基于多特征融合的人脸表情识别算法
2022-10-24单剑锋
吕 鹏,单剑锋
(南京邮电大学 电子信息与光学工程、微电子学院,江苏 南京 210023)
0 引 言
面部表情在人类的社会交往中起着至关重要的作用。1971年,心理学家Ekman与Friesen提出六种人类主要的基本表情,每种表情代表一种独特的心理活动,分别为愤怒、厌恶、恐惧、高兴、悲伤、惊讶。随着人工智能(AI)技术的不断发展,人机交互、智能控制等技术的研究变得越来越流行,面部表情识别[1](FER)是其中一个重要的视觉信息,如果机器能借此预测人类的情绪,就可以做出相应的行为来满足人类的需求。典型的表情识别系统包括人脸图像采集、特征提取、训练和识别。大多数人脸图像特征对噪声和光照变化非常敏感。因此,能够容忍噪声和光照变化的特征有助于生成鲁棒的表情识别系统。
传统的特征提取方法大致分为两种:基于几何特征的特征提取方法,即通过对嘴巴、眼睛、眉毛等具有显著特征的位置进行定位,测量确定其大小、距离、形状等特征,再进行分类。基于AUs的表情识别算法即通过检测一些预定义的AUs,然后根据FACS将它们的组合编码为特定的表情。由于AU的定义在语义上有歧义,在实际应用中很难实现对AU的准确检测。基于外观的传统特征提取方法,从面部整体或局部的图像过滤器来提取面部外观变化,即通过对图像整体或局部的纹理进行检测并提取,再进行分类。诸如,Gabor[2]小波、Haar小波、LBP[3]、LDP[4]等方法,在一定程度上提高了表情识别的正确率,但是对光照和噪声的鲁棒性并不高,在人脸图像的平滑区域提取基于边缘的局部特征会产生对噪声敏感的不稳定模式,对分类结果产生负面影响。LDN[5]算法通过提取表情图像的梯度方向信息,得到可以区分具有相同微结构但强度不同的编码,该算法对光照和噪声有不错的鲁棒性。
随着深度学习的快速发展,人脸表情识别进入新的阶段。G.Wang等[6]通过改进LeNet-5网络,增加了卷积层和池化层,将低级特征与高级特征相结合,用可训练卷积核学习其隐性特征,一定程度上提高了识别率;H.Yang等[7]通过cGAN网络生成原始人脸表情对应的中性表情,利用过滤在中间层的残余表情成分进行分类。该算法在一定程度上减少了在表情分类的过程中同一个人的不同表情被误分为同一类的概率;J.Li等[8]提出一种Faster R-CNN算法,用卷积网络提取表情隐性特征之后,利用RPNs生成高质量的区域建议并通过R-CNN进行检测,最后进行分类,一定程度上避免传统面部表情识别中复杂的显性特征提取过程和低层次数据操作的问题。以上大部分方法是提取单一特征或者对不同层次的单一特征进行识别分类,难免会对表情的部分细节特征有所遗漏,导致难以详细地描述表情图像信息。该文在研究浅层DenseNet模型的基础上,将LDN特征与稠密特征进行融合,利用特征的多样性提高表情识别率。
