基于FPGA 的低功耗YOLO 加速器设计
2022-10-28李钦祚肖灯军
李钦祚,肖灯军
(1.中国科学院空天信息创新研究院,北京 100190;2.中国科学院大学电子电气与通信工程学院,北京 100049)
深度学习在目标检测、图像分类、语义分割等方 面发挥着重要作用。在目标检测领域YOLO 算法[1]与其他算法[2-3]相比平衡了精度和速度。然而基于GPU 及ASIC 实现的YOLO 算法分别存在功耗高和设计周期长的问题。而FPGA 由于其功耗低、体积小、可编程性强等优点通常被用来进行神经网络加速计算。目前的研究主要针对卷积计算、模型、数据位宽等方面进行优化。文献[4]和文献[5]分别采用Winograd 及FFT 算法优化卷积计算;文献[6-7]利用神经网络参数稀疏性进行FPGA 加速,文献[8]采用XNOR 门优化模型,但对模型的优化容易影响检测精度;文献[9-10]使用16 bit 定点数部署YOLO 网络,而文献[11]采用浮点数部署消耗了大量片上资源。该文基于FPGA 在Xilinx 的软硬件平台上实现了低功耗Tiny YOLOv3 加速器,对神经网络的加速计算做进一步探索。
1 Tiny YOLOv3网络及优化探索
1.1 Tiny YOLOv3网络简介
Tiny YOLOv3 网络由13 个卷积层组成。输入图像大小默认为416 pixel×416 pixel,通过卷积层进行特征提取,最大池化层进行数据降维和维持特征不变性,升采样层可以增加特征图的维数,为26 pixel×26 pixel 的输出特征图提供更多的特征信息。随着卷积层数的加深,卷积核的感受野随之增大。为了检测不同大小的目标,Tiny YOLOv3网络分别采用13 pixel×13 pixel 和26 pixel×26 pixel 的YOLO层进行大目标和小目标的检测。Tiny YOLOv3 网络可以提取的特征为W×H×(4+1+C)×B,其中W和H是输出特征图的宽度和高度,将输入图像分成W×H个网格单元,每个网格单元都有(4+1+C)×B个通道,分别包含坐标信息、目标置信度、不同类别置信度(C)以及边界框数量(B)。
1.2 优化卷积计算
1.2.1 行寄存器设计
如图1所示,在实现卷积计算的过程中,FPGA 不需要存储所有输入信息,只需要存储当前卷积窗所在行的所有数据即可。在一个通道维度上,设输入图像宽度为fw,高度为fh,卷积窗尺寸为kw×kh,此时行寄存器的尺寸为kh×fw。在Tiny YOLOv3 的结构中,行寄存器的尺寸可以设置为418×3。行寄存器是一个移位寄存器数组,当有新的输入数据进入行寄存器时,对应列中的旧数据向上移位,新的输入数据便会插入。行寄存器区只会保存最近的kh行数据。

图1 行缓存区示意图
1.2.2 通道交错设计

图2 卷积数据流操作顺序
1.3 引入FIFO优化
在多通道并行执行的过程中,写入操作发生的次数比读取操作更加频繁。由于网络的输出通道数量普遍大于输入通道,将在输出端口产生数据拥塞。故在卷积输出和AXI4 流端口之间引入First-in Firstout(FIFO)来优化流水线结构。设输入通道数量为8,输出通道数量为16,由于该设计中采用16位定点数和64 位DMA,所以当Initial Interval(II)等于1 时,需要两个时钟周期来获取八个通道的输入数据。当新的八个输入通道到来时,由上一次输入产生的16 个输出通道将被清除,为了避免这种情况,输入流必须暂停三个额外的周期来完成一次完整的输入输出操作,故共需五个周期。若加入FIFO 优化,产生的输出数据会逐步被发送,这样便可以在任务层级流水化传输加速器的输入和输出数据。图3 以三个任务为例,进行该设计采用的流水化结构与传统设计的时序对比。

