基于遗传算法的岩体结构面产状的自动聚类方法研究
2022-10-20崔学杰陈江军向进洋关义涛胡小庆
崔学杰, 陈江军, 向进洋, 关义涛, 胡小庆
(1.湖北省地质局 水文地质工程地质大队,湖北 荆州 434020; 2.资源与生态环境地质湖北省重点实验室,湖北 武汉 430034)
地下水封储油(气)洞库是目前国际上石油、液化气等能源的主要储存方式[1]。结构面对岩体结构起控制作用,对地下水封洞库围岩的稳定性有重要影响[2-4]。由于地下水封洞库埋深大,结构面信息的获取目前主要依靠钻孔摄像(或电视)技术[5-6]。
结构面数据分析的首要任务是对结构面进行分组,传统方法是根据结构面走向玫瑰花图或极点密度等值线图来进行分组,该方法简单、直观,但结果依赖于分析者的个人经验,缺乏客观性,同时在数据量较大时不可用[7]。Shanley et al.[8]和Mahtab et al.[9]率先提出了用于结构面产状分组的聚类方法。Hammah et al.[10-12]采用模糊C均值(FuzzyC-means,FCM)方法进行结构面组数的划分,并讨论了常用的距离量度和聚类有效性指标。FCM是K-means算法结合模糊理论的改进版本,但二者都使用Picard迭代算法来最小化目标函数[13],因而易收敛于局部最优解,且聚类结果受初始聚类中心影响。Jimenez-Rodriguez et al.[14]尝试通过对相似度矩阵进行特征分解,从而将原始数据转换到区分度更显著的空间,提出了用于结构面分组的谱聚类方法,该方法避免了选择初始聚类中心的困难,但仍不能完全保证收敛于全局最优解。Xu et al.[15]将问题变量从解空间转换至混沌空间,开发了基于多尺度混沌优化算法的FCM算法,利用混沌变量的随机性、有序性和遍历性搜索从而获得全局最优解。Li et al.[16]提出了基于粒子群优化算法的K-means算法(KPSO),该方法的性能略优于Xu et al.[15]的方法。类似地,Song et al.[17]提出了基于量子粒子群的FCM算法(QPSO)。上述方法尽管改善了一些缺陷,但均需要指定结构面组数作为输入值,否则需要进行大量试算。
