基于二阶有效通道注意力网络的无约束人脸表情识别
2022-10-26周睿丽钟福金
周睿丽,钟福金
(1.重庆邮电大学 计算机科学与技术学院,重庆 400065;2.重庆邮电大学 计算智能重庆市重点实验室,重庆 400065)
0 引 言
人脸表情是指通过面部肌肉变化产生的各种情感,它是表达人类情绪状态最有力、最常见也是最自然的信号之一。由于人脸表情识别在心理学、医学、公共安全和商业领域有着广泛应用,因此人们对其进行了大量研究[1]。例如,通过观察人脸表情来推断患者的心理问题[2];通过检测驾驶员的疲劳度采取适当措施以避免事故发生[3]。目前已有许多人脸表情识别方法在受控环境的数据集[4-5]上取得较优的识别结果,然而当人脸图像处于无约束环境中时,人脸表情识别仍面临较大挑战,因为无约束人脸表情图像具有不同光照变化、头部姿态变化、身份偏差(种族、性别和年龄)和遮挡等不确定性因素。因此,设计一种鲁棒的无约束人脸表情识别方法很有必要。
比较早的人脸表情识别方法主要通过提取预先设计好的人脸特征进行表情分类,而人脸特征主要分为几何特征和纹理特征。基于几何特征的人脸表情识别方法是通过对人脸部件(眼睛、鼻子和嘴巴)的位置关系进行编码,从而利用得到的空间几何信息进行人脸表情识别。文献[6]模拟人脸和表情检测的人类视觉感知,将人脸局部信息(人脸特征的形状存储在每个节点的局部图中)和全局信息(人脸的拓扑结构)同时嵌入到模型中,然后将检测到的人脸图像与对应数据库中现有表情模型进行对比,进而识别人脸表情。该类方法可减弱光照变化和身份偏差给表情识别带来的影响,但不足之处是在人脸表情外观变化时很难准确定位到上述的人脸部件。基于纹理特征的人脸表情识别方法[7-9]通过使用图像滤波器对全局人脸图像或局部人脸区域进行滤波,检测到面部外观变化时人脸部件的确切位置,进而用来提取对表情识别任务贡献度较高的特征。然而,人们多变的生活环境导致人脸表情图像的多样化,使得研究者们很难设计出适用于不同环境的人脸表情特征提取方法。
近年来,研究者将卷积神经网络运用在无约束人脸表情识别任务中并获得较好的效果。例如,在没有大数据量的无约束人脸表情数据集的背景下,为解决无约束环境下头部姿态给人脸表情识别带来的问题,文献[10]提出一种同时进行人脸表情图像合成和识别的CycleAT网络模型(cycle-consistent adversarial attention transfer model),该模型利用迁移学习将人脸表情数据集和人脸数据集合成大量不同姿态下带有表情标签的数据,然后利用所生成的人脸表情图像训练目标分类器。通常情况下,增加网络的深度有利于人脸图像语义信息的学习,但仅仅增加其深度会导致梯度消失和网络性能的退化。为解决此问题,研究者提出残差网络(residual network, ResNet)[11]和密集连接网络(dense convolutional network, DenseNet)[12],这2种新型网络增强了层与层之间的信息交流,有利于深层特征的学习。但是上述研究方法通常只使用一幅全局图像的特征图来表示图像,相关研究[13]表明,人脸表情主要集中生成在人脸的局部区域,而现有的传统卷积神经网络无法学习到有利于表情识别的局部区域特征,并且在分类时对人脸局部区域的特征不能区别对待。