国内外科学数据管理FAIR 原则研究进展及应用综述
2022-10-26陈书贤刘桂锋
陈书贤,刘桂锋,刘 琼
(江苏大学科技信息研究所,镇江 212013)
1 引言
从21 世纪初萌芽的开放获取到如今大热的开放数据和开放科学,以知识共享为特征的开放运动在多领域纵深发展,开放的概念已经深入人心[1]。在开放数据的大背景下,科学研究进入了第四范式,数据密集型时代随之到来,科学数据的共享也成为全球的共识,科学数据的开放共享及管理逐渐成为开放科学建设的核心[2]。为解决科研数据领域的数据开放问题,FAIR原则于2014 年在荷兰莱顿的洛伦兹研讨会上被首次提出,随后由FORCE11 工作组于2016 年正式发布。同年,Scientific Data 杂志发表了 《科学数据管理的FAIR指导原则》[3],探讨了FAIR 原则的具体内容,此后FAIR 原则逐渐受到科学研究领域,尤其是科学数据管理和开放共享领域的广泛关注和研究,并逐渐向其他领域和行业过渡。FAIR 原则意为Findable(可发现)、Accessible(可访问)、Interoperable(可互操作)和Reusable(可重用),由4 个维度的15 条细则构成,为数据管理过程提供了指导要素,提高了研究的透明度,助力于数据的开放共享。目前国内对FAIR 原则的研究相对较少,主要集中在FAIR 原则的研究与实践进展[4]、FAIR 原则在国外生物信息学[5]和循证医学方面的应用实践[6]、欧盟推进FAIR 原则的经验[7,8]等方面,除此以外,有学者通过提炼出FAIR 政策的13 个要素,结合中国 《科学数据管理办法》,为中国的科学数据管理提供了实质性的依据[9],还有学者分析了中国应用FAIR原则的案例,为其他科学数据平台落实FAIR 原则提供了实践借鉴意义[10]。到目前为止,FAIR 原则的相关研究引起了诸多国内外学者的研究兴趣,产生了大量理论研究成果和实践探索成果,尚未有学者对国内外相关研究成果进行全面、深入、系统的总结与梳理。本文旨在全面梳理FAIR 原则的实施策略、评估方法和工作流程,以及在国内外各领域中的最新进展和应用情况,以期为中国科学数据的开放和管理提供借鉴和参考。
2 FAIR 原则实施的组织保障
FAIR 原则从理论的提出到最终实施,必然经历一个曲折而漫长的过程,或许存在许多问题,需要不断的进行探索和改进,以科学研究数据全球联盟(下文简称RDA)、GO FAIR、CODATA 为主的组织机构是促进FAIR 原则实施的主要保障。RDA 和Force11 之间根据具体案例而开展联合,向用户、数据生产商和数据政策进行推荐,并帮助最终用户提供具体使用的标准、描述等;GO FAIR 则是促进和协调FAIR 数据和服务互联网的连贯发展;CODATA 支持在FAIR 数据原则下,采取适当措施促进开放数据和开放科学。
2.1 研究数据联盟
科学研究数据全球联盟(RDA)于2013 年由欧盟委员会、美国政府国家科学基金会和国家标准与技术研究所以及澳大利亚政府创新部共同发起[11],是一项由社区驱动的倡议,其目标是建立社会和技术基础设施,以实现数据的公开共享和再利用。