遗传算法(Genetic Algorithm,GA)是一种高效、稳健的随机优化技术,理论和经验都表明该方法将提供全局最优解[18-21]。遗传算法在土木工程和地质工程领域获得了大量的应用,其有效性获得广泛地验证[22-26]。基于上述认识,本文对传统遗传算法做了改进,结合FCM算法,提出了一种用于结构面产状分组的聚类算法,并将其用于分析某地下水封洞库结构面产状数据,从而验证该方法的有效性。
1 结构面产状的表示方法
结构面通常被假设为空间中一个几何平面,其产状使用倾向α(0°≤α≤360°)和倾角β(0°≤β≤90°)表示,也可用结构面单位法向量或单位矩阵表示。如图1所示建立空间直角坐标系:x1轴正向指向正北,x2轴正向指向正东,x3轴正向指向上。图1中的结构面j可以由公式(1)表示。同时,公式(1)也可以表示定义在单位球体上半球面上的点的集合,因此参考文献[10]也将产状数据归类为球状数据。
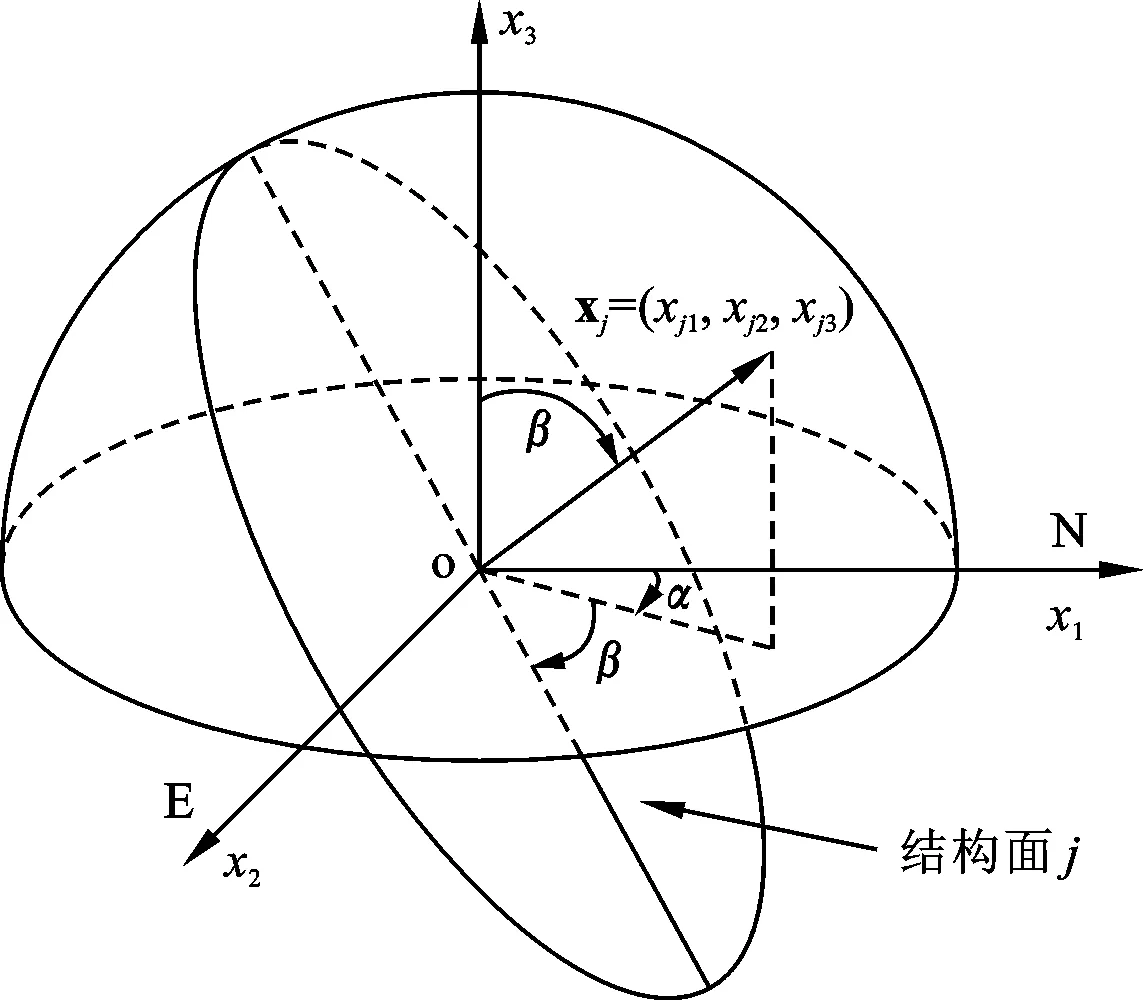
图1 结构面产状表征示意图
(1)
2 FCM算法
FCM算法是常用的动态聚类分析算法之一,这里作简要介绍。假设实测了n个结构面产状,用集合X表示,即X={x1,x2,…,xn},其中每一个元素都可以用一个3维向量表示,如公式(1)中的xj。FCM算法的目标是依据数据的相似性或非相似性,根据隶属度将数据集合X划分为K个子集(或组),如{C1,C2,…,CK}。FCM算法通常包含以下步骤[10,13]:
(1) 从数据集合X={x1,x2,…,xn}中随机选择K个数据作为初始聚类中心,即z1、z2、…、zK;
(2) 计算模糊隶属度矩阵U(X)=[ukj]K×n,其中:
(2)
式中:i,k=1,2,…,K;j=1,2,…,n;m为模糊指数,一般取m=2[13];D(zk,xj)表示xj与Ck组的聚类中心zk非相似性(或距离)。对于结构面产状等球状数据,参考文献[11]建议使用结构面法向量夹角或夹角的函数表示结构面产状的距离,即
(3)
式中:T表示矩阵转置。
(3) 根据模糊隶属度矩阵,计算新的聚类中心z′1、z′2、…、z′K。对于结构面数据等球状数据,参考文献[12]建议使用特征分析方法计算聚类中心,对于第k组结构面数据,需要先计算模糊产状矩阵Sk=[Sk,uv]3×3,其中:
(4)