图3 流水化与传统设计时序对比
图3 中,在任务级完成一次操作的时间(Ttask)包括从输入寄存器读取数据时间(Tin),在Processing Elements(PE)中进行计算的时间(Tout)以及从PE 中读取计算结果的时间(Tcmp),故传统设计结构完成三次任务需要的总时间(Tsum)如式(1)所示:

流水化之后完成三次任务的总时间(Tpip_sum)如式(5)所示:

显然,Tpip_sum<Tsum。
1.4 卷积层设计的伪代码
在卷积IP 运行过程中,首先加载输入权重数据;其次进行输入图像数据加载,数据进入行缓存区等待卷积计算;然后卷积计算按照滑窗的形式进行,随着滑动窗口的移动进行乘累加运算,计算完毕之后,进行输出通道的整合。在算法的设计中,引入输入输出通道折叠因子,以此适应不同层的通道参数,卷积IP 设计的伪代码如算法1:
算法1 卷积层优化伪代码


1.5 卷积优化算法的性能指标
该节对卷积层优化算法的资源占用和延迟进行估计。首先,由算法1 可以看出在设计中引入了流水线优化。其initial interval(II)主要受三方面因素的影响:卷积操作的折叠因子(factor)、输入输出比(ratio)以及包括行缓存等其他操作(other)。II的数学表达式如式(6)所示:

式(7)为factor的计算公式,其中,P代表内存分区,输出通道为N。由于HLS 工具会将行寄存器区综合为2-portBRAM形式,在计算卷积的过程中会使能2×P个并行卷积核,但是64 bit 的DMA 一次只能够处理四个输入通道,所以需要4×N个卷积滤波器的通道,由此计算出factor:
As the PRN code-phase observables ofand,the mean and standard deviation of the carrier-phase observablesandgenerated by the PLL can be expressed as:

在上述II计算的基础上,采用式(8)计算,可对卷积IP 的资源占用进行估计:

其中,M(x)为总的资源占用量。首先,进行BRAM占用量的估计。以第一层卷积的分析为例,卷积窗的大小被设置为3,故行寄存器区一共有12 行,每一个BRAM能够存储1 000 个16 bit 的定点数,故针对输入图像数据的BRAM占用如式(9)所示。针对权重数据的存储,如式(10)所示;因此总的BRAM占用如式(11)所示:

其次,进行DSP资源占用的分析。3×3 卷积需要9个DSP,所以在算法1 所示的卷积操作中,DSP的占用可以由式(12)得出:

数据处理的延迟由权重数据处理延迟和输入图像数据处理延迟两部分组成。在权重数据处理阶段,需要3 个周期来加载3×3 的权重数据;在输入图像数据处理阶段,延迟与输入图像尺寸有关,通常需要补零操作。此外,在算法的设计中,需要额外的一行延迟来使输出的读写达到流水线的效果,故关于延迟的计算如式(13)-(15)所示:

2 加速器的实现方案
2.1 加速器的整体架构设计
基于FPGA 的低功耗YOLO 加速器的整体架构设计如图4 所示。系统的软件部分可分为PL(Programmable Logic)和PS(Processing System)两部分。在PL 端,输入特征图和权重存储在片外DDR 中,通过FPGA 的AXI4 接口传入片上缓存,然后片上缓存的数据会传入FPGA 的并行处理单元进行计算,最后处理单元的计算结果会同样通过AXI4 接口传回片外DDR;在PS 端,集成的ARM CPU 将输入输出特征图输入到DDR 中,并且PS 端通过AXI4-Lite 总线下达DMA 与DDR 之间的数据传输命令,由DMA 控制器承担着YOLO 加速器与片外DDR 间的数据搬运工作[12-13]。CPU 通过AXI 总线读取加速器的运算结果,并在PS 端进行图像预处理和显示。综合PL 和PS 两部分便形成了YOLO 加速器的整体架构。
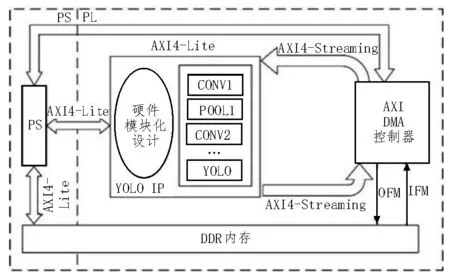
图4 低功耗YOLO加速器整体架构
2.2 卷积层的流设计
在图2(b)中给出了通道交错的整体数据流顺序,为了进一步说明,图5 中给出了卷积层流设计的具体结构。在图5 所示的结构中,输入寄存器包含四行数据,额外的一行用于缓存上次计算产生的数据,其他的三行数据传入PE 中进行计算,滑动立方体按通道维度滑动,更新的数据进入PE 进行计算,Ti个3×3 的数据与3×3 的卷积核进行计算,通过加法器计算出卷积结果,卷积的输出结果进入经过简化的批归一化层进行量化和激活,最后将量化的结果传入下一层进行计算。
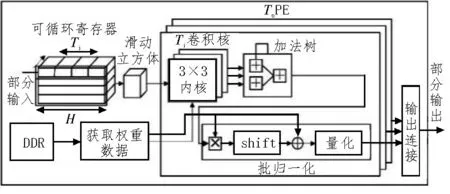
图5 卷积层流设计具体结构
此外,为了有效地获取权重数据来适应通道折叠的计算,将权重数据按照图6 的方式进行预处理。权重块的维度按照输出通道、输入通道、卷积内核分布,需要To数量的卷积块在To数量的PE 中进行计算,其中每一个卷积块又适用了Ti个输入通道。因此,权重块将按照卷积处理的方式进行连续存储,进而进行后续的卷积加速运算。

图6 权重数据预处理
2.3 CNN层分组设计
为了减轻FPGA 片上资源的压力,将权重数据以及图像数据存储在DDR 中,但各层频繁读取DDR会导致数据传输的延迟。如图7 所示,依据Tiny YOLOv3 网络结构中卷积层后面不同层的类型对所有的层进行分组。具体的分组操作,在Vivado SDK(Software Design Kit)软件中通过编程实现,将所有的层分成四组,通过开关选择对应的组。通过层分组操作,可以降低频繁读取DDR 导致的数据延迟。

图7 CNN层分组示意图
2.4 通道折叠设计
通道折叠设计适用于资源有限的情况,在IP 设计过程中,最大通道数的设定通常会小于输入输出通道数,将原始层分成子层将会更好地适应IP 设计,即进行通道折叠。如图8 所示,为了避免后续再次进行通道交错,所有的层都将分成子层进行通道折叠。

图8 通道折叠示意图
2.5 系统软件设计
软件设计主要包含对ZYNQ 系统进行初始化(对封装好的IP 进行初始化)和IP 核参数的设置,通过开关设定层的连接关系,导入输入数据以及导出输出数据。系统软件设计伪代码如算法2 所示:
算法2 软件设计伪代码