RDA 关注整个数据生命周期,鼓励数据生产者、用户和监管人员的加入,解决数据交换、处理和存储问题[12]。开放科学被视为推动科学进步和造福社会的重要组成部分,而研究数据的共享是这些目标的核心。RDA 满足了对开放和可互操作的研究数据共享的需求,并建立了社会、技术和跨学科的联系,以实现全球范围内的共享。RDA 成员通过重点工作组(WG)和兴趣小组(IG)开展工作,这些工作组和兴趣小组由来自世界各地的学术界、私营部门和政府的专家组成。任何赞同RDA 开放性、包容性和协调性指导原则的人都可以加入其中。
2.2 GO FAIR
GO FAIR 是一个自下而上的,由利益相关者发起的倡议[13],于2017 年底启动,旨在实施FAIR 数据原则,使数据Findable(可发现)、Accessible(可访问)、Interoperable(可互操作)和Reusable(可重用)。在荷兰、德国和法国政府的支持下,成立了GO FAIR 国际支持与协调办公室。GO FAIR 通过建立网络(INs),向个人、机构和组织提供一个开放和包容的生态系统,其三大支撑支柱如表1 所示[14],愿景、使命及战略如表2 所示[15]。

表1 GO FAIR 三大支撑支柱Table 1 Three pillars of GO FAIR
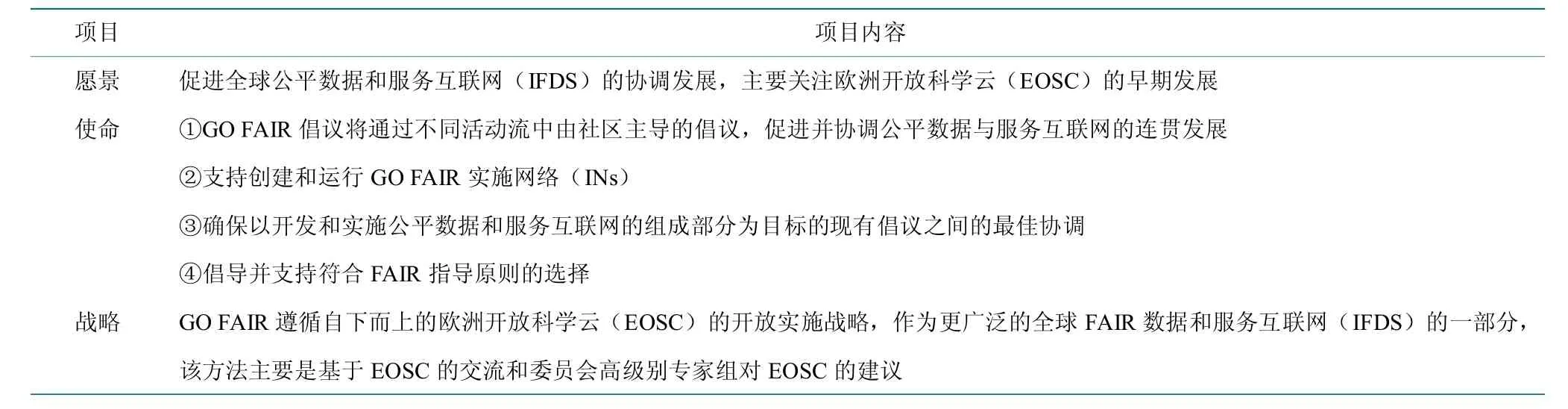
表2 GO FAIR 愿景、使命及战略Table 2 The vision,mission and strategy of GO FAIR
2.3 CODATA
国际数据委员会(以下简称CODATA),作为国际科学理事会(ISC)的数据委员会,CODATA 助力ISC 实现把科学作为全球公共利益产品并加以推进的愿景[16]。其目标是通过促进国际合作来推动开放科学,提高所有研究领域数据的可用性和实用性。CODATA 支持这样一个原则,由研究产生的和可能用于研究的数据应尽可能地开放,并在必要时尽可能地封闭。CODATA还致力于提高科研数据的互操作性和可用性,即研究数据应该是符合FAIR(可发现、可访问、可互操作和可重用)原则的。
3 FAIR 的4 个基本原则
技术的进步使科学数据更加密集且相互关联,研究人员在不断生产科学数据的同时更强调使数据FAIR化。FAIR 原则作为数据管理的指南,满足了对机器可操作数据的需求,并适用于各种利益相关者群体,包括数据生产者、数据供应商和数据管理员等[3]。最初的FAIR 原则包括15 条基本细则,这些细则主要围绕可发现、可访问、可互操作和可重用这4 个基本原则,4个原则各有偏重,以满足潜在重用者对数据发现和后续评估的需求。
3.1 Findable 可发现
Findable 可发现是实现数据共享和重用的前提,科学数据及其元数据都应易被人和计算机发现,且机器可读元数据对于自动发现数据集和服务至关重要。FAIR 数据拥有持久、唯一、可识别的标识符,能在网页上解析并与一系列描述性元数据相关联,极大降低了查找数据的难度[17]。拥有持久性标识符且机器可操作的元数据是实现FAIR 原则可发现的关键要素,在此基础上提升机器的自动化查找功能有利于缩短数字基础设施和服务的工作流程,从而更好地实现数据的重用[18]。在FAIR 科学中,数据及相关工具都是可发现的,在定义明确的条件下可访问,可互操作且可重用。基于这样的出发点,欧洲开放科学云专家组指出了建立互联网数据和服务公平(IFDS)体系的必要性[19],即在虚拟空间中,机器和用户彼此可发现、可访问、可互操作,从而在受信任的网络环境中重用彼此的研究成果。
3.2 Accessible 可访问
