Gadget-2在一个加速卡异构平台上的移植与优化
2022-10-27赵文龙王武
赵文龙,王武
1.中国科学院计算机网络信息中心,北京 100083
2.中国科学院大学,北京 100049
引言
N 体问题描述了多个粒子在经典力学下的运动规律,是广泛运用于天体物理学和分子动力学等多个重要领域中的基本问题之一。为了能够更加精准地预测宇宙中物质的分布以及预想模型的正确性,往往需要进行大规模的模拟,这对于传统计算机集群来说有极大的压力。而随着硬件与算法的快速发展,用来求解N 体问题的软件也在不断地更新迭代,如GreeM[1]、CUBE[2]和PHoToNs[3]。
目前模拟N 体问题的主要数值方法有粒子-粒子法(Particle-Particle,P2P),粒子-网格法[4](Particle-Mesh Method,PM),Barnes-Hut 树算法[5](Barnes-Hut Tree Method,BH-Tree)以及快速多极子算法[6](Fast Multipole Method,FMM)。P2P 方法的时间复杂度为,计算效率较低,但是精度最高;PM 方法将空间网格离散,通过快速傅里叶变换(Fast Fourier Transform,FFT)求解泊松方程得到作用力,但近距离时误差较大;而树方法,包括BH-Tree 算法与FMM 算法,可以控制计算精度。为了兼顾精度与效率,P3M[7]、TreePM[8]与FMM-PM[9]这样的混合算法成为了主流。
得益于目前高性能计算的快速发展,尤其以CPU+GPU 为主流的并行异构平台的强大的计算能力,N 体问题成为了加速卡异构平台的热点应用之一。
国际上已有不少针对GPU 这种SIMT(Single Instruction Multiple Thread)并行机制的加速卡的N体模拟异构算法与实现。Nyland[10]针对P2P 算法的优化提出了“i-parallel”方法以及“walk”的概念,在GPU 上加速了50 倍。而Yokota[11]在Nyland的基础上,实现了对107个粒子的150 倍加速。由Hamada 提出的“Chamomile Scheme”算法被完全移植到了GPU 上,最终模拟131,072 个粒子性能达到了256GFlops[12],之后通过对树算法进行一系列优化,用576 个GPU 模拟32 亿个粒子,性能达到了190.5TFlops[13-15]。