基于改进YOLOv4算法的苹果叶部病害缺陷检测研究*
2022-10-27王权顺吕蕾黄德丰付思琴余华云
王权顺,吕蕾, 2,黄德丰,付思琴,余华云
(1. 长江大学,湖北荆州,434023; 2. 中国农业科学院油料作物研究所,武汉市,430062)
0 引言
苹果素有“水果之王”的美称,因其风味优美、营养价值高,是全球食用最广泛的水果。苹果是世界四大水果之一,中国已成为世界最大的苹果生产国和消费国[1]。苹果产业在我国部分农村经济发展中占据着不可替代的主导产业地位,苹果病害对苹果的产量有着重要影响,也影响到国家和果农们的经济收益[2],苹果病害易发生在叶部,如果能够快速准确地识别出病虫害并及时对其进行控制,可以将果农们的经济损失降到最低[3]。
目前,在苹果的病害缺陷识别方面,主要是由果农们和专家们通过经验来判断病害的种类,但这些传统识别方法的准确率和效率都低下,已慢慢不适用于苹果叶部病害的诊断。随着深度学习在计算机视觉领域的飞速发展,卷积神经网络在各个领域得到了广泛的应用[4-6]。深度学习算法在农作物病害识别方面产生了巨大作用,傅云龙等[7]基于YOLO算法对马铃薯表面缺陷检测,平均识别精度达到99.46%,对腐烂、发芽、机械损失、虫眼、病斑检测的精度均高于98%。宋中山等[8]通过改进YOLOv3[9]对自然环境下绿色柑橘进行识别,采用DenseNet的密集连接机制替换YOLOv3网络中的特征提取网络DarkNet53中的后三个下采样层,加强特征的传播,实现特征的复用,最终训练得到的模型在测试集上的精确率为83.01%。周宏威等[10]利用迁移学习构建VGG16,ResNet50,Inception V3三种神经网络模型对苹果叶片病虫害进行识别,发现使用迁移学习能够明显提升模型的收敛速度以及准确率,三种模型的准确率分别达到了97.67%,95.34%和100%。王云露等[11]通过改进Faster R-CNN对苹果叶部病害识别,模型使用拆分注意力网络作为骨干特征提取网络(backbone),采用级联机制对建议框生成机制进行优化,与改进前相比,平均精度提升了8.7%。随着大量研究者的研究实践,深度学习也推动着农业方面的发展。
本研究以苹果叶片作为研究对象,通过深度学习技术实现对苹果病害叶片进行识别。在实际研究过程中苹果叶片病斑多为小目标,在图像所占比例较小,且在叶片中散布较广,YOLOv4的预设锚框(anchor)不适合应用于病斑等小目标缺陷检测[12]。另一方面,YOLOv4当中的CSPdarknet53特征提取网络的参数量和模型大小较大,不适用于大多数生活场景中。针对上述问题,笔者在YOLOv4的算法上基础上对其进行改进,主要改进工作如下:使用二分K均值聚类算法优化YOLOv4聚类算法能够满足对苹果叶部病斑等小目标检测;引用DenseNet121[13]网络代替YOLOv4当中的CSPdarknet53作为YOLOv4的特征提取网络,DenseNet121网络通过使用密集连接卷积网络,在保证其特征提取能力下还能够减少计算量,并且可以提高对苹果叶部病斑等小目标的检测性能。
1 样本采集与方法
1.1 数据集采集
本次研究以选取苹果灰斑病叶片,苹果锈病叶片,苹果黑星病叶片,苹果斑点落叶病叶片4种病害类别的图片作为研究对象,其中苹果黑星病数据来自于PlantVillage数据集,图片大小为256×256像素,苹果灰斑病,苹果锈病,苹果斑点落叶病通过百度等网站获取,图片大小为512像素×512像素。通过人工筛选,将冗余图片和模糊图片手动删除,对剩余图片进行labelimg工具进行标注。本次研究共有840张图片,其中苹果灰斑病叶片230张,苹果锈病叶片270张,苹果黑星病叶片110张,苹果斑点落叶病叶片230张,如图1所示。