Accessible 可访问是实现数据共享和重用的基本条件,一旦用户找到他们所需的数据,接下来的重点是他们需要知道如何访问这些数据。例如,在健康数据的可访问层面,2018 年5 月生效的欧洲 《通用数据保护条例》(GDPR)从FAIR 原则的可访问条件出发,制定了保障数据访问时涉及的隐私权、道德和监管问题的相关条例,强调将个人权利纳入FAIR 原则的组成中,从而实现对数据的负责任访问和使用[20]。另有研究主张使用本体来细粒度和安全地访问FAIR 数据,并提出了基于本体的数据访问策略(OBAC)[21],利用领域本体的概念和关系进行数据访问控制,并根据用户的角色确定用户是否有权访问数据,同时与保护隐私的数据访问策略相协调。上述研究表明,对可访问这一维度的研究正在从理论逐渐向实践过渡,研究界已然开始关注并致力于解决伴随数据访问而产生的种种问题。
3.3 Interoperable 可互操作
Interoperable 可互操作是实现数据共享和重用的重要桥梁,旨在解决数据在分析、存储和处理的应用过程中与其他数据之间的集成融合,最终目的是最大化信息产品的附加值。可互操作强调人类和机器之间对现有数据的交换和解释,也重视机器对不同系统间数据的可读性与识别,该过程涉及机器通用的词汇表、标识符、本体等。“可互操作” 曾经被认为是科学数据公平化过程的瓶颈,随着研究的深入,学者们发现本体是实现科学数据 “可互操作” 的重要前提[36]。国外学者[22]从本体和本体论层面出发提出了语义互操作性的概念,讨论了信息集成和信息系统互操作的重要性,强调形式本体论和基于形式本体论原则在信息系统中的语义表达作用,以解决访问数据集以及数据格式化问题。FAIR 的可互操作原则在本体一致的信息结构支持下能更好的实现,基于本体的语义互操作理论也拓宽了系统间互操作的可能性。
3.4 Reusable 可重用
Reusable 可重用原则是实现数据重用的最终目标,科学数据及其元数据应该得到很好的描述,以便可以在不同的操作环境中进行复制或组合。数据重用允许其他人验证结果、重复实验,并在此基础上开展新的研究[23],以实现有效和高效的开放科学。FAIR 原则中列出的元素编纂了每个数据集需要在(元)数据本身中提供的必要细节,以满足潜在重用者对数据发现和后续评估的需求。例如,有学者对地球科学领域的22名研究人员进行了重用数据的信息行为实验,从而发现他们如何发现和评估数据以供重用的过程[24]。多数情况下,数据共享是实现数据重用的前提,由于受到数据库、数据集等的访问许可证和版权保护的限制,需要从法律层面寻求保障数据开放的可能性,从而许可FAIR 数据以供重用[25]。
4 FAIR 原则的实践探索
FAIR 原则成立之初,仅为实现数据的可发现、可访问、可互操作以及可重用提供了指导方针,但没有制定关于每条细则的具体实施方案,也并未提出评估数据FAIR 化程度的一致标准。因此,学术界、科学团体、各类组织和社区等积极探索FAIR 原则的实践方案,开发了支持FAIR 原则的各种工具,制定了用以评估数据FAIRness 的指标,梳理了数据FAIR 化的流程,为未来实施FAIR 原则的社区和组织提供了实践路径。
4.1 实施FAIR 原则的策略方法
