面向医药信息的知识图谱构建
2022-10-24杜睿山张豪鹏
李 阳,杜睿山,张豪鹏
(1.东北石油大学 数学与统计学院,黑龙江 大庆 163318 2.东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318)
0 引 言
在信息化发展的今天,医药数据的存储及共享方式多变简洁,互联网中医药数据量呈指数型爆炸式增长,数据冗杂,医药知识相互独立,患者难以在海量的医药数据中寻求到合适的帮助。如何在大量医药数据中探寻医药数据关联以及挖掘医药数据的潜在价值成为了首要的研究目标。由谷歌公司提出的“知识图谱”可以很好地绘制知识脉络,挖掘数据的潜在关系,并且以简洁明了的可视化方式呈现数据之间的关系[1]。并且,随着知识图谱的迅猛发展,金融、农业、教育等其他领域也着眼于从知识图谱中寻找数据结构化存储及其数据关联的方案[2-5],成果显著,同时,在智能搜索等众多领域,知识图谱也凭借其特有的优势而备受青睐[6-9]。
医药大数据是医学人工智能的重要基石,一直以来都备受人们的关注。但也正因如此,在国内外出现了众多不尽相同的标准,这使得很多医药数据无法被人直接引用。近年来,国内加大了对知识图谱的重视[10-12],已有相关学者将中国传统医学和知识图谱相结合,在中医药领域知识图谱的构建和标准化进行了初步的尝试和探索。如阮彤等[13]以文本抽取、数据融合等技术为基础,展开了中医药知识图谱的构建。贾李蓉等[14]多角度探讨了如何构建中医药知识图谱。但可以应用到实际生活中的中文开源数据集仍是稀缺状态,构建医药知识图谱的意义是十分重大的。
知识图谱的出现为问题的解决提供了技术支撑,利用知识图谱可以对其进行有效的关系梳理。知识图谱是一种语义网络,用于揭示实体之间的关系[9]。药品和病症之间存在的诸如推荐用药关系,以及疾病与病症之间存在的伴随、检查等多种关系均可以在知识图谱中体现。目前,传统的网络图已经无法处理大数据时代下繁多的数据,与此相比,知识图谱更适合表示其数据关系。该文选择疾病作为切入点,从知识关联角度出发,通过考察疾病与药品的关联关系构建医药知识图谱,并实现医药图谱间关系查询及其可视化,为患者普及医疗知识,辅助医疗行业提供新视角。
1 医药知识图谱构建
该系统是基于医药知识图谱构建,首先是确定系统的需求,在人工参与的情况下获取医学词典,在医学词典的指导下通过相应的医药网站获取系统所需要的数据,如疾病名称、相关症状、所需药物、相应检查等等相关信息;经过知识融合及加工实现医药知识图谱的构建。
设计了医药知识图谱构建的总体框架,如图1所示。以寻医问药网以及39健康网为系统半结构化数据来源,分别对爬取的数据进行知识抽取、知识融合、可视化评估等迭代步骤,从而实现图谱的构建与更新。

