基于异构图神经网络的检务知识咨询业务分类
2022-10-24蔡惠民印忠文岳世彬
蔡惠民,印忠文,岳世彬
(1.中电科大数据研究院有限公司,贵州 贵阳 550022; 2.提升政府治理能力大数据应用技术国家工程实验室,贵州 贵阳 550022)
0 引 言
2017年以来,最高人民检察院先后出台了《关于深化智慧检务建设的意见》、《全国检察机关智慧检务行动指南2018-2020年》等重要文件,为打造智慧检务明确了发展方向。智慧检务是指运用大数据、人工智能等新兴技术,通过对司法数据的有机整合与智能分析,挖掘数据的潜在价值,使其服务于司法应用,推动更高形式的检察信息化建设,对于辅助科学决策、提升办案效能、规范司法办案、推进司法改革等有重要意义[1-2]。
随着大数据时代的到来,检务大数据的积累为进一步推进智慧检务建设奠定了坚实基础。检答网是检察人员内部业务研讨交流平台。其作为检务信息化建设的重要组成部分,多年来积累了大量用户对检察业务知识的咨询数据,以及检察机关各级领域专家对用户问题的解答与回复数据。然而,随着检察机关办理的案件日益增多,基层检察办案人员等用户对检务知识咨询需求不断增大,仅仅依赖检务领域专家对其人工回答需要投入大量的人力成本。其次,对问题的回复往往需要遵循特定的流程规范和内容审核,使用户的问题得不到及时解决。同时,很多常规检务知识的提问频次较高,存在重复性人工解答的现象。
为了提高用户咨询服务效率,增强计算机正确理解用户提问意图的能力,并准确预测用户提问内容所属的业务类型,是构建智能问答系统的关键环节。因此,该文将基于检答网用户提问数据,提出一种面向检务领域用户咨询的业务类型分类模型。首先对检答网原始数据中的业务类型重新进行梳理与归并,构建数据集。其次,基于句法依存分析得到用户提问内容的图表示,并应用RGCN图神经网络模型[3]提取其特征。同时基于邻域窗口得到用户提问内容的图表示,将GAT图神经网络模型[4]作为其特征编码器。最后,构建一种融合两种图表示特征的异构图神经网络模型,并通过引入辅助分类器优化模型性能,采用Focal Loss损失函数[5]解决样本数据的不均衡问题,实现对用户提问内容的业务类型预测与性能评估,为进一步构建面向检务领域智能问答系统打下坚实的基础。
1 相关工作
文本分类是自然语言处理的基础问题。与传统基于朴素贝叶斯方法[6]、支撑向量机(SVM)[7-8]等文本分类方法相比,以卷积神经网络(CNN)[9-12]、循环神经网络(RNN)[13-14]、长短期记忆神经网络(LSTM)[15-16]等为代表的深度学习模型提供了一种端对端的文本分类方法,以数据驱动的方式自动学习文本中潜在的语义模式,避免了人工构建特征的繁琐工作,并获得了更优性能。自2018年提出BERT模型[17]以来,以BERT模型为基础的多种自然语言处理任务均获得较大性能提升。文献[18]利用预训练BERT模型提取文本的字符特征,作为文本分类器的输入。文献[19]提出了多种基于BERT模型的微调方法,使其应用于文本分类。文献[20]则将BERT模型用于中文短文本分类。