为了促进FAIR 原则的落实和推广,FAIRsharing将标准、数据库、存储库及数据策略的生产者和消费者紧密地联系在一起,一方面指导数据消费者发现、选择和使用其所需的资源;另一方面帮助数据生产者的资源易被发现并得到广泛的使用[26]。FAIRsharing 是由社区驱动的数据资源平台,汇集了众多的利益相关者群体,针对不同的利益相关者群体,FAIRsharing 制定了不同的FAIR 原则实施策略[27],助其实现数据FAIR 化,提高标准、数据库和存储库的可发现和重用,具体措施详见表3。

表3 利益相关者实施FAIR 原则的策略Table 3 Stakeholder strategies for implementing the FAIR principles
FAIR 不仅在学术界异常活跃,而且随着实践的深入已逐渐扩展到其他领域,如工业界已经提出了开展FAIR 原则以消除 “数据孤岛” 的迫切需求[28]。同时,对FAIR 的数据管理也日益引起重视,基金资助组织将数据管理计划纳入研究资助周期,要求研究人员提供可重用的研究成果,FAIR 资助模式的提出亦加速了向数据管理实践的过渡[29]。
4.2 FAIR 数据的模型开发和评估方法
FAIR 原则发布以前,许多社区和组织就有了一套实现数据FAIR 化的实践标准,如何在社区间达成广泛一致的FAIR 实施方案成为一道难题。为了整合已有的FAIR 实践方案,从现有方案中寻找实现数据重用的最佳途径,GO FAIR 倡议构建了FAIR 融合矩阵[30]。矩阵将实施FAIR 原则的社区汇集在一起,并列出各个社区已有的FAIR 数据资源、技术、项目和实践方案等,社区之间可以互相借鉴和采纳,形成一套通用的、跨学科领域的实施标准。
对于采用FAIR 原则的不同利益相关者而言,评估资源的FAIRness 水平已成为新的考究。通过评估现有资源遵循FAIR 原则的程度可以确定资源是否达到初始目标,进而拟定改进措施或制定下一步实施方案。目前,已有组织制定了评估FAIRness 的框架和标准,如FAIR Metrics Group 制定了评估FAIRness 成熟度的14条通用指标,并以开放问卷的方式发布供各类群体进行自我评估[31];研究数据联盟(RDA)成立了FAIR 数据成熟度模型工作组,制定了一套用于数据评估的通用指标[32],并发表在RDA 建议书中;FAIRsFAIR 项目通过实际应用,在RDA 指标的基础上进行了修改和调整,增加了评估细节,建立了FAIRsFAIR 指标,开发了新的FAIRness 评估工具[33]。还有学者分析了基于调查问卷的FAIRness 自主评估方法和基于WEB 元数据收集器的半自动化FAIRness 评估方法[34],阐明了不同方法的优缺点及使用时的注意事项,为不同领域的研究人员选择合适的评估方法指明了方向。
4.3 FAIR 数据工作流程
FAIR 评估指标的发布及FAIR 工具的开发[35]都促进了数据FAIRization 的过程,与此同时,FAIR 化工作流程应运而生并覆盖了FAIR 原则的方方面面,该流程共包括7 个步骤[36]:①确定FAIRization 目标;②分析数据;③分析元数据;④定义数据(4a)和元数据(4b)的语义模型;⑤使数据(5a)和元数据(5b)可链接;⑥托管FAIR 数据;⑦评估FAIR 数据。每个步骤都以FAIR 原则为依据,旨在提高数据的FAIR 化水平。该工作流程适用于各个领域,目的是使数据FAIR化变得更容易,然而,数据流程的实施缺乏一定的管理,需要得到组织、机构或其他利益相关者的决策支持。
