一种基于自动标注语料的热点事件情感分析方法及应用
2022-10-27易寒冰刘倩
易寒冰,刘倩
公安部第一研究所,北京 100048
引言
文本情感分析作为自然语言处理的任务之一,由Nasukawa[1]等人于2003 年首次提出。近年来,随着自媒体的快速兴起,相应地对社交平台上热点事件的情感倾向分析也成了热点研究问题,对网友就热点事件发表的言论进行情感分析,是了解公众情绪和意见的重要工具[2],也是快速获取事件走势、转折点等重要信息的关键技术。
目前,基于社交媒体的情感分析在医疗、金融、社会学、政务等多方面都有很多研究,例如,对世界各地发生的伊斯兰国恐怖主义袭击事件相关文本的情感检测,能帮助发现恐怖分子社交账户、提供有效信息[3]。还有研究将社交媒体情感分析结果作为传统离线民意调查的补充数据,用来监测选举活动,并对选举结果进行预测[4]等。不可否认对社交媒体的言论进行情感分析能够获取大量潜在情报,而快速准确地获取信息可大幅提升对舆情等事件的应对和预防能力。
社交媒体短文本情感分析技术目前主要分为三类:基于情感词典的方法、基于传统机器学习的方法,以及基于深度学习的方法[1]。
情感词典最早由Whissell[5]等于1998 年提出。基于情感词典的方法主要是根据情感知识构建词典,情感分析的结果很大程度依赖情感词典的质量,虽然也有很多研究致力于如何丰富情感词典,但此方法还缺少对文本上下文语义的考虑。
随着机器学习的发展,在短文本情感分析领域,传统机器学习的方法也取得了突破。孙熙伟[6]提出使用朴素贝叶斯技术以及字典法针对论坛文本进行情感倾向性分析,并取得不错效果。基于传统机器学习的方法核心是特征工程,依赖人工设计,受人为因素影响,同样的特征对于不同的领域可能差别巨大,且此方法多使用经典的有监督分类模型,性能依赖于标注数据的质量,而获取高质量的标注数据需要消耗大量人工成本。
近年来,深度学习方法受大脑神经系统的启发,对自然语言处理、语音识别和计算机视觉等一系列应用产生了巨大的影响,也成功用于情感分析的研究[2]。技术也从基础的RNN、LSTM 等模型发展到基于Transformer 的预训练模型,例如BERT[7]、ERNIE[8]等预训练模型。相比LSTM 模型,预训练模型不仅引入了注意力机制,还解决了缺少大规模标注语料的难题。Azeemi[9]等人在文献中使用基于Transformer 语言模型的RoBERTa 对推特上新冠病毒话题下的言论进行了七类情感分类预测,并对预测结果进行了国别分析,且提取有关这一流行病中人们心理状况的有用指标。Kim 和Ganesan[10]在文献中将RoBERTa 应用于推特上公众对太阳能的情感分析预测,分析了美国各州不同的可再生组合能源组合标准等特征对公众情绪的影响,有助于政府了解公众对太阳能支持的地区差异以及未来部署太阳能的时机。
