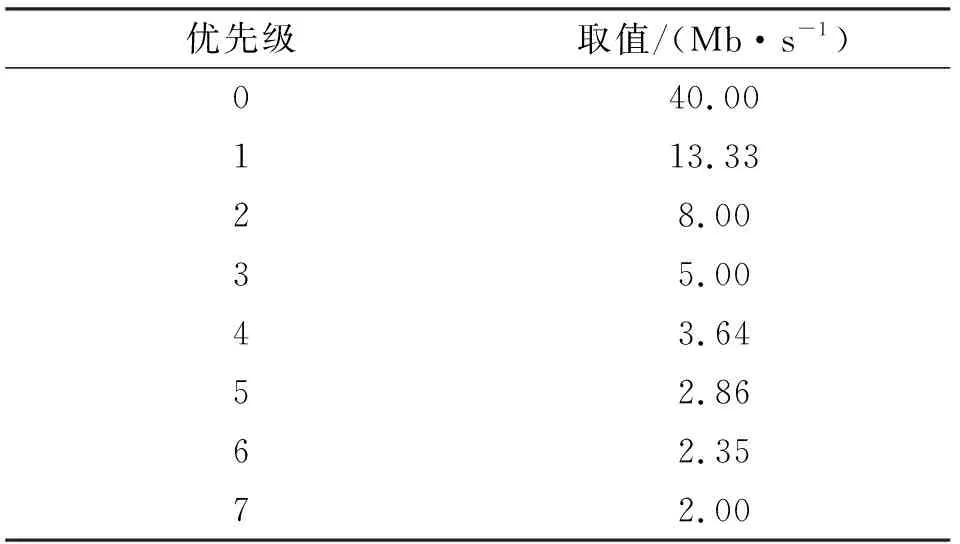
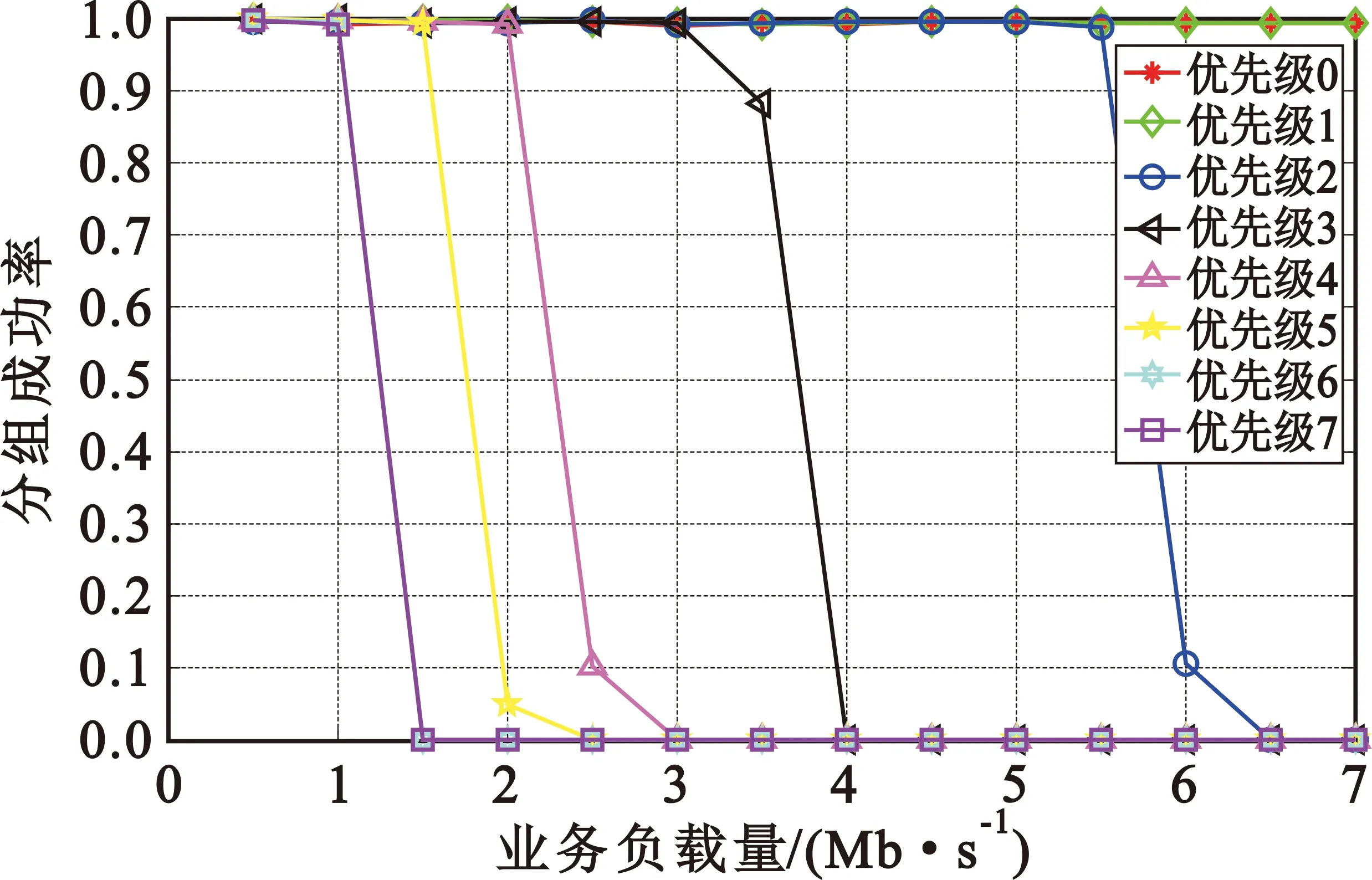
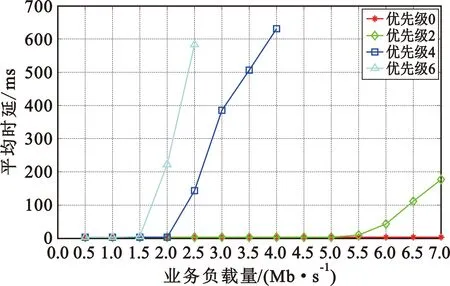
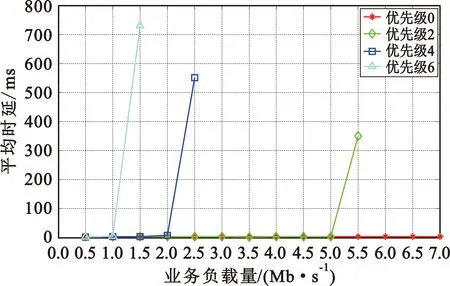
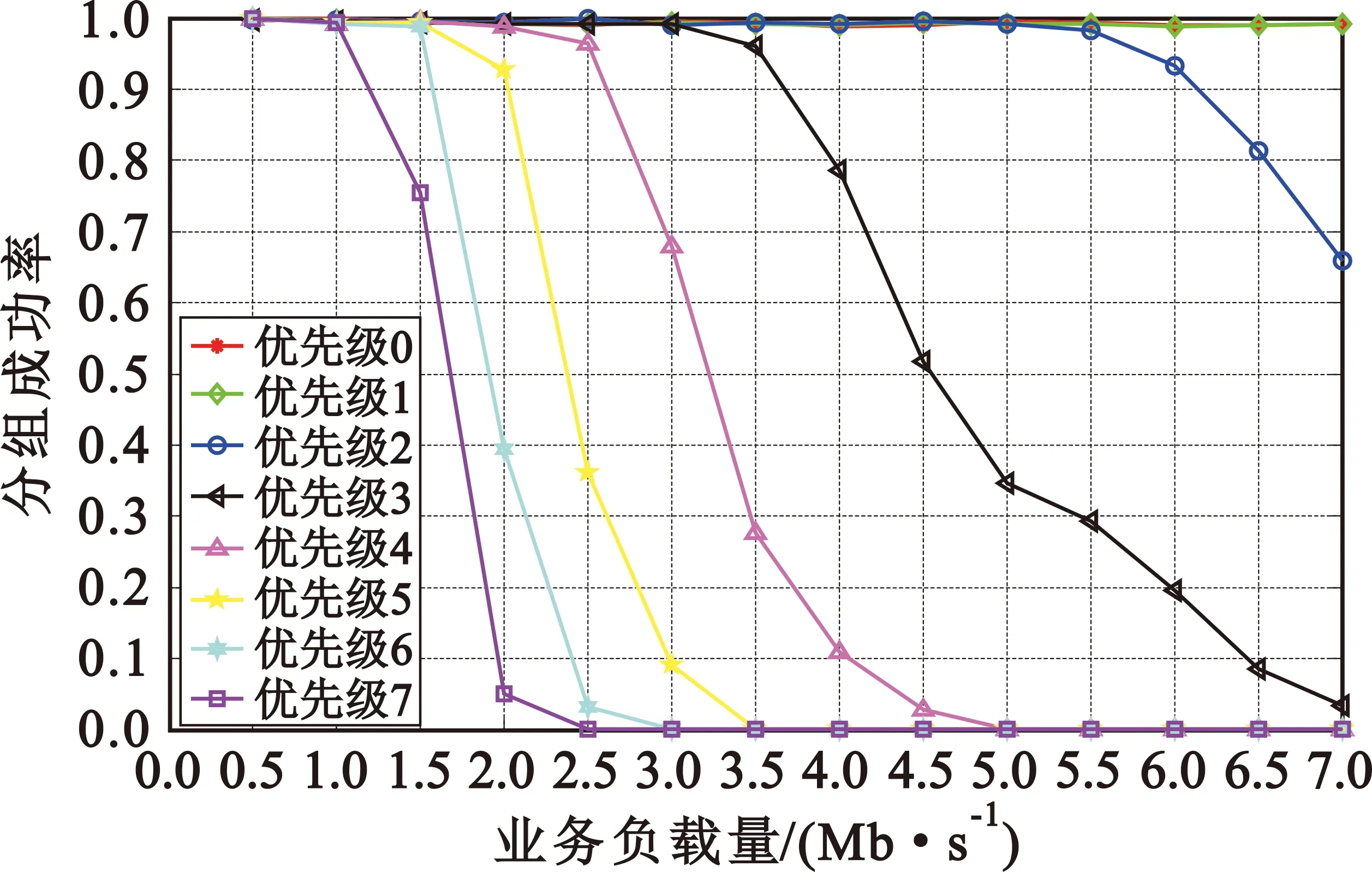
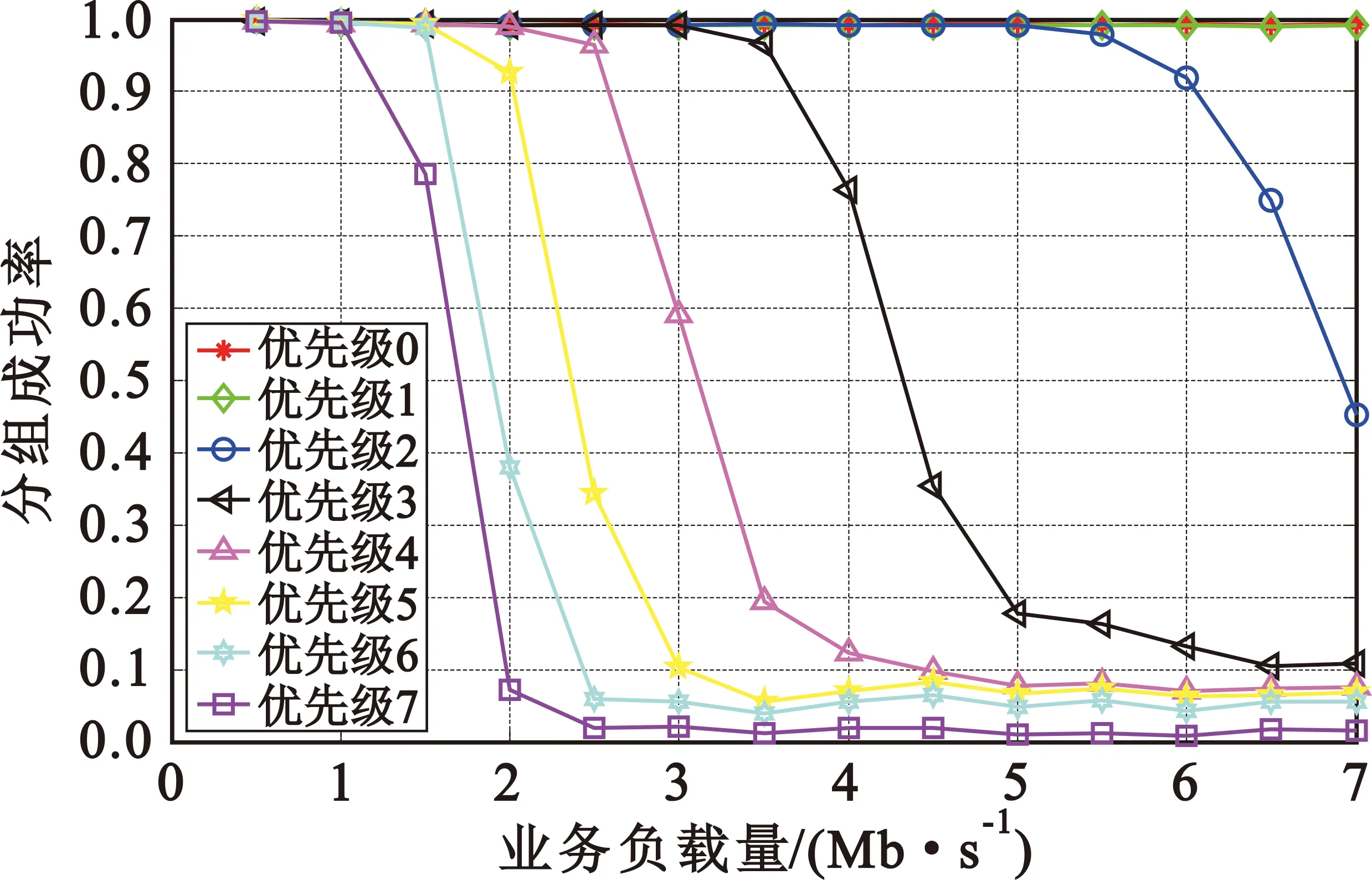
式中:r为基带处理速率;Bi为各优先级队列预设的接入带宽;i 虚拟时间戳是一个随时间增长的函数,可以理解为以所有需要调度的优先级队列能够得到的服务速率为边缘速率的递增函数。 (5) (6) 分析调度原理可以知道,使用虚拟时间戳的队列调度算法有如下特点: (2)各队列中的分组将按照虚拟完成时间大小递增排序; (3)虚拟完成时间考虑到了分组的大小和优先级。 系统的虚拟时间戳将在新的分组抵达时被更新,同时计算出分组虚拟完成时间,填入分组的控制信息域。队列调度核心按照虚拟完成时间从小到大依次发送分组,这样就使得低优先级分组存在被调度的可能,解决了其“饥饿问题”。 引入了队列调度算法,低优先级业务获得了有限的接入带宽,所以改进协议中对优先级低于pback的分组将不会直接丢弃,而是阻塞在该优先级队列中,等待队列调度算法的处理。 