基于U-Net的眼底视网膜血管图像分割
2022-10-28罗忠亮
罗忠亮
(韶关学院 信息工程学院,广东 韶关 512005)
眼底检查在眼科疾病的分析和诊断中占据重要地位,人体多种疾病都可在眼底上体现出来,如高血压、糖尿病、白内障、青光眼、视网膜血管病变等[1].从眼底图像分割出视网膜血管并进行分析,可有效地辅助医生对高血压、糖尿病等疾病进行早期诊断和治疗[2-3].
医生手工分割血管方式费时费力、可重复性差,还有可能存在误诊.由于视网膜血管的复杂性,眼底图像采集中会受到噪声、光照和病变背景干扰等因素的影响.因此,视网膜血管的准确分割仍充满挑战,视网膜血管自动分割的研究将具有较强应用价值[3-4].
通常,视网膜血管的分割方法可分为无监督学习方法和有监督学习方法两大类[5].无监督分割方法是基于图像亮度差异及血管纹理特征等对未标记图像建立分割模型,根据最小化函数对模型进行调整,找到血管与背景间的最佳分离.无监督分割方法如阈值法[6]、模型法[7]、血管跟踪法[8]、匹配滤波法[9]、数学形态学法[10]等,此类方法原理简单,计算复杂度低,速度较快,在对比度好、噪声少的眼底图像上可获得较好的分割结果.由于不同眼底图像形态特征复杂度差别大,分割效果不够理想,对于噪声过多及有病变干扰的图像,会导致细小血管的丢失和视盘区域检测出伪血管.而有监督分割方法是利用专家手工标注的视网膜血管图像对二分类器进行多次训练,结合血管特征构造特征训练分类器,对血管像素和非血管像素自动分类,实现血管和背景的分割.常见有传统机器学习分割方法和深度学习分割方法[11].利用深度学习技术提取的特征可更好地学习数据基本属性,具有更好的鲁棒性和较强泛化能力,可达到更好的分割性能.相比传统机器学习方法,深度学习可自动进行特征确定和分割,无需人工设计特征,但是需要人工准确的标注图像作为训练集且分割速度慢.
近年来,深度学习在语义分割、图像分类、目标检测和医学图像分割等多种场景得到非常成功的应用[12].Wang等将卷积神经网络(CNN)和随机森林混合在一起,得到较好的视网膜血管分割效果[13];Ronneberger 等采用全卷积神经网络(FCN)模型将深层信息与浅层信息结合分割结果好[14];徐光柱等采用Dense-net网络获得较高精度的视网膜血管分割[15].
在神经网络结构中,U-Net 结构在医学图像分割中取得了很好性能,非常适合数据量不大的医学图像分割,由于其出色的分割效果从而在医学图像分割中得到广泛应用[16].为了进一步提高分割准确率,笔者采用基于U-Net的视网膜血管分割方法,将浅层特征和高层特征进行融合,特征融合更加充分,可以达到更好的分割效果.
1 基于U-Net的视网膜血管分割
1.1 眼底图像预处理
视网膜血管图像通常包含红、蓝和绿三色通道图像,绿色通道对比度较高,选取绿色通道图像进行测试.因此,为消除眼底图像中普遍存在亮度不均、噪声、血管对比度差等现象,需对图像进行预处理,以便设计的网络模型可更好地学习血管特征.为加快训练网络的收敛性需进行图像归一化,把像素从 0~255 变成 0~1 的范围.预处理包括归一化、中值滤波和自适应直方图均衡化,以减小噪声,提高眼底图像的对比度和清晰度,见图1.