上述研究均是使用预训练模型对社交媒体上公众情绪的分析及其应用,虽然效果不错,但文献中的方法都存在相同的问题:第一对于数据预处理仅使用关键词和简单规则去除了URL、不相关的以及转发的噪音数据,没有考虑数据的口语化、语种等问题;第二对于带标签训练数据集的获取均采用人工标注,此方法成本大、耗时长。
本文旨在研究对实战中数据的预处理方法以及减少成本获取高质量标注数据来提高模型效果。主要工作如下:
(1)针对爬取得到的以非正式语言、非结构化语法和特殊符号编写的文本,研究了正则、语种识别以及分词相结合的方式对文本进行预处理。
(2)利用改进的PMI 算法得到每个事件的情感词典以及自动标注的训练语料,通过不断迭代提高标注语料的质量。
(3)利用SKEP 模型对文本情感先验知识的嵌入表示能力实现文本面向情感的语义表示以及将情感分析结果应用到舆情分析中。
1 基础预训练模型
1.1 注意力机制
本文是在SKEP 预训练模型的基础上进行的情感分析,SKEP 模型中应用了Transformer 的Encoder层,而Transformer 的核心是注意力机制,注意力机制(Attention)最早被使用于图像处理,2014 年Seq2Seq 模型[11]被提出应用于机器学习领域,后在此模型基础上引入Attention 机制取得巨大成功。随后各种基于注意力机制的模型开始应用到情感分析等其他自然语言处理任务中。
通俗理解,就像人在看图片、视频或者本文时,都会一眼关注到比较显眼的,而不是把注意力分散到每一个元素上,这就是注意力机制的思想。对文本不同特征会有不同的注意力即权重,不重要的特征允许忽略,而不是每个特征都赋予平均权重。因此注意力机制的关键在于如何计算不同特征的权重。Transformer 中的Attention 为多头自注意力机制,采用的是Key-Value 的设置,且K=V。对于一个输入的文本向量,其中每个词的Attention 向量是通过计算该文本中其他词向量的加权和所得,而权重则通过该词向量与其他词向量点乘再使用softmax 归一化所得,计算公式如下:

1.2 Transformer 模型
Ashish Vaswani[12]等人2017 年在文献中提出了Transformer 模型,使用全Attention 代替了CNN 和RNN 等网络结构,且可高度并行。
Transformer 模型采用编码器-解码器的结构,包含6 个编码器,6 个解码器。编码器包含多头自注意层和全连接层两个子层,解码器包含一个多头注意层、一个能够执行编码器输出的多头自注意的附加层,以及一个全连接层三个子层。结构如图1 所示。