与上述FAIR 化流程不同,依赖于机器处理数据的计算工作流程逐渐趋于自动化,经过数据收集、数据准备、数据分析、预测建模和模拟等步骤[37],将FAIR原则融入到计算工作流中,促进了对数据质量的评估,并产生了新的数据,提高了数据的标准化和可重用。
5 FAIR 原则的学科应用
目前FAIR 原则已在医学、生物多样性科学、地理科学和化学等学科领域得到了采纳与应用,且存在跨学科交叉的现象。其中研究者们对医学、生物多样性科学与其他学科的交叉探索最早且相对深入,已形成了较为系统的成果及科学数据共享实践项目,其他学科的研究尚在摸索阶段。
(1)在医学领域的应用。FAIR 原则在医学领域的应用主要涉及循证医学、生物医学和临床医学等。为了建立高质量的、结构化的循证医学数据库,实现循证医学的人工智能化,国内学者依据FAIR 原则进行循证医学本体的构建,以实现医学知识的快速迭代[6]。面对生物医学领域数据庞大、数据质量低且数据难以共享的难题,有关学者提出了建立跨学科领域的科学数据指导原则,完善相应的数据评价标准和管理流程的建议[38]。在临床医学层面,国内学者梳理了中国临床研究数据管理的发展历程,对比了国内外临床研究数据共享的差异性,提出以FAIR 原则指导临床研究数据管理与共享的实践[39];而国外学者[40]则讨论了将临床试验生物标志物数据FAIR 化而开发的自下而上的数据集成方法,即将现有临床试验生物标志物数据依据FAIR原则进行半自动化处理,构建生物医学的基础设施和标准体系,以促进数据FAIR 化,优化数据的管理工作。
(2)在交叉学科领域的应用。交叉学科主要涉及生物多样性科学、地理科学及化学领域。生物多样性研究界通过建立如全球生物多样性信息设施(GBIF)、自然历史馆藏保护协会(SPNHC)等致力于在国际上实现数据的公开共享和再利用。RDA 也成立了生物多样性研究工作组,助力研究人员和创新者公开分享跨学科和技术的国家生物多样性数据,以应对社会的重大挑战[41]。生物多样性科学和地理科学是FAIR 原则在学科领域应用中的交叉点之一。随着生物多样性科学和地球科学的不断发展,产生了数以亿计的实物资源(标本、化石等),以数字化的方式处理这些资源——使其转化为 “数字标本” 和 “数字藏品”,并建立相应的数据库,与其他领域的数据相关联,能实现信息的无缝统一访问[42]。基于此,分布式科学馆藏系统(DISSCO)应运而生,其技术愿景是创建无缝虚拟馆藏[43],具体内容如表4 所示。

表4 DISSCO 项目的具体内容Table 4 Details of the DISSCO project
地理科学不仅与生物多样性科学产生了跨学科发展的趋势,与化学界也产生了诸多交叉。国际纯粹化学与应用化学联合会(IUPAC)和美国地球物理联盟(AGU)为了解决科学数据共享中遇到的难题,进行了一系列合作与探索[44],具体措施如表5 所示。

表5 IUPAC 与AGU 的实践与合作Table 5 Practice and cooperation between IUPAC and AGU
交叉学科意味着建立跨越学科视角的统一知识框架,用综合的方法整合来自不同学科的数据知识,实现数据在学科领域间的流通和互操作。