图1 医药知识图谱构建总体框架
1.1 医药知识图谱的设计
目前知识图谱有两种构建方法:自顶向下和自底向上[15]。当构建垂直的领域知识图谱时,通常采用自顶向下的构建方法。但这种方法也是有利有弊,在保证数据质量和深度的同时,会存在大量人力和财力被消耗的问题[16]。由于本系统规模较小,从实际需求和应用出发采用自底向上的构建方式。
根据实际需求,医药知识图谱主要是为了非专业人士及患者提供自主查询以及了解相关疾病和药品,从而设计图谱的实体类型以及关系类型。
从实际需求出发,实体数据中应包含七大类,如表1所示,分别是:诊断检查项目、医疗科目、疾病、药品、建议饮食、在售药品、疾病相关症状。
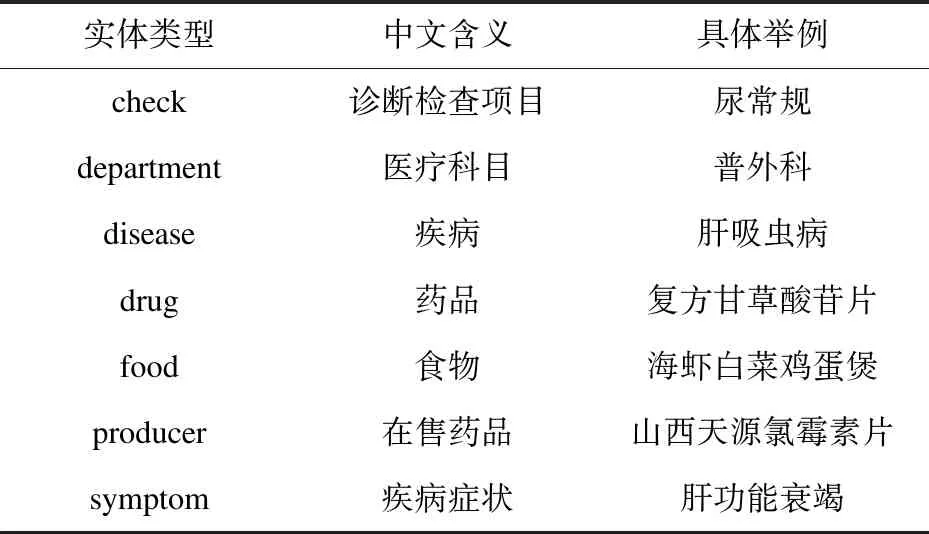
表1 实体类型信息
该系统是以疾病为中心的医药知识图谱,应以疾病展开,注重疾病相关信息的描述,即对于疾病实体来说,其属性值应包含:疾病名称、疾病简介、疾病病因、预防措施、治疗周期、治疗方式、治愈概率、疾病易感人群等八部分,如表2所示。
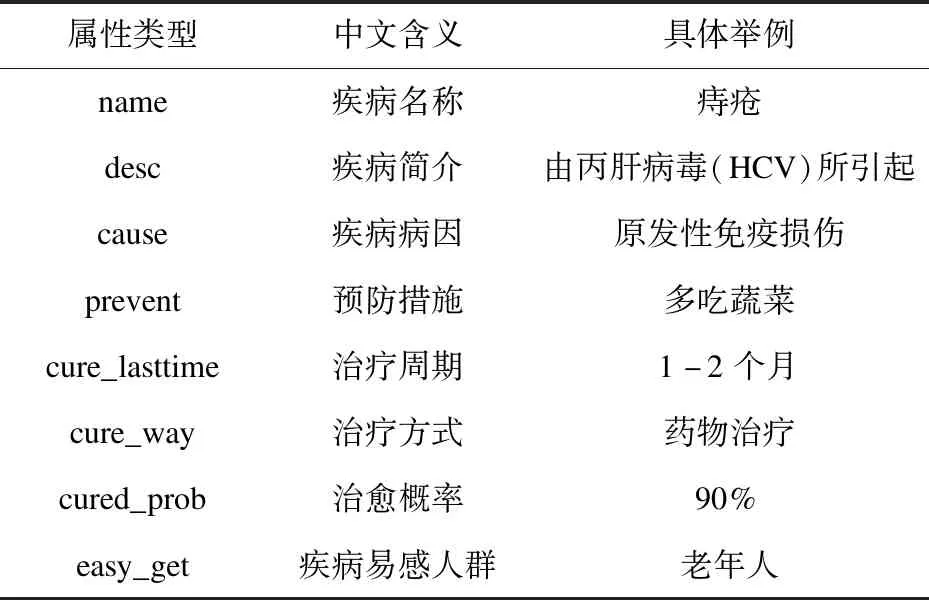
表2 属性信息
通过分析实体之间的关系以及实体的相关属性,设计出相应的关系类型共十种,如表3所示,分别是:属于,疾病常用药品,疾病宜吃食物,药品在售药品,疾病所需检查,疾病忌吃食物,疾病推荐药品,疾病推荐食谱,疾病症状,疾病并发疾病。