近年来以图卷积神经网络为代表的图神经网络模型得到了关注和发展[21-22]。图神经网络模型不仅保留了传统卷积神经网络的优良特性,同时具有能适应图数据的特点,使深度学习技术与图数据的有效结合成为必然。图神经网络通过迭代聚合邻域节点特征而学习到图数据中各节点的特征向量,从而支撑节点分类任务和图分类任务。图神经网络模型与自然语言处理技术的结合也成为一种趋势。文献[23]提出了基于词与词之间的互信息,以及词与文档之间的TF-IDF权重构建整个文本语料库图网络,并通过图神经网络模型实现对语料库图网络文档节点的分类。然而,这种构建大规模文本图网络实现节点分类的方式虽然能利用语料库中全局信息,但并不适合模型的在线部署,同时存在较大的内存消耗。为此,文献[24]通过词的邻域窗口构建文档的图表示,并提出了基于文档的图神经网络分类模型。文本的句法依存关系也用于文本的图表示。文献[25]通过将图神经网络用于句法依存图,实现机器翻译。文献[26-27]则将图神经网络与句法依存树相结合,用于事件抽取任务。
智能问答系统中的意图识别通常需要解决用户提问文本内容的领域分类[28]。针对检答网用户提问内容的长度短等特点,多样化的图表示有利于充分挖掘短文本的有用信息,因此尝试构建能融合不同图表示的异构图神经网络,以用于面向检务知识咨询的文本分类任务。
2 模型与方法
2.1 基于句法依存分析的图表示
针对检答网中的用户提问数据,用户提问内容的长度不一:有些提问简短,只包含一句话;有些提问的描述较为具体,可能包含多句话。因此,本节先从句子粒度考虑,通过句法依存分析构建单个句子的图表示。针对多句话的用户问题,通过单句的图表示构建多句的图表示。
2.1.1 单句的图表示
针对中文文本,当前句法依存树的提取技术较为成熟,该文采用哈工大语言技术平台的LTP工具,用于检答网中用户提问内容的句法依存分析,并基于提取的句法依存树构建单句的图表示。具体为:首先以句子为单位,将用户提问内容切分为多个句子的集合。针对每个句子,应用LTP工具得到分词后词与词之间的句法依存关系及其指向关系。以分词后每个词为图节点,节点的特征初始化为Word2vec预训练模型[29]的词向量。基于句法依存指向关系列表,连接词与词之间存在指向关系的所有边,句法依存关系即定义为边的类型。考虑到基于句法依存分析的边稀疏性,为了利于图神经网络的特征聚合,将原有句法依存指向性的单向边更改为双向边。同时添加一个句子节点,该节点连接句法依存关系为“HED”的词汇节点。此外,句子节点的特征向量初始化为Word2vec预训练模型中“起点”的词向量。通过这种方式,构建单句的图表示。
2.1.2 多句的图表示