式中:u,v=1,2,3。计算矩阵Sk的特征值λk1、λk2、λk3和归一化特征向量ηk1、ηk2、ηk3,如果λk1<λk2<λk3,则最大特征值λk3对应的特征向量ηk3为第k组的聚类中心,即:
z′K=ηk3
(5)
(4) 计算目标函数。计算公式如下:
(6)
(5) 重复步骤(2)—(4),直到目标函数Jm达到最小值,或U(X)不再发生改变。
3 基于遗传算法的FCM算法
遗传算法是由Holland受生物进化和自然遗传理论启发提出[20],适用于空间大、复杂且多峰的搜索和优化问题。该算法是一种全局优化搜索算法,具有简单通用、鲁棒性强等优势,其核心思想是将问题可能的解编码为字符串格式(称为染色体或个体),并将多个个体组成一个种群;种群遵循自然选择、适者生存的进化原则,在遗传算子引导下繁衍后代,产生新的种群;经过若干代后,算法收敛于最优个体。该算法主要包括编码方法与种群初始化、适应度函数和遗传算子三个部分。
3.1 编码方法与种群初始化
传统的编码方法通常以聚类中心作为遗传信息,将其编码为染色体。对于结构面产状数据的分组问题,结构面组的平均产状即为聚类中心。以种群中第i个染色体为例,如果通过现有资料能够确定有K组结构面,则染色体中将包含K个聚类中心,长度为3K(图2-a)。在无法预先确定结构面组数时,需要将K设置为不同的整数值进行试算。
为了克服上述缺陷,这里介绍一种新的编码方法。首先需要预估一个分组的上限值Km(图2-b)。对于结构面产状数据,为保守起见,可令Km=10。与传统方法不同,新方法为每一个聚类中心z附加一个随机实数变量p(0 ≤p≤ 1)。为了便于说明,这里借助于遗传学术语,将实数变量p称为启动子,而对应的聚类中心称为外显子,二者组成一个基因组,如pi1和zi1为染色体i的第1个基因组。启动子的作用在于控制对应的外显子是否表达,即聚类中心是否参与聚类过程。为了便于实现,这里采用如下简单规则:当启动子>0.5时,对应的外显子表达。使用该编码方法时,尽管种群中染色体长度相同,但由于染色体中启动子为随机变量,有效的聚类中心数量将是动态变化的,这样便可以实现结构面组数为动态的聚类分析。

图2 两种不同编码方法示意图