表3 知识图谱实体关系类型
1.2 数据层构建
医药知识图谱采用自底向上的构建方式,数据层的构建主要包括医药知识抽取、知识融合。层层对知识进行抽取和加工,最后存储到图数据库中。
1.2.1 知识抽取
知识抽取是对数据中的实体、属性及关系三个知识要素进行提取[17]。其数据来源种类多样,包括医药网站、医疗机构的诊疗数据,制药企业的生产数据等等。为获得疾病名称、药品名称、企业生产数据等信息,需要利用知识抽取技术对文本特征进行分析,得到相应的知识信息。
该系统是基于垂直网站的医药图谱,所采用的数据来自“寻医问药网”和“39健康网”。医药网站中包含大量的疾病数据,以及推荐用药、就诊科室、所需检查等等。同时,其数据分类明确,信息权威,是构建医药图谱的良好数据来源。
在知识抽取中,系统采用规则匹配方法进行实体、属性及其关系的获取[9]。确定以医药类网站为数据来源,获取其半结构化数据,解析其药品信息,疾病种类,症状表现,医疗科目,诊断检查项目,在售药品以及宜吃食物等相关实体及属性信息。根据实体种类设计其数据结构,定义关于疾病的“属性-属性值”关系。
首先利用最大向前匹配算法和最大向后匹配算法分别对获取到的医药数据进行字段的切分预处理,然后利用双向最大向前匹配算法对预处理结果进行知识验证,其主要过程如下:
(1)实体及属性抽取。
根据医学词典可对系统所获取的医药数据进行规则匹配从而得到图谱的实体及属性,并对其匹配结果进行统计分类,实体规模共七类,分别为疾病、药品、在售药品、疾病症状、诊断检查项目、医疗科目、食物。系统采用的是最大向前匹配及最大向后匹配算法,其中最大向前匹配算法描述如下:
STEP1:从左向右取待切分汉语句的M个字符作为匹配字段(M为医学词典中最长词条个数);
STEP2:查找医学词典并进行匹配。若成功匹配则会把该匹配字段当成一个词进行切分,若失败则按字符切分。
最大向后匹配算法则是从右向左取待切分语句,其余与最大向前匹配算法一致。
(2)知识验证。
在做完实体及属性的抽取后,为了提高实体及属性识别的准确率,将最大前向匹配算法及最大向后匹配算法的结果进行比较,从而决定正确的分词方法,即双向最大向前匹配算法。其启发式规则如下:
STEP1:若最大向前匹配算法和最大向后匹配算法的结果词数不同,则选择分词数量较少的结果。
STEP2:若两个匹配算法的分词词数相同,分词结果无歧义,则可返回任意一个结果;若分词结果不同,返回单字较少的结果。
其部分知识抽取映射如表4所示。

表4 部分知识抽取映射
抽取后的信息以三元组形式(<药品—关系—疾病>、<药品—属性—属性值>、<疾病—关系—特征>)等保存于数据库中,这些三元组本质上就是医药网络中的知识关联。
1.2.2 知识融合
目前的医药网站存在着知识来源斑杂,知识质量良莠掺杂等方面的问题,所以要将这些不同知识数据源在同一框架规范下进行异构数据处理,对知识进行判断,达到数据、信息、方法、经验与人思想的融合,将验证正确的知识通过对齐关联、合并计算有机地组织成知识库[17-18]。
知识抽取中常常存在数据冗余及数据错误等现象,而知识融合就是处理这些现象并将其整合在已有知识中的过程[2]。在医药和疾病数据中,各类数据中存在歧义现象。在实体融合中解决歧义的方法最常用的是实体连接以及实体分类;在属性融合中,通常使用基于向量的相似度计算、最小编辑距离等;关系融合中,主要方法为相似性度量[2]。
由于该系统的疾病实体是根据疾病词典所获取的,实体对齐过程省略,知识融合部分由属性对齐以及实体链接所组成。
(1)属性对齐。
在实体链接之前,为了提高识别的准确度,首先进行实体对齐,根据图谱构建设计时所划分的属性类别对同一类实体的同一属性的不同表达方式进行对齐,如表5所示。