针对多句话的用户问题,假设已通过句法依存分析工具得到单句的图表示,该文通过双向连接相邻句子的句子节点,从而构建多句的图表示。其中该双向连接的边类型定义为“SLINK”,如图1所示。图1的A部分示意了用户提问“是否应该抗诉?依据的条款是什么?”经过句法依存分析后的多句图表示。该图表示的边均为双向边,边的类型取决于句法依存分析的结果,句子与句子之间通过类型为“SLINK”的双向边连接。
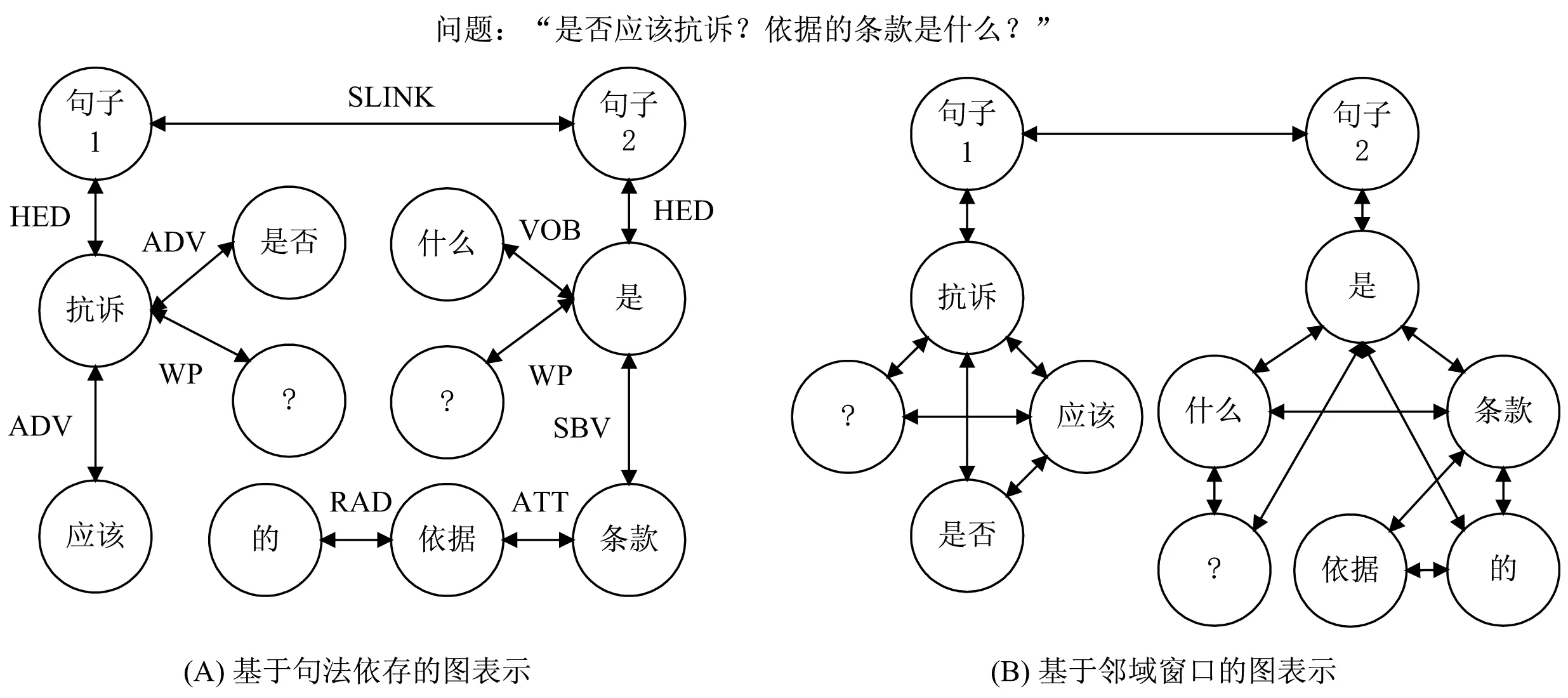
图1 基于句法依存分析及基于邻域窗口的多句图表示(d=2)
2.2 基于邻域窗口的图表示
基于句法依存分析的图表示虽然将用户提问内容分解为词与词之间的句法关系,但却忽略了词与词之间的邻域关系。而词的邻域关系在词向量学习中有广泛应用。同时,HUANG等提出了将词的邻域关系应用于图神经网络,证明了其可行性与有效性。因此,该文同时考虑基于邻域窗口的图表示。
2.2.1 单句的图表示
基于邻域窗口的图表示方式仍以分词后每个词为图节点,节点的特征初始化为Word2vec预训练模型的词向量。假设词的邻域定义为与词的距离不大于d的词集合,则基于邻域窗口的图表示构建规则为:单句分词后每个词为图的节点,每个词与其邻域中每个词建立双向边连接,从而得到该单句的图表示。考虑到用户提问内容长度较短,该文将d设为2。
2.2.2 多句的图表示
针对检答网中用户提问数据的多句情况,仍采用2.1节中多句图表示的策略。即通过双向边连接相邻句子的句子节点,使句子之间的信息可以交流。对于每个句子,句子节点与句法关系为“HED”的词节点相连,与2.1节保持一致,如图1所示。图1的B部分示意了用户提问内容基于邻域窗口的多句图表示。该图表示的边均为双向边,句子与句子之间也通过双向边连接,但不考虑边类型。
2.3 基于异构图的图神经网络模型
该文同时考虑基于句法依存分析的图表示,以及基于邻域窗口的图表示。从不同维度提取用户提问内容的结构信息,充分利用短文本的有限信息,有利于对提问意图的正确理解。由于这两种图表示方法的差异性,提出一种基于异构图的图神经网络模型,将提取并融合这两种图表示的特征。
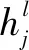
(1)
该文应用两层RGCN编码器对基于句法依存分析的图表示提取特征,如图2中M1部分所示。由于用户提问内容的长度较短,而基于句法依存分析的所构建的图较简单,不采用更多的RGCN层有利于避免图神经网络的过平滑效应。每层RGCN编码器后都经过ELU非线性变换以及DropOut层。最后通过ReadOut层得到图表示的特征编码。其中ReadOut层定义为输入全局最大池化和输入全局平均池化的拼接。

(2)
(3)