2011 年,波士顿大学针对FMM算法在天文问题上的应用进行GPU 加速[16],相较于CPU 端加速了70 倍。2017 年,Potter 将其开发的PKDGRAV3[17]中的FMM 算法成功移植到GPU 上,并用4,000 个GPU 节点实现了2 万亿粒子的天文模拟。在国内,针对国家天文台研发的PHoToNs-2 有相关的多GPU 的移植与优化[18-19]。上海交通大学以及厦门大学对CUBE 的PP 部分进行GPU 移植,单步运行速度提升了5.16 倍,并在64 个GPU 上有着83.8%的弱扩展效率。
Gadget-2[20]是天体物理领域最有影响力的并行模拟软件之一,它由Springel 开发,采用TreePM 算法,是国际上第一个可计算粒子规模达到百亿量级的开源宇宙模拟软件,在天文领域获得广泛认可,相关论文被引用超过6,500 次。针对不同的计算平台,Gadget 系列已经衍生出了众多分支版本来适应不同的并行架构和编程模式,如OpenAcc-Gadget3[21]、MP-Gadget[22]、AX-Gadget[23]。在2021 年推出的Gadget-4[24]采用了FMM-PM 算法。
本文针对国产高性能异构加速卡平台,基于HIP 完成了Gadget-2 的移植,并对其在核函数的访存效率进行了优化,最终整体性能加速13.27 倍,短程力计算加速35.67 倍,并行效率达到57.29%。第1 节主要介绍TreePM 以及相关算法的基本原理;第2 节介绍加速卡平台的计算环境,以及最耗时的短程力计算在加速卡上的实现方法;第3 节介绍短程力计算在加速卡上的性能优化方法;第4 节验证移植优化版本的结果正确性,并给出性能测试结果。
1 TreePM 算法原理
1.1 BH-Tree 算法
BH-Tree 算法是由Barnes 和Hut 提出的,其主要思想是将模拟空间看作是一个立方体,每一个维度递归地划分子空间,将空间中的粒子划分到不同的子节点,直到每个子空间只包含了一个粒子,以此构造一个八叉树,并将模拟的整个空间看作是根节点。
构造树之后,从叶子节点的父节点开始,由下往上依次计算每个节点的质点与质量,直到根节点。若节点只包含一个粒子,则该节点的质量与质心由该粒子的质量与位置决定,否则由子节点决定。在计算作用力的时候,自根节点向下遍历,粒子之间的相互作用转换为包含多个粒子的树节点与粒子之间的相互作用,这使得计算复杂度降低为,是否能够将包含多个粒子的节点看作一个整体来对目标粒子进行作用,是通过以下准则来判定:

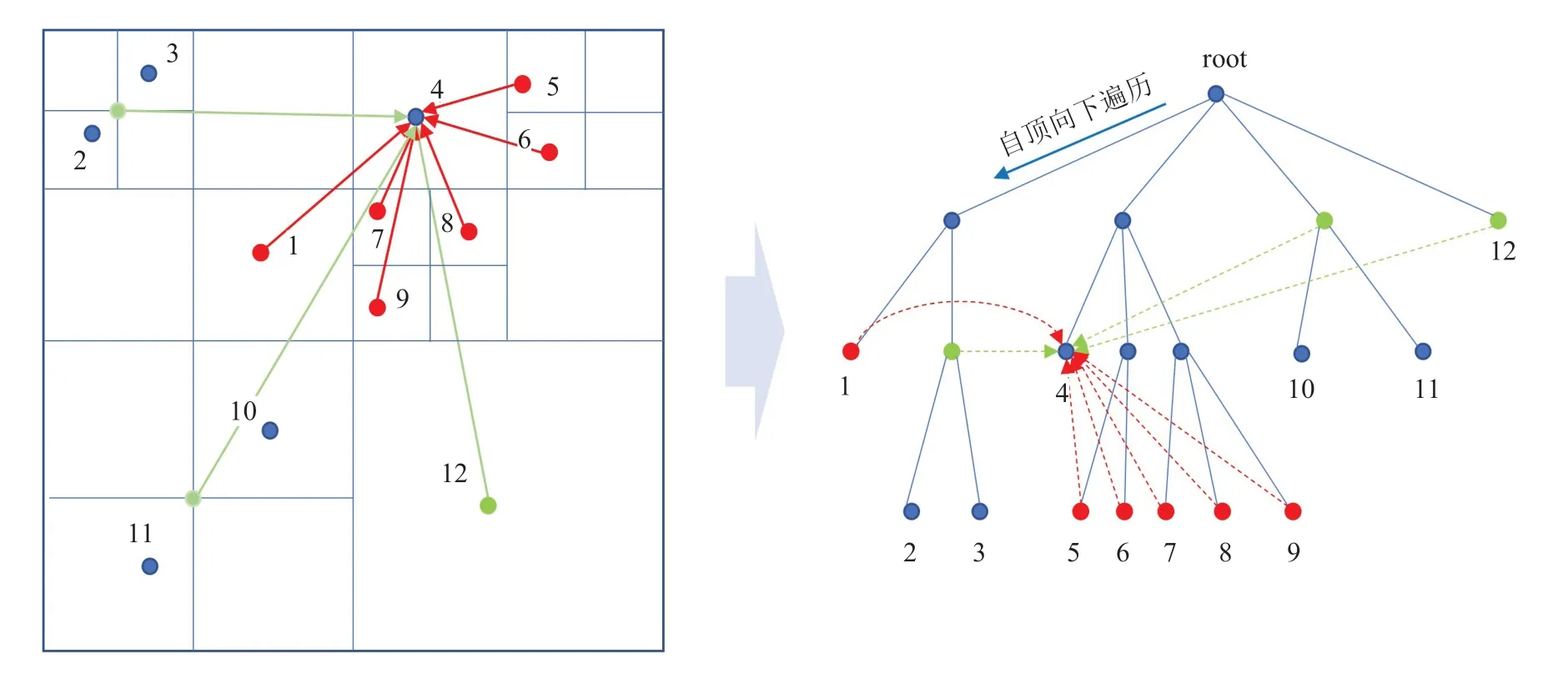
图1 BH-Tree 算法中八叉树的划分及粒子受力Fig.1 Partitioning of octrees and the forces acting on the particles in the BH-Tree algorithm
1.2 粒子-网格算法
粒子网格算法是将空间离散网格化,先计算引力势然后再通过引力势计算其所受作用力。粒子的引力势满足泊松方程[25]:
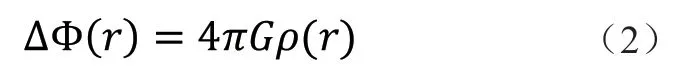
1.3 TreePM 算法
TreePM[26]算法由Xu 等人提出,其主要思想是由于PM 的运算效率比树方法快得多,但同时在小尺度范围内计算精度较低,而树方法可灵活控制精度但计算大尺度范围相互作用的效率较低,模拟大规模N 体问题依然存在性能瓶颈,因此综合权衡两个算法的优点和不足之处,TreePM 算法将引力势在谱空间中划分为两部分:长程力与短程力,树方法计算短程力,PM 方法计算长程力[27]:

实现时并不直接计算公式中的超越函数,而是通过样点查表和插值多项式快速计算
TreePM 方法与P3M 方法相比误差近似甚至更小,并且在树方法中只需要遍历目标粒子周围的一个小空间,兼顾了数值计算效率,使得该算法在多个领域中获得了广泛的应用,带来了巨大的性能提升。
但即便如此,TreePM 的性能瓶颈随着模拟尺度与粒子规模的增大依然明显。经过测试,PM 部分通过FFT 计算,计算时间在整个算法的运行过程中占用比例极小,而树方法中计算短程作用力的部分是计算密集型的任务,密度分布较集中时短程力计算时间平均占比90%左右,因此通过高性能异构平台对其进行硬件加速,利用多线程计算来提高这部分的计算速度,能够有效地提升整个算法的求解效率。
2 TreePM 在加速卡上的实现
2.1 ROCm 计算平台与HIP 编程模型
“中科先导1 号”是基于国产处理器和加速卡的高性能异构平台,其基本架构如图2 所示,其中每个节点有一个32 核的CPU 处理器以及4 张类GPU 加速卡,分别为Host 端与Device 端。Host 端的内存为128GB,每张加速卡有64 个流多处理器和16GB 显存,访存带宽1TB/s,与CPU 之间使用32 个PCIE 3.0 互联。加速卡与CPU 之间的访存带宽是16GB/s,节点间的网络带宽是25GB/s。CPU 支持x86 指令集以及常用的并行编程模型如OpenMP、MPI 等,加速卡支持ROCm 计算环境和HIP 编程模型。