因此,文献[14]提出一种深度注意力多路径卷积神经网络模型(deep attentive multi-path convolutional neural network, DAM-CNN),DAM-CNN可以自适应地为网络提取的特征图生成一个注意力掩码,利用该掩码给特征图的不同区域赋予不同权重,进而突显出一些与表情相关的局部特征区域。DAM-CNN只提取人脸图像的一阶信息,而人脸表情识别与人脸局部区域的微小变形高度相关,同时,相关研究[15]证明特征图的协方差矩阵等二阶信息比一阶信息更能捕捉到人脸表情的微小变化,故文献[16]利用流形网络和协方差池统计深层特征的二阶信息进行人脸表情识别,但该方法中涉及到不利于在GPU上进行的矩阵特征值分解操作,使其训练过程较为不稳定。
为充分利用注意力机制和图像的二阶信息,本文设计了一种用于无约束人脸表情识别的二阶有效通道注意力网络(second-order efficient channel attention network,SECA-Net)模型,该模型由轻量级的特征提取网络、SECA模块和一个全连接层组成。在SECA-Net中,首先使用轻量级的特征提取网络提取输入的人脸表情图像的深层特征;然后将其输入到SECA模块中,统计表情图像深层特征的二阶信息并捕获通道级特征间的相互依赖信息,使网络学习与表情高度相关的特征;最后,使用由Softmax损失和中心损失构成的联合损失函数优化模型进行表情分类。
本文主要工作如下。
1)设计一种新颖的SECA机制,将通道注意力和二阶信息结合,捕捉人脸表情局部区域微小变形的同时,获取不同通道级特征间的相关信息,从而使网络提取到表达力更强的特征。
2)提出用于无约束人脸表情识别的SECA-Net,该网络可以学习到与人脸局部区域变形高度相关的表情特征,同时具有较少的参数量、较低的显存需求和计算量。SECA-Net是一个通用的框架,可以推广到类似的分类任务上。
3)在2个无约束人脸表情数据集(RAF-DB[17]和FER-2013[18])上的实验结果表明,SECA-Net具有较好的性能,是有效的。
1 相关工作
1.1 基于卷积神经网络的无约束人脸表情识别
近年来,研究者提出多种基于CNNs的无约束人脸表情识别方法并取得较好的识别结果。例如,文献[19]设计了一种基于域转移的级联网络模型,该模型首先采用自适应神经网络生成与基本表情图像相对应的中性人脸表情图像,然后从自适应神经网络的中间层提取出残差表情特征,最后利用提取出的表情特征训练多个分类器进行无约束人脸表情识别。研究表明[20],较单个网络而言,集成多个网络可以表现出更好的性能,文献[21]设计了一个双分支的网络模型用于表情识别,其中,一个分支以人脸图像为输入用来提取全局表情特征;另一个分支以LBP(local binary patterns)特征图为输入提取局部纹理特征。此外,在主干网络中添加辅助块可以使网络学习表达力更强的特征。文献[22]提出一种将CReLU(concatenated rectified linear unit)与改进的残块相结合的网络模型,该模型可以增强网络中较浅层非线性的非饱和度;同时在不降低性能的前提下,通过增加网络的深度来学习能够捕捉面部表情变化的多尺度特征。然而上述网络模型较复杂,训练中需使用额外的数据集且难以部署到其他简易平台,故本文将采用一种轻量级的特征提取网络,在不降低性能的前提下简化训练过程。