基于句法依存分析的图表示与基于邻域窗口的图表示分别经过特征编码后,即各自ReadOut层的输出向量通过拼接的融合方式作为输出层的输入。输出层由两层全连接层组成。第一层全连接层后经ELU非线性变换以及DropOut层,而第二层全连接层通过Softmax层输出各类的预测概率,如图2中M3部分所示。
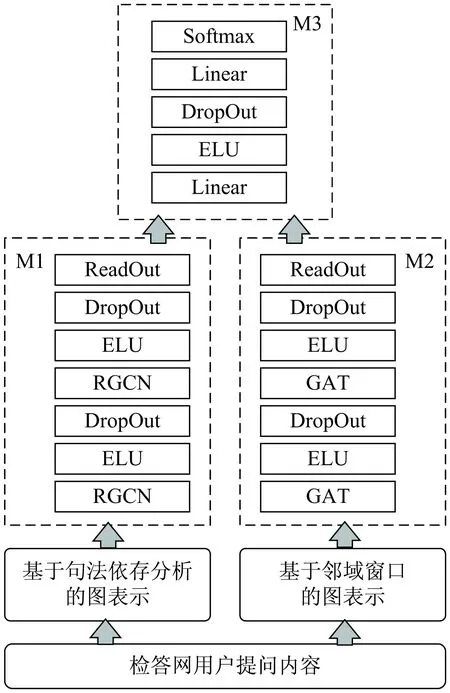
图2 面向检答网用户咨询问题分类的异构图神经网络模型
2.4 异构图神经网络的训练
为了应对异构图特征融合和训练样本不均衡等问题,该文针对异构图神经网络模型,通过引入辅助分类器[30]来增强底层网络的特征学习能力,有效防止梯度消失;同时通过引入Focal Loss损失函数应对训练样本的不均衡问题。
该文分别针对图2中M1部分的特征编码器和M2部分的特征编码器额外添加全连接层和Softmax层,作为两个辅助分类器的输出,如图3所示。因此,M1部分的ReadOut层引出的辅助分类器对应损失函数Loss1,原M3部分的分类器对应损失函数Loss2,而M2部分的ReadOut层引出的辅助分类器对应损失函数Loss3。总的损失函数Loss通过Loss1、Loss2和Loss3加权求和而得。如公式(4)所示,Loss1和Loss3赋予相同的权重α,则Loss2的权重为1-2α,其中权重α位于0到0.5区间。辅助分类器的引入将增加反向传播的梯度信号,并增强了正则化效果,有利于底层M1部分特征、底层M2部分特征的学习。
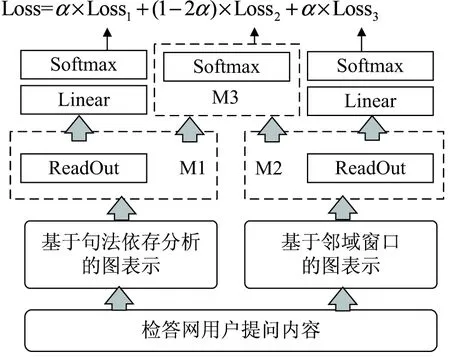
图3 异构图神经网络的辅助分类器示意图
Loss=α×Loss1+(1-2α)×Loss2+α×Loss3
(4)
由2.1节可知,检答网用户提问内容归并为16个类别,而这些类别存在样本数量不均衡的问题,且有些类别的样本数量差异较大。解决训练样本不均衡的方法有很多,该文主要应用Focal Loss损失函数,如公式(5)所示,其中N代表总样本数量,K代表总类别数,yn,k为第n个样本属于类别k的真值,I为指示函数,pi,n,k为图3中与Lossi对应的M模块关于分类类别为k的预测概率。通过对样本数量较少的类别k赋予较大的权重βk来平衡其反向传播中的梯度信号大小。其中各类别的权重取值策略为:各类别的归一化权重βk正比于自身样本数Nk倒数的平方根。取倒数的平方根是为了防止权重差异较大对模型训练带来的不稳定性,如公式(6)所示。另一方面,γ用于鼓励提高困难样本对梯度的贡献,而减少简单样本的权重,该文γ取值为1。
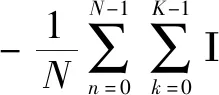
(yn,k=1)βk(1-pi,n,k)rlog(pi,n,k)
(5)
(6)
3 实验与评测
3.1 数据集构建与评估标准
该文以检答网用户提问的文本数据为研究对象,其提问内容覆盖了全国各省市检察院检察办案人员以及基层检察办案人员对检务领域的知识咨询。原始数据共包含了53 362条数据,每条数据包含了脱敏后的用户ID、提问内容、业务分类等字段。针对用户提问内容的业务分类预测需求,从原始数据中提取了提问内容和业务分类两个字段用于构建数据集。