当优先级队列非空时,将启动接入控制流程,如图3所示。 图3 改进协议接入控制流程 Step1 从高到低依次遍历各优先级队列,找出非空的最高优先级K,取出队首的数据分组,判断分组是否到期,若是,将分组丢弃;若否,进入下一步。 Step2 判断分组优先级i与退避优先级pback的大小,执行如下分支:若i>pback,进入Step 3;若i=pback,进入Step 4;若i Step3 对于低优先级的分组不做操作,阻塞该队列,返回Step 1。 Step4 优先级回退等待:通过当前信道负载得到统计差值,然后计算出退避时间,进入回退等待;在退避期间,有更高优先级分组到达,进入Step 5;退避时间结束,进入Step 5。 Step5 队列调度:遍历所有优先级队列,找到虚拟完成时间最小的分组;将分组从队列中移除,然后判断分组是否到期。若到期,直接删除;若否,将分组接入信道。 仿真中,参考无线自组织网络分层模型[9],在OPNET上搭建了节点模型,并在进程模型中添加SPMA改进协议,对比SPMA协议传统算法,验证系统吞吐量、优先级平均时延、高优先级传输成功率这三个性能指标。 业务源中将会周期性产生多个优先级的数据分组,分组将按照预定的优先级比列进行发送,发包间隔服从参数为λ泊松分布。假设总业务量为Ltotal,N个节点等量随机发送,单包容量为P,发包间隔的均值λ为λ=N×P/Ltotal。 