1.2 注意力机制
注意力机制使网络自适应选择图像聚焦位置,学习更易分辨的特征表示。由于一幅图像中总会存在与当前任务无关的信息,因此,注意力机制在计算机视觉领域中得到了广泛的应用。文献[23]构建了一种压缩-激励(squeeze-and-excitatio, SE)的结构单元,通过学习建模特征通道之间的依赖关系,以获取到每个通道的权重,然后利用该权重来重点学习对当前任务贡献度较高的特征。文献[24]设计出一种用于图像分割的双重注意力网络(dual attention network, DANet),DANet利用自注意力机制分别在空间和通道2个维度上建模特征依赖关系,然后融合上述2种特征进一步增强特征表示。然而上述注意力都只利用图像的一阶信息,限制了网络的学习能力;文献[25]提出一种二阶通道注意力(second-order channel attention, SOCA)模块用于图像超分辨率,SOCA使网络学习高频信息较多的特征,让其有利于超分辨率图像的重构。类似地,在无约束人脸表情识别任务中,二阶信息能够捕捉人脸局部区域的微小变形,有利于网络学习到与表情变化相关的特征。受到上述研究的启发,本文设计了一种用于无约束人脸表情识别的二阶有效通道注意力模块。
2 二阶有效通道注意力网络
本文设计的SECA-Net模型如图1所示,该模型由轻量级的特征提取网络(VoVNet-27-slim)、SECA模块和全连接层3部分组成,其中,OSA为一次性聚合(one-shot aggregation)模块。首先将人脸表情图像输入到轻量级特征提取网络中获得深层特征图;然后使用SECA模块统计深层表情特征的二阶信息,并捕获跨通道特征间的相互依赖关系,进而学习到对无约束人脸情识别任务贡献度较高的特征;最后,使用一个全连接层进行表情分类。本文采用Softmax损失和中心损失构成的联合损失函数优化模型。
2.1 VoVNet-27-slim
卷积神经网络在图像分类、目标检测和图像分割等领域运用广泛。其中,文献[11]提出的ResNet通过建立前层与后层之间的“短路连接”,从而解决深度网络性能退化的问题。为减小模型参数量和降低计算成本,文献[12]提出DenseNet,该网络的核心是每个层都会连接前面所有层的特征,实现特征重用以提升网络性能。但DenseNet的密集连接方式使每个层的输入通道数呈线性增长,这将会导致较高的内存访问成本,并占用较大的显存,使其训练速度变慢。于是,有研究者提出由OSA模块组成的VoVNet,OSA模块示意图如图2所示,该模块只在最后一层聚集前面所有层的输出特征,在降低特征冗余度的同时减少了模型参数量,并降低内存访问成本[26]。具体地,N1和N2分别表示卷积层(卷积→批归一化→非线性修正激活):Conv3×3-BN-ReLU和Conv1×1-BN-ReLU,Fcon∈Rc1×w×h表示聚集前面所有层特征的特征图映射,Fagg∈Rc×w×h表示将聚合后的特征图通过N2得到具有不同感受野的特征图。c1(c),w和h分别表示特征图的通道数、宽和高。兼顾精度和开销,SECA-Net采用VoVNet-27-slim获取人脸表情深层特征图表示,VoVNet-27-slim的具体网络组成见文献[26]中的表1。其中,每一个conv层包括的操作顺序为:卷积→批归一化→非线性修正激活,即Conv-BN-ReLU,其中未特别标注步长的地方默认步长为1,concat为通道间的特征图连接操作。将一张人脸表情图像3×90×90输入到VoVNet-27-slim网络中,最后输出512×5×5大小的特征图。