(a) 灰斑病 (b) 锈病
将苹果叶片病害数据集以训练集∶验证集∶测试集=8∶1∶1划分,数据集格式为VOC格式。
1.2 数据扩增
为避免数据集不足使得模型在训练过程中出现拟合情况,现对数据集进行数据扩增操作,本文通过对角线镜像变换、随机旋转、改变亮度(亮暗)对数据集进行数据扩充,由于图像的旋转会使得一部分信息损失,而且不能够容易地判断旋转后的图像是否还包含我们的完整目标。因此把原图像先安装长短边的长度填充为一个正方形,这样可以确保填充后的图像在旋转过程中,原图中的目标信息不会丢失。数据扩增可以使得训练数据尽可能的接近真实数据,从而提高预测精度。另外数据扩增可以使网络学习有更好的鲁棒性,从而使模型拥有更强的泛化能力。
通过数据扩增之后,原有840张苹果叶片图像扩增至4 200张,数据集变化如表1所示,扩增后的图像如图2所示。
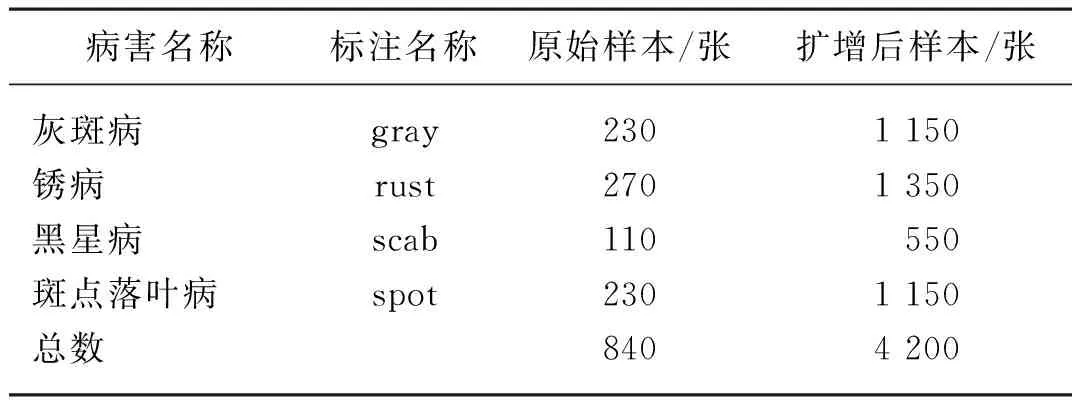
表1 苹果叶片数据集Tab. 1 Apple leaf data set

(a) 原图 (b) 亮度改变(暗) (c) 亮度改变(亮)
2 改进YOLOv4模型
2.1 YOLOv4模型
YOLOv4算法网络结构主要由主干特征提取网络Backbone,特征融合网络Neck,检测头Head部分组成。主干特征提取网络主要是由CSPDarknet53组成,其主要是由五层残差网络[14]Resblock Body组成,其输入的图像像素是416×416,其中Resblock Body有专门的卷积操作来降低分辨率,每一层的Resblock Body将像素逐渐降低一倍,其主要功能是提取图像数据的特征信息,Neck部分是由SPP[15]和路径聚合网络PANet[16]组成,SPP是空间金字塔池化网络,目的是增加网络的感受野,PANet是一种实例分割算法,PANet框架采用自底向上的路径增强,通过上采样(UpSample)操作使用先验局部卷积层来缩短高分辨率和低分辨率特征之间的信息路径。YOLOv4结构流程图如图3所示,并且YOLOv4使用了Mish[17]激活函数,极大的提高了检测的准确性。其中,Mish激活函数公式如式(1)所示。
Mish=xtanh[ln(1+ex)]
(1)
式中:x——图像像素经卷积操作后的像素值。