对用户提问内容的业务类型进行数据统计分析时,发现其存在以下问题:其一,业务类型较多,达到31个业务类别;其二,各个业务类型下的数据数量分布极不均衡,其中业务类别“普通犯罪检察”的样本数量达到最多的18 271条,而业务类别“铁检”和“公诉二”的样本数量仅为5条;其三,业务类型分类存在界限模糊、部分类别重复定义的情况,比如业务类型“未检”和“未成年人检察”应为相同类别,又如业务类型“公益诉讼”和“公益诉讼检察”可归并为相同类别。
因此,为了支撑分类算法模型的构建,对原始数据进行预处理,具体处理内容包括:(1)以人工的方式逐条分析用户提问内容和业务分类信息,排除无效数据,并对错误分类的数据进行重新标注;(2)去除业务类别样本量不足的少数数据;(3)基于检务知识背景,制定统一的业务分类标签体系,对类别重复的数据进行合并和类别标签统一,将业务类别数量从31个压缩至16个。图4显示了16个业务类型对应的样本数量分布图,其中类型为“司改”的样本数量仅为31,因此在图4中没有得到清晰显示。

图4 检答网用户提问数据业务类型样本数量直方图
最后,对预处理后每条数据的顺序随机化,并分别对16个业务类别按7∶1∶2相同的比例抽取样本形成训练集、验证集和测试集,其大小分别为36 275、5 196和10 382。图5给出了检答网用户提问内容文本长度直方图。从图可知,检答网用户提问内容以短文本为主。

图5 检答网用户提问内容文本长度直方图
考虑到检答网用户提问内容的业务类别在训练集、验证集和测试集中存在类型样本分布极度不均衡等问题,如图4所示,该文将以宏平均-准确率作为算法模型性能的统一评估标准。宏平均-准确率定义为计算各个业务类型分类准确率的平均值。
3.2 模型设置与训练
异构图神经网络参数设置如下:图3中的异构图神经网络模型基于Pytorch Geometric框架构建。对于M1部分的RGCN层,针对基于句法依存分析的图表示,边的类型通过遍历训练集中所有用户提问内容经过句法依存分析后,得到的句法依存关系集合,同时添加用于连接句子节点之间的“SLINK”关系类型。考虑到训练集之外可能存在其他的句法依存关系,因此添加一个“Others”关系类型用于应对特殊情况,共16个关系类型。为了缩减RGCN层的参数,每个RGCN层的隐层大小为64。对于M2部分的GAT层,每个GAT层的隐层大小设置为64。对于M3部分的第一个全连接层,其隐层大小为128。而第二个全连接层的输出大小为16,即业务类型的类别数量。
模型训练参数设置如下:异构图神经网络模型的训练采用Adam优化器,初始学习率设置为0.000 1。训练样本的batch size设置为64,epoch的大小设置为300。训练过程中,根据模型在验证集上的指标表现确定最终的模型参数。