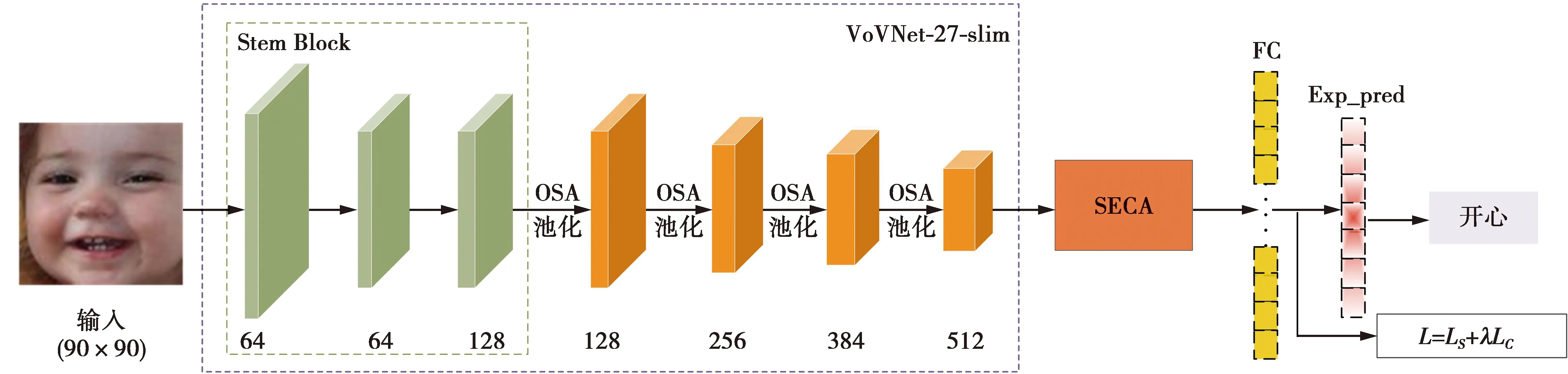
图1 基于SECA-Net的无约束人脸表情识别体系结构Fig.1 Architecture of SECA-Net for unconstrained facial expression recognition
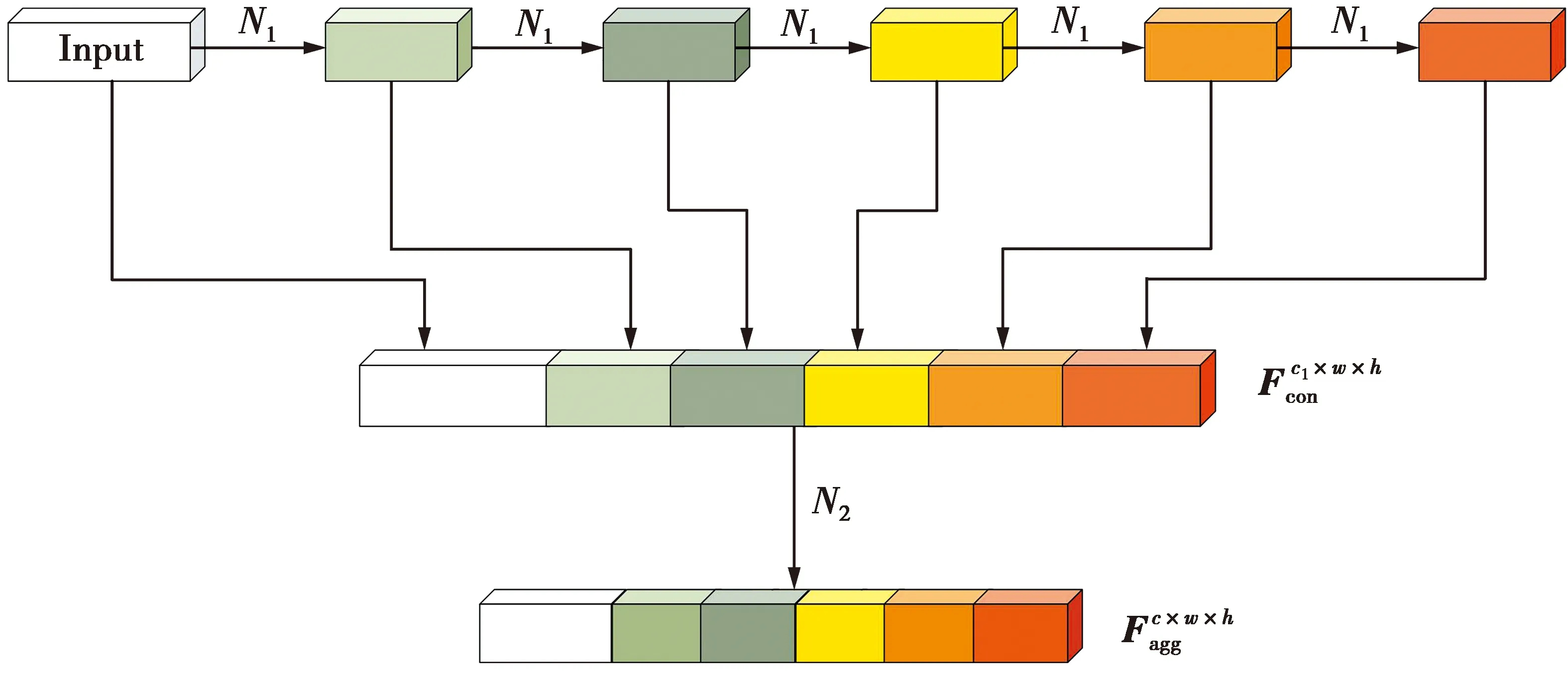
图2 OSA模块示意图Fig.2 Diagram of OSA module
2.2 二阶有效通道注意力
文献[25]基于二阶信息[19]提出一种用于图像超分辨率的二阶通道注意力(second-order channel attention,SOCA)模块,对其研究发现,SOCA中涉及到的降维操作使网络较难捕获到跨通道间的依赖关系,不利于通道注意力的预测。基于此,本文设计一个SECA,如图3所示。其中,iSQRT-COV为迭代矩阵平方根归一化方法;GCP为全局协方差池化(global convariance pooling)。SECA首先利用协方差池化层(图3中虚线框部分)统计深层特征的二阶信息,然后使用有效通道注意力捕获局部跨通道的信息交互,进而获得通道注意力向量,最后将通道注意力向量和VoVNet-21-slim输出的深层特征图进行乘积操作,输出最终的注意力特征图。
2.2.1 协方差池化层
1)协方差矩阵的计算。VoVNet-27-slim的最后一个卷积层输出大小为c×w×h的特征图。将上述大小的特征图Fagg压缩成一个m×c(m=w×h)的特征矩阵X,然后通过(1)式计算协方差矩阵S来进行二阶信息的统计(second-order statistics) ,表示为
(1)
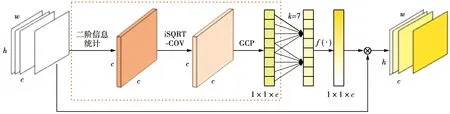
图3 二阶有效通道注意力模块图示Fig.3 Second-order effective channel attention module
2)协方差矩阵的归一化。由于文献[27]中指出协方差归一化操作可以获得判别力较强的特征,将对上述操作得到的协方差矩阵进行归一化。具体地,协方差矩阵S是一个对称的半正定矩阵,因此,可通过(2)式进行矩阵特征值分解来求解S的平方根,表示为
S=UΛUT
(2)
(2)式中:U是一个正交矩阵;Λ=diag(λ1,…,λc)是对角矩阵,其中任意λi(i=1,…,c)是矩阵S的特征值(按递减顺序排列)。然后,将协方差归一化操作转换为求解协方差矩阵S特征值的平方根,计算式为
(3)
Y2=S
(4)
然而,由于在图形处理器(graphic processing unit,GPU)上不能快速实现矩阵的特征值分解操作,故采用文献[24]中提出的iSQRT-COV方法加速协方差归一化的计算。令Y0=S,Z0=I,k=1,…,N,N代表迭代次数,然后按照牛顿-舒尔茨迭代公式[28]更新,表示为