(3)在其他学科领域的应用。RDA 积极成立兴趣工作组以支持多学科领域内的数据共享,推进FAIR 原则的采用。就农业领域而言,农业数据对国家和全球的可持续发展日益重要,RDA 成立农业数据兴趣小组(IGAD),旨在促进农业领域数据共享政策和数据管理计划的制定,提高数据的互操作性[49]。目前,该小组制定的数据框架已被EMBL 欧洲生物信息学研究所、慕尼黑蛋白质序列信息中心(MIPS)等组织采用;在语言学领域,语言学数据兴趣小组(LDIG)重点关注语言学中可重复研究的问题[50];在社会科学领域,RDA也成立相关兴趣小组研究数据管理工作,COVID-19 数据共享建议、元数据标准目录的创建等成为社会科学人员研究的热点问题[51]。
6 FAIR 原则的区域应用
FAIR 原则在2014 年首次提出后,受到了世界范围内的广泛关注,最具代表性的是欧洲,其中欧盟是在开放科学战略中最早全面采纳FAIR 原则并取得显著成效的机构之一,相比之下,FAIR 原则在非洲的实施相对滞后,但也初具成效。南美洲以巴西为代表,近年来也积极响应国际GO FAIR 倡议,从国家政策到基础设施自上而下开展了FAIR 运动。亚洲以日本相对较早地重视开放科学,通过制定科学技术基础规划、建立科技关联开放数据库等举措推动研究数据的开放共享,在科学技术振兴机构JST 的科学政策保障下,FAIR原则在日本也得以推行[52]。与此同时,由学术出版和学术资源联盟(SPARC)发起的开放获取周(OA Week)活动聚集了美国、英国、澳大利亚等国家,推动开放获取向开放科学转变,促进了科学数据在国际间的共享交流[53]。本节重点讨论FAIR 原则在欧洲、亚洲和南美洲的应用和实施进展。
6.1 FAIR 原则在欧洲的应用
欧盟先后出台地平线2020 计划(Horizon 2020)、欧洲地平线计划(Horizon Europe)及欧洲开放科学云计划(EOSCI)来推动欧洲开放科学的建设。其中,科研基础设施(RI)的建设是尤为重要的一环,此前尚未有学者展开讨论。欧洲于2002 年成立了欧洲科研基础设施战略论坛(ESFRI),为科研基础设施制定可持续发展战略和愿景,确保欧洲科研基础设施在科学创新领域的先进性[54]。ESFRI 自2006 年起发布科研基础设施路线图,并在2018 年的路线图中首次讨论了开放式科学的构建及开放式数据管理等问题,欧洲理事会在科研基础设施的建设中引入FAIR 原则,助力科学资源的开放获取[55]。在FAIR 原则未正式提出以前,一些代表性的分布式科研基础设施在自身的发展建设中就已经具备了FAIR 原则的特点[56]:①通用语言资源和技术基础设施(CLARIN ERIC),其建立初衷就是为了克服语言资源领域的碎片化,使数据和工具更易于查找、可访问和可重用;②生物银行和生物分子资源研究基础设施(BBMRI-ERIC),制定标准以实现生物银行领域相关的API 和数据模型的标准化;③欧洲板块观测系统(EPOS)推进开放标准,并在必要时与欧洲和全球的其他地球科学倡议合作开发新的标准,以解决数据共享和互操作性问题;④综合碳观测系统(ICOS ERIC),在其服务清单中为元数据存储中描述的任意数字对象提供动态登录页,提高了数据的可访问性。FAIR 原则的出现和广泛采用印证了上述基础设施从建立之初到发展至今的开创性努力,越来越多的科研基础设施也遵循FAIR 原则探寻跨学科间的资源共享。