种群初始化如下所述:对于任一条染色体,首先从均匀分布U[0,1]中随机产生Km个实数初始化启动子,再从结构面产状数据中随机选择Km个产状数据初始化外显子;如果种群中包含P个染色体,上述步骤将重复P次以完成种群初始化。注意,初始化完成后,应检查初始种群中的每一条染色体是否合格,若染色体中>0.5的启动子数量<2,则该染色体不合格,需重新初始化。
3.2 适应度函数
根据自然选择、适者生存的原则,个体的适应度越高,其繁衍后代并构成新种群的可能性越大。对于聚类问题,常用的做法是将聚类有效性指标作为适应度函数,定量评价染色体所对应的聚类结果的优劣,即适应度值。适用于FCM算法的模糊聚类有效性指标包括目标函数Jm、划分系数PC、划分熵指标PE、Xie-Beni指标、Fukuyama-Sugeno指标VFS等[27-28]。这里仍选择应用较为广泛的Xie-Beni指标,其定义如下[29]:
(7)
式中:K′表示有效聚类中心数量;σ表征组内紧凑度,值越小表示聚类效果越好;sep为组间距离的最小值,表征组间分离度,值越大表示聚类效果越好;其他符号与前述一致。
由公式(7)可知,当聚类效果最优时,XB指标取最小值。因此,应将适应度函数定义为XB指标的倒数,即
(8)
对于当前种群中的任一染色体,需要按以下步骤计算其适应度值:①提取染色体中有效聚类中心,并确定K′值;②按照FCM算法对结构面产状数据进行聚类;③将最终的隶属度矩阵和聚类中心代入公式(8)计算适应度值。
3.3 遗传算子
选择、交叉和变异是三种基本遗传算子,其共同引导种群的进化。
3.3.1选择算子
选择算子模拟达尔文进化论中的自然选择和适者生存过程。适应度越高的个体,有更高的概率被选择,从而繁殖后代,将遗传信息传递给后代。换言之,只有被选择的个体才能参与交叉和变异过程。常用的方法有赌轮盘选择法、锦标赛选择法、随机遍及取样法等[30]。本文选择易于实现的赌轮盘选择法。
3.3.2交叉算子
交叉算子交换父代个体的遗传信息,产生与父代不同的后代。单点交叉、两点交叉、多点交叉和均匀交叉是常用的交叉方法[20,30]。交叉虽然能够增加种群的多样性,但同时也存在破坏优势基因组合的风险。权衡利弊,这里选择两点交叉法,且设置交叉概率为μc(0<μc<1)。在交叉过程中,每一个聚类中心都被视为一个不可分割的三维向量,即交叉点只能位于启动子和外显子之间。