1 相关理论
1.1 DenseNet
K.He等[9]提出ResNet网络,通过残差块增加网络深度的同时也在一定程度上缓解梯度消失的问题。G.Huang等[10]提出的DenseNet网络借鉴了ResNet网络的思想,设计了Dense Block模块,通过对比式(1)ResNet中残差模块与式(2)DenseNet中Dense Block模块得出两者的本质区别,其目的在于将输入与该层之前的网络层输出叠加作为该层的输入,增加各卷积层特征的利用率。
x=H(x)+x
(1)
x=H([x0,x1,…,x])
(2)
其中,x为第层输出,H表示非线性变换,[x0,x1,…,x]表示从0到-1层的特征作合并操作。
每个Dense Block中都有多个BN-ReLU-Conv(3×3)层,同一个Dense Block中在不改变的输入尺寸的情况下,尽可能提取图像的隐性特征。假设每一个非线性变换H的输出为K个特征,那么第层网络的输入便为K+(-1)×K个输入特征,其中K称为增长率。为了防止特征图过多导致过拟合和计算复杂度的问题,在Conv(3×3)之前增加1×1的卷积层进行降维,即BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3),在每两个Dense Block之间增加过渡层,即BN-ReLU-Conv(1×1)+2X2AvgPooling在减小图像尺寸的同时再次降维,最终输入到Softmax层进行分类。
BN层为批量标准化层,将每个批量数据标准化,用来加快模型学习和收敛速度,防止梯度爆炸、消失和过拟合的问题。ReLU为激活函数,用以增加非线性因素,提高模型的表达能力。此外,面对全连接层有增加Training以及testing的计算量而降低了训练速度和参数量过多导致过拟合的缺点,DenseNet中利用全局平均池化层(GAP)来代替全连接层。GAP使得特征图与最终的分类间转换更加简单自然,不像全连接层需要大量训练调优的参数,降低了空间参数会使模型更加健壮,抗过拟合效果更佳。
1.2 LDN算法
A. Ramirez Rivera等提出LDN(Local Directional Number)算法,以一种紧凑的方式对人脸纹理的方向信息(即纹理的结构)进行编码,通过与方向算子进行卷积,产生比现有方法更有分辨力的编码。如图1所示,借助提取方向信息的kirsch算子来计算每个微图像的结构,并使用突出的方向索引(方向号)和符号来编码这些信息。这能够区分具有不同强度转换的相似结构模式。