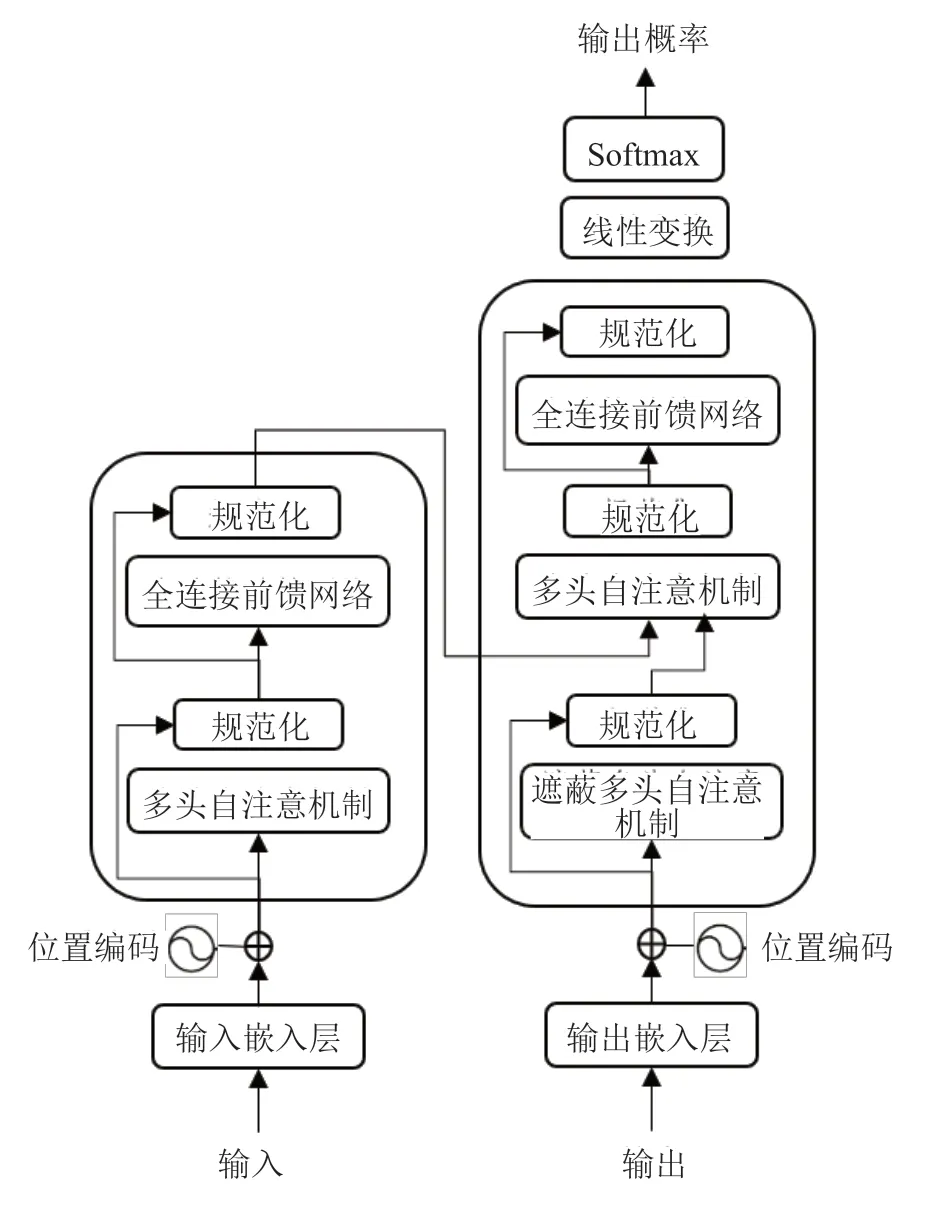
图1 Transformer 结构图Fig.1 The transformer-model architecture
因为Transformer 模型中不包括RNN 或CNN,为了保留序列信息,在输入时,对每个token 生成一个维的位置向量,将此位置向量与输入向量相加得到最终的输入。位置向量的计算公式[12]如下,其中pos表示位置索引,i表示维度索引。
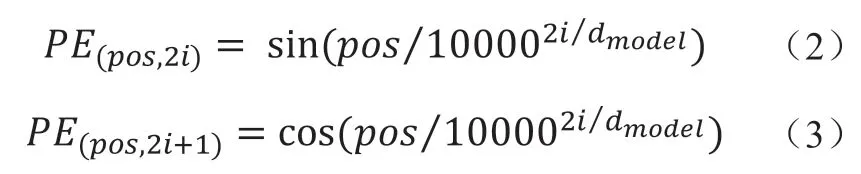
模型中的多头注意力机制使用多个自注意力,对输入的Q、K、V 进行多次不同的映射,再使用concat 连接得到最后向量。公式如下,其中Attention为1.1 节中介绍的。

1.3 SKEP 预训练模型
SKEP 是百度研究团队和中国科学院在2020 年提出的一个基于情感知识增强的情感预训练模型。
SKEP 预训练目的是预测情感词及词性、情感词对,情感倾向分析任务在预训练模型的基础上完成。预训练第一步基于挖掘的情感先验知识,将输入的原始文本中的情感先验知识屏蔽替换成[MASK],屏蔽的词为句子总词数的10%。第二步使用Transformer 的编码器对屏蔽后的输入序列预测屏蔽部分的词以及情感极性。
情感先验知识挖掘使用基于简单的点互信息[13]方法,通过计算词和种子词的相关概率来判断,即认为和正向词相关性越大则正向概率越大,这个方法只需要少量的种子词典。对于预测的情感词,把其附近不超过距离为3 的词作为对应的情感词对候选词。预训练过程如图2 所示。

图2 SKEP 预训练过程[14]Fig.2 SKEP pretraining process
2 情感分析方法
2.1 数据预处理
本文使用的数据源为根据事件名称或者用户账号从境外社交媒体平台上爬取的文本,此类文本不像新闻内容表达正规,而是口语化严重,充斥着表情、图片和URL 元素的零碎信息,还混合中、英、俄、日、韩等多语种,其中中文文本中还有粤语、繁体等情况,而训练数据的质量也是影响模型性能的因素,因此对数据进行预处理变得非常关键。本文预处理方法结合了正则清洗数据、语种识别、繁转简以及分词技术。
数据清洗即使用正则表达式清洗文本中的URL、除表情符号以外的符号等零碎信息。
由于本文研究主要针对中文,而数据来源于推特等海外社交媒体平台,用户使用语言多样化,因此本文对文本进行了语种识别,筛选出中文文本。针对中文文本中存在的大量中国香港繁体字以及中国台湾繁体字,本文做了进一步研究处理,通过收集粤语专用字词典、港台繁体字词典,借助词典结合HanLP 将非简体中文文本分类转化成简体中文并进行分词。