表1~3给出了网络中的基本仿真参数,包括系统参数和物理层性能参数。 表1 系统参数 表2 不同优先级业务量比例 表3 物理层参数 表4给出了算法仿真中需要收集的统计变量信息,所有统计量将被绘制成曲线,然后分析算法性能。 表4 仿真统计量 3.2.1 统计差值SPMA仿真分析 仿真程序在业务进程模型中设置平稳的业务量,业务量从500 kb/s~7 Mb/s变化;统计周期T均为0.1 s,比较传统SPMA协议中固定门限简单退避算法与本文统计差量退避算法的性能差异。固定门限值按照表2的优先级业务量比例和文献[4]中的公式(2)~(3)进行计算,具体计算结果如表5所示。 表5 优先级门限值 (1)优先级成功率 图4给出了采用统计差值退避算法和固定门限简单退避算法的接入协议优先级成功率随业务负载量变化的关系。可以看到,两种算法均能保证高优先级的传输成功率,但是,固定门限简单退避算法的优先级成功率出现陡降,几乎直接从1下降至0;而统计差值避算法的优先级成功率存在中间值,呈现出随业务负载量逐渐下降趋势。 (a)统计差值避算法 (b)固定门限简单退避算法图4 不同算法的优先级成功率随业务负载量的变化关系 (2)优先级平均时延 图5给出了采用统计差值退避算法和固定门限简单退避算法的接入协议分组平均时延随业务负载量变化的关系。可以看到,两种算法的平均时延在分组未退避时维持在3 ms左右。分组开始退避后,时延随着负载量增大逐渐增大。