图1 kirsch算子
将人脸表情图像与M0到M7各个算子卷积得到不同方向的边界响应,找出特定方向上具有高值的边界响应,生成编码。这里以高值的边界响应作为主要区域进行编码。正响应最高和负响应最低分别为编码方案中的MSB和LSB,其表达式为:
LDN(x,y)=8×i(x,y)+j(x,y)
(3)
其中,(x,y)为编码局域的中间像素,i(x,y)为最大正响应(MSB)的方向数,j(x,y)为最小负响应(LSB)的方向数,其表达式为:
i(x,y)=argmaxi{Ⅱi(x,y)|0≤i≤7}
(4)
j(x,y)=argmini{Ⅱj(x,y)|0≤j≤7}
(5)
其中,Ⅱi为原始图像的卷积运算:
Ⅱi=Ⅰ*Mi
(6)
其中,Mi为kirsch第i个掩模,得到整体的LDN编码和直方图vi,但是由于该编码方式缺乏位置信息,需要将图像分成多个cell,通过顺序级联每个cell的LDN编码和直方图,可以得到人脸表情图像的全局纹理信息,如公式(7)所示。其中si为第i个cell。
(7)
LDN算法对噪声和光照有较好的鲁棒性,可以有效地描述人脸表情的方向纹理信息。
2 文中模型
针对单一特征可能会丢失部分表情图像信息的问题,设计一种多特征融合的并行网络,如图2所示。上侧通道通过参考DenseNet结构,设计了三个Dense Block级联的浅层网络结构,用以提取人脸表情特征,下侧通道通过LDN算法提取表情图像的方向信息,将两种方法提取的特征进行融合,最后一起送入SoftMax进行表情分类。
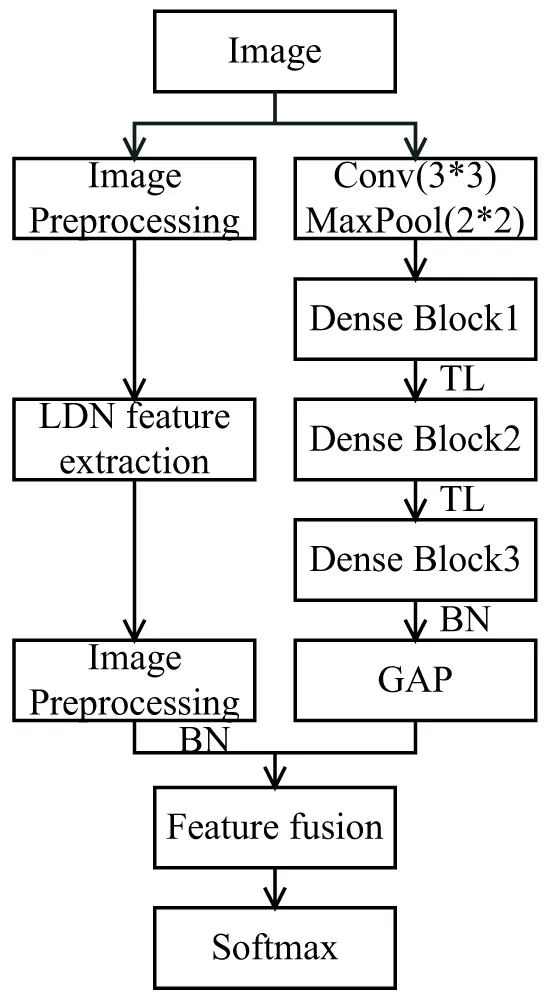
图2 文中网络模型
左侧通道通过预处理表情图像与kirsch算子卷积得到每张图像的各个方向信息,利用公式计算最高正响应和最低负响应,得到每张图像的局部方向数字编码,再将编码输入到全连接层,经过BN层后与右通道提取的稠密特征级联。
右侧通道是改进的Dense Block结构(如图3所示),特征图通过瓶颈层(bottleneck layer)Hi(i=1,2,3)后在通道上进行叠加。图4为瓶颈层结构,每个Dense Block结构中包含3个bottleneck layer结构级联,每个瓶颈层中包含64个1*1卷积核和32个3*3卷积核,右侧通道网络总层数为20层,在利用稠密网路结构特点的同时大大缩短稠密网络的层数,缩短每个Dense Block深度的同时增加每层卷积核来增加特征图的数量尽可能提取图像的隐性特征。为防止特征图在之后的卷积层中叠加过多造成特征冗余,在每两个Dense Block之间增加过渡层(Transition Layer,TL结构),压缩系数为0.5,用来缩小图像尺寸和防止特征冗余。