HanLP 对于日期、带数值的量词、地理词的分词效果表现并不好,而这些词可能是重要的情感词,如果分词不当可能导致数据标注效果降低,因此本文根据中文用语习惯,在HanLP 分词方法的基础上增加了如下三条规则:
(1)ns+n*:地理名词后面如果还是名词即合并。
(2)m+q:数词后面如果是数词或者量词则合并。
(3)v+v/f:动词后面如果还是动词或者方向词则合并。
2.2 PMI+SKEP 模型训练
(1)利用PMI 进行情感词典构建
中文情感分析主流的情感词典有BasonNLP、HowNet、台湾大学NTUSD 褒贬义情感词典、清华大学李军中文褒义贬义词典。BasonNLP 情感词典是利用从微博、新闻、论坛等平台上获取的上百万篇情感标注数据自动构建的情感词典[15]。虽然与舆论相关,但过于普遍,没有侧重点。HowNet 包括否定词词典、副词词典、自定义总结词以及转折词词典等基础词典,其他两个都为通用的褒义词和贬义词,在社交媒体很多没有明显褒贬词的文本中效果甚微。
社交媒体对于不同事件的发言,表示支持和反对的词各有不同,对情感词的偏重也不同,因此需要专门的情感词典及情感词得分计算方法。本文研究了基于从热点事件中抽取的少量标注数据迭代生成情感词典的方法。
对于预处理好的文本,利用点互信息计算每个词的情感得分,主要思想是一个词在正向文本中出现的比在负向文本中出现的频繁则认为更积极,反之认为更消极。计算公式如公式(6)所示:
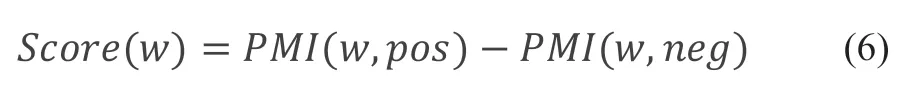
其中w表示需要求得分的情感词,pos表示正向文本,neg表示负向文本,表示点互信息,由于原始的点互信息需要借助种子词典,而不同的事件,需要的种子词可能差别比较大,受人为因素影响。本文使用的点互信息方法,借助句子原本情感属性,分别计算词在正负向文本中出现的概率。计算公式如公式(7)[16]所示:

在本文所用的数据生成的词典基础上,增加了一个HowNet 的否定词词典,以及既有中文又有英文的程度副词词典,每个程度副词都有对应的程度得分。
(2)基于词典自动标注数据
对于实际业务需求中的文本数据,无法提供足够的标注数据训练模型,如果采用人工标注数据,则会产生非常高成本,因此如何生成足够的标注语料变得非常重要。
文本所表达的情感是文本中所有词贡献的情感总和,即利用生成的情感词典融合文本的所有情感词得分,进而计算整个文本的得分。融合计算方式如公式(8)所示:
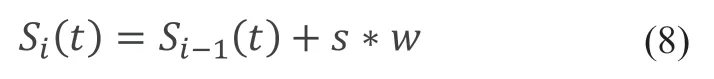

本文从所有文本中随机抽取出1,000 条,快速标注,根据这个标注的文本生成第一次词典,再利用生成的词典对5,000 条文本计算情感得分,筛选出得分值高于阈值的文本与第一批合并,再生成词典,如此迭代三次。