图3 YOLOv4结构流程图
2.2 缺陷检测流程
缺陷检测流程如图4所示。

图4 缺陷检测流程图
首先将采集到的数据集进行数据扩增操作,将处理之后的数据集通过二分K均值聚类算法聚类出9个锚框,将9个锚框坐标加入YOLOv4网络参数,把YOLOv4模型中特征提取网络CSPDarknet53网络替换为DenseNet121网络,最终得到B-YOLOv4-D网络模型。将处理之后的数据集使用B-YOLOv4-D模型训练得到一组训练权重,选出最优权重验证检测效果。
2.3 二分K均值聚类算法
YOLOv4算法预设锚框是通过采用K均值聚类算法[18](K-means)在COCO数据集上进行分析,得到一组先验框,由于COCO数据集多种多样而苹果叶片病害缺陷多以小目标为主,容易筛选出不适合苹果叶片病害数据集的Bounding Box。K均值聚类算法对于离群点和噪音点比较敏感,在计算过程中质心是随机初始化的,虽然最后会通过划分后的点加均值函数重新计算,但质心没有真正的进行最优化收敛,K均值聚类算法收敛到了局部最小值,而非全局最小值。因此,将原始K均值聚类算法改进为二分K均值聚类算法可以克服收敛局部最小值的问题。二分K均值聚类算法首先将所有点作为一个簇,计算总误差,使用K-means将数据集分成两个簇,记录误差平方和(SSE),选择使得误差平方和最小的那个簇进行划分操作,重复上述操作,直到得到用户指定的簇数目为止。其中误差平方和
(2)
式中:Ci——第i个聚类;
p——样本点;
mi——第i个聚类中心。
经过多次试验,使用改进二分K均值聚类算法对数据集进行聚类,共聚类出9个锚框,结果为(16,17),(26,26),(37,36),(50,49),(64,65),(72,89),(90,79),(105,109),(145,150)。聚类中心在数据集的分布如图5所示。
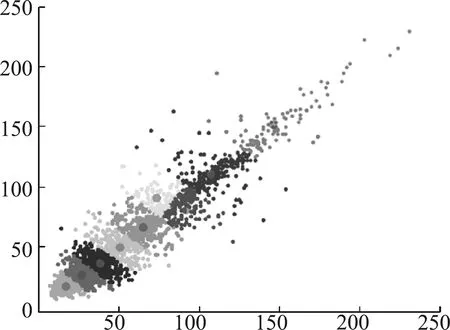
图5 二分均值聚类中心图
2.4 引入DenseNet121作为特征提取网络
YOLOv4算法以CSPDarknet53网络作为特征提取网络,共计有104层卷积网络,其中卷积层72个。并且大量使用3×3卷积操作。YOLOv4模型参数量可达6 000多万,模型参数大小达到245.53 MB,难以达到日常生活的需求,并且由于卷积层数的增多,使得YOLOv4对苹果叶片病斑等小目标特征提取能力下降。因此,引入DenseNet121作为YOLOv4的特征提取网络。
DenseNet主要包含卷积层、密集块、过渡层和分类器组成,它采取密集连接机制[19],以前馈方式将各个密集块中的层直接连接,Dense Block中每层均以密集连接方式连接到后续所有层中,将之前层的输出作为当前层的输入。Dense Block如图6所示,在DenseNet121中,共有4个Dense Block,数目分别为6,12,24和16。DenseNet121的网络参数少,由于Dense Block的设计,在Dense Block中每个卷积层输出的Feature Map数量很少,同时这种连接方式使得特征和梯度的传递更加有效,网络更加容易训练,因为梯度消失的主要原因就是输入信息以及梯度信息在很多层之间传递导致的,采用Dense Block连接则相当于每一层和Input及Loss直接相连,减轻梯度消失的发生。