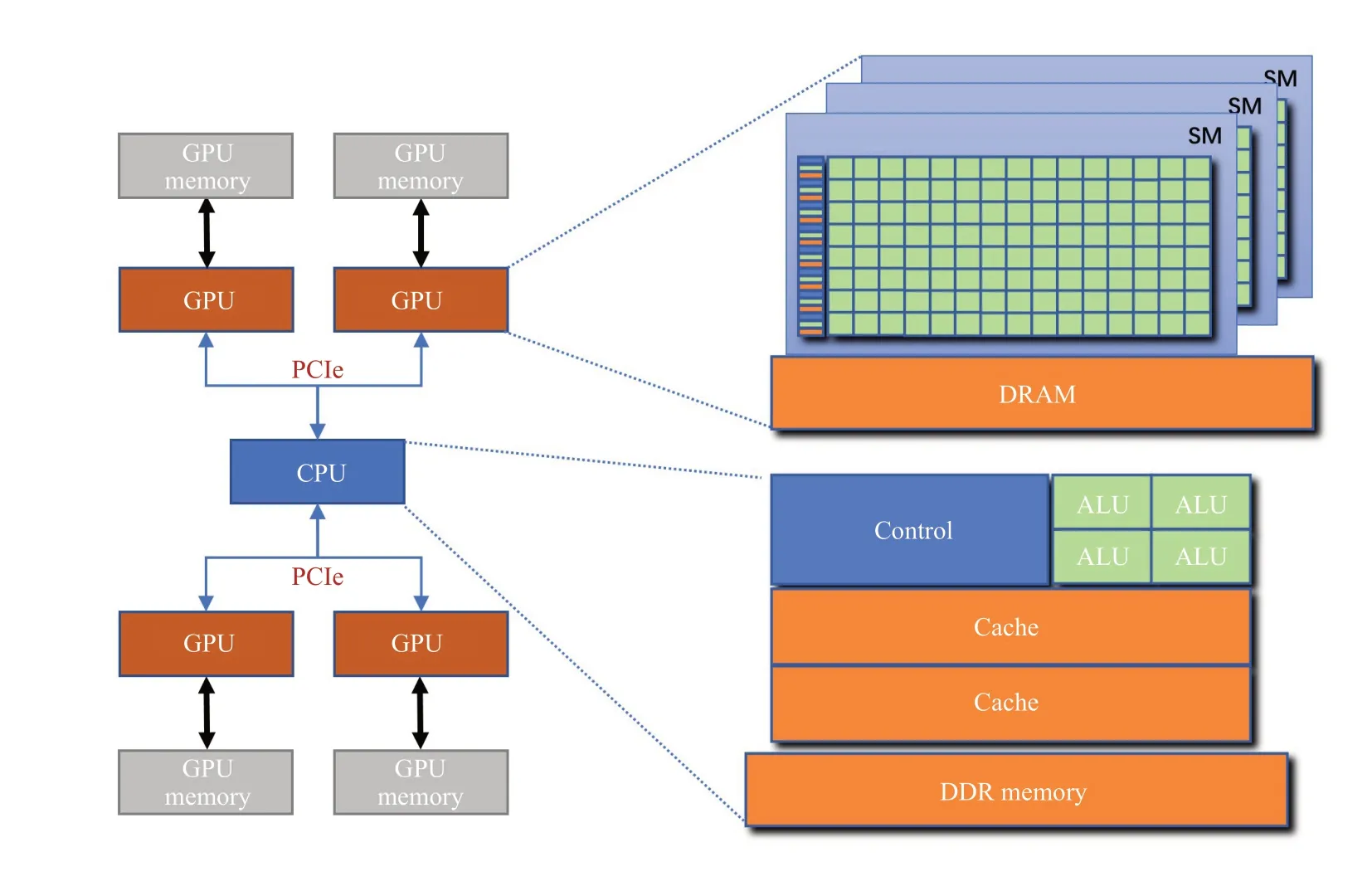
图2 “中科先导1 号”架构Fig.2 Architecture of Xiandao-1,CAS
ROCm[28-29]开源计算平台基于新一代的Radeon硬件,支持最新的数学函数库和汇编语言环境,以及多加速卡的计算,为开发大规模、高性能计算软件提供了便利,并大大降低了功耗,同时该平台还提供了机器学习框架等多种开源技术,并在不断地更新,有着优秀的可扩展性,其中用于可移植性的异构计算接口HIP 是一种C++运行时API 和内核语言,它主要是为了简化CUDA 应用向可移植C++代码的转换,接口可以跨主机/内核边界使用模板和类,以及其他C++功能集。移植工具HIPify 可以自动完成大部分CUDA 到HIP 的转换工作,代码在AMD 的DCU 与NVIDIA 的GPU 上通过各自的编译器进行编译后便可以正常运行,同时没有性能上的损失。
2.2 树方法的短程力计算在加速卡上的实现
TreePM 方法中,短程力部分采用树方法计算。加速度的计算是整个N 体模拟计算流程最主要的开销,占比可以达到90%以上,而这一部分中计算短程力的部分占了极大比例。以表1 为例,粒子数为1283,采用4 个进程,迭代200 个时间步。加速度的计算耗时905.1 秒,占总时间的93.6%,而其中计算短程力的部分可以占总耗时的89%,因此对这一部分进行加速,可以大幅度地提升整个流程的效率。
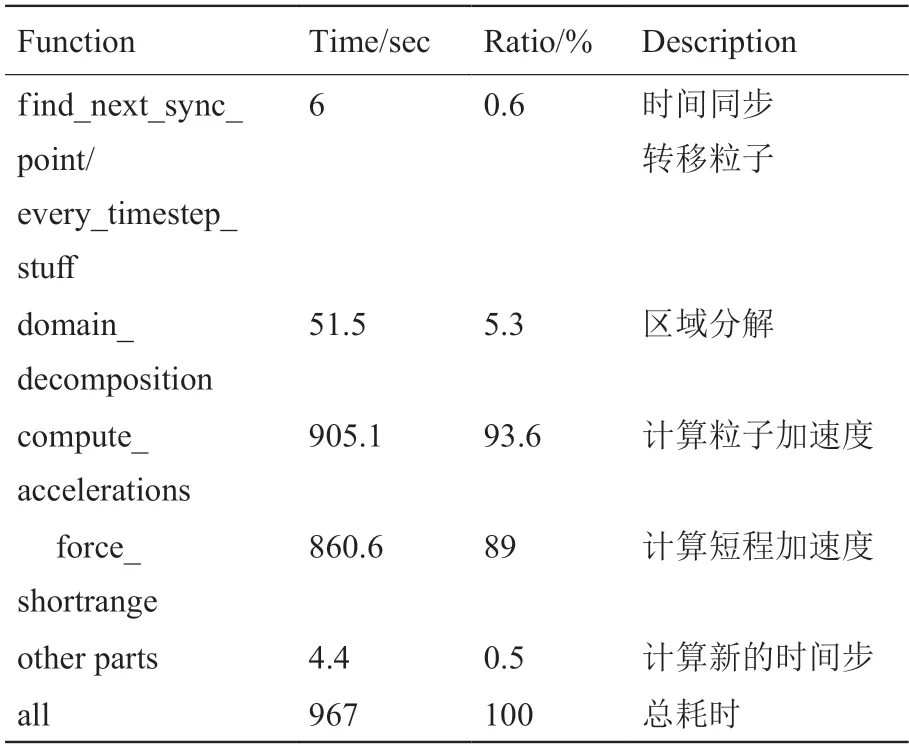
表1 Gadget-2 的各部分耗时Table 1 Time consumption for each part of Gadget-2
在Gadget-2 中,树方法的实现是一个“边走边算”的过程,即获得目标粒子后,从根节点开始,对目标粒子附近的空间节点进行遍历,获得相关的作用节点,然后计算两者的作用力,因此本文树方法在加速卡上的实现中,将对树遍历的过程与粒子作用力计算同时转移到设备端进行操作,相应的我们需要将粒子信息与树的相关信息共同传入设备端,即如图3 所示。
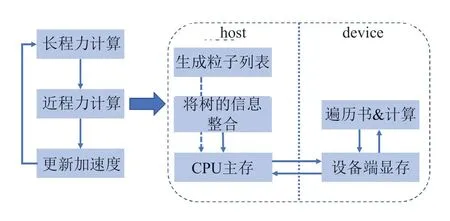
