面向互联网食品文本实体关系联合抽取研究
2022-10-26薛明慧张青川蔡圆媛
左 敏,薛明慧,张青川,蔡圆媛
(北京工商大学 农产品质量安全追溯技术及应用国家工程实验室,北京 100048)
0 引 言
实体关系抽取从非结构化文本中提取出结构化3元组知识,是知识库构建等下游任务的基础,主要分为实体关系联合抽取和流水线式抽取两种方法。文献[1-2]通过先提取出文本中的实体,再抽取出关系的方式提取实体关系3元组,存在给没有关系的实体强加关系的问题。流水线式抽取方法存在错误传播,忽略2个任务之间关系的问题。
实体关系联合抽取的方法可以增强实体识别任务和关系抽取任务之间的联系。文献[3-4]采用实体关系联合抽取模型抽取文本中的实体关系3元组,但其模型需要人工构造大量的特征,同时依赖NLP工具包自动抽取,影响抽取结果。文献[5]首次使用深度学习的方法联合抽取实体和关系,用序列标注模型标记实体,使用多分类器抽取关系,通过共享参数进行联合学习,但存在实体识别和关系抽取没有明显交互作用的缺点。文献[6]提出一种新的序列标注方法,将实体关系抽取问题转化为序列标注问题,使用端到端模型取得了较好的实验效果,但无法有效抽取复杂句中一个实体属于多个关系的情况。文献[7]改进了文献[6]的标注方式,在标注中加入了重叠标签,但仍不能抽取句中所有复杂的重叠实体关系。上述论文使用词向量来表示句子的语义特征,没有在字级别上对一字多义的情况进行有效的表征。
针对流水线式抽取中存在的错误传播和词向量无法对字符多义性表征的问题,为提升食品领域文本中重叠实体关系的识别效果,本文将实体关系抽取任务转变为序列标注问题,采用基于位置感知的领域词注意力机制的字词双维度语义编码向量,利用双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)对上下文的理解能力和条件随机场(conditional random field, CRF)对标签的约束能力,构建了序列标注模型(position attention-bidirectional encoder representation from transformer, PA-BERT),并根据序列标注结果和规定的匹配规则实现实体关系抽取。
1 互联网食品文本实体关系抽取模型
互联网食品文本实体关系抽取模型主要由3部分组成,分别是文本预处理、PA-BERT序列标注模型、实体关系抽取。
1.1 文本数据预处理
对于互联网食品文本数据预处理主要包括以下几个步骤。