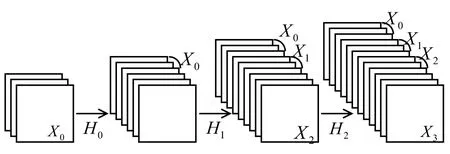
图3 Dense Block i(i=1,2,3)结构
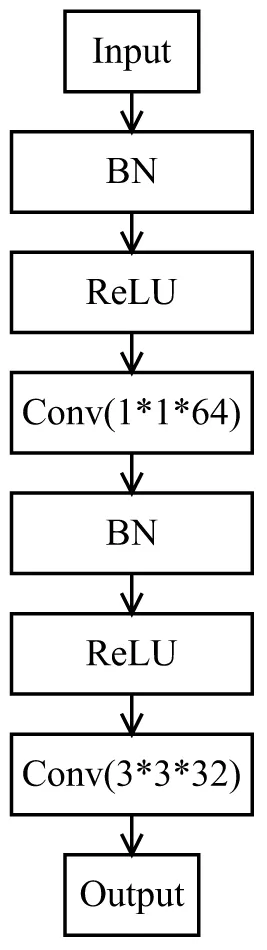
图4 bottleneck layer
3 仿真实验
3.1 数据集预处理
CK+[11]数据集由123名参与者的593个表情图像序列组成,包含7种基本表情:生气、蔑视、厌恶、恐惧、高兴、悲伤、惊讶。从每个序列中选取3幅最具表情代表性的人脸图像。通过人脸检测选取人脸部分,并将图像裁剪为48*48大小的人脸表情图像,如图5所示。

图5 CK+数据集
Jaffe数据集是由10位日本女性在实验室条件下根据指示做出的7种表情,包括生气、厌恶、恐惧、高兴、悲伤、惊讶、中性,共213张图像,如图6所示。通过对每张图像镜像反转并在左上角、右上角、右下角、左下角、中心方位裁剪为42*42的图像,将数据集扩大10倍,再送入模型进行训练。

图6 Jaffe数据集
3.2 实验结果分析
将数据集分成5份,令其中4份作为训练集,1份作为测试集,并将5次测试结果取平均作为最终的识别率。为了增加模型的鲁棒性,对训练集部分作数据增强:随机水平翻转、随机角度旋转、随机水平或者垂直方向平移、随机缩放等操作。模型采用Adam优化器,进行150轮训练,初始的学习率为0.001,经过100轮训练之后,学习率衰减10倍继续进行训练。CK+数据集的批数量为64,由于Jaffe数据集的样本数量相对较少,批数量为16。
表1为CK+数据集测试集的混淆矩阵。从表1中可以得出高兴、厌恶、恐惧和惊讶的表情识别率最高,蔑视的表情识别率相对较低,模型将某些蔑视的表情误分类成恐惧,通过观察CK+数据集中的蔑视类和恐惧类表情,原因可能是试验人员在发出蔑视和恐惧表情时带有相似特征,如嘴巴紧闭等,增加了两类表情的混淆度。
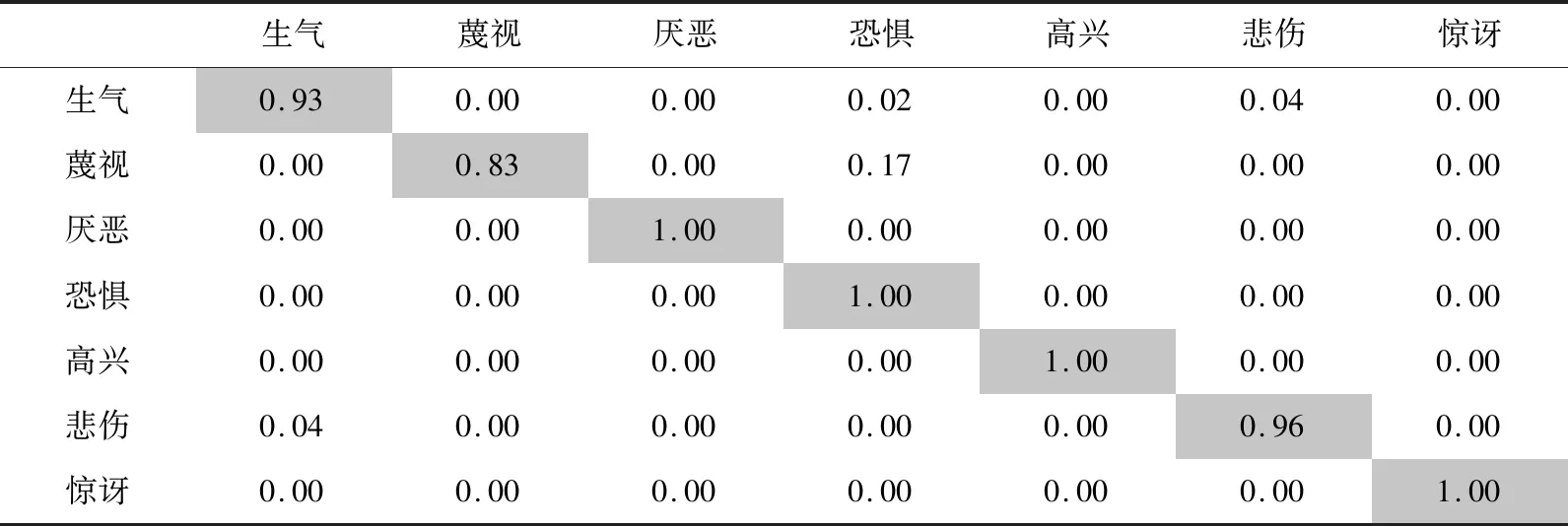
表1 CK+数据集混淆矩阵
表2为针对CK+数据集的不同算法之间识别率的对比,文献[12]提出了特征冗余缩减卷积神经网络(FRRCNN),通过在同一层的特征映射之间呈现更具辨别力的图像特征来减少冗余,文献[13]通过利用方向信息和三元模式有效地编码情绪相关特征,文献[14]提出了一种表情敏感对比损失方法来度量表情相似度并且提出了一种身份敏感的对比损失算法,用于从身份标签中学习身份相关信息,实现身份不变表达式识别,都取得了不错的识别率。从表2中可以看出,利用稠密网络改进的卷积神经网络取得了94.57%的识别率,但是由于数据量小,单一特征容易丢失表情图像信息的问题,表情识别率并不算高。提出的稠密特征与LDN特征融合算法在一定程度上弥补了单一特征的不足,提高了表情的识别率,证明该算法有一定的有效性。