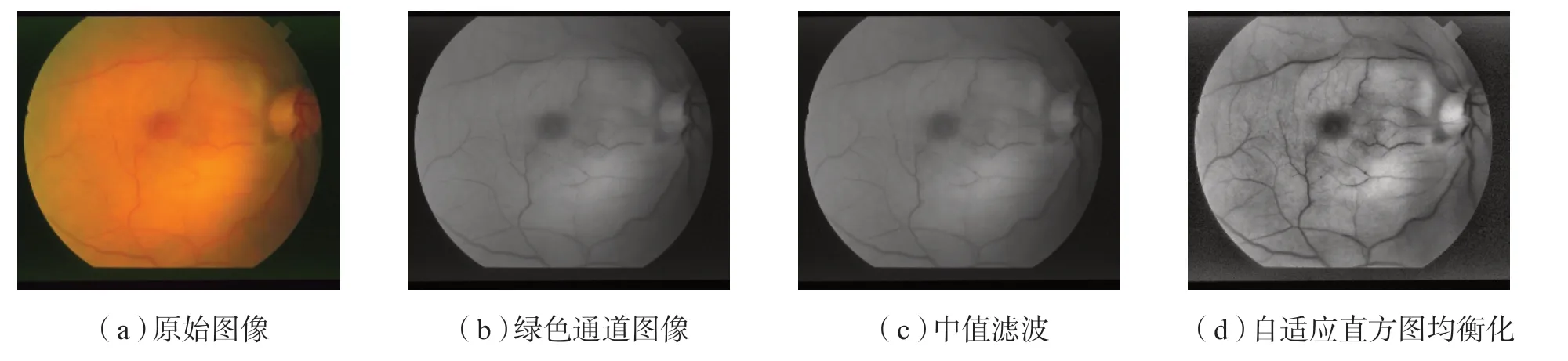
图1 原始图像预处理
1.2 眼底图像数据扩增
眼底图像视网膜血管需要专家手工标注,标注成本很高,导致数据集较少.DRIVE和STARE数据集中分别有40 幅专家标记图像,其中20张用于训练,20张用于测试,图像大小分别为565×584和605×700像素.为了防止网络在训练过程中出现过拟合的现象,提高分割效果与训练学习能力,在网络训练前对数据库训练集中的图像进行数据扩增[3],而测试集中的图像不需数据扩充.数据扩增的过程分别进行0°、45°、90°、135°、180°旋转,再分别进行水平、垂直和镜像翻转人为地扩增训练数据集,DRIVE 和STARE数据库中原始训练集图像数量扩充至原来的15倍,将每幅图像随机裁剪成9 500个48×48的训练集图像块,用于神经网络训练,避免图像数据量不足的问题,以提高其分割性能.
1.3 构建U-Net模型
U-Net是一种在FCN改进基础上的图像语义分割网络,与FCN 相比,U-Net模型不再使用全连接层,可避免出现过多参数.其采用编解码器的思想是以图像为整体进行分割,能将提取后浅层特征和高层特征进行拼接,特征融合更加充分,直接生成分割图,实现图像端到端的自动分割.该结构具有很好的泛化性能,可以在数据集有限的情况下获得较好的分割效果[14].
U-Net结构主要由编码器模块、解码器模块和跳连模块3部分组成[14,17]. U-Net模型构建时,整个U-Net 网络由28个卷积层构成,其中24个卷积层分布在4个卷积块和4个反卷积块中[3].编码器模块通过卷积和池化等操作提取图像的特征信息,由普通CNN组成,包含卷积层,池化层与激活函数等部分,通过最大池化实现下采样层获得图像深层细节特征.特征提取过程使用多个卷积核提取不同形态特征,逐步压缩图像语义特征,通过池化降维减少冗余信息,降低图像尺寸. U-Net中卷积层使用两个3×3非填充卷积,为提高训练网络性能,每个卷积层后跟一个ReLU修正单元和一个2×2池操作,步长为2,实现图像尺寸的收缩,同时在池化后将卷积通道数加倍,以便让更多的图像特征(如边缘、形状等)在各卷积层间传播,弥补池化损失的特征.解码器模块在上采样时得到图像的浅层位置特征,通过一系列2×2反卷积层经过训练后将卷积通道数量减半,恢复分辨率,直到与输入图像的分辨率一致.每次上采样结果与对应裁剪后的下采样特征映射进行求和操作,并融合网络不同尺度高低层语义特征,保留更多高分辨率细节信息,获得更加精细的语义分割效果,提高分割精度.跳连模块为1×1的卷积层,采用激活函数对血管有效像素与背景噪声像素进行分类,实现输出特征图像的二分类.在每个卷积层采用零填充方式进行填充.根据式(1)可知利用零填充可保证网络模型的最终输出与输入图像大小保持一致[3,14].即:

其中,Ii和Io分别表示网络模型输入和输出图像,F、P、S分别表示卷积大小、填充大小和步长,实验时F为33,P为11,S为1.