1)数据获取。爬取京东、百度百科上的食品信息。京东关于食品非结构化的文本信息在食品详情页的图片中,使用百度OCR接口提取图片中的文本信息;百度百科的食品信息主要是食品词条信息。
2)数据筛选和标注。对爬取的数据分句过滤掉无关句子,筛选出要人工标注的句子,以句子为单位进行人工标注,再将句子转化为以字为单位的标签序列。
3)构建领域词库。通过新词发现算法和人工筛选修正构建得到互联网食品文本领域词库。
4)定义实体关系。根据爬取的语料样本,总结出其中5种关系及其关系的主体、客体。
5)确定实体标注标签。实体标注标签由单实体标签和重叠实体标签构成。单实体标签由3部分组成,即实体边界、实体关系、实体角色标签。实体边界标签用BIO表示元素在实体中的位置信息,B表示元素在实体的开头,I表示元素在实体的中间或结尾部分,O表示元素非实体;实体关系标签由5种关系的英文单词的前3个字母表示;实体角色标签表示实体在3元组中的角色,用1、2来表示,1表示主体,2表示客体。
重叠实体标签由实体边界标签和“OVE”构成,即“B-OVE”和“I-OVE”。
实体标签分为3类共23种。
1.2 PA-BERT序列标注模型
PA-BERT序列标注模型的整体结构如图1所示,主要有字词双维度向量编码、BiLSTM层和CRF标签输出层3部分。
1.2.1 基于位置感知的领域词注意力机制
模型中基于位置感知的领域词注意力机制对词向量的加权算法过程如图2所示。先得到句子中领域词的位置,再根据位置感知影响力传播得到加权后的词向量。
使用高斯核函数模拟基于位置感知的影响传播,表示为
(1)
(1)式中:u为领域词与当前词的距离;σ为约束传播范围的参数;Kernel(u)为距离领域词为u时,当前词所受到的影响。
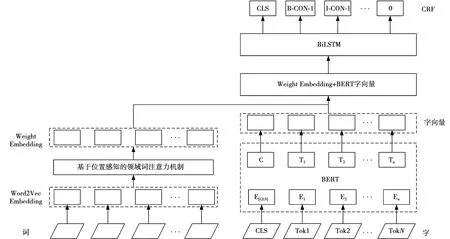
图1 PA-BERT序列标注模型Fig.1 PA-BERT sequence annotation model

图2 基于位置感知影响的词向量表示过程Fig.2 Word vector representation process based on the influence of location perception
假设领域词对特定距离词的影响服从维度上的高斯分布,根据此假设定义基础影响矩阵K,K中每个元素定义为
K(i,u)~N(Kernel(u),σ)
(2)
(2)式中:K(i,u)为第i维度上距离为u时受到的影响;N为符合期望值是Kernel(u)、标准差是σ的正态分布。