(3)训练模型
SKEP 预训练模型采用的是无监督方法自动挖掘情感知识,然后利用情感知识构建预训练目标,进而让机器学会理解情感语义,它为各类情感分析任务提供统一且强大的情感语义表示。使用SKEP预训练模型实现情感分类即在Transformer 编码器的上层增加了一个分类输出层,以基于整体表示计算情感概率。本文基于SKEP 预训练模型[14]对分类层网络进行微调训练实现短文本情感分类。方法处理流程如图3 所示。
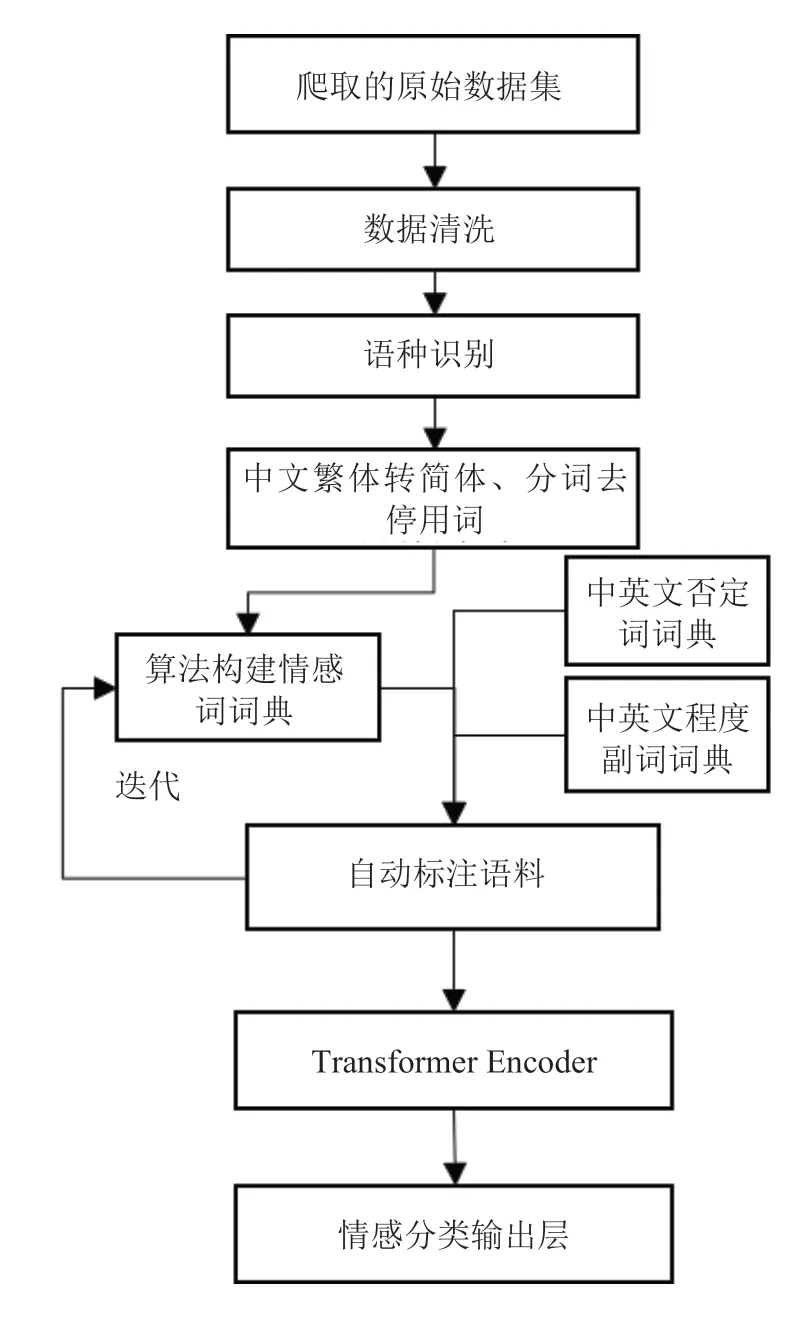
图3 情感分析过程Fig.3 The process of sentiment analysis
3 实验及结果分析
3.1 实验环境
本文微调实验是在paddle 框架下完成,所以需要在python 环境中提前安装好paddlepaddle 以及paddlenlp 的包。实验每台服务器配置如表1,开发环境如表2。

表1 服务器环境Table 1 Server environment
表2 开发环境Table 2 Development environment
3.2 实验过程及结果分析
(1)数据准备
本文进行情感分析的实验数据均为公开社交平台上某些事件下的言论。经过清洗及迭代词典构建并自动标注数据,得到包含了36,556 个词的情感词典以及10,509 条标注数据,实验使用其中的30%作为测试数据,70%作为训练数据。词典结构如图4所示。标注后的数据1 表示正向,0 表示中性,-1 表示负向。

图4 情感词典Fig.4 Sentiment lexicon
(2)实验参数
深度学习模型的实验参数设置非常关键,对实验结果有很大影响,本文结合实验服务器最大性能,以及实验数据情况确定实验参数。
针对中文数据,采用的是预训练好的“skep_ernie_1.0_large_ch”模型进行微调实验。训练时可选择调整实验参数,本文设置的参数有:输入序列长度最大为128,批大小为16,学习率3e-5,迭代次数为5。
(3)对比实验
为了验证方法的有效性,针对预处理,本文做了与不进行翻译成简体中文而直接进行情感分析的实验对比;针对模型,首先验证自动标注方法的有效性,然后与前期提出没有考虑情感先验知识的ERNIE 预训练模型进行了对比。
(4)实验及结果分析
本文实验先利用chnesenticorp 数据集对自动标注算法进行验证。将训练数据分成三份,使用自动标注算法对数据进行迭代处理,得到情感词典,在测试数据上进行实验验证,算法正确率达到89.38%,此结果证明该标注能利用少量标签数据快速得到大量可用的标注语料。