表2 CK+数据集算法对比
表3为Jaffe数据集的混淆矩阵,从表中得出惊讶和中性的表情识别率相对较高,达到98%。生气和厌恶表情的识别率相对较低,分别被误分为悲伤和恐惧。对比欧美人组成的CK+数据集,亚洲女性组成的Jaffe数据集中面部表情幅度较小,而且生气会伴随悲伤,恐惧伴随厌恶,具有相似的特征,因此增加了表情的混淆度。
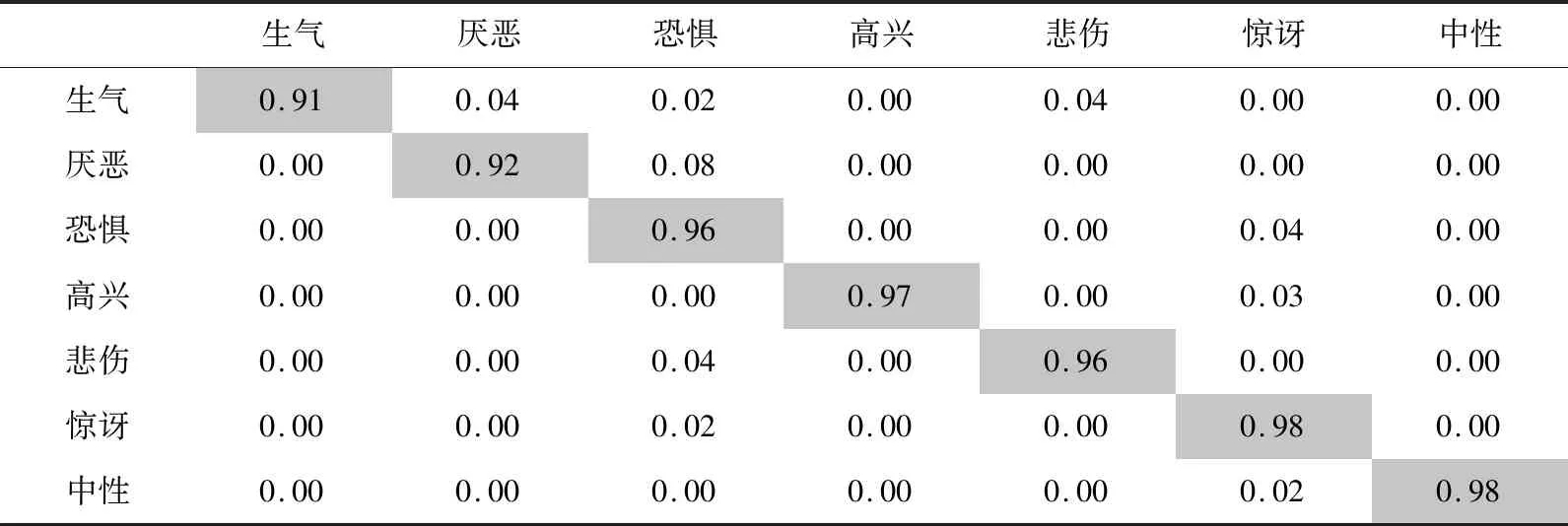
表3 Jaffe数据集混淆矩阵
表4为Jaffe数据集的不同算法之间识别率对比。文献[15]采用Cabor小波变换提取图像特征再利用神经网络进行分类,用单一方法很难提取表情图像的全部特征,并且该数据集相对较小,使得提取的图像特征更少,因此该方法的识别率并不高。文献[16]通过训练一个点分布模型(PDM)来提取人脸特定区域的几何特征,再利用SVM进行分类。但是该方法依赖特定区域的定义,而且部分表情的变化对特定区域的改变很难察觉。文献[17]的ARLCP算法是利用边缘响应的符号、幅度和方向信息提取表情图像相关特征,但单一方法难以提取表情的全部信息,因此改进的DenseNet方法取得的识别率不高,通过结合LDN算法提取的特征,经过5折交叉验证,并将5次测试结果取平均值后取得95.43%的识别率。

表4 Jaffe数据集算法对比
表5为模型参数量的对比,其中VGG模型深度为10层,参数量为180万左右。DenseNet具有独特的特征提取和传递方式,对比相同深度的卷积神经网络,其模型总体的参数复杂度会低很多。而改进的DenseNet缩短了原模型的深度,进一步减少了参数复杂度。在其基础上结合LDN特征提取算法,最终提高了模型的人脸表情识别率。虽然在一定程度上增加了参数复杂度,但相比VGG模型的参数量,总体增加的参数复杂度并不大。
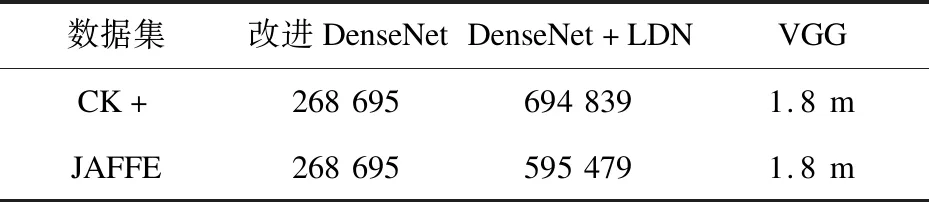
表5 参数量对比
4 结束语
针对在小数据集上单一特征可能丢失表情图像部分信息,该文提出一种多特征融合的并行网络,将DenseNet网络提取的稠密特征与LDN算法提取的特征进行融合,再用Softmax进行分类。对比改进DenseNet网络在CK+数据集和Jaffe数据集上的识别率,有一定的提升,证明了该并行网络的有效性。且该方法采用稠密连接的特点和缩短网络深度后使得网络的参数量较少,但该网络在有效提高表情识别率的同时也增加了算法复杂度,下一步工作可以继续优化网络模型和参数。