在基础影响矩阵的基础上,通过累加领域词对邻近词的影响得到特定位置处的影响向量Pj为
Pj=K(i,u)cj
(3)
(3)式中:cj为距离计数向量,计算出现在某个距离中领域词的数量。cj(u)的计算式为
[(j+u)∈pos(q)]
(4)
(4)式中:Q为句子中的领域词数量;q为Q中的一个领域词;pos(q)表示q在句子中的位置集合;[·]是判断符号,如果满足条件则为1,否则为0。
句子中位置j的词注意力可表示为
(5)
(5)式中:hj为句子位置j处的词向量;l表示句子中词的个数;a(·)是打分函数,用来计算句子中某个词获得的权重,其计算式为
a(i,t)=vTφ(WHhj+WpPj+b)+c
(6)
(6)式中:WH、WP是矩阵;b、c是偏置向量;v是全局向量;vT是v的转置向量;φ(·)=max(0,x)是ReLU函数。最终的词向量表示wj为
wj=αjhj
(7)
1.2.2BERT编码层
BERT基于Transformer的encoder部分,以无监督的方式对无标注文本进行训练。Transformer基于自注意力机制并行计算,其编码单元如图3所示。
Transformer编码单元中最重要的部分是自注意力机制,它表示一句话中字与字之间的相互关系,其计算式为
(8)
(8)式中:Q、K、V均为字向量矩阵,由输入向量和一个随机初始化向量相乘得到;dk表示输入向量的维度。
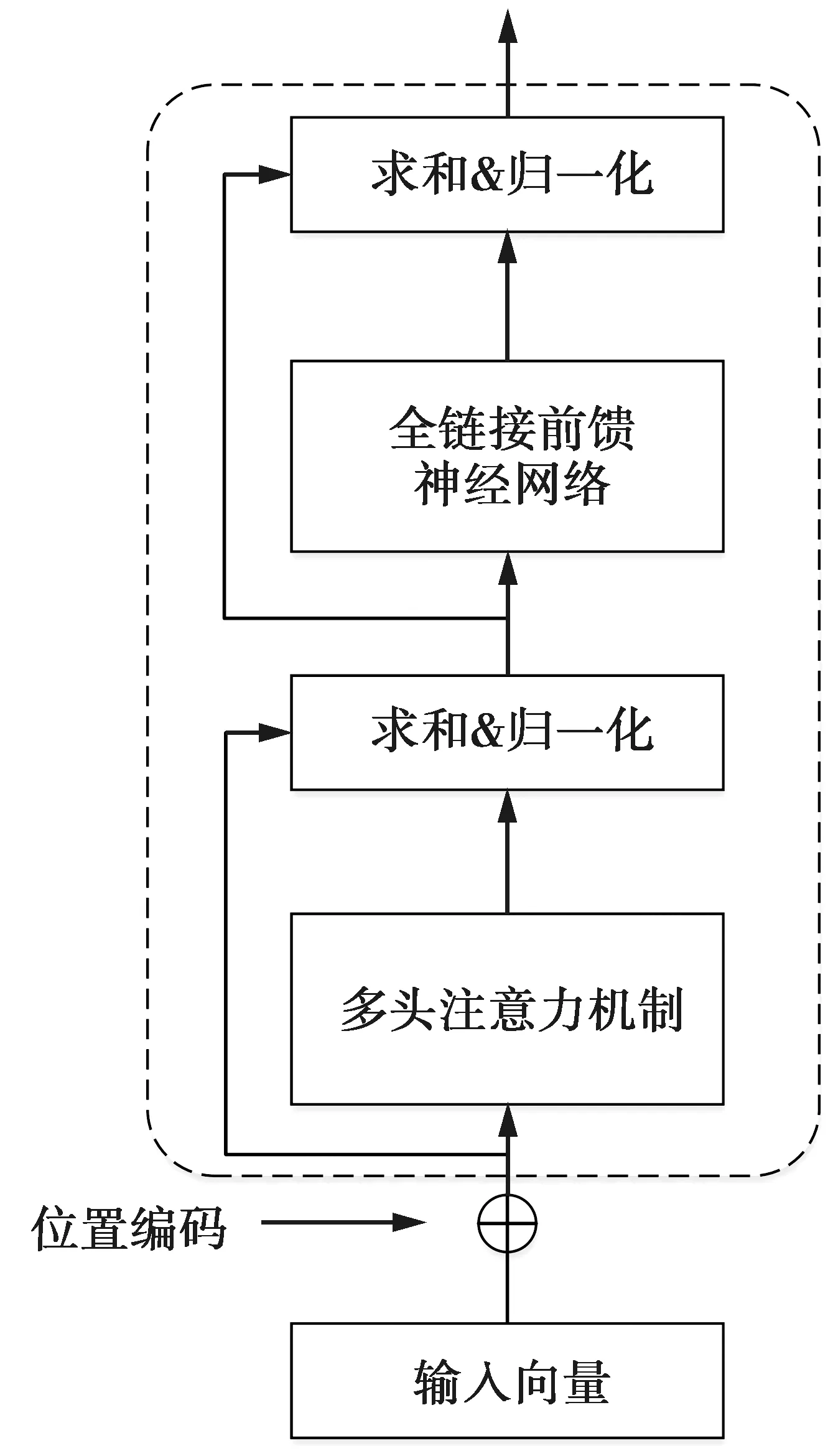
图3 Transformer编码单元Fig.3 Transformer coding unit
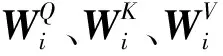
MultiHead(Q,K,V)=concat(head1,…,headn)W0
(9)
(10)
除此之外,Transformer还加入了残差连接和层归一化,改善多层堆叠时可能产生退化的问题。前馈神经网络层使用全连接层和激活函数ReLU实现。
BERT基于Transformer进行双向编码,相比其他模型,可以充分利用字的上下文信息,得到更好的字向量表示。
1.2.3BiLSTM层
本文选择字标注的方式,将文本字向量加上其对应的词向量,作为字词融合编码[8]。将字词双维度融合后的向量输入到BiLSTM中,捕获上下文信息,提取文本深层次特征,得到每个字,对应预测各个标签的概率。