图6 Dense Block结构
因此,通过改进二分K均值聚类算法确定锚框,引入DenseNet121代替CSPDarknet53网络作为YOLOv4的特征提取网络,提出B-YOLOv4-D算法。算法模型结构如图7所示。
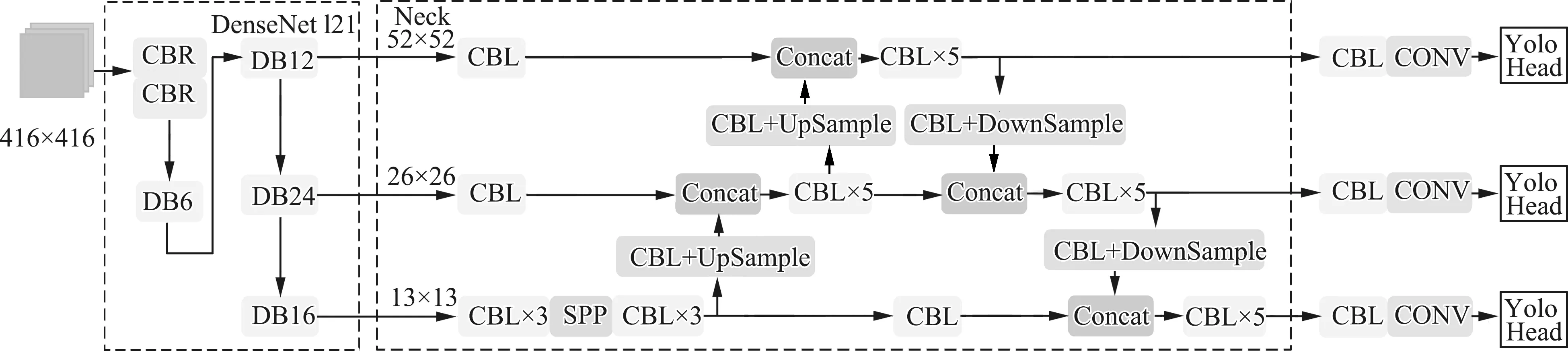
图7 B-YOLOv4-D结构流程图
3 试验结果及分析
3.1 试验环境
本试验平台操作系统为Windows 10 64位,中央处理器(CPU)为Intel Core i7-10870H CPU @ 2020GHz,计算机内存为16 G,图形处理器(GPU)为NVDIA GeForce RTX 2060,显存大小为6 G,深度学习框架为Pytorch。
3.2 超参数设置
在B-YOLOv4-D训练过程中,输入图片大小设置为416×416,数据集大小为4 200张图片,epoch设置为300,优化器使用Adam优化器,初始学习率设置为0.001,在50个epoch之后学习率设置为0.000 1,衰减系数设置为0.000 5。
3.3 训练结果
在B-YOLOv4-D训练过程中,损失值(Loss)能否迅速收敛并且达到稳定是模型性能的重要指标之一,此模型在300个epoch的损失曲线如图8所示。从图8中可以看到在第70个epoch之后损失值已经收敛,从收敛情况来看,算法模型训练效果理想。

图8 B-YOLOv4-D loss曲线
3.4 试验结果与对比
本文训练模型采用mAP(mean average precision)和FPS作为模型评价标准,FPS为每秒模型能够识别得图片数量,mAP的计算是通过各类别的P-R曲线图中面积AP的总和再进行平均得来的,AP由精确率(precision,P)与召回率(recall,R)计算的来的,其计算方法如式(3)~式(6)所示。
(3)
(4)
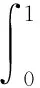
(5)
(6)
式中:TP——预测为正的正样本;
FP——表示预测为正的负样本;
FN——表示预测为负的正样本;
n——类别总数。
试验通过各个模型对苹果叶部病害数据集进行训练,得到的AP值如表2所示。经过对比,各个模型性能对比如表3所示。

表2 改进前后YOLOv4模型的AP值Tab. 2 AP values of YOLOv4 model with/without improvement

表3 模型性能对比Tab. 3 Model performance comparison
由表3可得,B-YOLOv4-D算法相对于YOLOv4算法检测mAP提升0.89%,模型大小只有62.71 MB,相比于原来减小182.82 MB,并且在检测速度上B-YOLOv4-D算法提升6.78 FPS。以上结果表明B-YOLOv4-D比YOLOv4性能更优。
为了更直观的验证本文算法的效果,将B-YOLOv4-D算法应用于苹果叶部病害缺陷检测,检测效果如图9所示。

(a) 灰斑病 (b) 锈病
由图9可知,B-YOLOv4-D算法可以准确地检测出苹果叶部病害缺陷。
4 结论
本次试验基于深度学习技术通过改进YOLOv4算法应用于苹果叶片病害识别研究,得到如下结论。
1) 使用数据扩增技术将数据集进行扩增,使网络学习有更好的鲁棒性,提高了模型的泛化能力。通过使用二分K均值聚类算法解决YOLOv4算法的预设锚框不适用于苹果叶部病斑等小目标的问题,增强算法模型的识别性能。
2) 引入DenseNet121代替CSPDarknet53网络作为YOLOv4的特征提取网络,减少了网络的参数量,减轻梯度消失的问题,提出B-YOLOv4-D算法。试验结果表明,B-YOLOv4-D算法比原始YOLOv4算法mAP提升0.89%,检测速度提高6.78 FPS,并且模型大小减小182.82 MB。
3) 通过上述对比试验,B-YOLOv4-D算法具有较高的泛化能力,较小的模型大小以及较高的检测精度。能够满足日常生活的需求,为苹果叶部病害防治提供了科学的识别方法。