使用生成的标注语料作为模型的训练数据,训练了一个针对相关事件的情感分析模型。实验结果根据正向文本的准确率进行评测。
在给出的数据集上,使用本文的方法训练模型正确率达到92.87%,比ERNIE 模型正确率高了3.17%,比没有进行翻译处理的方法高了2.32%。这说明在预训练模型基础上,对于社交媒体上热点事件的短文本情感分析,完善的数据预处理方式以及情感先验知识能够很好地改善模型效果。
4 情感分析在舆情分析中的应用研究
情感倾向的分析都是服务于应用,通过调研现有的业务系统以及需求,发现无论情报获取还是舆情分析系统,对于事件的脉络陈述中都缺少对重点节点情感分析的使用,而事件传播过程中的核心用户以及事件走向的及时反馈能很大程度提高应对突发事件的能力。针对问题,本文对情感倾向分析结果进行了四个方面的应用,对文本根据事件进行分类,针对不同的事件进行相应的情感分析,再对情感分析进行应用:
(1)根据具体事件统计总体情况,直观地了解广大网民对事件的总体倾向。
(2)展示事件关键节点言论的情感倾向,可以快速定位负向消息传播关键节点及言论内容。
(3)统计近期网民对事件情感倾向的变化情况,方便掌握和及时引导事件变化趋势。
(4)根据用户所有言论的情感倾向,预测负向言论传播的核心用户。
应用以“中国新冠疫苗”为例,从推特上爬取了7,308 条原创中文文本,利用本文提出的方法对此数据进行了情感分析预测及结果的应用,包括:对采集数据情感预测结果统计,分析用户参与情况、正负向及中性言论占比情况(如图5 左上角所示);对事件脉络中关键节点言论的情感分析展示;对近几个月网民情感变化的统计分析(如图5 右侧所示)。通过这样多方位的分析应用,用户可以预测网民对热点话题的情感变化趋势以及造成变化可能的原因等情报,有助于用户掌握舆论动态,并提早做出应急方案。
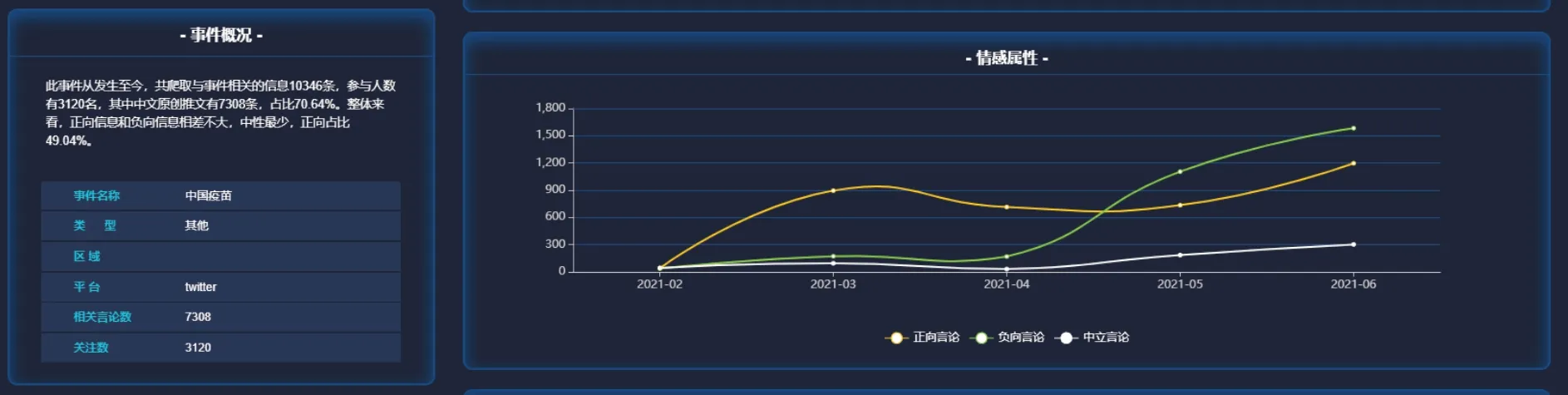
图5 网民对“中国疫苗”情感倾向变化Fig.5 Tendency of netizens’ sentiment towards “China vaccine”
5 结束语
全面客观地掌握某些事件中参与用户的情感倾向,可以快速地得到重要信息,从而采取相应措施。本文研究选取了国安法、反送中等热议的78 个政治相关话题,对参与讨论的用户言论进行了情感分析,形成了一个丰富的带有情感得分的情感词典集,并通过实验和应用获取了事件在境外社交平台的情感倾向变化趋势,并得到一批有潜在风险的用户。但通过实践,也发现对于一些反讽的文本,效果不佳,且目前对言论的情感缺少更细粒度的分析,下一步会持续深入地研究获取用户发表的情感主题,自动给言论进行更细粒度的情感分类。
利益冲突声明
所有作者声明不存在利益冲突关系。