(5)
通过一定次数的迭代,Yk和Zk将分别二次收敛于Y和Y-1。(5)式只涉及到矩阵的乘积操作,故该方法适合在GPU上并行实现。在具体实现过程中,可通过设置一定的迭代次数求得近似解,后续实验中将迭代次数N设置为5。
牛顿-舒尔茨迭代方法仅是局部收敛,可通过(6)式保证其收敛性。
(6)
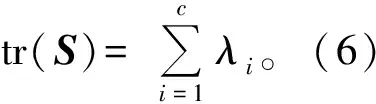
(7)
(8)
(8)式中,HGCP(·)代表全局协方差池化函数。与全局平均池化相比,全局协方差池化对网络学习到的深层特征进行二阶信息的统计,使网络能捕捉到人脸表情区域的微小变化。
2.2.2 有效通道注意力
为充分利用协方差池化层中聚合特征的相互依赖关系,SECA将采用一个门控机制,使用sigmoid函数实现一个较为简单的门控函数[29],表示为
(9)
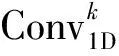
最终,由(9)式得到的注意力权重向量M和深层特征图Fagg可根据(10)式得出注意力特征图Fatt,表示为
Fatt=M⊗Fagg
(10)
(10)式中,⊗表示元素级的乘积操作。
2.3 联合损失函数
由于Softmax损失在优化类内距离上的效果不理想,SECA-Net将其和中心损失[30]联合使用来优化表情的类内距离。中心损失是通过将样本拉向该样本所属类别的类中心来减小类内距离,表示为
(11)
(11)式中,qyi∈Rc表示类别为yi(第i个样本所属类别)的类中心特征向量。最终,联合使用中心损失LC和Softmax损失LS优化网络模型,联合损失函数表示为
L=LS+λLC
(12)
(12)式中,变量λ∈[0,1]平衡2个损失。
3 实验结果及分析
3.1 数据集和实验设置
实验采用2个广泛应用于无约束人脸表情识别的数据集(RAF-DB[17]和FER-2013[18])来评估SECA-Net,其数据集图像实例如图4所示(从左到右依次为:生气、厌恶、害怕、开心、中性、悲伤、惊讶)。RAF-DB有29 672张从互联网上采集的人脸表情图像,其中,训练集和测试集分别有12 271张和3 068张人脸图像,这些图像经过人工众包标记和评估,包括6种基本表情和中性表情;FER-2013数据集中的人脸表情图像是利用谷歌图像搜索引擎下载收集的,其中,训练集有28 709张人脸图像,测试集和验证集分别有3 589张图像,该数据集的表情类别标签和RAF-DB相同。

图4 RAF-DB(第1行)和FER-2013(第2行) 数据集示例图Fig.4 Samples in RAF-DB (first row) and FER-2013 (second row)
由于RAF-DB中的人脸图像大小(100×100)和FER-2013中的人脸图像大小(48×48)不同,因此,在实验过程中将图像大小统一转换成90×90。为避免网络模型过拟合,在训练前使用数据增强进行训练样本的扩增,具体增强方法包括对图像进行随机裁剪、随机水平翻转和在(-10°,10°)内旋转。本实验采用深度学习框架Pytorch(v 1.5),服务器的配置为Ubuntu 16.04,NVIDIA 2080ti GPUs, CUDNN v 7.2, CUDA v 9.2。初始网络的学习率设置0.1,每训练30个epoch,学习率下降为原来的1/10,总共迭代90个epoch,每次迭代的批处理大小为64。训练模型时采用SGD优化算法,其中动量系数为0.9,权重衰减系数为1E-5。实验表明,参数λ取0.000 5时,本文提出的方法能取得较高的准确率。