图3 Tree 方法在加速卡的实现Fig.3 Implementation of BH-Tree method on accelerators
短程力计算中,首先在CPU 端将树节点的相关信息传入设备端,再通过函数CountParticlesInCurrTime()遍历粒子列表,得到当前时间步的目标粒子数量以用于分配传送粒子信息所需要的内存。
开始对粒子进行引力计算。对短程力的计算包含两个部分:local 和export,分别表示当前进程以及其他进程的粒子对目标粒子进行的作用力。在计算local list 时,遍历树的过程中会判定并标记当前粒子是否会对其他进程的粒子进行作用,当计算完本地进程粒子之间的作用力之后,根据标记从其他进程获取需要进行相互作用的粒子列表,开始计算export list。实现时在函数force_treeevaluate_shortrange_hip()中调用核函数进行引力计算,并传入参数0 或者1 来表示计算local list 或是export list,从而在核函数开始前进行对应的数据预处理。最终计算完成之后对结果进行汇总,传回CPU 端后,更新粒子加速度以进行下一次迭代。
在原本的Gadget-2 中,是将当前时间步中参与引力计算的粒子划分为多次任务后进行计算,为了减少核函数的调用次数以及数据传输开销,在计算第一次任务时即可将当前进程中所有粒子的本地加速度在加速卡上计算完成,之后的多次任务只进行export list 中的粒子的引力计算。
核函数中线程根据索引取得对应的粒子信息,然后通过遍历树计算粒子与节点之间的作用力。遍历从根节点开始,其流程与原Gadget-2 基本相同,都是依靠NextNode 数组来获得下一个需要遍历的节点,然后进行判定处理,计算加速度并更新。由于我们需要在遍历树的时候标记粒子是否会对其他进程中的粒子进行作用,此时粒子在线程中的索引与其在CPU 端Particle 数组中的索引是不同的,因此还需要将粒子在CPU 端实际的索引传到设备端。Gadget-2 在构造树时高效利用了节点之间的索引关系,相关内存的消耗大大降低,并且提高了遍历树的效率,同时也有效地减少了需要传入设备端的数据量。经过测试,在模拟规模达到1283粒子的整个过程中,数据传输所占用的时间比例仅是2.5%。

3 核函数在加速卡上的优化