U-Net模型采用的损失函数是二值交叉熵,交叉熵函数能够更好地优化神经网络,使得分割效果明显,交叉熵公式为:
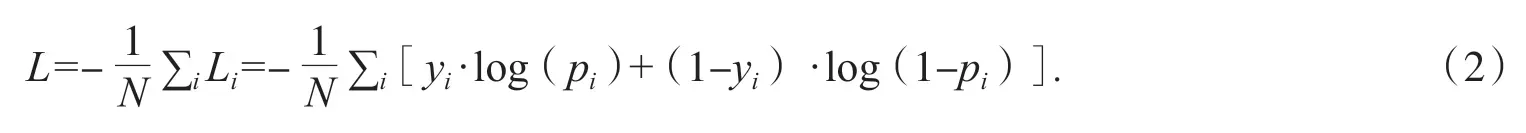
其中,yi表样本i的标记,血管为1,背景及干扰为0;pi表样本i预测为血管的概率.
基于U-Net的视网膜血管图像分割步骤描述为:(1)对眼底图像进行预处理;(2)对训练集进行数据扩增,从而增加训练集数目;(3)将眼底图像数据集上训练好的模型迁移至编码部分;(4)用训练样本对网络模型进行训练;(5)用训练好的网络模型对测试样本进行分割,得到视网膜分割结果,其中U-Net具体结构见图2.
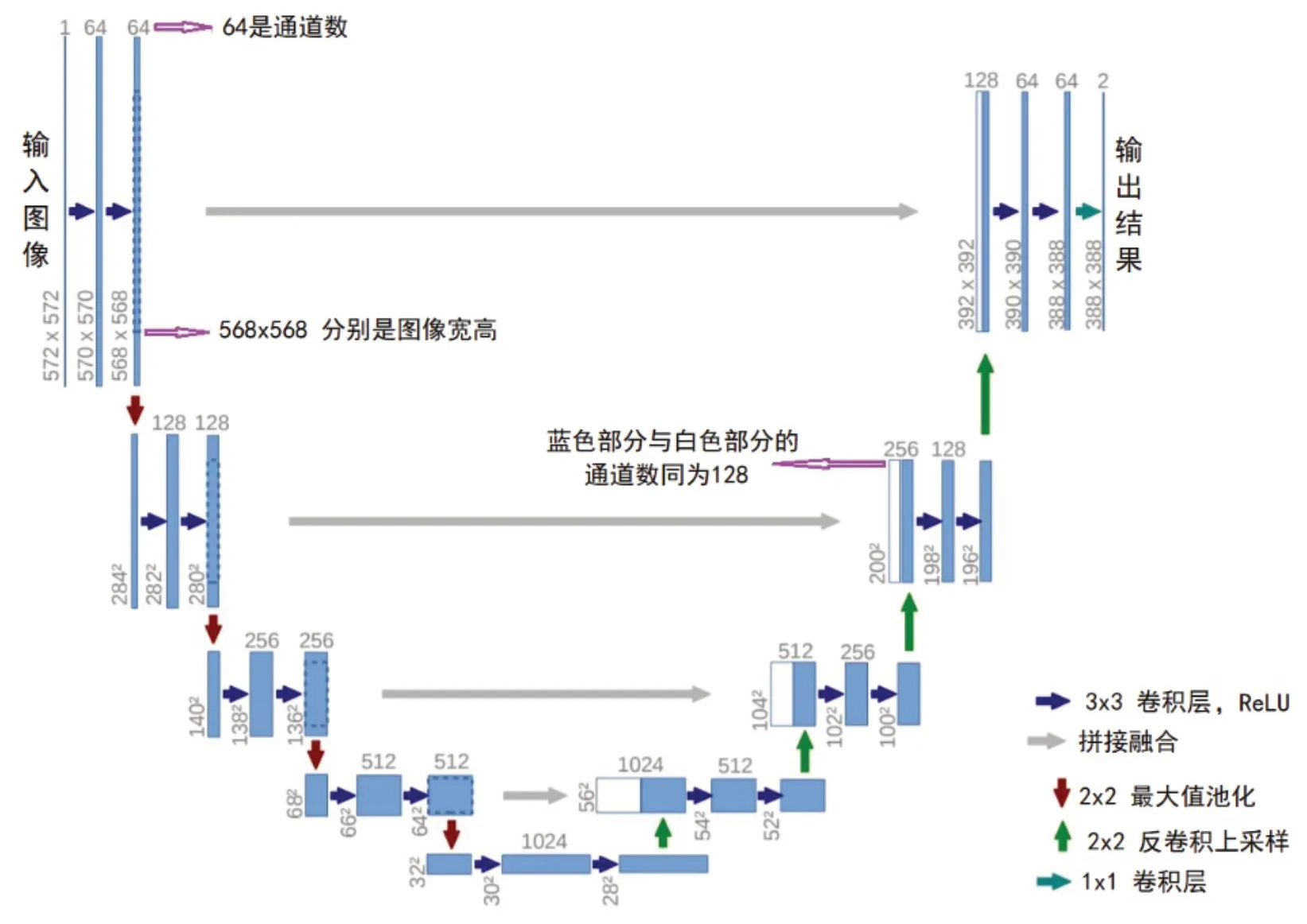
图2 U-Net 结构
2 实验结果分析
网络模型采用U-Net架构搭建,以TensorFlow、Keras 2.3.1、Python 3.8为实验环境,在主频3.6 GHz、CPU 为i7-7700、内存8 GB,64位Win10操作系统的计算机上进行实验.为了测试算法的性能,采用DRIVE[18]和STARE[19]数据库中的眼底图像进行测试.数据集中包含彩色视网膜图像以及视网膜图像标签,其中前20张图像及其标注图像作为实验训练样本,后20张图像及其标注图像作为实验测试样本,标注图像选择第一个专家所做的标注.