3.2 模块分析实验
VGG[31],ResNet[11]和DenseNet[12]在表情识别中应用较多,将这3种网络与VoVNet-27-slim做进一步实验对比分析,如表1所示。从表1可知,这3种网络的模型参数量较大,且在训练时对显存的需求较高,计算量(FLOPs)较大,模型过于复杂,不太适用于训练样本数较少的人脸表情识别任务。而VoVNet-27-slim的模型参数、所需显存和计算量均远低于其他3种网络,且识别准确率最高,达到84.88%,进一步验证SECA-Net采用VoVNet-27-slim的有效性。
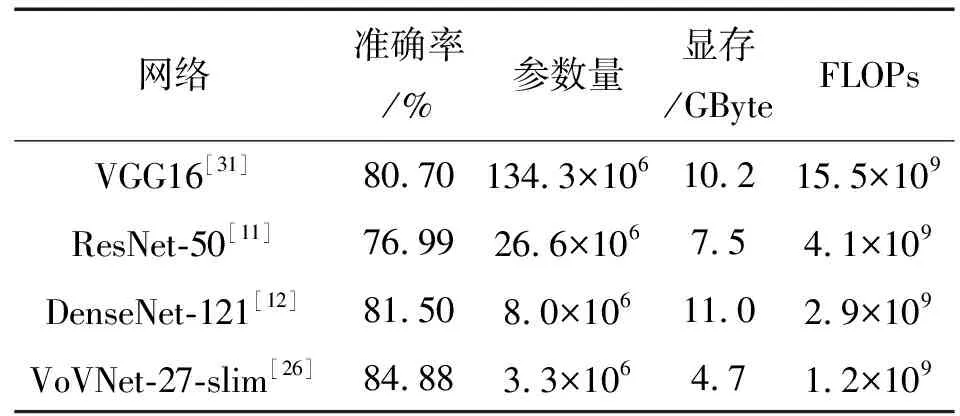
表1 不同特征提取网络在RAF-DB测试集上的性能Tab.1 Performance of different CNN architectures on the RAF-DB
为研究SECA中卷积核k的大小对表情识别准确率的影响,本实验将卷积核k的大小分别设置为3、5、7和9,在RAF-DB和FER-2013上分别做实验,结果如图5所示。从图5观察可得,对于RAF-DB,随着k值的增大,准确率先增高后降低;而对于FER-2013,随着k值的增大,准确率先降低后增高,然后再降低,这是因为FER-2013数据图像分辨率低且为灰度图像,一些细节信息很难被模型提取到。具体地,当k值较小时,表明参与到一个通道注意力预测的邻居特征点就越少,即模型很少利用到特征间的相关信息来进行通道注意力权重的学习;而当k值较大时,则意味着参与到一个通道注意力预测的邻居特征点就越多,此时干扰信息也较多,不利于模型通道注意力权重的学习;当k=7时,SECA模块的效果最好。因此,在后续试验中将k的大小设置为7。
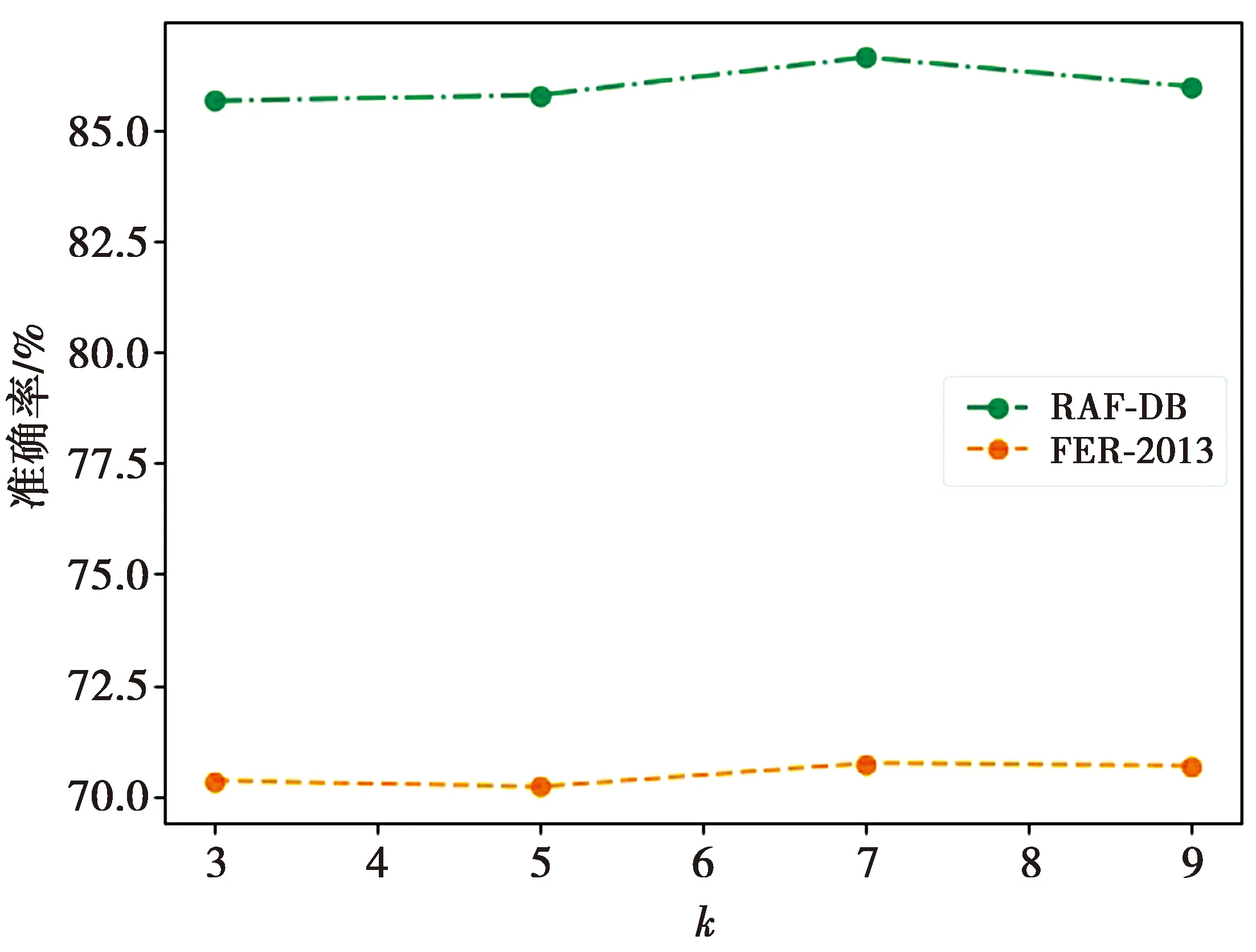
图5 k的大小对模型识别准确率的影响Fig.5 Effect of the model identificated accuracy with various number of k
SECA可以捕捉面部局部区域的微小变化,同时增强局部跨通道的特征交互能力。为从数据层面客观验证SECA对无约束人脸表情识别的有效性,在SECA-Net模型中将SECA替换为4种常用注意力模块(SE(second-order)[23],DANet[24],ECA(efficient channel attention)[29],SOCA[25]),然后在RAF-DB上做相同设置的实验,分别训练模型,对得到的识别准确率进行对比分析,如表2所示。表2中基于一阶信息的注意力模块(SE、DANet、ECA)和基于二阶信息的注意力模块(SOCA、SECA)的数据对比可知,对深层特征进行二阶信息的统计,将会提高人脸表情识别方法的准确率。此外,在基于一阶信息的3种注意力模块(SE、DANet、ECA)中,通道注意力(SE、ECA)更有利于无约束人脸表情识别,因为在网络较深层已学习到人脸图像的轮廓信息,更需要统计通道特征间的相关性。最后,在基于二阶注意力的SOCA和SECA中,SECA准确率高于SOCA,进一步验证SECA在无约束人脸表情识别中的优越性。