模型训练与测试的硬件环境为:CPU型号为Intel(R) Xeon(R) CPU E5-2620 v4 32核,内存64G,GPU型号为NVIDIA GTX1080ti。其软件环境为:操作系统为Ubuntu 16.04.7 LTS,Python版本为3.6。
3.3 实验结果
3.3.1 超参数α对模型的影响
模型的RGCN编码器和GAT编码器分别引入辅助分类器,其对应的损失函数为Loss1和Loss3。为了评估超参数α对模型的影响,该文以0.1为步长从0开始扫描超参数α,并记录模型在验证集下的最大宏平均-准确率。如图6所示,超参数α等于0时,模型在验证集上的最大宏平均-准确率为59.3%,此时Loss1和Loss3的权重均为0,等效于不引入辅助分类器的情况。超参数α等于0.3时,模型在验证集上的最大宏平均-准确率为61.6%,高于超参数α取其他值时的性能。此时Loss1和Loss3的权重均为0.3,Loss2的权重为0.4。通过进一步测试,超参数α等于0和0.3时模型在测试集上的宏平均-准确率分别为58.0%和59.3%,模型性能提升了1.3%。该对比实验也说明了通过引入辅助分类器,有助于RGCN编码器和GAT编码器的特征学习,从而提升了模型的整体性能。因此,模型在后续的性能评估中,超参数α固定为0.3。
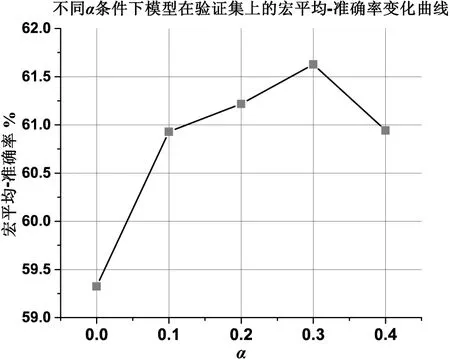
图6 超参数α对模型性能在验证集上的影响
3.3.2 不同编码器对模型的影响
针对检答网用户提问内容,该文采用RGCN编码器对基于句法依存的图表示进行特征提取,同时采用GAT编码器对基于邻域窗口的图表示进行特征提取,最后通过特征的拼接融合方式实现所属业务类型的分类,该模型定义为Model-RGCN+GAT。为了评估不同编码器对模型性能的影响,将独立采用RGCN编码器的模型定义为Model-RGCN,模型结构如图3中M1直接作为M3的输入,无辅助分类器和M2部分。同时,独立采用GAT编码器的模型定义为Model-GAT,模型结构如图3中M2直接作为M3的输入,无辅助分类器和M1部分。三者在测试集上的表现如表1所示。从对比结果看,RGCN编码器提取的特征与GAT编码器提取的特征融合后对提升业务类型分类的宏平均-准确率更有帮助。

表1 不同编码器条件下的模型性能对比
3.3.3 损失函数对模型的影响