表5 部分属性对齐映射
在完成属性对齐之后,根据数据库设计的属性类型对属性值进行规范化处理,本系统将属性值分别划分为三类:字符串型、数值型、数值区间型。然后对这三类属性进行规范化。
(2)实体链接。
系统可以借助属性对其结构拓展名称的相似度的计算方法,将其实体与知识图谱中对应实体项相链接[16]。假设有a,b两个实体,对应名称分别为Sa和Sb。
①实体名称相似度。
(1)
其中,len_lcs(i,j)表示名称i和j最大公共子序列的长度;len(name)表示name的长度,name∈{i,j}。
②字符串型属性相似度。

(2)
③数值区间型属性相似度。
(3)
其中,len_overlap表示两个区间属性重合部分的长度,数值区间和时间区间属性都采用这种方法计算相似度。
最后综合考察实体名称相似度和属性相似度相加得到的实体对综合相似度,判断实体对是否指向同一实体。
2 医药知识图谱的实现
该系统是基于医药知识图谱构建,采集的数据规模约34万条,其中知识实体共七类约4万条,实体关系共11类约30万条。主要信息有疾病种类约9 000种,药品种类约5 000种,在售药品信息约17 000条,症状表现约6 000种等等。采用Neo4j图数据库进行知识存储,并利用Neo4j数据库支持的属性图来进行知识表示以及图谱可视化。利用Neo4j图数据库进行知识图谱的可视化,将疾病信息爬取后以三元组的形式导入其中。Neo4j使用图形清楚明了地展示出数据之间的关系,其基本单元是节点、关系与属性。不同来源的医疗医药数据经过知识抽取、知识融合等步骤,形成三元组的知识文件,最后将加工完成的知识信息导入到Neo4j图数据库中,将其可视化。其可视化界面如图2和图3所示

图2 疾病伴随症状
图3 混合关系
3 评 估
为了验证本图谱的正确性以及合理性,采用随机实验的方法,随机抽取50名用户作为测试对象,用户人群分别为大学在校生30人、社区老人10人、教师5人、医护相关人员5人。用户通过对实体的查询,了解相关的实体关系,判别系统功能的正确性和实用性。其测试主要考察:用户能否查询到相关疾病信息的描述即知识覆盖面的广泛度;系统中疾病属性描述的正确性;知识关联的正确性和系统实用性,测试结果如表6所示。

表6 系统评估测试
通过以上的测试结果可以看出,用户对系统的满意度较好,但仍存在一定的问题:医药知识图谱构建的不够全面,对于疾病的原因、预防等信息的获取实际上是一串文字,由于医学词典的局限性,知识匹配所划分的实体和关系还不够准确,测试中仍有部分实体无法查询到;知识的关系分类还可以更加详细,知识关联可以进一步进行挖掘。
4 结束语
该系统以垂直网站为数据来源,构建起以疾病为中心的医药知识图谱,利用预先定义的医学词典以规则匹配的方式进行知识抽取,以综合考察实体名称相似度与属性相似度方式进行实体链接,构建医药知识图谱。知识图谱及其数据库设计基于所采集的结构化数据生成,以Neo4j图数据库作为存储,并以此实现图谱的可视化。
下一步将继续完善医药知识图谱,在医药知识图谱的基础上设计智能问答系统,在“查询”方面进一步智能、简便化。