训练网络中的偏差参数和权重使用正态分布随机进行初始化,损失函数采用二进制交叉熵进行优化,训练迭代 20 个 epoch.每个卷积层之后的激活函数为ReLU,并且在两个连续卷积层之间使用0.2的dropout.将模型训练的 batch size 设定为 4 ,学习率设置为 0.001.
2.1 视网膜血管分割方法评价标准
为全面评估血管分割性能,采用敏感度Sen、特异性Spe、准确率Acc、马修斯相关系数Mcc、戴斯相关系数Dice等5种参数作为评价指标,其公式分别为:.其中,TP为真阳性、FP为假阳性、TN为真阴性、TP为假阴性;的值在-1和1之间,1表示完美分割,-1表示完成错误分割,Dice越大,相似性越高.
2.2 视网膜血管分割性能分析
为了评价U-Net 网络模型的分割性能,分别对DRIVE 和STARE数据库中的图像进行分割测试,测试结果见图3.图3(a)为原始图像,(b)为专家1手工分割图像,(c)为阈值法,(d)为匹配滤波法,(e)为数学形态学法,(f)为线性跟踪法,(g)为利用U-Net网络模型得出的结果.
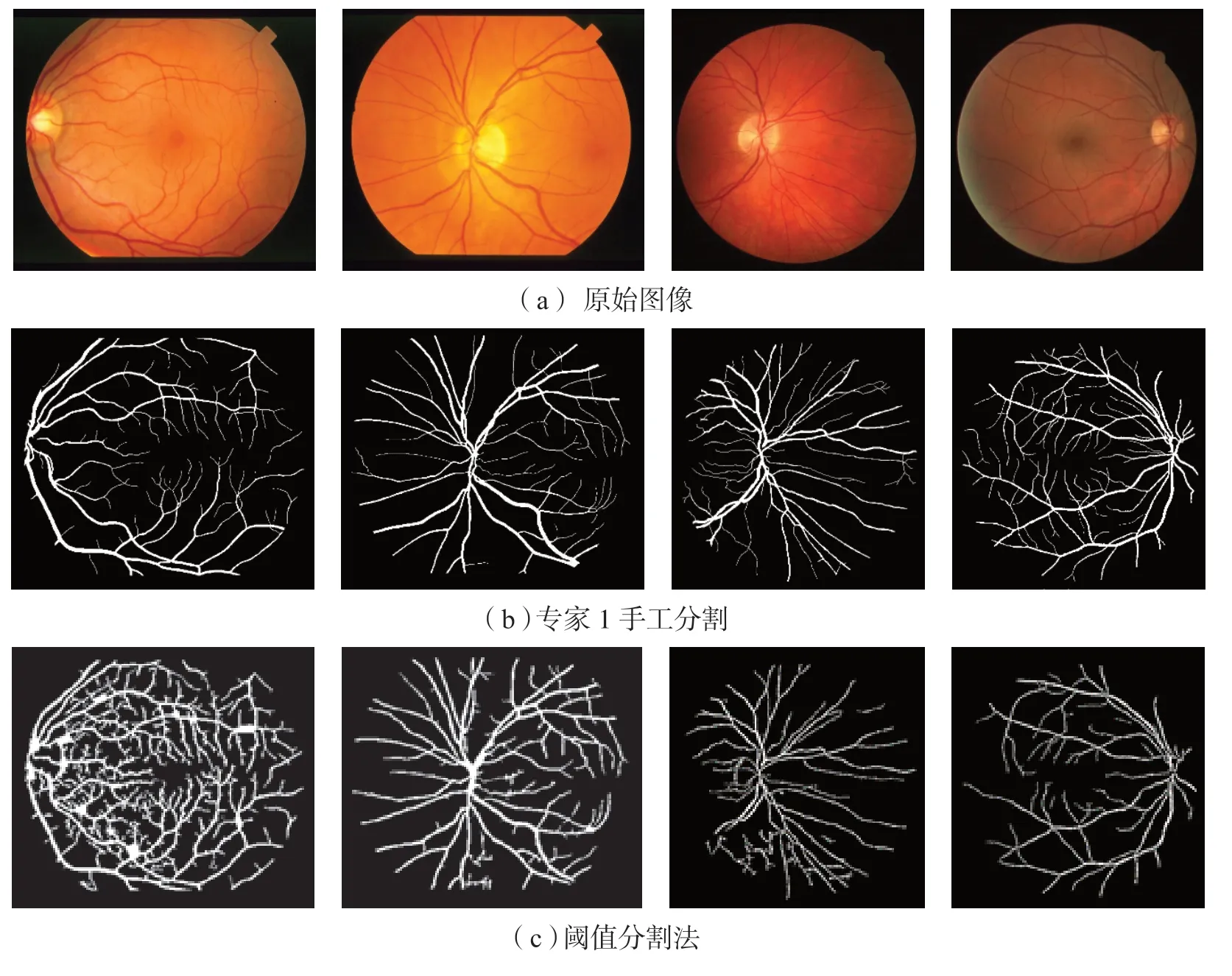
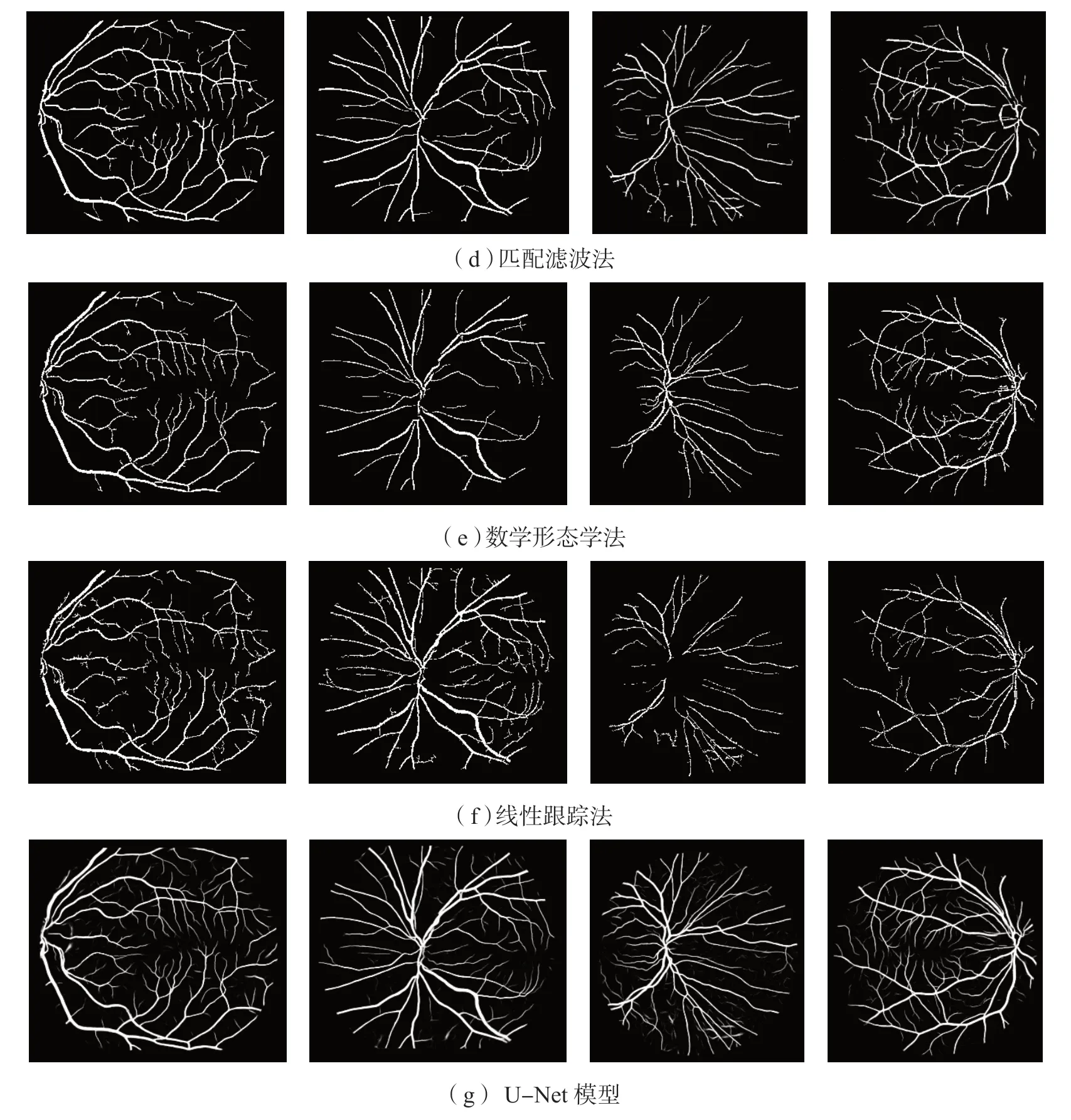
图 3 部分图像分割结果
通过与专家1金标准图像进行对比, U-Net可以较好地区分血管与背景的像素点,证实了本文方法在血管细小、曲折和分叉等复杂情形下能取得较好的分割效果.由图3可知,基于U-Net的分割效果优于几种相比较的方法,具有更强的鲁棒性,能够更准确地提取局部特征并整合全局特征.
通过分析评价指标评估本文算法的性能,U-Net在DRIVE和STARE数据库中的各项分割数据见表1、表2,包括灵敏度Sen、特异性Spe、准确率Acc、马修斯相关系数Mcc和戴斯相关系数Dice.
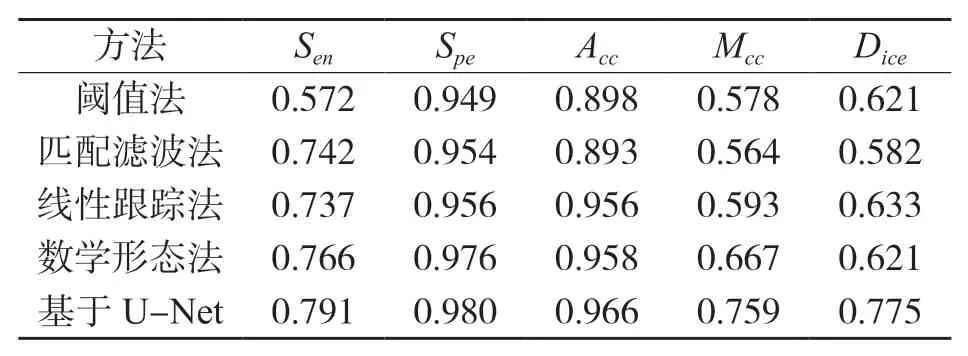
表2 在STARE 数据库的分割性能比较
由表1、表2可知,在DRIVE和STARE数据库中测试对比,本文算法的分割指标Sen、Spe、Acc、Mcc、Dice五个参数均优于所比较的无监督分割方法,准确率、敏感度有明显的提升,说明U-Net网络模型分割血管性能较好.
3 结语
视网膜血管分割是眼底图像研究的一个重要课题,能够有效地辅助医生进行心脑血管疾病、眼科疾病的临床诊断.采用U-Net模型在DRIVE和STARE数据库图像中进行视网膜血管分割测试,从客观评价指标和主观视觉效果来看,文中方法优于几种常见的非监督视网膜分割方法,鲁棒性较好.分割的视网膜血管细小血管末梢分割更为清晰,血管连通程度更高,能有效弥补细小血管断裂和丢失的问题,验证了U-Net模型在医学图像分割的优越性.U-Net模型对小数据集眼底图像视网膜血管分割可获得较高精度,但随着网络加深,U-Net模型在采样过程中会造成一些细节特征的丢失,易造成过拟合,导致网络性能下降,分割准确性降低.为此,在以后的研究中将引入残差模块和注意力学习模块以改进U-Net 模型,进一步提升视网膜血管分割性能.