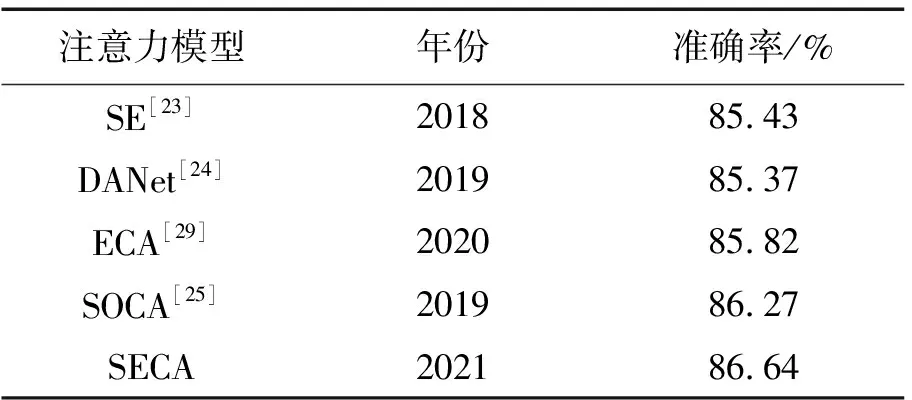
表2 不同注意力模块在RAF-DB测试集上的实验对比Tab.2 Comparison of different attention modules on the RAF-DB
为从图像层面直观解释SECA的优势,将上述实验训练的5种模型进行可视化表示,如图6所示。

图6 不同注意力模块在RAF-DB上的注意力可视化图Fig.6 Visualization diagrams of different attention modules on the RAF-DB
图6a是数据集RAF-DB中的原始表情图像,图6b—图6d是基于一阶信息的注意力可视化图,可看出这3种注意力会聚焦一些与表情特征无关的区域,图6e—图6f是基于二阶信息的注意力可视化图,可见,基于二阶信息的注意力更关注人脸表情特征区域的微小变形。同时,对比图6e—图6f可知,SOCA虽然能够捕捉到表情区域的微小变化,但它忽略了一些与表情高度相关的人脸组件,而SECA正好弥补了SOCA的不足,学习到表达能力更强的表情特征。
3.3 对比实验结果
为验证SECA-Net对无约束人脸表情识别的有效性,将其与近几年4种典型的无约束人脸表情识别方法进行对比分析,如表3所示。从表3可知,SECA-Net在数据集RAF-DB和FER-2013上的识别准确率都高于其他4种方法。此外,由于现有表情数据集的数据量较小,若设计的网络模型参数量较大,则会导致模型过拟合,故本实验列出模型参数量的大小。显然,SECA-Net的模型参数量为3.6×106,远低于文献[14,17,33]中的模型参数量,虽然文献[32]中的模型参数量最小,但它的识别准确率远低于其他几种方法。在评估网络模型时,内存占用也是一个重要的评估指标,较高的内存需求将会限制模型的使用设备,故本实验中还列出每种模型训练时所占用的GPU显存,可以看出,SECA-Net所占显存为3.1 GByte,而文献[33]中的GCN所需显存最低,仅需1.8 GByte,但SECA-Net所占显存远低于剩余的其他3种方法,且准确率在5种方法中最高。
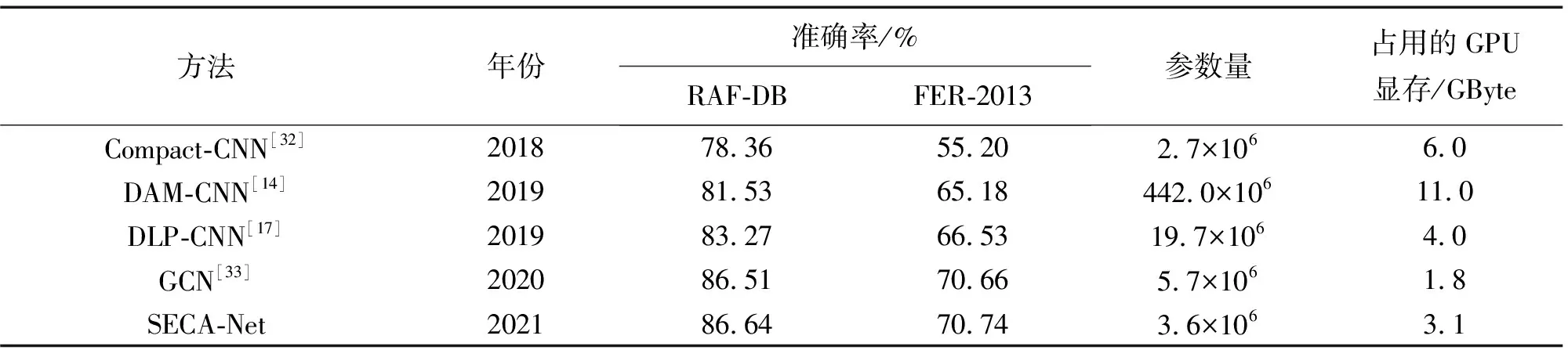
表3 不同先进方法在RAF-DB和FER-2013测试集上的性能Tab.3 Performance of different methods on the RAF-DB and the FER-2013
为进一步分析SECA-Net模型的性能,实验还绘制了SECA-Net模型在2个数据集上训练过程中的损失变化曲线图,如图7所示。train和test分别是2个数据集中的训练集和测试集,横坐标表示训练的迭代次数epoch,纵坐标表示模型的损失值。从图7可看出,SECA-Net模型在训练60个epoch左右时其损失值基本趋于稳定,即达到收敛状态,收敛速度较快。此外,训练集和测试集的损失曲线图始终较为接近,即模型训练状态稳定且没有出现过拟合现象。