LSTM通过3个门结构控制和管理输入输出信息。遗忘门决定从单元状态中丢弃掉部分信息,将上一时刻的输出ht-1以及当前时刻的xt输入到sigmoid神经层,输出一个数值在0到1之间的向量ft,表示为
ft=σ(Wf·[ht-1,xt]+bf)
(11)
(11)式中:σ表示sigmoid函数;Wf是权重矩阵;bf是偏置向量。
输入门决定让多少新的信息加入到单元状态中,使用sigmoid层决定要更新哪些信息,使用tanh层创建一个新的向量Ct,最后将单元状态Ct-1更新为Ct。输入门的表达式分别为
it=σ(Wi·[ht-1,xt]+bi)
(12)
(13)
(14)
(12)—(14)式中:Wi、Wc表示权重矩阵;bi,bC表示偏置向量。
输出门决定输出信息,使用sigmoid层决定要输出哪些信息,将Ct通过tanh层,将sigmoid层的输出和tanh层的输出相乘,得到最终的输出结果。输出门的表达式分别为
ot=σ(Wo[ht-1,xt]+bo)
(15)
ht=ot*tanh(Ct)
(16)
(15)—(16)式中:Wo表示权重矩阵;bo表示偏置向量。
BiLSTM将前向和后向LSTM的隐藏层向量拼接作为输出。
1.2.4CRF层
文本经过BERT和BiLSTM层后得到文本序列与标签之间的关系,无法考虑标签与标签之间的关系;通过CRF层对得到的预测标签进行约束,减少无效预测标签的数量,获得全局最优标签序列[9]。
在CRF层中有两种类型的分数,一种是经过BiLSTM层得到的标签概率p,矩阵p大小为n×m,n为句子个数,m为标签种类,Pi,j代表句子中第i个字的第j个标签的概率;另一种是转移矩阵T,Ti,j代表标签i到标签j的转移概率。句子序列x={x1,x2,x3,...,xn}对应的标签序列y={y1,y2,y3,...,yn}的得分表示为
(17)
CRF的损失函数由真实路径得分es(x,y)和所有可能路径总得分构成,表示为
(18)
得到CRF层中的标签概率和转移概率后,使用维特比算法找到最短路径,得到句子中每个字的预测标签。
1.3 实体关系3元组抽取
根据食品语料特点,句子分为单一实体关系抽取和重叠实体关系抽取。
单一实体关系抽取中,根据实体边界、关系、角色标签提取出实体,按顺序将实体向前向后匹配。若匹配的两个实体,关系标签相同,角色标签不同,则认为这两个实体组成一个3元组。重复此过程直到所有实体都参与一次匹配。