对于加速卡来说,核函数的内存请求通常是在DRAM 设备和片上内存间以内存事务来实现的。连续对齐、合并的内存访问对于设备内存来说是最佳访问模式,否则会因为内存事务中有大部分传输的数据不会被使用,而造成带宽的浪费,或者是事务请求的数量过于庞大,增加了访存压力,降低了最终的访存效率。通常来说,有两种数据组织的方式,分别是Struct of Array (SOA)与Array of Struct(AOS)。相比于AOS,SOA 通常能更加有效地减少访存事务的数量,提高访存效率。
如图4,采用AOS 模式在加速卡上读取坐标数据x 字段,由于隐式加载以及数据的交叉存储访问,每次读取事务中只有1/3 的数据是我们实际需要的,同时会由于加载了不需要的数据而浪费缓存空间。如果线程0 到线程5 需要读取x 轴坐标,按照图示读取方式需要三次事务请求,而在SOA 模式下读取数据只需要一次事务请求,更好地利用了加速卡的内存带宽,以达到更高效的访存效果。


图4 SOA 与AOS 内存布局Fig.4 The memory layout of SOA and AOS

如算法2 中的伪代码所示,在核函数中,在遍历树的过程中会反复用到许多常数来判断节点之间的关系,同时在更新加速度因子fac 时,会涉及到对表的查询,该表是对修正系数的插值。为了提高线程的访存效率,在不影响并行效率的情况下这些常数可以先预取保存在寄存器中,而对于查询表可以将其保存在共享内存。
优化过程中也可以采用页锁定内存以及异步多流的方式来提高数据在CPU 端与设备端之间的传输效率,但是如2.2 节所述,数据传输占据的整体运行时间比例仅为2.5%,因此该类方法并不能大幅提升整体性能。
4 数值结果与正确性
4.1 正确性验证
下面将Gadget-2 的HIP 移植优化版本记作G2H。实验平台为“中科先导1 号”,软硬件环境详见2.1 节。宇宙模拟的初始条件由基于二阶拉格朗日扰动理论和Lambda Cold Dark Matter(LCDM)模型编写的软件2LPTic 生成。LCDM 模型是宇宙大爆炸理论的数学参数化描述,该模型假设宇宙中的大部分物质由冷暗物质组成,它们只存在引力相互作用。这是如今宇宙学中普遍认同的标准化模型,也是目前可以为观察到的宇宙微波背景辐射、宇宙的大尺度结构等现象提供合理解释的最简单的模型,同时在该宇宙模型中有一个与暗能量相关的常数Lambda,它能够解释哈勃定律,即宇宙随时间不断加速膨胀的过程。