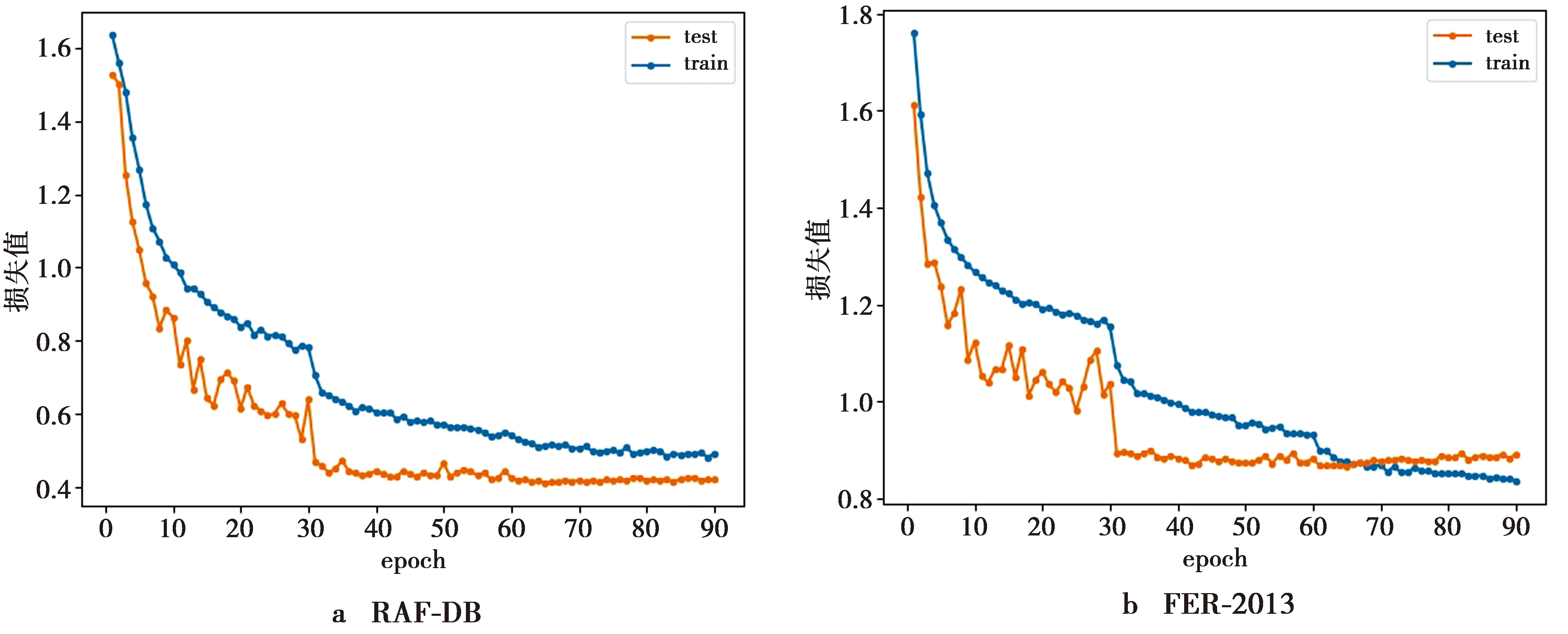
图7 SECA-Net损失值变化曲线图Fig.7 Loss change curve of SECA-Net
为研究SECA-Net在2个数据集中每类表情的分类性能,本实验报告了混淆矩阵,如图8所示。从图8a可看出,RAF-DB上的厌恶和害怕这2种表情的识别准确率略低,因为在训练样本中厌恶和害怕这2种表情的样本数较少;从图8b可看出,FER-2013数据集中除开心和惊讶这2种表情的识别准确率较高以外,其他几种表情的识别准确率较低,主要是因为该数据集中的图片是灰度图且分辨率较低,缺少一些图像细节信息,不利于网络模型的细节特征提取。此外,厌恶易被误识别为生气,害怕易被误识别为惊讶,因为这几种表情本身的面部表情局部区域(眼睛和嘴巴)变化极为相似,所以在表情识别过程中较难识别这几种表情,容易混淆。数据集的数据分布图如图9所示。图9a中,RAF-DB训练集数据中开心表情的样本数最多,使其识别准确率最高;图9b中,FER-2013训练集的数据分布图中除厌恶表情的样本数很少之外,其他几种表情的样本分布较为均衡,这一点可在混淆矩阵图8b中得以体现,因为厌恶表情的样本数较少,所以导致网络模型提取相关特征不充足,进而使得该表情识别准确率最低。
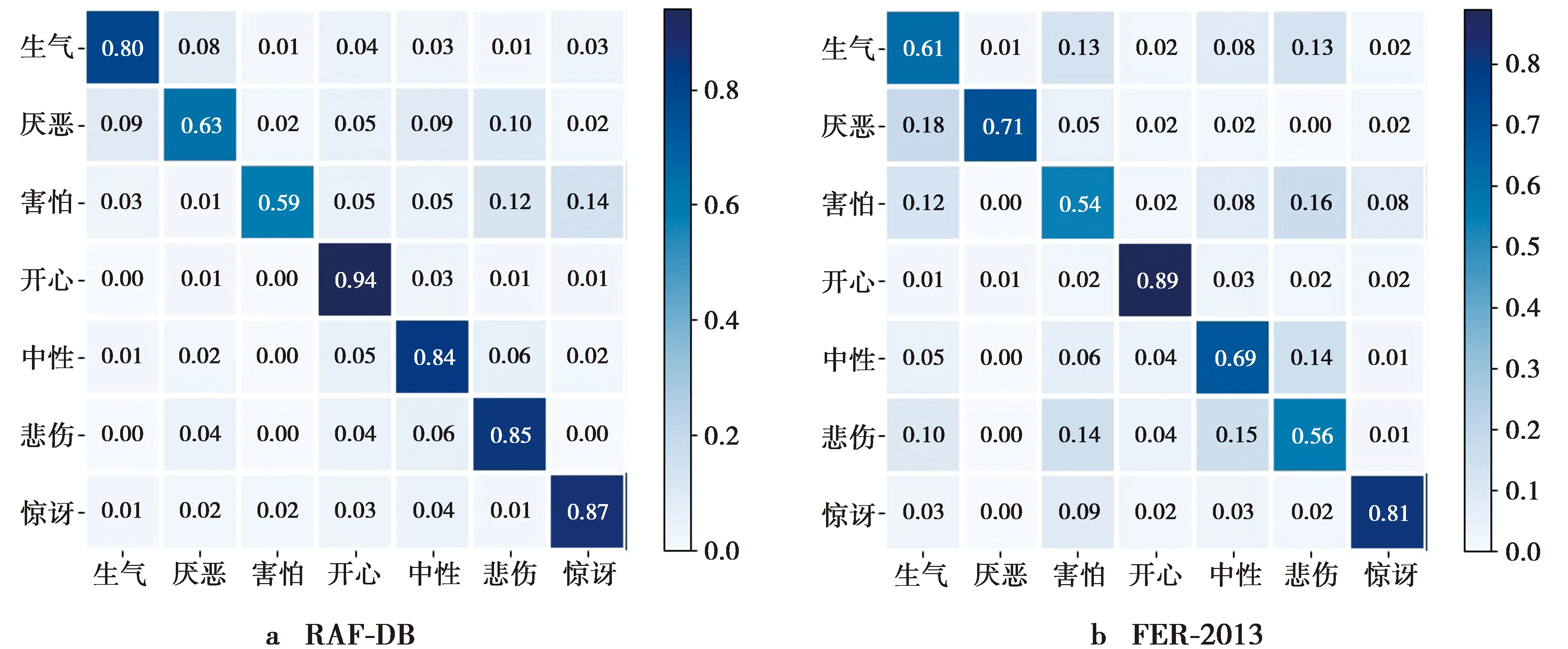
图8 混淆矩阵Fig.8 Confusion matrix
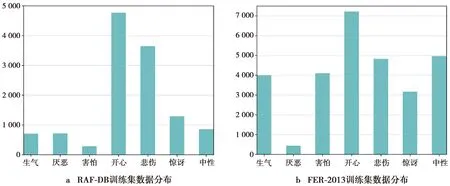
图9 数据集的数据分布图Fig.9 Data distribution of the dataset
3.4 消融实验
SECA-Net由多个子模块组成,为验证每个子模块对模型识别最终性能的有效性,本文对每个子模块在人脸表情数据集上做了实验且对其进行分析和讨论,如表4所示。首先,使用轻量级网络VoVNet-27-slim获取人脸表情图像特征的深层表示;然后,将Softmax损失替换为由Softmax和中心(Center)损失组成的联合损失函数,使用联合损失函数来优化表情的类间和类内距离;最后,在VoVNet-27-slim网络末端加入本文提出的SECA模块以提取人脸表情微小变形区域的纹理特征。

表4 子模块在RAF-DB测试集上的性能分析Tab.4 Component analysis on the RAF-DB %
4 结束语
本文设计了一种新颖的SECA,并联合轻量级网络VoVNet-21-slim构造了一种用于无约束人脸表情识别的网络(SECA-Net)。SECA-Net首先采用VoVNet-27-slim提取人脸表情深层特征,然后使用SECA模块统计深层表情特征的二阶信息并捕获跨通道特征间的相互依赖关系。SECA-Net能够学习人脸表情微小变化的局部区域特征,并统计表情特征图通道间的相关信息,进而学习到对无约束人脸表情识别任务贡献度较高的特征。在2个著名的无约束人脸表情数据集RAF-DB和FER-2013上的实验表明,相较于近年几种先进的无约束人脸表情识别方法,SECA-Net在识别准确率、模型参数量和显存需求上是具有竞争力的。此外,SECA-Net也是一个通用的框架,可以推广到类似的分类任务上。