重叠实体关系抽取中,根据实体边界、关系、角色标签提取出实体,将非重叠实体按顺序向前向后匹配。若匹配到实体为非重叠实体,根据关系、角色标签判断两实体是否可组成3元组,匹配过的非重叠实体不再参与后续匹配;若匹配到的实体为重叠实体,根据非重叠实体的关系标签确定3元组,重叠实体可继续参与后续匹配。重复此过程直到所有实体都标记抽取。
2 实验与结果分析
2.1 实验构建
本文数据来源为京东食品信息和百度百科食品词条信息。将爬取的语料以句为单位筛选,人工标注得到互联网食品文本数据集(FD-Data)并作为实验使用的数据集。在数据集中随机选取20%的语料作为测试集,在训练集中选取10%作为验证集。
利用查准率(P)、查全率(R)和F1值(F1)评估模型的效果,计算表达式为
(19)
(20)
(21)
(19)—(20)式中:Tp是将正样本判定为正样本的个数;Fp是将负样本判定为正样本的个数;Fn是将正样本判定为负样本的个数。
模型试验参数如表1所示。序列标注模型训练在Epoch为6时,验证集数据表现不再提升,模型的损失函数变化趋势如图4所示。

表1 参数设置Tab.1 Parameter setting
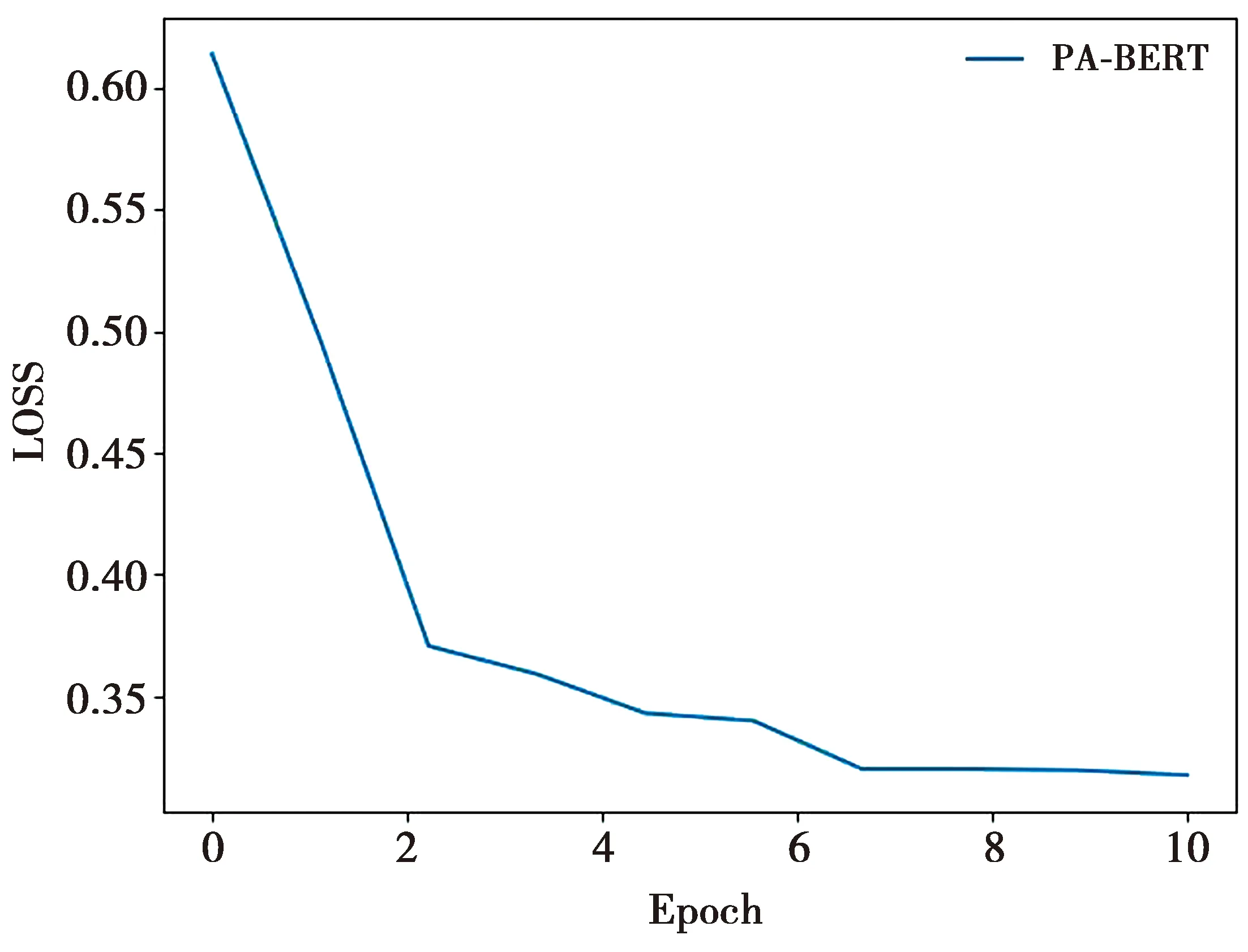
图4 损失函数图Fig.4 Loss function graph
2.2 实验结果对比与分析
为证明PA-BERT序列标注模型的有效性,将其同常规的CNN和BiLSTM模型及添加注意力机制的CNN和BiLSTM模型做比较。
BiLSTM使用随机初始化的字向量作为模型输入,用以对比本文提出的基于位置感知的领域词注意力机制的有效性;BiLSTM-Attention使用经注意力加权后的词向量作为模型输入,用以对比本文字词双维度向量的有效性。不同模型序列标注结果如表2所示。
通过对比实验发现,经注意力机制加权后的BiLSTM-Attention模型比使用随机初始化字向量的BiLSTM模型在序列标注任务中表现要好;而PA-BERT模型在前两个模型的基础上有了进一步提升,可以证明本文提出的模型在实体关系抽取任务中是有效的。
3 结 论
本文通过爬取京东、百度百科等网站的食品信息,构建了互联网食品文本语料库,针对食品文本中存在重叠关系的特点,采用重叠关系实体标注标签和实体关系抽取规则提取文本中的重叠关系3元组,将实体关系抽取任务转化为序列标注问题;使用基于位置感知的领域词注意力机制的字词双维度语义编码向量增强字和词的语义表征和序列文本上下文的理解,构建PA-BERT的互联网食品文本实体关系抽取模型。实验表明,本文提出的模型在中文互联网食品文本中抽取实体关系是有效的。