文中用功率谱来验证G2H 的计算正确性。验证方法是通过计算统计暗物质密度分布,然后根据模拟尺度得到密度分布对应的功率谱。功率谱是随机振幅的两点相关函数的傅里叶变换,这个振幅会在引力的影响下随着时间的推移而缓慢变化,因此我们可以通过比较程序模拟中相同红移处的功率谱检验正确性。
实验过程中模拟1283个粒子在尺寸为100h-1Mpc,以共动坐标系为参考的盒子中的运动状态,并考虑周期边界条件,初始红移z=49,其他参数包括:同时采用PM 方法,网格参数设置为PMGRID=128。实验过程中选取红移z=0、1、2、3、5 来进行功率谱的比对。
Gadget-2 和G2H 在红移z=0 时粒子分布的柱密度图如图5 所示,图6 的功率谱中线条和符号分别表示G2H 和Gadget-2 的结果,两者的残差几近为0,保证了G2H 的正确性。

图5 Gadget-2(左)与G2H(右)的N 体模拟在红移z=0 时的柱密度图Fig.5 The density map for the N-body simulation of Gadget-2(left panel) and G2H (right panel) as red shift is 0

图6 Gadget-2 与G2H 的功率谱比较Fig.6 Comparison of power spectrum of Gadget-2 and G2H
4.2 性能测试
下面分别测试加速比和并行效率。由于计算过程中每一步粒子的分布不同,因此每个时间步的运行时间有波动,我们进行10 步迭代然后取平均值作为单步运行时间进行比较。粒子规模分别取1283、2563、5123,分别使用4、8、16 个进程(记作Np)与相同数量的加速卡对Gadget-2、G2H 进行性能测试,平均单步的总运行时间和短程力运行时间见表2。
由表2 可以得到,粒子规模越大,程序在加速卡上的加速效果越明显,因为短程力的计算时间占比一般会和粒子规模一同增加。相比于Gadget-2,G2H 程序的整体加速比可以从11.47 倍提高到13.27倍,短程力部分计算加速比可以从24.25 倍提高到35.67 倍。
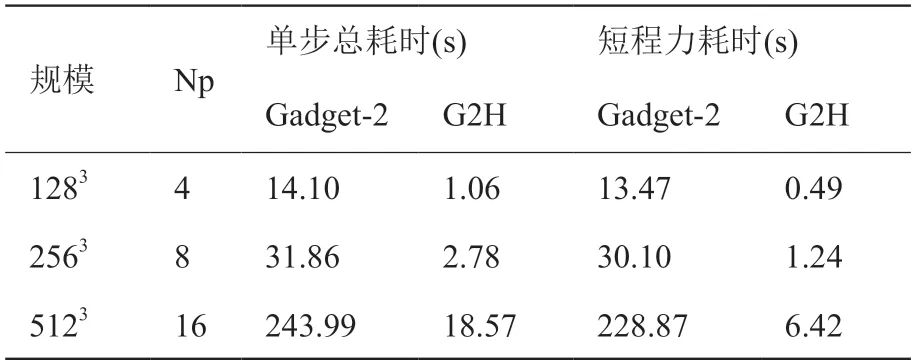
表2 Gadget-2、G2H 的单步平均耗时Table 2 Average step runtime of Gadget-2 and G2H
