基于预训练模型与神经网络的军事命名实体识别
2022-10-28金浩哲董宝良杨诚
金浩哲,董宝良,杨诚
(华北计算技术研究所系统四部,北京 100083)
军事命名实体识别是军事信息抽取的一个基础而重要的环节,用于从军事文本中检测相关军事实体,并将其分类为预先定义的类别,如人物、武器、地点、任务和组织等,从而可以从原始数据中提取有价值的信息。
目前,军事命名实体识别在知识图的构建、智能问答系统、信息检索等方面有着广泛的应用[1-2]。在军事命名实体识别的过程中,主要有三个难点:1)军事领域实体存在大量的嵌套、组合、缩写等形式。并且由于军事文本没有固定的表达模式,军方也未对全部内容进行统一规范,难以构建全面合理的实体特征;2)现有的分词模型主要适用于通用领域,军事领域的分词准确率不高,也缺少专业军事术语的相关数据。即使加入军队语言词典也难以囊括所有军事实体;3)目前还没有公开权威的军事文本语料库,而自构建的语料库数据数量、分布及准确性也有待提高。文中以军事领域文本为研究主体,通过BERT(Bidirectional Encoder Representations from Transformers)模型进行词向量的构建,并结合BiLSTM(Bidirectional Long Short-Term Memory)与CRF(Conditional Random Fields)模型和注意力机制(Attention,ATT),构建BERT-BiLSTM-ATT-CRF 模型,完成军事命名实体识别的任务。
1 军事命名实体识别
命名实体识别(Name Entity Recognition,NER)的概念最早是在Message Understanding Conference-6上提出的,对NER 的相关研究工作至今已经进行了20 多年。由于汉语命名实体识别研究起步较晚且汉语固有的特殊性及其结构的复杂性,难度大于英语命名实体识别。目前,NER 的方法主要包括基于规则、基于机器学习[3]和基于神经网络[4-5]的方法。
NER 研究的初期主要是基于规则的方法,该方法由语言专家人工构建规则,并为每条规则分配权重,然后根据实体和规则的符合性来确定类型。然而这种方法依赖于大量手工设定的识别规则,很难对语料进行全面覆盖。因此,后续的研究重心逐渐转移到基于统计机器学习的方法上。目前常用的统计模型包括支持向量机[6]、隐马尔可夫[7]和CRF[8]等。单赫源[9]等提出了一种小粒度策略下基于条件随机场的军事命名实体识别方法。运用小粒度策略,结合手工构建的军事命名实体标注语料进行建模,采用CRF 模型识别出不可再分的小粒度,再通过对小粒度的组合得到完整的军事实体。
随着深度学习的发展,研究人员逐渐将深度学习方法应用到NER 的任务中,从而避免了繁琐的特征工程,基于深度学习的方法也逐渐成为了NER 任务的主流方法。高学攀[10]等提出一种基于BiLSTMCRF 的实体识别方法,使用词嵌入方法自动学习中文字符的分布式表示作为模型输入,旨在识别军事文本中的人名、军用地名、军事机构名、武器装备、设施目标、部队番号等军事命名实体。李丽双[11]等提出了一种基于CNN-BiLSTM-CRF 的作战文书命名实体识别方法,分析命名实体在不同分类标注情况下,对模型性能所产生的影响,取得了较好的准确率与召回率。此外,还有部分研究将LSTM 神经网络替换为Gate Recurrent Unit 网络[12],或者使用注意力机制[13-14],均在一定程度提升了模型识别的准确率。
为了增强深度学习在特征提取方面的能力,Devlin[15]等基于Transformer提出了BERT模型,它是一个预训练的语言表征模型,采用新的MLM(Masked Language Model),以生成深度的双向语言表征,该模型发表时在11 个自然语言处理领域获得SOTA(Satte-Of-The-Art)的结果。BERT 模型极大地缓解了传统深度学习依赖数据集的不足,对于小规模训练语料和序列标注任务有良好的适应性和处理能力。屈倩倩[16]等提出了一种基于BERT-BiLSTMCRF 的中医文本命名实体识别,通过BERT 模型进行词向量的构建,并结合BiLSTM 与CRF 模型完成生物医学命名实体识别的任务。
2 BERT-BiLSTM-ATT-CRF模型
近年来,将传统的命名实体识别问题转化为序列标注任务是汉语NER 深度学习模型的基本思想。BERT-BiLSTM-ATT-CRF 模型结构如图1 所示,模型整体由4 个模块组成,分别是BERT 预训练模型、BiLSTM 模块、注意力机制以及CRF 层。首先,通过BERT 层用基于上下文信息的词向量表示标注语料库,然后将词向量输入BiLSTM 层进一步进行训练,并通过注意力机制获得句子中的重要语义特征。最后,对输出结果进行CRF 解码,得到最优句子级别的标签序列,然后对序列中的每个实体进行提取分类,完成军事文本实体识别任务。