举例说明(图3),如果个体1、个体2被选为父代个体,且交叉点位置如图3-a中箭头所示,则执行交叉后的子代个体如图3-b所示。交叉完成后,个体3与父代个体1相比较,其获得了两个新的外显子z21、z22,但外显子z21是否表达取决于启动子p11,而原始外显子z13是否表达取决于新的启动子p23。子代个体4情况相似。两点交叉法在提高基因重组概率的同时,使得对基因组的破坏仍相对较小。

图3 交叉算子示意图
3.3.3变异算子
变异算子通过产生新的基因来保持种群多样性,即引导探索新的搜索空间,防止受限于当前局部空间。对于所使用新的编码方法,启动子和外显子将采用不同的变异方法,但变异概率均设置为μm(0<μm<1)。
对于染色体中的任一启动子pik,变异后的启动子p′ik按下式计算:
p′ik=pik±0.5
(9)
式中:±号取正和取负的概率均为0.5。变异后的启动子若<0,则设置为0;若>1,则设置为1。
聚类中心zik的变异是通过向量的旋转运算实现的。如图4所示,将zik假想为一虚拟结构面,αik、βik分别表示其倾向和倾角,则:
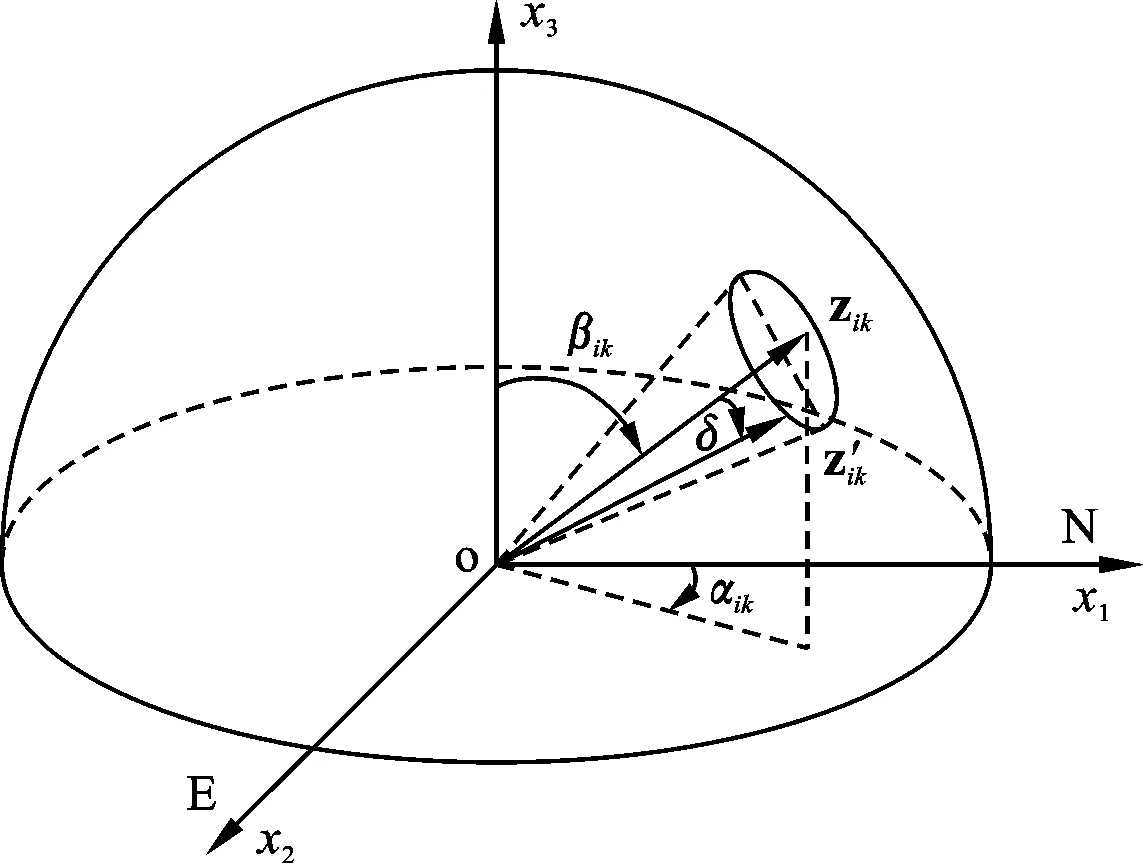
图4 变异算子示意图
(10)
假设新的聚类中心为z′ik,与zik之间的夹角为δ(图4)。显而易见,新的聚类中心z′ik是将zik绕原点o旋转角度δ而产生,而旋转方位角θ则是随机的,将从均匀分布U[0,2π)中随机产生。变异的数学表达如以下公式所示:
(11)
式中:R2(βik)、R3(αik)分别表示将向量绕x2轴、x3轴旋转的旋转矩阵。
(12)
(13)
3.4 收敛准则
本文使用精英模型[18,30]来保证最优个体不会因遗传算子的随机性而被遗漏。当种群中最优个体的适应度值无明显变化时,认为算法收敛。
3.5 算法的实现
采用C++语言实现了上述算法。算法采用通用性较强的文本文件(.txt)作为输入、输出格式,结构面产状作为输入数据,输出信息包含结构面组数、隶属度矩阵、平均产状等。
4 工程实例应用
该地下水封储油(气)洞库位于浙江省东部沿海地带,主要岩性为上侏罗统高坞组花岗斑岩,结构面比较发育。根据设计运行压力已确定洞库埋深,结构面的发育规律对主洞室轴向有重要影响,进而影响洞库的平面布置和主洞室截面形状的选择。为了探明设计埋深区域内结构面发育情况,进行了初步的勘探工作。本文选用了操作竖井附近的1条垂直钻孔,根据其声波电视解译结果(图5)获得了从地表至-172 m高程范围内的386个结构面产状数据,其等密度极点投影如图6所示。