3 实验及比较
3.1 实验建立
该设计主要采用Vivado HLS 2019.1 进行低功耗的YOLO 加速器的IP 设计,高层次综合可以将C/C++语言转化成FPGA 需要的RTL 语言。加速器硬件模块化设计在Vivado 2019.1 中进行,最后,通过Xilinx SDK 软件完成YOLO 加速器的软硬件协同设计。基于FPGA 的低功耗YOLO 加速器设计部署在Xilinx Zedboard FPGA 平台上,该平台的主芯片是Zynq XC7Z020-CLG484-1,包 含512 MB 的DDR 和220个DSP。
3.2 实验比较及数据分析
如表1 所示,在完成相同设计功能的情况下,该设计与Intel CPU 相比加速了17 倍,与ARM CPU 相比加速了289 倍,具有良好的加速效果。
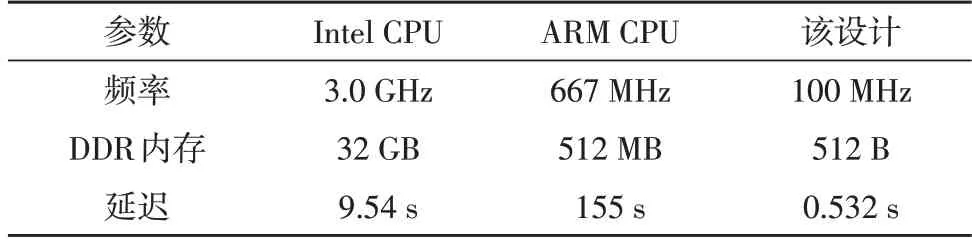
表1 该设计与CPU运行分析比较
该文的计算性能和功耗比实验结果如表2 所示,实验表明,该文设计的功耗为3.4 W,总体的性能功耗比为10.45 GOPS/W。与此同时表2 也展示了与前人研究成果的比较。文献[1]的功耗为170 W,性能功耗比为8.89 GOPS/W,该文的性能功耗比相对于原始GPU 设计提升了1.17 倍。该设计的功耗低于其他文献方法。此外,文献[15]的BRAMs、DSPs 和LUT-FF 的资源消耗分别为1 026、168、60k~86k,文献[5]的BRAMs、DSPs和LUT-FF 的资源消耗分别为1 706、377、135k~370k,而该设计的BRAMs、DSPs 和LUT-FF 的资源消耗分别为185、160、26k~46k,显著降低了硬件资源的消耗。
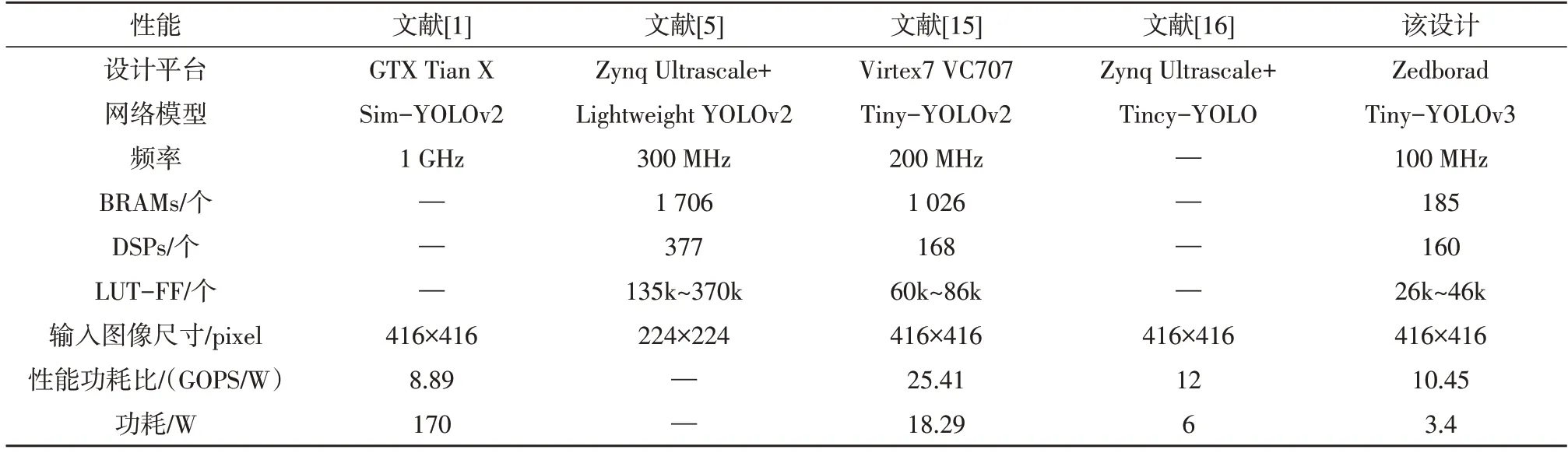
表2 研究性能比较
4 结论
该文提出了一种基于FPGA 的低功耗YOLO 加速器设计。通过软硬件协同优化完成YOLO 加速器部署:运用通道交错方法优化卷积计算;使用层分组方法减少数据传输的延迟;利用通道折叠方式降低硬件资源消耗。在Xilinx 平台上的验证结果表明,该设计在较低功耗和硬件资源消耗的情况下,具有良好的性能。因此,该文对有限资源情况下YOLO加速器边缘部署的实现具有重要意义。