图1 BERT-BiLSTM-ATT-CRF 模型结构
2.1 BERT预训练模型
在自然语言处理领域中,采用词嵌入方法将词映射到低维空间中,有效地解决了文本特征稀疏的问题,使语义空间中的相似词的距离更近。传统的词向量生成方法,如one hot、word2vec、Elmo[17]等预训练的语言模型大多不依赖于词的上下文信息,难以准确表示词的多义性。而BERT 模型可以根据单词的上下文信息以无监督的方式表示单词,可以有效地解决一词多义的表示问题。
BERT 模型以双向Transformer 神经网络作为编码器,并利用大规模文本数据的自监督性质构建了两个预训练任务,分别是MLM 和NSP(Next Sentence Prediction)。MLM 是BERT 能够不受单向语言模型限制的原因。简单来说就是随机将句子中15%的词语进行遮盖,结合上下文的语句预测出遮盖处的原有词语,很好地解决了一词多义的问题。NSP 通过将成对的句子作为输入来预测两个句子是否连在一起,从而理解句子间的前后关系。
BERT 模型将文本中各个字的词向量作为模型的输入,一般利用word2vec 算法将文字转换为字向量作为初始值;模型输出则是输入各字对应的融合全文语义信息后的向量。
如图2 所示,BERT 模型同时将字向量、句子向量和位置向量进行加和作为模型输入。句子向量的取值在模型训练过程中自动生成,用于刻画句子的全局语义信息,并与单字的语义信息相融合;位置向量用于区分不同位置的字所携带语义信息的差异。

图2 BERT 词向量
2.2 BiLSTM模块
LSTM 是一种特殊的循环神经网络,其网络结构如图3 所示。

图3 LSTM网络结构
与循环神经网络不同的是,LSTM 通过遗忘门、输入门、输出门来遗忘句子中需要抛弃的信息并加入新信息,从而更好地提取文本中上下文之间的关系。LSTM 层的主要结构的计算公式如下表示:
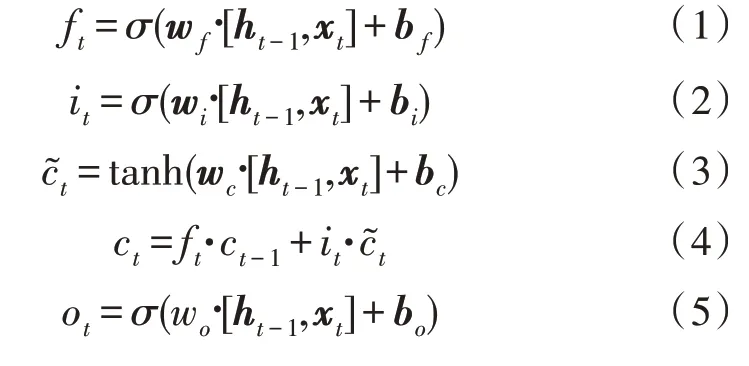

式中,σ是sigmoid 激活函数,xt为输入向量,ht为输出向量,ft、it、ct和ot分别代表遗忘门、输入门、记忆单元和输出门,w是参数矩阵,b是偏置向量。
但LSTM 模型忽略了当前信息的下文信息,为了充分地利用文本中的上文信息,提出了BiLSTM 模型。BiLSTM 模型由一个前向LSTM 和一个后向LSTM 模型组成。前向LSTM 处理正向的序列数据,后向LSTM 处理反向的序列数据。对于每个时刻,来自前向LSTM 的隐藏状态向量和来自后向LSTM 的隐藏状态向量被组合,以形成最终输出。
2.3 注意力机制
注意力机制借鉴人类的视觉注意力机制,通过快速扫描获得需要重点关注的目标区域。近年来,注意机制被广泛应用于图像识别、自然语言理解等领域,以打破传统编码器-解码器结构的局限性,从而从输入序列中提取尽可能多的特征信息。为了提取到句子中重要的特征信息,该模型将BiLSTM 与注意力机制结合,深入捕捉词汇中的语义信息。在NER 任务中,句子中每个汉字的语义对该任务的影响并不相同,该机制通过为每个字分配不同的权重,从而可以自动聚焦于在实体识别中起到决定性作用的文字。通过捕获输入序列中的重要语义信息,提高模型的整体效果。
2.4 CRF层
文本信息中的标注序列存在依赖关系。以BIO标注为例,一个合法的实体的标识可能会是“B-W,I-W,I-W”。如果标识过程不受控制,可能会出现“B-P,I-W”的非法标识,然而BiLSTM 层主要关注输入序列的上下文信息和句子特征,无法学习这些注释规则。
CRF 层在预测标签时将标签之间的依赖信息转化为约束,以保证预测的准确性。对于给定的输入x,输出预测结果y的得分计算表示如下:
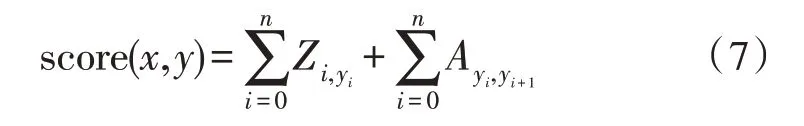
式中,Zi,yi表示字符i是标签yi的概率,Ayi,yi+1表示标签从yi转移到yi+1的概率。然后使用softmax计算归一化概率:

在最终解码阶段,使用Viterbi 算法获得所有序列中得分最高的标记序列,并将全局最优序列作为军事命名实体识别的最终结果,完成模型训练。
3 实验结果与分析
3.1 实验数据及评价标准
由于目前没有统一的军事数据集,故使用Scrapy框架从互联网爬取公开军事文本数据,来源包括环球军事网、新浪军事、中国军网等。获得文本语料后,军事领域相关人员通过人工对良莠不齐的数据进行筛选,去除不符合主题或相关性不大的语句,最终获得共计3 628 条语句。依托以上语料将实体类别分为五大类,分别为军事人物、军事地点、组织机构、武器装备、军事事件。
使用YEDDA 对实体进行人工标注。对于以上数据采用BIO 标注法,即“B-实体类别”表示实体的第一个字,“I-实体类别”表示实体的后续内容,“O”表示非实体。以上五类数据经过BIO 标注后共分为11 类:B-PER,I-PER,B-LOC,I-LOC,B-ORG,I-ORG,B-WPN,I-WPN,B-EVT,I-EVT,O。具体标注方案如表1 所示。

表1 军事实体标注方案
实验采用准确率(P)、召回率(R)和F1 值(Fscore)来对实验结果进行评价,其中F1 值能够体现整体测试效果。
3.2 实验结果
该实体识别模型实验基于Python3.6 环境以及Tensorflow1.15 版本下进行的。其中最大句子长度设置为128,batchsize 为128,学习率为0.001,epoch 为60,dropout 为0.2,BERT 模型为谷歌发布的Bert-Base-Chinese 版本,未对其参数进行修改。
为了验证实验的有效性,在实验中加入CRF,BiLSTM-CRF,CNN-BiLSTM-CRF 三种模型进行对比实验,三组模型使用word2vec 进行词向量构建。实验的最终结果如表2 所示。

表2 不同模型最终结果对比
实验结果表明,相较于CRF 模型,BiLSTM 结构可以更好地提取出文本中的特征信息,F1 值提高了11.54%;在BiLSTM 结构前加上CNN 模型使得模型的识别效果在三个维度上均略有提升。BERT-BiLSTMATT-CRF 通过BERT 预训练模型构建的词向量更有效地保证了军事实体的特征提取,相比于BiLSTMCRF 与CNN-BiLSTM-CRF 模型的F1 值分别提升了4.83%与4.23%。实验结果表明,BERT-BiLSTM-ATTCRF 模型在军事领域实体识别中准确度较高,可以运用到相关领域之中。基于BERT-BiLSTM-ATTCRF 模型对各类别实体识别效果如表3 所示。
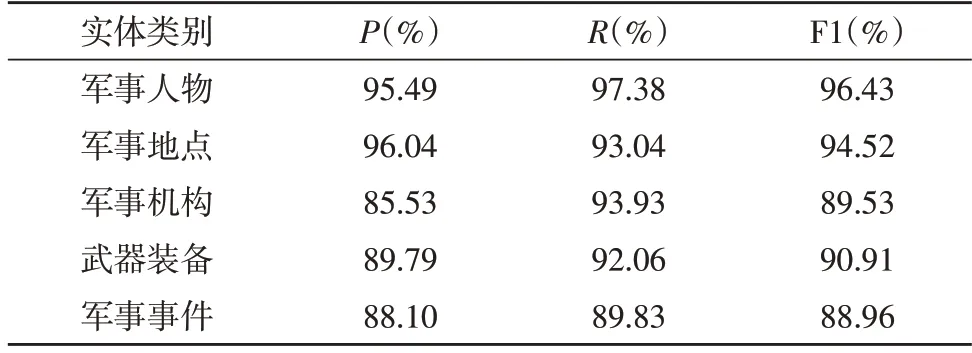
表3 各类别实体识别效果
4 结束语
针对传统方法不能充分表达军事文本语义特征信息的问题,文中提出了一种基于BE-RT-BiLSTMATT-CRF 模型的军事命名实体识别方法。该方法使用BERT 模型根据文本的特征表达构建出词向量,并通过BiLSTM-ATT-CRF 来提取文本中的特征信息生成全局最优序列,最终完成军事命名实体识别任务。实验结果表明,该模型在军事领域命名实体识别任务中能够取得较好的效果,准确率和召回率都高于基准方法。未来,将扩展军事命名实体语料库,整合更多文本数据资源,增加更多实体类型,进一步提高军事命名实体识别的效率。