但是,在相同业务负载下,统计差值退避算法的平均时延略小于固定门限简单退避算法。 (a)统计差值退避算法 (b)固定门限简单退避算法图5 不同算法的分组平均时延随业务负载量的变化关系 3.2.2 系统吞吐量 图6给出了采用统计差值退避算法和固定门限简单退避算法的接入协议系统吞吐量随业务负载量变化的关系。可以看到,两种算法的吞吐量均随负载的增大而增大,在超过1.5 Mb/s后,吞吐量开始趋于稳定。但是,固定门限简单退避算法的稳定吞吐量低于统计差值退避算法,并且存在较大波动。 图6 不同算法的系统吞吐量随业务负载量变化的关系 分析协议的接入原理可以知道,在负载超过门限值后,固定门限的SPMA协议通过退避整个优先级分组的方式来限制低优先级分组的接入,一旦开始退避,该优先级的分组成功率将立刻下降到0。退避掉整个优先级虽然保证了高优先级的成功率,但是也使得一部分信道容量被浪费,并且导致了吞吐量出现波动。同时,根据退避公式可知,采取简单退避算法时,低优先级分组一般需要退避多个统计周期才有可能再次接入信道,这样也大大增加了分组时延,而统计差值算法的退避时间是通过信道负载和优先级门限差值计算得到,是较优的退避时间。 3.2.3 队列调度算法仿真分析 在与3.2.1相同的条件下,按表6所示的预定义优先级接入带宽比例,比较无队列调度和使用虚拟时间戳队列调度的改进协议的性能差异。 