该文引入Focal Loss损失函数的目的是为了应对检答网用户提问数据中业务类型样本较大的分布差异。为了评估损失函数对模型性能的影响,如表2所示,将Model-F定义为引入Focal Loss损失函数的情况(与章节3.3.2中的Model-RGCN+GAT相同),而Model-C定义为采用传统交叉熵损失函数的情况。表2展示了Model-F和Model-C在测试集上各个业务类型的分类准确率以及宏平均准确率。由数据对比可知,采用传统交叉熵损失函数时,模型的宏平均准确率为53.7%。对于样本数量最少的“司改”类型,模型的预测准确率为0。而引入Focal Loss损失函数后,模型的宏平均准确率为59.3%,性能提升了5.6%。该模型在各业务类型的预测准确率更均衡,有13个类别的预测准确率均高于对照组。该对比实验说明了Focal Loss损失函数有效解决了检答网用户提问内容业务类型的样本数量不均衡问题。
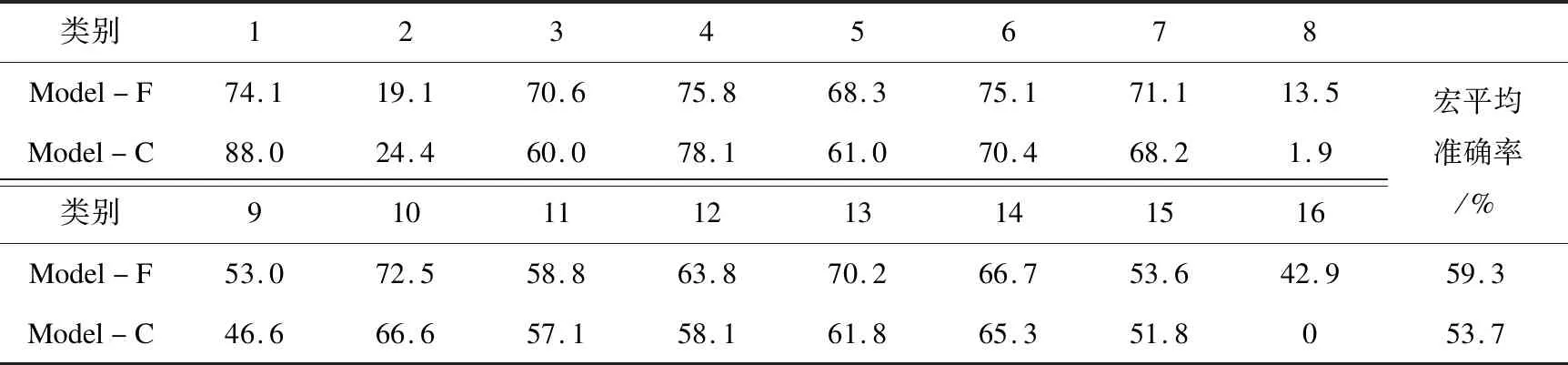
表2 Focal Loss损失函数与传统交叉熵损失函数对模型的性能对比
3.3.4 与其他基准模型的性能对比
本节将提出的基于异构图神经网络文本分类模型与传统CNN、LSTM、Bi-LSTM文本分类基准模型,同时与近年来主流的BERT模型进行性能对比。对比结果如表3所示。从对比结果可知,提出的异构图神经网络文本分类模型在测试集上的性能均优于传统的CNN、LSTM、Bi-LSTM等基准模型,分别提升了5.6%、5.1%和4.5%。从表1可知,单独以RGCN编码器或者GAT编码器完成文本分类的性能低于BERT分类模型,但RGCN编码器与GAT编码器特征融合后的性能却略优于BERT分类模型,性能提升了1.1%。也说明了RGCN编码器所提取特征与GAT编码器所提取特征具有一定的互补性,使特征融合后能增强模型整体性能。此外,表3同时比较了各个模型的大小和推理时间。所提出的异构图神经网络文本分类模型大小与CNN、LSTM、Bi-LSTM等模型相近。相比于BERT模型(型号为chinese_L-12_H-768_A-12),所提出模型的模型大小和推理时间远小于BERT模型。该模型占用更少的内存空间和计算资源,更有利于模型的在线部署和应用。

表3 所提出模型与其他深度学习模型的性能对比
4 结束语
该文提出了一种基于异构图神经网络的检务知识咨询业务分类模型。针对用户提问内容长度短的特点,该模型通过RGCN编码基于句法依存分析的图表示,并通过GAT编码基于邻域窗口的图表示,最后通过特征融合实现了用户提问内容业务类型预测。这种特征融合方式比单独采用RGCN编码器的方式提升了1.9%的性能,而比单独采用GAT编码器的方式提升了1.5%的性能。为了平衡这两个编码器的特征学习,分别对RGCN编码和GAT编码器引入辅助分类器,使模型提升了1.3%的性能。为了解决检答网用户提问内容业务类型的样本数据不均衡问题,引入Focal Loss损失函数,使模型提升了5.6%的性能。此外,所提出模型在测试集上的宏平均准确率均优于传统深度学习文本分类模型,略优于BERT分类模型。所提出模型的模型大小和推理时间远小于BERT模型。该模型有助于计算机正确理解用户关于检务领域的知识咨询意图,为进一步构建检务智能问答系统提供技术基础。