最新发布的2021 路线图将2019 年启动的5 个集群项目纳入其中,分别是面向环境研究的ENVRI-FAIR、面向生命科学的EOSC-Life、面向天文学与粒子物理的ESCAPE、面向多领域科学分析的PaNOSC 和面向人文科学的SSHOC[57],这些项目旨在建立ESFRI 科研基础设施和欧洲开放科学云(EOSC)之间的联系,创建一个开放的、数字的、协作的空间来管理和整合各种数据和元数据。国家层面如德国建立了通用科研数据基础设施GeRDI[58],法国也为推动开放科学建立了完善的开放科学基础设施体系[59]。
然而,为进一步巩固欧洲RI 的格局,许多方面仍有待改进。例如,需要建立一个符合FAIR 原则的可互操作的数据系统,且该系统能集成到一个运行良好的EOSC 生态系统中,以满足欧洲研究界的需求。在基础设施运营层面,仍需进一步加强科研基础设施之间的合作,探索各科研基础设施之间的协同作用,实现RI间的资源共享。
6.2 FAIR 原则在非洲的应用
相比于欧洲和美洲,非洲在FAIR 原则的实施层面存在滞后性[60]。东非共同体意识到加强数据重用的必要性后,将FAIR 原则作为推动数据共享和设计数字工具的准则,并建立了东非健康开放科学云(EAOSCH),该组织作为一个实时的区域数据仓库,用于捕获、存储、检索、分析和管理国家及区域的健康问题[61]。此外,非洲参与了GO-FAIR 实施网络(IN Africa)的建设,IN Africa 作为一个开放网络,致力于分享来自非洲和世界各地机构及研究人员的成果[62]。尽管在推行FAIR 原则的进程中有诸多进展,但非洲的数字卫生倡议在知识共享方面的基础有限,且铺开面较窄,面临着后续可持续性发展问题。
6.3 FAIR 原则在南美洲的应用
南美洲以巴西为实施FAIR 原则的典范,巴西响应国际GO FAIR 倡议,搭建支撑FAIR 数据和服务的全球互联网(IFDS),共享全球环境数据驱动的研究和创新[63];政策上,巴西政府颁布 《信息公开法》,加强信息公开和政府数据公开[64];在开放数据研究层面,巴西于2011 年制定了 《国家开放政府行动计划》[65],后经巴西科学技术信息研究所(IBICT)正式发布了《GO FAIR 巴西宣言》,关注科学和政府数据的获取[66];巴西国际博览会成为概念建模、本体论和公平数据元数据管理研讨会的共同组织者之一[67];GO FAIR 巴西社区实施的第一个主题网络是GO FAIR Health,该网络已经在公共卫生、健康监测、健康信息与交流、以及专业健康教育等领域得到了多个机构的支持和参与。
7 总结与展望
FAIR 原则由理论提出到实践应用需要多方共同努力。国外的RDA、GO FAIR 和CODATA 等组织为推进FAIR 原则,助力数据的开放共享出台了一系列措施,取得了一系列成果,包括建立较为完善的实施FAIR 原则的策略、较为成熟的FAIR 评估模型和方法、较为稳定的FAIR 工作流程等,在欧美国家的医学、生物科学、地理科学和化学等领域已经建立了基于FAIR原则的数据开放管理项目。国内对于FAIR 原则的研究和应用较为落后,正逐步由理论探索过渡到实践研究阶段。FAIR 原则需要融入到数据政策的制定、内容和实施等全流程中,为科学数据的再利用起到规范和指导作用。在科学数据管理政策的最新进展中,目前国内仍缺乏国家层面对于开展FAIR 原则的政策支持,相应的研究组织也亟待成立,对FAIR 原则的采纳和实施也尚未建立统一的标准和共识。因此,中国应积极将FAIR 原则纳入相关数据管理政策的制定和修改中,鼓励学术界、相关组织、数据平台等遵循并推广FAIR 原则,将其作为数据分享和管理的统一指南,打破数据壁垒,使数据更加开放。