表6 预定义优先级接入带宽比例 图7给出了无队列调度算法和采用虚拟时间戳队列调度算法的接入协议分组成功率随业务负载量变化的关系。可以看到,两种算法均可以满足高优先级对成功率的要求。无队列调度算法时,在低优先级分组开始退避后,因为业务量稳定且长期过载,低优先级分组将完全无法接入网络;但是采用虚拟时间戳队列调度的改进协议后,在业务量长期处于过载时,因为给低优先级分组分配了最低带宽容量,所以能够得到部分接入。 (a)无队列调度的改进协议 (b)基于虚拟时间戳队列调度改进协议图7 队列调度算法对分组成功率随业务负载量变化的影响 针对经典SPMA协议算法中存在的固定门限设置导致的吞吐量下降、退避时间设置过于简单、低优先级分组“饥饿”等问题,本文提出了改进协议,并通过OPNET软件进行仿真研究。结果表明,改进协议具有更大更稳定的系统吞吐量,并且在负载持续过载时,保证了低优先级分组的最低带宽接入要求,并能够应用于复杂的战术数据链和航空自组网中,满足特殊网络对优先级接入、重负载下维持稳定吞吐量和大量用户同时接入等QoS要求。同时,在添加了队列调度算法后,改进协议解决了实际场景中的分组“饥饿问题”。对于使用跳频跳时脉冲编码的信号体制,改进SPMA协议具有很重要的理论意义和实践价值。
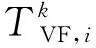
2.3 改进协议接入控制

3 改进协议的建模与仿真分析
3.1 仿真搭建



3.2 仿真结果分析



4 结 论