图5 声波钻孔电视成像图(91~96 m)

图6 结构面等面积上半球极点投影图
由图6可知,陡倾角结构面的极点投影较为集中,构成了3个高密度区,按照经验应分为2组结构面,一组倾向NE,一组倾向SE;中—缓倾角结构面数量少,极点投影比较分散,将这些结构面分为1组或2组都是合理的。因此,若采用目前常见的聚类算法,需要试算来确定结构面组数。为了验证本文提出的基于遗传算法的FCM算法的有效性,使用该方法对图5所示结构面产状数据进行分组,所用的参数如表1所示,聚类结果如图7和表2所示。新方法将所获得的结构面按产状分为3组,其中中—缓倾角结构面被分为1组(J3)。为了验证该方法的合理性,使用Li et al.[16]提出的KPSO法计算结构面组数不同情况下的Ray-Turi指标值,结果见表3。由结果可知,Ray-Turi指标在结构面组数为3时取得最小值,即最优组数应取3,与本文提出的方法结果一致。结构面的分组成果将为洞室的设计和围岩稳定性分析提供参考。

表1 基于GA的FCM算法参数表

表2 使用基于GA的FCM算法的结构面聚类结果
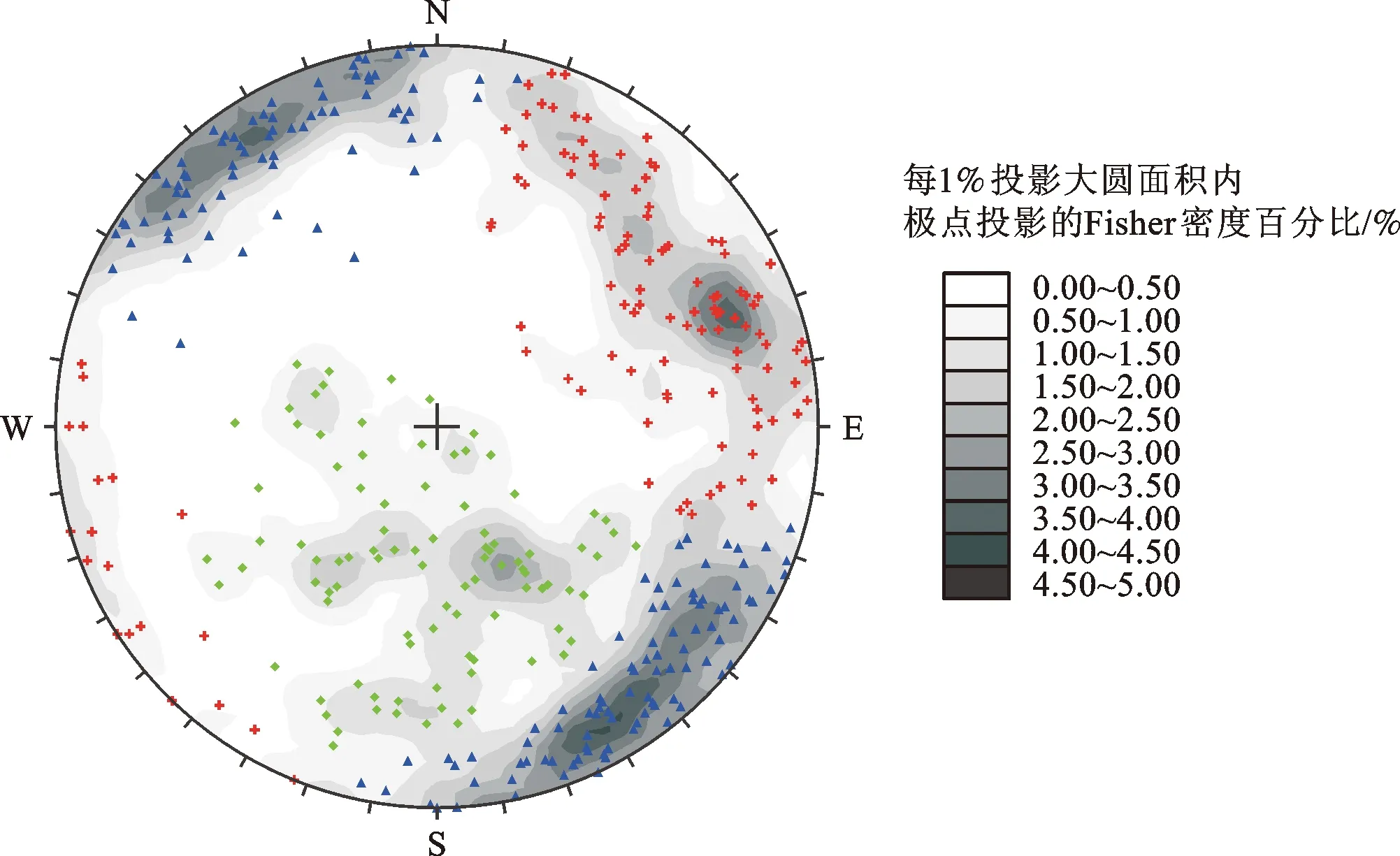
图7 聚类结果等面积上半球极点投影图

表3 不同结构面组数情况下KPSO方法聚类结果的Ray-Turi指标值
5 结论
根据结构面产状进行优势分组是开展岩体稳定性分析工作的基础。与传统方法相比,聚类方法更加客观且分组结果更加明确,FCM算法是常用的动态聚类分析算法之一,但也存在明显缺陷。鉴于遗传算法较强的稳健性和全局最优性,将其与FCM算法结合,提出了一种用于分析产状数据的聚类方法,该方法的聚类结果不受初始聚类中心影响,总是能够收敛于全局最优解;而且由于使用了新的染色体编码方法,该方法无需输入结构面组数,在难以确定结构面组数的情况下,能够节约大量时间。与现有聚类方法相比,该方法参数较少、客观性更强。将该方法用于某地下水封储油(气)洞库结构面产状数据的聚类分析,获得了明确、合理的结构面分组,可见此方法具有良好的工程实用性。