在以往PHoToNs 的移植优化工作中,短程力计算效率可以提升上百倍,而Gadget-2 中热点函数在加速卡上移植优化后性能只能提升30 倍左右,这与两者的计算流程有关。在PHoToNs 中提前进行树的遍历,将相互作用的粒子放入包中,而加速卡提取对应的包进行计算,没有过多的其他步骤,但在Gadget-2 中由于需要通过遍历树不断判定来进行引力对的计算,除计算外的冗余步骤以及逻辑判断较多,这些都严重影响了G2H 中核函数的并行效率,导致两者的优化效果有着明显的差异。
在并行效率测试中,粒子规模为5123,分别使用8、16、32、64、128 个进程与相同数量的加速卡迭代10 步后取平均值作为单步耗时。图7 显示了G2H 在“中科先导一号”上的强可扩展性,表3 是测试中对应的具体耗时。可以看出,在加速卡上不仅有短程力的计算,还有树的遍历,这对短程力在加速卡上的并行效率有着较大的影响,而在主机端实现了非本地树节点之间的通信以及PM 的通信,这些因素也成为了程序主要的性能瓶颈。最终G2H 的整体并行效率是57.29%,其中短程力并行效率是53.87%。
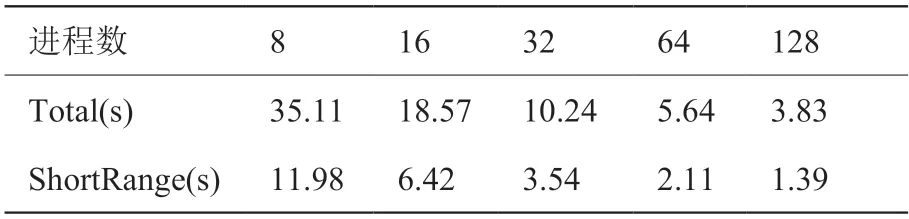
表3 G2H 强可扩展性测试的单步平均耗时Table 3 Average step runtime of G2H in strong scalability test

图7 G2H 的强可扩展性测试Fig.7 The strong scalability test of G2H
5 结论与展望
本文将基于TreePM 算法的宇宙学N 体模拟软件Gadget-2 中耗时占比90%以上的短程力计算模块通过HIP 移植到加速卡异构平台“中科先导一号”。通过数据内存重构,并充分利用寄存器和共享内存,减少了加速卡对内存存取开销,提高了设备端访存效率。通过功率谱验证了移植优化的正确性,并进行相关的性能测试,程序整体与短程力部分的计算速度最高分别提升了13.27 倍与35.67 倍,并行效率分别达到57.29%与53.87%。由于本文的方案是在加速卡上进行树的遍历,导致较多的逻辑判断,这对加速卡性能的充分挖掘是不利的,因此考虑将树的遍历尽可能地在CPU 上进行,在加速卡端进行主要的计算,同时这样也能平衡主机与设备端之间的数据传输,这些将作为下一步的研究任务。本文的移植优化方法可为类似的树结构算法在高性能异构平台上的实现与大规模异构并行模拟提供借鉴。
利益冲突声明
所有作者声明不存在利益冲突关系。
